1 引子
为作性能工程的前置介入,性能建模分析推导完成后,可观性平台搭建完成后,针对后续的业务迭代对性能的影响,以新项目的架构设计是否符合性能诉求,需要不断的持续维护和优化,这个过程基本上与迭代的生产周期保持同步,甚至是一个长期的系统工程:不断优化,不断适配的过程。
2 针对已经完成的性能建模指标,该如何进行持续的推护
结合上述系列第一讲前置工程介入完成后,后续的性能工程模型数据如何持续进行维护并沉淀下来,以作为平台建设,AI智能诊断的数据仓库打下基础,仍然是一个系统工程,继续以系列1中的案例进行分析:
2.1 落地实施
基于系列一中 "订单创建链路性能可观测方案",监控指标的持续看护核心是避免 "监控部署后无人问津""指标过期失效""告警麻木"等现象,通过建立 "全生命周期管理 + 自动化运营 + 团队闭环" 机制,让指标始终服务于 "性能达标、资源可控" 的目标,在建立这套机制之前,得明确团队能够达成共识,基础支撑需要能够满足,如:监控平台,告警阀值的共识,及降躁工作的持续投入认知,以此共同以目标导向进行聚集:
首先:
需要明确持续维护的核心目标不是『一次监控部署』,对监控无需盯大盘,常规作法通过告警感知,机制确保,这需要前置条件为指标有效性-指标采集不中断、口径不失效(如线程池核心数指标始终能反映真实配置,不因代码迭代丢失);,告警精准性-无 "告警风暴"(如重复告警、无效告警),无 "漏告警"(如响应时间超阈值但未触发通知);,问题可预见性-过历史数据发现 "隐性性能退化"(如响应时间从 150ms 逐月升至 180ms),而非等故障发生;优化联动性-看护数据能反哺性能建模与资源配置(如发现连接池 100 冗余,可优化至 80 降低资源浪费)等
其次:
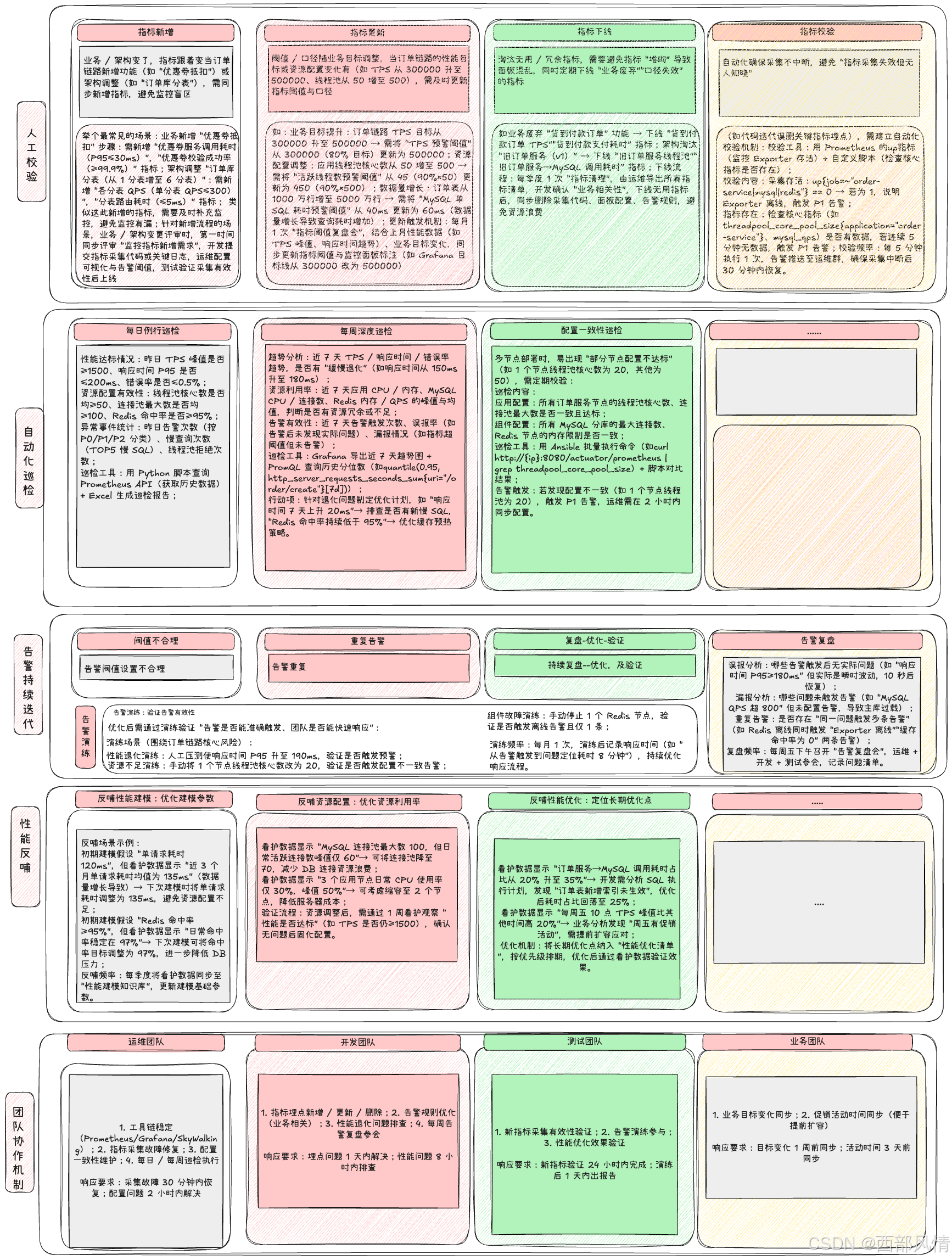
可 以从 指标新增,指标更新,指标下线,指标校验进行持续维护,人工介入
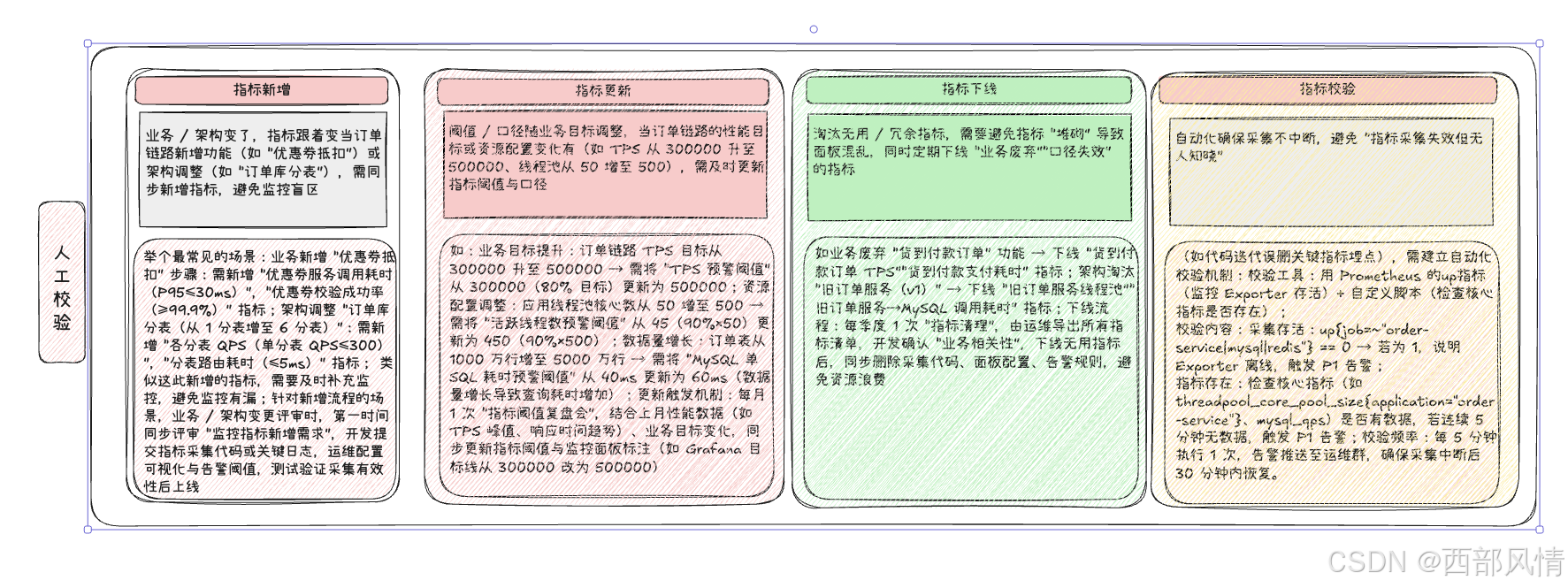
使用自动化机制替代人力(人工每天盯面板易遗漏问题,需通过 "脚本 + 工具" 实现自动化巡检,聚焦 "核心指标趋势、异常波动、配置一致性":),提升效率
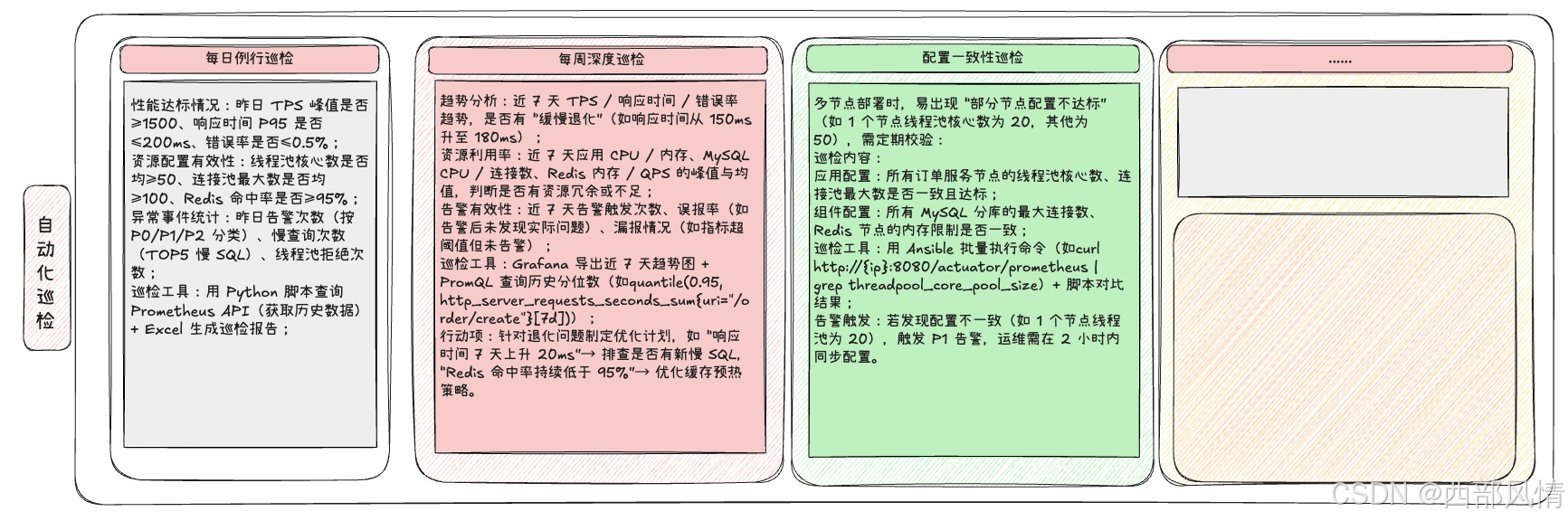
交付物:每日 9 点前推送《订单链路性能巡检日报》至技术群,示例如下:

也可以通过告警持续迭代(避免 "告警风暴" 与 "漏告警")
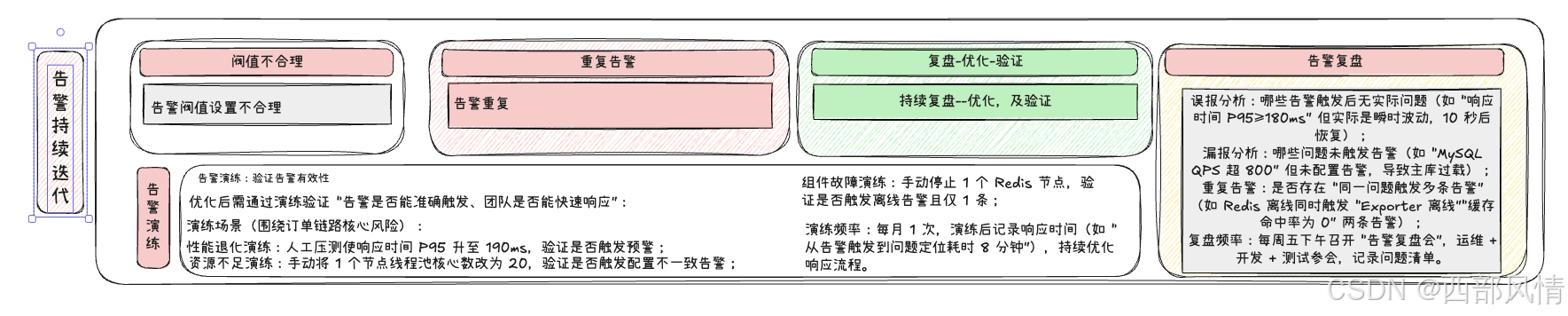
其中告警优化:针对性解决复盘问题
优化手段示例:

通过数据反哺(让看护数据服务于性能优化)
持续看护积累的历史数据,是优化性能建模、资源配置的重要依据,需建立 "数据 - 优化 - 验证" 的反哺闭环:
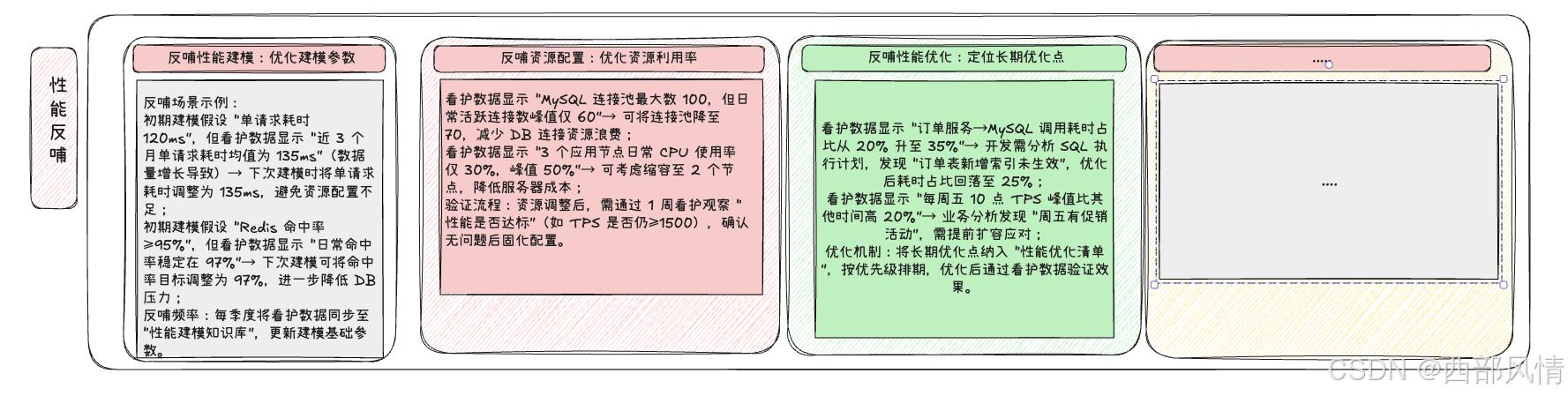
也可以通过团队协作机制(确保 "问题有人管、闭环有人追")
持续看护需跨团队协作,需明确 "责任分工、响应流程、闭环标准":
a. 责任分工:谁负责什么.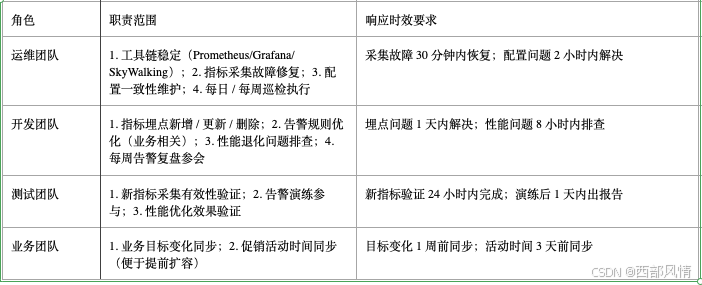
b. 响应流程:告警触发后怎么做
建立 "告警 - 排查 - 解决 - 复盘" 的闭环流程,以 "P0 告警(TPS≤1000)" 为例:
告警接收:运维 + 开发负责人收到电话 + 短信告警,5 分钟内确认;
初步排查:运维查看 Grafana 面板,定位是 "链路哪个节点耗时增加"(如 MySQL 耗时突增),10 分钟内反馈;
问题解决:开发排查具体原因(如慢 SQL),30 分钟内优化(如紧急创建索引);
效果验证:测试验证 TPS 是否恢复至 1500 以上,1 小时内确认;
复盘记录:24 小时内更新 "故障复盘文档",记录原因、解决过程、预防措施。
c. 闭环标准:确保问题不遗漏
时间闭环:P0 告警 2 小时内解决,P1 告警 4 小时内解决,P2 告警 1 个工作日内解决;
文档闭环:所有问题需记录至 "性能问题跟踪表",包含 "问题描述、原因、解决措施、验证结果";
预防闭环:针对重大问题(如 TPS 骤降),需制定 "预防措施"(如定期检查 SQL 索引),并纳入下次巡检内容。
七、总结:持续看护的核心是 "机制化 + 自动化 + 闭环"
监控指标的持续看护不是 "靠人盯",而是通过以下机制实现长期有效:机制化:建立 "指标生命周期、巡检、告警复盘" 的固定流程,避免 "随人员变动而中断";自动化:用脚本、工具替代人工巡检,提升效率,减少遗漏(如每日自动化巡检报告);闭环化:每个问题从 "发现 - 解决 - 验证 - 预防" 形成闭环,避免重复发生(如告警优化后演练验证)。
对订单创建链路而言,通过持续看护,能确保 "TPS≥1500、响应时间≤200ms" 的目标长期达标,同时让 "线程池≥50、连接池≥100" 的配置始终有效,最终实现 "性能稳定、资源可控、问题可预见" 的长期保障。
整体而言,可以用一大图进行概括: