目录
buffer的commit字段
commit字段的含义即为提交,即提交给消费者处理的数据。
赋值部分之分配新内存
buffer的commit字段,是used字段的影子,即每次申请一个新buffer时,会将此前已经满了的buffer的commit字段赋值为used的值。
b = buf->tail;
/* This is the slow path - looking for new buffers to use */
n = tty_buffer_alloc(port, size);
if (n != NULL) {
n->flags = flags;
buf->tail = n;
/* paired w/ acquire in flush_to_ldisc(); ensures
* flush_to_ldisc() sees buffer data.
*/
smp_store_release(&b->commit, b->used);
/* paired w/ acquire in flush_to_ldisc(); ensures the
* latest commit value can be read before the head is
* advanced to the next buffer
*/
smp_store_release(&b->next, n);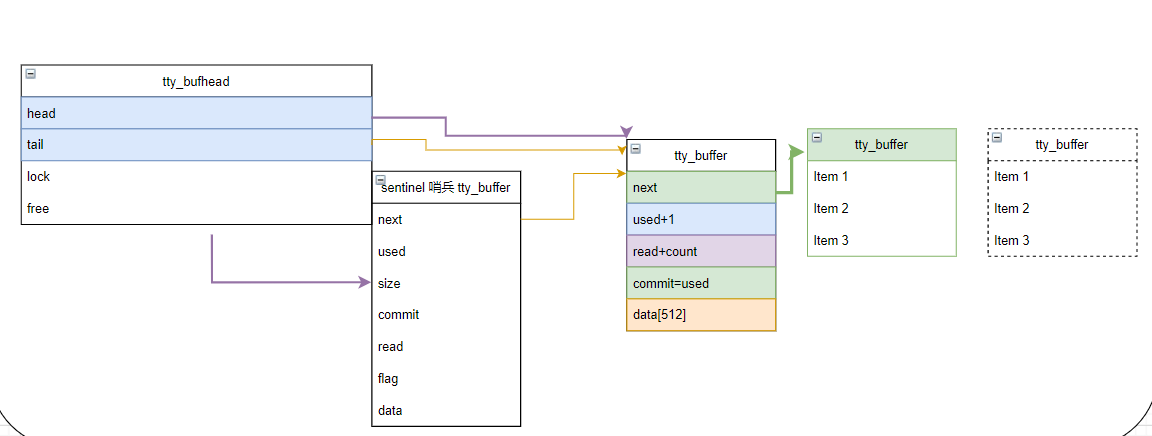
如上图绿色部分,为分配新buffer时相关结构体字段的变化。commit仅仅作为used的一个影子值,需要注意: 此处仍然处于中断上下文中。
1) buffer tail指向绿色新buffer
2) commit记录used的数值
应用
应用则在work上下文中,此处注释与赋值时的注释遥相呼应。当中断中写入的数据,即commit字段与read字段相同时,即表示此buffer中数据已经被取走了,则
next = smp_load_acquire(&head->next);
/* paired w/ release in __tty_buffer_request_room() or in
* tty_buffer_flush(); ensures we see the committed buffer data
*/
count = smp_load_acquire(&head->commit) - head->read;
if (!count) {
if (next == NULL)
break;
buf->head = next;
tty_buffer_free(port, head);
continue;
}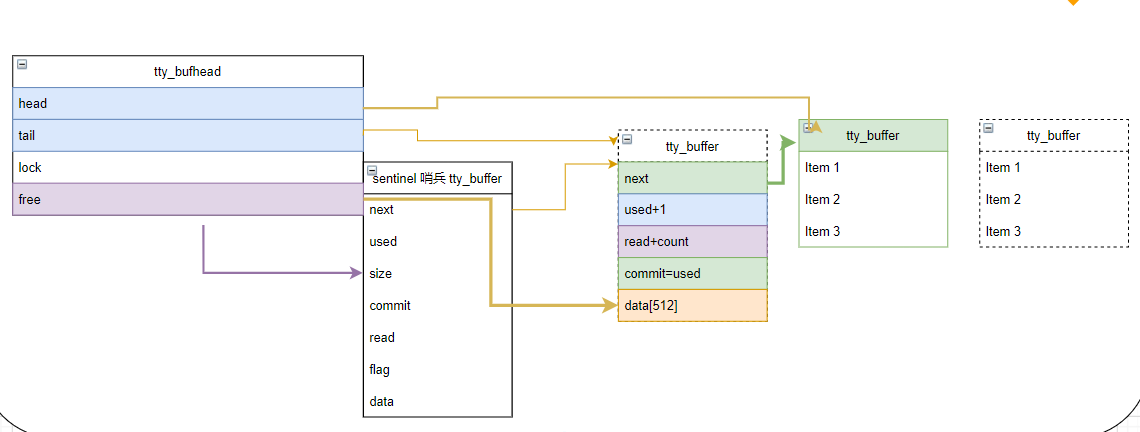
1) 移动head 到绿色buffer
2) 将原先buffer放入free链表中
如果commit 大于read,则继续通知用户读取。
总结
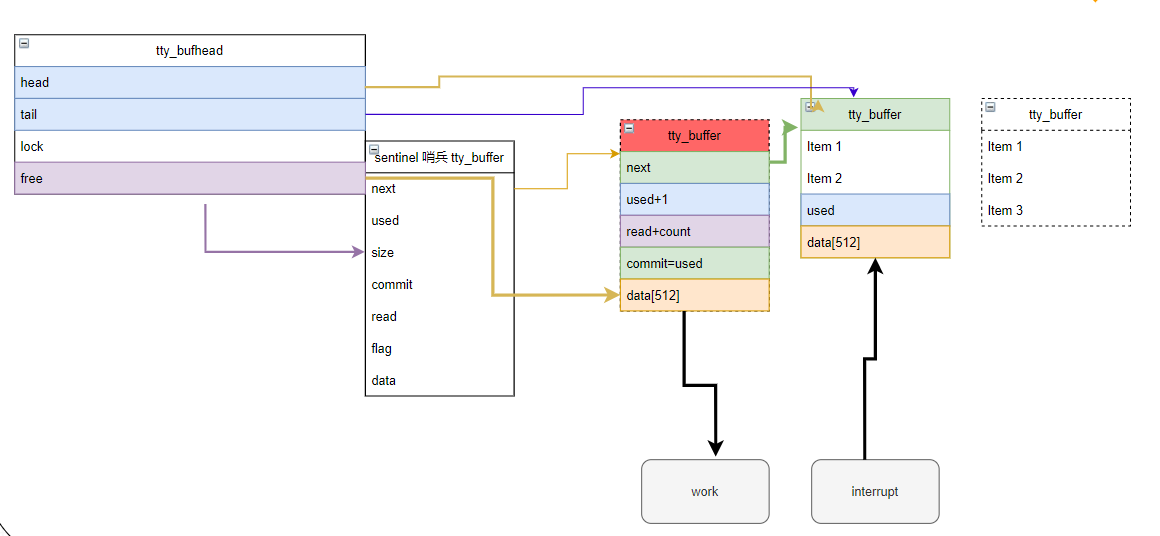
基于上述两节的过程,看起来
1)work每次从红色tty_buffer读取数据
2) 中断往绿色tty_buffer中写入数据。
假设中断往绿色的写入了100个字节,而后再没有数据从串口进来了,此时绿色tty_buffer的commit依然是0,read依然为0,最后这个buffer中的数据不能被接收到了!
同步作用
1) 假设没有commit字段
// 假设初始状态:b->used = 0, b->read = 0
// 生产者代码(编译后可能被重排):
void producer() {
// 写入数据
b->data[0] = 'A'; // (1) 写入数据A
b->data[1] = 'B'; // (2) 写入数据B
b->used = 2; // (3) 更新used计数器
}
// 消费者代码:
void consumer() {
if (b->used > b->read) { // (4) 检查有新数据
char data1 = b->data[0]; // (5) 读取数据A
char data2 = b->data[1]; // (6) 读取数据B
process_data(data1, data2);
}
}上述代码存在以下可能性,由于重排
CPU 1 (生产者) CPU 2 (消费者)
b->used = 2; if (b->used > 0) → true! (看到used=2)
char data1 = b->data[0]; → 垃圾值! (数据还没写入)
b->data[0] = 'A';
b->data[1] = 'B';2) 增加commit字段,并且采用smp_strore和smp_load函数
// 生产者代码:
void producer() {
// 1. 写入数据
b->data[0] = 'A'; // (1)
b->data[1] = 'B'; // (2)
b->used = 2; // (3)
// 2. 发布提交 - 关键!
smp_store_release(&b->commit, b->used); // (4)
}
// 消费者代码:
void consumer() {
// 1. 获取提交点 - 关键!
size_t commit = smp_load_acquire(&b->commit); // (5)
if (commit > b->read) {
// 2. 安全读取数据
char data1 = b->data[0]; // (6)
char data2 = b->data[1]; // (7)
process_data(b->read, commit, data1, data2);
}
}smp_store_release(&b->commit, value) 保证:
-
在存储commit之前的所有内存写入都对其他CPU可见
-
存储commit操作本身不会被重排到之前的写入之前
smp_load_acquire(&b->commit) 保证:
-
在加载commit之后的所有内存读取都不会被重排到加载之前
-
会看到smp_store_release发布的最新值
CPU 1 (生产者) CPU 2 (消费者)
b->data[0] = 'A'
b->data[1] = 'B'
b->used = 2
commit = smp_load_acquire(&b->commit)
smp_store_release(&b->commit, 2)
↓ (看到 commit == 2)
data1 = b->data[0] // 保证看到 'A'
data2 = b->data[1] // 保证看到 'B'
commit字段通过内存屏障解决了以下问题:
-
编译器重排序:防止编译器优化破坏写入顺序
-
CPU重排序:防止CPU乱序执行导致数据不一致
-
缓存一致性:确保写入数据对其他CPU核心可见
-
可见性时序:建立明确的"数据就绪"时间点
核心原理 :smp_store_release和smp_load_acquire创建了一个同步点,确保在这个点之前的所有写入,在这个点之后的所有读取都能看到完整的结果。
同时,这里采用commit一次性提交了一个tty_buffer,而非单字节提交。
最后tty_buffer数据的提交
buffer的lock字段
static void flush_to_ldisc(struct work_struct *work)
{
struct tty_port *port = container_of(work, struct tty_port, buf.work);
struct tty_bufhead *buf = &port->buf;
mutex_lock(&buf->lock);在所有代码实现中,只看到了此接口中有lock,作为一个消费者,它用于和谁的并发控制呢?
同步作用
与工作队列调度器同步
代码中调度工作队列的地方示例:
1) 中断接收完字节后
2) 读取数据时。通过接口 n_tty_kick_worker
/没有这个锁,flush_to_ldisc可能并发执行,示例如下:
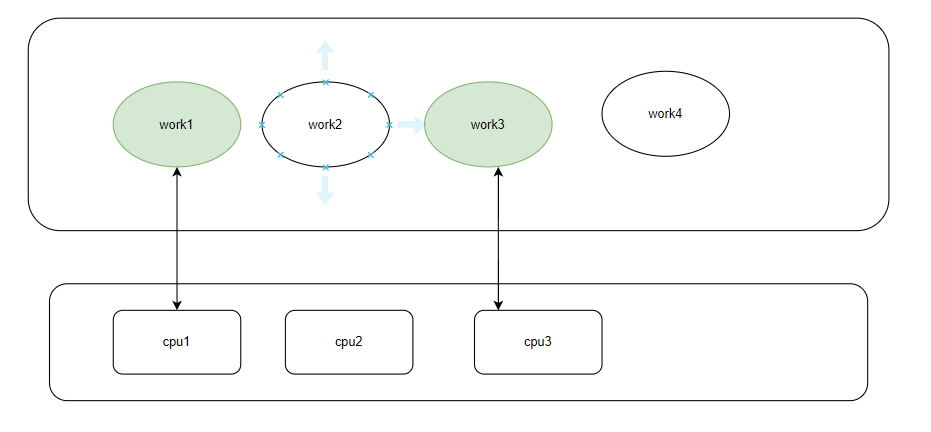
上图的情况具体描述如下:
// 假设没有mutex_lock的情况:
// CPU 1 CPU 2
// flush_to_ldisc() flush_to_ldisc()
// head = buf->head head = buf->head (相同值)
// process data process data (重复处理!)
// buf->head = next buf->head = next (竞争条件!)
// free(head) free(head) (双重释放!)mutex_lock(&buf->lock)的作用是:
-
确保
flush_to_ldisc的单实例执行 - 防止工作队列重入 -
保护线路规程的单线程要求 -
receive_buf不是线程安全的 -
保护缓冲区链表操作 - 防止并发修改链表结构
-
提供消费进度的一致性 - 确保
head->read的更新是原子的
总结
通过lock保证多个work的并发执行;通过commit字段保证生产者和消费者对数据访问的并发。
而非简单的对链表加一个锁。