做一个能上线的 AI 应用
-
- [一、bert-base-chinese 介绍](#一、bert-base-chinese 介绍)
-
- [1.1. 模型本质](#1.1. 模型本质)
- [1.2. 模型特性](#1.2. 模型特性)
- [1.3. 实际应用场景](#1.3. 实际应用场景)
- 二、使用流程与核心原理
-
- [2.1 Tokenizer:文本→模型输入的桥梁](#2.1 Tokenizer:文本→模型输入的桥梁)
- [2.2 BertModel:语义特征提取核心](#2.2 BertModel:语义特征提取核心)
- 三、环境搭建与模型使用
-
- [3.1. 安装依赖](#3.1. 安装依赖)
- [3.2. 模型自动下载](#3.2. 模型自动下载)
- [3.3. 手动下载(国内必选)](#3.3. 手动下载(国内必选))
- 四、示例用法
-
- [4.1. Tokenizer分词功能](#4.1. Tokenizer分词功能)
- [4.2. Model模型功能](#4.2. Model模型功能)
- 五、模型微调
-
- [5.1 微调概念](#5.1 微调概念)
- [5.2 训练准备工作](#5.2 训练准备工作)
- [5.3 模型训练](#5.3 模型训练)
- [5.4 训练的模型使用](#5.4 训练的模型使用)
- 六、AI应用落地
一、bert-base-chinese 介绍
1.1. 模型本质
BERT 是谷歌 2018 年提出的双向 Transformer 预训练模型,核心是通过 "掩码语言模型" 和 "下一句预测" 任务,理解文本上下文语义。
- 核心特点
- 基于 Transformer 的编码器结构,能并行处理文本且捕捉长距离依赖。
- 双向预训练机制,同时关注词语左右两侧的上下文,突破传统单向模型局限。
- 采用 "微调" 模式,预训练后可快速适配分类、问答等多种 NLP 任务。
- 关键优势
-
语义理解更精准,解决了多义词、歧义句的语境判断问题。
-
迁移能力强,仅需少量任务数据就能实现高效适配。
-
推动了 NLP 领域 "预训练 + 微调" 范式的普及,成为后续众多模型的基础。
bert-base-chinese 是Google BERT 模型的中文优化版本,基于 Transformer 架构,在大规模中文语料上完成预训练,具备强大的中文语义理解能力。
1.2. 模型特性
| 类别 | 具体内容 |
|---|---|
| 核心能力 | 1. 上下文双向语义理解(区别于单向的 LSTM/GRU) 2. 捕捉长距离依赖关系 3. 适配中文语言特性(字级分词、成语 / 俗语理解) |
| 选择优势 | 1. 预训练优势:在大规模中文数据上学习,开箱即有中文语言知识 2. 迁移学习高效:仅需少量标注数据即可微调适配下游任务 3. 工业级性能:多项中文 NLP 任务基准测试领先 4. 生态完善:Hugging Face 提供标准化工具链支持 |
1.3. 实际应用场景
- 电商领域搜索与评论分析
用于优化商品搜索推荐:精准解析用户搜索意图,比如用户搜索 "轻薄便携办公本" 时,模型能突破关键词匹配局限,理解核心需求并推送契合商品,提升用户购买转化率。
商品评论情感分析:基于 ChnSentiCorp 数据集微调后,对评论的情感多分类准确度达 85%,助力商家快速掌握用户对商品质量、服务的评价倾向。
- 外卖行业服务质量优化
不少开发者和平台基于该模型对美团等外卖平台的 10k 量级评论数据做情感二分类。微调后的模型能精准识别用户对菜品口味、配送速度、包装质量等维度的评价好坏,平台和商家可据此针对性改进服务,比如优化配送路线或升级包装材质。
- 新闻媒体内容分类管理
在 THUCNews 等新闻数据集上微调并优化后,该模型的新闻分类准确率可达 94.6%,仅比 RoBERTa 模型低 0.2%,但推理速度快 9.4%。国内新闻平台常用它对时政、体育、财经等多类别资讯自动分类归档,既减少人工整理成本,也方便用户快速检索感兴趣内容。
- 智能客服高效应答
众多企业的智能客服系统均集成该模型。面对用户包含多个诉求的复杂咨询,如 "如何办理退换货且退款何时到账",模型能拆解核心问题并匹配对应知识库内容,快速生成准确回复,大幅降低人工客服的响应压力,提升用户咨询解决效率。
- 命名实体识别相关应用
广泛用于需提取关键信息的场景,比如政务文书处理、金融报告分析、新闻稿件梳理等。模型可精准提取文本中的人名、地名、机构名等实体信息,例如从财经新闻中提取上市公司名称,从政务文件中提取涉及的地名和机构名,助力相关岗位提升信息整理效率。
- 开发者与科研领域原型搭建
国内开发者和科研人员常借助 Hugging Face、ModelScope 等平台的工具链,基于该模型快速搭建中文 NLP 任务原型。除常见的情感分析、文本分类外,还可用于文本相似度计算、机器翻译辅助等任务的开发测试,其无需大量标注数据的特性,显著降低了中文 NLP 任务的开发与科研门槛。
二、使用流程与核心原理
2.1 Tokenizer:文本→模型输入的桥梁
- 作用:将中文文本转换为模型可理解的数字序列
- 核心逻辑 :
- 分词流程 :
tokenize负责文本拆分 →convert_tokens_to_ids映射为索引 →encode/encode_plus封装为模型输入(添加特殊符号、处理长度)。 - 文本对处理 :如输入两个句子,
encode_plus会自动用[SEP]分隔,并生成token_type_ids标记句子归属(0 表示第一句,1 表示第二句)。 - 兼容性 :
from_pretrained与 Hugging Face 预训练模型(如bert-base-chinese)无缝对接,确保分词规则与模型训练时一致。
- 分词流程 :
- 核心方法
| 方法名 | 参数类型 | 说明 |
|---|---|---|
__init__ |
vocab_file: str``do_lower_case: bool = True``max_len: int = 512 等 |
初始化分词器,加载词表(vocab.txt),配置是否小写、最大序列长度等基础参数。 |
encode |
text: str``text_pair: Optional[str] = None``add_special_tokens: bool = True``max_length: Optional[int] = None``truncation: bool = False |
将文本(或文本对)转换为 input_ids(token 索引列表)。支持添加特殊符号([CLS]、[SEP])、截断 / 填充到指定长度。 |
encode_plus |
text: str``text_pair: Optional[str] = None``return_tensors: Optional[str] = None``padding: Union[bool, str] = False``truncation: Union[bool, str] = False 等 |
增强版 encode,返回更完整的模型输入(input_ids、attention_mask、token_type_ids 等)。支持返回张量(如 pt 为 PyTorch 张量)、自动填充和截断。 |
tokenize |
text: str |
对文本进行分词(中文按字符拆分,英文按子词拆分),返回 token 列表(如 ["我", "爱", "自", "然", "语", "言", "处", "理"])。 |
from_pretrained(类方法) |
pretrained_model_name_or_path: Union[str, os.PathLike]``**kwargs |
从预训练模型路径或名称加载分词器(自动加载对应的词表和配置),无需手动指定 vocab_file。 |
名词解释
- 张量(Tensor) :是最核心的数据结构,简单说就是 "多维数组",可以理解为标量、向量、矩阵的高维扩展。
- input_ids : 把文本分词并一一编码索引,根据索引可以找到对应的词。
- attention_mask : 模型要求输入长度和格式,会填充一些特殊字符如
[CLS](句首)、[SEP](句尾 / 句分隔)、[PAD](填充)、[UNK](未知词)等,过滤 "凑数内容",让模型只关注有用信息。 - token_type_ids : 对于多个短话的句子,给句子 "分段落"。
- **词表vocab.txt **: BERT 等预训练模型的 "词典",里面存着模型认识的所有基础 "文字单位"(token),每个单位对应一个唯一编号,就像我们用的字典里的 "词条",是模型把文本转换成数字的关键依据。
2.2 BertModel:语义特征提取核心
- 核心作用:基础 BERT 模型,输出隐藏层特征(无具体任务头),是所有文本分类任务、命名实体识别、问答任务的基础。
- 用途:作为特征提取器(如文本相似度计算、聚类),或作为文本分类任务、命名实体识别、问答任务的模型的基础(需叠加任务头)
- 核心方法
| 方法名 | 参数类型 | 说明 |
|---|---|---|
__init__ |
config: BertConfig |
初始化 BERT 核心结构,根据配置构建词嵌入层、Transformer 编码器、池化层等组件。 |
forward |
input_ids: Optional[Tensor]``attention_mask: Optional[Tensor]``token_type_ids: Optional[Tensor]``output_hidden_states: Optional[bool] = False``output_attentions: Optional[bool] = False |
前向传播核心方法,输入文本编码后输出隐藏层特征(last_hidden_state、pooler_output 等),支持返回所有层隐藏状态和注意力权重。 |
from_pretrained(类方法) |
pretrained_model_name_or_path: Union[str, os.PathLike]``config: Optional[BertConfig] = None``**kwargs |
从预训练权重(名称或本地路径)加载模型,自动匹配配置,直接复用预训练语义知识,是迁移学习核心方法。 |
save_pretrained |
save_directory: Union[str, os.PathLike]``**kwargs |
将模型权重(pytorch_model.bin)和配置(config.json)保存到本地,用于持久化微调后模型。 |
get_input_embeddings |
无 | 获取模型的词嵌入层实例(nn.Embedding),支持后续词表扩展或嵌入层定制。 |
set_input_embeddings |
value: nn.Embedding |
设置自定义词嵌入层,需保证嵌入维度与模型 hidden_size 匹配,用于领域词表扩展。 |
prepare_inputs_for_generation |
input_ids: Tensor``attention_mask: Optional[Tensor] = None``**kwargs |
为生成式任务准备输入(如补全 attention_mask),适配 BERT 作为编码器的 seq2seq 场景。 |
三、环境搭建与模型使用
3.1. 安装依赖
sh
# 安装PyTorch(根据CUDA版本选择)
pip install torch torchvision torchaudio
# 安装Hugging Face Transformers
pip install transformers
# 可选:数据处理与可视化库
pip install pandas numpy matplotlib3.2. 模型自动下载
首次调用代码from_pretrained会自动从Hugging Face 下载并缓存模型,无需手动操作,但是国内环境因为网络与原因不支持,我配置了镜像也无法成功,故此处选用手动下载。(可用梯子)
python
from transformers import BertTokenizer, BertModel
# 加载分词器和模型
tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
model = BertModel.from_pretrained("bert-base-chinese")3.3. 手动下载(国内必选)
hugging Face 国内镜像网站 搜索bert-base-chinese 找到对应的模型,进入详情页下载模型文件
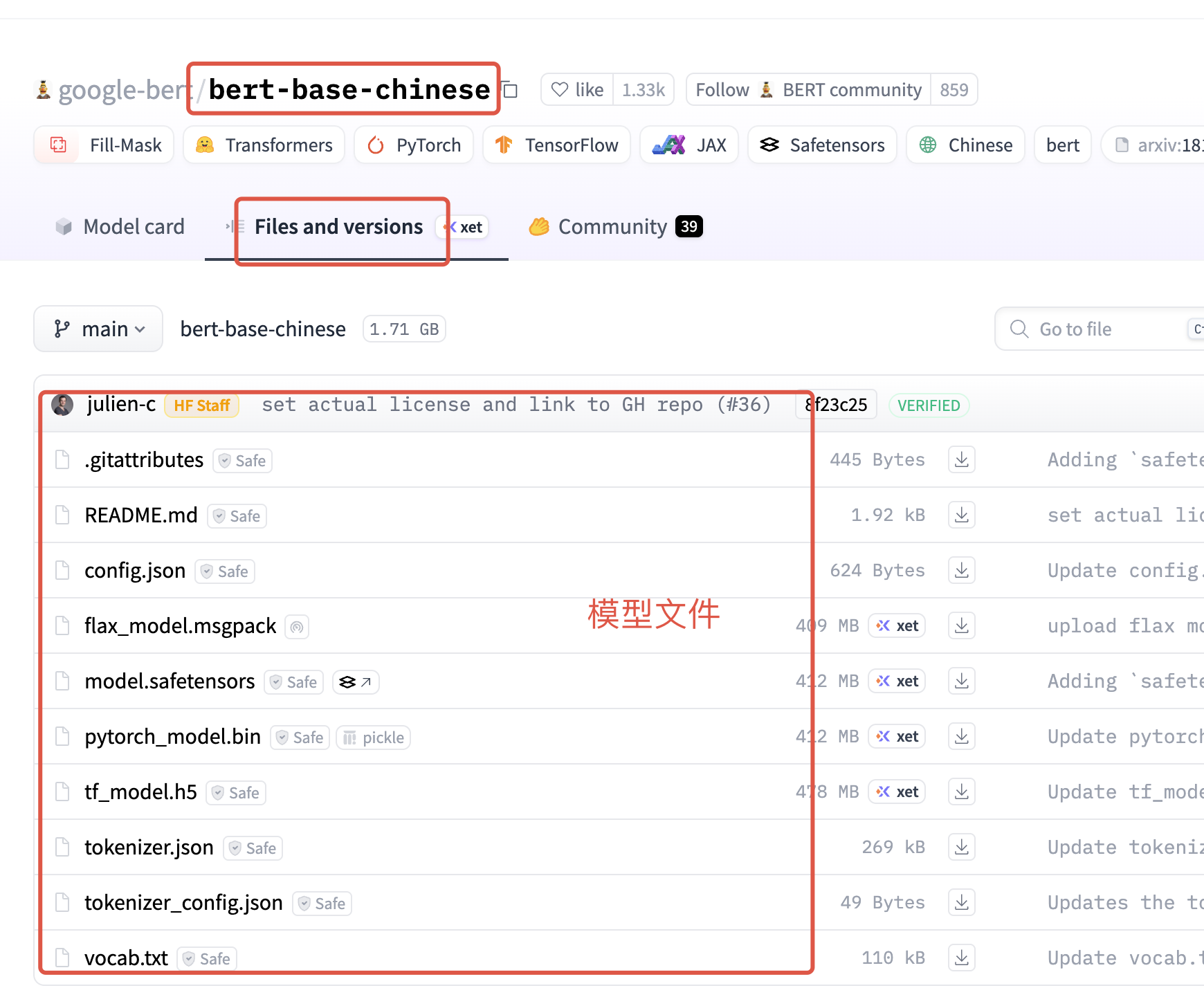
| 文件名 | 作用说明 |
|---|---|
config.json |
模型配置文件,存储 BERT 的超参数(如隐藏层维度、层数、注意力头数等) |
flax_model.msgpack |
Flax 框架下的模型权重文件,用于在 JAX/Flax 生态中加载和使用 BERT 模型 |
pytorch_model.bin |
PyTorch 框架下的模型权重文件,存储 BERT 各层的参数 |
tf_model.h5 |
TensorFlow 框架下的模型权重文件,存储 BERT 的参数 |
model.safetensors |
安全的模型权重文件格式,兼容多种框架,存储模型的参数(权重、偏置等) |
tokenizer.json |
分词器配置文件,存储分词规则、词表映射等信息,用于文本到 input_ids 的转换 |
tokenizer_config.json |
分词器的额外配置文件,定义分词器类型、特殊符号等 |
vocab.txt |
词表文件,存储模型可识别的所有 token 及其索引(行号即索引) |
说明
- config.json:模型的 "身体结构"(比如有多少层神经网络、每层有多少个计算单元)相当于机器人的 "设计图纸"。
- 权重文件: 模型 "通过预训练学来的经验和本事" 的存储文件。, 权重文件里存的全是模型训练好的 "参数"。这些参数数字对应神经网络里每个 "计算节点" 的 "重要性" 或 "关联强度"。
- PyTorch框架下使用就需要关注pytorch_model.bin,基于Flax框架使用模型则关注flax_model.msgpack权重文件、同理基于TensorFlow 框架使用模型则需要关注tf_model.h5。
四、示例用法
4.1. Tokenizer分词功能
加载(from_pretrained)
python
from transformers.models.bert.tokenization_bert import BertTokenizer
from transformers import BertTokenizerFast
#先加载模型
# 先从网络下载模型 没有则使用本地模型
online_model = "bert-base-chinese"
local_model = "xxx/xxx/local_models/bert-base-chinese"
# BertTokenizer
tokenizer = BertTokenizer.from_pretrained(local_model)
from transformers import BertTokenizerFast
tokenizer = BertTokenizerFast.from_pretrained("bert-base-chinese") # 用法和 BertTokenizer 完全一样| 特性 | BertTokenizer(原生 Python) |
BertTokenizerFast(Rust 加速) |
|---|---|---|
| 底层实现 | Python 纯代码 | Rust 编译(调用 tokenizers 库) |
| 速度 | 较慢(批量处理大文本时明显) | 极快(适合大规模数据处理) |
| 功能 | 基础编码 / 解码、分词 | 支持批量溢出处理、偏移量映射等高级功能 |
| API 兼容性 | 完全兼容模型输入 | 与前者完全一致,可直接替换 |
| 使用场景 | 小规模测试、简单任务 | 大规模训练、批量数据处理 |
分词(tokenize)
将文本拆分为模型可识别的最小单元(中文按字,英文按子词)
python
def test_tokeninzer() -> None:
# ===================== 核心逻辑1:分词(tokenize)=====================
text = "我爱自然语言处理,也喜欢ai技术,同时喜欢spring Boot!!!"
# bert-base-chinese 会将大写字母标记为[UNK] 所以为避免分词丢失数据,将文本中英文字符转换为小写
text = text.lower()
tokens = tokenizer.tokenize(text)
print(f"原始文本:{text}")
# 中文按字拆分,特殊符号保留
print(f"分词结果:{tokens}") 编码(encode)
将 token 转为数字索引 (input_ids),并添加特殊符号(CLS/SEP)、生成 token_type_ids(文本对)和 attention_mask(填充标记),此处会将文本分转换成模型可以理解的张量数据了,便于后续文字分类、命名等下游任务。
python
def test_encode() -> None:
# ===================== 核心逻辑2:编码(encode/encode_plus)=====================
print("\n" + "=" * 50)
print("2. 编码(encode/encode_plus):token转数字+补全必要字段")
text = "我爱自然语言处理,也喜欢ai技术,同时喜欢spring Boot!!!"
text = text.lower()
# 流程:先分词 - 在进行编码
# 底层也是调用 encode_plus 只是返回数据只截取input_ids
encoded_single = tokenizer.encode(
text=text,
add_special_tokens=True, # 强制添加[CLS](句首)和[SEP](句尾)
truncation=False, # 不截断(超长会报错,后续批量处理会演示截断)
)
# print(f"单句encode结果(input_ids):{encoded_single}")
# 2.2 文本对编码(encode_plus:输出完整字段,含token_type_ids/attention_mask)
text1 = "什么是自然语言处理?" # 第一句(如问题)
text2 = "自然语言处理是AI的重要分支。" # 第二句(如答案)
# 3. 调用 encode_plus 并补全参数
encoded_inputs = tokenizer.encode_plus(
text=text1,
text_pair=text2,
add_special_tokens=True, # 自动添加 [CLS](句首)、[SEP](句间/句尾)
padding="max_length", # 补全策略:"max_length"(固定长度)/"longest"(批次最长)/"do_not_pad"
truncation="longest_first", # 截断策略:"longest_first"/"only_first"/"only_second"/False
max_length=12, # 序列最大长度(必须 >= 2,因为含 [CLS] 和至少一个 [SEP])
stride=16, # 滑动窗口步长:当文本超长时,子文本重叠部分长度 = max_length - stride
return_tensors="pt", # 返回 tensor 类型:"pt"(PyTorch)/"tf"(TensorFlow)/"np"(NumPy)
)
print(f"\n2.2 文本对encode_plus结果:")
print(f"input_ids:{encoded_pair['input_ids'].squeeze().numpy()}") # 展平张量为数组
print(f"token_type_ids:{encoded_pair['token_type_ids'].squeeze().numpy()}") # 0=第一句,1=第二句
print(f"attention_mask:{encoded_pair['attention_mask'].squeeze().numpy()}") # 全1(无填充)分析流程,编码过程是 先将中文句子分成一个个字(集合)会按照格式插入补全PAD、CLS 、 SEP等、,接着对照模型中的vocab.txt 找到的索引映射为inputs_ids数组集合。多文本会针对input_ids每个词 区分是第几句的token_type_ids 集合。同时对于插入的inputs_ids 集合中设置对应的遮盖掩码,对于真实字或者句首CLS、SEP、或者凑字符补全字符PAD 设置对应的注意力掩码(1=有效token,0=填充)
比如句子:
sh
text1 = "我爱你" # 第一句(如问题)
text2 = "我也爱你" # 第二句(如答案)
# 分词后,我要求是12个字符,不够需要补全,所以补充了2个PAD
# 句子按照中文字符分词后的索引列表
#对照vocab.txt 101为插入的CLS句首标识 102是SEP分隔符(句子之间的分隔)0 是PAD字符 同理中间文字是中文对应的索引。
映射索引:input_ids:[ 101 2769 4263 872 102 2769 738 4263 872 102 0 0]
#句子属于哪个文本对,0 第一句 1第二句 后面0是补全
token_type_ids:[0 0 0 0 0 1 1 1 1 1 0 0]
#注意力掩码 PAD是一个无效的需要模型在后续处理无序关注 所以只有最后补全的PAD 设置为0 无效,其他均为有效文字
attention_mask:[1 1 1 1 1 1 1 1 1 1 0 0]
i从0开始文本中行号是102对应索引为101
解码(decode)
将inputs_ids 还原成原始文本。根据索引逆向通过词表库vocab.txt找到对应文本
py
# 对编码的inputs_ids 进行解码
print("\n" + "="*50)
print("3. 解码(decode):数字索引转回可读文本")
# 对单句编码结果解码
decoded_single = tokenizer.decode(encoded_single)
print(f"单句解码结果:{decoded_single}") # 自动还原[CLS]/[SEP]和原始文本
# 对文本对的input_ids解码
decoded_pair = tokenizer.decode(encoded_pair['input_ids'].squeeze().numpy())
print(f"文本对解码结果:{decoded_pair}") # 还原两句话和分隔符批量(batch)
上述编码逻辑处理了 单文本和文本对(双文本)的编码处理,此处提供多文本的编码处理,批量编码逻辑同编码逻辑一致,不在赘述。
python
def test_batch_decode() -> None:
# ===================== 核心逻辑2:批量处理 编解码(padding+truncation)=====================
print("\n" + "=" * 50)
print("4. 批量处理:统一文本长度(填充/截断)")
# 准备不同长度的文本列表
batch_texts = [
"我爱NLP", # 短文本
"自然语言处理是人工智能领域的核心技术,应用场景非常广泛!", # 长文本
"BERT模型真好用", # 中等长度
]
#文本处理成小写
batch_texts = [text.lower() for text in batch_texts]
encoded_batch = tokenizer(
batch_texts,
padding=True, # 填充:短文本补[PAD](对应attention_mask=0)
truncation=True, # 截断:超长文本截取前max_length个token
max_length=15, # 统一长度为15(可根据模型调整,如BERT-base最大512)
return_tensors="pt", # 返回PyTorch张量
)
print(f"批量处理后形状:{encoded_batch['input_ids'].shape}") # 输出:torch.Size([3, 15])(3个样本,每个15长度)
print(f"\n批量input_ids:")
print(encoded_batch['input_ids'].numpy())
print(f"\n批量attention_mask(0=填充位):")
print(encoded_batch['attention_mask'].numpy())
#解码
input_ids = encoded_batch['input_ids']
decoded_texts = []
for ids in input_ids:
# 逐个解码:自动忽略 [PAD] 填充位,还原 [CLS]/[SEP] 和原始文本
text = tokenizer.decode(
ids,
skip_special_tokens=False, # 是否跳过特殊符号(False=保留,True=去除)
clean_up_tokenization_spaces=True # 清理多余空格
)
decoded_texts.append(text)
print(f"多文本解码结果(原始文本):{decoded_texts}")4.2. Model模型功能
训练好的模型 加载模型与分词器 新文本数据 文本编码为模型输入 模型推理计算 输出预测结果 业务应用落地
推理应用流程核心是 "加载模型→数据适配→推理输出→业务落地" 的线性链路
- 先加载已训练好的模型及配套分词器,完成推理前准备;
- 接收新的文本数据,通过分词器编码为模型可识别的输入格式;
- 模型对编码后的输入进行推理计算,提取特征并输出预测结果;
- 将预测结果应用到实际业务场景(如文本分类、问答等),完成落地。
常用模型
| 模型名称 | 核心区别(功能定位) | 应用场景(通俗说明) |
|---|---|---|
| BertModel | 基础 BERT 模型,仅输出语义向量(无任务头) | 文本特征提取(如句子向量、token 向量)、相似度计算、聚类 |
| BertForSequenceClassification | 官方标准文本分类模型(适配分类任务的输出头) | 同上(更通用,支持自定义分类数,适配 HF 生态) |
| BertForMaskedLM | 掩码语言模型(MLM 头,预测 MASK 位置 token) | 文本填空、语法纠错、文本生成辅助(完形填空) |
| BertForQuestionAnswering | 问答专用模型(输出答案起始 / 结束位置头) | 抽取式问答(给定问题 + 上下文,提取精准答案) |
BertModel使用
BertModel 的核心是 "输出语义相关的特征向量"(句子级 / Token 级)流程如下:
-
分词:数据基础。分词器先将文本转换为模型model能够识别的参数信息比如inputs_ids token_type_ids attention_mask等
-
生成向量:模型再将输入的参数信息转换为语义向量 为后续相似度计算、分类,聚类任务做准备
语义向量就是把文本的 "意思" 转换成一串数字,就像给文本的 "语义" 发了一个唯一的 "数字身份证"------BERT 提取的向量能精准捕捉文本的语义信息,后续可用于相似度计算、分类、聚类等任务。
python
from transformers import BertModel,BertTokenizerFast,BertTokenizer
import torch
local_model = "/本地模型目录/local_models/bert-base-chinese"
def test_bert_model() -> None:
# 获取分词器
tokenizer = BertTokenizerFast.from_pretrained(local_model)
# 获取bert模型
model = BertModel.from_pretrained(local_model)
# 分词器先将文本转换为模型model能够识别的参数信息比如inputs_ids token_type_ids attention_mask等
# 模型再将输入的参数信息转换为语义向量 为后续训练做怎办
texts= ["我如果爱你 ------绝不像攀援的凌霄花,借你的高枝炫耀自己",
"我如果爱你 ------绝不学痴情的鸟儿,为绿荫重复单调的歌曲",
"我必须是你近旁的一株木棉,作为树的形象和你站在一起。",
"你有你的铜枝铁干,像刀,像剑,也像戟",
"我有我红硕的花朵,像沉重的叹息,又像英勇的火炬。"]
#编码
encode_data = tokenizer(
texts,
padding=True,
truncation=True, max_length=30,
add_special_tokens=True,
return_tensors="pt")
model.eval()
with torch.no_grad():
outputs = model(**encode_data)
# print("模型处理:", outputs)
# 句子级向量
cls_vector = outputs.last_hidden_state[:, 0, :]
# Token级向量
token_vector = outputs.last_hidden_state[0]
# 输出:torch.Size([5, 768]) → (批量数, 向量维度)
print("句子级语义向量形状:", cls_vector.shape)
# 输出:torch.Size([28, 768]) → (Token数, 向量维度)
print("Token级语义向量形状:", token_vector.shape)| 维度 | 语义向量(统称) | Token向量(子集) |
|---|---|---|
| 定义 | 所有 "承载语义的数字向量" 的总称 | 仅对应句子中单个 Token(中文单字 / 英文子词)的语义向量 |
| 粒度范围 | 可大可小(句子级、Token 级、段落级等) | 固定为 "单个 Token" 的局部粒度 |
| 典型来源 | - 句子级:BERT 的 CLS 向量、Sentence-BERT 输出- Token 级:BERT 的 last_hidden_state 每行 | 仅 BERT 等模型的 last_hidden_state 每行向量(每个 Token 对应 1 个) |
| 输出形状 | 句子级:1, 768(单句)、N, 768(批量)Token 级:seq_len, 768 | 固定为 seq_len, 768(seq_len=Token 数量) |
| 核心作用 | 句子级:相似度计算、文本分类、聚类Token 级:NER、词性标注、关键词提取 | 仅用于 Token 级细粒度任务(捕捉单个 Token 的语义 + 上下文关联) |
文本分类模型使用
简介
BertForSequenceClassification 是 Hugging Face transformers 库中用于文本分类任务的核心模型类,基于 BERT 架构扩展而来,专为 "给文本分配类别标签" 场景设计。
核心特点
- 结构 :在 BERT 基础模型后添加分类头 (全连接层),将 BERT 输出的 CLS 语义向量映射到
num_labels个类别得分(logits)。 - 功能 :支持二分类、多分类等任务,只需指定
num_labels(类别数)即可快速适配。 - 易用性 :开箱即用,可直接加载预训练权重(如
bert-base-chinese),结合分词器即可完成文本分类推理或微调。
适用场景
- 情感分析(正面 / 负面)、垃圾邮件识别、新闻主题分类等有监督文本分类任务。
- 可直接用于推理,也可通过自定义数据集微调以适配特定业务场景。
用法
python
from transformers import BertModel,BertTokenizerFast,BertTokenizer
import torch
def test_bert_for_sentence_model() -> None:
"""
官方标准文本分类模型
:return:
"""
# 1. 加载分词器和分类模型(二分类:num_labels=2)
tokenizer = BertTokenizer.from_pretrained(local_model)
model = BertForSequenceClassification.from_pretrained(
local_model,
num_labels=2 # 2=二分类(正面/负面),可根据任务调整(如多分类设3/4等)
)
# 推理模式(禁用Dropout)
model.eval()
# 2. 准备测试文本(情感分析示例:正面/负面)
test_texts = [
"这部电影剧情精彩,演员演技超棒!", # 正面
"服务态度差,体验非常糟糕", # 负面
"自然语言处理技术真有意思" # 正面
]
# 3. 批量编码文本(统一长度)
encoded_inputs = tokenizer(
test_texts,
padding=True,
truncation=True,
max_length=32,
return_tensors="pt"
)
# 4. 模型推理(禁用梯度计算,提速省内存)
with torch.no_grad():
outputs = model(**encoded_inputs)
logits = outputs.logits # 模型输出分数(未归一化)
# 归一化
probs = torch.softmax(logits, dim=1)
# 取概率最大的类别(0/1) 也可以直接计算
predictions = torch.argmax(logits, dim=1).numpy()
# 5. 解析结果(0=负面,1=正面)
label_map = {0: "负面", 1: "正面"}
for text, pred in zip(test_texts, predictions):
print(f"文本:{text} → 预测结果:{label_map[pred]}")原理
BertTextClassifier 和BertForSequenceClassification 都是文本分类任务模型,其支持按照分类数量(2分类 正面、负面,多分类),计算中文语句在各个分类上的概率。比如文本列表如下(batch_size = 3):
python
test_texts = [
"这部电影剧情精彩,演员演技超棒!", # 正面
"服务态度差,体验非常糟糕", # 负面
"自然语言处理技术真有意思" # 正面
]基于N分类,通过模型推理后产生了batchSize, N, 如果是二分类 则产生 一个3,2 3行2列的矩阵
| 0(负面得分) | 1(正面得分) |
|---|---|
| -0.00483 | -0.42220 |
| 0.14522 | -0.42633 |
| 0.21539 | -0.38200 |
torch.argmax(probs, dim=1).numpy():在 "类别维度" 取最大值 ------ 对每个样本(batch_size 维度的每一行),找概率最大的类别索引。
| 文本列表索引 | 二分类(0 负面 1 正面) |
|---|---|
| 0 | 1 |
| 1 | 0 |
| 2 | 1 |
torch.softmax(logits, dim=1) :在 "类别维度"(第 1 维,索引从 0 开始)做归一化 ------ 即对每个样本的 num_labels 个得分,单独转成 0~1 概率,且每个样本的概率总和为 1。
| 文本列表索引 | 负面概率 | 正面概率 |
|---|---|---|
| 0 | 0.47948 | 0.52052 |
| 1 | 0.53096 | 0.46904 |
| 2 | 0.42337 | 0.57663 |
遮码语言模型
BertForMaskedLM 是 Hugging Face 中专门用于 "掩码语言建模"(Masked Language Modeling, MLM) 的模型类 ------ 简单说,它是 BERT 预训练阶段的 "核心工具",本职是 "根据上下文猜被挡住的词",也是 BERT 能理解语言的关键。
流程
- 输入文本时,随机把部分词(比如 15%)换成特殊符号
[MASK](相当于 "挡住" 这个词); - 模型根据上下文(前后词),预测
[MASK]位置原本应该是什么词; - 训练目标是让 "猜词" 的准确率越来越高,过程中模型学会语言规律(比如 "我___电影",结合上下文可能猜 "看""喜欢")。
python
from transformers import BertTokenizer,BertForMaskedLM
import torch
def test_bert_for_mask_model() -> None:
# 1. 加载模型和分词器(用中文预训练权重)
tokenizer = BertTokenizer.from_pretrained(local_wwm_model)
model = BertForMaskedLM.from_pretrained(local_wwm_model,ignore_mismatched_sizes=True)
model.eval()
# 2. 输入带[MASK]的文本(完形填空) 批量
batch_texts = [
"周末和朋友去[MASK],那里的[MASK]真的超棒!", # 样本1:2个掩码
"这家餐厅的[MASK]很正宗,价格也[MASK]!", # 样本2:2个掩码
"他在[MASK]上认真学习,准备[MASK]考试。" # 样本3:2个掩码
]
# 3. 编码文本(需记录[MASK]的位置)
# 3. 批量编码文本(padding=True 自动补齐长度,return_tensors="pt" 返回张量)
encoded = tokenizer(
batch_texts,
padding=True, # 批量文本长度不一致时,自动补齐到最长句子长度
truncation=True, # 超长句子截断
max_length=128,
return_tensors="pt"
)
# 获取文本的数字索引
input_ids = encoded["input_ids"]
# 4. 找到批量文本中所有[MASK]的位置(关键:行索引=样本序号,列索引=样本内掩码位置)
mask_bool = (input_ids == tokenizer.mask_token_id) # 布尔张量:[3,15],True=掩码
# 获取到所有mask掩码索引
batch_indices, seq_indices = mask_bool.nonzero(as_tuple=True) # 分别取行、列索引
# 示例结果:batch_indices = tensor([0,0,1,1,2,2])(0代表样本1,1代表样本2...),seq_indices = tensor([6,12,5,10,4,9])
# 5. 批量预测(一次处理所有样本)
with torch.no_grad():
outputs = model(**encoded)
logits = outputs.logits # 形状:[batch_size, 文本长度, 词典大小],比如 [3,15,21128]
# 6. 按样本分组,输出每个样本的每个[MASK]候选词
for sample_idx in range(len(batch_texts)): # 遍历每个样本
print(f"\n===== 第{sample_idx + 1}个文本:{batch_texts[sample_idx]} =====")
# 找到当前样本的所有掩码位置(筛选出batch_indices中等于当前样本序号的索引)
current_mask_pos = seq_indices[batch_indices == sample_idx]
# 遍历当前样本的每个掩码
for mask_idx, pos in enumerate(current_mask_pos, 1):
top5_indices = torch.topk(logits[sample_idx, pos], 5).indices # 取Top5候选词
top5_words = tokenizer.decode(top5_indices, skip_special_tokens=True).split()
print(f" 第{mask_idx}个[MASK]的候选词:{top5_words}")遗留问题:还是解决不了使用模型预测词为单个中文字符而非词语。
问答模型使用
BertForQuestionAnswering是 Hugging Face Transformers 库中基于 BERT 架构的抽取式问答模型,核心作用是:
给定一对「问题(Question)+ 上下文(Context)」,模型从上下文文本中精准抽取连续片段作为答案(而非生成全新文本)。
核心特点:
- 仅依赖上下文,不编造信息,答案可信度高;
- 需确保答案明确包含在上下文中(抽取式),无法回答上下文未覆盖的问题;
- 支持中文 / 英文等多语言,适配各类领域的问答需求。
核心使用场景:
- 知识库问答:如企业文档、产品手册、帮助中心的智能问答(例:"产品的退款期限是多久?"→ 从退款政策文档中抽取答案);
- 阅读理解评测:如考试中的阅读理解选择题 / 简答题自动化批改(例:基于文章片段回答 "作者为什么推荐这个方案?");
- 智能客服:处理用户高频咨询(例:"快递多久能送达?"→ 从物流规则上下文抽取答案);
- 信息检索辅助:从长文本中快速定位关键信息(例:从论文摘要中抽取 "该研究的核心结论是什么?");
- 聊天机器人:结合上下文对话历史,回答用户针对性问题(例:用户先问 "推荐一款性价比高的手机",再问 "它的电池容量是多少?"→ 从推荐手机的参数上下文抽取答案)。
python
def run_bert_for_qa_model() -> None:
# 1. 加载中文问答模型和分词器(专为中文问答优化)
tokenizer = BertTokenizer.from_pretrained(local_wwm_lager_model)
model = BertForQuestionAnswering.from_pretrained(local_wwm_lager_model)
model.eval() # 推理模式,关闭训练相关层
context = """
2024年杭州亚运会于2023年9月23日至10月8日在杭州举办,共有45个国家和地区的运动员参赛,
比赛项目包括40个大项、61个小项,产生了481枚金牌。中国代表团以201枚金牌、111枚银牌、71枚铜牌的成绩
位居奖牌榜首位,创造了亚运会参赛以来的最佳战绩。
"""
question = "中国代表团在2024年杭州亚运会上获得了多少枚金牌?"
# 2. 编码「问题+上下文」(BERT要求问题在前,上下文在后,用[SEP]分隔)
inputs = tokenizer(
question, # 问题
context, # 上下文(答案必须包含在其中)
truncation=True, # 超长截断
max_length=50, # BERT-base/large的最大输入长度
return_tensors="pt" # 返回PyTorch张量
)
# 3. 模型预测(输出答案的起始位置和结束位置概率)
with torch.no_grad(): # 禁用梯度计算,加速推理
outputs = model(**inputs)
start_logits = outputs.start_logits # 每个token作为答案起始的概率
end_logits = outputs.end_logits # 每个token作为答案结束的概率
# 4. 解析预测结果(取概率最高的起始和结束位置)
start_idx = torch.argmax(start_logits, dim=1).item() # 起始位置索引
end_idx = torch.argmax(end_logits, dim=1).item() # 结束位置索引
# 5. 解码答案(将token索引转换为中文文本)
# 处理特殊情况:起始位置 > 结束位置 → 无答案
if start_idx > end_idx:
return "未找到答案(上下文未包含该问题的相关信息)"
# 解码时排除[CLS](开头符)、[SEP](分隔符)等特殊token
answer_tokens = inputs["input_ids"][0][start_idx:end_idx + 1] # 截取答案token
answer = tokenizer.decode(answer_tokens, skip_special_tokens=True)
print(f"问题:{question}\n答案:{answer}")基于上下文 问答 模型回答并不是很好,即使使用 hfl/chinese-roberta-wwm-ext-large模型
五、模型微调
5.1 微调概念
模型微调(Fine-tuning)的核心目的是:**让通用预训练模型(如 bert-base-chinese)适配你的具体任务,**微调就是给这个 "学霸" 做 "专项刷题":用你场景的标注数据(比如带标签的评论 / 新闻),让模型在保留通用语义能力的基础上,学会你的任务逻辑,最终能精准解决你的问题。
训练流程图核心是 "数据准备→模型构建→迭代训练→达标保存" 的闭环
- 原始标注数据经预处理、划分训练 / 验证集、编码后,转化为模型可识别的输入格式;
- 加载 bert-base-chinese 预训练模型,添加适配具体任务的顶层适配层;
- 模型进入训练循环,结合编码后的训练数据持续优化参数;
- 每轮训练后用验证集评估性能,未达标则继续迭代训练;
- 性能达标后,保存最终训练好的模型,供后续推理使用。
训练流程图
否 是 原始标注数据 数据预处理 划分训练/验证集 文本编码为模型输入 加载bert-base-chinese预训练模型 添加任务适配层 模型训练循环 验证集评估性能 性能达标? 保存训练好的模型
该训练是基于bert-base-chinese模型的3 分类文本分类(示例:正面 / 负面 / 中性情感分类)做的训练,训练数据标准是不少于1000条,建议按照500一个分类测试数据,数据过少训练不准确。
5.2 训练准备工作
数据准备
按照如下格式创建csv格式的训练数据。
| text | label |
|---|---|
| 这款手机续航超强,拍照效果很好! | 正面 |
| 电影剧情平淡,没有亮点也没有槽点 | 中性 |
| 快递延迟 3 天,客服态度敷衍 | 负面 |
数据加载
python
import pandas as pd
# ---------------------- 数据加载 ----------------------
def load_data(data_path):
df = pd.read_csv(data_path)
# 标签转换(字符串→数字)
if df["label"].dtype == "object":
df["label"] = df["label"].map(LABEL_MAP)
# 数据清洗
df = df.dropna(subset=["text", "label"]).drop_duplicates(subset=["text"])
return df["text"].tolist(), df["label"].tolist()获取数据集合
将加载的csv数据 通过模型的分词器将训练数据转换为模型可以读懂的数据。适配 PyTorch 的训练流程,让文本数据能被模型高效读取和处理 。PyTorch 的 DataLoader 就能自动识别和处理你的数据。
python
import torch
from torch.utils.data import Dataset
# ---------------------- 数据集类 ----------------------
class TextDataset(Dataset):
def __init__(self, texts, labels, tokenizer):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
encoding = self.tokenizer(
self.texts[idx],
truncation=True,
padding="max_length",
max_length=MAX_LENGTH,
return_tensors="pt"
)
return {
"input_ids": encoding["input_ids"].flatten(),
"attention_mask": encoding["attention_mask"].flatten(),
"label": torch.tensor(self.labels[idx], dtype=torch.long)
}评估函数
计算模型预测正确的样本占总样本的比例,是最直观的 "整体效果指标"。
python
from sklearn.metrics import accuracy_score, classification_report
# ---------------------- 评估函数 ----------------------
def compute_metrics(eval_pred):
logits, labels = eval_pred
preds = torch.argmax(torch.tensor(logits), dim=1).numpy()
return {
"accuracy": accuracy_score(labels, preds),
"weighted_f1": classification_report(labels, preds, output_dict=True)["weighted avg"]["f1-score"]
}5.3 模型训练
| 配置参数 | 作用说明 |
|---|---|
MODEL_NAME |
指定预训练模型名称,此处为 bert-base-chinese(中文基础版 BERT) |
NUM_LABELS |
计算分类任务的类别数(等于 LABEL_MAP 的长度) |
MAX_LENGTH |
文本最大编码长度(此处为 128),超过该长度的文本会被截断,不足则补全 |
BATCH_SIZE |
每次训练 / 验证时的样本批次大小(此处为 32) |
EPOCHS |
训练轮数(此处为 3),即模型完整遍历训练集的次数 |
LEARNING_RATE |
训练学习率(此处为 2e-5),即模型参数更新的步长 |
python
import torch
import logging
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
from torch.utils.data import Dataset, DataLoader
from transformers import (
BertTokenizer,
BertForSequenceClassification,
TrainingArguments,
Trainer
)
# ---------------------- 基础配置(按需修改) ----------------------
MODEL_NAME = "bert-base-chinese"
LABEL_MAP = {"负面": 0, "中性": 1, "正面": 2} # 3分类标签映射
NUM_LABELS = len(LABEL_MAP)
MAX_LENGTH = 128
BATCH_SIZE = 32
EPOCHS = 3
LEARNING_RATE = 2e-5
VAL_SPLIT = 0.2
SAVE_PATH = "./bert_3class_model"
DATA_PATH = "./3class_text_data.csv" # 数据文件路径
# 日志配置
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s")
logger = logging.getLogger(__name__)
# ---------------------- 核心训练流程 ----------------------
def train():
# 1. 加载并划分数据
texts, labels = load_data(DATA_PATH)
train_texts, val_texts, train_labels, val_labels = train_test_split(
texts, labels, test_size=VAL_SPLIT, random_state=42, stratify=labels
)
logger.info(f"训练集:{len(train_texts)}条 | 验证集:{len(val_texts)}条")
# 2. 加载分词器和模型
tokenizer = BertTokenizer.from_pretrained(MODEL_NAME)
model = BertForSequenceClassification.from_pretrained(
MODEL_NAME, num_labels=NUM_LABELS, ignore_mismatched_sizes=True
)
logger.info(f"模型加载完成,使用设备:{torch.device('cuda' if torch.cuda.is_available() else 'cpu')}")
# 3. 创建数据集
train_dataset = TextDataset(train_texts, train_labels, tokenizer)
val_dataset = TextDataset(val_texts, val_labels, tokenizer)
# 4. 训练参数配置
training_args = TrainingArguments(
output_dir=SAVE_PATH,
per_device_train_batch_size=BATCH_SIZE,
per_device_eval_batch_size=BATCH_SIZE,
num_train_epochs=EPOCHS,
learning_rate=LEARNING_RATE,
weight_decay=0.01,
logging_dir=f"{SAVE_PATH}/logs",
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
metric_for_best_model="weighted_f1",
fp16=torch.cuda.is_available()
)
# 5. 训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=compute_metrics,
tokenizer=tokenizer
)
trainer.train()
# 6. 保存模型和评估
trainer.save_model(SAVE_PATH)
logger.info(f"模型已保存到:{SAVE_PATH}")
# 输出详细评估结果
val_preds = trainer.predict(val_dataset)
print("\n分类报告:")
print(classification_report(
val_preds.label_ids,
torch.argmax(torch.tensor(val_preds.predictions), dim=1).numpy(),
target_names=list(LABEL_MAP.keys())
))
if __name__ == "__main__":
train()训练后的文件
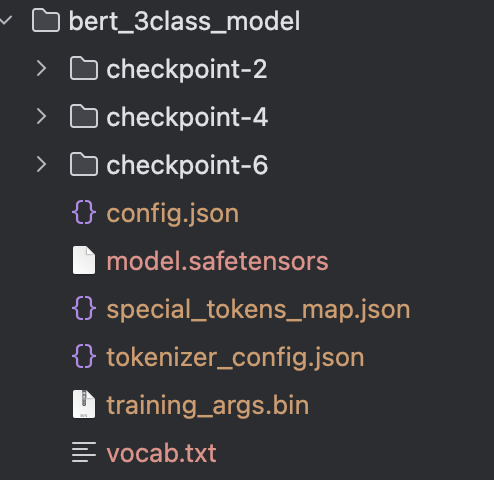
| 文件 | 说明 |
|---|---|
| checkpoint-x | 模型训练过程中自动保存的 "检查点文件" ,核心作用是记录训练到特定阶段的模型状态, 方便后续恢复训练、选择最优模型。每一个checkpoint都是一个完整的模型权重信息。 每个checkpoint都保存着完整的模型信息。 |
config.json |
模型的结构配置文件,记录 BERT 的核心参数(如层数、隐藏维度、注意力头数、分类类别数等),加载模型时需用它还原模型结构。 |
model.safetensors |
模型的权重文件(安全格式),存储了训练完成后所有可训练参数(如 Transformer 层的权重、分类头的参数),是模型推理 / 复用的核心文件。 |
special_tokens_map.json |
分词器的特殊 Token 映射表 ,定义[CLS]、[SEP]、[PAD]等特殊标记的名称与索引对应关系(比如{"cls_token": "[CLS]"})。 |
tokenizer_config.json |
分词器的配置文件,记录分词器的参数(如最大长度、截断 / 填充策略、是否小写等),加载分词器时需用它还原分词逻辑。 |
training_args.bin |
训练时的超参数 / 训练配置文件(二进制格式),存储了训练时的批次大小、学习率、迭代轮数等参数,方便复现训练过程。 |
vocab.txt |
BERT 的词汇表文件 ,记录了分词器可识别的所有 Token 及其对应的索引(比如 "我" 对应 2769),是文本转input_ids的核心依据。 |
5.4 训练的模型使用
模型训练好后,可以通过加载训练好的模型直接使用
python
tokenizer = BertTokenizer.from_pretrained("../models/bert_3class_model)
model = BertForSequenceClassification.from_pretrained(
"../models/bert_3class_model",
num_labels=3 # 2=二分类(正面/负面),可根据任务调整(如多分类设3/4等)
)影响模型训练效果的核心
| 核心维度 | 具体影响因素 | 关键说明(简明版) |
|---|---|---|
| 数据层面(基础) | 数据规模与覆盖度 | 数据量不足 / 场景单一 → 欠拟合 / 泛化差;覆盖全量目标场景更优 |
| 数据质量(标注 / 洁净度) | 标注错误 / 噪声多 → 误导模型;需去重、去噪、修正标注 | |
| 数据分布(类别 / 集间一致性) | 类别失衡 → 偏向多数类;训练 / 验证集分布差异大 → 评估失真 | |
| 数据预处理(分词 / 编码) | 分词错误、max_length 设置不当 → 丢失关键信息或引入冗余 | |
| 模型层面(工具) | 模型选型与规模 | 模型与任务不匹配(如 GPT 做分类)→ 效果差;模型过大(小数据)→ 过拟合 |
| 适配层设计与冻结策略 | 适配层过简 / 过繁 → 欠拟合 / 过拟合;冻结层数不当 → 无法充分适配任务 | |
| 核心结构超参数 | 隐藏层维度 / 注意力头数 → 过大过拟合、过小欠拟合,默认值微调即可 | |
| 训练策略(方法) | 优化器与权重衰减 | 首选 AdamW;权重衰减(0.01~0.1)→ 过小过拟合、过大泛化差 |
| 学习率与调度策略 | 初始学习率(1e-5~5e-5)→ 过大爆炸、过小收敛慢;需用线性衰减 / 余弦退火 | |
| 损失函数选择 | 分类用交叉熵、类别失衡用 Focal Loss;选则不当 → 无法有效学习 | |
| 批次大小与训练轮次 | batch size(8/16/32)→ 过小震荡、过大显存不足;轮次过多 → 过拟合(需早停) | |
| 正则化手段 | Dropout、梯度裁剪、权重衰减 → 缺失易过拟合,保障训练稳定性 | |
| 工程实现(保障) | 硬件资源 | GPU 显存不足 → 训练中断;性能不足 → 周期过长 |
| 环境配置与随机种子 | 库版本不兼容 → 报错;未固定种子 → 结果不可复现 | |
| 训练监控与内存管理 | 未监控验证指标 → 忽略过拟合;未用 torch.no_grad () → 显存泄漏 |
六、AI应用落地
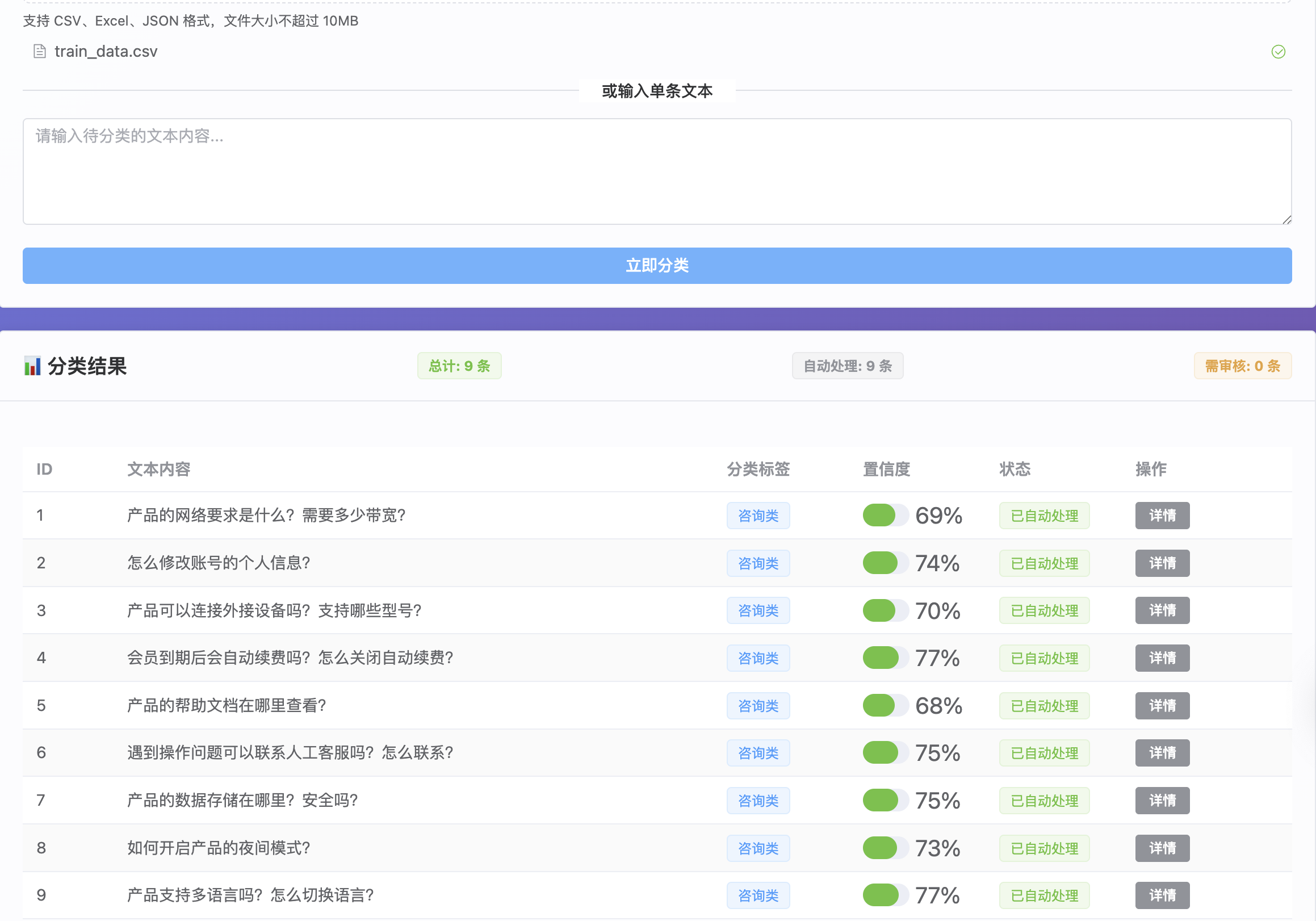
基于bert-base-chinese模型的文本分类场景实现一个AI应用逻辑。
需求场景如下:
私信对话一大堆,分类打到手抽筋?每人标准还不一样,数据根本对不上?
灵标AI来帮你!把聊天记录往里一丢,它立马就能自动判断问题类型。
85%的活儿它直接帮你干完,剩下15%才需要你人工把关。原来1小时的活儿,现在5分钟清空!
# 项目结构说明
```
LingBiaoAI/
├── api/ # API 服务层
│ ├── __init__.py
│ └── main.py # FastAPI 主应用
│
├── data_processing/ # 数据处理层
│ ├── __init__.py
│ ├── data_loader.py # 数据加载器(CSV/Excel/JSON)
│ └── preprocessor.py # 文本清洗、分词、特征提取
│
├── model/ # 模型层
│ ├── __init__.py
│ ├── bert_classifier.py # BERT 分类模型与预测器
│ └── trainer.py # 模型训练/验证逻辑
│
├── scripts/ # 工具脚本
│ ├── __init__.py
│ └── train_model.py # 训练入口(支持 CLI 参数)
│
├── data/ # 数据目录
│ └── sample/
│ └── train_data.csv # 示例训练数据
│
├── models/ # 模型文件
│ └── saved_models/
│ └── bert_classifier # 默认模型输出路径
│
├── frontend/ # 前端工程(Vue 3 + Element Plus)
│ ├── src/
│ │ ├── App.vue
│ │ ├── main.js
│ │ ├── router/
│ │ └── views/
│ ├── package.json
│ ├── vite.config.js
│ ├── Dockerfile # 前端容器化(可选)
│ └── nginx.conf
│
├── logs/ # 运行日志
├── uploads/ # 上传文件临时目录
│
├── config.py # 全局配置
├── requirements.txt # Python 依赖清单
├── README.md # 中文文档
├── README-EN.md # 英文文档
├── PROJECT_STRUCTURE.md # 本文件
├── QUICKSTART.md # 快速上手指南
├── run.sh # Linux/macOS 启动脚本(Conda)
└── run.bat # Windows 启动脚本
```
## 模块说明
### 1. API 层 (`api/`)
- **main.py**:FastAPI 应用入口,提供
- `/api/classify` 单文本分类
- `/api/classify/batch` 批量分类
- `/api/classify/upload` 文件上传批处理
- `/health` 健康检查
### 2. 数据处理层 (`data_processing/`)
- **data_loader.py**:封装 CSV/Excel/JSON 的加载与统一格式化
- **preprocessor.py**:中文文本清洗、分词、特征提取(jieba)
### 3. 模型层 (`model/`)
- **bert_classifier.py**:BERT 分类模型、推理器与单例获取
- **trainer.py**:训练循环、验证评估、模型保存/加载
### 4. 脚本 (`scripts/`)
- **train_model.py**:命令行训练脚本,支持数据路径、epoch、batch size 等参数
### 5. 前端 (`frontend/`)
- Vue 3 + Element Plus 构建的交互界面,提供文件上传、单条输入、分类结果展示、人工审核、CSV 导出等功能
## 数据流向
1. 用户在前端上传文件或输入文本
2. 前端调用 FastAPI 接口
3. 后端进行文本预处理
4. BERT 模型推理得到标签与置信度
5. 返回前端展示,并按置信度标记是否自动通过
6. 人工审核低置信度结果并可导出仓库地址:灵标AI
项目demo展示:
单文本输入
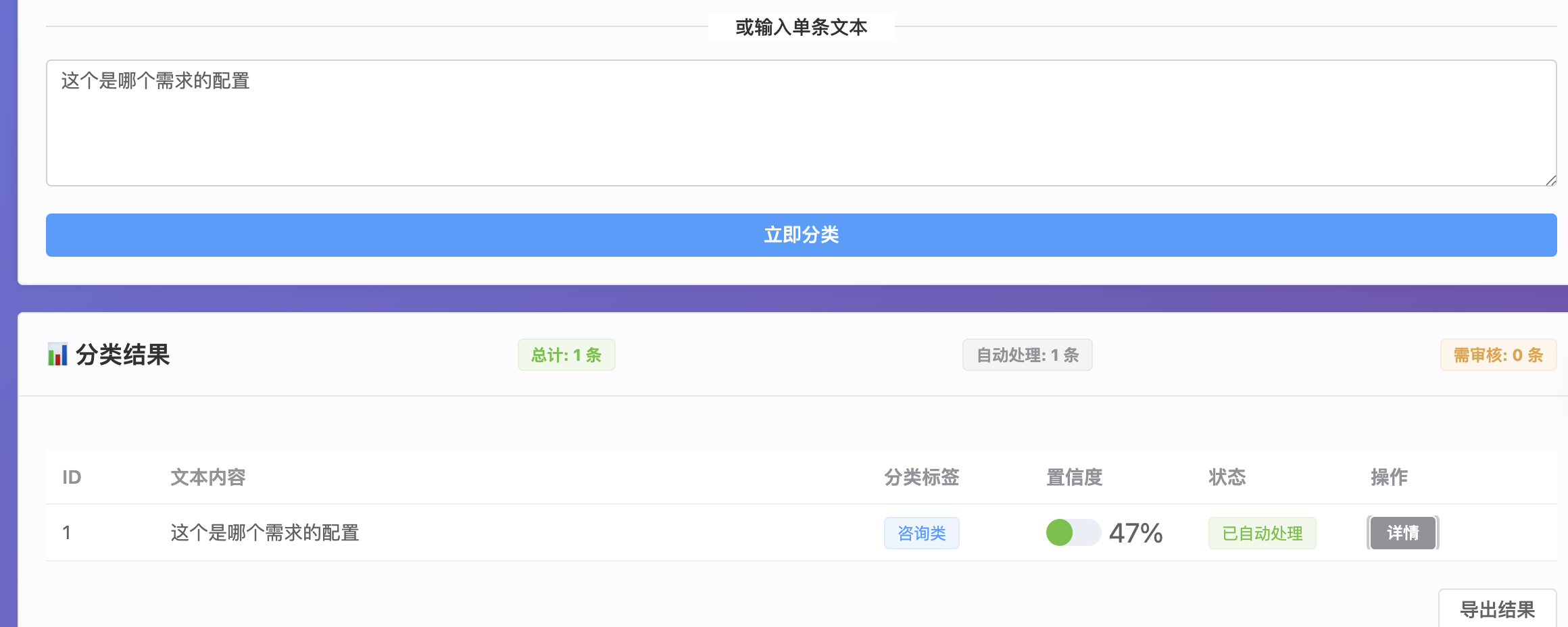
批量上传