推荐直接网站在线阅读:aicoting.cn
在神经网络的理论基础中,有一个非常重要的结果,叫做通用逼近定理(Universal Approximation Theorem, UAT)。它是深度学习能够大放异彩的根基之一。简单来说,这个定理告诉我们:只要神经网络的隐藏层神经元足够多,它就能逼近任意复杂的函数。
以下是通用逼近定理的定义: 假设我们有一个连续函数 f:Rn→R,定义在一个紧致集合(比如一个有限区间)上。
通用逼近定理断言:
∀ϵ>0,∃g(x)=∑i=1mαiσ(wiTx+bi),使得 ∣f(x)−g(x)∣<ϵ
其中:
- σ:是非线性激活函数(如 Sigmoid、Tanh、ReLU 等)
- wi,bi:是权重和偏置
- αi:是线性组合系数
- m:隐藏层神经元的数量
换句话说,只要神经元数量够多,一个单隐层前馈神经网络就能近似任何连续函数。
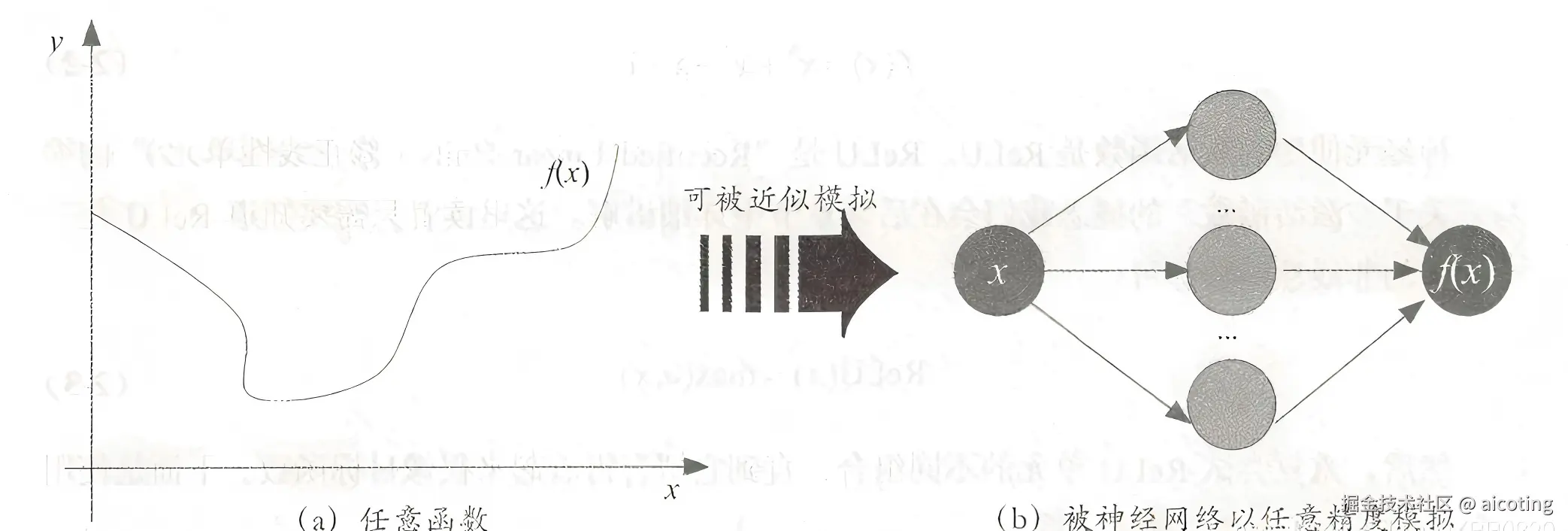
在深度学习之前,很多人质疑神经网络是不是只能处理一些特定任务?、它到底能不能解决更复杂的模式识别问题? 通用逼近定理给了一个非常有力的回答:神经网络是通用的函数拟合器。无论是回归、分类,还是更复杂的模式识别,本质上都是函数逼近问题。而神经网络理论上都有能力胜任。
虽然结论很强大,但需要注意这仅仅是理论,理论上一个隐藏层就能实现通用逼近。但在实际应用中,这往往需要成千上万个神经元,训练效率极差。所以深度网络后面更受欢迎, 因为深度结构(多层隐藏层)能够用更少的参数表达复杂函数。它们更高效、更易训练。
通用逼近定理只保证逼近能力,并没有保证泛化能力。也就是说,网络可能完美拟合训练数据,但在测试集上表现很差。
通用逼近定理成立的一个关键条件是激活函数必须是非线性且满足一定性质。Sigmoid、Tanh、ReLU、GELU 等常见激活函数都满足条件。如果只用线性激活函数,整个网络退化为线性变换,就失去了逼近任意非线性函数的能力。
直观点理解,可以把神经元类比成乐高积木,每个神经元的作用就是构造一个简单的非线性积木。隐藏层就是把这些积木拼在一起。只要数量足够,就能拼出任意复杂的形状。这就是通用逼近定理背后的直觉。
通用逼近定理证明了神经网络的潜力是无限的。它不受任务限制,只要设计得当、数据足够,就能近似任何复杂函数。虽然在实际中我们不会用一个巨大的一层网络去拟合函数,而是倾向于用更深的网络结构,但通用逼近定理给了我们信心------神经网络不是玄学,它有坚实的数学理论做支撑。
📚推荐阅读
最新的文章都在公众号aicoting更新,别忘记关注哦!!!