AI之PaperTool:Aella Science Dataset Explorer(LAION )的简介、安装和使用方法、案例应用之详细攻略
目录
[Aella Science Dataset Explorer的简介](#Aella Science Dataset Explorer的简介)
[架构 (Architecture):](#架构 (Architecture):)
[数据处理流程 (Data Pipeline):](#数据处理流程 (Data Pipeline):)
[语义嵌入 (Semantic Embedding):](#语义嵌入 (Semantic Embedding):)
[可视化与聚类 (Visualization & Clustering):](#可视化与聚类 (Visualization & Clustering):)
[LLM 策展标签 (LLM-Curated Labels):](#LLM 策展标签 (LLM-Curated Labels):)
[部署 (Deployment):](#部署 (Deployment):)
[项目范围 (Project Scope):](#项目范围 (Project Scope):)
[Aella Science Dataset Explorer的安装和使用方法](#Aella Science Dataset Explorer的安装和使用方法)
[先决条件 (Prerequisites):](#先决条件 (Prerequisites):)
[设置 (Setup):](#设置 (Setup):)
[(1)、获取数据库 (Get the Database):](#(1)、获取数据库 (Get the Database):)
[(2)、运行应用程序 (Run the Application):](#(2)、运行应用程序 (Run the Application):)
[Aella Science Dataset Explorer的案例应用](#Aella Science Dataset Explorer的案例应用)
Aella Science Dataset Explorer的简介
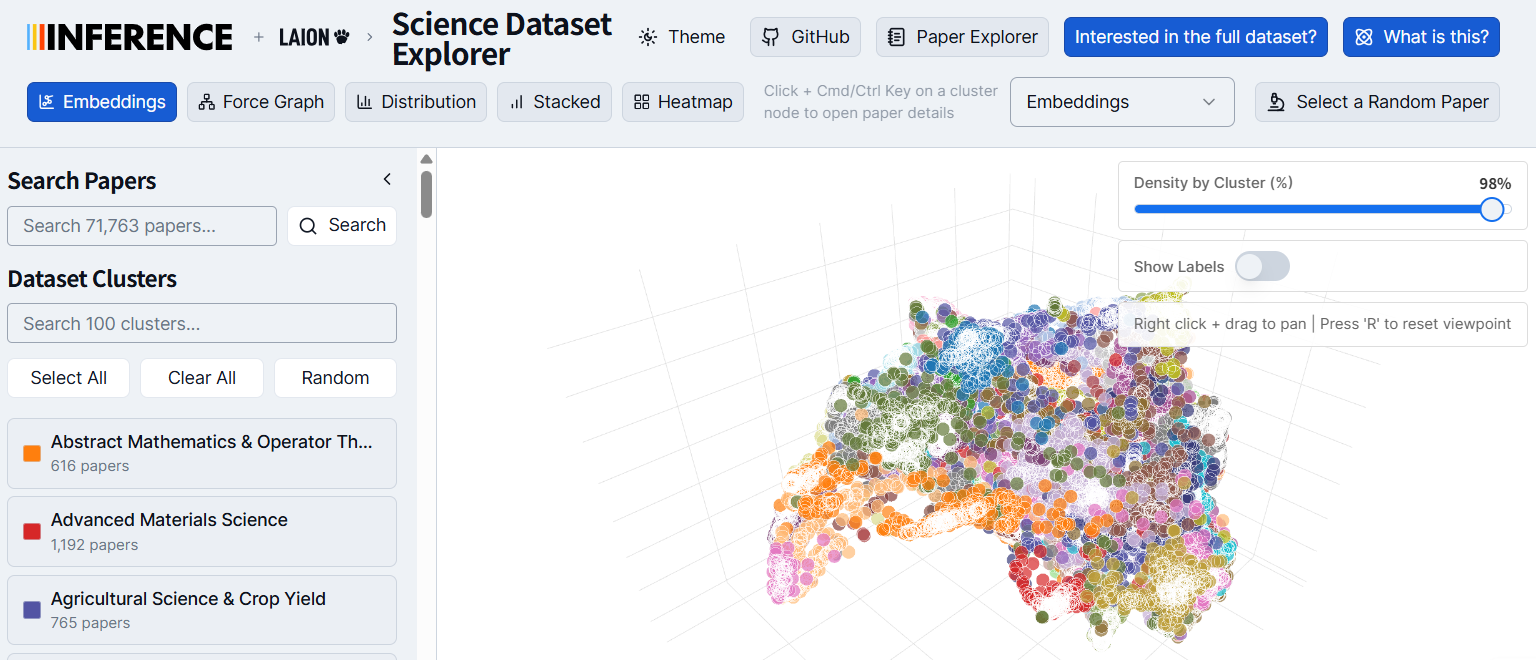
Aella Science Dataset Explorer 是一个用于 LAION 研究论文数据集的可视化探索工具。该项目旨在提供一个交互式的Web应用程序,用于探索来自 Aella 开放科学数据集的科学论文。
这个项目是 Inference.net 和 LAION 之间的合作成果。LAION 整理了原始数据集,其中包含大约 1 亿篇抓取的科学和研究文章,而 Inference.net 则微调了一个自定义模型,用于从这些文章中提取结构化摘要。此仓库包含一个针对已提取数据集的一个小规模子集的可视化探索器。
该Web应用程序通过语义嵌入、降维和聚类可视化来探索科学论文。用户可以通过 live explorer 在线查看:https://aella.inference.net。
Github地址 :https://github.com/context-labs/aella-data-explorer
1、特点
该项目在架构、数据处理和可视化方面具有以下主要特点:
架构 (Architecture):
前端 (Frontend): 使用 React + TypeScript + Vite 构建,并结合 D3.js 实现交互式可视化。
后端 (Backend): 使用 Python FastAPI 提供数据服务,本地使用 SQLite 数据库,生产环境则使用 Cloudflare D1。
存储 (Storage): 本地使用 SQLite,生产环境使用 Cloudflare D1 + R2。
数据处理流程 (Data Pipeline):
初始数据提取和过滤: 对原始数据进行初步的提取和筛选。
摘要生成: 运行一个管道来生成论文摘要。
内容排除: 排除特定的非科学内容和失败的摘要。
结果编译: 编译结果以进行进一步处理。
注意: 构建此数据集的数据管道代码尚未开源,主要是因为它是为一次性处理而设置,并非生产就绪。
语义嵌入 (Semantic Embedding):
使用 SPECTER2 (allenai/specter2_base) 模型生成 768 维的嵌入向量。
支持 GPU 加速,分批处理论文。
将嵌入向量存储为二进制大对象 (blobs),以便进行相似性搜索。
可视化与聚类 (Visualization & Clustering):
使用 UMAP 算法和余弦距离将嵌入向量降维到 2D 坐标。
应用 K-Means 聚类算法,并通过轮廓系数(silhouette scores)自动优化聚类数量(20-60 个簇)。
利用标题和字段的 TF-IDF 分析生成初始的聚类标签。
LLM 策展标签 (LLM-Curated Labels):
应用经过人工审查的、领域特定的聚类标签。
相比于自动生成的 TF-IDF 标签,这些标签提高了可解释性。
部署 (Deployment):
支持部署到 Cloudflare。
项目范围 (Project Scope):
该项目被有意地限定为数据集的一次性预览,目前不计划大幅扩展其现有功能。鼓励有重大新功能需求的用户 Fork 项目并在此基础上进行开发。
Aella Science Dataset Explorer的安装和使用方法
1、安装
要安装和运行 Aella Science Dataset Explorer,请遵循以下步骤:
先决条件 (Prerequisites):
您需要安装以下工具:
Python 3.11+: 下载
uv: Python 依赖管理工具 - 安装
bun: JavaScript 运行时 - 安装
Task: 任务运行器 - 安装
设置 (Setup):
安装所有依赖项:
task setup
这会同时安装后端和前端的依赖项。
2、使用方法
(1)、获取数据库 (Get the Database):
下载数据库:
task db:setup
这会将 SQLite 数据库下载到 backend/data/db.sqlite。
(2)、运行应用程序 (Run the Application):
在两个独立的终端中分别运行后端和前端:
后端 (Terminal 1):task backend:dev
前端 (Terminal 2):task frontend:dev
应用程序将可在以下地址访问:
API 文档: http://localhost:8787/docs
部署 (Deployment):部署到 Cloudflare:
task deploy
这将提示您部署后端 API 和/或前端。
3、在线使用
地址:https://aella.inference.net/embeddings
Aella Science Dataset Explorer的案例应用
Aella Science Dataset Explorer 的核心案例应用是作为 LAION 研究论文数据集的可视化探索工具。具体来说:
科学论文的交互式可视化和探索
它提供了一个直观的界面,使用户能够通过语义嵌入、降维和聚类可视化来浏览和理解大规模的科学论文数据集。
数据集预览和理解
作为 LAION 策展的约 1 亿篇科学文章数据集的一个小规模子集的视觉探索器,它帮助研究人员和用户快速了解数据集的结构、主题分布和潜在关联。
主题发现和趋势分析
通过聚类和 LLM 策展的标签,用户可以识别数据集中的主要研究主题、发现不同主题之间的关系,并可能洞察科学领域的发展趋势。
研究工具
对于需要对大量科学文献进行初步筛选、分类或理解其内在结构的研究人员来说,这是一个有用的辅助工具。它将复杂的语义信息转化为易于理解的视觉表示。
展示数据处理能力
该项目也展示了 Inference.net 在利用自定义模型从海量科学文章中提取结构化摘要,并通过先进的机器学习技术(如 SPECTER2 嵌入、UMAP 降维和 K-Means 聚类)进行处理和可视化的能力。