引言:多模态的"终极形态"已来? 背景: 回顾 Gemini 1.5 到 3.0 的跨越,点出 Google DeepMind
在原生多模态(Native Multimodality)上的执念。 核心论点: 为什么说之前的多模态只是"拼接怪"(Text Encoder
- Image Encoder),而 Gemini 3.0 才是真正的"原生融合"? 本文目标: 不吹不黑,从架构原理、长窗口机制、推理能力三个维度硬核拆解。
第一章:架构深潜 ------ "原生"到底意味着什么?
在 Gemini 3.0 发布之前,市面上绝大多数所谓的"多模态模型"(LMM),在架构师眼中更像是一个"缝合怪"(Frankenstein)。
为了理解 Gemini 3.0 的**原生多模态(Native Multimodality)**到底强在哪里,我们必须先看清上一代架构的阿喀琉斯之踵。
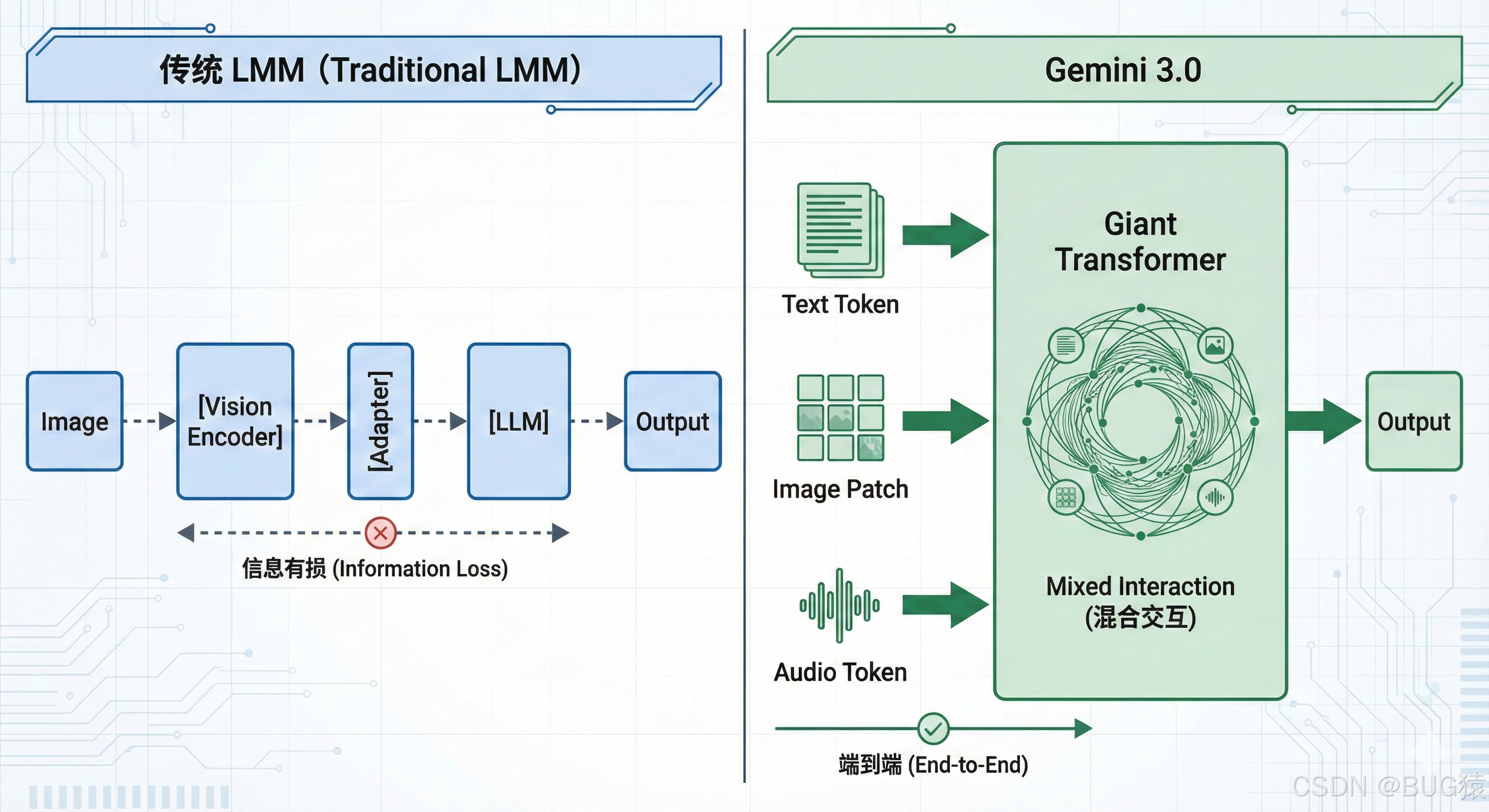
1.1 告别"外挂":从 LLaVA 模式到端到端原生
在开源界(如 LLaVA, CogVLM)以及早期闭源模型中,主流架构通常遵循 ViT + Adapter + LLM 的范式。
- 视觉编码器(Vision Encoder): 使用 CLIP 或 SigLIP 等预训练模型提取图像特征。
- 对齐层(Projection/Adapter): 一个简单的线性层或 MLP,试图将图像特征"翻译"成 LLM 能听懂的词向量(Embedding)。
- 大语言模型(LLM): 接收翻译过来的视觉特征,进行文本生成。
这种架构的致命缺陷在于"有损压缩"与"语义断层"。 视觉编码器在预训练时并未考虑到复杂的逻辑推理任务,大量细节(如图片中文字的字体、微小的空间关系、图表趋势)在经过 Projection 层时被压缩丢失了。模型是在"看图说话",而不是在"理解世界"。
Gemini 3.0 的"原生"架构则完全推翻了这一套路:
它不再区分"视觉编码器"和"语言模型"。从训练的第一天起,它是端到端(End-to-End)训练的。
在 Gemini 3.0 的 Transformer 内部,文本、图像、音频、视频被映射到了同一个共享的向量空间(Joint Embedding Space)。
Etotal=Etext∪Eimage∪Eaudio∪Evideo E_{total} = E_{text} \cup E_{image} \cup E_{audio} \cup E_{video} Etotal=Etext∪Eimage∪Eaudio∪Evideo
这意味着,对于模型而言,一张图片的 Patch 和一个单词 Token 在物理层面上是平等的。模型不需要"翻译"图像,它直接"阅读"图像。这种架构带来的质变是:模型能捕捉到跨模态的细微 Nuance(神韵)。 比如,它不仅能听懂音频里的文字,还能通过波形数据的变化,直接理解说话人的"阴阳怪气"或"犹豫不决",这是传统 ASR + NLP 管道永远无法做到的。
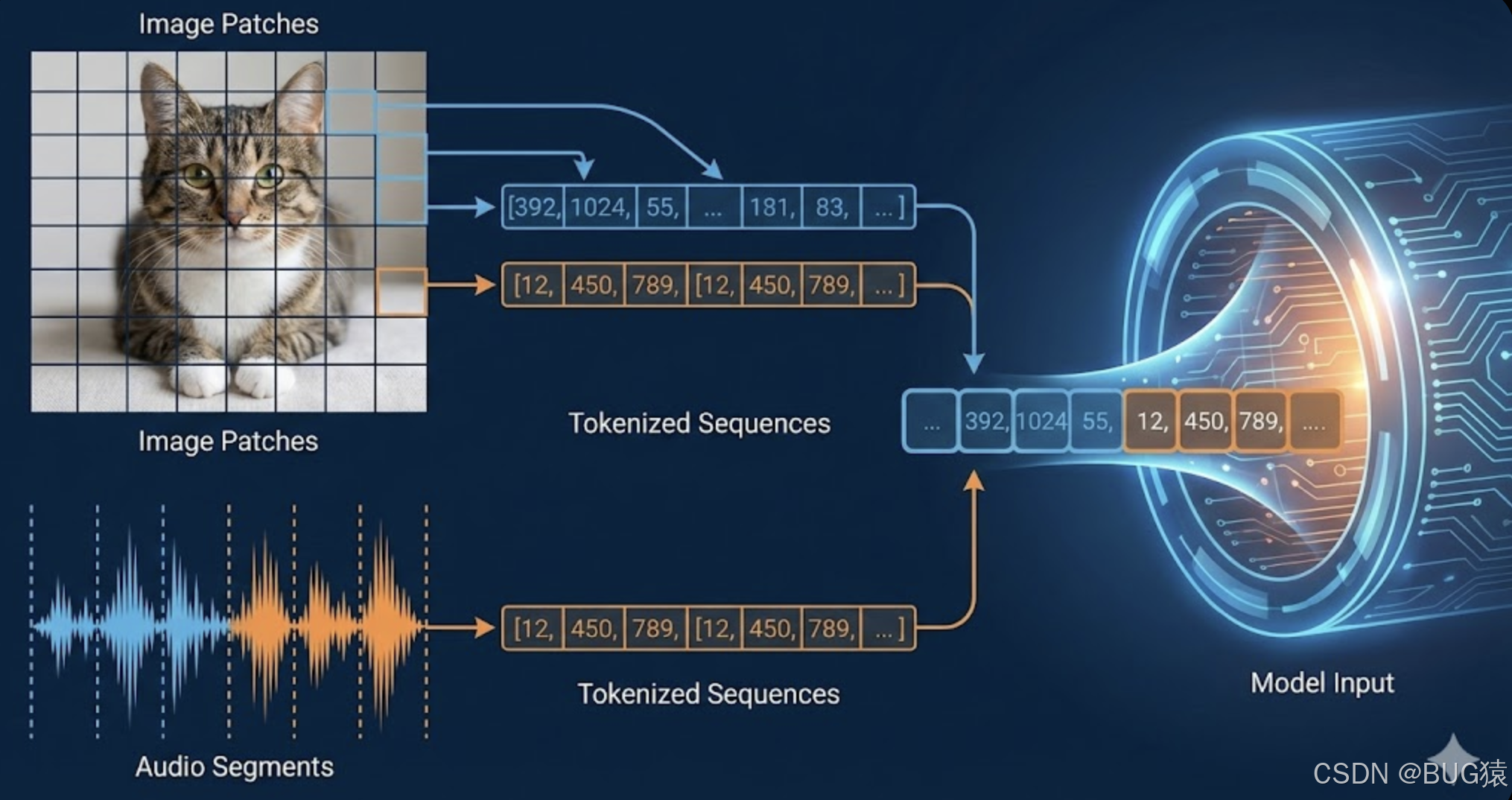
1.2 Token 的革命:万物皆可离散化
要实现上述的"大一统",核心难点在于如何将连续信号(视频流、音频波形)转化为离散的 Token,以便 Transformer 处理。
Gemini 3.0 极有可能采用了改进版的 USM (Universal Speech Model) 和 VQ-VAE (Vector Quantized Variational AutoEncoder) 技术。
- 视频离散化: 视频不再被视为一帧帧独立的图片。Gemini 3.0 将视频切分为时空立方体(Spatiotemporal Patches),将时间维度 TTT 和空间维度 H×WH \times WH×W 同时进行 Token 化。这使得模型能够理解"因果关系"和"物理运动",而不是单纯的静态物体识别。
- 音频离散化: 音频波形被以 100Hz 甚至更高的频率采样为离散 Token。
这种全模态 Token 化带来了两个可怕的能力:
- 交错输入(Interleaved Input): 用户可以混合输入
[文本, 图片, 视频片段, 文本, 音频],模型能处理任意顺序的上下文流。 - 原生输出(Any-to-Any): 既然输入是共享的,输出自然也是。Gemini 3.0 不再需要调用 Stable Diffusion 画图或 TTS 引擎转语音,它可以直接预测图像 Token 或音频 Token,生成速度和连贯性呈指数级提升。
1.3 混合专家模型(MoE)的极致进化
参数量越大,推理成本越高,这是 Scaling Law 的魔咒。Gemini 3.0 为了在保持"天花板"级智商的同时降低延迟,必然将 MoE(Mixture of Experts) 架构推向了极致。
与 GPT-4 的 MoE 相比,Gemini 3.0 的架构亮点可能在于 "细粒度路由(Fine-grained Routing)" 和 "模态专精专家"。
- 动态路由机制: 并不是所有的 Token 都需要激活整个大脑。处理简单的语法连接词时,路由门控(Router)只激活极小部分的参数;而在进行复杂的视觉代码重构时,则激活高维推理专家。
- 模态感知专家(Modality-Aware Experts): 传统的 MoE 专家通常是通用的。但在 Gemini 3.0 中,极有可能存在专门针对"视觉纹理"、"音频频谱"或"代码逻辑"优化的专家组。当处理多模态 Token 时,Router 会根据 Modality ID 将其分发给最擅长的专家。
一言以蔽之: Gemini 3.0 的架构革新,不在于把模型做大,而在于打破了模态之间的"生殖隔离"。它不再是一个戴着眼镜(视觉编码器)和助听器(音频编码器)的文科生,而是一个天生具备视听通感的全能天才。