⚠️ 免责声明 本文仅用于网络安全技术交流与学术研究。文中涉及的技术、代码和工具仅供安全从业者在获得合法授权的测试环境中使用。任何未经授权的攻击行为均属违法,读者需自行承担因不当使用本文内容而产生的一切法律责任。技术无罪,请将其用于正途。干网安,请记住,"虽小必牢"(虽然你犯的事很小,但你肯定会坐牢)。
终端安全(EDR):用深度学习识别未知勒索软件
你好,我是陈涉川,欢迎你来到我的专栏 。本文是整个专栏中极具"暴力美学"的一章。我们将离开相对宏观的网络流量层,潜入操作系统的内核深处。在这里,没有 IP 地址,没有 HTTP 协议,只有寄存器、堆栈和数以亿计的 API 调用。
如果说前两篇是在城墙上巡逻的哨兵(IDS)和在作战室分析情报的参谋(SOC),那么这一篇就是贴身肉搏的禁卫军。因为一旦勒索软件绕过了防火墙,终端(Endpoint)就是最后一道防线。一旦失守,数据即变为乱码,那将是不可逆转的毁灭。
我们将深入探讨勒索软件的本质、传统 AV 的溃败,以及如何用计算机视觉(CNN)和序列分析(LSTM)来捕捉这些数字幽灵。
引言:从特征匹配到认知智能的范式转移
在网络安全的防御纵深中,终端(Endpoint)始终承受着最大的压力。随着勒索软件即服务(RaaS)的兴起和高级持续性威胁(APT)技术的下沉,传统的基于签名(Signature-based)和启发式(Heuristic)的防御手段已面临严峻挑战。当攻击者利用多态代码混淆视听,利用"鉴白"工具(LotL)潜行渗透时,防御者必须寻求新的维度。
本章将通过深度学习(Deep Learning)的透镜,重新审视终端安全。我们不再仅仅依赖于匹配已知的"恶",而是试图赋予计算机一种类人的"认知能力":通过卷积神经网络(CNN)去"看"二进制文件的结构纹理,通过长短期记忆网络(LSTM)和 Transformer 去"读"API 调用的上下文语义,甚至通过强化学习(DRL)去"学"会如何在毫秒级生杀予夺。这是一场从"特征匹配"到"行为认知"的范式转移,也是构建下一代智能 EDR(Endpoint Detection and Response)的必经之路。
1. 最后的防线:当"城墙"失效之后
在专栏的前几章,我们在网关处部署了自编码器,在 SOC 里部署了图神经网络。这听起来固若金汤。然而,现实是残酷的:防御是面,攻击是点。 黑客只需要找到一个漏洞(比如一封精心构造的钓鱼邮件,或者一个未修补的浏览器 0-day),就能绕过所有网络层的防御,直接在 CEO 的笔记本电脑上通过 PowerShell 执行代码。
此时,网络流量看起来是加密且正常的(HTTPS),SOC 的关联规则还没来得及触发。
在 CPU 的指令周期里,一场屠杀正在酝酿。
1.1 勒索软件:不只是病毒,是商业模式
勒索软件是图灵遗产中长出的最恶毒的果实。它利用了计算机科学中最强大的武器------密码学,反过来对付人类。
- 不可逆性: 不同于窃密木马,勒索软件一旦完成加密,除了支付赎金或拥有量子计算机,别无他法。
- RaaS(Ransomware-as-a-Service): 现在的攻击者不需要懂技术,只需要在暗网租用勒索软件平台,这导致了变种数量的指数级爆炸。
- 双重勒索: 不仅加密数据,还威胁公开数据。
1.2 传统杀毒软件(AV)的墓志铭
如果你还在依赖基于特征库(Signature-based)的杀毒软件,那你实际上是在"裸奔"。
传统的 AV 引擎工作原理是:
- 提取文件哈希(MD5/SHA256)。
- 在黑名单数据库中比对。
- 如果匹配,则查杀。
图灵的嘲笑: 黑客只需修改源代码中的一个变量名,或者加一层"壳"(Packer),文件的哈希值就会彻底改变。这叫做多态(Polymorphism)。现代勒索软件(如 LockBit, Conti)在每次感染时都会动态生成不同的二进制文件。
面对每天新产生的 50 万个恶意样本,基于黑名单的防御在数学上已经宣告死亡。
我们需要一种新的防御逻辑:不要看它长什么样(静态特征),要看它干了什么(动态行为)。
2. 数据源的革命:从静态文件到 API 调用流
要用 AI 抓坏人,首先要决定"喂"给 AI 什么数据。
在终端层,最有价值的数据不是硬盘上的文件(那是尸体),而是内存中正在执行的 API 调用(System Calls / API Calls)。
2.1 API:操作系统的语言
Windows 操作系统通过 API(Application Programming Interface)与应用程序交互。勒索软件要加密文件,必须"请求"操作系统。
这一系列请求构成了一种语言:
- 正常记事本进程:OpenFile -> ReadFile -> ShowUI -> CloseFile
- 勒索软件进程:FindFirstFile -> OpenFile -> ReadFile -> CryptEncrypt -> WriteFile -> DeleteFile
不管勒索软件怎么加壳、混淆、变形,它为了实现"加密文件"这个目的,必须 调用加密 API 和文件写入 API。这是它的行为指纹,是无法伪装的。
2.2 数据的获取:钩子(Hooking)与内核探针
在构建 EDR 数据集时,我们需要在系统底层埋下探针。
- User-mode Hooking: 拦截 kernel32.dll 或 ntdll.dll。容易被高级黑客绕过(Un-hooking)。
- **Kernel-mode Callbacks:**现代 EDR 更多依赖操作系统提供的标准回调(如 PsSetCreateProcessNotifyRoutine 监控进程创建)和微过滤器驱动(Minifilter,监控文件 I/O)。此外,ETW(Event Tracing for Windows)特别是其中的 Microsoft-Windows-Threat-Intelligence 供给者,已成为无感知捕获系统行为的主流方式。这是 EDR 的黄金标准,能够捕获最真实的系统行为。
3. 静态分析的进阶:让 AI "看见"恶意软件(CNN)
虽然动态行为是王道,但静态分析速度快,可以在文件落地(Drop)的瞬间进行初筛。深度学习为静态分析引入了全新的视角:计算机视觉。
3.1 二进制图像化(Malware Visualization)
任何文件本质上都是一串 0 和 1。我们可以将这串二进制流映射为一张灰度图片。
- 映射规则: 每 8 位(1 Byte)代表一个像素点的灰度值(0-255)。
- 宽度固定: 根据文件大小设定固定的图像宽度(例如 256 像素)。
当你这样做时,神奇的事情发生了:
- 代码段(.text): 看起来像细密的沙粒(高熵)。
- 数据段(.data): 看起来像平滑的条纹。
- 资源段(.rsrc): 如果包含图标或图片,甚至能隐约看到轮廓。
勒索软件的纹理: 同一个家族的勒索软件,即使哈希值不同,其"图像纹理"往往惊人地相似。加壳软件则会表现出极高熵值的"雪花点"区域。
3.2 卷积神经网络(CNN)的降维打击
一旦转化为图像,分类恶意软件就变成了分类"猫和狗"的问题。我们可以直接迁移 ResNet 或 VGG 等成熟的 CNN 架构。
模型架构设计:
- 输入层: N \times N 的灰度图像(恶意软件二进制图)。
- 卷积层(Convolution): 提取局部特征(如特定的代码片段纹理、加壳算法产生的特定噪声模式)。
- 池化层(Pooling): 降维,保持空间不变性(Shift Invariance)。即使攻击者在代码中插入了一些无用的指令(Padding),导致恶意代码段平移,CNN 依然能识别出核心纹理。
- 全连接层(FC): 输出分类概率(正常软件 / LockBit / WannaCry)。
数学视角:
CNN 学习的是非线性的特征映射函数 f(x),它能够捕捉到人类逆向工程师难以言喻的"代码风格"。
y = \text{Softmax}(W \cdot \text{ReLU}(\text{Conv}(x)) + b)
实战价值:
这种方法对于识别已知家族的变种极其有效。只要变种是基于同一套源代码编译的,其二进制纹理就会保留。
4. 动态分析的核心:API 序列与 LSTM
静态分析的弱点在于"加壳"和"加密载荷"。如果恶意代码在硬盘上是加密的,只有运行到内存中才解密,那 CNN 看到的就是一团随机噪声。
这时,我们需要动态分析。我们需要监听进程的"心跳"------API 调用序列。
4.1 将 API 视为自然语言(NLP)
如果我们将每一个 API 函数名(如 CreateFileW)看作一个单词(Word) ,那么一个进程的执行轨迹就是一个句子(Sentence)。
勒索软件的执行轨迹,就是一篇描述"如何绑架用户数据"的文章。
这意味着,我们可以直接借用自然语言处理(NLP)领域的重武器。
4.2 嵌入层(Embedding):API 的语义空间
计算机无法直接理解 CreateFileW 这样的字符串。我们需要将其转化为向量。
使用 Word2Vec 或 FastText 算法,在大规模的正常软件和恶意软件 API 序列上进行预训练。
训练后,我们会得到一个高维向量空间(Vector Space)。
在这个空间里:
- WriteFile 和 NtWriteFile 的距离非常近(语义相似)。
- SocketConnect 和 HttpSendRequest 的距离非常近。
- CryptEncrypt(加密)和 MessageBox(弹窗)的距离则较远。
这一步至关重要。它让 AI 理解了 API 之间的功能关联性。
4.3 循环神经网络(RNN)与长短期记忆(LSTM)
普通的神经网络(DNN)无法处理序列数据,因为它没有"记忆"。它不知道当前的 WriteFile 是因为用户在保存文档,还是勒索软件在覆写数据。这取决于上下文------即前 100 个 API 调用了什么。
LSTM(Long Short-Term Memory) 是处理此类问题的标准架构。
LSTM 单元拥有三个门控机制:
- 遗忘门(Forget Gate): 决定遗忘多少之前的状态。
- 输入门(Input Gate): 决定吸纳多少当前输入的信息。
- 输出门(Output Gate): 决定输出什么状态。
勒索软件检测的 LSTM 逻辑:
假设输入序列为:
x_1: FindFirstFile (遍历文件)
x_2: OpenFile (打开文件)
x_3: ReadFile (读取内容)
...
x_{t}: CryptEncrypt (加密内容)
当 LSTM 读到 x_t (CryptEncrypt) 时,单纯看这一个操作也许是正常的(如浏览器访问 HTTPS)。
但 LSTM 的细胞状态(Cell State) C_{t-1} 中保留了之前的记忆:"刚才已经进行了密集的 FindFirstFile 和 ReadFile 操作"。
这种上下文的累积 ,使得模型能够判定:"遍历+读取+加密 = 勒索行为"。
4.4 为什么 LSTM 优于 N-gram?
在深度学习普及前,业界常用 N-gram(如 3-gram)统计短序列出现的频率。
- N-gram 只能看 3 个词的窗口,视野极短。
- LSTM 可以捕捉长距离依赖(Long-term Dependencies) 。
- 有些勒索软件非常狡猾,它会先遍历文件列表(Step 1),然后休眠 10 分钟或执行一些无关注册表操作(Step 2),最后再开始加密(Step 3)。
- N-gram 会忽略 Step 1 和 Step 3 的联系。
- LSTM 能够跨越 Step 2 的噪声,将 Step 1 和 Step 3 关联起来,识别出攻击意图。
3.3 孪生网络(Siamese Networks):解决"第一眼"识别难题
传统的 CNN 分类器(如 ResNet)有一个致命缺陷:它需要成千上万个样本来训练每一个类别。然而,当一个新的勒索软件家族(如某天的 LockBit 4.0)刚刚爆发时,我们手头可能只有 1 个样本。这时候,普通的深度学习模型是瞎的。
为了解决小样本学习(Few-Shot Learning)的问题,我们需要引入孪生网络(Siamese Networks)。
- 核心逻辑:
我们要训练的不是"这是 LockBit 吗?",而是"样本 A 和样本 B 是同一个家族吗?"。
孪生网络包含两个结构完全共享权重(Shared Weights)的 CNN。我们将两个文件(一个是已知的恶意样本,一个是未知的可疑文件)同时输入网络。
- 度量学习(Metric Learning):
网络不再输出分类概率,而是输出两个特征向量之间的欧氏距离。
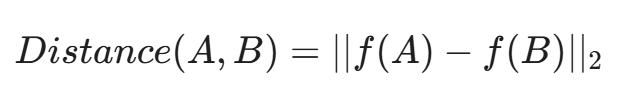
- 对比损失(Contrastive Loss):
- 如果 A 和 B 属于同一家族,损失函数会强迫它们的特征向量距离趋近于 0。
- 如果 A 和 B 不同,损失函数会推远它们的距离。
- 实战意义:
这种方法赋予了 EDR **"举一反三"**的能力。即使是一个全新的勒索软件变种,只要它保留了核心加密模块的微小代码风格,孪生网络就能计算出它与已知样本库的高相似度,从而在只有 1 个参考样本的情况下实现精准检出。
5. 代码实战:构建 PyTorch API 序列分类器
理论讲完了,让我们把手弄脏。我们将构建一个基于 LSTM 的恶意行为检测模型。
5.1 数据预处理
假设我们已经通过 Cuckoo Sandbox 提取了 API 序列,并清洗为整数索引列表。
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
# 假设词汇表大小为 300 (即监控了 300 种核心 Windows API)
VOCAB_SIZE = 300 + 1 # +1 for padding
EMBEDDING_DIM = 64
HIDDEN_DIM = 128
NUM_LAYERS = 2
NUM_CLASSES = 2 # 0: Benign, 1: Ransomware
MAX_SEQ_LEN = 200 # 截取前200个API调用,或者滑动窗口
# 模拟数据
class APIDataset(Dataset):
def __init__(self, num_samples=1000):
# 随机生成数据用于演示
self.data = torch.randint(1, VOCAB_SIZE, (num_samples, MAX_SEQ_LEN))
self.labels = torch.randint(0, NUM_CLASSES, (num_samples,))
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.labels[idx]注意:现实世界的"好坏样本"比例极度不平衡。除了在 Loss 中加权,我们在预处理阶段通常会使用 **SMOTE (过采样)** 增强恶意样本,或对正常样本进行 **下采样 (Undersampling)**,以防止模型倾向于预测"全是好人"。
5.2 定义 LSTM 模型
这是一个经典的序列分类模型架构:Embedding -> LSTM -> Fully Connected。
python
class RansomwareLSTM(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers):
super(RansomwareLSTM, self).__init__()
# 1. 嵌入层:将 API 索引转换为密集向量
# padding_idx=0 表示数字0是填充位,不参与计算梯度
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=0)
# 2. LSTM 层
# batch_first=True 表示输入维度为 (batch, seq, feature)
self.lstm = nn.LSTM(embedding_dim,
hidden_dim,
num_layers=n_layers,
batch_first=True,
dropout=0.5) # 防止过拟合
# 3. 全连接层
self.fc = nn.Linear(hidden_dim, output_dim)
# 4. Dropout 和 Sigmoid
self.dropout = nn.Dropout(0.5)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# x shape: [batch_size, seq_len]
# embedded shape: [batch_size, seq_len, embedding_dim]
embedded = self.embedding(x)
# LSTM 输出
# output: 所有时间步的隐状态
# (hidden, cell): 最后一个时间步的隐状态和细胞状态
output, (hidden, cell) = self.lstm(embedded)
# 我们只取最后一个时间步的隐状态来做分类
# hidden shape: [num_layers, batch_size, hidden_dim]
# 取最后一层: hidden[-1] -> [batch_size, hidden_dim]
last_hidden = self.dropout(hidden[-1])
# 全连接分类
prediction = self.fc(last_hidden)
# 既然是二分类,最后一层一般不加Softmax而是直接输出Logits
# 或者在推理时过 Sigmoid
return prediction5.3 训练与损失函数
在安全领域,**漏报(False Negative)**的代价远高于误报。漏报一个勒索软件意味着全盘皆输。
因此,我们在定义损失函数时,应该赋予正样本(勒索软件)更高的权重。
python
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 初始化模型
model = RansomwareLSTM(VOCAB_SIZE, EMBEDDING_DIM, HIDDEN_DIM, NUM_CLASSES, NUM_LAYERS).to(device)
# 定义加权 Loss
# 假设数据集中正常样本是恶意的 10 倍,我们可以设置 weight
weights = torch.tensor([1.0, 10.0]).to(device) # 给类别1(勒索)10倍权重
criterion = nn.CrossEntropyLoss(weight=weights)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练循环 (伪代码)
# for epoch in range(EPOCHS):
# for text, labels in dataloader:
# optimizer.zero_grad()
# predictions = model(text)
# loss = criterion(predictions, labels)
# loss.backward()
# optimizer.step()6. 特征工程的深水区:Windows PE Header 的奥秘
除了 API 序列,Windows 可执行文件(PE 文件)的头部信息也是极佳的特征来源。这属于结构化数据,非常适合与 API 序列模型结合(多模态学习)。
传统的特征工程可能会提取"文件大小"、"导入表数量"。
但在深度学习时代,我们关注更细微的统计特征:
- 节(Section)的熵值序列:
正常程序的 .text 段熵值通常在 6.0-6.5 之间(汇编指令的统计规律)。
如果 .text 段的熵值高达 7.9(接近 8.0 的随机极限),这几乎 100% 说明它被加壳 或加密了(注:完全加密或压缩的数据在统计学上等同于均匀分布的随机噪声,其香农熵趋近于 8.0 bits/byte)。我们可以将各节的熵值作为一个向量输入神经网络。
- 导入表(IAT)哈希(Imphash):
攻击者虽然会重写代码,但往往懒得重写导入表。很多勒索软件变种共享相同的 Imphash。
- 资源目录特征:
很多恶意软件伪装成 Word 图标,但其资源段中却没有对应的版本信息(VS_VERSION_INFO)。这种不一致性是强特征。
我们将这些结构化特征通过一个简单的 MLP(多层感知机)处理,然后将其输出与 LSTM 的 API 特征向量进行 拼接(Concatenation),最后送入分类层。这能显著提高模型的鲁棒性。
7. 中场思考:矛与盾的较量
至此,我们在第一部分中构建了一套基于 CNN(视觉)和 LSTM(时序)的检测系统。
这套系统已经能够秒杀 90% 的传统勒索软件变种。它不依赖签名,只看二进制纹理和 API 行为。即使黑客修改了代码哈希,只要他还需要调用 CryptEncrypt,只要他还保留着加壳后的高熵特征,LSTM 就能捕捉到他。
但是,黑客不会坐以待毙。
如果黑客不使用恶意的 API 呢?
如果黑客利用系统自带的、合法的工具(如 PowerShell, WMI)来搞破坏呢?这就是所谓的 Living off the Land (LotL) 攻击。
对于 LSTM 来说,PowerShell 只是一个正常的进程,它的 API 调用看起来完全合法。
此外,LSTM 有一个致命缺陷:它是串行的,训练慢,且对于超长序列(例如监控 1 小时的行为)容易遗忘。
在下文 中,我们将引入 AI 领域的"变形金刚"------Transformer 模型 。我们将探讨如何利用 自注意力机制(Self-Attention) 来处理 LotL 攻击,并引入 深度强化学习(DRL) 来实现毫秒级的自动化阻断。
我们还将直面那个最棘手的问题:由于数据隐私,企业不愿意把端点数据传到云端训练,怎么办? 答案是:联邦学习(Federated Learning)。
请深呼吸,检查你的备份。下一章,我们将进入更为激烈的对抗。
请确认是否继续输出第二部分?
收到,我们将继续这场深入内核的防御之战。
在第一部分,我们掌握了用 CNN 识别恶意软件的"长相",用 LSTM 听懂它的"语言"。但正如你所预料的,真正的顶级黑客(State-sponsored Hackers)绝不会止步于此。他们开始使用系统自带的工具(LotL),他们学会了长时间潜伏,他们甚至试图通过"数据隐私"的法律壁垒来阻止防御者共享情报。
8. 超越 LSTM:Transformer 与注意力机制的觉醒
LSTM 虽然经典,但它有两个致命弱点:
- 串行计算,慢: 它必须看完 t-1 才能看 t,无法充分利用 GPU 的并行能力。
- 记忆衰退: 尽管有长短期记忆单元,但当序列长度超过 1000 时(这在 API 调用日志中很常见),早期的信息依然会丢失。
2017 年,Google 提出了 Transformer 架构(论文《Attention Is All You Need》),彻底改变了 NLP,也重塑了终端安全。
8.1 自注意力机制(Self-Attention):上帝视角
不同于 LSTM 的"逐词阅读",Transformer 拥有"一目十行"的能力。它能同时看到整个 API 序列,并计算每一个 API 对其他所有 API 的重要性(权重)。
数学公式如下:
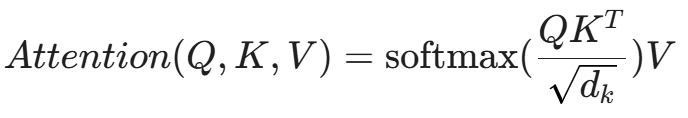
- Query (Q): 当前正在分析的 API(比如 WriteFile)。
- Key (K): 序列中的其他 API(比如之前的 SocketConnect)。
- Value (V): API 的特征向量。
安全含义:
当 Transformer 分析 WriteFile 时,它不仅看到了这一瞬间,还会自动"关注"(Assign High Attention Weight)到序列前面那个不起眼的 SocketConnect(建立了 C2 连接)和 GetSystemInfo。
它会忽略掉中间几百个无关紧要的 UI_Refresh(界面刷新)操作。
这种跨越长距离的直接关联能力,让攻击者的"延迟执行"和"噪音填充"战术失效。
除了"上帝视角",Transformer 相比 LSTM 的最大工程优势在于**并行计算**。LSTM 必须按时间步 t=1, t=2... 顺序计算,而 Transformer 可以一次性将整个 API 序列输入 GPU,训练效率提升数倍,这对于日产亿级日志的 EDR 厂商至关重要。
8.2 BERT for Security (BERT4Sec)
我们可以借鉴 NLP 中的 BERT 模型,使用 掩码语言模型(Masked Language Modeling, MLM) 进行预训练。
- 预训练(Pre-training): 收集数亿条正常的 Windows API 调用序列。随机遮挡住中间的一个 API,让 Transformer 猜它是啥。
- 输入:OpenProcess, VirtualAlloc, MASK, CreateRemoteThread
- AI 学习到:在这个注入进程的上下文中,中间那个通常是 WriteProcessMemory。
- 结果: 模型深刻理解了正常的系统行为逻辑。
- 微调(Fine-tuning): 使用少量标注好的勒索软件序列,训练分类器。
优势: 这种模型对 "无文件攻击"(Fileless Attack) 极其敏感。因为无文件攻击必须依赖异常的 API 组合来实现功能,这会打破 BERT 在预训练中建立的"正常语法概率",产生极高的困惑度(Perplexity)。
9. 隐形杀手:对抗"Living off the Land" (LotL)
现代黑客最喜欢的战术是 Living off the Land(就地取材)。他们不上传 .exe 病毒,而是运行一个 PowerShell 脚本,或者调用 WMI(Windows Management Instrumentation)。
对于传统的白名单防御,powershell.exe 是受信任的合法程序,必须放行。
9.1 上下文感知检测
LSTM 和简单的 Transformer 可能会被迷惑,因为 powershell.exe 这个进程本身是白的。
我们需要分析的是 命令行参数(Command Line Arguments) 和 父子进程关系。
- 正常: 用户点击开始菜单 -> explorer.exe -> powershell.exe。
- 恶意: 用户打开 Word 文档 -> winword.exe -> cmd.exe -> powershell.exe。
我们将 进程树(Process Tree) 图结构化,结合 Transformer,可以构建一个分层注意力网络(Hierarchical Attention Network)。
- 第一层: 字符级 CNN,分析命令行参数(如 -Enc Base64 编码的字符串)。
- 第二层: 序列级 Transformer,分析 API 调用。
- 第三层: 图级 GNN,分析父子进程关系。
只有当这三层特征融合时,AI 才能判定:"虽然这是 PowerShell,但它是由 Word 启动的,且参数包含混淆代码,且行为涉及外网连接,因此它是恶意的。"
10. 深度强化学习(DRL):从"检测"到"阻断"
EDR 中的 R (Response) 往往被忽视。
传统 EDR 发现病毒后,通常是弹窗:"发现威胁,是否隔离?"
但在勒索软件面前,速度就是生命。等你看到弹窗并点击"是"的时候,硬盘已经被加密了 50%。我们需要毫秒级的自动阻断。
但这有风险:如果 AI 误杀了关键的业务进程(比如 ERP 系统的数据库同步进程),会导致生产事故。
这是一个典型的决策问题 。我们需要 深度强化学习(Deep Reinforcement Learning, DRL)。
10.1 智能体(Agent)与环境(Environment)
我们将 EDR 视为一个智能体(Agent),它在操作系统这个环境(Environment)中生存。
- 状态(State, S_t): 当前系统的快照(CPU 使用率、API 序列、打开的文件句柄、网络流量)。
- 动作(Action, A_t):
- A_0: 什么都不做(Continue)。
- A_1: 发出告警(Alert)。
- A_2: 暂停进程(Suspend)。
- A_3: 杀死进程(Kill)。
- A_4: 隔离网络(Isolate Network)。
10.2 奖励函数(Reward Function)的设计
这是 DRL 的灵魂。我们通过奖励和惩罚来训练 AI 掌握"分寸"。
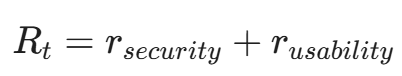
- 正向奖励: 成功拦截勒索软件,且在加密发生前(R = +100)。
- 负向惩罚(小): 漏报,导致少量文件被加密(R = -50)。
- 负向惩罚(大): 误杀正常业务进程(R = -200)。(注意:这是一个策略选择。对于关键业务服务器,误杀代价高于漏报;而对于核心机密终端,漏报代价高于误杀。奖励函数需根据资产重要性动态调整)。
10.3 训练过程:DQN (Deep Q-Network)
使用 DQN 或 PPO (Proximal Policy Optimization) 算法,让 Agent 在沙箱环境中与数千种勒索软件和正常软件进行对抗演练。
起初,Agent 可能会疯狂乱杀进程(得到巨额负分),或者唯唯诺诺不敢动手(导致系统被加密)。
经过数百万次的迭代(Episode),Agent 学会了最优策略(Optimal Policy):
"对于这种特征的进程,先执行 A_2(暂停),分析 100 毫秒后,如果确认是恶意的,再执行 A_3(杀死);如果是误判,立即 A_0(恢复),用户甚至感觉不到卡顿。"
11. 联邦学习(Federated Learning):打破数据孤岛
构建强大的 EDR 模型需要海量数据。但银行 A 绝不会把自己的终端日志上传给安全公司,因为里面可能包含客户账号或内部机密。
黑客利用这一点,对每家公司进行"分而治之"。
联邦学习(FL) 允许我们在不共享原始数据的情况下,共享智慧(模型参数)。
11.1 训练流程
- 本地训练: 银行 A、医院 B、工厂 C 各自在本地的 EDR 设备上,使用自己的私有数据训练同一个模型结构(比如 BERT4Sec)。
- 梯度上传: 它们不上传日志,只上传计算出的梯度(Gradients)或模型权重更新量(Weights Update)。为了防止逆向推导,还会加上**差分隐私(Differential Privacy)**噪音。
- 全局聚合: 云端的中央服务器收到各方的权重,使用 FedAvg 算法进行平均:
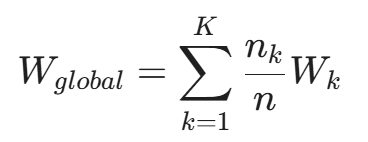
- 模型分发: 中央服务器将更新后的全局模型 W_{global} 发回给所有参与者。
结果: 医院 B 的 EDR 学会了如何防御一种新型勒索软件,尽管这个样本只在银行 A 出现过。
"数据不动,模型动"。这构建了一个全行业免疫系统。
12. 矛与盾的终极博弈:对抗样本(Adversarial Examples)
最后,我们必须冷静地面对现实:黑客也在进化。
针对 AI EDR,黑客正在开发 对抗样本攻击(Adversarial Evasion)。
12.1 模拟攻击(Mimicry Attack)
黑客发现 AI 高度依赖 API 序列。于是,他们在恶意 API 调用之间,插入大量无意义的、但在正常软件中常见的 API(No-op insertion)。
- 原始: ReadFile, Encrypt
- 对抗: ReadFile, DrawText, LoadIcon, GetTime, Encrypt
这些"良性噪音"会稀释恶意特征,让 LSTM 或 Transformer 的注意力机制分散,导致分类置信度下降到阈值以下。
12.2 梯度攻击(Gradient-based Attack)
如果黑客获取了你的 EDR 模型(例如通过逆向工程本地 Agent),他可以计算模型对输入的梯度,从而精确地修改二进制文件中的非功能性字节(Padding),使得文件指纹正好落在决策边界的"安全侧"。
防御之道:对抗训练(Adversarial Training)
我们在训练 EDR 模型时,不能只给它看标准样本。我们必须使用 FGSM (Fast Gradient Sign Method) 等算法,主动生成对抗样本加入训练集。
这就像在练拳击时,专门找人来攻击你的弱点,练就"金钟罩铁布衫"。
13. 打开黑盒:可解释性 AI (XAI) ------ 建立信任
在结束技术探讨之前,我们必须面对一个阻碍 AI EDR 落地的最大现实问题:信任。
如果你的 AI 模型以 99.9% 的置信度判定一个进程为勒索软件,并自动杀死了它。结果发现,那是财务部门正在运行的年终结算脚本。这种"误杀"在企业环境中是灾难性的。SOC 分析师会愤怒地质问:"为什么 AI 认为它是恶意的?"
如果回答是:"因为神经网络的第 3 层第 4 个神经元激活值是 0.9",那么这套系统会被立刻下线。
我们需要 XAI (Explainable AI,可解释性 AI)。
13.1 SHAP 值与归因分析
我们需要告诉分析师,AI 是依据哪些具体行为做出的判断。我们可以引入 SHAP (SHapley Additive exPlanations) 值来量化每个特征对决策的贡献。
- 黑盒输出:恶意概率 0.98。
- XAI 解释 :
- vssadmin.exe Delete Shadows(删除卷影副本):贡献度 +40%
- High Entropy Write(高熵写入):贡献度 +30%
- Traverse All Directories(遍历全盘):贡献度 +20%
- Unknown Publisher(未知签名):贡献度 +8%
13.2 注意力可视化 (Attention Visualization)
对于 Transformer 模型,我们可以直接提取 Attention Map (注意力热力图)。在 EDR 控制台上,分析师可以看到一条被高亮的 API 序列:
Start -> DownloadString (PowerShell) -> Sleep(100s) -> VirtualAlloc (RWX) -> CreateThread -> Encrypt
通过高亮显示关键步骤,AI 不再是一个冷冰冰的杀手,而是一个能够提供证据的数字侦探。只有具备了可解释性,AI 才能真正从"实验品"变成安全团队敢于依赖的"战友"。
14. 代码实战:基于 Transformer 的 API 行为检测
为了展示前面所述的核心,我们用 PyTorch 实现一个简化版的 Transformer Encoder 来处理 API 序列。
python
import torch
import torch.nn as nn
import math
class PositionalEncoding(nn.Module):
"""
Transformer 内部没有循环结构(Recurrence),因此无法天然捕获序列位置信息,必须手动注入位置信息。
"""
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe)
def forward(self, x):
# x shape: [seq_len, batch_size, d_model]
return x + self.pe[:x.size(0), :]
class TransformerEDR(nn.Module):
def __init__(self, vocab_size, d_model, nhead, num_encoder_layers, num_classes):
super(TransformerEDR, self).__init__()
self.d_model = d_model
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoder = PositionalEncoding(d_model)
# 定义 Transformer Encoder 层
encoder_layers = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead, dropout=0.1)
self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_layers=num_encoder_layers)
self.classifier = nn.Linear(d_model, num_classes)
self.dropout = nn.Dropout(0.1)
def forward(self, src, src_mask=None):
# src shape: [seq_len, batch_size] (注意 Transformer 默认 batch 在第二维)
# 1. Embedding + Positional Encoding
src = self.embedding(src) * math.sqrt(self.d_model)
src = self.pos_encoder(src)
# 2. Transformer Encoding
# output shape: [seq_len, batch_size, d_model]
output = self.transformer_encoder(src, src_key_padding_mask=src_mask)
# 3. Pooling (取平均值或取第一个token)
# 这里简单地取所有 token 的平均值作为序列的表示
output_mean = output.mean(dim=0)
# 4. Classification
output_mean = self.dropout(output_mean)
logits = self.classifier(output_mean)
return logits
# 模型参数实例化
VOCAB_SIZE = 500 # API 种类
D_MODEL = 128 # 嵌入维度
NHEAD = 4 # 多头注意力的头数
NUM_LAYERS = 2 # Encoder 层数
NUM_CLASSES = 2 # 良性 / 勒索
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = TransformerEDR(VOCAB_SIZE, D_MODEL, NHEAD, NUM_LAYERS, NUM_CLASSES).to(device)
print(f"Transformer EDR 模型构建完成,参数量: {sum(p.numel() for p in model.parameters())}")
# 模拟推理
# 假设 batch_size=1, 序列长度=50
sample_input = torch.randint(0, VOCAB_SIZE, (50, 1)).to(device)
output = model(sample_input)
# output shape: [1, 2] -> [[score_benign, score_malware]]
# 使用 Softmax 获取概率
probs = torch.softmax(output, dim=1)
print(f"恶意概率 (Malware Probability): {probs[0][1].item():.4f}")代码解读
这段代码虽然简短,但它包含了下一代 EDR 的核心:
- 位置编码(PositionalEncoding): 让模型知道 API 调用的顺序(Open 在 Read 之前很重要)。
- 自注意力(Self-Attention):
nn.TransformerEncoderLayer 内部会自动计算 API 之间的关联权重,捕捉长距离依赖。
- 并行处理: 相比 LSTM,这个模型在训练时可以一次性输入整个序列,极大提升了 MLOps 效率。
结语:硅基的博弈与碳基的漏洞
在本章中,我们完成了一次穿越操作系统内核的深潜之旅。 我们见证了 CNN 如何透过多态代码的迷雾,利用计算机视觉捕捉到恶意软件那无法掩盖的二进制纹理; 我们利用 LSTM 和 Transformer 的注意力机制,将枯燥的 API 调用日志还原为攻击者意图的连贯叙事; 我们甚至赋予了 EDR 智能体(Agent)以 深度强化学习(DRL) 的决断力,让它在毫秒之间切断勒索软件的黑手; 最后,我们通过 联邦学习,在保护数据隐私的前提下,构建起了全行业的数字免疫网络。
但这并不是终点,而是一个新的起点。 我们在本章构建的所有防线,都有一个共同的前提:我们假设操作计算机的是一个"程序"或"进程"。我们通过分析程序的行为来判定善恶。
然而,如果那个正在加密文件、正在导出数据库的操作,确实是由作为合法用户的你(或者是盗用了你身份的人)亲手敲下的呢? 如果是黑客通过社工手段获取了管理员密码,利用合法的 RDP 远程登录,然后像正常上班一样打开了 PowerShell 呢? 此时,系统没有漏洞,代码没有病毒,API 调用完全合法。对于 EDR 来说,这是一次无可挑剔的"正常操作"。
机器是安全的,但"人"成了最大的漏洞。
当基于软件行为 (Software Behavior)的防御达到极致时,我们必须把目光投向人类行为(Human Behavior)。 下一章,我们将跨越新的边界,进入身份认证的深水区。我们将探讨如何利用 AI 捕捉那些你通过键盘和鼠标留下的、独一无二的生物特征。 请做好准备,下一篇:《身份与访问:行为生物识别(按键习惯、移动轨迹)的 AI 建模》。
陈涉川
2026年02月06日