大家好,我是磊磊落落,目前我在技术上主要关注:Java、Golang、AI、架构设计、云原生和自动化测试。欢迎来我的博客(leileiluoluo.com)获取我的最近更新!
开始本文前,让我们首先明确提示词与提示工程的概念。提示词是我们与大语言模型沟通时输入的指令,而提示工程则是发现能生成符合预期、稳定、可靠、和可复现结果的提示词的过程。
为什么需要提示工程呢?就是因为当前的生成式人工智能还不够智能,其输出具有不确定性,用专业术语来说,就是存在随机生成「次品」的可能。为解决这个问题,必须有一套工程化的方法对提示词进行适当的优化。
一些工程师在实践中也确实探索出一组好用的原则,被称为「编写提示词的五个原则」,遵循这些原则编写出来的提示词能以更高的概率让 AI 模型生成稳定、可靠、可复现的结果。
接下来就介绍一下这「五个原则」,然后以「Spring Boot 项目中的 MyBatis 转 JPA」为例演示如何遵照原则优化提示词来让 AI 助手达到高质量的结果交付。
1 编写提示词需要遵循的五个原则
- 明确方向
详细描述期望的结果,最好给出一个现实世界的参考模板。比如:生成一段搞笑的脱口秀稿子,参考「徐志胜」风格。
- 规范格式
指定大模型需遵循的规则,并明确限定输出结果的结构或格式。比如:要求大模型返回的结果为 JSON 格式,避免接收无规则的结果,且便于程序化集成。
- 提供范例
提供样例代码或提供一组多样化的预期输出的范例供大模型参考。比如:生成一组样例学生 JSON 数据,如 [{"name": "Larry"}, {"name": "Lucy"}]。
- 评估质量
对输出结果进行评级,通过测试来找出提升模型准确性的关键因素。比如:针对 AI 模型的输出结果,给出每个结果的分值,然后反馈给模型,这样能提升输出结果的准确性。
- 拆分任务
不要将一个复杂任务不做拆分就直接扔给大模型,而应将其拆分为多个步骤,这样大模型做起来才更得心应手。比如:不要跟大模型说「把这个事做了」,而是应将一个事拆分为多个步骤,然后指导大模型一步步去达成目标。
2 实践案例:将 Spring Boot 项目的数据库访问层由 MyBatis 转换为 JPA
接下来以实际项目「博友圈」的后端(boyouquan-api)数据库访问层的转换为例,演示编写提示词时如何运用上述五个原则。
博友圈后端是一个使用 Maven 管理的 Spring Boot 项目,负责给前端提供 RESTful API。
其数据库访问层目前是基于 MyBatis 实现的,源码目录 src/main/java 下的包 com.boyouquan.dao 下定义了一组 Mapper 接口;资源目录 src/main/resources 下的子目录 mapper 下存放与 Mapper 接口对应的 XML 文件。
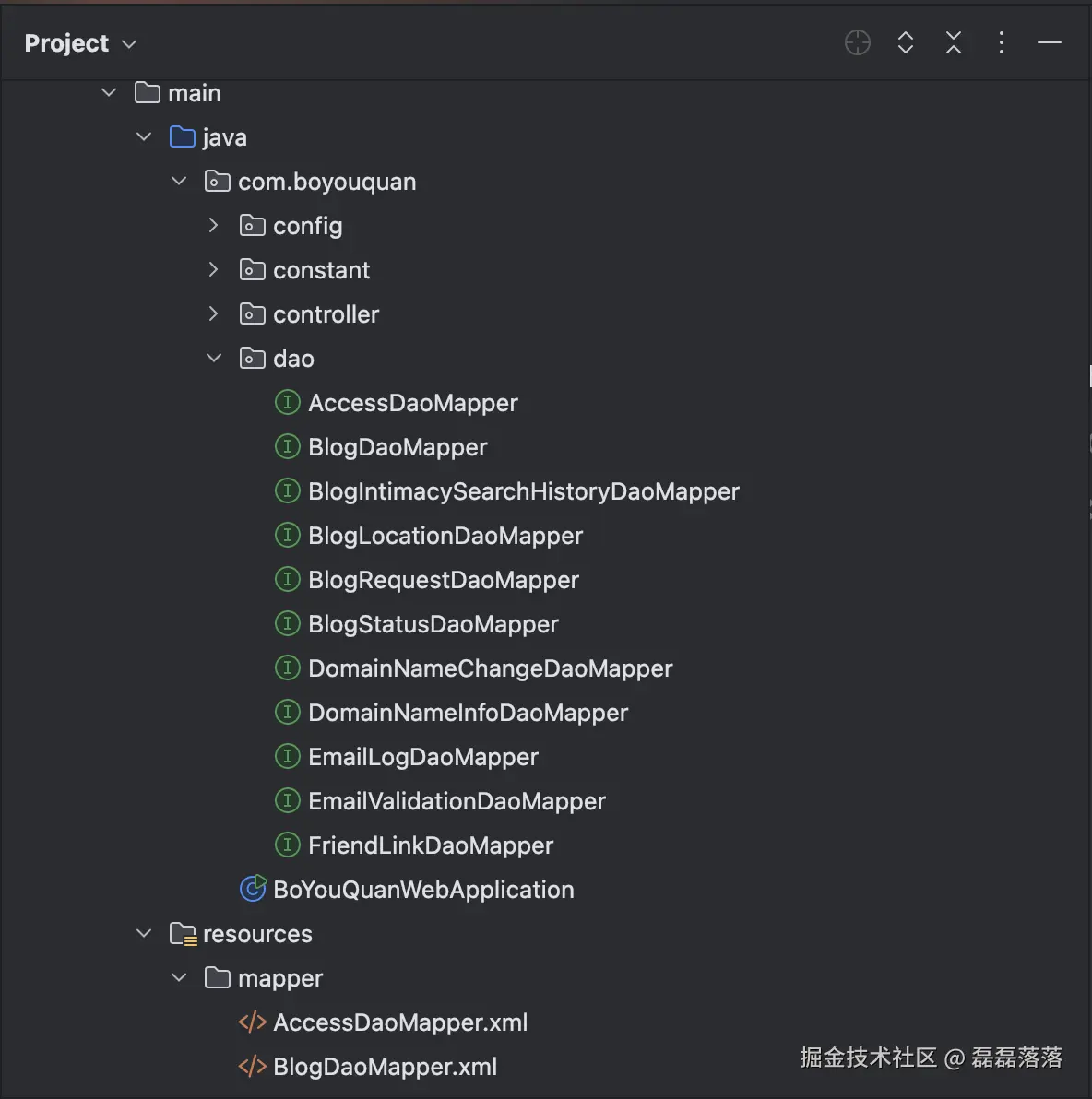
Mapper 接口中定义了一组方法:
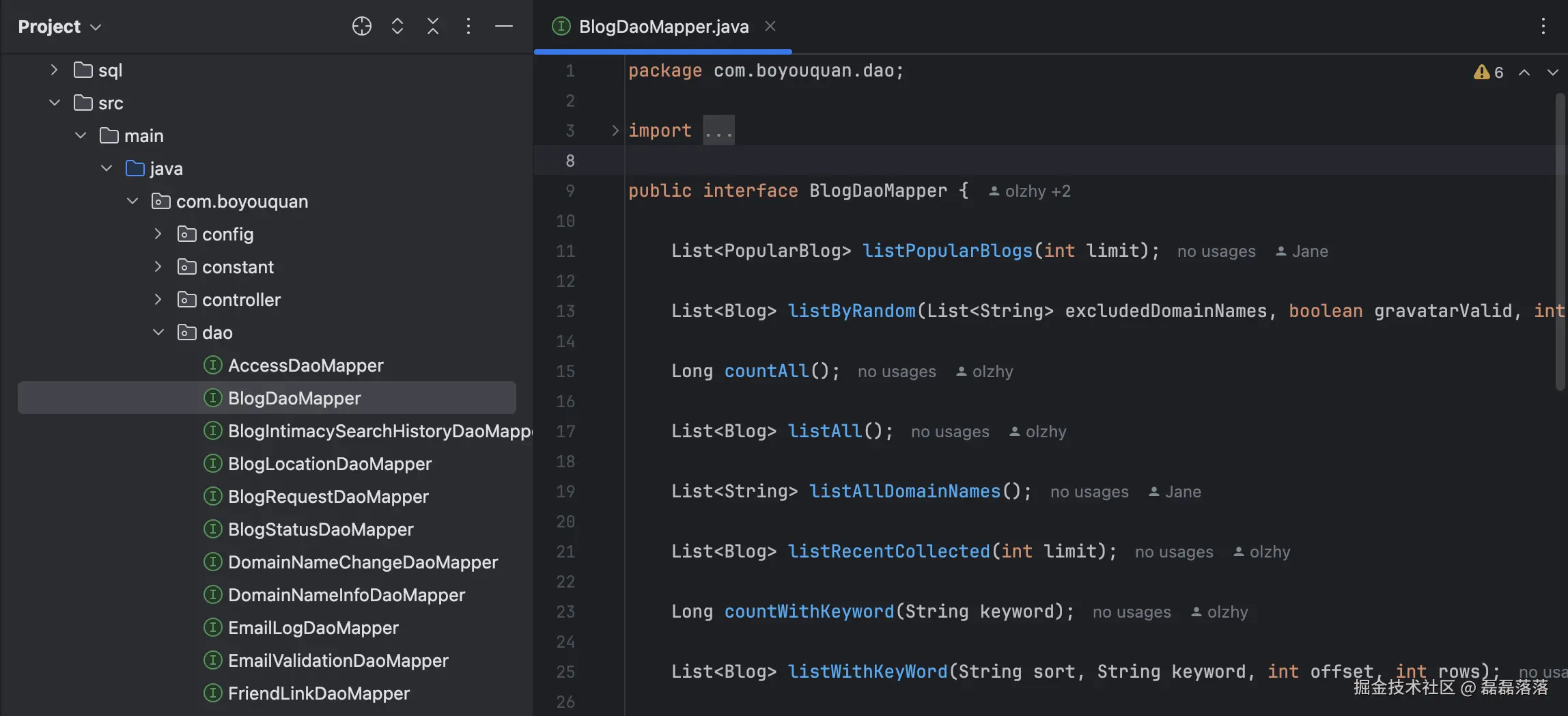
与 Mappper 接口对应的 XML 文件中定义了方法所使用的 SQL:
若我们想让 AI 助手帮忙将该工程的数据库访问层由 MyBatis 转换为 JPA,该如何编写提示词呢?
下面我们首先尝试一下未学习上述「五个原则」前的常规提示词,然后尝试一下学习了「五个原则」后的改进提示词,并对比两者的结果有何差异。
2.1 常规提示词
下面是实现上述转换任务的常规提示词:
text
当前项目是一个使用 Maven 管理的 Spring Boot 项目,源码位于 src/main/java 下,配置文件位于 src/main/resources 下。
当前数据库访问层使用的是 MyBatis。Mapper 接口定义于包 com.boyouquan.dao 下,Mapper 配置文件 XxxDaoMapper.xml 位于 resources 的 mapper 目录下。
现在我们想将数据库访问层由 MyBatis 更改为 JPA。请自动抓取 MyBatis Mapper 接口中的方法名称与 Mapper 配置文件里的 SQL 语句,然后在 com.boyouquan.repository 下编写与 Mapper 接口对应的 Repository 接口、定义与 Mapper 接口中方法同名的方法并使用 @Query(value = "", nativeQuery = true) 注解填入 Mapper 配置文件里对应的 SQL。
完成后,请在项目根目录生成一个 report.md 报告文件,以表格的方式展示原始 Mapper 接口与新生成的 Repository 的对应关系。在上述提示词中,我首先说明了当前项目的架构、源码目录、配置文件目录等背景信息;接着说明了 MyBatis Mapper 接口和 Mapper XML 文件的位置;然后说明了任务要求,并简单给出了实现步骤;最后我要求完成后生成一个报告。
下面尝试用 VS Code 打开项目,然后在 Copilot 聊天窗输入上述提示词,让 AI 助手以 Agent 模式帮我实现上述任务。
几分钟后,AI 助手帮我完成了 MyBatis 到 JPA 的转换:
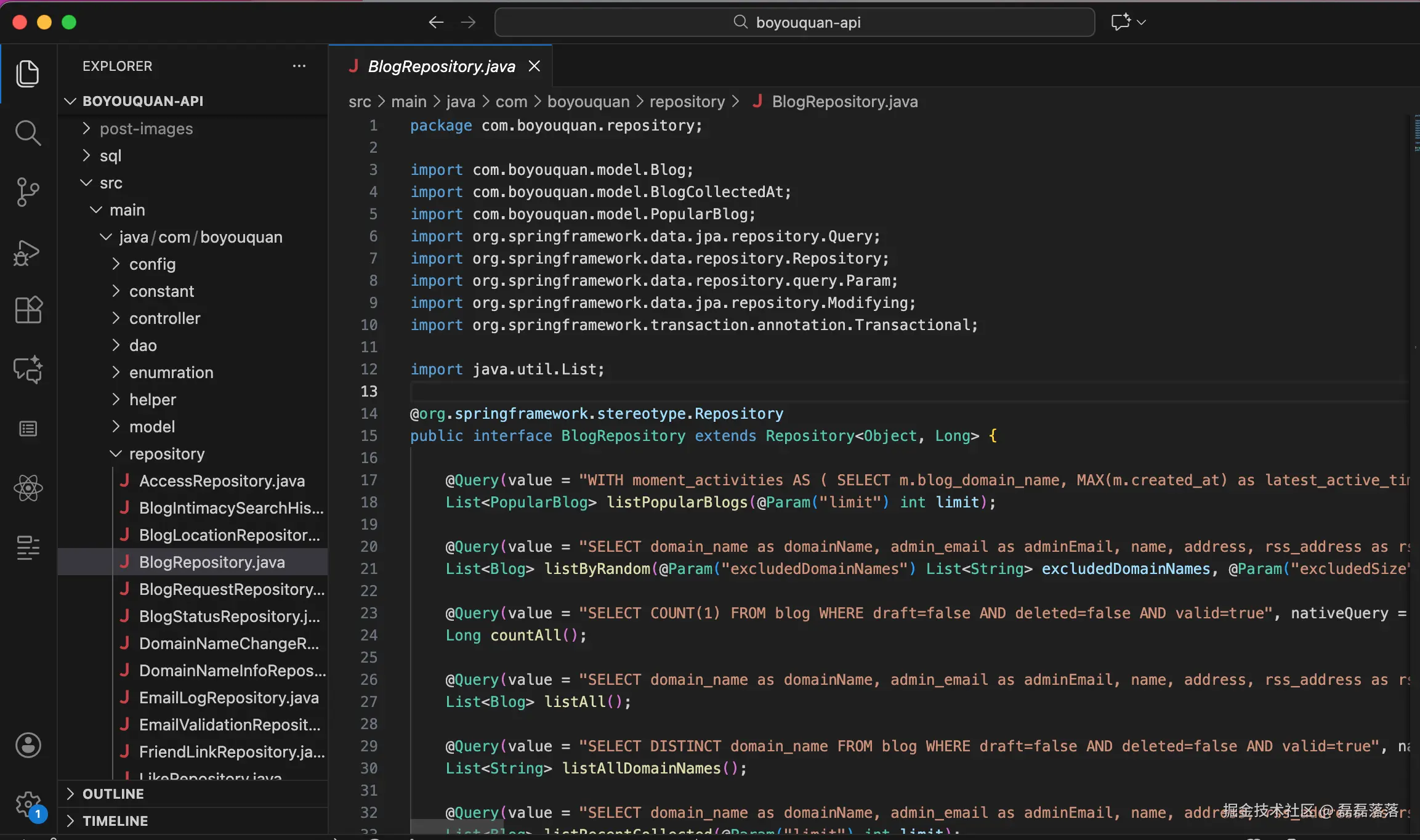
但结果不太理想,主要存在如下几个问题:
- 生成的 JPA Repository 接口继承了
Repository,而不是我想象中的CrudRepository; - 不论是简单查询语句还是复杂查询语句,均使用了自定义查询,而没有根据情形将简单查询语句转换为 JPA 的命名方法实现;
@Query注解里填入的 SQL 不论长短均使用一个单行展开,而未根据情形使用 Java 13 的文本块特性将 SQL 换行。
这就是我们当下使用 AI 的现状:我们指派 AI 做一些任务时,默认 AI 具备一些「常识」,但从结果来看,AI 并不一定具备这些「常识」。这也就是提示工程存在的意义。
2.2 优化后的提示词
下面尝试使用上述的「五个原则」优化提示词,并将其放入项目根目录的文件 mybatis-to-jpa.prompt.md 中。
优化后的提示词如下:
markdown
# 将 MyBatis 替换为 JPA
## 1 背景知识
当前项目是一个使用 Maven 管理的 Spring Boot 项目,源码位于 `src/main/java` 下,配置文件位于 `src/main/resources` 下。
当前数据库访问层使用的是 MyBatis。Mapper 接口定义于包 `com.boyouquan.dao` 下,Mapper 配置文件 `XxxDaoMapper.xml` 位于 resources 的 mapper 目录下。
## 2 任务简介
现在我们想将数据库访问层由 MyBatis 更改为 JPA。请自动抓取 MyBatis Mapper 接口中的方法名称与 Mapper 配置文件里的 SQL 语句,然后在 `com.boyouquan.repository` 下编写与 Mapper 接口对应的 Repository 接口、定义与 Mapper 接口中方法同名的方法并使用 `@Query(value = "", nativeQuery = true)` 注解填入 Mapper 配置文件里对应的 SQL。
## 3 实现步骤
### 3.1 编写与 Mapper 接口对应的 Repository 接口
首先,需要找到 `com.boyouquan.dao` 包下所有的 Mapper 接口,然后在 `com.boyouquan.repository` 包下新建对应的 Repository 接口。
如下为一个示例。
`com.boyouquan.dao` 包下原始的 `BlogDaoMapper` 接口定义如下:
```java
package com.boyouquan.dao;
public interface BlogDaoMapper {
}
```
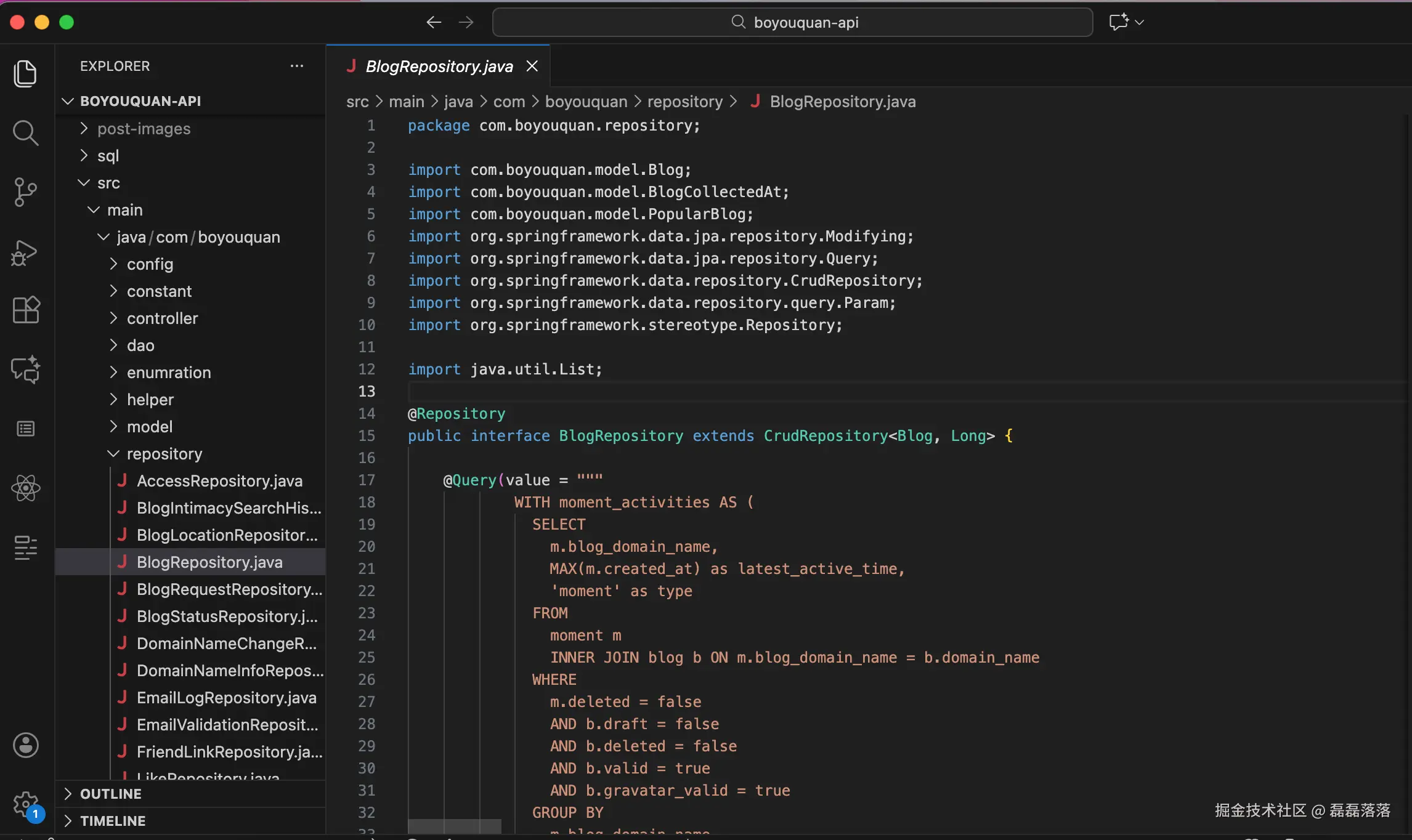
那么在 `com.boyouquan.repository` 包下新建一个与 `BlogDaoMapper` 接口对应的 Repository 接口 `BlogRepository`,并让该 Repository 继承 `CrudRepository`:
```java
package com.boyouquan.repository;
import org.springframework.data.repository.CrudRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface BlogRepository extends CrudRepository<Blog, Long> {
}
```
### 3.2 在 Repository 接口定义与 Mapper 接口中方法同名的方法
接下来,扫描原始 Mapper 接口中所有定义好的方法,然后在对应的 Repository 接口新建与之同名的方法。
如下为一个示例。
原始 `BlogDaoMapper` 包含一组方法:
```java
package com.boyouquan.dao;
public interface BlogDaoMapper {
Blog getByAddress(String address);
List<PopularBlog> listPopularBlogs(int limit);
...
}
```
那么在新建的 `BlogRepository` 接口里定义一组与 `BlogDaoMapper` 接口里方法同名的方法:
```java
package com.boyouquan.repository;
import org.springframework.data.repository.CrudRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface BlogRepository extends CrudRepository<Blog, Long> {
Blog getByAddress(String address);
List<PopularBlog> listPopularBlogs(int limit);
...
}
```
### 3.3 针对 Mapper 接口中的方法,从 XxxMapper.xml 抓取与之对应的 SQL
对于一个给定的 Mapper 接口,需要到 `resources/mapper` 文件夹下找到与之对应的配置文件;然后针对 Mapper 接口中的方法,从 `XxxMapper.xml` 配置文件抓取出所对应的 SQL。
如,`BlogDaoMapper` 接口的 `getByAddress` 方法在 Mapper 配置文件 `resources/mapper/BlogDaoMapper.xml` 中的配置如下:
```xml
<select id="getByAddress" resultType="com.boyouquan.model.Blog">
SELECT
<include refid="select_columns"/>
FROM blog
WHERE address=#{address}
</select>
```
抓取 SQL 时,看到有 `include` 标签,要在文件中找到标签定义的地方:
```xml
<sql id="select_columns">
domain_name as domainName,
admin_email as adminEmail,
name,
address,
rss_address as rssAddress,
description,
self_submitted as selfSubmitted,
collected_at as collectedAt,
updated_at as updatedAt,
valid,
gravatar_valid as gravatarValid,
draft,
deleted
</sql>
```
然后抓取出 `getByAddress` 方法所使用的完整 SQL:
```sql
SELECT
domain_name as domainName,
admin_email as adminEmail,
name,
address,
rss_address as rssAddress,
description,
self_submitted as selfSubmitted,
collected_at as collectedAt,
updated_at as updatedAt,
valid,
gravatar_valid as gravatarValid,
draft,
deleted
FROM blog
WHERE address=#{address}
```
没有 `include` 标签的 SQL 则直接抓取即可。
### 3.4 在 Repository 接口为方法添加 @Query 注解并填入对应的 SQL
接下来是本次实现的重点:使用 `@Query` 注解将上一步找到的 SQL 填入与 Mapper 接口对应的 Repository 接口方法上。
填入 SQL 时,需要遵循两个原则:
- a)如果对应的方法能使用 JPA 的命名方法实现就不要使用自定义查询方式实现。所以方法名可以根据需要做相应的更改,只要在最后的报告中做出说明即可;
如,在 BlogRepository 中实现 `getByAddress` 方法时,没必要使用自定义查询,写成:
```java
package com.boyouquan.repository;
import org.springframework.data.repository.CrudRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface BlogRepository extends CrudRepository<Blog, Long> {
@Query(value = "SELECT * FROM blog WHERE address=#{address}", nativeQuery = true)
Blog findByAddress(String address);
}
```
而应使用 JPA 的命名方法,写成:
```java
package com.boyouquan.repository;
import org.springframework.data.repository.CrudRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface BlogRepository extends CrudRepository<Blog, Long> {
Blog findByAddress(String address);
}
```
对于这一方法名的变更,只需要在最后的报告中做出说明即可。
- b)使用 `@Query` 注解指定自定义查询时,如果对应的 SQL 语句太长,则 `value` 字段需要用 Java 13 引入的三个引号引用文本块的方式实现,而不要将一个长 SQL 放在一个单行上,影响阅读。
如,`BlogDaoMapper` 接口的 `listPopularBlogs` 方法在 Mapper 配置文件 `BlogDaoMapper.xml` 中的 SQL 很长。在 BlogRepository 中实现 `listPopularBlogs` 方法时,须写成:
```java
package com.boyouquan.repository;
import org.springframework.data.repository.CrudRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface BlogRepository extends CrudRepository<Blog, Long> {
@Query(value = """
WITH moment_activities AS (
SELECT
m.blog_domain_name,
MAX(m.created_at) as latest_active_time,
'moment' as type
FROM
moment m
INNER JOIN blog b ON m.blog_domain_name = b.domain_name
WHERE
m.deleted = false
AND b.draft = false
AND b.deleted = false
AND b.valid = true
AND b.gravatar_valid = true
GROUP BY
m.blog_domain_name
),
post_activities AS (
SELECT
p.blog_domain_name,
MAX(p.published_at) as latest_active_time,
'post' as type
FROM
post p
INNER JOIN blog b ON p.blog_domain_name = b.domain_name
WHERE
p.deleted = false
AND p.draft = false
AND b.draft = false
AND b.deleted = false
AND b.valid = true
AND b.gravatar_valid = true
GROUP BY
p.blog_domain_name
),
combined_activities AS (
SELECT
blog_domain_name,
latest_active_time,
type
FROM
moment_activities
UNION ALL
SELECT
blog_domain_name,
latest_active_time,
type
FROM
post_activities
),
ranked_activities AS (
SELECT
blog_domain_name as blogDomainName,
latest_active_time as latestActiveTime,
type,
ROW_NUMBER() OVER (
PARTITION BY blog_domain_name
ORDER BY
latest_active_time DESC
) as rn
FROM
combined_activities
)
SELECT
blogDomainName,
latestActiveTime,
type
FROM
ranked_activities
WHERE
rn = 1
ORDER BY
latestActiveTime DESC
LIMIT
:limit
""", nativeQuery = true)
List<PopularBlog> listPopularBlogs(int limit);
}
```
## 4 报告生成
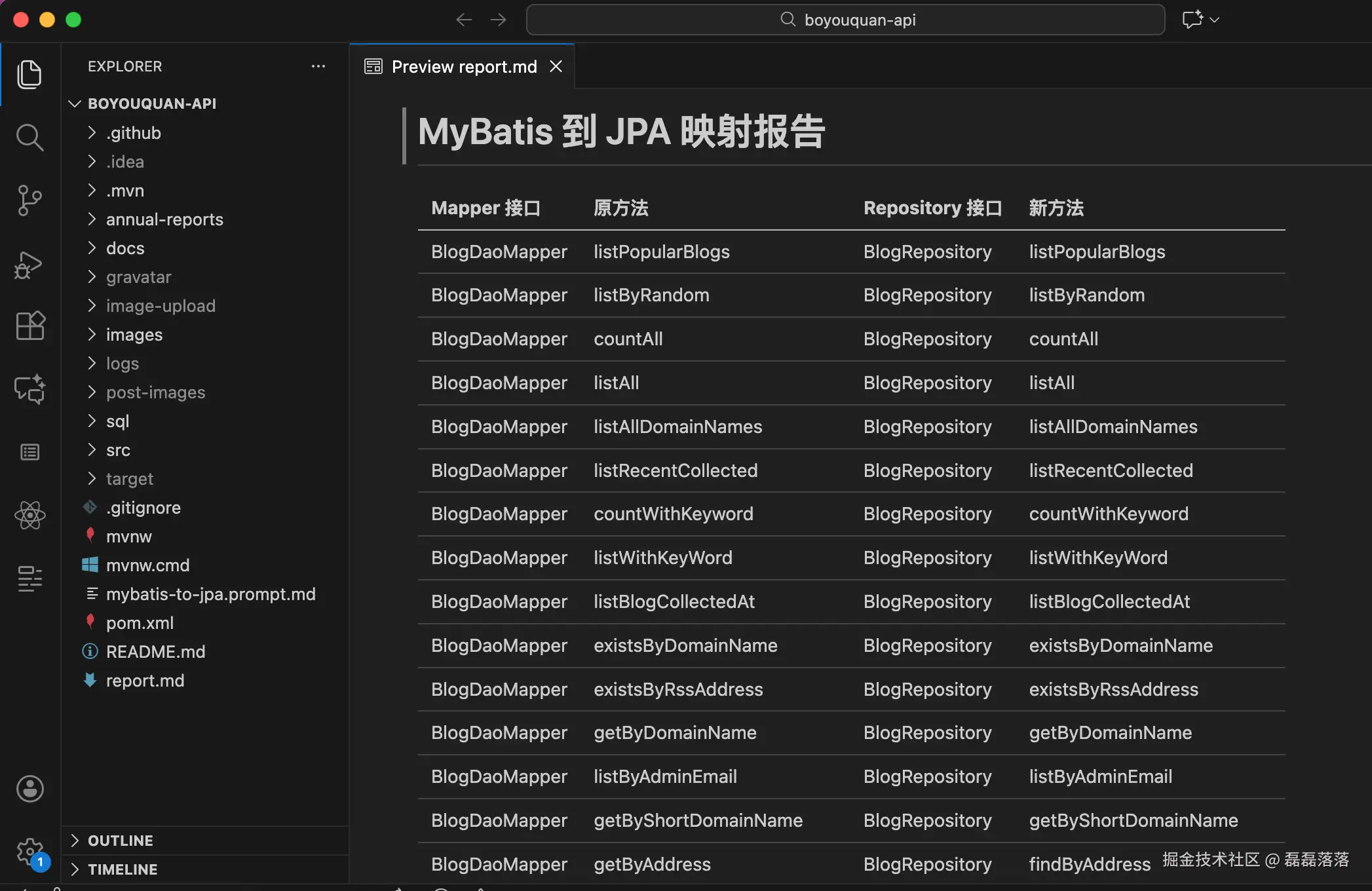
所有步骤完成后,请在项目根目录生成一个 `report.md` 报告文件,以表格的方式展示原始 Mapper 接口、原始 Mapper 接口中的方法、新生成的 Repository 、新生成的 Repository 中的方法的对应关系。
示例:
| Mapper 接口 | 原方法 | Repository 接口 | 新方法 |
| ------------- | ------------ | --------------- | ------------- |
| BlogDaoMapper | getByAddress | BlogRepository | findByAddress |可以看到,对比上一小节的常规提示词,优化后的提示词按照「五个原则」做了拆分任务、明确方向、提供范例等多个方面的调整,这样使得任务更具体、步骤更详细、要求更明确。
在 VS Code 中打开并执行包含上述提示词的 mybatis-to-jpa.prompt.md 文件后,AI 助手的完成质量有了明显的提升,对于之前常规提示词的结果所存在的几个问题也都没有了。
3 小结
综上,本文首先介绍了提示词与提示工程的概念;接着介绍了「编写提示词需要遵循的五个原则」;最后以「MyBatis 转 JPA」为例,演示了对「五个原则」的运用。
总的来说,这「五个原则」对于我们在日常工作中指派 AI 助手做任务时是非常有价值的。
参考资料
1 Book: Prompt Engineering for Generative AI by James Phoenix and Mike Taylor (O'Reilly) - www.oreilly.com/library/vie...
2 Saxifrage Blog: Prompt Engineering, from Words to Art and Copy - www.saxifrage.xyz/post/prompt...
3 OpenAI: Prompt engineering - platform.openai.com/docs/guides...