概述
系列前作,请参考快手开源模型/项目介绍。
LivePortrait
论文,项目主页,开源(GitHub,17.4K Star,1.8K Fork)。
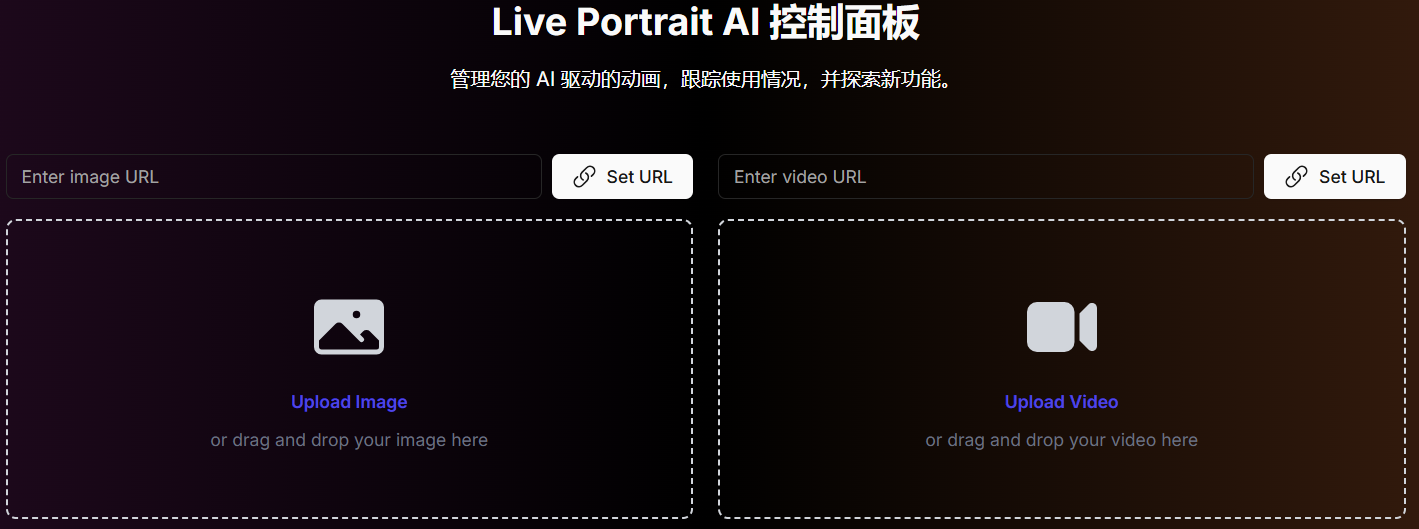
支持在线试玩的网站,输入图片和视频URL,等待大致1分钟即可生成视频:
- 官网1:https://liveportrait.org
- 官网2:https://liveportrait.app
- 官网3:https://liveportraitai.ai
- 其他:https://liveportrait.wingetgui.com
- HF
FacePoke
官网,由Julian Bilcke开发并开源(GitHub,902 Star,98 Fork,项目于2025.11.1归档)、跨平台、基于LivePortrait框架,可实现实时面部表情编辑的AI应用。
原理:利用先进的AI算法分析静态图像中的面部特征。用户随后可实时操纵这些特征,调整表情、角度,甚至细微的情感变化。结果是一种动态、交互式的体验,以前所未有的方式为静态图像注入生命。
VANS
瞄准以下三个层面的问题:
- 模态局限:传统的下一事件预测(Next Event Prediction,NEP)任务,答案始终是文本。但文字在描述复杂的物理互动、动作序列和场景变化时,往往不够直观和高效。VANS开创视频化下一代事件预测的新范式,让AI能用更符合人类认知方式的动态视频来展示答案。
- 任务挑战:生成视频作为答案/答复,要求模型必须具备多模态理解、因果推理和高质量视频生成等能力,这对现有模型来说是巨大挑战。
- 协同困难:一个直观的方案是用视觉语言模型(VLM)生成文本描述,再交由视频扩散模型(VDM)生成视频。但问题是,这两个模型通常独立训练:VLM只追求文本准确,不知道自己的描述能否被顺利可视化;VDM则要费力协调文本指令和输入视频画面,两者存在
语义-视觉鸿沟。
通过一个核心框架和一项关键算法来应对上述挑战。
- 核心框架:模型将VLM和VDM融合在一个框架内。
- 理解与推理:VLM负责理解输入视频和问题,并生成一个描述预测事件的文本字幕。
- 可视化与生成:VDM以VLM生成的字幕和输入视频的视觉线索为条件,生成最终答案视频。
- 关键创新(Joint-GRPO):为解决VLM和VDM的协同问题,团队提出联合分组相对策略优化算法,两阶段RL策略:
- 阶段一:冻结VDM,优化VLM。奖励函数不仅鼓励VLM生成文本准确的字幕,还要求这个字幕能被VDM读懂并生成视觉连贯的视频。这促使VLM学会生成易于可视化的描述。
- 阶段二:冻结优化好的VLM,优化VDM。奖励函数要求VDM生成的视频既要忠实于VLM的字幕内容,又要与输入视频的视觉上下文(如场景、物体)保持连贯,防止它忽略指令或简单复制输入画面。
架构
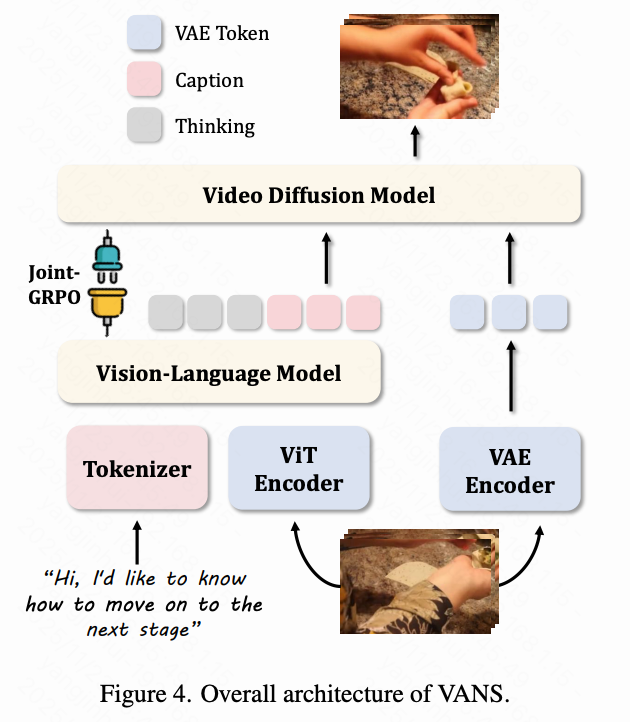
输入问题经令牌化后,与输入视频的高级ViT视觉特征共同输入VLM。要求VLM执行基于指令的推理,生成描述预测下一事件的文本字幕,作为VDM的语义引导。为确保视觉一致性,VDM同时以生成的字幕和低级视觉线索为条件------后者通过VAE对n个采样输入帧进行令牌化提取,随后将这些令牌拼接至VDM的条件潜在空间;在生成新场景时能保持细粒度视觉对应关系。
现有NEP数据集因视频质量欠佳和缺乏多样化指令性问题,无法直接适用于VNEP(Video Next Event Prediction)任务。为弥补这一空白,也为训练和评估模型,团队构建VANS-Data-100K数据集,包含10万组(输入视频,问题,输出视频)三元组,包含3万个流程性样本和7万个预测性样本,覆盖流程性和预测性场景。
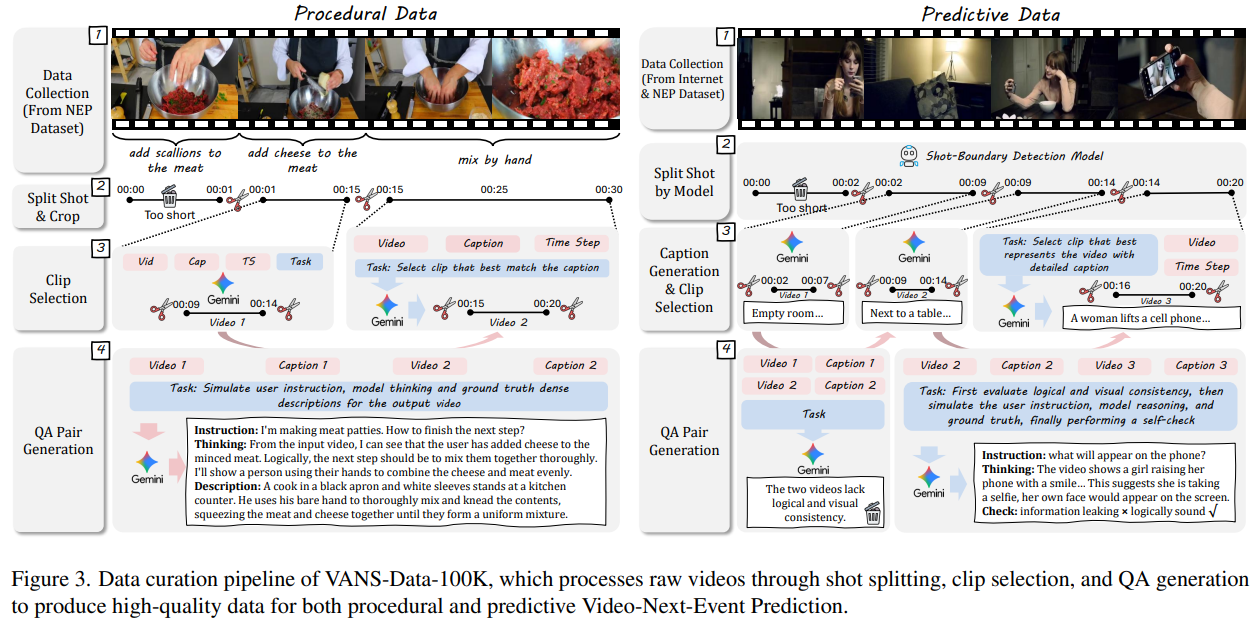
数据构建流程包含四个阶段:
- 原始数据收集:从两个不同来源收集数据以覆盖流程性与预测性场景:流程性数据采用COIN和YouCook2的高清视频以确保步骤演示的清晰度;预测性数据则采集自通用场景数据集和短片,这些资源富含叙事性与因果动态。
- 镜头分割:将原始视频分割为连贯片段:流程性视频采用真实时间戳进行分割,预测性视频则使用镜头边界检测模型。本文过滤掉短于3秒的片段以确保动作完整性。
- 片段筛选:采用Gemini-2.5-Flash作为自动质量过滤器筛选最优3-5秒片段:对于流程性数据,选择与给定字幕最匹配的片段;对于预测性数据,首先生成每个片段的详细字幕,确保所选片段兼具高质量与语义代表性。
- 问答对生成:使用Gemini-2.5-Flash基于视频-字幕序列生成问答对。该VLM模拟多样化问题------聚焦流程性任务的逻辑下一步骤与预测性任务的假设性场景,同时生成思维链推理与真实答案,并通过自检机制确保逻辑严谨性且避免信息泄露。更多数据集细节见附录A。
意义在于:
- 开辟新方向:为AI问答系统开辟
视频作为答案的全新范式,让AI不仅能告诉你接下来会发生什么,还能直接演示给你看,使人机交互更加直观和生动; - 推动技术边界:推动AI在时序理解、因果推理和动态视觉生成方面的深度融合,是向构建能够真正理解并模拟物理世界的AGI迈出的重要一步;
- 应用潜力巨大:在教育(模拟实验步骤)、内容创作(快速生成视频素材)、机器人模拟训练等领域都具有广阔的应用前景。
SeamlessFlow
论文,
技术创新:
- 引入独立数据平面层,其核心是轨迹管理器(Trajectory Manager),彻底解耦RL训练和智能体实现。轨迹管理器在智能体与语言模型服务之间静默记录所有交互细节,包括输入输出及多轮对话的分支结构,从而构建完整轨迹树。不仅避免重复计算、提升存储效率,还支持精确的在线与离线策略区分。
- 推理管理器(Rollout Manager),实现对模型更新与资源调度的无感控制,使得智能体无需适配训练框架即可实现任务的无缝暂停与恢复,大幅提升系统灵活性与训练效率。
- 标签驱动的资源调度范式,通过为计算资源赋予如训练或推理等能力标签,统一集中式(Colocated)与分布式架构(Disaggregated)的资源管理模式。持时空复用机制,使得具备多标签的机器可根据任务需求动态切换角色,将GPU闲置率降至5%以下,彻底缓解传统架构中的流水线空闲问题。
HiPO
系列模型包括:
UniDex和UniSearch
共同目标是将搜索从传统关键词匹配升级到智能的语义理解。在技术上共享同一个基石:视频语义ID(SID)。可将语义ID理解为给每一个视频或直播间发放的语义身份证。UniDex利用它来高效检索已有内容,而UniSearch则更进一步,能够直接生成目标内容的语义ID,再进行匹配。因此,两项技术共同构成快手搜索深语义理解 + 智能生成的双引擎驱动。
| 维度 | UniDex(统一语义倒排) | UniSearch(统一生成式搜索) |
|---|---|---|
| 核心目标 | "找得准、找得快",侧重判别与检索 | 直接"生成"或"预测"用户想要的内容,侧重生成与推荐 |
| 技术范式 | 判别式:重构搜索引擎的索引大脑,用语义ID替代关键词 | 生成式:端到端生成符合用户需求的答案,再匹配内容 |
| 主要应用场景 | 主搜索场景,尤其是处理模糊、抽象的长尾查询 | 直播搜索等对时效性要求极高的场景 |
| 工作方式比喻 | 过目不忘的天才图书管理员,通过"语义身份证"理解内容 | 从买菜到上桌全包的全能主厨,直接为你"现做"答案 |
| 关键创新 | 提出UniTouch和UniRank,用模型生成的语义ID进行索引和排序 | 将视频编码和搜索生成放在一个框架内联训,实现真端到端 |
| 官方公布效果 | 响应速度提升25%,能多找出25%的优质"漏网之鱼" | 带来近2年最大的直播间进间数收益(+3.31%) |
UniDex
论文。为让搜索能像推荐一样懂用户、懂视频,快手团队尝试一条新路径:用更智能的语义表征替代传统 Term,用能理解、能生成的模型重构整个搜索链路。以视频语义ID表征为基础,从判别和生成两大范式出发:
- 首创Model-based倒排方案UniDex,全量替换Term-based倒排,大幅降低系统存算资源的同时,将响应速度提升25%;
- 创新生成式搜索架构UniSearch,首次实现编码和生成联训,打造真正的端到端生成式搜索方案,并在直播搜索场景中创造近两年最大的直播间进间数收益。
倒排索引的问题,如离线资源消耗大、动态更新成本高以及泛化能力不足等。
业界倒排系统通常由两个核心模块组成:召回(Touch)模块和排序(Rank)模块。Touch模块基于倒排索引进行Term级检索获取候选集,Rank模块计算Query-候选集打分。传统倒排召回包含多路人工Touch方法(同义词扩展、Term省略、实体归一等),以及数十种策略/模型特征等启发式规则的Rank方法。UniDex通过提出UniTouch和UniRank,分别统一传统倒排的Touch和Rank模块,避免繁复的人工设计。在保障相关性和长尾需求的情况下,大幅节省链路资源消耗,为搜索体验带来增益。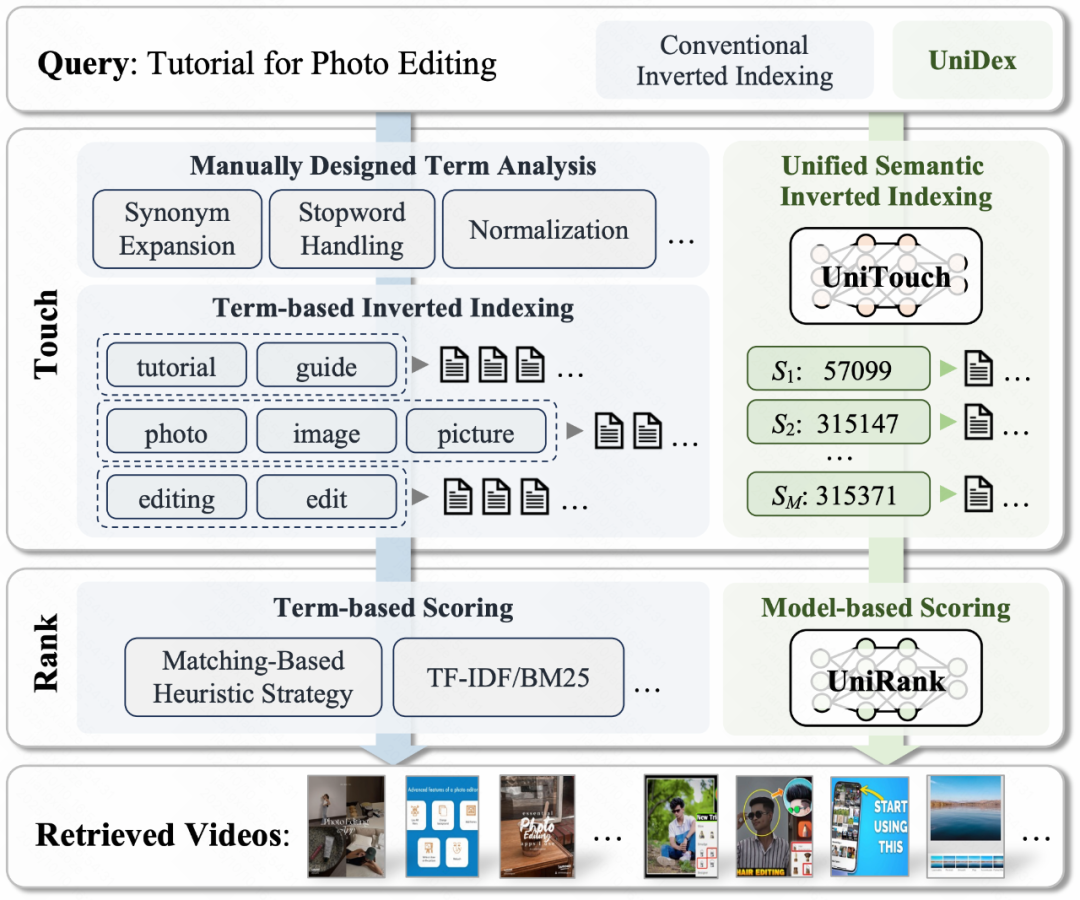
UniDex完整架构流程图:
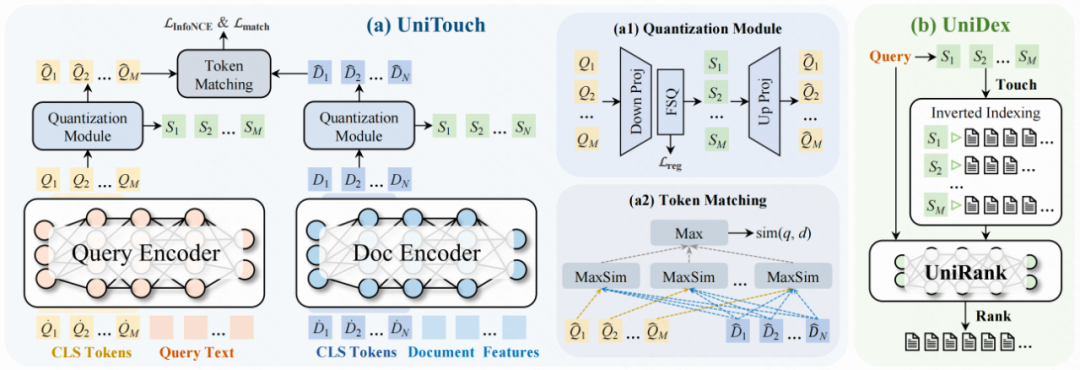
UniTouch
(一)语义编码
- FSQ量化:以Query为例,Query侧拼接多组可学习的Token,经过Encoder编码产出多组稠密向量,经过FSQ量化为离线语义ID。
- EWGS梯度优化:FSQ采用的STE方法未考虑量化误差。UniDex构建FSQ-EWGS对量化梯度的回传过程进行优化,提高量化网络训练的稳定性和准确性。
- Token-Matching 机制:构建Token-Matching模块驱动模型强化训练/检索一致性。
该方法从本质上更好地保持UniTouch模型训练阶段与检索阶段之间的一致性,与倒排索引范式高度契合。倒排索引的核心逻辑是:Query端与Doc端任一SID匹配即可召回;而Mean或Sum方法要求Query端所有SID均需与文档端SID达到一定相关度才能检索,这与倒排机制相悖。
(二)学习策略
- Contrastive Learning:学习搜索链路的排序逻辑,提升模型的排序性能。采用分段可学习的ListWise InfoNCE Loss,将Query对应下低于当前视频档位的其他视频作为负样本,同时在同Batch内采样随机负例。
- Matching Loss:引入针对高档位相关正例的Matching损失目标,强化模型使Query与高相关视频产出相同SID的能力。
- Quantization Regularization:引入二进制量化正则项,以缓解TensorRT推理加速带来的浮点精度(Float)损失,二进制量化正则损失(Binary-Quant RegLoss)越小作为目标。
UniRank
(一)语义编码
- UniRank框架:UniRank采用与UniTouch相似的双塔架构设计。二者的核心差异在于:UniRank以提升语义匹配准确度为核心目标,将Query与视频的语义信息分别编码为多个128维稠密向量(Dense Vector),并执行Token-level细粒度交互。
- Token-level Interaction:通过拼接多组可学习CLS头,实现Token-level延迟交互,进而完成Query与视频的细粒度语义交互。Token-level Interaction驱动Query侧所有语义Token向量均参与最终排序得分的决策过程,强化模型的表征能力。
(二)学习策略
- Pointwise Relevance Loss:蒸馏精排模型的相关性得分,提升模型的相关性判别准确度。
- InfoNCE Loss:同UniTouch的对比损失,学习搜索链路序,提升排序能力。
UniSearch
论文。
直播搜索是快手重要的搜索流量来源,也是短视频应用场景中的新业务领域,为应对直播业务场景高时效性要求的挑战,快手搜索技术团队设计统一的生成式搜索架构,提升用户体验并优化搜索效率。
架构
与以往依赖多阶段模型的级联系统不同,采用统一架构,在同一框架内完成端到端训练与推理,消除各阶段目标之间的不一致性,降低系统复杂度。
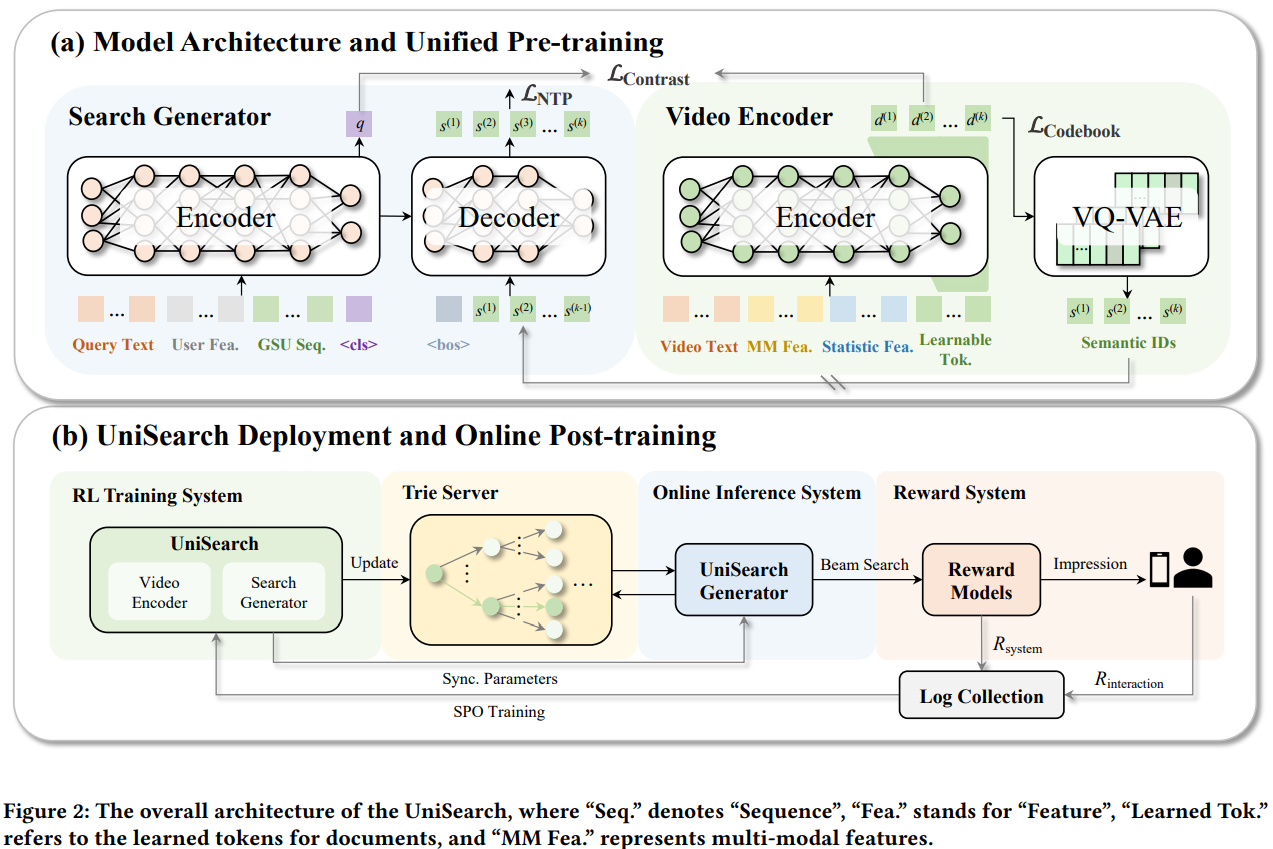
UniTouch建模:真端到端
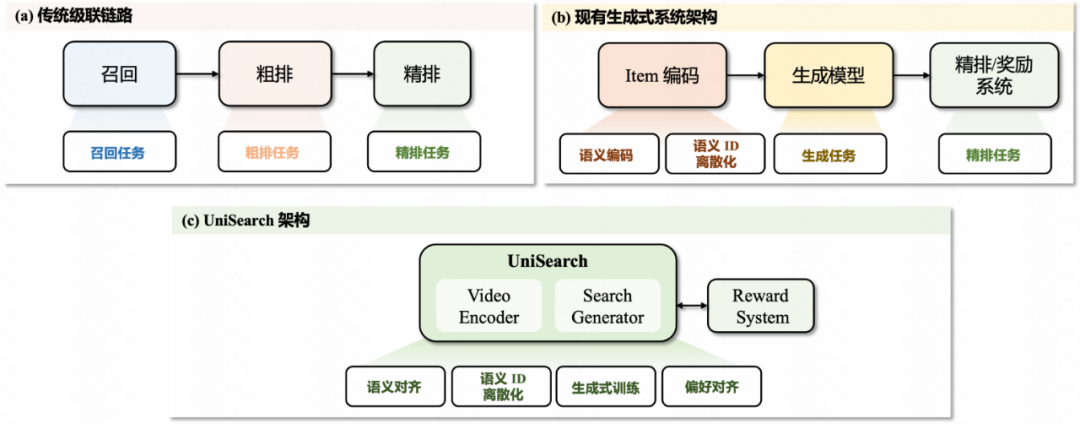
先前的生成式搜推模型(如OneRec)采用两阶段训练,item离散化表示和item生成任务,这会导致两阶段目标不一致。为此,设计真端到端训练架构UniSearch,将Search Generator和Video Encoder统一到一个训练框架。
Search Generator采用Encoder-Decoder架构,输入为搜索词、用户特征序列等。使用<cls>来表征query侧整体语义向量。Decoder侧自回归地预测出视频的语义ID。
Video Encoder,为每个视频学习潜在embedding表示和语义ID。Encoder的输入为视频侧特征,输出为Learnable Token对应的语义序列表征。同时Video Encoder有一个用于离散化的VQ Codebook,用于将连续的Embedding转化为语义ID。
通过联训Search Generator和Video Encoder,UniSearch能够缓解item生成和item表征之间的鸿沟,实现整个生成搜索框架的统一与连贯性。
离线训练:残差渐进式
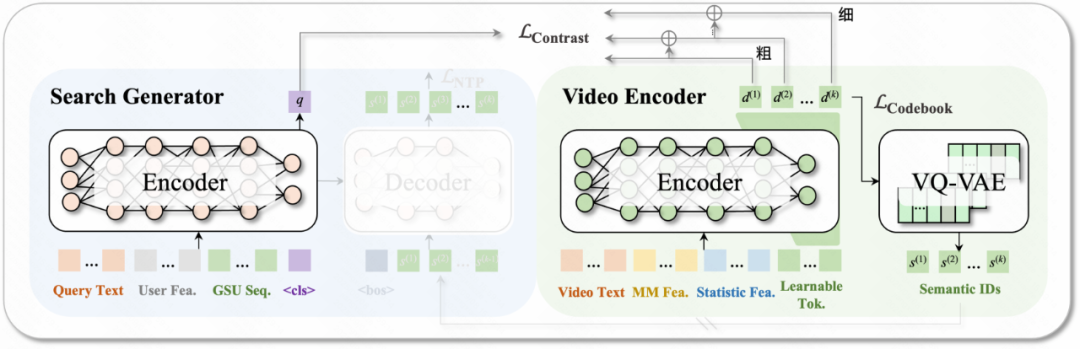
三部分:
- 残差对比语义学习:将传统生成式工作中的采用类似于RQ-Kmeans的残差聚类过程,建模到语义学习的过程中:与采用两阶段残差聚类的残差量化方法(如RQ-Kmeans)相比,该方法实现端到端的训练,避免由分步训练带来的目标不一致问题。
- 渐进式粗到细建模目标:query-video残差对比学习的建模目标模拟级联链路由
召回->粗排->精排的漏斗结构,构建一种层次化的语义刻画模式。具体来说:学习类召回的分档逻辑,学习类粗排的分档逻辑,...,学习更精细化的精排分档逻辑。 - 码本离散化学习:与依赖后聚类方法的工作不同,采用VQ-VAE方法,在训练过程中联合更新码本(codebook)。对于每个语义向量,VQ-VAE编码器在可学习的码本中执行最近邻查找,获得量化后的及其对应的语义,同时让量化向量和原语义向量相互逼近。引入SimVQ策略,即在量化层之后增加一个线性层协同优化,避免码本坍塌问题。借助VQ模块,视频可以以完全端到端的方式被离散化为语义ID,从而避免离线聚类所带来的不一致性问题。生成约束较为常规,在这里额外采用一种拒绝采样的训练策略,即根据标签判断出的低质量样本会被过滤掉,并且针对不同质量等级的样本,会相应地对其损失进行加权。
UniSearch整体的训练目标为上述各个分量的加和,实现query-video语义对齐、视频离散化以及生成的联合优化。
在线训练:搜索偏好强化学习
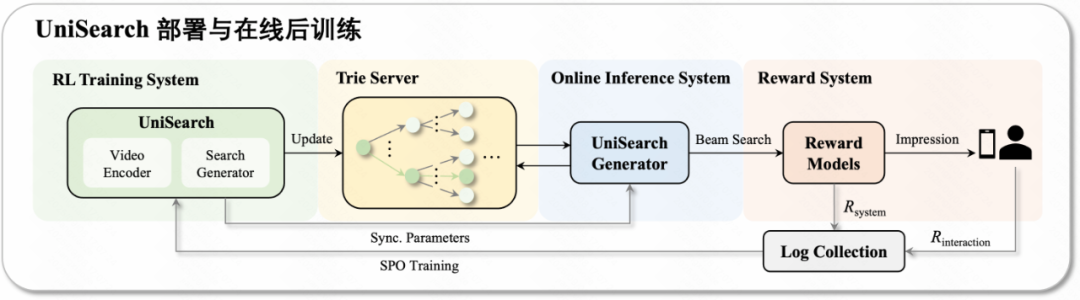
在离线训练结束后,UniSearch 线上模型通过接收当前搜索系统对生成结果的评估以及用户的真实反馈,将学习搜索偏好下的生成模式。整个Reward系统包括2部分:线上精排奖励、用户行为反馈奖励。
类似于GRPO,应用搜索业务感知的强化学习优化 Search Preference Optimization (SPO) 来进一步提升生成性能。
推理:动态Trie约束
直播搜索具有明显的时效性特性,在不同时刻,直播间的表征会发生剧变,这就需要对直播码本进行监听与实时更新。
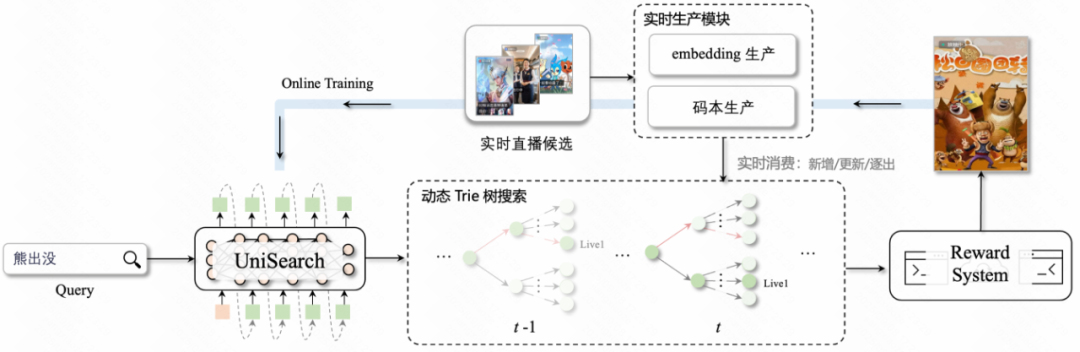
链路主要由3部分构成:
- 生成模型:采用encoder-decoder架构的模型,实时接受Query和上下文输入,产出码本概率分布;
- 动态 Trie 树构建与搜索:首先构建码本生产服务,以 1 min 的时间窗口来更新直播间表征,实时生产直播间 id 映射到最新码本的数据流;动态 Trie 树模块实时监听数据流,更新当前有效直播间的码本路径;生成模型产出的码本概率分布,在动态 Trie 树上进行beamsearch搜索,保证了生成结果的合法性。
- Reward System:实时地对生成模型的产出进行奖励,用于指导模型的在线训练。