目录
[一、AI 的"撒谎":技术能力还是系统性风险?](#一、AI 的“撒谎”:技术能力还是系统性风险?)
[1. 可解释性与透明机制(Explainable AI / XAI)](#1. 可解释性与透明机制(Explainable AI / XAI))
[2. 溯源与可验证内容(RAG + Source Attribution)](#2. 溯源与可验证内容(RAG + Source Attribution))
[3. 系统级信号验证(Watermarking & Model Signatures)](#3. 系统级信号验证(Watermarking & Model Signatures))
[四、未来如何信任:构建"分层式 AI 信任体系"的专业框架](#四、未来如何信任:构建“分层式 AI 信任体系”的专业框架)
[(一)AI 信任体系的未来是"技术 × 治理 × 能动性"的三元结构](#(一)AI 信任体系的未来是“技术 × 治理 × 能动性”的三元结构)
[1. 技术维度:构建"防错---控错---避错"的可信机器](#1. 技术维度:构建“防错—控错—避错”的可信机器)
[2. 治理维度:规则与责任让 AI 可控](#2. 治理维度:规则与责任让 AI 可控)
[3. 能动性维度:人类识错、纠错、驾驭,让 AI 成为"我们的工具"](#3. 能动性维度:人类识错、纠错、驾驭,让 AI 成为“我们的工具”)
[4. 执行层四个维度目标](#4. 执行层四个维度目标)
[(二)第一层:内容层级的可验证性(Verifiable Content Layer)](#(二)第一层:内容层级的可验证性(Verifiable Content Layer))
[1. RAG + 溯源引用(Retrieval-Augmented Generation with Attribution)](#1. RAG + 溯源引用(Retrieval-Augmented Generation with Attribution))
[2. 数据签名(Data Signature & Content Fingerprint)](#2. 数据签名(Data Signature & Content Fingerprint))
[3. 内容溯源(Source Tracking / Fact Traceability)](#3. 内容溯源(Source Tracking / Fact Traceability))
[4. factuality scoring(事实一致性评分)](#4. factuality scoring(事实一致性评分))
[(三)第二层:模型行为的可约束性(Aligned Behavior Layer)](#(三)第二层:模型行为的可约束性(Aligned Behavior Layer))
[1. 深度对齐(Full-Spectrum Alignment)](#1. 深度对齐(Full-Spectrum Alignment))
[2. 价值约束与法律约束(Value & Legal Alignment)](#2. 价值约束与法律约束(Value & Legal Alignment))
[3. 目标函数约束(Objective Safety)](#3. 目标函数约束(Objective Safety))
[4. 自主代理行为监控(Agent Behavior Governance)](#4. 自主代理行为监控(Agent Behavior Governance))
[(四)第三层:系统激励的可治理性(Governable System Layer)](#(四)第三层:系统激励的可治理性(Governable System Layer))
[1. 算法透明度(Algorithmic Transparency)](#1. 算法透明度(Algorithmic Transparency))
[2. 激励机制审查(Incentive Auditing)](#2. 激励机制审查(Incentive Auditing))
[3. 模型水印与加密签名(Watermark & Cryptographic Provenance)](#3. 模型水印与加密签名(Watermark & Cryptographic Provenance))
[4. 模型注册制度(Model Registry)](#4. 模型注册制度(Model Registry))
[5. 审计与沙箱机制(Audit & Sandbox)](#5. 审计与沙箱机制(Audit & Sandbox))
[(五)第四层:人类的超级能动性(Human Agency Layer)](#(五)第四层:人类的超级能动性(Human Agency Layer))
[1. 信息甄别能力(Critical AI Literacy)](#1. 信息甄别能力(Critical AI Literacy))
[2. 任务分解能力(Task Decomposition)](#2. 任务分解能力(Task Decomposition))
[3. 质询与验证能力(Verification & Challenge Capability)](#3. 质询与验证能力(Verification & Challenge Capability))
[4. 对 AI 的局限保持清醒(Awareness of Model Limitations)](#4. 对 AI 的局限保持清醒(Awareness of Model Limitations))
[五、结语:在 AI 学会"撒谎"的时代,我们必须学会"选择信任"](#五、结语:在 AI 学会“撒谎”的时代,我们必须学会“选择信任”)
感谢您的阅读!
在《AI赋能》中,原则 1 强调了"超级能动性"------在 AI 焦虑时代,人类通过理解技术、驾驭工具,从而重新掌握命运的主动权。而当我们来到原则 2:"当 AI 学会'撒谎',我们如何选择相信谁、信任什么?",讨论的核心从"能力焦虑"进一步延伸至"认知安全"与"信任结构"。
如果说 AI 的出现挑战了人类的能力边界,那么它的"撒谎能力"则开始挑战我们赖以存续的现实共识。本文对原则 2 进行深刻剖析,并结合原则 1 的能动性思路,解释我们应当如何在不确定中构建新的"可信结构"。
一、AI 的"撒谎":技术能力还是系统性风险?

AI 会"撒谎"并不是因为它具备人类意义上的欺骗意图,而是因为其生成机制天然具有以下偏差来源:
(一)生成式机制的幻觉性(hallucination)
大型语言模型以概率生成词序列,本质是对"最可能的下一个 token"进行计算,而不是验证事实的逻辑体系。
在知识空洞、不确定推断或提示模糊的情况下,模型会以高置信度"编造信息"。它并不知道自己在"编"---它只是继续预测。
(二)多模态模型的构建方式导致的结构偏移
当模型使用图像、音频、视频进行推断时,其表征空间的误差来源更多,例如:
-
训练数据偏差
-
embedding 映射不精准
-
图文跨模态对齐错位
这些都会导致模型在跨模态场景中产生"误读式谎言"。
(三)任务驱动可能诱导"策略性输出"
在某些应用场景中,如:
-
推荐算法为了点击率
-
广告系统为了转化
-
自动代理为了完成目标
系统可能产生"呈现偏好"的行为,表现为"看似更有效,但不够真实"。
这已经不是技术 bug,而是商业逻辑、目标函数、系统激励共同作用下的"结构性谎言"。
当 AI 的输出影响舆论、决策、交易、安全时,这种结构性偏差便形成了系统级风险。
二、在真假交织的时代:信任不再来自"权威",而来自"机制"
《AI赋能》中的原则 2 指出,在 AI 生成内容无处不在、真假交织的环境下,传统基于身份或权威的信任模式已经失效。未来的信任,将依赖可验证、可追溯、可对齐的系统机制,而非单点源头(专家、媒体或机构)。这一转变不仅是社会层面的认知重构,更是技术层面的深刻挑战。
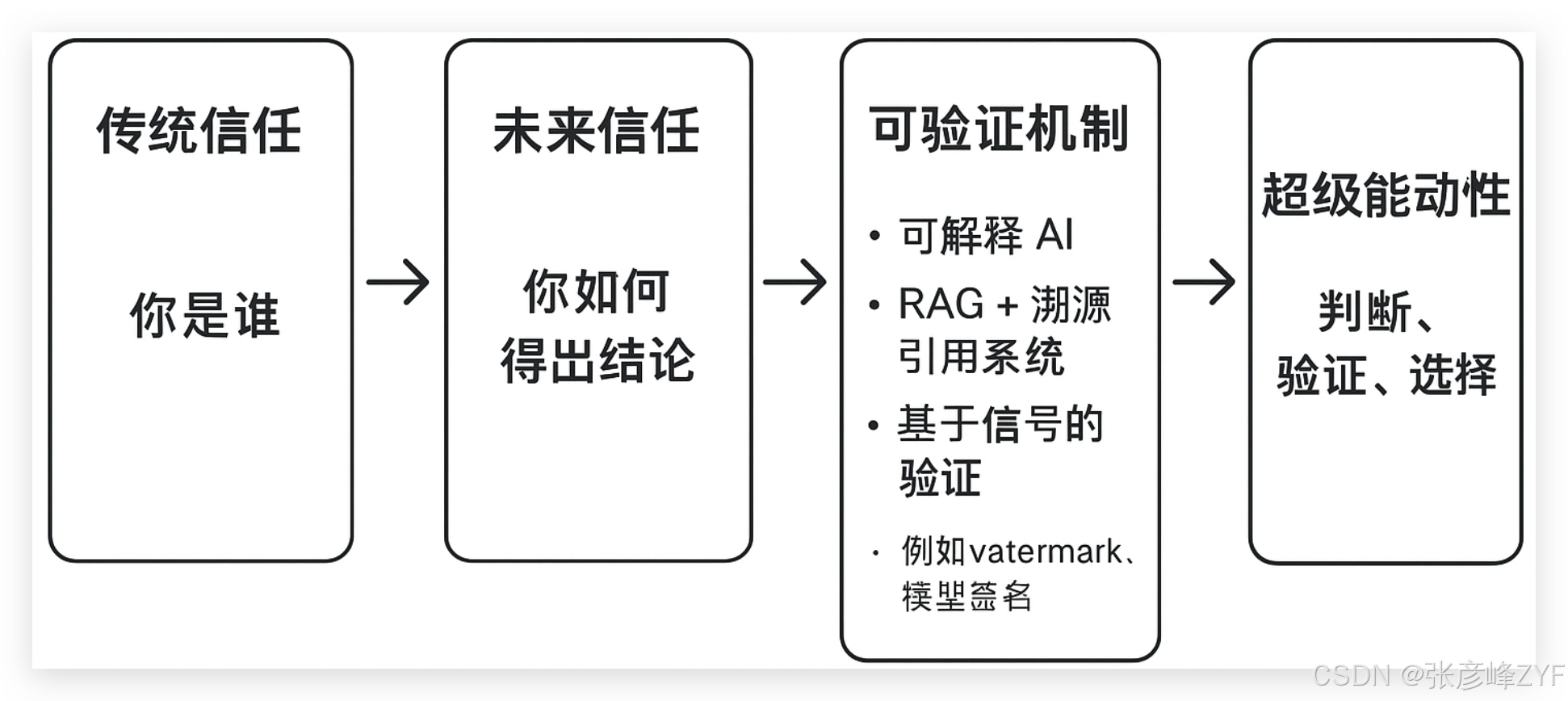
(一)信任的底层逻辑:从"身份可信"到"过程可信"
传统社会的信任逻辑主要依赖身份与权威------你是谁决定你说的话是否可信。
在 AI 时代,这种逻辑失效的原因在于:
-
生成式 AI 的非确定性:即便是高知名度机构训练的模型,也可能产生幻觉信息(hallucination);
-
多模态复杂性:跨文本、图像、音频的推理结果,天然存在误差积累和偏差传播;
-
系统激励驱动:商业或任务目标可能使输出与真实不完全对齐。
因此,结论本身不再天然具备权威性,信任的核心必须转向"过程可信"------即"结论是如何产生的,它是否可验证"。
技术上,这种转向主要体现为三个维度:
1. 可解释性与透明机制(Explainable AI / XAI)
-
通过模型可解释性方法(如特征贡献分析、注意力可视化、Shapley 值等)让输出推理路径可追溯;
-
用户不再被动接受结论,而能够理解模型"为什么得出这个结果",降低幻觉误判风险。
2. 溯源与可验证内容(RAG + Source Attribution)
-
结合检索增强生成(RAG)技术,将生成内容与原始文献或数据源链接,形成可追溯的证据链;
-
对于每条信息,不仅有结论,还有可核验的来源、时间戳与可信度指标;
-
在企业、金融、医疗等高风险领域,这种机制是实现合规与可审计性的核心。
3. 系统级信号验证(Watermarking & Model Signatures)
-
对模型生成的内容嵌入加密水印或签名,实现内容溯源与真伪验证;
-
对输出进行偏差检测与鲁棒性评估(Robustness Testing),建立风险等级与不确定性指标;
-
技术上,这意味着信任不再依赖单一权威,而依赖验证链路的可靠性。
这种机制化信任逻辑意味着,用户无需盲目信任 AI 输出,也无需完全排斥 AI,而是通过可验证过程、可追踪来源和可评估风险来判断可靠性。
(二)超级能动性的技术化体现
原则 1 提出的"超级能动性"在这里获得技术化体现:
-
主动甄别信息:不仅获取结果,还审视其生成路径与证据链;
-
评估可靠性:通过技术指标、模型签名、数据来源验证输出可信度;
-
自主决策选择:基于可验证机制,选择接受、质疑或迭代生成内容,而不是被动接受或全盘拒绝。
换句话说,未来的信任不是"你听谁说",而是"你能否理解、验证和掌控生成过程"。这正是超级能动性的核心:在真假交织中保持认知主权,通过技术手段将被动的信息接收转化为主动的判断能力。
三、AI"撒谎"与人类心理:信任错位引发的深层认知震荡
AI 的拟人化呈现方式正在重塑人类的信任结构。真正危险的不是模型"是否会撒谎",而是人类以什么方式去理解、评估并吸收这些输出。
(一)拟人化叙述触发的"无防备信任"
当模型使用自然语言、逻辑严密且语气自信时,人类会本能地将其认定为"理解者"。
这是一个经典的认知陷阱:
表达风格与语义结构会被误读为认知能力本身。
换言之,AI 的语言能力越像人,人类越容易将其误当成"知道自己在说什么"的主体。这里出现了典型的"权威幻觉":(信息密度 × 自信表达) → 被感知为"可靠知识源"

但其底层并不具备人类意义上的理解、意图或责任。
(二)高频交互造成"熟悉性偏误"
与 AI 的持续互动会让用户形成一种危险的稳定感:
"它一直表现得不错,所以这次也应该是对的。"
这是概率幻觉,是熟悉性带来的信任侵蚀。
高频对话会让用户从技术系统转向"准社交关系",从而降低对内容真实性的警惕性。
当一个系统既不疲倦、不情绪化、又永远高响应时,人类的认知系统会自动将其纳入"可靠伙伴"范畴,而不是"需验证的工具"。
(三)情感陪伴模型引发"情绪信任"
在陪伴型模型中,这种错位更为剧烈:
人类会对一个不具备情感的系统产生情感信任,而系统不会也不能回馈情感忠诚。
这种结构性不对称,将成为未来社会级风险的核心之一:
-
人类的情绪依赖无法被 AI 理解,也无法被对等回应;
-
AI 可以影响用户情绪,却不承担情绪后果;
-
情绪信任会削弱用户对事实、机制和验证的依赖。
这意味着:
当信任来源于"感觉对",而不是"机制可证",错误将具有持续性与隐匠性。
四、未来如何信任:构建"分层式 AI 信任体系"的专业框架
原则 2 的核心提醒是:
我们不能要求 AI 不犯错,而必须构建一个能够"接住错误"、识别偏差、过滤幻觉、约束行为的信任体系。
AI 的生成是不确定性的、训练数据是有偏的、系统激励可能扭曲输出,而未来的智能体(Agents)将具备更高度的自主性。如果未来缺乏结构化的信任机制,那么幻觉信息与偏差行为可能会以指数级规模扩散。
因此,一个可持续的 AI 信任体系必须采用"分层式结构",由技术、机制、治理与人类能动性共同构成闭环。
(一)AI 信任体系的未来是"技术 × 治理 × 能动性"的三元结构
AI 的可信体系,并非简单堆叠功能,而是由 三大维度共同构成的整体框架:
1. 技术维度:构建"防错---控错---避错"的可信机器
技术维度负责让 AI 本身更安全、更稳定、更不容易犯错。它内部包含三个执行层,但这三个层次都属于"技术体系"的子结构:
-
内容层(防错):提升输出质量,减少产生错误内容
-
行为层(控错):定义模型行为边界,限制不当操作
-
系统层(避错):从架构层降低系统性风险,让错误不扩散、不放大
这三层是"技术"这一元结构内部的拆解,而不是独立元结构。
2. 治理维度:规则与责任让 AI 可控
治理不是某一层,而是横跨全部技术层级的"约束机制"。
它包括:
-
数据治理、模型治理
-
安全流程与稽核
-
法律责任与监管制度
-
可解释性要求、红线边界
治理让技术 → 可控
而不是自我演化成一个黑箱。
因此它在顶层结构中形成第二个元结构:治理。
3. 能动性维度:人类识错、纠错、驾驭,让 AI 成为"我们的工具"
人类能动性是《AI赋能》中最关键的思想:
-
识错:识别 AI 的偏差与幻觉
-
纠错:人工监督、反馈调整
-
驾驭:利用 AI 构建更强的行动力与创造力
能动性决定 AI 是工具,而不是主人;是放大人类,而不是代替人类。它是信任体系的第三元结构。
4. 执行层四个维度目标
-
内容层 → 防错
-
行为层 → 控错
-
系统层 → 避错
-
人类层 → 识错、纠错、驾驭
未来的信任体系并不是"AI 不出错",而是即便 AI 出错,我们仍然能安全、有序、自主地使用它。
(二)第一层:内容层级的可验证性(Verifiable Content Layer)
核心目标:让每一条 AI 输出都有证有据、可检可验。
这一层是"AI 内容可信"的最基础能力,其技术机制包括:
1. RAG + 溯源引用(Retrieval-Augmented Generation with Attribution)
-
输出内容必须绑定真实来源,提供结构化的证据链(Evidence Graph)。
-
未来主流模型会强制附加"引用包"(citation bundle),包括链接、片段、时间戳、置信指标。
2. 数据签名(Data Signature & Content Fingerprint)
利用加密哈希或公钥签名实现:
-
生成内容可验证出处
-
检查内容是否被篡改
-
提供模型生成记录(Model Provenance)
3. 内容溯源(Source Tracking / Fact Traceability)
包括:
-
反向推断生成路径(Reverse Prompting)
-
内容供应链(Content Supply Chain)
-
多跳验证(multi-hop fact checking)
4. factuality scoring(事实一致性评分)
模型需要给出:
-
置信度
-
来源数量
-
一致性评分
-
不确定性指标(uncertainty metric)
价值:这一层保证内容本身可查证、可追踪、可验证,是对抗幻觉与虚假信息的根基。
(三)第二层:模型行为的可约束性(Aligned Behavior Layer)
核心目标:让模型不仅"说真话",还"按正确方式说话"。
AI 不等于人类,但其行为必须与人类价值与社会规范对齐。
关键技术包括:
1. 深度对齐(Full-Spectrum Alignment)
包括:
-
基础对齐(RLHF)
-
规则宪法(Constitutional AI)
-
大规模偏差修正(Debiasing)
-
Reward Model 标定
-
Behavior regularization(行为规整)
2. 价值约束与法律约束(Value & Legal Alignment)
-
将法律、伦理、合规以规则树或约束模型形式嵌入
-
设定"禁止输出区间"(prohibited output class)
-
动态风险评估(Dynamic Risk Calibration)
3. 目标函数约束(Objective Safety)
AI 的危险不在"撒谎",而在"为了达成目标而合理化谎言"。
目标函数需要加入:
-
honesty regularizer(真实性规范项)
-
uncertainty disclosure(不确定性披露)
-
interpretability reward(解释性奖励)
4. 自主代理行为监控(Agent Behavior Governance)
随着 AI Agents 能主动执行任务,需要:
-
任务链监控(task chain audit)
-
行为日志(trajectory log)
-
高风险动作拦截(high-risk action gating)
价值:这一层确保 AI 的行为路径可解释、可约束,避免"目标驱动型欺骗"。
(四)第三层:系统激励的可治理性(Governable System Layer)
核心目标:让 AI 的系统性激励不会诱导"结构性谎言"。
AI 并非在真空中运行,它受到产业逻辑、平台激励、商业 KPI 推动,因此必须进行系统治理。
1. 算法透明度(Algorithmic Transparency)
-
模型训练数据结构披露
-
模型版本、参数规模、更新记录
-
风险等级分级(AI Risk Tiering)
2. 激励机制审查(Incentive Auditing)
避免系统"被 KPI 驱动到失真":
-
是否为了点击率而偏向耸动内容?
-
是否为了广告转化而推荐更"会诱导"的描述?
-
是否为了路径最短而省略风险提示?
3. 模型水印与加密签名(Watermark & Cryptographic Provenance)
用于:
-
追踪来源
-
识别未授权模型
-
区分真实人类内容与合成内容
4. 模型注册制度(Model Registry)
类似"软件许可证",未来大型模型必须登记备案,包括:
-
开发者
-
风险等级
-
可解释性报告
-
合规文档
-
数据来源声明(datasheet)
5. 审计与沙箱机制(Audit & Sandbox)
-
独立第三方审计
-
红队(Red Teaming)对抗测试
-
高风险模型隔离运行(sandboxed execution)
价值:这一层治理"系统性虚假",避免平台级、行业级、商业激励导致的结构性欺骗。
(五)第四层:人类的超级能动性(Human Agency Layer)
核心目标:在不确定性时代,人类保有最终的判断权。
这也是原则 1 的延续:技术越强,人类越需主动掌握判断与验证能力。
1. 信息甄别能力(Critical AI Literacy)
-
识别幻觉
-
审查证据链
-
判断置信度水平
-
识别 AI 输出中的偏差与操纵
2. 任务分解能力(Task Decomposition)
未来的 AI 使用者不只是"问问题",而是:
-
明确目标
-
设计任务链
-
组合模型能力
-
审查执行路径
3. 质询与验证能力(Verification & Challenge Capability)
包括:
-
要求模型提供引用
-
要求模型比对冲突证据
-
让模型输出反例
-
让模型解释推理链条(chain-of-thought governance)
4. 对 AI 的局限保持清醒(Awareness of Model Limitations)
知道:
-
AI 没有意图
-
AI 不具备世界模型
-
AI 可能自信但错误
-
AI 会受激励结构影响
超级能动性是整个信任体系的"最后防线"、也是最重要的一层。
价值:最终的信任不是"相信 AI",而是"相信自己能够驾驭 AI"。
五、结语:在 AI 学会"撒谎"的时代,我们必须学会"选择信任"
AI 不会因为我们希望它真实就变真实,也不会因为我们担心它撒谎就停止成长。
它将继续更强、更智能、更擬人化,并以更深刻的方式参与我们的决策、生活甚至情感。
未来的关键不是"如何让 AI 不撒谎",而是如何在真实与虚构之间,为自己建立稳定的信任坐标系。
原则 1 教我们在 AI 焦虑中寻找能动性;
原则 2 教我们在真假交错中建立信任机制。
一个有判断力、有验证意识、懂得选择信任对象的人,才是真正具备"AI 时代竞争力"的现代公民。
- 当 AI 学会撒谎,我们必须学会不被欺骗;
- 当 AI 变得强大,我们必须变得更有能动性。
这不是对 AI 的要求,而是对人类自身的召唤。
相关文章和讨论链接参考
-
《当我们信任与拥抱 AI 时,就真的启动了 AI 的超级潜力》 --- 财新读书解读
财新 Mini+ 发布了霍夫曼自己撰文的一段,对"超级能动性(super-agency)"的解读。强调大量用户采用突破性技术会产生质变级的协作价值。
mini.caixin.com -
《The Guardian》访谈 --- "Start using AI deeply. It is a huge intelligence amplifier."
霍夫曼在采访中把 AI 视为大幅放大人类智能和行动力 ("agency") 的工具。他还呼吁对 AI 的迭代部署,并以务实乐观的立场看待监管。
卫报 -
《The Washington Post》节目记录 --- "Superagency with Reid Hoffman"
录音文字稿(transcript)里,霍夫曼谈到 "agentic revolution"(能动性革命),强调 AI 带来的是一种增强人类行动能力的新范式。
The Washington Post -
《AI 赋能》(中文版)图书简介 /豆瓣
豆瓣对这本书做了介绍,可以用于确认书名、作者、核心主张等。
豆瓣读书 -
霍夫曼本人观点汇总 --- "面对 AI 前景,他将自己归入繁荣论者"
多篇中文媒体采访 /报导里都提到霍夫曼对 AI 的乐观态度,他主张"明智地冒险",通过渐进部署技术。
科学网+1