很多人第一次接触各家大模型时,都会觉得它们的回答能带来意想不到的惊喜,但有时,AI回答又怪怪的、啰嗦、甚至有点危险。
这背后,其实就是一个核心问题:对齐(Alignment)。
预训练让模型会"说话",但对齐训练,才让模型更符合人类偏好:更有用、更安全、更有温度。在当下的大模型时代,有三种常被提到的对齐方法:PPO、DPO和KTO。
本期,LLaMA-Factory Online将用尽量通俗的方式,帮你搞懂它们的底层逻辑。
一、PPO:造一个"裁判",再用强化学习调教模型
PPO(Proximal Policy Optimization,近端策略优化)最经典的应用就是:RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习)。
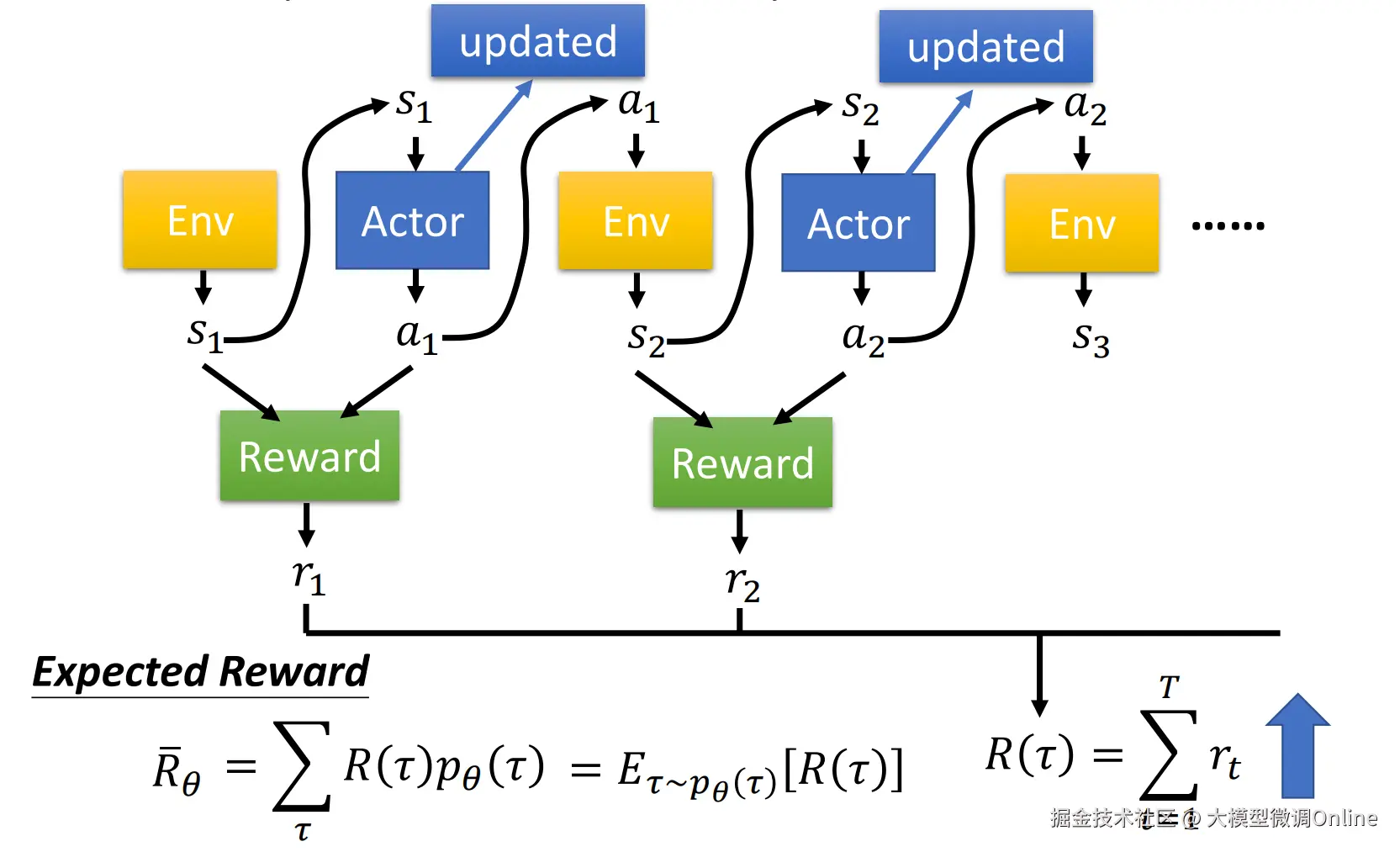
它的思路是"三件套":
● 先由"SFT老师"教模型基础礼仪
用高质量指令-回答数据,把预训练模型变成一个基本听话的聊天助手
● 再训练一个"阅卷老师RM"初步打分
让人类对一批回答打偏好,用这些偏好去训练一个专门"打分"的模型,以后看到一个回答,这个打分模型就会判断:"这个 0.9 分" 或 "这个只有 0.2 分"
● 最后用PPO算法,让模型按阅卷老师给的分数改进回答
先让模型生成回答,高分回答方向上的参数被奖励模型"鼓励",低分回答方向被"惩罚"。每次更新,又会用 PPO 的"裁剪机制"限制更新幅度,防止模型突然学偏
为什么大家爱用 PPO?又为什么很多团队逐渐"逃离"它?
优点:
● 上限高,通用性强:有了奖励模型,你可以把任意"主观偏好"变成一个可学习的分数。模型的回答是否符合事实、是否礼貌、是否安全、是否有条理等要素,都可以揉进一个奖励里,PPO 按这个总分来优化,想象空间很大。
● 理论成熟,工业验证充分:ChatGPT、Claude 早期版本等,都用 PPO+RLHF 这套路线走起来的,对大厂来说,这是"保险方案"。
缺点:
● 流程复杂、成本高:至少要维护两个大模型(基座 + RM),训练管线复杂、显存压力巨大,对中小团队来说,非常"肉疼"。
● 容易被"奖励黑客":裁判是模型,它也会"犯蠢":比如误把"长篇大论"当成高质量,结果你看到的就是:回答变得又长又啰嗦,但不一定更有用。
● 对长推理任务不友好:很多数学/代码题,只在"最终答案对不对"这里给奖励,中间推理过程没标注。价值函数不好学,PPO 更新就会非常不稳定。这也是后来 GRPO、GSPO 等新算法诞生的重要原因。
如果你手头只有几张 GPU,还想用 PPO+RM 跑一套完整 RLHF 流程,大概率会被现实猛猛教育一下。
但如果你有技术、有精力,可以在LLaMA-Factory Online中,以平民价用H卡训练市面上各种强大模型,享受优惠的同时,性能绝不缩水。

二、DPO:直接教学生分好坏
DPO(Direct Preference Optimization,直接偏好优化)的出发点很简单:既然人类已经告诉我们 A 比 B 好,为什么还要多绕一步去训一个奖励模型?直接用这对偏好数据更新大模型本身不就行了?
所以,DPO 直接跳过奖励模型RM的训练流程,用一个特殊的损失函数,让模型满足这样的目标:在同样的输入下,提高"偏好回答"的生成概率,降低"非偏好回答"的生成概率。
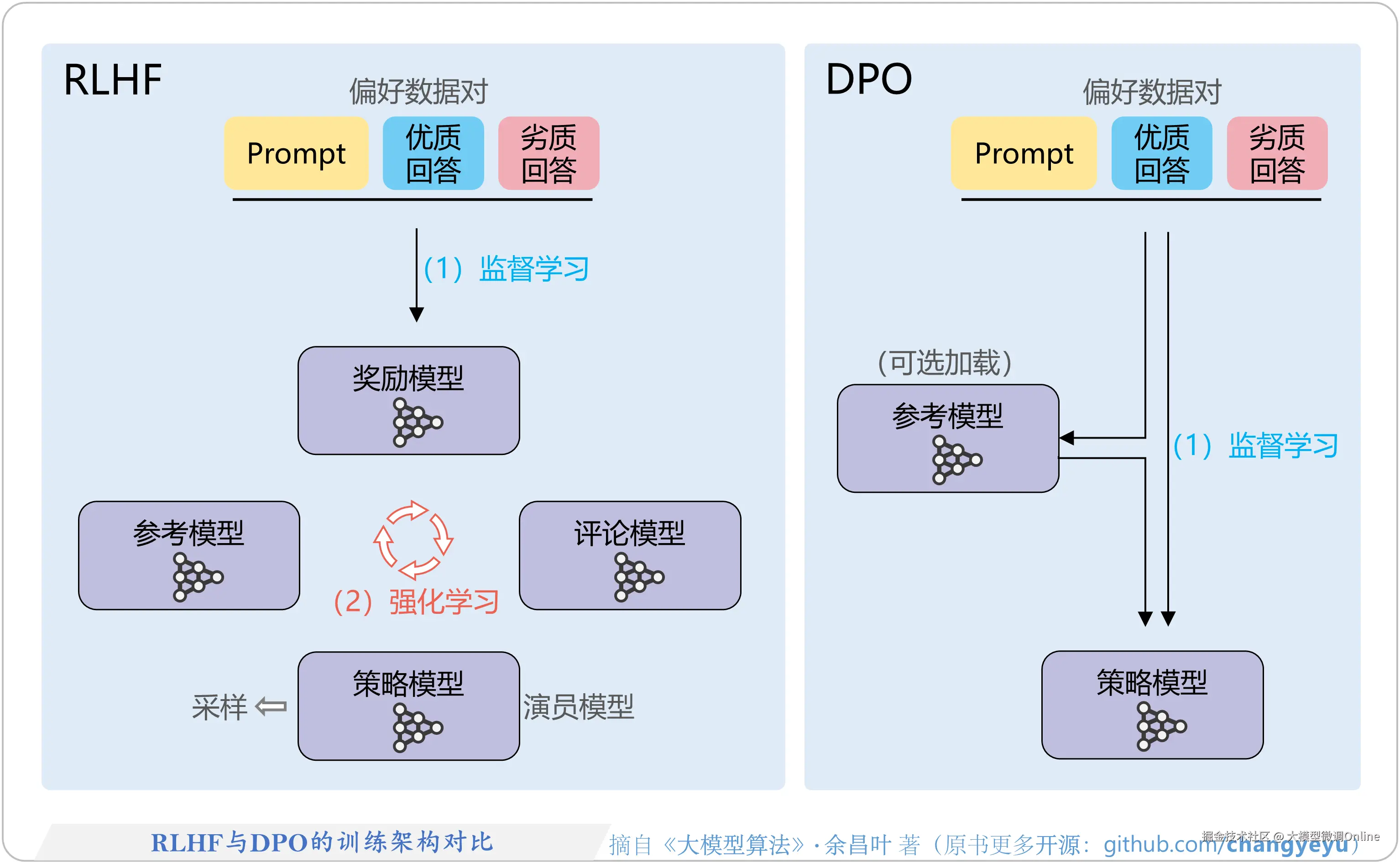
一条典型 DPO 样本是这样的结构:
makefile
{
输入:用户问题 x
偏好回答: y_preferred
非偏好回答: y_dispreferred
}我们可以发现,和PPO相比,DPO中间整整省掉了一整个模型和一套管线。
DPO 的优缺点:典型的"中量级选手"
优点:
● 不用奖励模型,算力成本与工程复杂度骤降,比 PPO 至少少一大截,对中小团队、开源社区尤其友好。
● 训练稳定,没有价值函数、优势估计这些"强化学习坑点",训练过程更像普通 SFT。
● 效果可观,在很多对话任务上,适当规模的成对偏好数据 + DPO就能把一个 SFT 模型拉到接近GPT-3.5的体验。
缺点:
● 非常依赖偏好数据质量。如果标注员的标准不统一、甚至本身理解有误,模型就会学错偏好,而且很难通过"奖励模型分析"把问题拆出来。
● 对复杂、多维度目标支持较弱。比如代码生成,你同时在意:正确性、效率、可读性,但单纯的偏好往往很难覆盖所有维度,不如 PPO+RM 那么灵活可控。
● 标注成本仍不低。成对偏好数据毕竟需要两个候选回答,再由人类比较、选择哪个更好。相比"单条打好/坏",还是贵不少------这就给 KTO 留出了舞台。
三、KTO:好与坏的极简判断
KTO(Kahneman--Tversky Optimization)名字里的两位,就是诺奖得主卡尼曼和特沃斯基------他们提出了著名的前景理论:人类对"损失"的敏感度,远远大于对"收益"的敏感度,例如捡 100 块钱没有你丢 100 块钱那么"疼"。
KTO 把这个想法搬到了模型训练里,核心有两点:
● 不再需要成对数据,只要给每个回答一个标签:
可取 / Desirable:+1
不可取 / Undesirable:-1
● 对"坏回答"惩罚更重,对"好回答"奖励更细腻
生成坏回答 → 惩罚力度大
没生成好回答 → 也会被"温柔地惩罚一下"
让模型学会:"少犯错,比偶尔超常发挥重要得多。"
和 DPO 的成对数据比,KTO 的数据格式非常朴素:
json
{
"input_x": "计算 2 + 3 × 4 的结果",
"response": "2 + 3 = 5,5 × 4 = 20。",
"desirability_label": -1 // 坏
}
json
{
"input_x": "计算 2 + 3 × 4 的结果",
"response": "2 + 3 = 5,5 × 4 = 20。",
"desirability_label": -1 // 坏
} 人类标注任务从"二选一"降维到"单条打分":看到一个回答 → 点👍 / 👎即可。
在实际平台中,这和我们给机器人"好评 / 差评"的交互方式非常接近,可以利用大量弱标注数据,快速积累样本。
KTO 的优缺点:极度节省,换来的是"粗粒度"
优点:
● 标注成本极低,不需要成对比较,大部分人只要有"常识+审美",就能给出好/坏评价,非常适合从线上用户反馈中直接挖掘训练数据。
● 训练流程简单、计算开销小,本质上是一个带特殊损失函数的"带标签微调",没有价值函数、群体对比这种 RL 元素,工程实现很友好。
● 对"不平衡场景"特别有用。比如医疗场景中:错误回答的危害远超过正确回答带来的"惊喜"。使用 KTO,可以重点惩罚那些危险、错误、消极的回答,让模型优先减少灾难性输出。
缺点:
● 只能学"好/坏",难学"细微偏好",比如两条回答都正确,一条详细带例子,一条简洁干脆,这时你想让模型倾向其中一种风格,单一好/坏标签表达力就不够了。
● 对标签质量敏感,若打标签的人并不专业,甚至情绪化,模型容易学到稀奇古怪的偏好。
● 缺少"事实性约束",只要标注员没把事实错误当"坏",模型就可能把"圆滑但不一定对"的回答学成"好风格"。
四、PPO、DPO、KTO,不同团队怎么选?
最后,把这三位主角拉到一张决策表上:
| 维度 | PPO(RLHF) | DPO | KTO |
|---|---|---|---|
| 训练流程 | 最复杂:SFT + 奖励模型 + RLHF | 类 SFT:直接用偏好对训练 | 类 SFT:用好/坏标签训练 |
| 数据要求 | 成对偏好 + 奖励模型训练数据 | 成对偏好数据 | 单条好/坏标签 |
| 算力 & 工程 | ★★★★★ | ★★★ | ★★ |
| 对齐精细程度 | ★★★★★(可多维度综合) | ★★★★(对话/任务效果很好) | ★★(粗粒度好/坏) |
| 典型适用场景 | 通用大模型、追求 SOTA 的大厂 | 垂直问答、领域助手、开源模型 | 安全防护、粗对齐、低预算项目 |
如果用一句话给不同类型团队提建议:
● 大厂 / 研究机构
有工程团队、有算力、有大量标注资源:优先采用 PPO+RM,在此基础上再探索 GRPO、GSPO 等更前沿算法。
● 中小型团队 / 垂直应用
有一定数据 & 预算,希望在一个细分领域做出体验不错的模型,DPO就是非常务实的首选:成本可控、效果明显、社区实践多、工具链成熟(如 HuggingFace TRL)。
● 个人开发者 / 极度预算敏感项目
手里只有少量"好/坏"反馈,或者主要依赖线上用户点击、评分:从 KTO 起步,把最差的回答先"挡下去",再视情况逐步升级到 DPO。
但事实上,大量开源优质数据都可以在LLaMA-Factory Online上轻松获得,你也可以在这个平台直接用高算力显卡落地你的想法,所以从DPO起步是完全可以的。
LLaMA-Factory Online已经把过去需要专业工程团队才能搭起来的流水线,做成了一个开箱可用的在线一站式平台:
● 无配置负担------浏览器打开即可训练,无需写脚本、配环境、调依赖
● 支持全流程训练:SFT、DPO、KTO、PPO、LoRA、QLoRA 全套都能跑
● 高性价比算力------H20、A100、4090 等多种 GPU 即开即用
● 兼容 HuggingFace / OpenAI 接口,训练后的模型可直接部署上线
● 支持主流大模型:Llama、Qwen、Baichuan、Gemma、Mistral......想训就训
你不再需要几十万的集群成本,也不用自己搭 RLHF 训练框架,一个浏览器 + 一点训练数据,你就能和大厂同款技术体系赛跑。对于想快速验证想法、打造垂直领域智能体、或在真实业务中使用大模型的团队来说,这就是实打实的生产力提升。