摘要 :随着社交媒体的普及,微博等平台成为了公众表达意见、宣泄情感的重要场所。海量的用户评论数据中蕴含着极具价值的舆情信息。本文介绍了一个基于Python数据挖掘技术的微博情感分析及话题追踪系统。该系统利用机器学习(XGBoost、随机森林等)和深度学习(MLP)算法对微博评论进行情感倾向判断,并结合Flask Web框架开发了可视化的舆情监控平台,实现了单条文本分析、批量历史记录管理、特定话题的舆情追踪及可视化展示功能。
关键词:情感分析;数据挖掘;NLP;Flask;XGBoost;LSTM;话题追踪
系统演示视频:https://www.bilibili.com/video/BV1pkSiBPEfe/
1. 项目背景与意义
在互联网大数据时代,网络舆情对社会事件的发展有着重要影响。如何从海量的碎片化文本中快速提取公众的情感倾向,追踪热点话题的舆论走向,对于企业品牌监控、政府舆情引导以及社会治理都具有重要意义。
本项目旨在构建一个自动化的情感分析系统,通过自然语言处理(NLP)技术对中文微博文本进行清洗、特征提取和分类,并以Web应用的形式提供友好的用户交互界面,帮助用户实时掌握舆情动态。
2. 系统总体架构
本系统采用 B/S 架构,后端基于 Python Flask 框架,前端使用 Bootstrap 进行响应式布局。核心数据处理流程包括:
-
数据层:使用 SQLite 存储用户信息、情感分析记录和话题追踪配置;使用 CSV 文件存储训练数据集。
-
算法层:
- 预处理:Jieba分词、去停用词、正则清洗。
- 特征工程:TF-IDF 文本向量化。
- 模型库:集成 Logistic Regression, Random Forest, XGBoost, MLP 以及 LSTM 深度学习模型。
- 应用层:提供用户认证、仪表盘、实时分析、历史查询、话题管理和数据可视化功能。
3. 数据挖掘与算法建模
3.1 数据集与预处理
项目使用包含 10万+ 条微博评论的 `weibo_senti_100k.csv` 数据集,标签分为 0 (负面) 和 1 (正面)。
数据清洗关键代码:
python
import jieba
import re
def preprocess_text(text):
# 1. 移除特殊字符和数字,只保留中文和字母
text = re.sub(r'[^\u4e00-\u9fa5a-zA-Z]', ' ', str(text))
# 2. 移除多余空格
text = ' '.join(text.split())
# 3. Jieba分词
words = jieba.lcut(text)
# 4. 过滤停用词和短词
stop_words = {'的', '了', '在', '是', '我', '有', '和', '就', '不', ...}
words = [word for word in words if len(word) > 1 and word not in stop_words]
return ' '.join(words)样本标签分布:
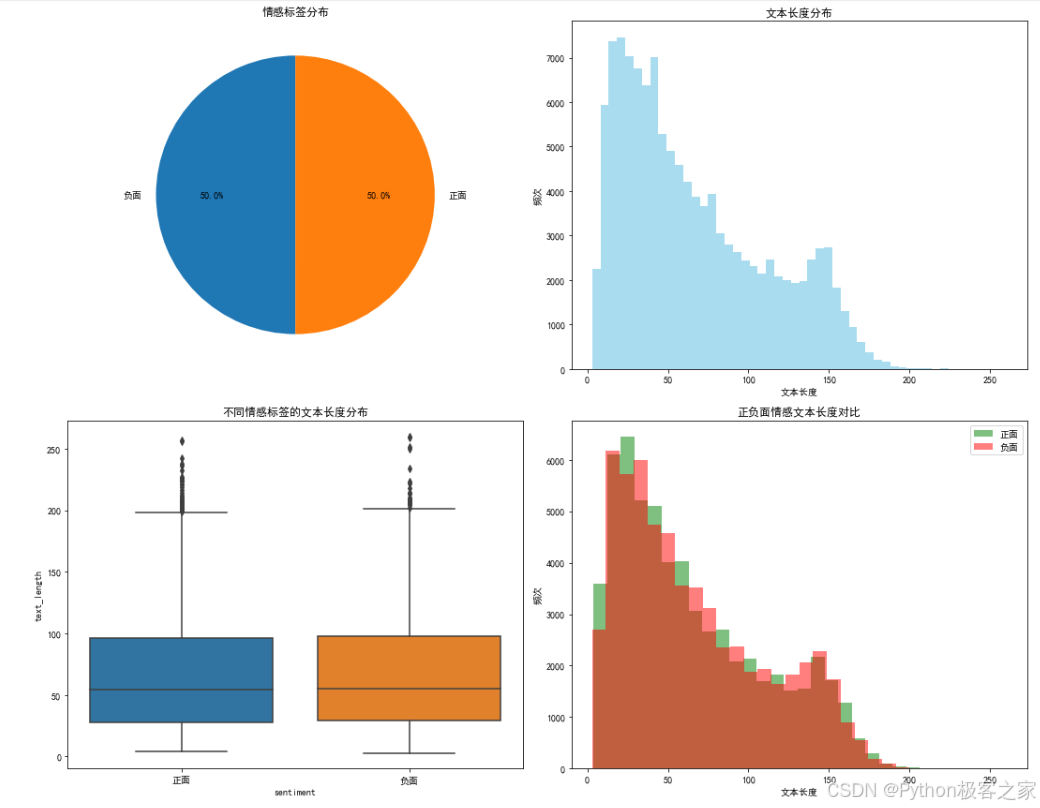
中文分词与可视化:
python
# 中文分词
def segment_text(text):
"""
中文分词函数
"""
if pd.isna(text) or text == "":
return []
# 使用jieba分词
words = jieba.lcut(text)
# 过滤停用词和短词
stop_words = {'的', '了', '在', '是', '我', '有', '和', '就', '不', '人', '都', '一', '一个', '上', '也', '很', '到', '说', '要', '去', '你', '会', '着', '没有', '看', '好', '自己', '这'}
words = [word for word in words if len(word) > 1 and word not in stop_words]
return words
print("开始中文分词...")
df['segmented_words'] = df['cleaned_review'].apply(segment_text)
df['segmented_text'] = df['segmented_words'].apply(lambda x: ' '.join(x))
print("分词完成!")
print("分词示例(前3条):")
for i in range(3):
print(f"原文: {df.iloc[i]['cleaned_review'][:50]}...")
print(f"分词: {df.iloc[i]['segmented_text'][:50]}...")
print("-" * 50)
3.2 特征提取 (TF-IDF)
使用 `sklearn.feature_extraction.text.TfidfVectorizer` 将分词后的文本转换为向量。
python
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(
max_features=5000, # 保留词频最高的5000个词
ngram_range=(1, 2), # 使用1-gram和2-gram
min_df=2, # 忽略出现频率极低的词
max_df=0.95 # 忽略出现频率极高的通用词
)
X = vectorizer.fit_transform(corpus)3.3 模型训练与对比
项目实现了多种模型的训练与评估。
3.3.1 传统机器学习模型
通过 `simple_model_training.py` 脚本训练了逻辑回归、随机森林、XGBoost 和 MLP。其中 **XGBoost** 通常表现最佳,具有较高的准确率和泛化能力。
python
# XGBoost 模型配置
from xgboost import XGBClassifier
model = XGBClassifier(
n_estimators=100,
max_depth=6,
learning_rate=0.1,
random_state=42,
eval_metric='logloss'
)
model.fit(X_train_tfidf, y_train)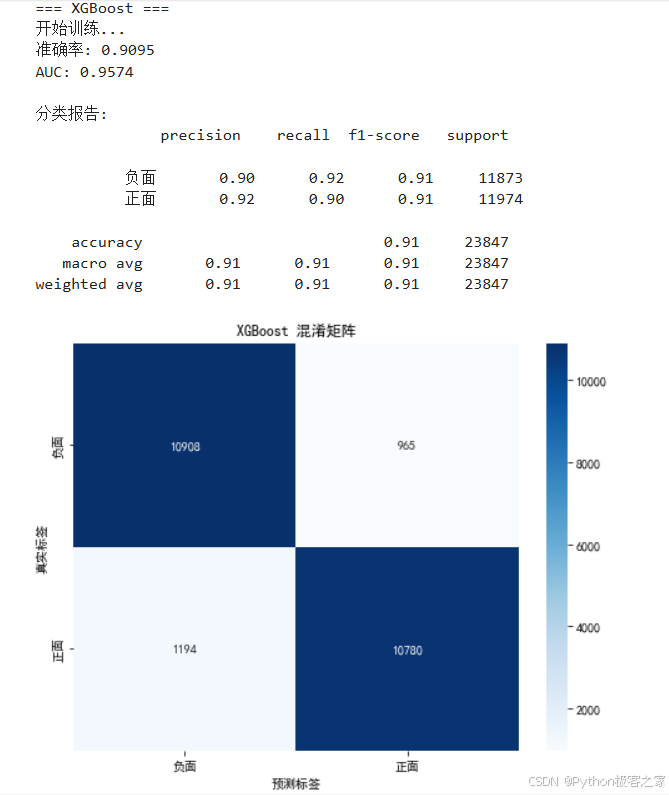
3.3.2 深度学习模型 (多层感知机)
python
# 标准化特征(对于神经网络很重要)
scaler = StandardScaler(with_mean=False) # 稀疏矩阵不能计算均值
X_train_scaled = scaler.fit_transform(X_train_tfidf)
X_test_scaled = scaler.transform(X_test_tfidf)
# 多层感知机(MLP)模型
mlp_model = MLPClassifier(
hidden_layer_sizes=(128, 64), # 两个隐藏层
activation='relu',
solver='adam',
alpha=0.001,
batch_size='auto',
learning_rate='constant',
learning_rate_init=0.001,
max_iter=200,
random_state=42,
early_stopping=True,
validation_fraction=0.1
)3.3.3 模型对比
python
# 模型性能对比
models_performance = {
'逻辑回归': {'accuracy': lr_acc, 'auc': lr_auc},
'随机森林': {'accuracy': rf_acc, 'auc': rf_auc},
'XGBoost': {'accuracy': xgb_acc, 'auc': xgb_auc},
'多层感知机': {'accuracy': mlp_acc, 'auc': mlp_auc}
}
# 创建性能对比图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# 准确率对比
models = list(models_performance.keys())
accuracies = [models_performance[model]['accuracy'] for model in models]
aucs = [models_performance[model]['auc'] for model in models]
ax1.bar(models, accuracies, color=['skyblue', 'lightgreen', 'orange', 'pink'])
ax1.set_title('模型准确率对比')
ax1.set_ylabel('准确率')
ax1.set_ylim(0.8, 1.0)
for i, acc in enumerate(accuracies):
ax1.text(i, acc + 0.005, f'{acc:.4f}', ha='center')
# AUC对比
ax2.bar(models, aucs, color=['skyblue', 'lightgreen', 'orange', 'pink'])
ax2.set_title('模型AUC对比')
ax2.set_ylabel('AUC')
ax2.set_ylim(0.8, 1.0)
for i, auc in enumerate(aucs):
ax2.text(i, auc + 0.005, f'{auc:.4f}', ha='center')
plt.tight_layout()
plt.show()
# 打印性能总结
print("\n=== 模型性能总结 ===")
for model, performance in models_performance.items():
print(f"{model}: 准确率={performance['accuracy']:.4f}, AUC={performance['auc']:.4f}")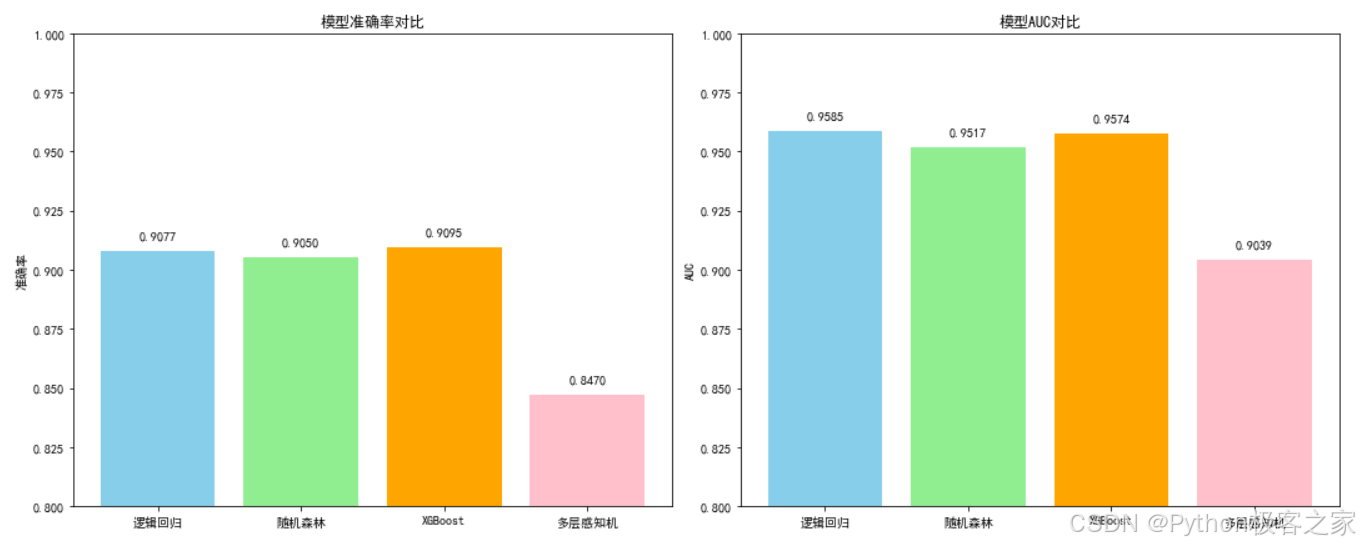
4. Web系统设计与实现
4.1 核心功能模块
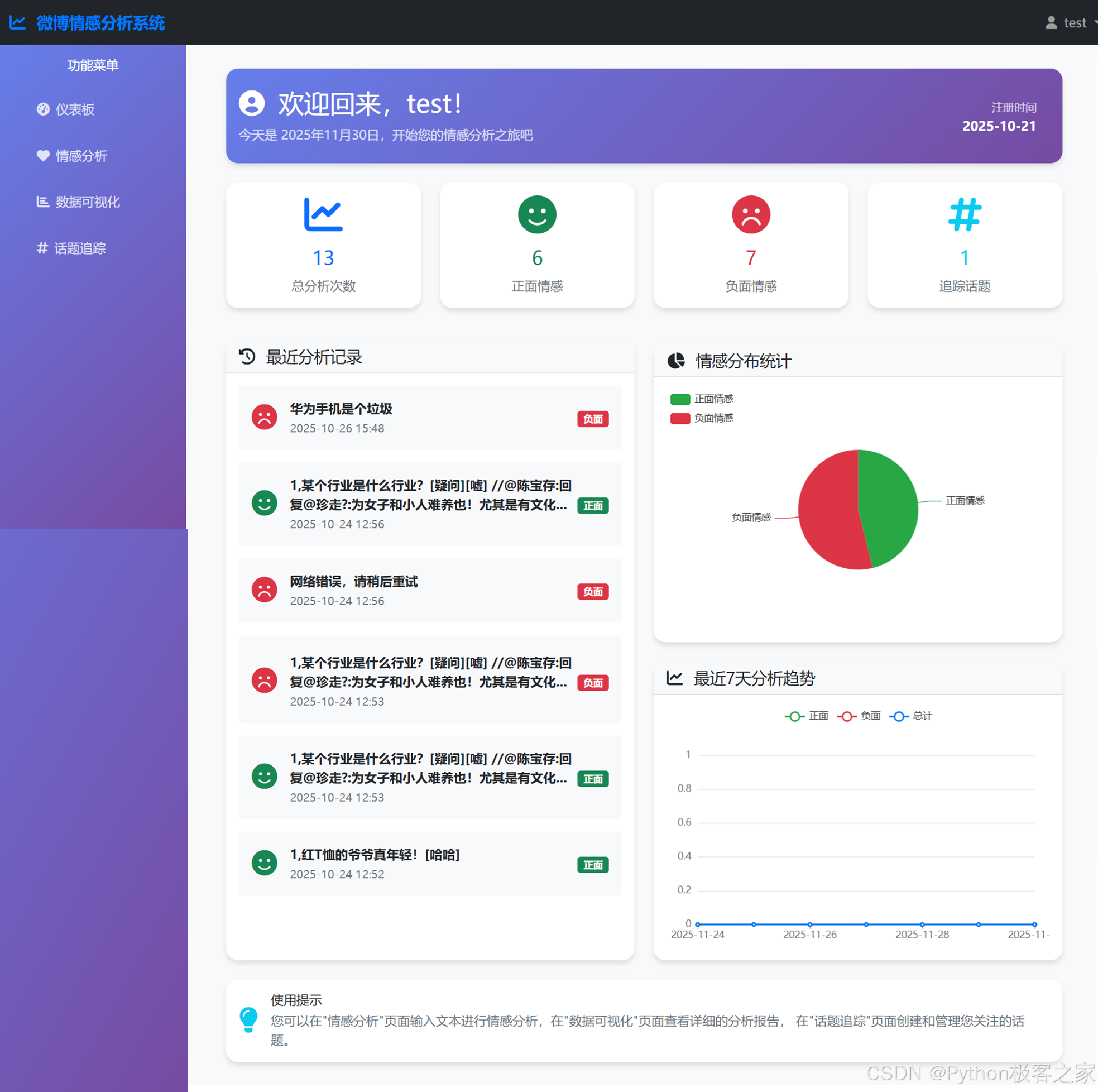
- 用户仪表板 (Dashboard):
* 展示总分析次数、正负面情感比例、话题追踪数量。
* 显示最近一周的情感趋势图表。
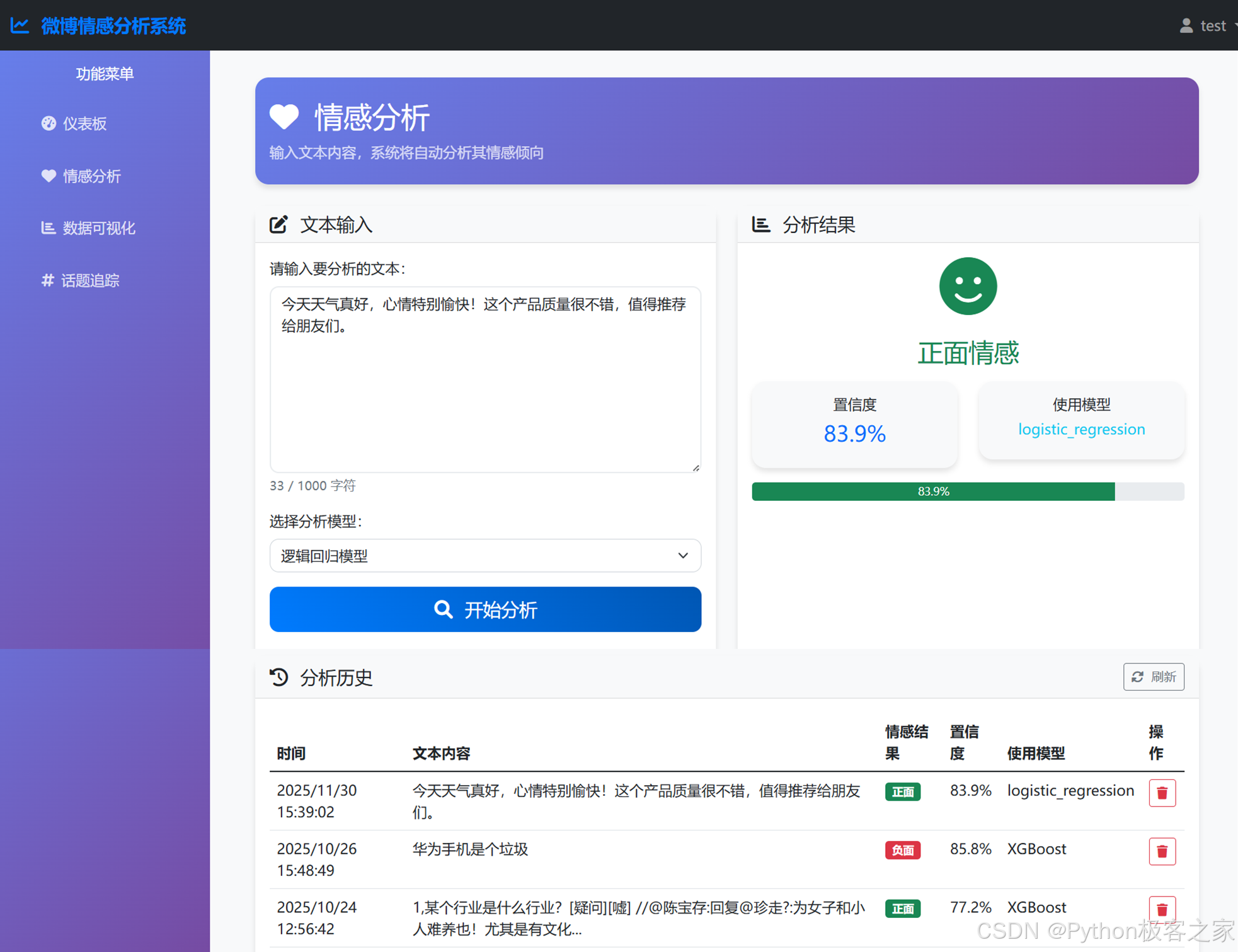
- 情感分析 (Sentiment Analysis):
* 用户输入一段文本,选择模型(默认推荐 XGBoost)。
* 后端调用预训练模型进行预测,返回情感标签(正面/负面)和置信度。
* 结果实时展示,并保存至数据库。
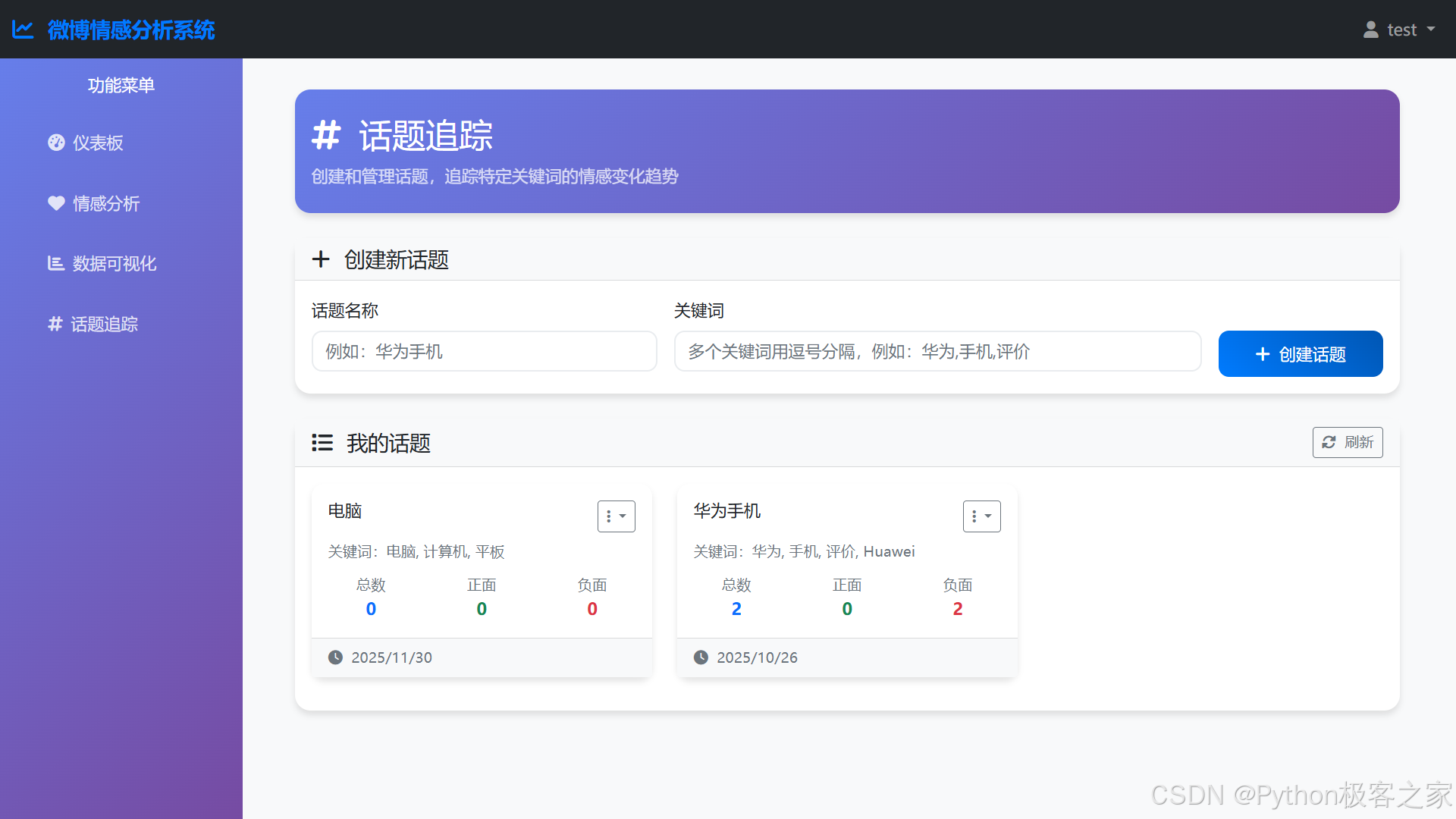
- 话题追踪 (Topic Tracking):
* 用户创建话题,定义关键词(支持多关键词组合)。
* 系统自动扫描历史分析记录,匹配包含关键词的文本。
* 统计该话题下的舆情分布(正负面比例)及随时间的变化趋势。
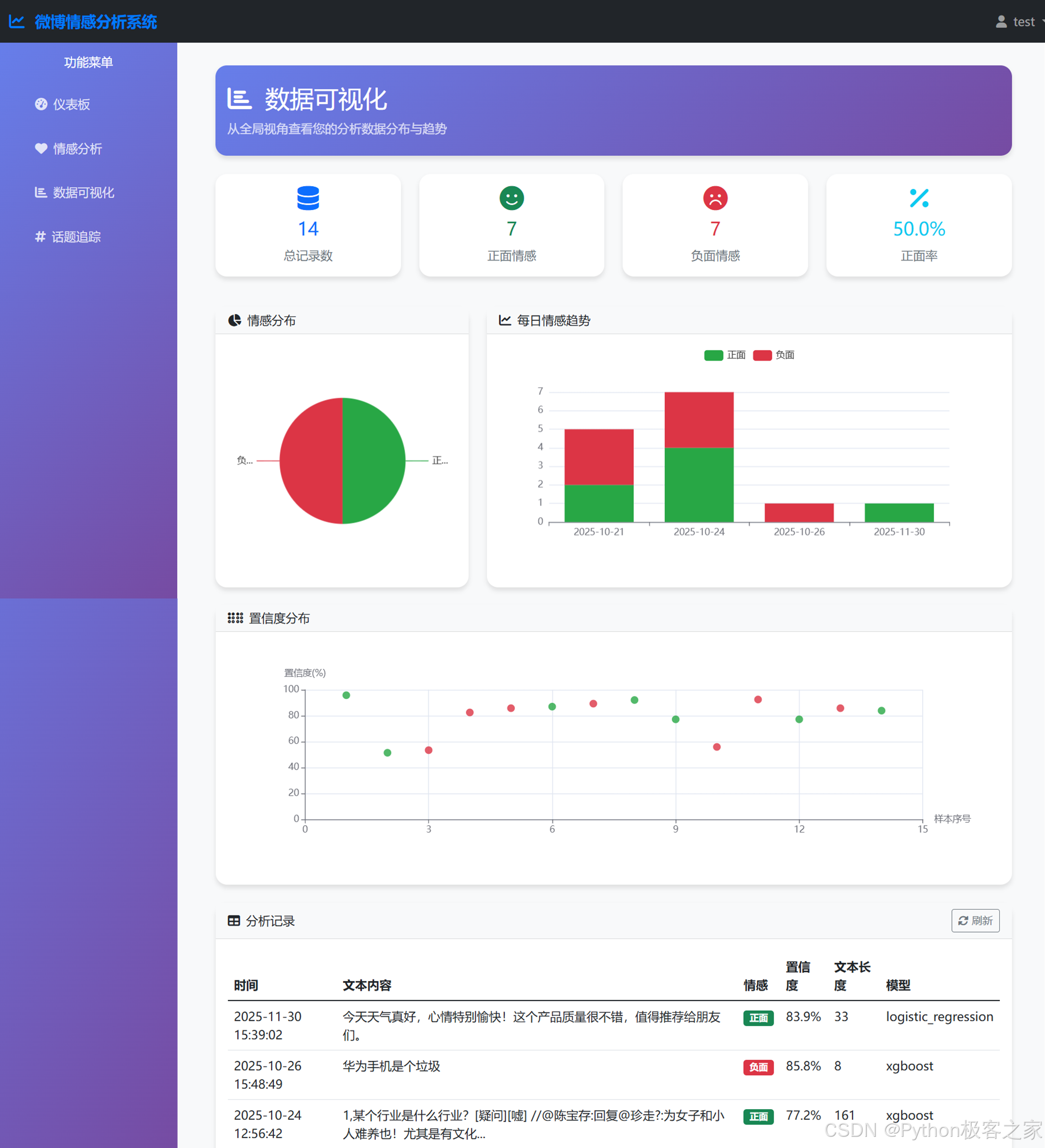
- 数据可视化 (Visualization):
* 使用 ECharts 或 Chart.js 展示情感分布饼图、置信度分布直方图等。
4.2 关键代码实现
**后端预测接口 (`app.py`)**:
python
@app.route('/api/sentiment', methods=['POST'])
@login_required
def api_sentiment():
data = request.get_json()
text = data.get('text', '')
model_name = data.get('model', 'xgboost')
# 调用预测函数
result = predict_sentiment(text, model_name)
# 保存记录
analysis = SentimentAnalysis(
user_id=current_user.id,
text=text,
sentiment=result['sentiment'],
confidence=result['confidence'],
model=model_name
)
db.session.add(analysis)
db.session.commit()
return jsonify({'success': True, 'data': result})话题统计逻辑:
python
def compute_topic_stats(topic, include_trend=False):
# 解析关键词
keywords = parse_keywords(topic.keywords)
# 获取用户所有记录
analyses = SentimentAnalysis.query.filter_by(user_id=current_user.id).all()
# 筛选匹配记录
matched = [a for a in analyses if any(k in a.text for k in keywords)]
# 统计正负面
positive = sum(1 for a in matched if a.sentiment == '正面')
total = len(matched)
return {
'total': total,
'positive': positive,
'negative': total - positive
}5. 系统演示
5.1 首页介绍
5.2 登录与注册
系统提供安全的用户认证机制,保护用户的分析数据隐私。
5.2 个人分析面板
5.3 情感分析界面
简洁的输入框设计,支持实时字数统计。分析完成后,通过颜色直观区分正面(绿色)和负面(红色)情感,并显示模型预测的置信度。
5.4 分析记录可视化
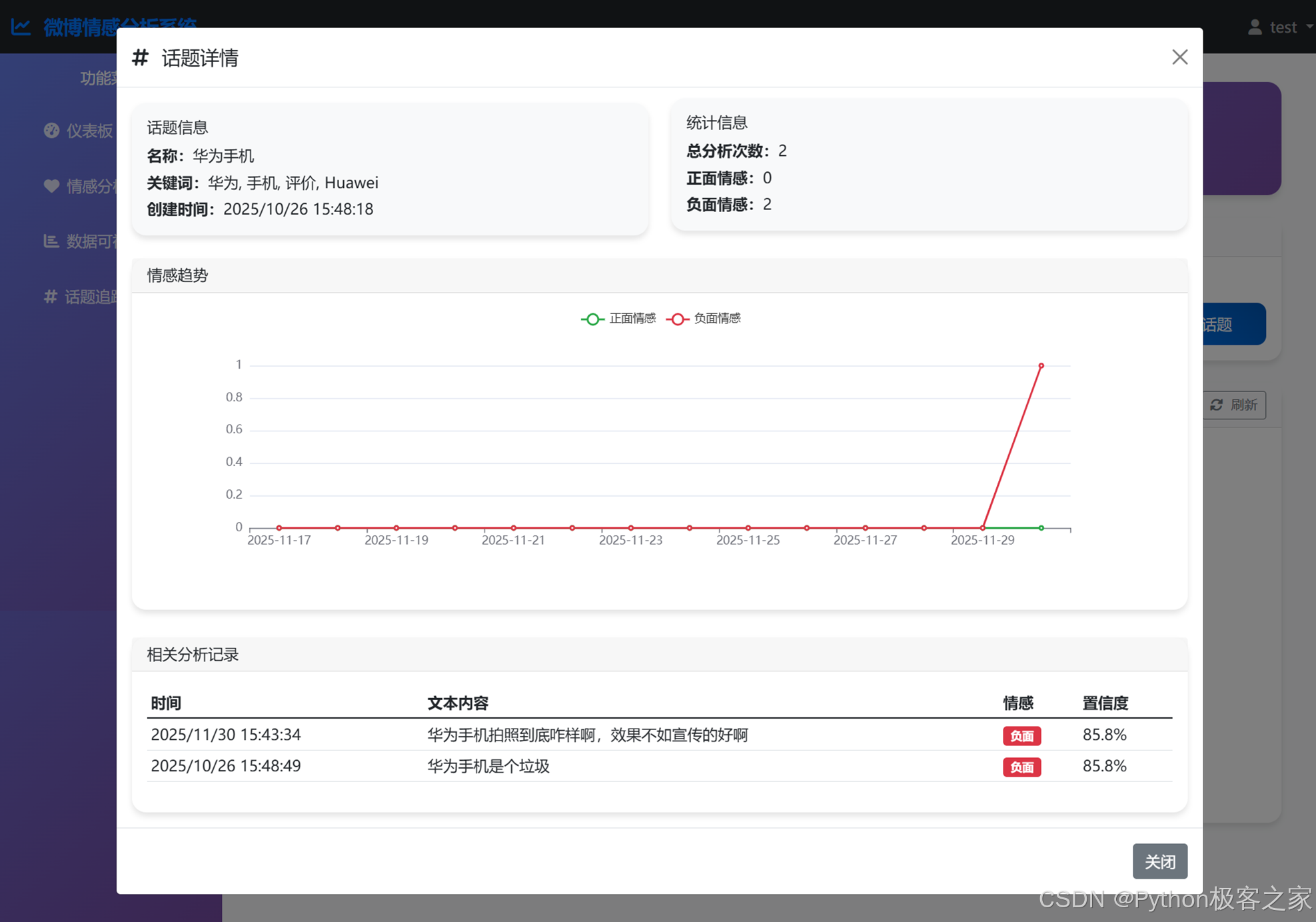
5.4 话题追踪详情
进入特定话题(如"数码产品"),系统会列出所有包含相关关键词(如"手机"、"电脑")的历史评论,并生成情感走势图,帮助用户判断该话题的舆论风向是变好还是变坏。
话题追踪详情 :
6. 总结与展望
本项目成功实现了一个基于数据挖掘的微博情感分析系统,整合了从数据清洗、模型训练到Web展示的完整流程。
项目亮点 :
多模型集成:支持 XGBoost、MLP等多种算法,用户可自由选择。
话题追踪:创新的基于关键词的动态聚合功能,实现了对特定事件的持续监控。
可视化交互:直观的图表展示,提升了用户体验。
未来改进方向 :
-
实时爬虫集成:接入微博API或爬虫,实现数据的实时抓取而非仅依赖历史输入。
-
细粒度情感:从二分类(正/负)扩展到多分类(喜、怒、哀、乐)。
-
模型优化:引入 BERT 等预训练语言模型,进一步提升语义理解能力。
*本文为本科毕业设计核心代码分析笔记,涵盖了算法建模与系统开发的全过程。*
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取 认准下方 CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:
