1 引用
如何将前面介绍过的三篇系列的内容,能过平台化能力进行承载并高效执行落地,使性能工程的各个阶段有人跟进,有平台支撑,有数据支撑,有经验指导,这需要可持续集成平台进行产研高效流程,即性能工程效能平台;
针对 "性能建模、指标看护、模型反模式积累" 的推广落地需求,核心是打破 "开发管设计、运维管监控、知识碎片化" 的部门壁垒,通过 "产研一体化执行标准" 明确权责,"集成化平台" 承载工具与知识,"场景化知识传播" 统一认知,最终实现 "性能工作融入产研全流程、决策基于数据、知识可复用" 的目标。
1、第一步:构建产研一体化执行标准 ------ 明确 "谁在什么阶段做什么"
执行标准是产研协同的基础,需将 "性能建模、指标看护、模型反模式" 三大核心活动,拆解到产研全生命周期(需求→设计→开发→测试→运维→迭代),明确各阶段 "产研角色职责、核心动作、交付物、平台工具",避免 "边界模糊、责任推诿"。
- 产研全生命周期性能职责矩阵(核心框架)
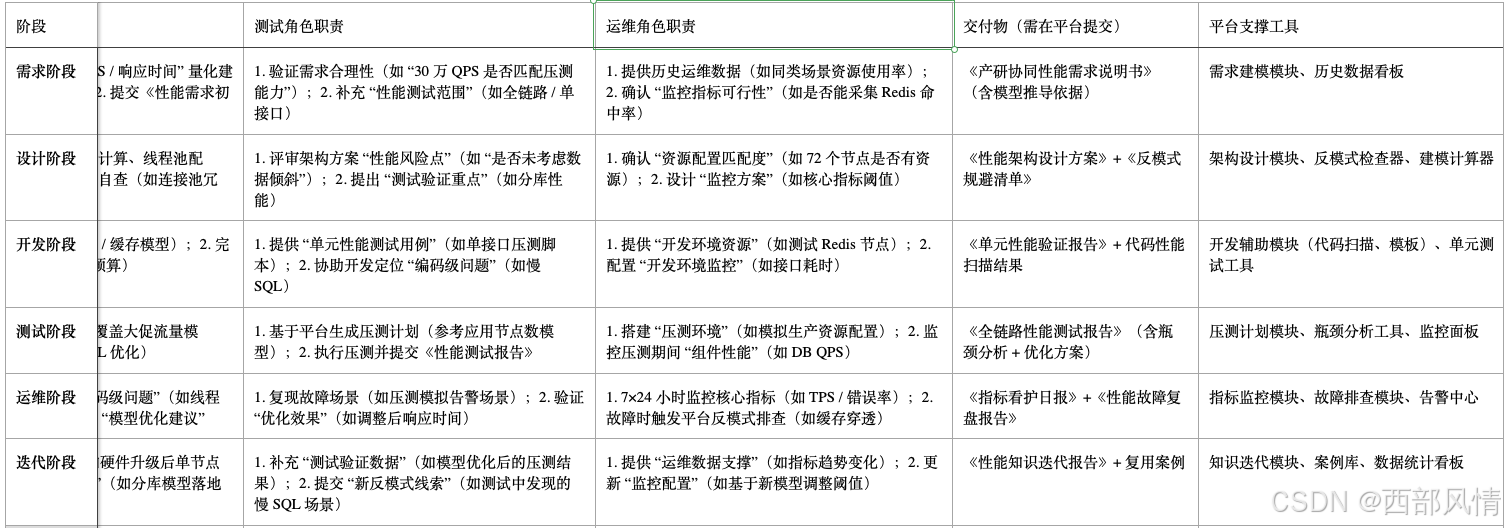
2、第二步:集成化平台建设 ------ 打造 "知识 + 工具 + 流程" 一体化载体
平台是标准落地的核心支撑,需整合 "性能建模工具、指标监控工具、模型反模式知识库",并打通产研现有工具链(如 Jira、Grafana、JMeter),实现 "数据不落地、流程不脱节、知识不孤立"。
1. 平台核心模块集成设计(打破工具孤岛)
(1)"知识 - 工具" 融合模块:让知识直接驱动工具
将 "模型反模式知识" 嵌入工具流程,避免 "知识在文档里、工具在别处" 的割裂:
建模计算器增强:输入 "业务需求(如 30 万 QPS)",自动关联 "TPS - 并发数模型" 计算参数,同时弹出 "同类场景反模式提醒"(如 "注意分库数据倾斜,参考 XX 案例");
反模式检查器集成:检查架构方案时,不仅提示 "存在连接池过度冗余",还自动推荐 "连接池配置模型(核心数 = 写线程数 ×1.2)",支持 "一键生成优化建议";
指标监控面板:展示 "TPS / 响应时间" 时,标注 "参考模型阈值(如 TPS 上限 30 万)",指标异常时自动关联 "反模式排查指南"(如 "响应超时→检查是否触发慢 SQL 反模式")。
(2)"产研流程" 打通模块:让数据跨角色流转
对接产研现有工具,实现 "数据从开发设计→测试压测→运维监控" 全链路贯通:
与 Jira 打通:开发在 Jira 创建 "架构设计任务" 时,自动触发平台 "反模式检查",检查结果同步至 Jira 任务,未通过则任务无法关闭;
与 Grafana 打通:运维在平台配置 "监控指标阈值"(如响应时间≤300ms),自动同步至 Grafana,告警触发时,Grafana 告警信息同步至平台 "故障中心",并推送至开发 / 测试角色;
与 JMeter 打通:测试在平台生成 "压测计划"(参考应用节点数模型),自动导出 JMeter 压测脚本,压测结果同步回平台,生成 "性能测试报告"。
(3)"协同办公" 模块:让产研高效沟通
解决 "跨角色沟通低效" 问题,提供专属协同功能:
性能协同看板:实时展示 "各阶段性能任务进度"(如 "设计阶段反模式检查未完成"),标注 "责任人 + 超时预警",支持跨角色评论(如运维评论 "分库数需考虑未来 3 个月数据增长");
故障协同室:指标异常时,自动创建 "故障协同室",拉取开发(代码)、测试(压测)、运维(监控)相关人员,支持 "共享屏幕 + 日志上传 + 方案记录",故障复盘报告自动生成并同步至平台;
知识问答广场:按 "产研角色" 分类展示问题(如开发问 "线程池模型在云原生下是否适用",运维问 "指标堆砌反模式如何优化监控面板"),专家团 24 小时内回复,回复关联知识文档。
3、第三步:场景化知识传播 ------ 让产研团队 "懂标准、会使用"
知识传播需摆脱 "文档宣讲" 的传统模式,结合产研角色的实际工作场景,通过 "案例化、互动化、实战化" 方式,让标准和知识 "听得懂、用得上"。
1. 分角色知识传播体系(聚焦 "痛点 + 解决方案")
(1)开发团队:聚焦 "建模落地 + 问题解决"
传播形式:
"实战工作坊":模拟 "秒杀 30 万 QPS" 场景,带领开发用平台建模计算器生成分库数 / 线程池配置,通过反模式检查器规避 "连接池冗余",最后输出可落地的架构方案;
"踩坑案例库":收集开发常见问题(如 "分库后数据倾斜导致 DB 瓶颈"),附 "平台模型优化前后对比"(如 "调整哈希规则后,单库 QPS 从 1500 降至 1000"),嵌入开发 IDE 插件,实时推荐;
效果验证:新开发通过 "建模认证考试"(用平台完成某场景建模)方可参与核心项目,确保 "会用标准、会用工具"。
(2)测试团队:聚焦 "压测设计 + 瓶颈验证"
传播形式:
"压测实战营":基于平台 "压测计划模块",指导测试从 "模型推导压测目标→生成脚本→执行压测→定位瓶颈" 全流程操作,重点讲解 "如何用反模式库验证压测场景(如是否覆盖缓存穿透)";
"测试数据看板":在平台展示 "各项目性能测试通过率",标注 "未通过原因(如未参考模型导致压测不达标)",组织测试团队分析 "如何优化压测方案";
效果验证:测试提交的《性能测试报告》需在平台标注 "参考模型 / 反模式",否则需补充说明,确保 "测试动作对齐标准"。
(3)运维团队:聚焦 "指标监控 + 故障快速响应"
传播形式:
"监控配置实操课":演示 "基于平台模型配置监控阈值(如 TPS=30 万→告警阈值设 27 万)""基于反模式优化监控面板(如核心指标不超过 20 个)",同步提供 "监控配置模板";
"故障演练":模拟 "Redis 离线触发多告警" 场景,运维通过平台 "故障排查模块" 定位根因(参考 "告警链式风暴反模式"),并协同开发 / 测试解决,演练结果纳入运维考核;
效果验证:运维的《指标看护日报》需在平台提交,包含 "指标异常分析(是否关联反模式)""优化建议(是否参考模型)",确保 "监控动作对齐标准"。
2. 跨角色知识协同传播 ------ 打破认知壁垒
"产研性能圆桌会":每月组织开发、测试、运维代表,围绕 "某项目性能问题" 展开讨论(如 "大促响应超时"),还原 "设计时模型复用→测试时压测验证→运维时指标监控" 全流程,分析 "跨角色协同断点"(如 "开发未告知测试分库规则,导致压测数据倾斜"),输出 "协同优化方案" 并更新至执行标准;
"知识复用明星案例":每季度评选 "产研协同优秀案例"(如 "某订单项目通过模型复用,开发设计→运维监控仅用 5 天,性能故障 0 次"),在公司技术大会分享,标注 "各角色核心动作 + 平台工具使用技巧",强化 "协同创造价值" 的认知。
4、第四步:平台落地执行与保障 ------ 确保 "标准不流于形式"
- 分阶段落地路径(风险可控,逐步推广)
阶段 1:试点验证期(1-2 个月)
目标:选择 1-2 个核心项目(如订单创建链路迭代),验证标准与平台的可行性;
核心动作:
对试点项目的产研团队(开发 3-5 人、测试 2 人、运维 2 人)进行 "标准 + 平台" 专项培训;
试点项目全流程按标准执行,平台记录 "各阶段交付物提交率、工具使用率";
每周召开 "试点复盘会",优化标准(如 "开发反馈设计阶段反模式检查太耗时→简化低风险检查项")、完善平台(如 "增加压测脚本一键导出功能")。
阶段 2:推广期(2-3 个月)
目标:覆盖 80% 核心业务线(如订单、商品、支付);
核心动作:
组建 "产研性能推广组"(含试点团队代表),负责各业务线的标准培训与平台指导;
在公司研发流程中明确 "核心业务必须按产研性能标准执行",非核心业务鼓励参考;
平台新增 "业务线性能看板",展示各业务线 "标准执行率(如交付物提交率 90%)、知识复用率(如模型复用 8 次)",按月排名公示。
阶段 3:固化期(3-6 个月)
目标:产研开发部署上线常态化执行落地,并常态化卡点执行