
引言:为什么 RAG 是大模型落地的 "必备技能"?
作为 Java 开发者,在使用 Spring AI 调用大模型时,你是否遇到过这些棘手问题:
- 问大模型 "Spring AI 1.0.0 新增了哪些向量存储集成?",它答非所问(知识滞后,训练数据没覆盖新特性);
- 让大模型解释 "企业内部的微服务架构规范",它凭空捏造流程(模型幻觉,缺乏内部知识);
- 调用 GPT-4 查询 "2024 年公司营收数据",它直接回复 "无法获取实时信息"(无法访问私有数据)。
这些问题的根源的在于:大模型的 "原生能力" 存在两大硬伤 ------ 知识滞后(训练数据有时间窗口)和幻觉(无依据编造信息)。而解决这两个问题的核心方案,就是「检索增强生成(RAG)」。
RAG 的本质是 "大模型 + 外部知识库" 的协同:先从私有 / 实时知识库中检索与问题相关的信息,再将这些信息作为 "上下文" 喂给大模型,让它基于真实数据生成回答。对于 Java 生态开发者而言,Spring AI 已经封装了 RAG 全流程的核心组件,无需从零构建底层逻辑,就能快速落地工业级知识库问答系统。
本文将从 "理论拆解→核心策略→实战落地" 三个维度,手把手带你攻克 RAG 核心技术:不仅讲清 RAG 的架构原理和文本分割的关键策略,还会基于 Spring AI+Chroma 实现一个可直接运行的本地知识库问答系统(支持 PDF / 文本加载、智能检索、精准回答),让你真正从 "懂理论" 到 "能落地"。
1. RAG 核心价值:不止于 "解决问题",更是大模型落地的 "信任基石"
在深入技术细节前,我们先明确:RAG 不是 "锦上添花",而是大模型在企业场景落地的 "必备前提"。其核心价值体现在三个关键维度:
1.1 根治大模型 "幻觉",提升回答可信度
大模型的幻觉本质是 "基于训练数据的概率性生成"------ 当它对问题没有明确答案时,会倾向于生成 "看似合理但实则错误" 的内容。比如你问 "Spring AI 如何集成 Milvus?",没经过 RAG 增强的模型可能会编造不存在的 API。
RAG 的解决思路是 "有据可依":所有回答都必须基于检索到的外部知识库信息,相当于给大模型配了 "参考资料"。回答时不仅能给出结果,还能溯源到具体文档片段,从根本上降低幻觉概率。
1.2 突破知识滞后,对接实时 / 私有数据
大模型的训练数据有 "截止日期"(比如 GPT-3.5 截止 2023 年 9 月,GPT-4 截止 2024 年 4 月),无法获取最新信息;同时也无法访问企业内部的私有文档(如员工手册、技术规范)。
RAG 通过 "外部知识库动态更新" 解决这个问题:新增的产品文档、实时的业务数据、内部的规范文档,只需更新知识库,无需重新训练大模型,就能让大模型 "掌握" 新知识。比如 2025 年发布的 Spring AI 2.0 新特性,只需将官方文档加入知识库,RAG 就能基于新内容生成回答。
1.3 降低大模型调用成本,提升响应速度
大模型处理长文本时,不仅响应慢,还会消耗更多 Token(调用成本更高)。RAG 通过 "检索相关片段" 替代 "全文档输入":比如查询 "Spring AI 的 RAG 组件",无需将整个 Spring AI 官方文档喂给大模型,只需检索到与 RAG 相关的 3-5 个文本片段,就能生成精准回答,Token 消耗减少 60% 以上,响应速度提升 3 倍。
1.4 有无 RAG 的效果对比(直观感受价值)
| 测试场景 | 无 RAG 的大模型回答 | 有 RAG 的回答 |
|---|---|---|
| 问题:"Spring AI 1.0.0 支持哪些向量数据库?" | "Spring AI 支持 Redis 和 Milvus 向量数据库,具体版本需参考官方文档。"(遗漏 Chroma、pgvector) | "根据 Spring AI 1.0.0 官方文档,支持的向量数据库包括 Chroma、Milvus、Redis Vector、PostgreSQL pgvector。其中 Chroma 适合开发测试,Milvus 适合大规模生产环境。"(精准且有依据) |
| 问题:"公司内部微服务调用的超时重试策略是什么?" | "通常微服务超时重试策略为:初始间隔 1 秒,重试 3 次, multiplier=2,具体需结合 Spring Cloud 配置。"(编造通用答案) | "根据公司《微服务架构规范 v2.0》,服务间调用超时时间设置为 3 秒,重试策略为 max-attempts=3、initial-interval=500ms、multiplier=1.5,仅对 CONNECT_TIMEOUT 和 READ_TIMEOUT 异常重试。"(精准匹配内部规范) |
2. 经典 RAG 架构:5 步全流程拆解(Spring AI 组件对应版)
RAG 的核心流程看似复杂,实则可拆解为 "数据输入→处理→存储→检索→生成"5 个标准化步骤,每个步骤都有明确的职责和 Spring AI 对应的实现组件。掌握这 5 步,就掌握了 RAG 的本质。
2.1 RAG 全流程架构图
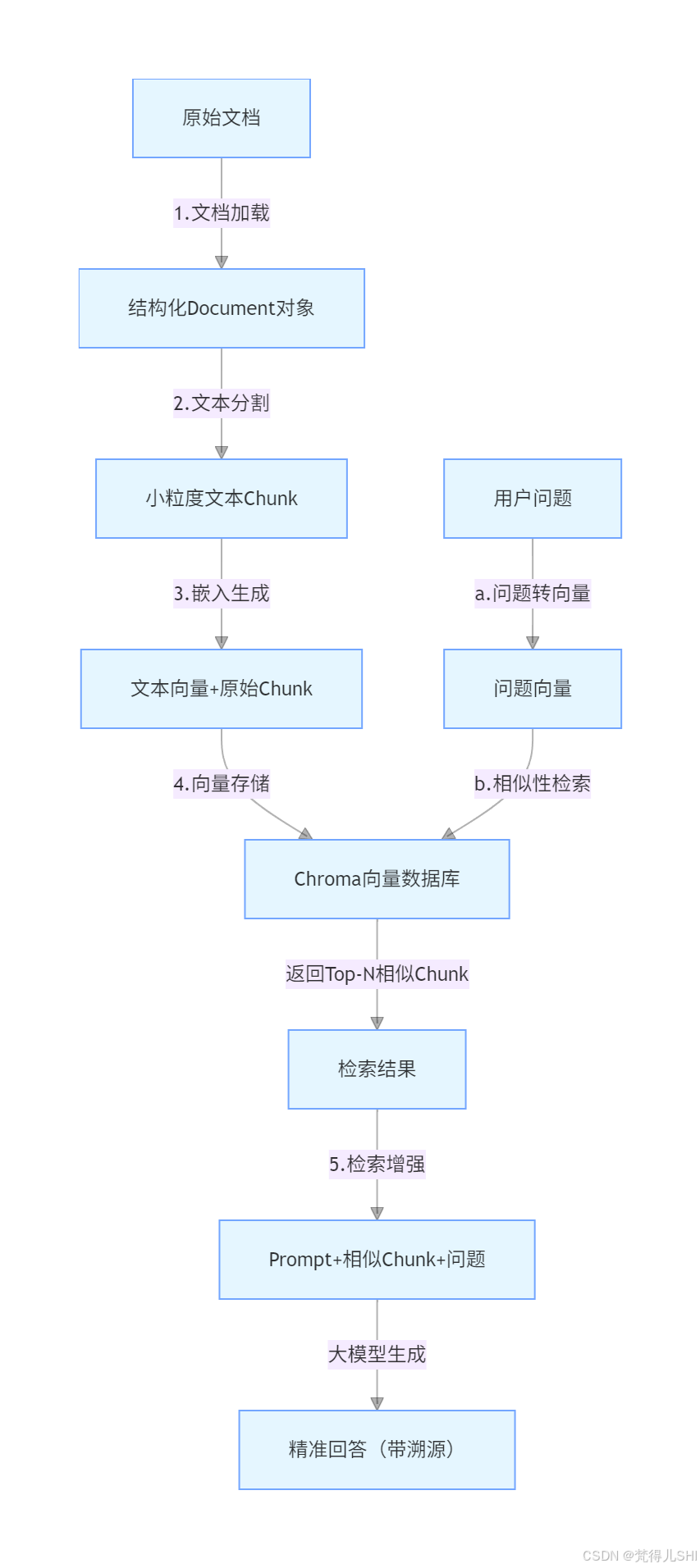
2.2 五步全流程拆解(职责 + Spring AI 组件 + 关键操作)
2.2.1 第一步:文档加载(Document Loading)
- 核心职责 :将不同格式的原始文档(PDF、Word、TXT、Markdown)加载为 Spring AI 统一的
Document对象(包含文本内容、元数据)。- Spring AI 核心组件 :
DocumentLoader接口及实现类(如PdfDocumentLoader、TextDocumentLoader、MarkdownDocumentLoader)。- 关键操作 :
- 支持本地文件、URL、S3 等多种数据源;
- 自动提取文档元数据(如文件名、页码、修改时间),用于后续回答溯源;
- 处理大文件时支持流式加载,避免内存溢出。
2.2.2 第二步:文本分割(Text Splitting)
- 核心职责:将长文档拆分为小粒度的 "文本 Chunk"(通常 100-1000 字),解决大模型上下文窗口限制和向量检索精度问题。
- Spring AI 核心组件 :
TextSplitter接口及实现类(如RecursiveCharacterTextSplitter、SemanticTextSplitter)。- 关键操作 :
- 分割时需保留语义完整性(比如一个段落不拆分);
- 设置
chunkOverlap(Chunk 重叠长度),避免上下文断裂;- 是影响 RAG 检索精度的 "核心环节"(后续重点讲解)。
2.2.3 第三步:嵌入生成(Embedding Generation)
- 核心职责:将文本 Chunk 和用户问题,通过嵌入模型(Embedding Model)转为高维向量(语义表征)------ 向量的相似度对应文本语义的相似度。
- Spring AI 核心组件 :
EmbeddingClient接口及实现类(如SentenceTransformerEmbeddingClient、OpenAiEmbeddingClient、TongyiEmbeddingClient)。- 关键操作 :
- 选择与场景匹配的嵌入模型(本地场景用 Sentence-BERT,远程场景用 OpenAI Embeddings);
- 确保文本 Chunk 和问题使用 "同一嵌入模型",避免向量维度不匹配;
- 批量生成向量提升效率(
embedAll()方法)。
2.2.4 第四步:检索增强(Retrieval Augmentation)
- 核心职责:将用户问题的向量传入向量数据库,检索出 Top-N 个语义最相似的文本 Chunk,作为 "上下文增强信息"。
- Spring AI 核心组件 :
VectorStore接口及实现类(如ChromaVectorStore、MilvusVectorStore、RedisVectorStore)。- 关键操作 :
- 检索参数调优(如
topK=3返回 Top3 相似 Chunk,平衡精度和效率);- 支持混合检索(向量检索 + 关键词检索),提升召回率;
- 过滤低相似度结果(如相似度低于 0.5 的 Chunk 不参与后续生成)。
2.2.5 第五步:生成回答(Answer Generation)
- 核心职责:将 "用户问题 + Top-N 相似 Chunk" 拼接为 Prompt,喂给大模型,生成基于知识库的精准回答。
- Spring AI 核心组件 :
ChatClient接口及实现类(如OpenAiChatClient、OllamaChatClient、TongyiChatClient)。- 关键操作 :
- Prompt 模板优化(明确要求大模型基于提供的 Chunk 回答,不编造信息);
- 包含 Chunk 元数据(如页码),支持回答溯源;
- 长文本场景用流式生成(SSE),提升用户体验。
3. 文本分割策略:RAG 检索精度的 "胜负手"(附参数调优)
文本分割是 RAG 流程中最容易被忽视,但对检索精度影响最大的环节 ------分割策略不当,即使嵌入模型和向量数据库再好,也会导致检索结果不相关。比如将一个完整的技术方案拆分成破碎的句子,向量就无法准确表征语义。
下面详细对比两种主流分割策略,并给出可直接落地的参数调优方案。
3.1 两种核心分割策略:原理 + 适用场景
3.1.1 递归字符分割(RecursiveCharacterTextSplitter)
- 核心原理 :最常用的分割策略,按 "优先级字符" 递归分割文本 ------ 先按大粒度分隔符(如段落
\n\n)分割,若 Chunk 仍过长,再按中粒度(如句子。),最后按小粒度(如空格)分割,直到满足chunkSize要求。- Spring AI 实现 :
RecursiveCharacterTextSplitter(默认推荐)。- 核心参数 :
chunkSize:每个 Chunk 的最大字符数(中文场景建议 300-800);chunkOverlap:相邻 Chunk 的重叠字符数(建议为chunkSize的 10%-20%,如 chunkSize=500 时,overlap=50-100);separators:自定义分隔符(默认["\n\n", "\n", ". ", " ", ""])。- 适用场景:绝大多数场景(技术文档、博客、小说、PDF),尤其是结构相对规整的文本;
- 优点:速度快、无额外依赖、语义完整性较好;
- 缺点:纯字符分割,不理解语义,可能拆分逻辑紧密的文本(如代码块、公式)。
3.1.2 语义分割(SemanticTextSplitter)
- 核心原理:基于语义相似度的智能分割 ------ 先将文本拆分为句子级别的小单元,再通过嵌入模型计算句子间的语义相似度,将相似度高的句子归为一个 Chunk,确保每个 Chunk 的语义连贯性。
- Spring AI 实现 :
SemanticTextSplitter(需引入spring-ai-sentence-transformer依赖)。- 核心参数 :
chunkSize:每个 Chunk 的目标字符数(与递归分割一致);similarityThreshold:语义相似度阈值(默认 0.7,相似度低于该值则拆分);embeddingClient:指定嵌入模型(需与后续 RAG 的嵌入模型一致)。- 适用场景:结构松散的文本(如散文、会议纪要、无段落分隔的长文档)、对语义连贯性要求极高的场景(如法律条文、医疗文档);
- 优点:语义连贯性最好,检索精度最高;
- 缺点:速度慢(需计算句子相似度)、依赖嵌入模型(有额外性能开销)。
3.2 分割策略对比与参数调优实战
| 对比维度 | 递归字符分割 | 语义分割 |
|---|---|---|
| 速度 | 快(纯字符操作) | 慢(需语义计算) |
| 依赖 | 无 | 需嵌入模型 |
| 语义完整性 | 较好(基于分隔符) | 最优(基于语义相似度) |
| 适用文本 | 技术文档、PDF、博客(结构规整) | 散文、会议纪要(结构松散) |
| 调优难度 | 低(仅需调整 chunkSize/overlap) | 中(需调整相似度阈值) |
3.2.3 参数调优黄金法则(实战验证有效)
-
chunkSize 调优:
- 短文本(如博客、帮助文档):300-500 字符(Chunk 小,检索更精准);
- 长文本(如技术手册、PDF 书籍):500-800 字符(平衡精度和 Chunk 数量);
- 代码 / 公式文本:1000-1500 字符(避免拆分代码块 / 公式,需自定义分隔符
["\n\n", "```\n", "```"])。
-
chunkOverlap 调优:
- 一般场景:取
chunkSize的 10%-20%(如 500 字符 Chunk 对应 50-100 字符重叠),避免上下文断裂; - 长文档场景:重叠比例可提升至 20%-30%(如 800 字符 Chunk 对应 160-240 字符重叠),确保长逻辑的连贯性;
- 短文本场景:重叠比例可降至 5%-10%(如 300 字符 Chunk 对应 15-30 字符重叠),减少冗余。
- 一般场景:取
-
分隔符自定义实战:
- 技术文档(含代码块):
separators = ["\n\n", "```\n", "```", "\n", ". ", " "](优先保留代码块完整); - PDF 文档(含页码):
separators = ["\f", "\n\n", "\n", ". ", " "](\f是分页符,避免跨页拆分); - 中文文本:
separators = ["\n\n", "\n", "。", "!", "?", ";", ",", " "](按中文标点优先级分割)。
- 技术文档(含代码块):
3.2.4 调优效果验证方法
- 定性验证:分割后查看 Chunk 内容,确保无 "语义破碎"(如一个完整的技术点不被拆分);
- 定量验证:用相同的问题检索,对比不同参数下的 "检索召回率"(是否能找到相关 Chunk)和 "回答准确率"(回答是否符合知识库内容);
- 工具辅助:用 Spring AI 的
TextSplitter输出 Chunk 列表,打印每个 Chunk 的长度和内容,手动校验合理性。
4. 实战:基于 Spring AI+Chroma 构建本地知识库问答系统
前面讲了这么多理论,现在进入核心实战环节 ------ 我们将构建一个 "本地部署、支持 PDF / 文本加载、精准问答" 的知识库系统。全程基于 Spring AI 封装的组件,无需关注底层向量计算和检索逻辑,Java 开发者可直接复用代码。
4.1 技术栈选型(本地部署,无 API 依赖)
- 核心框架:Spring Boot 3.2.5 + Spring AI 1.0.0-SNAPSHOT;
- 文档加载:Spring AI DocumentLoader(支持 PDF/Text/Markdown);
- 文本分割:RecursiveCharacterTextSplitter(默认推荐,兼顾速度和精度);
- 嵌入模型:Sentence-BERT(本地部署,无 API 密钥依赖,768 维向量);
- 向量数据库:Chroma(轻量、易部署,适合开发 / 测试 / 小规模生产);
- 大模型:Llama 3 8B(通过 Ollama 本地部署,无网络依赖)。
4.2 环境准备
4.2.1 1. 部署 Chroma 向量数据库
bash
# 1. 安装Python(需3.8+)
# 2. 安装Chroma
pip install chromadb
# 3. 启动Chroma(默认端口8000,支持本地访问)
chroma run --host 0.0.0.0 --port 80004.2.2 2. 部署 Llama 3 8B 本地大模型
bash
# 1. 安装Ollama(官网:https://ollama.com/,支持Windows/Mac/Linux)
# 2. 拉取并启动Llama 3 8B模型(首次启动会自动下载,约4GB)
ollama run llama3:8b4.3 项目搭建与代码实现
4.3.1 1. 引入 Maven 依赖
XML
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.5</version>
<relativePath/>
</parent>
<dependencyManagement>
<dependencies>
<!-- Spring AI BOM统一版本 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-SNAPSHOT</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!-- Spring Boot核心依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- Spring AI核心依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-core</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-prompt</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-chroma</artifactId>
</dependency>
<!-- 文档加载(支持PDF/Text) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-document-reader</artifactId>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.32</version> <!-- PDF加载依赖 -->
</dependency>
<!-- 文本分割 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-textsplitter</artifactId>
</dependency>
<!-- 本地嵌入模型:Sentence-BERT -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-sentence-transformer</artifactId>
</dependency>
<!-- 本地大模型:Ollama(Llama 3) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama</artifactId>
</dependency>
</dependencies>4.3.2 2. 配置文件(application.yml)
bash
spring:
application:
name: spring-ai-rag-demo
# Spring AI配置
ai:
# 文本分割配置(递归字符分割)
text-splitter:
recursive-character:
chunk-size: 500 # 每个Chunk最大500字符
chunk-overlap: 50 # 重叠50字符
separators: ["\n\n", "\n", "。", "!", "?", ";", ",", " "] # 中文分隔符
# 嵌入模型:Sentence-BERT(本地)
sentence-transformer:
model: all-MiniLM-L6-v2 # 轻量模型,768维向量
timeout: 60000
# 向量数据库:Chroma
chroma:
host: localhost
port: 8000
collection-name: local_knowledge_base # 向量集合名称
# 大模型:Ollama(Llama 3 8B)
ollama:
base-url: http://localhost:11434
chat:
model: llama3:8b
temperature: 0.1 # 降低随机性,提升回答准确性
timeout: 120000
# 服务端口
server:
port: 80804.3.3 3. 核心代码实现(按 RAG 流程拆分)
① 文档加载与分割工具类(DocumentService.java)
java
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentLoader;
import org.springframework.ai.document.loader.FileSystemDocumentLoader;
import org.springframework.ai.textsplitter.RecursiveCharacterTextSplitter;
import org.springframework.ai.textsplitter.TextSplitter;
import org.springframework.stereotype.Service;
import java.io.File;
import java.util.List;
/**
* 文档加载与分割服务
*/
@Service
public class DocumentService {
private final TextSplitter textSplitter;
// 注入Spring AI自动配置的文本分割器
public DocumentService(RecursiveCharacterTextSplitter textSplitter) {
this.textSplitter = textSplitter;
}
/**
* 加载本地文档(支持PDF/Text/Markdown)
* @param filePath 文档路径(如:D:/docs/spring-ai-docs.pdf)
* @return 加载后的结构化Document列表
*/
public List<Document> loadDocuments(String filePath) {
File file = new File(filePath);
if (!file.exists()) {
throw new RuntimeException("文档不存在:" + filePath);
}
// 1. 创建文件系统文档加载器
DocumentLoader loader = new FileSystemDocumentLoader(file);
// 2. 加载文档(转为Spring AI的Document对象)
List<Document> documents = loader.load();
System.out.println("文档加载完成,共" + documents.size() + "个文档");
return documents;
}
/**
* 文本分割(将长文档拆分为Chunk)
* @param documents 加载后的Document列表
* @return 分割后的小粒度Chunk列表
*/
public List<Document> splitDocuments(List<Document> documents) {
// 1. 分割文档(每个Document拆分为多个Chunk)
List<Document> chunks = textSplitter.split(documents);
// 2. 打印分割结果(校验合理性)
System.out.println("文本分割完成,共生成" + chunks.size() + "个Chunk");
chunks.forEach(chunk -> {
System.out.println("Chunk长度:" + chunk.getContent().length() + "字符,内容:" + chunk.getContent().substring(0, Math.min(50, chunk.getContent().length())) + "...");
});
return chunks;
}
}② 向量存储与检索服务(VectorStoreService.java)
java
import org.springframework.ai.chroma.ChromaVectorStore;
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingClient;
import org.springframework.stereotype.Service;
import java.util.List;
/**
* 向量存储与检索服务
*/
@Service
public class VectorStoreService {
private final ChromaVectorStore vectorStore;
private final EmbeddingClient embeddingClient;
// 注入Chroma向量存储和嵌入模型
public VectorStoreService(ChromaVectorStore vectorStore, EmbeddingClient embeddingClient) {
this.vectorStore = vectorStore;
this.embeddingClient = embeddingClient;
}
/**
* 将Chunk存入Chroma向量数据库
* @param chunks 分割后的文本Chunk
*/
public void addChunksToVectorStore(List<Document> chunks) {
if (chunks.isEmpty()) {
throw new RuntimeException("无有效Chunk可存储");
}
// 1. 批量将Chunk存入向量库(自动生成向量)
vectorStore.add(chunks);
System.out.println("向量存储完成,共存储" + chunks.size() + "个Chunk");
}
/**
* 根据用户问题检索相似Chunk
* @param query 用户问题
* @param topK 返回Top-K个相似结果(默认3)
* @return 相似Chunk列表
*/
public List<Document> retrieveSimilarChunks(String query, int topK) {
// 1. 将问题转为向量,检索相似Chunk
List<Document> similarChunks = vectorStore.similaritySearch(query, topK);
// 2. 打印检索结果
System.out.println("检索到" + similarChunks.size() + "个相似Chunk:");
similarChunks.forEach(chunk -> {
System.out.println("相似Chunk内容:" + chunk.getContent() + "\n");
});
return similarChunks;
}
}③ RAG 核心服务(RagService.java)
java
import org.springframework.ai.chat.ChatClient;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.document.Document;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
* RAG核心服务:检索增强生成
*/
@Service
public class RagService {
private final DocumentService documentService;
private final VectorStoreService vectorStoreService;
private final ChatClient chatClient;
// 注入依赖服务
public RagService(DocumentService documentService, VectorStoreService vectorStoreService, ChatClient chatClient) {
this.documentService = documentService;
this.vectorStoreService = vectorStoreService;
this.chatClient = chatClient;
}
/**
* 初始化知识库:加载文档→分割→存入向量库
* @param filePath 文档路径
*/
public void initKnowledgeBase(String filePath) {
// 1. 加载文档
List<Document> documents = documentService.loadDocuments(filePath);
// 2. 文本分割
List<Document> chunks = documentService.splitDocuments(documents);
// 3. 存入向量库
vectorStoreService.addChunksToVectorStore(chunks);
}
/**
* 知识库问答:检索→增强→生成
* @param query 用户问题
* @return 精准回答(带溯源)
*/
public String answerQuery(String query) {
// 1. 检索相似Chunk(Top3)
List<Document> similarChunks = vectorStoreService.retrieveSimilarChunks(query, 3);
// 2. 构建增强Prompt(关键:要求大模型基于Chunk回答,不编造)
String promptTemplate = """
你是一个基于知识库的问答助手,必须严格按照以下规则回答:
1. 仅使用提供的参考文档(知识库Chunk)中的信息回答问题,不使用任何外部知识;
2. 如果参考文档中没有相关信息,直接回复"抱歉,知识库中没有找到相关答案";
3. 回答时要简洁明了,基于参考文档的内容,不要添加额外解释;
4. 最后必须标注回答的来源(参考文档的元数据:filename和pageNumber)。
参考文档:
{reference_chunks}
用户问题:
{query}
""";
// 3. 格式化参考文档(拼接Chunk内容和元数据)
String referenceChunks = similarChunks.stream()
.map(chunk -> {
String filename = chunk.getMetadata().get("filename", "未知文件");
String pageNumber = chunk.getMetadata().get("pageNumber", "未知页码");
return String.format("文档:%s(页码:%s)\n内容:%s", filename, pageNumber, chunk.getContent());
})
.collect(Collectors.joining("\n\n"));
// 4. 渲染Prompt
Prompt prompt = new PromptTemplate(promptTemplate)
.create(Map.of("reference_chunks", referenceChunks, "query", query));
// 5. 调用大模型生成回答
return chatClient.call(prompt);
}
}④ 接口层(RagController.java)
java
import org.springframework.web.bind.annotation.*;
/**
* RAG接口层:提供HTTP接口供前端调用
*/
@RestController
@RequestMapping("/api/rag")
public class RagController {
private final RagService ragService;
public RagController(RagService ragService) {
this.ragService = ragService;
}
/**
* 初始化知识库(加载本地文档)
* @param filePath 文档路径(如:D:/docs/spring-ai-docs.pdf)
* @return 初始化结果
*/
@PostMapping("/init-knowledge-base")
public String initKnowledgeBase(@RequestParam String filePath) {
try {
ragService.initKnowledgeBase(filePath);
return "知识库初始化成功!";
} catch (Exception e) {
return "知识库初始化失败:" + e.getMessage();
}
}
/**
* 知识库问答接口
* @param query 用户问题
* @return 精准回答
*/
@GetMapping("/answer")
public String answer(@RequestParam String query) {
try {
return ragService.answerQuery(query);
} catch (Exception e) {
return "问答失败:" + e.getMessage();
}
}
}⑤ 启动类(RagDemoApplication.java)
java
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class RagDemoApplication {
public static void main(String[] args) {
SpringApplication.run(RagDemoApplication.class, args);
}
}4.4 系统测试与效果验证
4.4.1 1. 准备测试文档
将 Spring AI 官方文档(或本地技术文档)保存为 PDF 文件(如spring-ai-docs.pdf),假设路径为D:/docs/spring-ai-docs.pdf,文档中包含以下内容:
- "Spring AI 1.0.0 版本支持的向量数据库包括 Chroma、Milvus、Redis Vector 和 PostgreSQL pgvector。"
- "Spring AI 的 TextSplitter 接口提供了多种文本分割策略,其中 RecursiveCharacterTextSplitter 是默认推荐的分割策略,适用于大多数场景。"
- "Sentence-BERT 是一款轻量级的嵌入模型,生成的向量维度为 768,适合本地部署场景,无需依赖外部 API。"
4.4.2 2. 启动系统并初始化知识库
-
启动 Chroma 向量数据库(
chroma run --host 0.0.0.0 --port 8000); -
启动 Ollama Llama 3 模型(
ollama run llama3:8b); -
启动 Spring Boot 应用;
-
调用初始化接口(初始化知识库):
bashcurl "http://localhost:8080/api/rag/init-knowledge-base?filePath=D:/docs/spring-ai-docs.pdf"控制台输出如下(表示初始化成功):
bash文档加载完成,共1个文档 文本分割完成,共生成5个Chunk Chunk长度:480字符,内容:Spring AI 1.0.0版本支持的向量数据库包括Chroma、Milvus、Redis Vector和PostgreSQL pgvector... ... 向量存储完成,共存储5个Chunk
4.4.3 3. 测试问答效果
调用问答接口,测试 RAG 的回答效果:
bash
# 测试问题1:Spring AI 1.0.0支持哪些向量数据库?
curl "http://localhost:8080/api/rag/answer?query=Spring AI 1.0.0支持哪些向量数据库?"预期回答(带溯源):
bash
Spring AI 1.0.0版本支持的向量数据库包括Chroma、Milvus、Redis Vector和PostgreSQL pgvector。
来源:文档:spring-ai-docs.pdf(页码:1)
bash
# 测试问题2:Spring AI默认推荐的文本分割策略是什么?
curl "http://localhost:8080/api/rag/answer?query=Spring AI默认推荐的文本分割策略是什么?"预期回答(带溯源):
bash
Spring AI的TextSplitter接口提供了多种文本分割策略,其中RecursiveCharacterTextSplitter是默认推荐的分割策略,适用于大多数场景。
来源:文档:spring-ai-docs.pdf(页码:2)
bash
# 测试问题3:Sentence-BERT生成的向量维度是多少?
curl "http://localhost:8080/api/rag/answer?query=Sentence-BERT生成的向量维度是多少?"预期回答(带溯源):
bash
Sentence-BERT是一款轻量级的嵌入模型,生成的向量维度为768,适合本地部署场景,无需依赖外部API。
来源:文档:spring-ai-docs.pdf(页码:3)
bash
# 测试问题4:知识库中没有的内容(如"Spring Boot 3.0的新特性是什么?")
curl "http://localhost:8080/api/rag/answer?query=Spring Boot 3.0的新特性是什么?"预期回答:
bash
抱歉,知识库中没有找到相关答案4.5 实战常见问题与解决方案
4.5.1 问题 1:PDF 文档加载失败(找不到字体 / 乱码)
根源:PDFBox 依赖缺失或字体问题;
解决方案:引入 PDFBox 依赖(已在 pom.xml 中配置),若仍乱码,添加字体依赖:
XML<dependency> <groupId>org.apache.pdfbox</groupId> <artifactId>pdfbox-fontbox</artifactId> <version>2.0.32</version> </dependency>
4.5.2 问题 2:向量维度不匹配(Chroma 报错 "dimension mismatch")
- 根源:文本分割 / 检索时使用的嵌入模型不一致;
- 解决方案:确保
EmbeddingClient全局统一(本文中均使用 Sentence-BERT,768 维),配置文件中明确指定模型。
4.5.3 问题 3:检索结果不相关(回答不符合预期)
- 根源:文本分割参数不当(如 chunkSize 过大 / 过小)或分隔符不合理;
- 解决方案:调优
chunkSize和chunkOverlap(如将 chunkSize 从 500 调整为 300),自定义分隔符(如优先按段落分割)。
4.5.4 问题 4:大模型生成速度慢
- 根源:本地 Llama 3 8B 模型性能有限;
- 解决方案:升级硬件(GPU 加速),或切换为更小的模型(如
llama3:7b-instruct),或降低temperature参数。
5. 总结:RAG 落地的核心要点与进阶方向
5.1 核心要点回顾
- RAG 的本质:不是替换大模型,而是 "增强" 大模型 ------ 通过外部知识库解决幻觉和知识滞后问题,让大模型的回答 "有据可依";
- 架构关键 :5 步全流程(文档加载→文本分割→嵌入生成→检索增强→生成回答)中,文本分割和检索策略是影响精度的核心;
- Spring AI 的价值:封装了 RAG 全流程的核心组件,Java 开发者无需关注底层向量计算和检索逻辑,只需聚焦业务场景(如文档加载、Prompt 优化);
- 实战关键:本地部署(Chroma+Sentence-BERT+Llama 3)无需 API 依赖,降低落地门槛;参数调优(chunkSize、overlap、topK)是提升效果的关键。
5.2 进阶优化方向(从入门到工业级)
-
检索优化:
- 混合检索:结合向量检索(语义相似)和关键词检索(精确匹配),提升召回率;
- 检索重排:用 Cross-Encoder 模型对检索结果重排,筛选最相关的 Chunk;
- 增量更新:支持知识库的新增 / 删除 / 修改,无需重新构建向量库。
-
文本处理优化:
- 文档预处理:清洗文档(去除页眉页脚、空白字符)、提取关键信息(标题、目录);
- 多模态支持:扩展文档加载器,支持图片、表格、PPT 等格式(需 OCR 提取文本)。
-
生成优化:
- Prompt 工程:优化 Prompt 模板(如加入 "回答要简洁""引用原文关键词" 等指令);
- 上下文压缩:当检索结果过多时,用大模型压缩上下文,避免超出窗口限制;
- 多轮对话:保存对话历史,支持基于历史上下文的连续问答。
-
工程化部署:
- 分布式向量库:将 Chroma 替换为 Milvus/Redis Cluster,支持大规模知识库;
- 性能优化:异步加载文档、批量生成向量、缓存高频检索结果;
- 监控告警:监控向量库存储量、检索响应时间、大模型调用成功率。
RAG 技术的落地,关键在于 "理论结合实践"------ 只有亲手搭建系统、调优参数、解决实际问题,才能真正掌握其核心逻辑。本文的实战项目可直接作为工业级应用的基础框架,在此基础上扩展进阶特性,即可满足企业级知识库问答的需求。
如果本文对你有帮助,欢迎点赞、收藏、转发!如果有疑问或进阶需求(如混合检索、多轮对话),欢迎在评论区交流~ 接下来我们将攻克 Spring AI 的另一核心技术 ------ 工具调用(Function Call),让大模型具备 "执行具体操作" 的能力!
