Linux单机部署spark
前提:java17环境
官网下载:
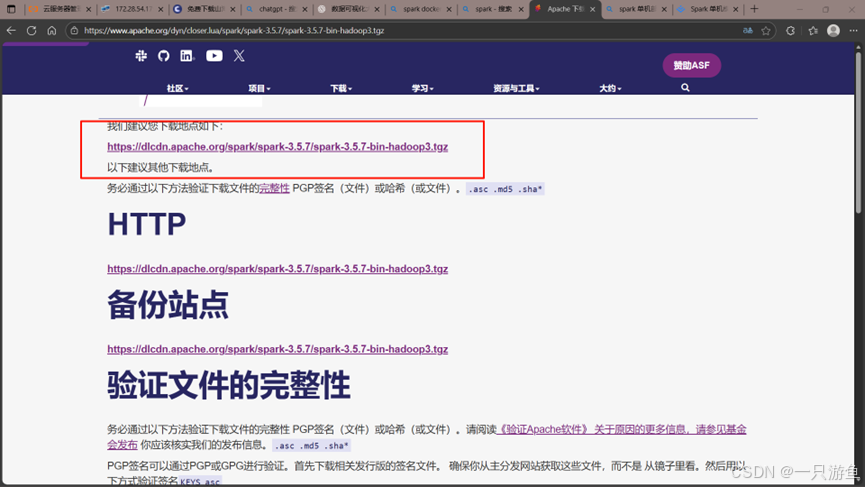
下载成功后通过终端上传到服务器并解压:
tar -zxvf spark-3.5.7-bin-hadoop3.tgz

添加到环境变量:
vi /etc/profile
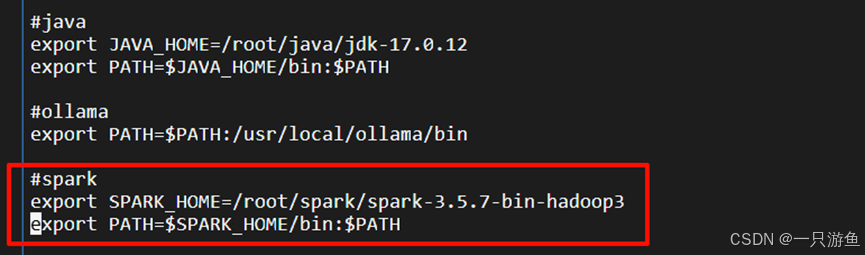
添加如下内容:
#spark
#这里路径给位你的spark的实际路径
export SPARK_HOME=/root/spark/spark-3.5.7-bin-hadoop3
export PATH=SPARK_HOME/bin:PATH
刷新环境变量:
source /etc/profile
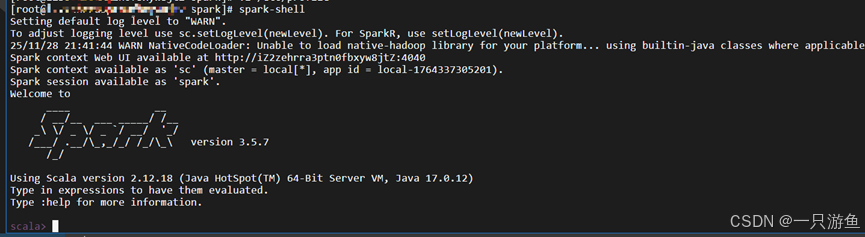
检查环境变量是否配置成功:
spark-shell
出现以下,证明配置成功: