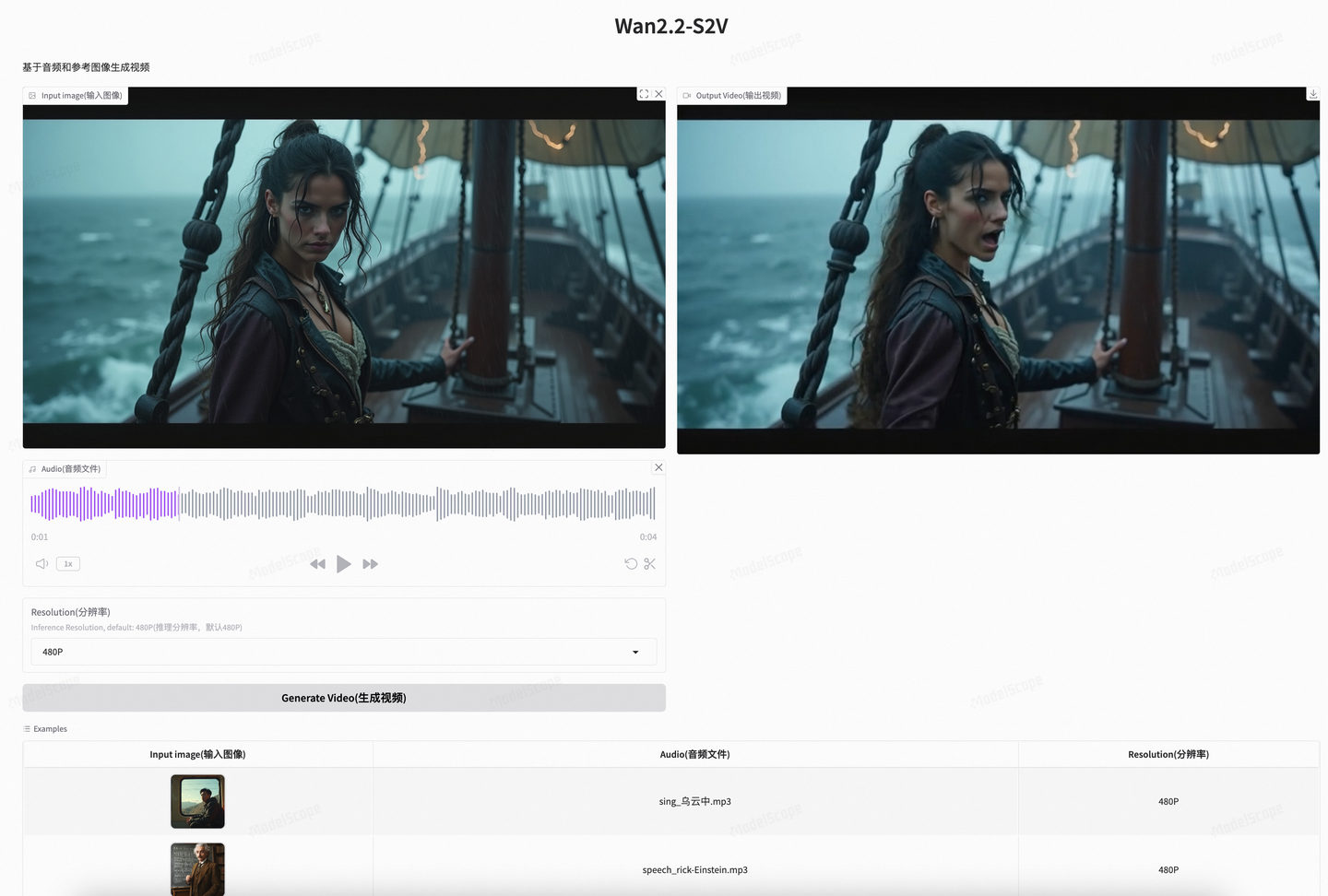
数字人视频制作模型开源啦!
体验链接:通义万相2.2-S2V
github: https://github.com/Wan-Video/
模型链接:https://www.modelscope.cn/models/Wan-AI/Wan2.2-S2V-14B
模型介绍
Wan2.2-S2V接收单张静态图像和音频输入,生成与音频同步的高质量视频。通义团队针对复杂场景的视频生成优化,在复杂的电影和电视剧场景中表现出色,能够呈现逼真的视觉效果,包括生成自然的面部表情、肢体动作和专业的镜头运用。同时支持全身与半身角色生成,可高质量地完成对白、演唱及表演等多种专业级内容创作需求。
技术特点:
- 扩展音频驱动生成到复杂场景:超越传统说话头部生成,能够在多样化和具有挑战性的场景中创建自然且富有表现力的角色运动,结合文本引导的全局运动控制和音频驱动的细粒度局部运动。
- 长视频稳定性:通过对层次化帧压缩技术,极大地降低了历史帧的token数量。 通过这种方式我们将motion frames(历史参考帧)的长度拓展到73帧(传统方法受计算复杂度限制只能支持几帧的motion frames),从而实现了稳定的长视频生成效果。
- 全面的训练数据和应用探索:针对影视剧场景构建了大规模的音视频数据集,通过混合并行训练进行全参数化训练,充分挖掘了模型的性能。训练阶段通过多分辨率训练,支持模型多分辨率的推理,从而能够支持不同分辨率场景的视频生成需求, 如竖屏短视频,横屏影视剧。
模型架构
给定单张参考图,输入的音频和文本用来描述视频内容,模型会保留参考图的内容,生成与输入音频同步的视频。生成的视频第一帧不一定跟输入的参考图一样,因为模型只约束生成的视频保留参考图的内容,而不是从参考图作为首帧开始生成。模型的原始输入会被提取为多帧噪声隐向量,训练时的每个时间步对连续的视频隐向量去除噪声。测试时,模型同时接收音频、文本和参考图的条件输入,从噪声开始不断去噪生成最终的视频。
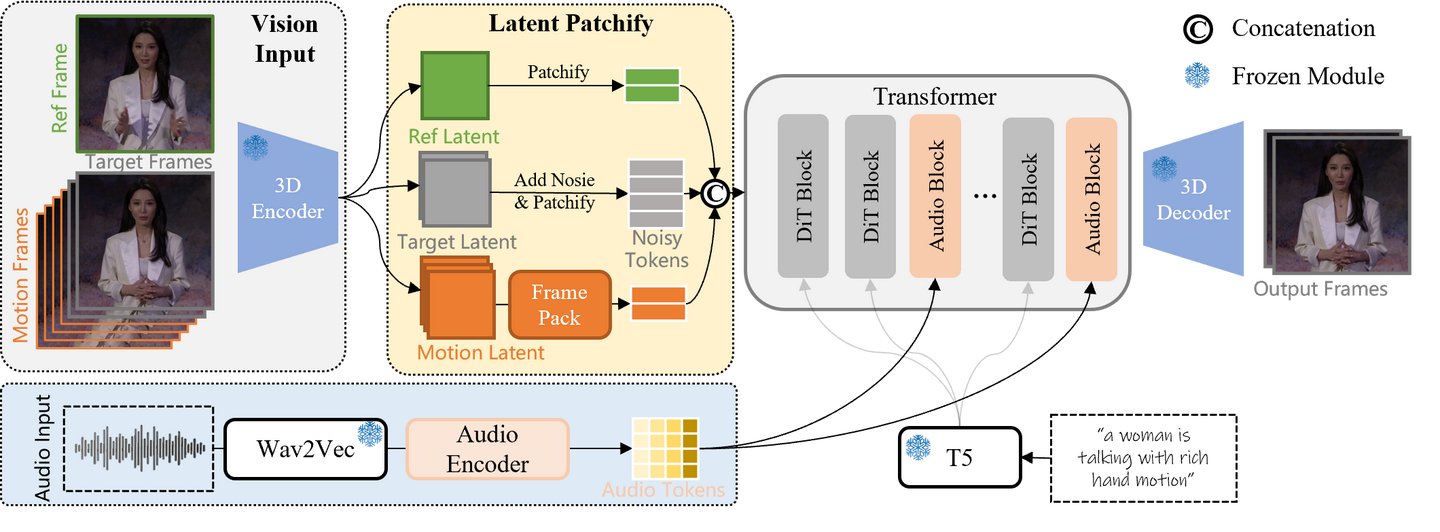
音频驱动的视频模型架构
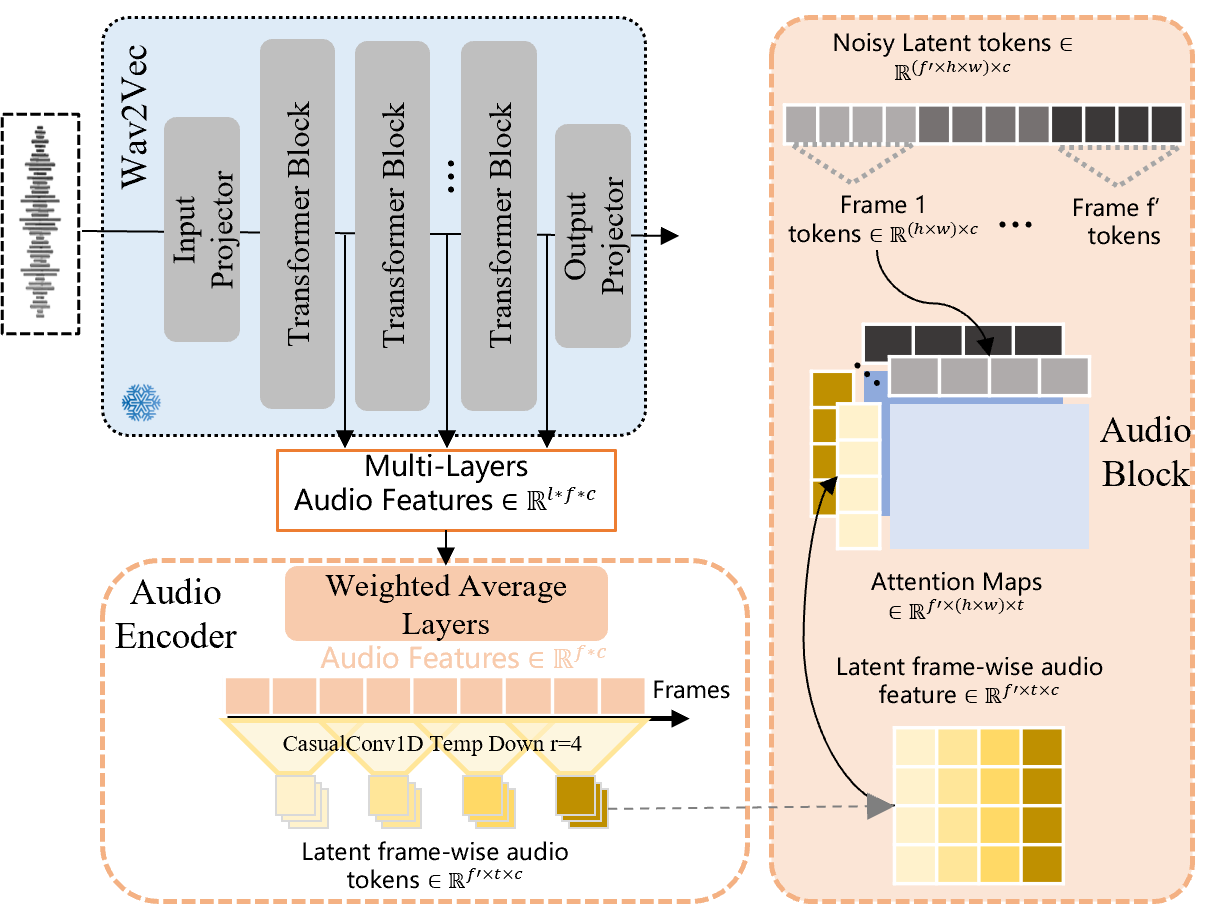
音频信息的注入流程
数据精制流程
通义团队通过大规模数据集(OpenHumanVid、Koala36M)的自动筛选和高质量样本的手动策划策略,专注于收集处理包含人类角色参与特定活动(如说话、歌唱、跳舞)的视频,创建了一个包含数百万以人为中心的视频样本的综合数据集。
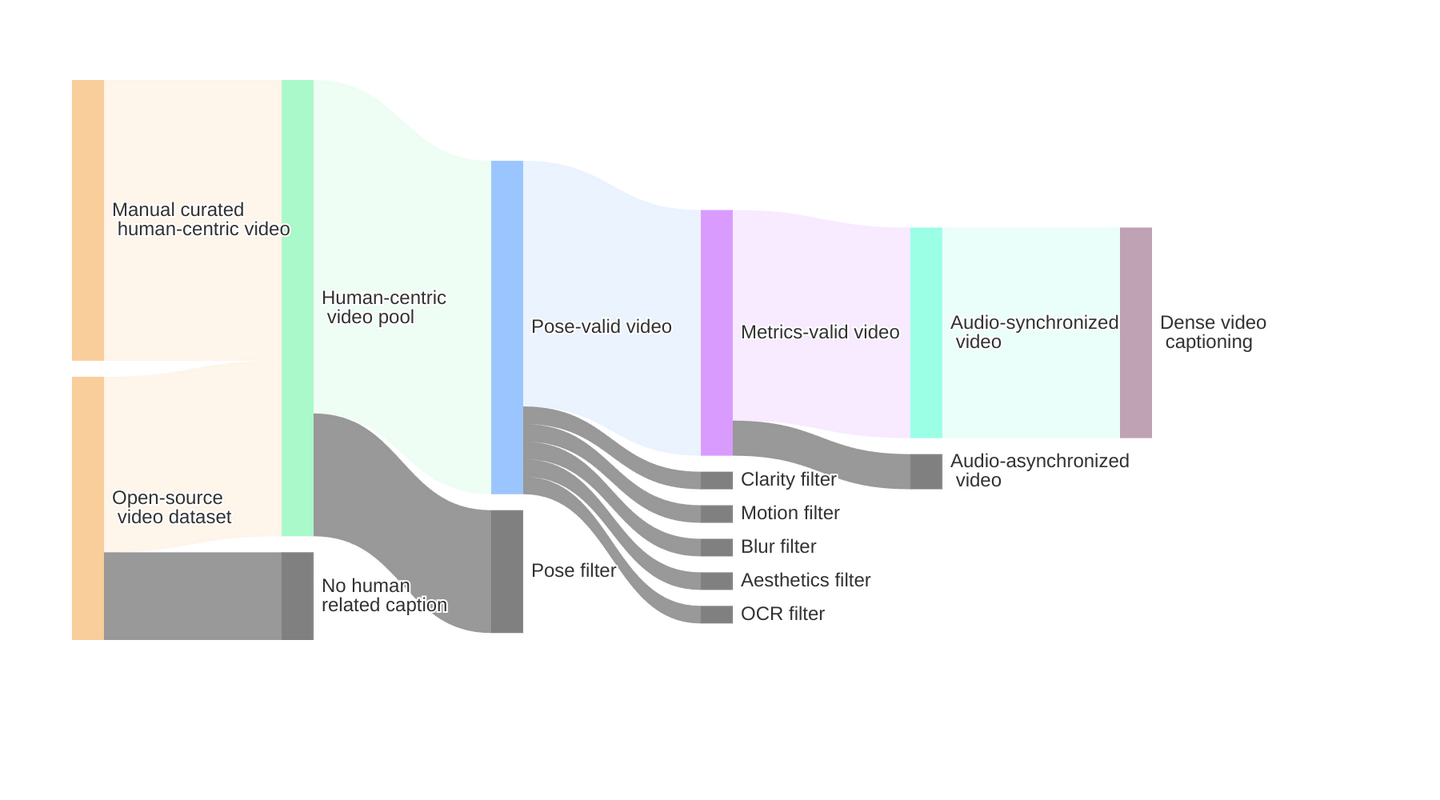
结构化视频精制流程
评估指标
通义团队在EMTD数据集上进行了定量评估,与多个最先进方法比较,Wan2.2-S2V-14B模型在多个指标上实现了卓越性能。
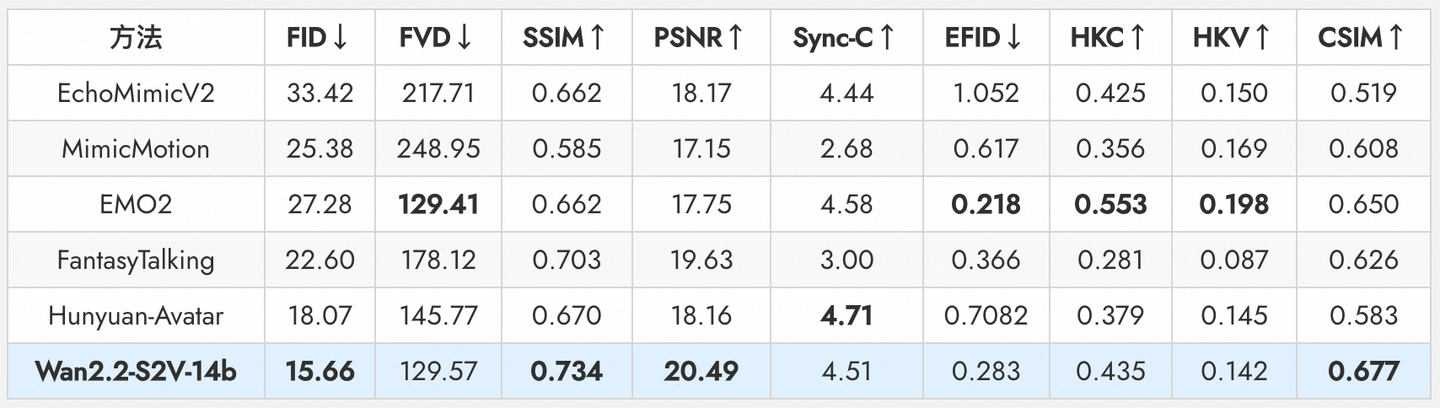
定量比较结果
示例效果
长视频的动态主体一致性保持
Wan2.2-S2V可以在生成长视频时确保主体的一致性,并在更长的视频持续时间内保持流畅自然的动态。
电影级音频驱动
Wan2.2-S2V能够生成电影级质量的视频, 实现电影对话的合成和叙事场景的重现。
提示词: "在视频中,一个穿着西装的男人坐在沙发上。他向前倾身,似乎想要劝阻对面的人。他以严肃的关切表情对对面的人说话。"
提示词: "视频显示一群修女在教堂里唱圣歌。天空散发着波动的金光,金色粉末从天空落下。她们穿着传统的黑色长袍和白色头巾,整齐地排成一行,双手合十放在胸前。她们的表情庄严而虔诚,仿佛在进行某种宗教仪式或祈祷。修女们的眼睛向上看,表现出极大的专注和敬畏,仿佛在与神灵对话。"
更强的指令遵循 ,运动与环境可控
能够根据指令生成视频中人物的动作及环境因素,从而创作出更贴合主题的视频内容。
提示词: "在视频中,一个男子拿着苹果说话,他咬了一口苹果。"
模型推理
官方GitHub代码的推理支持单卡和多卡,推荐使用A100以上规格的显卡运行,单卡运行显存占用60G左右。
环境与代码安装
git clone https://github.com/Wan-Video/Wan2.2.git
cd Wan2.2
# Ensure torch >= 2.4.0
# If the installation of `flash_attn` fails, try installing the other packages first and install `flash_attn` last
pip install -r requirements.txt模型下载
cd Wan2.2
modelscope download --model Wan-AI/Wan2.2-S2V-14B --local_dir ./Wan2.2-S2V-14B单卡推理
python generate.py --task s2v-14B --size 1024*704 --ckpt_dir ./Wan2.2-S2V-14B/ --offload_model True --convert_model_dtype --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard." --image "examples/i2v_input.JPG" --audio "examples/talk.wav"
# Without setting --num_clip, the generated video length will automatically adjust based on the input audio length多卡推理
torchrun --nproc_per_node=8 generate.py --task s2v-14B --size 1024*704 --ckpt_dir ./Wan2.2-S2V-14B/ --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard." --image "examples/i2v_input.JPG" --audio "examples/talk.wav"