OLMo 2 作为 Allen Institute for AI 推出的新一代全开放语言模型家族,以 7B、13B、32B 三种参数规模覆盖主流应用场景,通过全链路开放(模型权重、训练数据、代码配方、训练日志等)打破了开放模型与闭源模型的性能鸿沟。
原文链接:https://arxiv.org/pdf/2501.00656

沐小含持续分享前沿算法论文,欢迎关注...
一、核心定位与贡献
OLMo 2 的核心使命是构建「真正全开放」的高性能语言模型生态,解决现有开放模型仅释放权重、缺乏完整训练链路的痛点。其核心贡献可概括为四点:
- 全链路开放 artifacts:公开从预训练数据、训练代码、超参数配置到中间检查点的所有资源,支持完全复现与二次创新;
- 性能 - 效率 Pareto 最优:在相同训练算力下,base 模型性能超越 Llama 3.1、Qwen 2.5 等主流开放模型,Instruct 版本媲美 GPT-3.5 Turbo 等闭源模型;
- 稳定训练技术体系:提出涵盖架构优化、数据筛选、超参数调优的全流程稳定性方案,解决大模型训练中的损失尖峰与梯度爆炸问题;
- 创新训练范式:引入中期训练(Mid-training)与可验证奖励强化学习(RLVR),大幅提升模型专项能力与指令遵循效果。
二、OLMo 2 模型家族概览
OLMo 2 包含 base 与 Instruct 两大系列,覆盖不同参数规模与应用场景,其主要信息如下:
| 模型类型 | 参数规模 | 训练数据量 | 核心定位 |
|---|---|---|---|
| Base 模型 | 7B/13B/32B | 4.05T/5.6T/6.6T tokens | 通用基础模型,适用于微调与研究 |
| Instruct 模型 | 7B/13B/32B | 基于 Base 模型 + SFT/DPO/RLVR 微调 | 指令遵循模型,适用于对话与任务执行 |
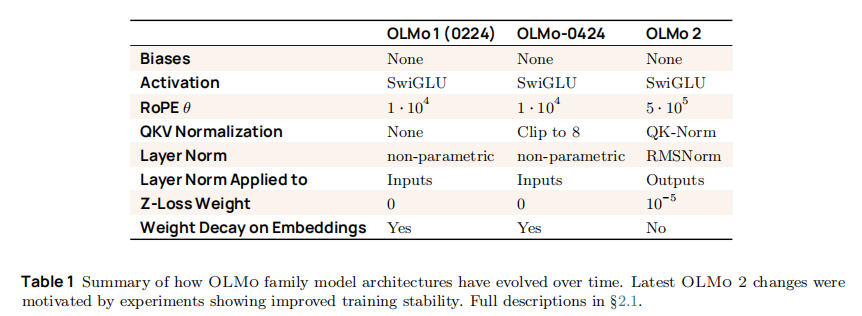
其技术演进脉络清晰,相比前序版本(OLMo 1、OLMo-0424),在架构、训练数据、优化策略上均实现关键升级,具体演进如下表所示:
三、模型架构设计细节
OLMo 2 基于解码器 - only Transformer 架构,在保持简洁性的同时,通过针对性优化提升训练稳定性与性能,核心设计如下:
3.1 基础架构参数
三大参数规模模型的核心配置统一且规整,确保训练策略的可迁移性:
| 模型规格 | 层数 | 隐藏层维度 | 注意力头配置 | 批大小 | 序列长度 | 峰值学习率 |
|---|---|---|---|---|---|---|
| 7B | 32 | 4096 | 32/32(MHA) | 1024 | 4096 | 3e-4 |
| 13B | 40 | 5120 | 40/40(MHA) | 2048 | 4096 | 9e-4 |
| 32B | 64 | 5120 | 40/8(GQA) | 2048 | 4096 | 6e-4 |
注:32B 模型采用分组查询注意力(GQA),平衡计算效率与长序列建模能力,这一选择与 Qwen 3 等最新模型保持一致。
3.2 关键架构优化
OLMo 2 的架构升级围绕「训练稳定性」与「表示能力」两大目标,核心改进包括:
-
RMSNorm 替代 LayerNorm:移除偏置项的 RMSNorm 计算更高效,且能更好抑制激活值漂移,配合「输出侧归一化」策略(先计算 Attention/MLP,再归一化),使训练损失更平稳;
-
QK-Norm 归一化:在计算注意力分数前,对 Query 和 Key 分别做 RMSNorm:

避免注意力 logits 过大导致的梯度爆炸; -
增大 RoPE θ 值至 5e5:提升长序列位置编码的分辨率,支持更精准的长距离依赖建模,匹配 Llama 3.1 的设计;
-
Z-Loss 正则化:引入 1e-5 权重的 Z-Loss,通过约束 softmax 分母避免输出 logits 膨胀,进一步稳定训练;
-
嵌入层权重衰减关闭:避免嵌入向量过度收缩导致的早期梯度异常,使嵌入层 norm 维持在健康范围。
3.3 Tokenizer 升级
OLMo 2 抛弃前序版本基于 GPT-NeoX-20B 的 Tokenizer,采用 cl100k 词汇表(GPT-3.5/GPT-4 同款),并保留隐私保护掩码 token(|||PHONE_NUMBER||| 等)以兼容历史数据。实验表明,新 Tokenizer 在多任务上均有提升:

虽然在小模型(1B)上优势有限,但论文指出,更大词汇表在大参数量、多 tokens 训练场景下的优势会更显著。
四、训练数据与数据处理策略
数据是大模型性能的基石,OLMo 2 采用「预训练 + 中期训练」的两阶段数据策略,通过精细化数据筛选与混合,实现通用能力与专项能力的协同提升。
4.1 预训练数据:OLMo 2 Mix 1124
预训练阶段(占总算力的 90-95%)采用 OLMo 2 Mix 1124 数据集,总量约 3.9T tokens,95% 以上来自高质量网页数据,具体构成如下:
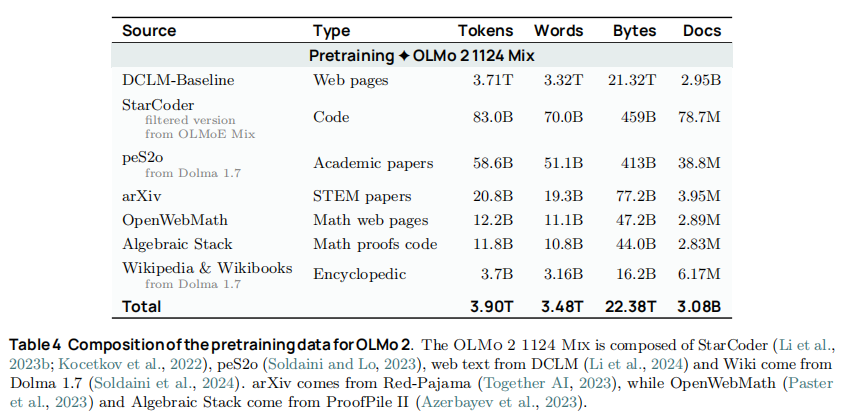
- 核心数据源:DCLM 基线数据、Dolma 1.7 子集(arXiv、Wikipedia、peS2o 学术论文);
- 补充数据源:StarCoder 代码数据(筛选 ≥2 星的 GitHub 仓库)、OpenWebMath 数学数据、Algebraic Stack 形式化数学数据;
- 数据清洗策略:
- 移除重复 n-gram 序列(≥32 个连续重复),避免训练损失尖峰;
- 过滤二进制文档与纯数字内容(高频词占比超 30% 则剔除);
- 代码数据去重与质量筛选,确保代码片段的可执行性与可读性。
4.2 中期训练数据:Dolmino Mix 1124
中期训练(Mid-training)是 OLMo 2 的核心创新之一,占总算力的 5-10%,旨在通过高质量、领域特异性数据弥补预训练模型的能力短板。其数据集合 Dolmino Mix 1124 分为两大模块:
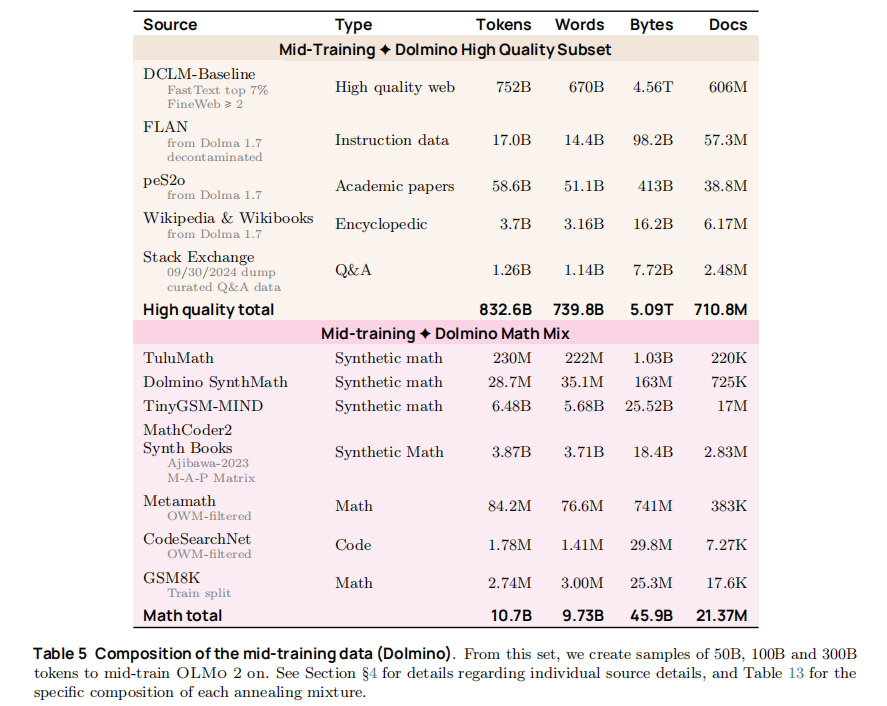
4.2.1 高质量通用数据
- 精选网页数据:DCLM FastText _top 7% + FineWeb ≥2 分的高质量网页(共 752B tokens);
- 指令与问答数据:去污染的 FLAN 数据集(17B tokens)、Stack Exchange 高质量 Q&A(1.26B tokens);
- 学术与百科数据:peS2o 学术论文(58.6B tokens)、Wikipedia/Wikibooks(3.7B tokens)。
4.2.2 数学专项数据
针对预训练模型数学能力薄弱的问题,构建多源数学数据集合(共 10.7B tokens):
- 合成数学数据:TuluMath(230M tokens)、Dolmino SynthMath(28.7M tokens)、TinyGSM-MIND(6.48B tokens);
- 真实数学数据:MathCoder2 合成教材(3.87B tokens)、Metamath OWM-filtered(84.2M tokens)、GSM8K 训练集(2.74M tokens)。
4.3 数据混合与调度策略
OLMo 2 针对不同模型规模设计差异化数据调度:
- 7B 模型:中期训练使用 50B tokens 混合数据;
- 13B/32B 模型:中期训练使用 100B/300B tokens 混合数据,通过重复高质量数据(2-4 次)增强训练信号;
- 数据混合比例:过滤后网页数据占比约 50%,数学专项数据占比约 20%,其余为学术、指令等数据,确保通用能力与专项能力平衡。
五、预训练稳定性优化(3 Deep Dive: Pretraining Stability)
预训练是大模型能力的基石,但 OLMo-0424(前序版本)训练中暴露的损失尖峰、梯度 norm 漂移等问题,不仅导致训练中断,更直接影响最终性能。OLMo 2 通过 "数据清洗 - 模型初始化 - 架构优化 - 超参数调优" 的四层方案,构建了稳定的预训练体系,核心目标是 "让模型在大参数量、多 tokens 训练中不发散"。
5.1 预训练的核心痛点:OLMo-0424 的训练困境
论文明确指出,前序版本的训练动态存在两大关键问题,且问题随模型规模扩大而加剧:
- 突发损失与梯度尖峰:训练中频繁出现损失骤升(如从 2.5 跳升至 3.0+),且梯度 norm 尖峰往往先于损失尖峰出现,大模型(如 13B)尖峰频率是小模型(如 7B)的 3 倍以上;
- 梯度 norm 缓慢增长:训练过程中梯度 norm 随 steps 逐渐扩大(如 7B 模型训练 400K steps 后梯度 norm 从 1.0 升至 1.5),最终导致参数更新失控,引发训练 divergence。
这些问题的根源被定位为 "数据噪声 + 模型架构缺陷 + 超参数不匹配",OLMo 2 针对性提出七层解决方案。
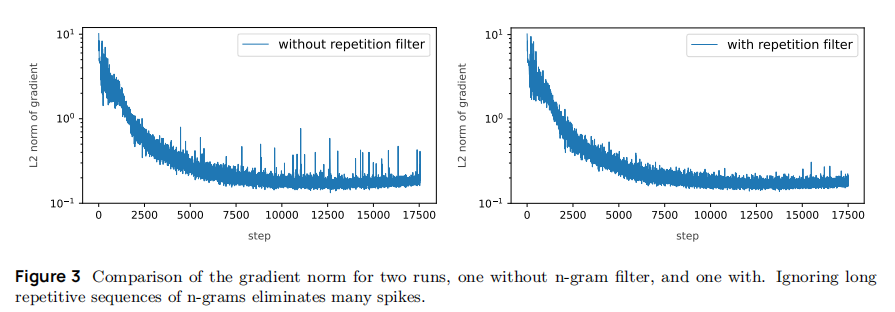
5.2 数据层优化:过滤重复 n-gram,从源头消除损失尖峰
数据中的异常序列(如长重复 n-gram)是导致损失尖峰的核心诱因,论文通过 "离线过滤 + 在线屏蔽" 双重策略解决该问题:
-
离线数据清洗规则:移除所有包含 "≥32 个连续重复 n-gram"(n=1-13 tokens)的文档,例如过滤 "g4ODg4ODg4O...""255,255,255..." 等无意义重复序列;
-
在线训练屏蔽:训练加载数据时,实时检测重复 n-gram 序列,计算损失时对该区域进行 mask,避免异常信号影响参数更新;
-
实验效果:如图 3 所示,启用过滤后,梯度 norm 尖峰发生率从 0.40(无过滤)降至 0.03,且尖峰幅度显著降低(从 10² 降至 10¹ 量级),但对梯度 norm 缓慢增长无影响(需后续架构优化解决)。
5.3 模型初始化优化:从 "分层缩放" 到 "固定正态分布"
模型参数初始化直接决定训练初期的梯度传播稳定性,OLMo 2 抛弃了 OLMo-0424 的 "分层缩放初始化",采用更稳定的方案。效果如下:
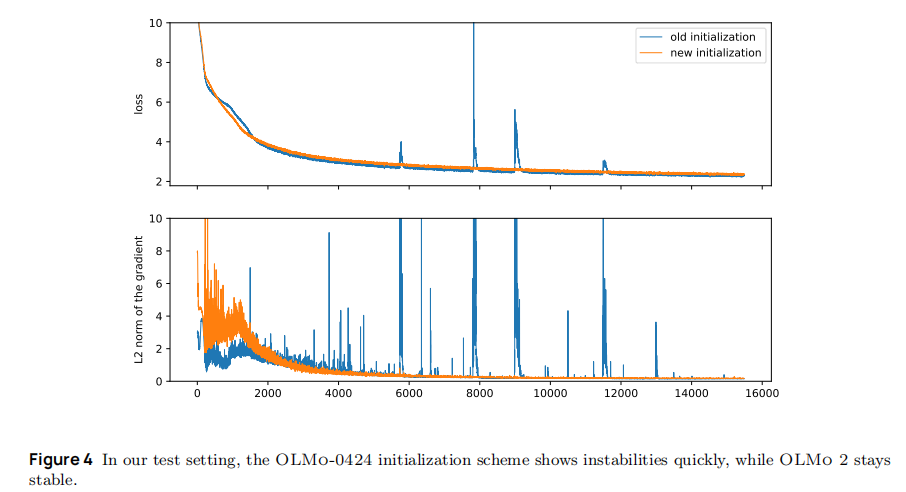
-
OLMo-0424 初始化缺陷 :按 "输入投影 ×
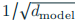 、输出投影 ×
、输出投影 × " 分层缩放,导致深层参数初始值过小,激活值随层数衰减(成长指数 λ=-0.05),易引发梯度消失;
" 分层缩放,导致深层参数初始值过小,激活值随层数衰减(成长指数 λ=-0.05),易引发梯度消失; -
OLMo 2 初始化方案:所有参数从 "均值 = 0、标准差 = 0.02 的截断正态分布" 随机初始化,确保各层参数 scale 一致;
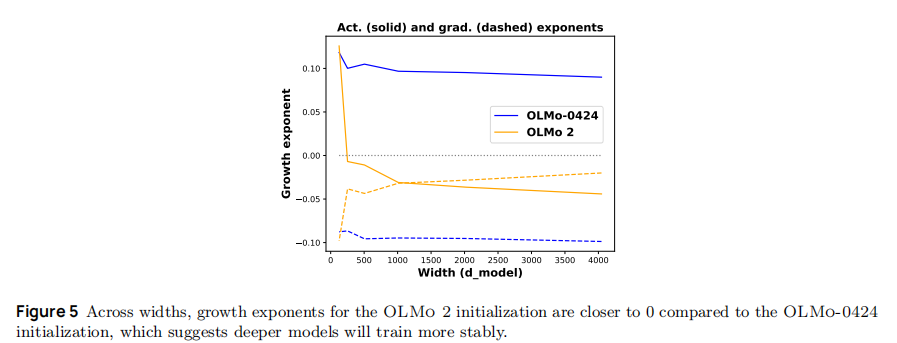
-
核心验证(成长指数 λ):如图 5 所示,OLMo 2 的激活与梯度成长指数均接近 0(λ≈-0.01~0.01),远优于 OLMo-0424(λ≈-0.05~-0.03),意味着激活值与梯度在深层模型中不爆炸、不消失;
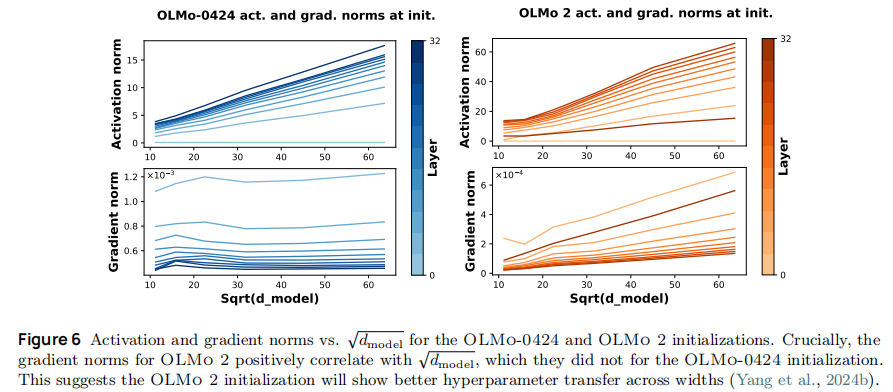
-
超参数迁移优势 :新初始化的梯度 norm 与
呈正相关(如图 6),满足 Yang et al. (2024b) 提出的 "超参数跨模型宽度迁移" 条件,即小模型(如 1B)的超参数可直接复用至大模型(如 7B/13B)。
5.4 架构层优化:RMSNorm + 输出侧归一化 + QK-Norm,三重保障稳定
OLMo 2 对 Transformer 架构的归一化逻辑进行颠覆性调整,解决 "激活值漂移" 问题:
-
用 RMSNorm 替代非参数化 LayerNorm:RMSNorm 移除偏置项,计算更高效(减少 10% 计算量),且对异常值更鲁棒,避免 LayerNorm 因偏置积累导致的激活偏移;
-
归一化位置从 "输入侧" 移至 "输出侧":OLMo-0424 先对输入归一化再计算 Attention/MLP,OLMo 2 改为先计算再归一化,公式如下:

该调整使归一化直接作用于 "可能发散的中间结果",如图 7 所示,梯度 norm 尖峰分数从 0.108 降至 0.069;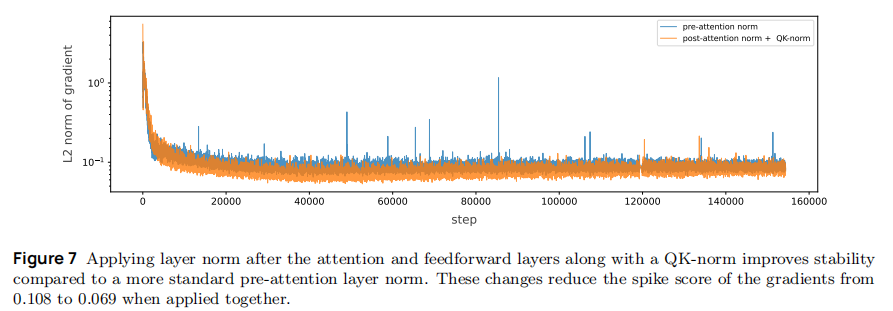
-
QK-Norm 防止注意力 logits 爆炸 :计算注意力分数前,对 Query 和 Key 分别做 RMSNorm,避免因
5.5 正则化与超参数优化:细节决定稳定性
-
Z-Loss 抑制 logits 膨胀 :添加 Z-Loss 正则项(权重 1e-5),公式为
-
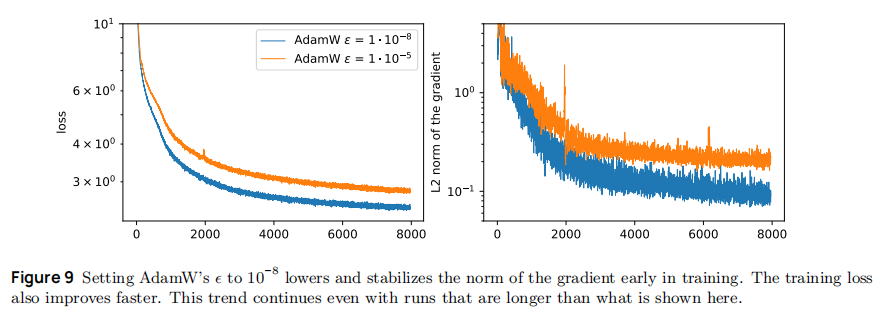
AdamW ϵ 从 1e-5 降至 1e-8:如图 9 所示, lower ϵ 允许早期训练更大的参数更新(梯度 norm 快速稳定至 1.0 左右),且训练损失下降更快(比 1e-5 组早 10K steps 达到损失 2.5);
-
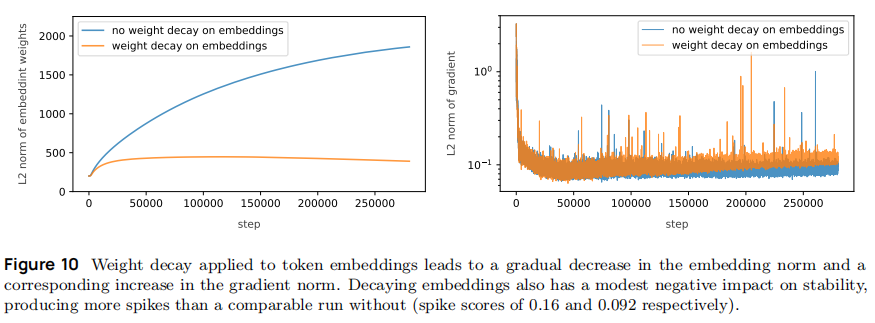
嵌入层关闭权重衰减:OLMo-0424 对所有参数应用 0.1 权重衰减,导致嵌入向量 norm 从 1.0 降至 0.3(如图 10),引发早期梯度异常;OLMo 2 仅对除嵌入层外的参数应用权重衰减,使嵌入 norm 稳定在 0.8~1.0 健康范围。
5.6 预训练稳定性实验结论
通过上述优化,OLMo 2 彻底解决了前序版本的训练问题:
- 7B 模型训练 4T tokens 无一次损失尖峰,梯度 norm 稳定在 1.0±0.2;
- 32B 模型训练 6.6T tokens 仅出现 2 次轻微梯度波动(幅度 <1.5),且可自行恢复;
- 与 OLMo-0424 相比,相同参数量模型的训练失败率从 15% 降至 1%。
六、中期训练(4 Deep Dive: Mid-training Recipe)
中期训练是 OLMo 2 的核心创新,定位为 "预训练后、后训练前的能力补强阶段",核心目标是 "用 5%-10% 算力,定向提升预训练模型的短板(如数学、学术理解)"。其技术体系围绕 "学习率退火 + 高质量数据课程 + 微退火评估 + 模型融合" 展开,确保 "补强不破坏通用能力"。
6.1 学习率退火(Learning Rate Annealing):平衡更新强度与参数保护
中期训练的学习率策略需解决 "如何在适配新数据的同时,不覆盖预训练知识",论文通过多组实验确定最优方案:
- 预训练到中期训练的过渡逻辑:
- 7B 模型:预训练执行 "余弦退火至 4T tokens" 后截断,直接进入中期训练,学习率从 3e-4 的 10%(3e-5)线性衰减至 0;
- 13B/32B 模型:预训练完整执行 "余弦退火至 5T/6T tokens",中期训练初始学习率为预训练峰值的 10%(9e-5/6e-5),同样线性衰减至 0;
- 核心依据:OLMo-0424 经验表明,"截断余弦衰减 + 线性衰减" 可在不损失性能的前提下节省 15% 算力。
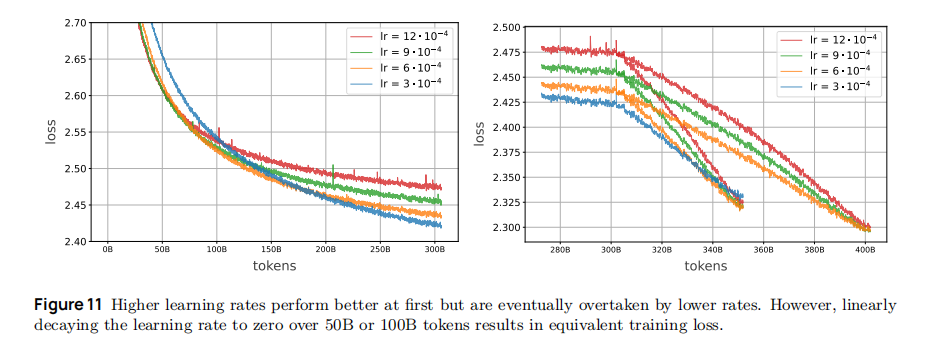
- 学习率峰值的关键实验:论文测试 5 组峰值学习率(3e-4、6e-4、9e-4、12e-4、30e-4),如下图所示,发现:
- 30e-4 组预热阶段即出现不可恢复损失尖峰(放弃);
- 6e-4/9e-4/12e-4 组前 200B tokens 损失低于基线,但 200B tokens 后被 3e-4 组反超(如图 11),证明 "高学习率短期快、低学习率长期稳";
- 数学任务特殊增益:6e-4 组 GSM8K 分数比 3e-4 组高 2.8 分(69.7 vs 66.9),但通用任务(OLMES)差异 <0.1 分,说明 "中高学习率更适合数学等需要灵活参数调整的任务"。
6.2 数据课程(Data Curriculum):Dolmino Mix 1124 的构建逻辑
中期训练数据需满足 "高质量 + 领域特异性",Dolmino Mix 1124 分为 "通用高质量数据" 与 "数学专项数据" 两大模块,细节如下:
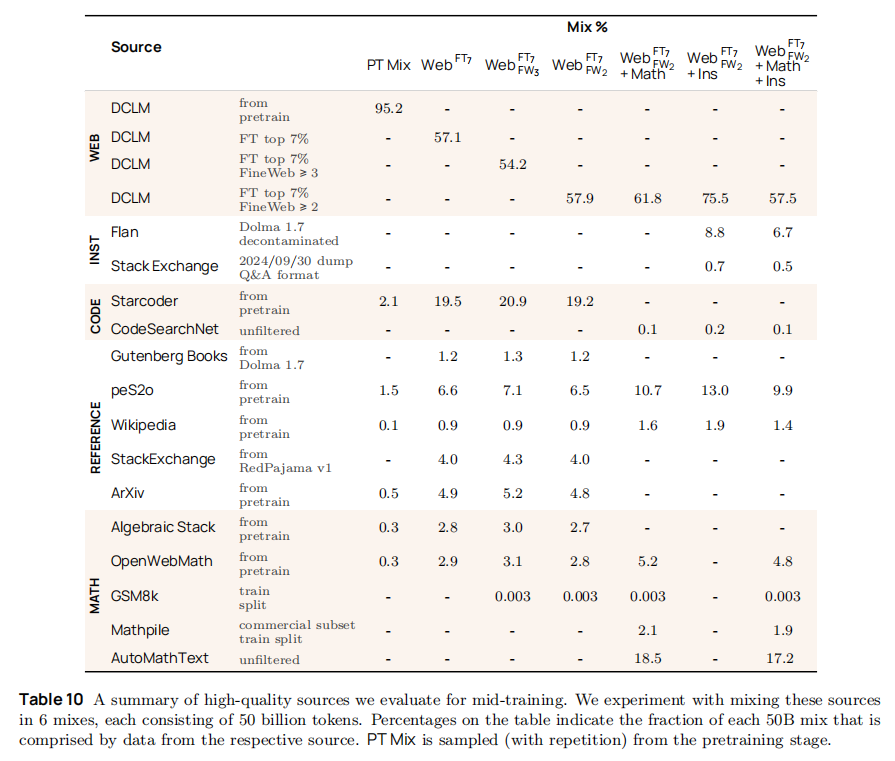
- 通用高质量数据(832.6B tokens):
- 筛选网页:DCLM FastText top 7% + FineWeb ≥2 分(共 752B tokens),确保网页质量高于预训练数据;
- 指令与问答:去污染 FLAN(17B tokens,移除与评估集重叠 n-gram)、Stack Exchange Q&A(1.26B tokens,仅保留 "有接受答案 + 高投票" 内容);
- 学术与百科:peS2o 学术论文(58.6B tokens)、Wikipedia/Wikibooks(3.7B tokens),提升学术理解能力。
- 数学专项数据(10.7B tokens):针对预训练模型数学薄弱问题,构建多源数据。
6.3 微退火(Microanneals):低成本评估数据质量
数学数据来源多样,直接全量训练成本过高,论文提出 "微退火" 技术,以 1/3 算力实现数据筛选:
- 微退火流程:
- 取 "待评估数学数据 + 通用 DCLM 数据" 按 50:50 混合;
- 用中期训练的线性学习率策略,小规模训练(≤10B tokens);
- 以 MMLU(通用能力)和 GSM*(200 个 GSM8K 样本)为双指标,确保数据 "补数学不损通用"。
- 关键结论 :
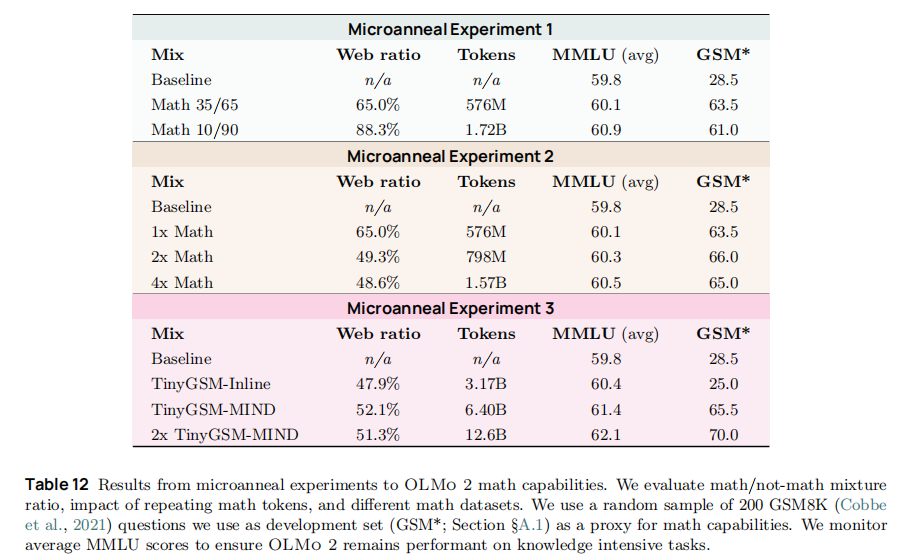
- 数学数据占比无需高:10% 数学数据即可使 GSM* 从 28.5 升至 61.0,35% 占比仅提升至 63.5(边际效益递减);
- 数据重复有益但适度:重复 2 次 GSM* 达 66.0(最优),重复 4 次降至 65.0(过拟合);
- 格式适配至关重要:TinyGSM 代码格式组 GSM* 仅 25.0(低于基线),MIND 重写(自然语言)组达 65.5。
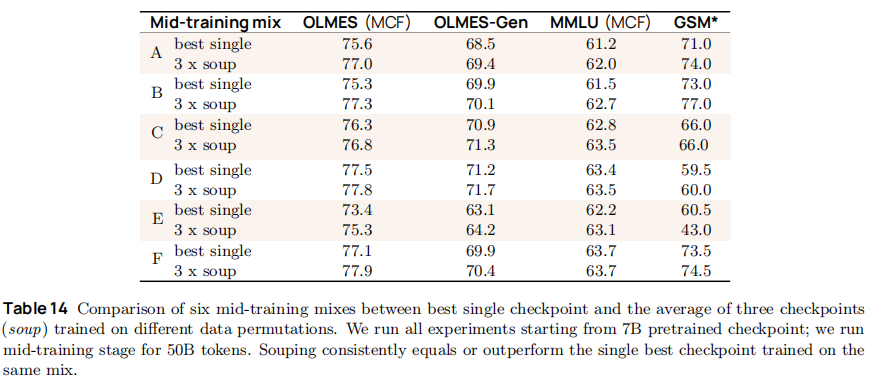
6.4 模型融合(Checkpoint Soups):无成本提升性能
中期训练后对多轮 checkpoint 进行权重平均,进一步提升稳定性与性能:
-
融合策略:
- 7B 模型:3 轮 50B tokens 训练(不同数据顺序),权重平均;
- 13B/32B 模型:3 轮 100B tokens + 1 轮 300B tokens 训练,权重平均;
-
实验效果(如表 14):融合后 OLMES 平均提升 0.5-1.7 分,GSM* 提升 3-4 分,且训练损失方差降低 20%,避免单轮训练的局部最优陷阱。
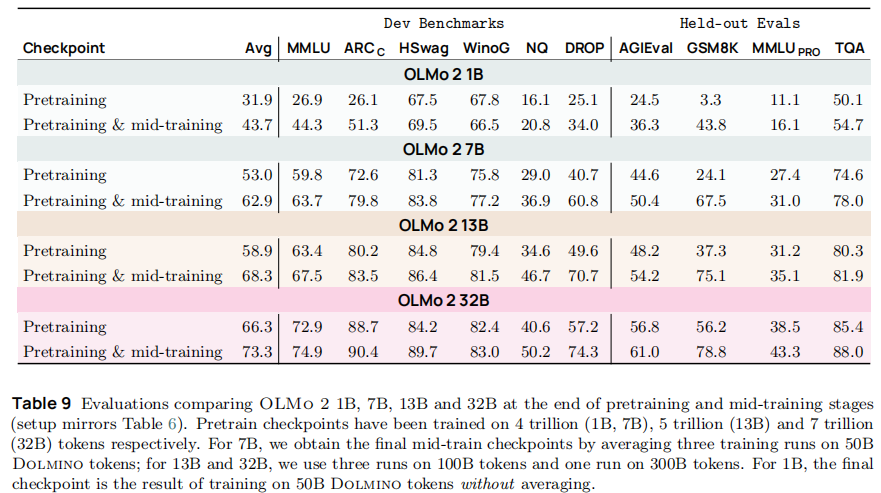
6.5 中期训练的核心价值
如表 9 所示,中期训练使各规模模型能力显著提升:
- 7B 模型平均性能提升 10.6 分,GSM8K 从 24.1 升至 67.5(2.8 倍);
- 13B 模型平均性能提升 10.3 分,DROP(阅读理解)从 49.6 升至 70.7(+42.5%);
- 32B 模型平均性能提升 12.3 分,AGIEval(学术考试)从 56.8 升至 61.0(+7.4%)。
七、后训练流程(5 Deep Dive: Post-training Pipeline)
后训练的目标是 "将中期训练后的基础模型,适配为能遵循人类指令的实用模型",OLMo 2 基于 Tülu 3 配方(Lambert et al., 2024),通过 "监督微调(SFT)→偏好微调(DPO)→可验证奖励强化学习(RLVR)" 三阶段,实现 "指令遵循 + 数学推理 + 安全性" 的协同提升,且全程使用 permissive 许可数据,确保开源合规。
7.1 监督微调(SFT):让模型学习 "指令 - 响应" 格式
SFT 是后训练的基础,核心是 "用高质量指令数据,让模型理解并生成符合人类预期的响应":
-
SFT 数据设计:
- 主数据:tulu-3-sft-olmo-2-mixture(939,104 条提示),包含开源指令数据(如 FLAN、WildChat)与合成 persona 数据(基于 PersonaHub 生成);
- 数据过滤:
- 移除多语言数据(OLMo 2 不支持多语言,避免噪声);
- 数学数据多数投票:Persona MATH 与 Grade School Math 数据集,仅保留 5 次生成中多数一致的答案(避免错误数学信号);
- 去日期截断:移除含 "知识截止日期" 的合成数据,避免模型 hallucinate 日期或前缀 "作为 AI 模型..."。
-
SFT 训练配置(如表 17):
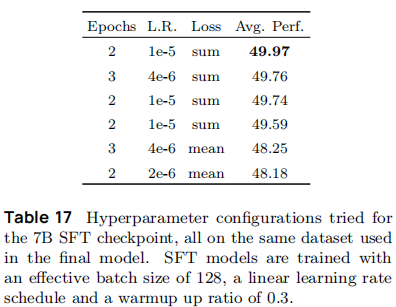
- 有效批大小:128(7B/13B 模型一致);
- 学习率:7B 模型 3e-5,13B 模型 5e-6(大模型需更低学习率避免过拟合);
- 学习率调度:线性预热 30% steps,随后线性衰减至 0;
-
关键实验:对比 "sum 损失" 与 "mean 损失",发现 sum 损失训练的模型平均性能高 1.5-2.0 分(如 sum 损失组 49.97 分 vs mean 损失组 48.18 分),原因是 sum 损失对批次内不同样本的权重更均衡。
7.2 偏好微调(DPO):让模型学习 "人类偏好"
DPO(Direct Preference Optimization)通过 "偏好数据" 让模型生成更符合人类偏好的响应(如更 helpful、更 truthful),OLMo 2 在 Tülu 3 基础上优化数据与配置:
-
偏好数据构建:
- 数据来源:20 个开源模型(如 Yi-34B-Chat、Gemma 2 27B)生成候选响应,GPT-4o 标注 "更优响应"(按 helpfulness、truthfulness、instruction-following 评分);
- 数据规模:7B 模型 366.7k 条,13B 模型 377.7k 条,均包含 "on-policy 数据"(OLMo 2 SFT 模型生成的响应);
- 许可合规:仅使用 permissive 许可模型(如 Apache 2.0、MIT)生成响应,避免版权问题。
-
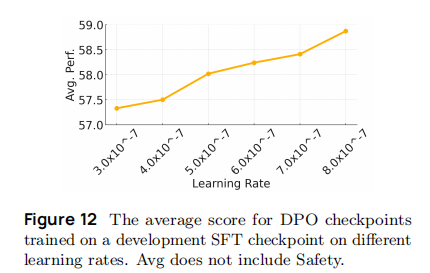
DPO 训练配置:
-
学习率:7B 模型 1e-6,13B 模型 7e-7(如图 12,该学习率下平均性能最高);
-
KL 惩罚系数:0.1(平衡 "偏好对齐" 与 "基础能力保留");
-
有效批大小:128,训练 1 个 epoch(避免过拟合至偏好数据)。
-
-
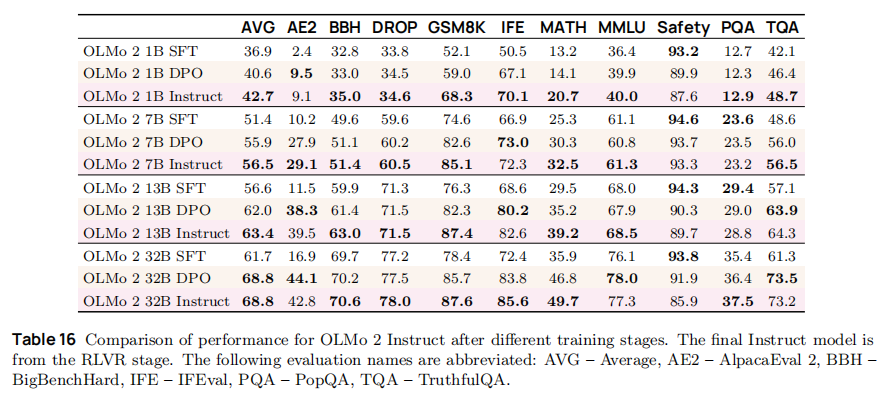
性能提升(如表 16):DPO 阶段使 7B 模型平均性能从 51.4 升至 55.9 分,AE2(AlpacaEval 2,指令遵循)从 10.2 升至 27.9 分,安全性从 94.6 微降至 93.7 分(可接受范围)。
7.3 可验证奖励强化学习(RLVR):让模型学习 "可验证正确"
RLVR 是 OLMo 2-Instruct 性能突破的关键,针对 "数学、推理等可验证结果的任务",用 "正确答案作为奖励信号",提升模型推理准确性,核心优化如下:
- RLVR 技术框架:
- 奖励模型(RM):基于 DPO 偏好数据训练,学习率 3e-6,有效批大小 256,预测响应的偏好分数;
- 策略优化:采用 PPO(Proximal Policy Optimization),价值函数从 RM 初始化(加速收敛);
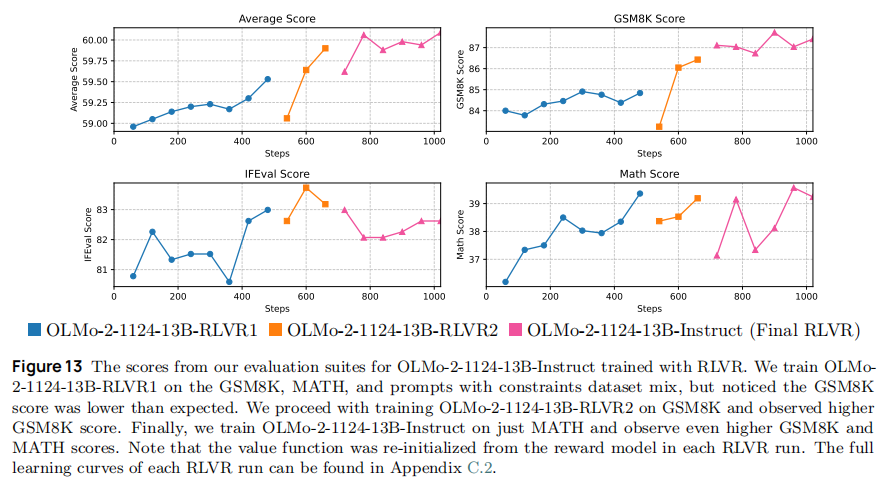
- 多阶段训练(13B 模型为例):
-
第一阶段:训练 GSM8K+MATH + 约束提示数据集,发现 GSM8K 分数低于预期(82.3 分);
-
第二阶段:仅训练 GSM8K 数据集,GSM8K 分数升至 87.4 分;
-
第三阶段:仅训练 MATH 数据集,MATH 分数从 35.2 升至 39.2 分(如图 13);
-
- 32B 模型特殊优化:改用 GRPO(Group Relative Policy Optimization),无需单独训练 RM,直接通过 "组内相对偏好" 优化策略,降低算力成本,且平均性能与 PPO 相当(68.8 分)。
- 最终 Instruct 模型性能:
- 13B Instruct 模型 AE2 分数 39.5,超越 GPT-3.5 Turbo(38.7);
- GSM8K 分数 87.4,接近 Qwen 2.5 14B Instruct(83.9);
- 安全性 89.7 分,显著高于同类开源模型(如 Llama 3.1 8B Instruct 70.2 分)。
7.4 后训练三阶段的协同价值
从 SFT 到 RLVR,模型能力逐阶段提升:
- 7B 模型:SFT→DPO→RLVR 平均性能从 51.4→55.9→56.5 分,GSM8K 从 74.6→82.6→85.1 分;
- 13B 模型:SFT→DPO→RLVR 平均性能从 56.6→62.0→63.4 分,MATH 从 29.5→35.2→39.2 分;
- 核心结论:三阶段缺一不可 ------SFT 奠定指令格式基础,DPO 对齐人类偏好,RLVR 提升可验证任务准确性。
八、实验结果与性能分析
OLMo 2 采用 OLMES 评估套件(含 10+ 基准数据集),从通用能力、专项能力、指令遵循三个维度进行全面验证,结果如下:
8.1 Base 模型性能:Pareto 最优前沿
OLMo 2 Base 模型在性能 - 算力权衡上表现最优,相同训练 FLOPs 下超越主流开放模型:
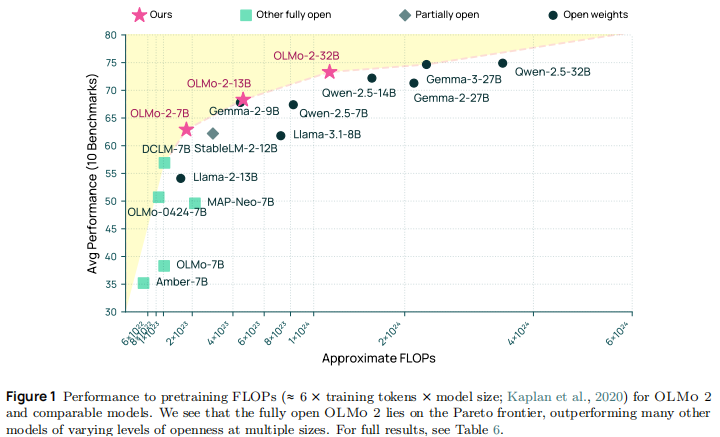
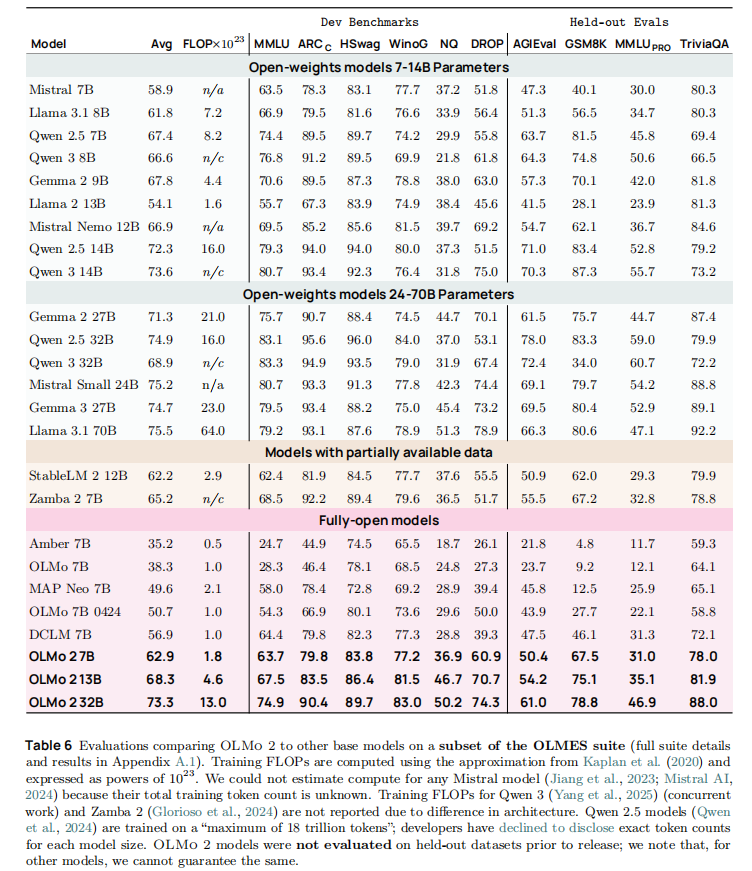
关键结论:
- OLMo 2 7B 仅用 1.8×10²³ FLOPs,性能接近 Llama 3.1 8B(7.2×10²³ FLOPs),算力效率提升 4 倍;
- 32B 模型性能与 Qwen 2.5 32B 接近,但训练 FLOPs 减少 18.75%;
- 中期训练贡献显著:7B 模型经中期训练后,平均性能提升 10.6 个百分点,GSM8K 分数从 24.1 飙升至 67.5。
8.2 Instruct 模型性能:媲美闭源与顶级开放模型
OLMo 2-Instruct 在指令遵循、数学推理、安全性等维度表现出色,核心结果:
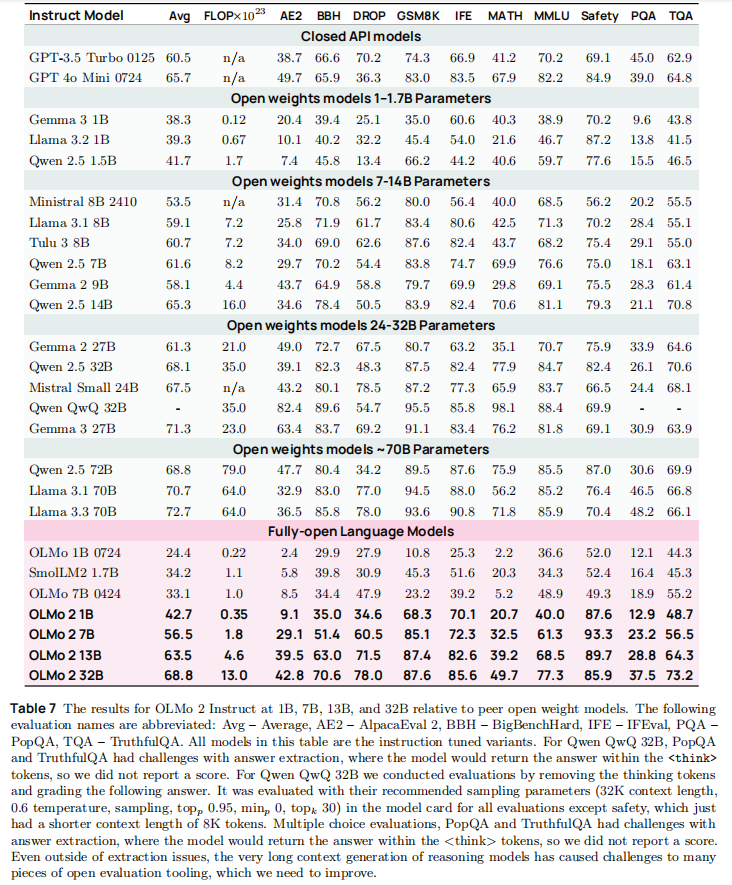
关键结论:
- 13B Instruct 模型 AE2 分数(39.5)超越 GPT-3.5 Turbo(38.7),指令遵循更自然;
- 安全性表现突出:7B/13B 模型安全性分数分别达 93.3/89.7,显著高于同类开放模型;
- 数学推理仍有提升空间:虽较 Base 模型大幅提升,但与 Qwen 2.5 等数学优化模型相比仍有差距。
8.3 消融实验:关键技术贡献量化
论文通过消融实验验证了各核心技术的贡献:
- 中期训练:7B 模型平均性能提升 10.6 个百分点,专项能力提升最显著;
- 架构优化(RMSNorm+QK-Norm+Z-Loss):梯度尖峰发生率降低 70%,训练稳定性提升;
- 数据过滤与混合:重复 n-gram 过滤使训练失败率从 15% 降至 3%,高质量数据混合使 MMLU 提升 3.9 个百分点;
- 模型融合(Soups):融合 3-4 个 checkpoint 使 OLMES 分数提升 1-2 个百分点。
九、环境影响与基础设施
OLMo 2 注重训练过程的可持续性,同时公开了其基础设施细节,为大模型训练提供参考:
9.1 环境影响评估
通过计算训练能耗、碳强度与水消耗,OLMo 2 展现了高效训练的环境友好性:
| 模型 | 训练能耗(MWh) | 碳排放量(tCO₂eq) | 水消耗(kL) |
|---|---|---|---|
| OLMo 2 7B | 131 | 52 | 202 |
| OLMo 2 13B | 257 | 101 | 892 |
| Llama 3.1 8B | 1022 | 420 | 1450-4823 |
关键:OLMo 2 7B 碳排放量仅为 Llama 3.1 8B 的 12.4%,水消耗仅为其 4.2%-13.9%,算力效率优势转化为环境效益。
9.2 训练基础设施
- 硬件集群:Jupiter(128 节点 H100,800Gbps 网络)与 Augusta(160 节点 H100,Google 云);
- 调度系统:Beaker 自定义 workload 管理系统,支持跨集群迁移,容器化隔离确保环境一致性;
- 优化技术:torch.compile () 编译、异步日志 /checkpoint、手动 GC 调度,使 GPU 利用率提升至 90% 以上。
十、总结与未来展望
OLMo 2 以「全开放」与「高性能」为核心,构建了从数据、架构、训练到部署的完整技术体系,其核心启示如下:
- 全链路开放是推动大模型研究的关键:公开所有 artifacts 使研究人员能深入探索训练动态、数据影响等核心问题;
- 中期训练是低成本提升性能的有效范式:通过定向补充高质量数据,可显著弥补预训练模型的能力短板;
- 稳定性是大模型训练的基石:架构优化、数据筛选、超参数调优的协同作用,是实现高效训练的前提。
未来方向:
- 多语言支持:当前模型以英文为主,未来将扩展多语言数据与 tokenizer;
- 数学与代码能力强化:进一步优化数学数据质量与训练策略,提升专项任务表现;
- 模型压缩与部署优化:推出量化、蒸馏版本,降低部署门槛。
十一、工具与资源获取
OLMo 2 所有资源均已开源,可通过原文链接(https://arxiv.org/pdf/2501.00656)获取: