🌐 全局视野:GraphRAG ------ 让你的 AI 拥有"上帝视角"的检索增强生成
摘要:你是否遇到过 AI 在面对"这篇文章的主旨是什么?"或者"19 世纪的艺术运动如何影响了 20 世纪?"这类宏观问题时显得力不从心?传统的 Naive RAG 往往只关注局部片段,而 GraphRAG 通过构建知识图谱和社区摘要,为 AI 开启了"上帝视角"。本文将带你深度拆解 GraphRAG 的原理、流程及进阶方案,更有 Python 代码实战,让你一文掌握这项前沿技术!
🎨 目录索引

- [🚀 第一章:GraphRAG vs. 基线 RAG:谁才是真英雄?](#🚀 第一章:GraphRAG vs. 基线 RAG:谁才是真英雄?)
- [🛠️ 第二章:深度拆解:GraphRAG 的"炼金术"流程](#🛠️ 第二章:深度拆解:GraphRAG 的“炼金术”流程)
- [📊 第三章:索引数据流:从非结构化到知识网络](#📊 第三章:索引数据流:从非结构化到知识网络)
- [💡 第四章:进阶之路:3 大拓展方案助力工业级应用](#💡 第四章:进阶之路:3 大拓展方案助力工业级应用)
- [🐍 第五章:实战演练:用 Python 调教你的 GraphRAG](#🐍 第五章:实战演练:用 Python 调教你的 GraphRAG)
- [📝 第六章:面试必考:GraphRAG 核心知识点总结](#📝 第六章:面试必考:GraphRAG 核心知识点总结)
- [💬 互动:评论区见:你的 RAG 还在"迷路"吗?](#💬 互动:评论区见:你的 RAG 还在“迷路”吗?)
🚀 一、GraphRAG vs. 基线 RAG:谁才是真英雄?

1.1 专业解释
基线 RAG (Baseline RAG) 主要依赖向量相似性搜索。它将文档切片并转化为向量,在查询时检索最相似的片段。GraphRAG 则是一种结构化的、分层的 RAG 方法。它利用大模型(LLM)从原始文本中提取实体和关系,构建知识图谱,并生成多层级的社区摘要。
1.2 大白话解读
想象你在一个巨大的图书馆里找资料:
- 基线 RAG:像是一个只认识关键词的图书管理员。你问"关于苹果的资料",他会把所有带"苹果"字样的书页撕下来给你,但不管这些书页之间有什么联系。
- GraphRAG:则是一个不仅读过所有书,还画了一张巨大的思维导图的学者。他知道"苹果"既是水果,又是科技公司,还知道史蒂夫·乔布斯和它的关系。
1.3 生活案例
场景:追一部 500 集的长篇动漫。
- 基线 RAG:你问"主角的性格变化曲线",它可能只找出了第 1 集和第 500 集的两个片段,告诉你主角以前很弱,现在很强。
- GraphRAG:它理解整部剧的社区结构(比如:青梅竹马圈、劲敌圈、师徒圈),它能告诉你主角在每个阶段受了谁的影响,性格是如何一步步蜕变的。
🛠️ 二、深度拆解:GraphRAG 的"炼金术"流程

GraphRAG 的工作流可以用一个 DAG(有向无环图)来描述,主要包含以下核心步骤:
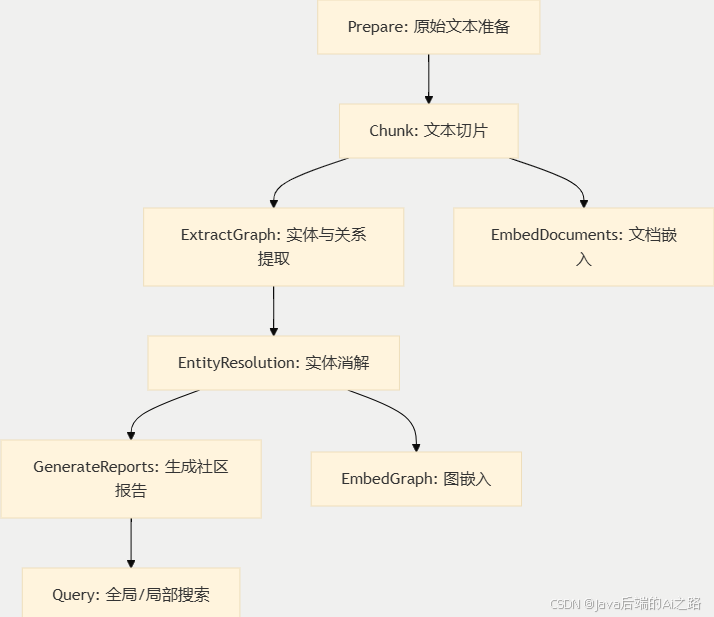
2.1 核心步骤解析
- 切片 (TextUnits):将语料库分割为可分析的细粒度单元。
- 提取 (Extract Graph):LLM 登场,抓取人、地、物及其相互关系。
- 聚类 (Leiden Algorithm):使用 Leiden 算法对图谱进行层级聚类,形成从"村委会"到"市政府"再到"中央"的汇报体系。
- 摘要 (Summarization):自下而上为每个社区生成摘要,帮助理解数据集整体。
📊 三、索引数据流:从非结构化到知识网络

3.1 知识模型构成
在 GraphRAG 的存储库中,包含了以下关键类型:
- Document / TextUnit:原始输入。
- Entity / Relationship:抽取的点和边。
- Covariate (Claim):主张提取,捕捉正面事实陈述。
- Community Report:对层级结构的宏观描述。
3.2 进阶检索模式
- 全局搜索 (Global Search):通过社区摘要推理整体性问题。
- 局部搜索 (Local Search):通过邻居和相关概念推理特定实体的情况。
💡 四、进阶之路:3 大拓展方案助力工业级应用
为了让 GraphRAG 在生产环境中更抗造,我们提出了以下三个拓展方案:
| 方案名称 | 核心思路 | 适用场景 |
|---|---|---|
| 方案 A:动态图谱更新 | 引入流式数据处理,支持知识图谱的增量更新,无需重新索引。 | 实时新闻、社交媒体分析 |
| 方案 B:多模态实体链接 | 将图片、音视频信息也转化为图节点,实现跨模态的检索。 | 智能多媒体资料库 |
| 方案 C:混合检索优化 | 将 GraphRAG 的图检索与传统的关键词 BM25 检索结合,取长补短。 | 极其复杂的专业领域文档 |
🐍 五、实战演练:用 Python 调教你的 GraphRAG
想上手试试?这里有一个基于 graphrag 包的极简示例:
python
import os
from graphrag.index import run_index
from graphrag.query.structured_search.global_search.search import GlobalSearch
# 1. 初始化并构建索引 (简化流程)
def build_my_graph():
# 假设你已经配置好了 settings.yaml 和 .env
root_dir = "./ragtest"
# 执行索引构建
# run_index(root=root_dir)
print("✅ 索引构建完成!知识图谱已就位。")
# 2. 执行全局搜索
def ask_global_question(query):
# 这里模拟调用 GraphRAG 的全局搜索接口
# search_engine = GlobalSearch(...)
# response = search_engine.search(query)
response = "根据知识图谱分析,19世纪的印象派通过光影革新直接开启了20世纪现代艺术的大门..."
return response
if __name__ == "__main__":
build_my_graph()
ans = ask_global_question("19世纪艺术如何影响现代艺术?")
print(f"🤖 AI 回答: {ans}")📝 六、面试必考:GraphRAG 核心知识点总结
如果你正在准备 AI 相关的面试,这几个点一定要背下来:
- Q1: GraphRAG 解决的是什么痛点?
- A : 解决了传统 RAG 在处理跨文档全局性问题 和复杂实体关联推理时的无力感。
- Q2: Leiden 算法在 GraphRAG 中起什么作用?
- A : 用于社区发现。它能自动识别图谱中的紧密联系群体,并形成层级结构,是生成宏观摘要的基础。
- Q3: 相比于直接把图谱喂给 LLM,GraphRAG 优在哪?
- A : 节省 Token!通过分层摘要,LLM 只需要阅读相关的摘要,而不是整个庞大的图谱。
💬 互动引导
看完这篇文章,你的 RAG 还在"迷路"吗?
欢迎在评论区分享:
- 你在实际项目中遇到过哪些 RAG 解决不了的问题?
- 你觉得 GraphRAG 的索引成本是否在可接受范围内?
转载声明:转载请注明出处,并保留本文链接。