今天给大家演示一个 基于 ComfyUI 的音频转文本(ASR)工作流。该工作流以实际音频文件作为输入,通过集成 FunASR 语音识别能力,实现音频内容的自动识别、时间戳切分以及字幕格式化输出。整体流程从音频加载开始,到识别结果预览,再到字幕与文本文件的落地保存,结构清晰、执行路径直观,非常适合用于语音内容处理与自动化字幕生成的场景。
通过效果展示可以看到,该工作流不仅能够输出连续的文本结果,还能生成带时间轴的字幕内容,便于后续直接用于视频剪辑、字幕封装或内容审核等工作。对于初次接触 ComfyUI 音频处理的用户来说,这是一套上手成本低、实用性很强的 ASR 示例工作流。
文章目录
- 工作流介绍
-
- 核心模型
- [Node 节点](#Node 节点)
- 工作流程
- 大模型应用
-
- [AVASRTimestamp 语音识别与时间戳解析](#AVASRTimestamp 语音识别与时间戳解析)
- 使用方法
- 应用场景
- 开发与应用
工作流介绍
这是一个围绕 音频识别 → 结果结构化 → 字幕输出 设计的 ComfyUI 工作流。在模型层面,工作流以 FunASR 语音识别模型作为核心,负责将原始音频解析为可读文本,并生成包含时间戳的识别结果;在节点层面,通过音频加载、ASR 处理、字幕格式转换、结果预览与文本保存等多个节点协同工作,将"音频"这一非结构化输入逐步转化为可复用的文本与字幕数据。
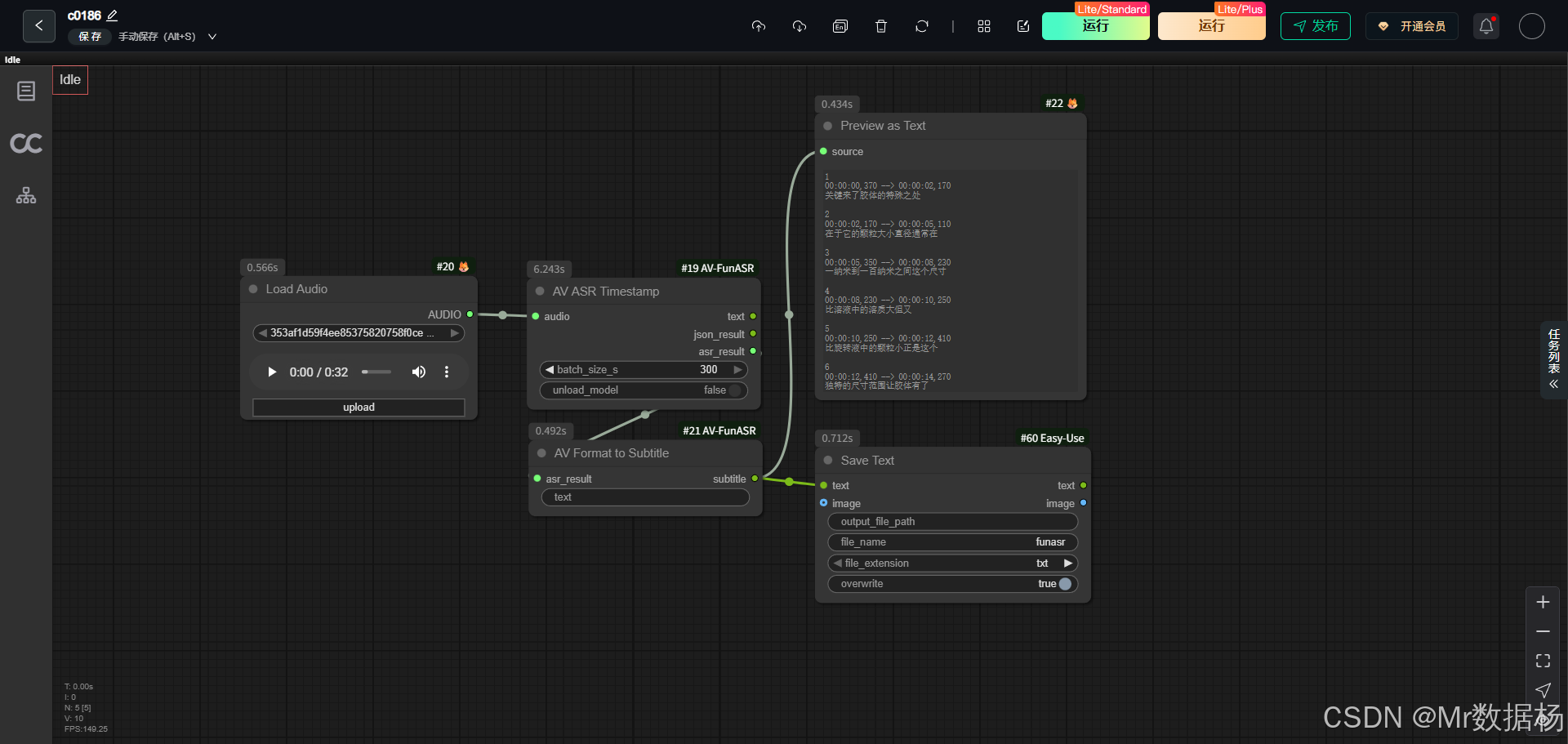
核心模型
该工作流的核心模型围绕 FunASR 语音识别体系 构建,主要承担音频内容的自动语音识别与时间戳对齐任务。模型在工作流中并不以"显式加载模型节点"的方式出现,而是被集成在 ASR 处理节点内部,用户只需提供音频输入即可完成完整的识别过程。
在实际使用中,核心模型会对音频进行分段分析,将连续语音转换为结构化的文本结果,同时生成对应的时间戳信息。这种输出形式不仅适合直接阅读,也为后续字幕格式化、文本保存以及内容再加工提供了稳定的数据基础,使整个工作流既简洁又具备较强的实用性。
| 模型名称 | 说明 |
|---|---|
| FunASR(集成于 ASR 节点) | 用于音频到文本的自动语音识别,支持时间戳输出,为字幕生成和文本整理提供基础能力 |
Node 节点
该工作流的 Node 节点设计以"音频 → 识别 → 格式化 → 输出"为主线,节点数量精简但功能覆盖完整。每个节点在流程中都有明确分工,通过数据连线形成清晰的处理路径,使用户可以直观看到音频是如何一步步转化为可用文本和字幕的。
节点之间的衔接注重实际使用场景,一方面提供识别结果的实时预览,另一方面支持将最终内容直接保存为文本文件,减少额外处理步骤,提升整体效率。
| 节点名称 | 说明 |
|---|---|
| LoadAudio | 加载本地音频文件,作为整个工作流的输入源 |
| AVASRTimestamp | 对音频进行语音识别,输出带时间戳的 ASR 结果 |
| AVFormat2Subtitle | 将 ASR 结果转换为字幕或可读文本格式 |
| PreviewAny | 对识别或字幕结果进行可视化预览,便于快速检查 |
| easy saveText | 将最终文本或字幕内容保存为本地文件,支持直接输出 |
工作流程
该工作流的整体流程围绕音频内容的自动解析与结果输出展开,从音频输入开始,到最终生成可保存、可复用的文本或字幕文件为止。流程设计强调线性与直观性,每一个阶段都对应明确的处理目标,并由对应节点完成具体工作,使用户在 ComfyUI 中可以清晰地理解数据是如何一步步流转和演变的。
从加载音频开始,工作流首先完成基础数据准备;随后进入语音识别阶段,核心模型对音频内容进行解析并生成带时间戳的 ASR 结果;在此基础上,对识别结果进行字幕格式化处理,生成更适合阅读和使用的文本结构;最后,通过预览与保存节点,实现结果的可视化检查和本地落地,形成一个完整且可直接投入使用的音频转文本处理闭环。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 音频输入 | 加载本地音频文件,作为语音识别的原始数据来源 | LoadAudio |
| 2 | 语音识别 | 对音频内容进行自动语音识别,生成带时间戳的 ASR 结果 | AVASRTimestamp |
| 3 | 格式转换 | 将 ASR 结果整理为字幕或可读性更高的文本格式 | AVFormat2Subtitle |
| 4 | 结果预览 | 对识别或字幕结果进行可视化展示,便于快速检查内容质量 | PreviewAny |
| 5 | 内容保存 | 将最终文本或字幕结果保存为本地文件,便于后续使用 | easy saveText |
大模型应用
AVASRTimestamp 语音识别与时间戳解析
AVASRTimestamp 是该工作流中承担"大模型能力"的核心节点,内部集成了 FunASR 语音识别模型,用于将输入音频自动转换为文本,并同步生成精确的时间戳信息。
该节点的职责非常聚焦,只负责对音频内容进行语音理解与结构化输出,不参与字幕格式化或文件保存等后处理工作。虽然它不依赖显式的 Prompt 文本控制,但其内部参数(如分段时长、批处理设置)在实际效果上起到了类似 Prompt 的作用,间接影响识别的连贯性、准确度以及长音频处理的稳定性。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| AVASRTimestamp | 无(该节点不使用显式 Prompt,语义由模型与参数控制) | 基于 FunASR 的语音识别节点,负责将音频解析为文本并输出对应时间戳结果 |
使用方法
该工作流的运行逻辑以"音频驱动的自动化处理"为核心,用户只需替换输入音频素材,即可完整触发从语音识别到文本/字幕输出的全过程。音频通过 LoadAudio 节点进入工作流后,会被直接送入 ASR 大模型节点进行解析,生成结构化的识别结果;随后这些结果会被自动整理为可读文本或字幕格式,并在预览节点中展示,最终由保存节点输出为本地文件。
在整个过程中,用户无需手动干预中间步骤,只需要关注输入音频本身以及 ASR 节点的关键参数设置即可。音频是唯一必须的核心素材,其内容质量直接决定最终识别效果;其他节点更多承担流程衔接与结果输出的角色,保证整体自动化顺畅运行。
| 注意点 | 说明 |
|---|---|
| 音频清晰度 | 尽量使用人声清晰、背景噪音较少的音频,可明显提升识别准确率 |
| 音频时长 | 超长音频建议合理设置分段参数,避免一次性处理导致效率或稳定性下降 |
| 语言匹配 | 确保音频语言与 ASR 模型支持的语言一致,否则可能出现识别错误 |
| 输出检查 | 建议先通过预览节点确认识别内容,再进行最终文本保存 |
应用场景
该工作流在实际应用中具有较强的通用性,适用于多种音频内容整理与文本化需求。通过一次音频输入,即可快速获得结构清晰、带时间信息的文本结果,显著降低人工听写和整理的成本。无论是日常办公、内容创作,还是音视频生产流程中的辅助环节,都可以通过该工作流实现高效自动化处理。
结合不同使用目标,用户可以将输出结果直接用于字幕制作、文稿整理或内容归档,进一步扩展到翻译、润色或二次编辑等后续流程中,充分发挥 ComfyUI 工作流的可组合优势。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 视频字幕生成 | 快速生成带时间轴的字幕文本 | 视频创作者、自媒体 | 音频对应字幕内容 | 提升字幕制作效率,减少人工校对 |
| 会议录音整理 | 将会议音频转为文字记录 | 办公人员、项目团队 | 会议全文文本 | 快速形成可检索的会议纪要 |
| 课程与访谈转写 | 将长音频内容转为可阅读文本 | 教育从业者、播客作者 | 课程或访谈文本 | 便于整理、发布与二次编辑 |
| 音频内容归档 | 为音频资料生成文字备份 | 研究人员、资料管理者 | 结构化文本文件 | 提高资料管理与查阅效率 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用