你可能每天都在使用AI,从手机上的语音助手到电商网站的商品推荐,但你知道这些强大的AI系统是由哪些核心要素构建起来的吗?想象一下,要建造一座宏伟的大厦,你需要设计图纸、高质量的材料、合适的工具和强大的机械,一个高效的人工智能系统也是如此。构建人工智能的四大模块包括:算法、数据、硬件和软件,本文将从高层次介绍AI模型中常用的算法部分。
文章目录
- 一、什么是算法?
-
- [1.1 算法如何学习?](#1.1 算法如何学习?)
- 二、常见AI算法类别
-
- [2.1 分类和回归 -- 监督学习](#2.1 分类和回归 -- 监督学习)
- [2.2 排序和聚类 -- 无监督学习](#2.2 排序和聚类 -- 无监督学习)
- 三、算法透明度
-
- [3.1 透明算法](#3.1 透明算法)
- [3.2 黑盒算法](#3.2 黑盒算法)
一、什么是算法?
简单来说,算法就是一套明确的指令,用于执行特定任务或解决问题,就像人类根据菜谱进行做菜一样,算法就是计算机的"菜谱",本质上就是一个"输入-处理-输出"模型。算法支撑着我们如今看到的各种先进功能,从歌曲推荐这种简单的操作,到自动驾驶这种复杂的任务。
1.1 算法如何学习?
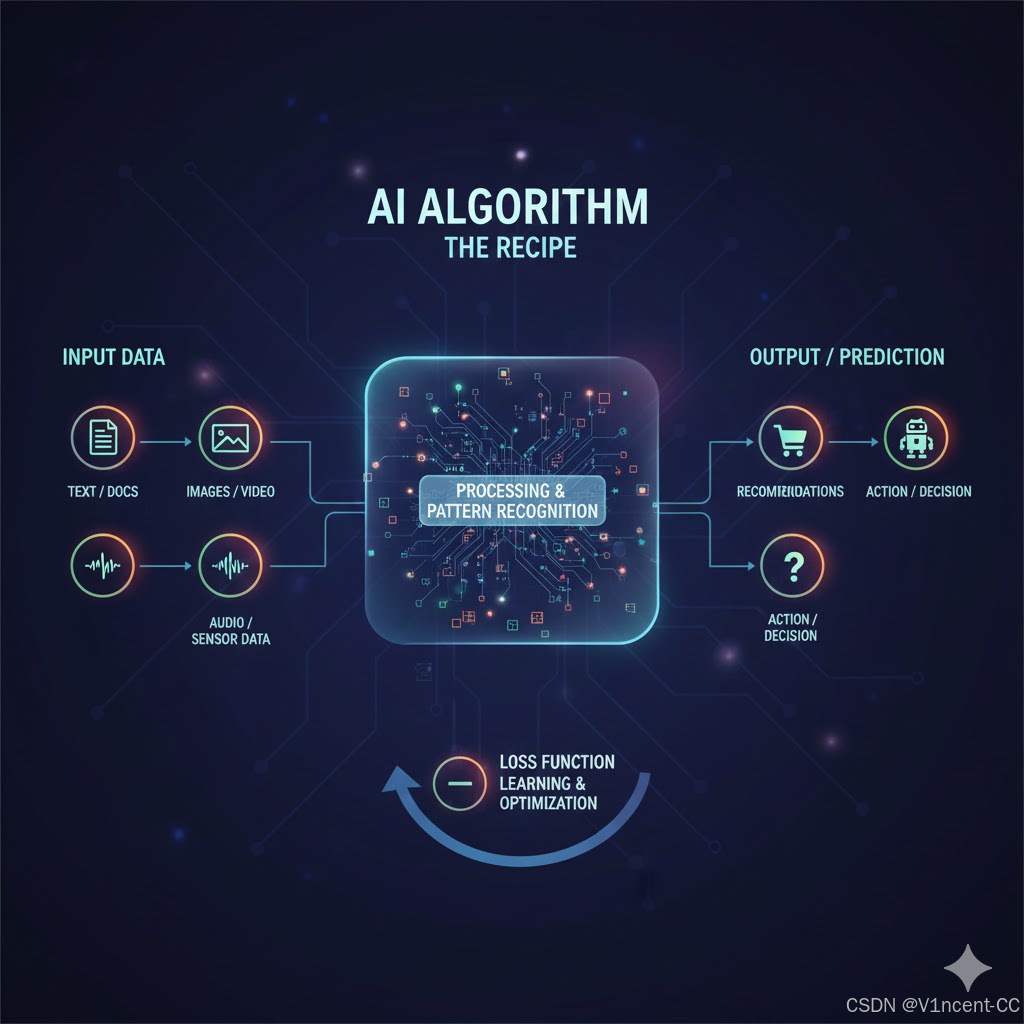
和传统程序固定性能的算法不同,人工智能算法通常具有随时间推移学习和改进的能力。随着处理的数据越来越多,AI算法会不断调整其理解能力,那么AI算法是如何学习和改进的?
AI 的学习机制依赖于一套反馈系统:
这种反馈通常以"损失函数和参数"的形式出现,损失函数是衡量算法执行任务能力的指标,损失函数量化了算法实际输出与预期输出之间的差异,损失函数值越低,性能越好。
- 损失函数 (Loss Function): 衡量算法实际输出与预期输出之间的差异,可以理解为 AI 衡量自己犯错程度的指标,损失函数值越低,性能越好。
- 优化过程: 当损失函数表明结果不理想时,算法就会进行优化,调整其内部参数(Parameters)。参数是算法在优化过程中调整的内部设置。本质上这是算法从过去的错误中学习的方式,参数越多,算法的复杂度通常也越高(例如深度学习模型有数百万个甚至上亿个参数)。
二、常见AI算法类别
没有放之四海而皆准的算法。不同的算法适用于不同的任务和不同类型的数据。算法的选择取决于你试图解决的具体问题。从高层次看,AI 算法主要包括四大类解决问题的技术:分类、回归、排序和聚类。此外,根据算法的可解释性,它们又可以分为透明算法和黑盒算法。
2.1 分类和回归 -- 监督学习
分类和回归算法在 AI 中都属于"监督学习"的范畴,它们都需要在 带有正确答案(标签) 的数据上进行训练,唯一的区别在于:它们试图预测的目标是什么类型的数据。
分类算法旨在根据输入数据的特征将其分配到特定的类别或类中,预测目标是类别或种类(离散的标签),分类任务是通过分析现有示例的特征或组成,然后创建一个预测模型来捕捉特征与类标签之间的关系,从而预测尚未分类的实例的类别。
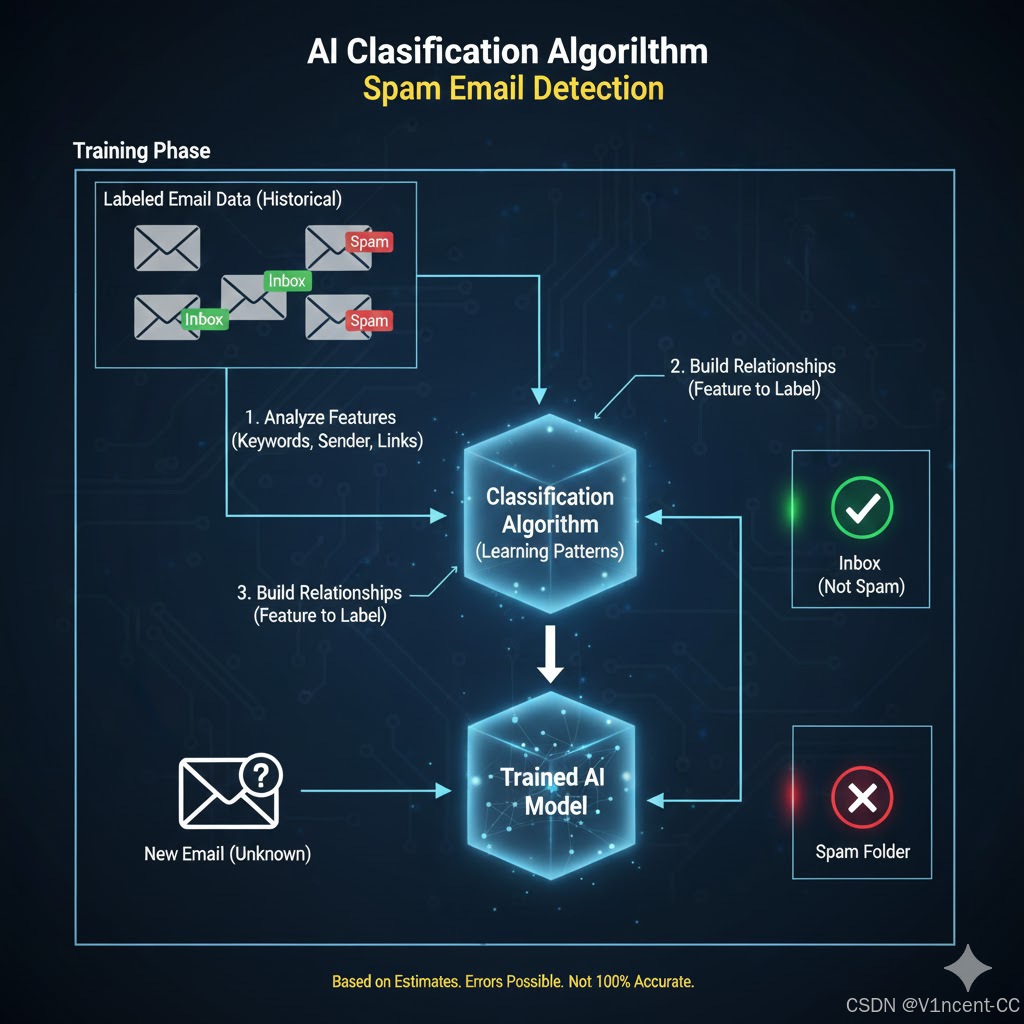
例如识别电子邮件是否为垃圾邮件,AI会在大量已经分类好的数据上进行训练,练过程包括:
- 将大量邮件数据及其对应的类别标签("垃圾邮件"或"非垃圾邮件")输入算法。
- 算法将分析这些特征,并建立它们与对应类别标签之间的关系。
- 创建一个能够捕捉这些关系的训练模型。
当新的数据输入模型时,模型可以根据从训练数据中学习到的关系,将其分类为"垃圾邮件"或"非垃圾邮件"。然而务必记住,模型实际上是根据训练数据进行估算的,虽然这种方法可能非常准确,但错误是不可避免的,AI无法做到100%准确率。
回归算法和分类算法相似,但是它用于预测连续值,例如预测患者的预期寿命。算法基于数据集训练回归算法(例如线性回归)来创建模型。训练过程包括将大量患者的特征(例如血压、身体质量指数BMI、年龄和胆固醇水平)及其对应的预期寿命值输入算法。算法随后会分析这些特征,并建立解释变量与预期寿命(该模型的目标变量)之间的关系。训练阶段完成后,即得到一个能够预测患者预期寿命的模型,当新患者的数据输入模型后,模型会根据其具体的健康指标估算其预期寿命。
总而言之,分类和回归算法旨在处理不同类型的问题:
- 当目标变量是类别或种类时,例如在电子邮件过滤中,判断为"垃圾邮件"或"非垃圾邮件",则使用分类。
- 当目标变量是实数或连续值时,例如房价或预期寿命,则使用回归。
2.2 排序和聚类 -- 无监督学习
排序算法的任务就是将一组项目或数据点,按照某个特定的规则或顺序重新排列,你可以把它想象成整理书架或衣柜的过程。例如搜素引擎、商品搜索、数据分析中都会经常用到排序算法。
聚类算法的核心是:物以类聚,人以群分,根据数据点之间的"相似性"或"共同特征",将它们分成不同的群组,听起来感觉和分类算法有点类似,但最大的区别是:
- 分类算法需要预定义的标签或类别(监督学习)。
- 聚类算法不需要预定义的标签或类别(无监督学习),它会自己去发现数据中隐藏的结构和模式。
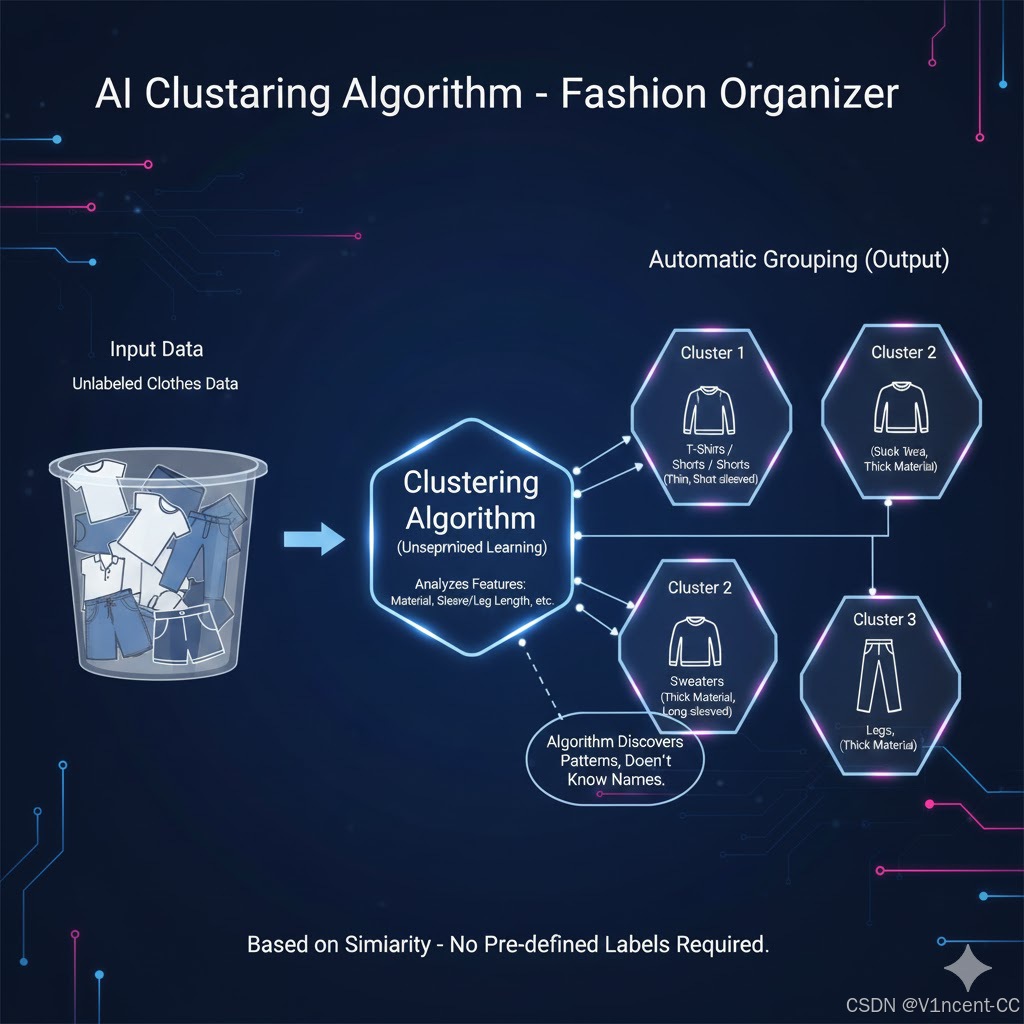
例如一个对衣服进行聚类的算法,处理流程可能如下:
- 输入: 所有衣服的特征数据。
- 处理:算法观察数据特征,分析每件衣服的特点,比如材质、袖子长度、腿部长度等,将具有相同特征的衣服总结为一类。
- 输出:自动分组,算法会发现:
- 袖子短、材质薄的衣服可以归为一类 (T恤)。
- 材质厚、有袖子的衣服可以归为另一类 (毛衣)。
- 有腿部、材质较厚的衣服可以归为第三类 (长裤)。
当然算法事先并不知道这些群组叫"T恤"或"长裤",它只是根据相似性将它们归类了。
三、算法透明度
算法透明度关注的核心问题是:"为什么 AI 会做出这个决定?"当AI给出一个结果时,我们能否理解它是如何一步步得出这个结果的?根据透明度的不同,AI 算法可以分为两大阵营:透明算法(白盒)和黑盒算法。
3.1 透明算法
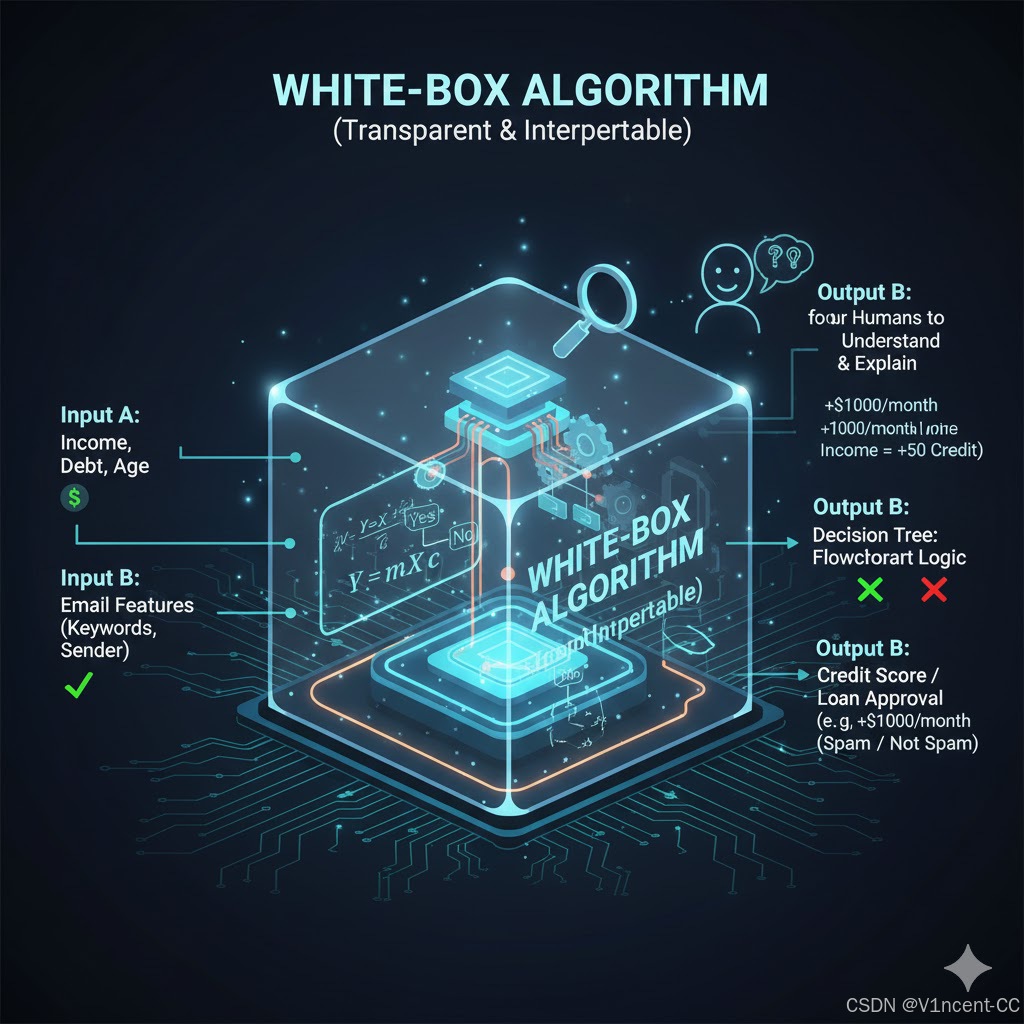
透明算法也被称为"白盒算法",因为它们的内部决策过程是清晰、可追踪和易于理解的,就像看着一个透明的盒子内部运作一样。核心特点:逻辑简单,容易解释,人类可以轻松地理解输入和输出之间的关系。
线性回归和决策树就是两个白盒算法,它们的输入和输出之间的关系清晰易懂:
- 线性回归:例如信用额度审核,AI通过一个简单的数学公式来计算结果,你可以清楚的看到"收入每增加一千元,你的信用额度就会增加多少"这样的逻辑。
- 决策树:它就像一系列的"是/否"问题构成的流程图,每一步的判断原因都清清楚楚,例如"因为你的收入超过 X,且没有未偿还的债务,所以批准额度。"
一般来说,透明的算法在理解决策背后的原因至关重要的场合非常有用,例如在需要问责制和信任的场合:医疗诊断、信贷决策、法律裁决等。
3.2 黑盒算法
黑盒算法之所以被称为"黑盒",是因为它们的内部运作机制极其复杂和不透明,我们很难或无法理解它是如何从输入数据得到最终结果的。这类算法通常由数百万甚至数十亿的参数组成,它们在多层复杂的结构中进行非线性转换,使得人类几乎不可能追踪整个决策链。
典型的黑盒算法有多层神经网络:它们由层层互连的"神经元"组成,数据在这些层之间被不断地转换和扭曲。例如识别猫:我们知道它工作得很好,但很难说清它是因为图片中的"眼睛形状"还是"胡须长度"才判断出是猫。
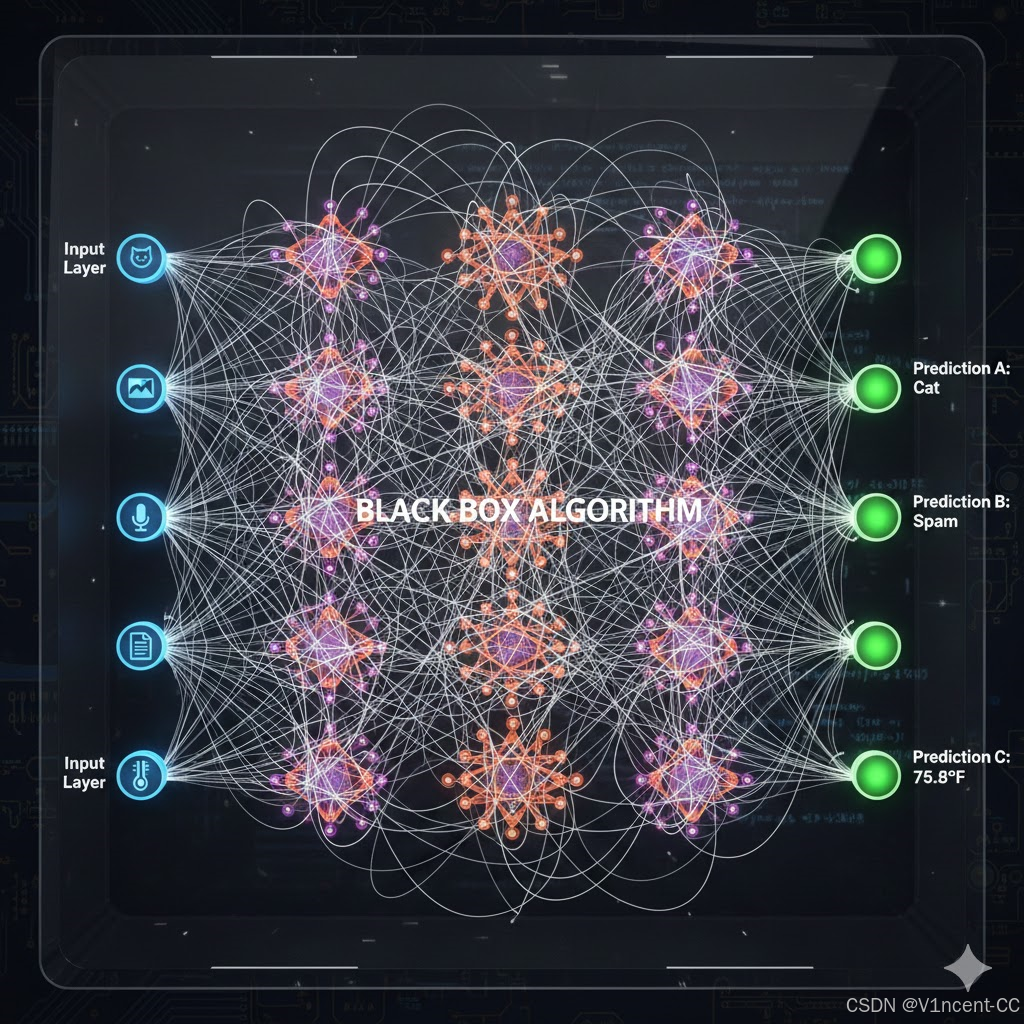
在需要或偏爱可问责性和可解释性的环境中,这种缺乏透明度的情况可能会成为问题。
AI是一个复杂的系统,所有算法的性能都高度依赖于高质量的(数据)进行训练,下篇文章我们将了解AI训练中的数据集。