Redis 数据类型String,List,Set
(String、List、Set 底层实现原理)
一、String 类型(底层结构:RAW、EMBSTR、INT)
String 是 Redis 最基础的类型,底层实现由 RedisObject + SDS 组成。
根据值的大小和类型不同,String 的 encoding 有三种:
1.1 RAW(OBJ_ENCODING_RAW)
适用场景:
- 长度大于 44 字节的字符串
- 或者 String 被修改过(embstr 被扩容后自动变 RAW)
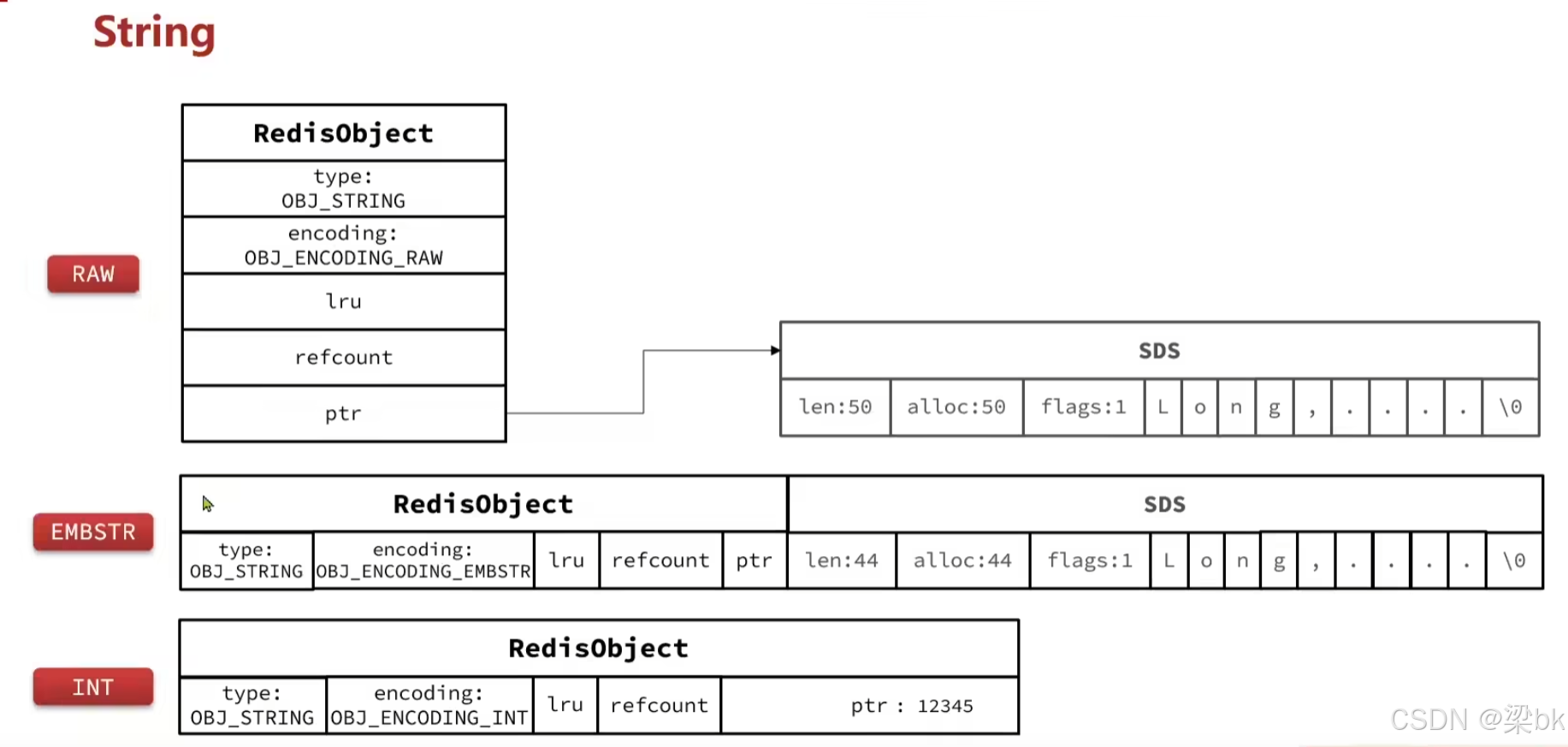
结构示意(图 1):
RedisObject
├ type: OBJ_STRING
├ encoding: OBJ_ENCODING_RAW
├ lru
├ refcount
└ ptr → SDS而 SDS 内部结构:
len / alloc / flags / buf[]特点:
- RedisObject 与 SDS 分开分配(两次 malloc)
- 适合可变长字符串
- 支持 SDS 的自动扩容、惰性空间释放
1.2 EMBSTR(OBJ_ENCODING_EMBSTR)
适用条件:
- 字符串长度 ≤ 44 字节(Redis 6+)
- 初次创建时满足条件
结构示意:
RedisObject + SDS 统一分配在连续内存中特点:
- 只 malloc 一次,内存连续
- 释放时速度更快(一次 free)
- 更适合短字符串、小 JSON、小 token
但:
- 一旦修改长度 → 自动转为 RAW
1.3 INT(OBJ_ENCODING_INT)
适用于:
- 字符串内容为整数
- 且在 64bit 有符号整数范围内
结构示意:
RedisObject
├ type: OBJ_STRING
├ encoding: OBJ_ENCODING_INT
└ ptr = 整数值(long long)特点:
- 不使用 SDS,直接存整数指针
- 占用内存最少
- 性能最高
1.4 String 底层编码转换规则(面试高频)
| 值类型 | 编码 |
|---|---|
| 整数 | INT |
| 短字符串(≤44B) | EMBSTR |
| 长字符串 | RAW |
| embstr 被修改后 | RAW |
二、List 类型(底层结构:quicklist)
从 Redis 3.2 开始,List 的底层实现全部使用:
quicklist = linkedlist + ziplist 的结合体
示意图:
RedisObject(type=OBJ_LIST, encoding=OBJ_ENCODING_QUICKLIST)
↓
QuickList
↓
多个 QuickListNode 节点(双向链表)
↓
每个 node 内部保存一个 ziplist2.1 为什么需要 quicklist?
旧版本的 List 结构:
- 元素少 → ziplist
- 元素多 → linkedlist
缺点:
- linkedlist 内存碎片严重
- ziplist 大了以后插入/删除效率差
quicklist = ziplist(紧凑内存) + linkedlist(灵活插入删除)
2.2 quicklist 的结构解析
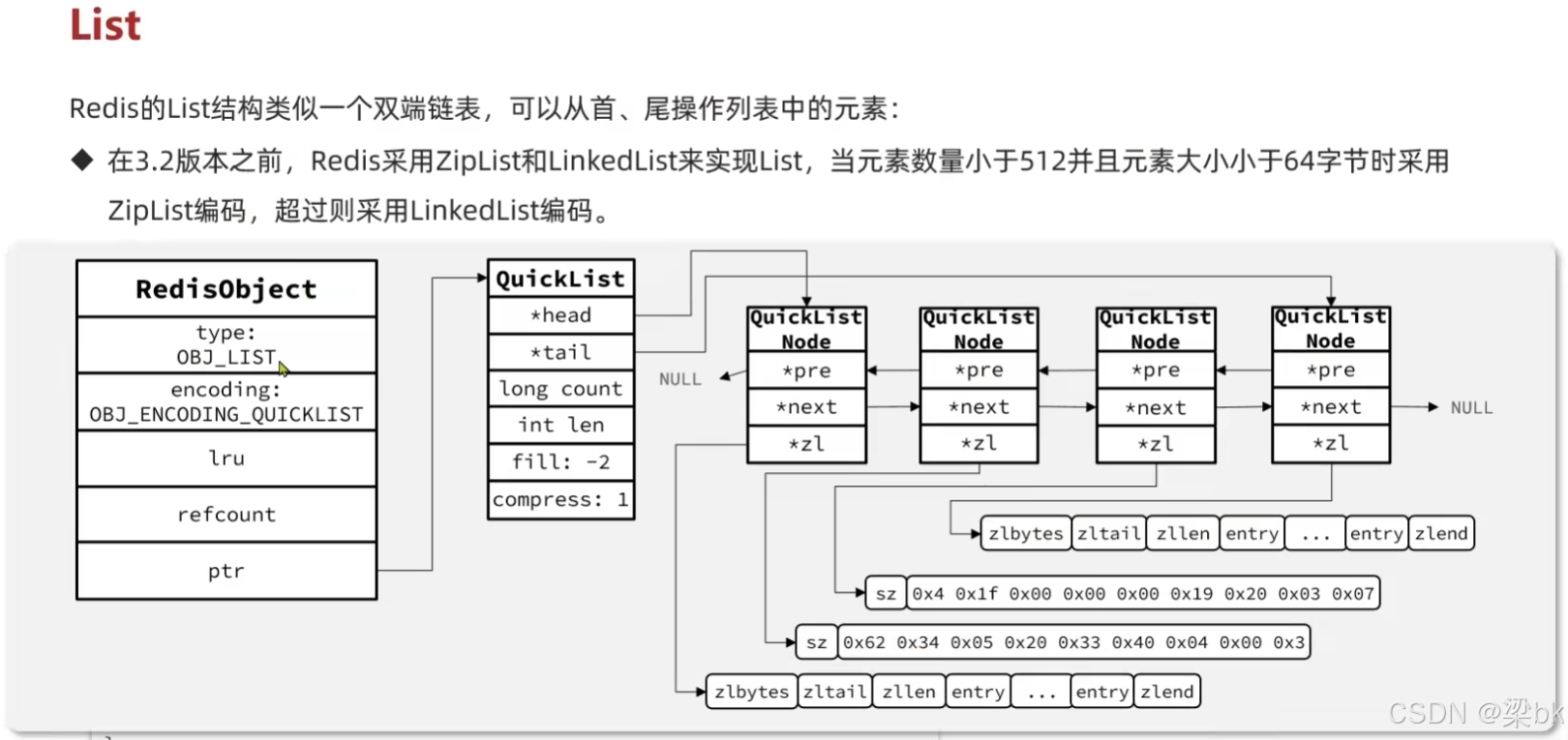
QuickList
QuickList
├ head
├ tail
├ count // 总元素统计
├ len // 节点数量(多少个 ziplist)
├ fill // 每个 ziplist 最大容量策略
└ compress // 是否开启压缩QuickListNode
每个 node 是一个 ziplist:
QuickListNode
├ *pre
├ *next
└ *zl(ziplist)ziplist 内部结构
zlbytes / zltail / zllen / entry... / zlend2.3 quicklist 的优势
- 内存紧凑(ziplist)
- 插入删除效率高(链表 node 跳转)
- 支持 ziplist 压缩(节省内存)
- 兼顾性能 & 内存消耗
2.4 quicklist 的使用场景
Redis List 类型操作:
- LPUSH / RPUSH
- LPOP / RPOP
- LRANGE
- Trim 队列
- 消息队列(非阻塞场景)
三、Set 类型(底层结构:intset / dict)
Set 是一个无序、不重复的集合,底层结构分两种情况:
3.1 intset(OBJ_ENCODING_INTSET)
当满足两个条件时使用 intset:
- 所有元素都是整数
- 元素数量 ≤
set-max-intset-entries(默认 512)
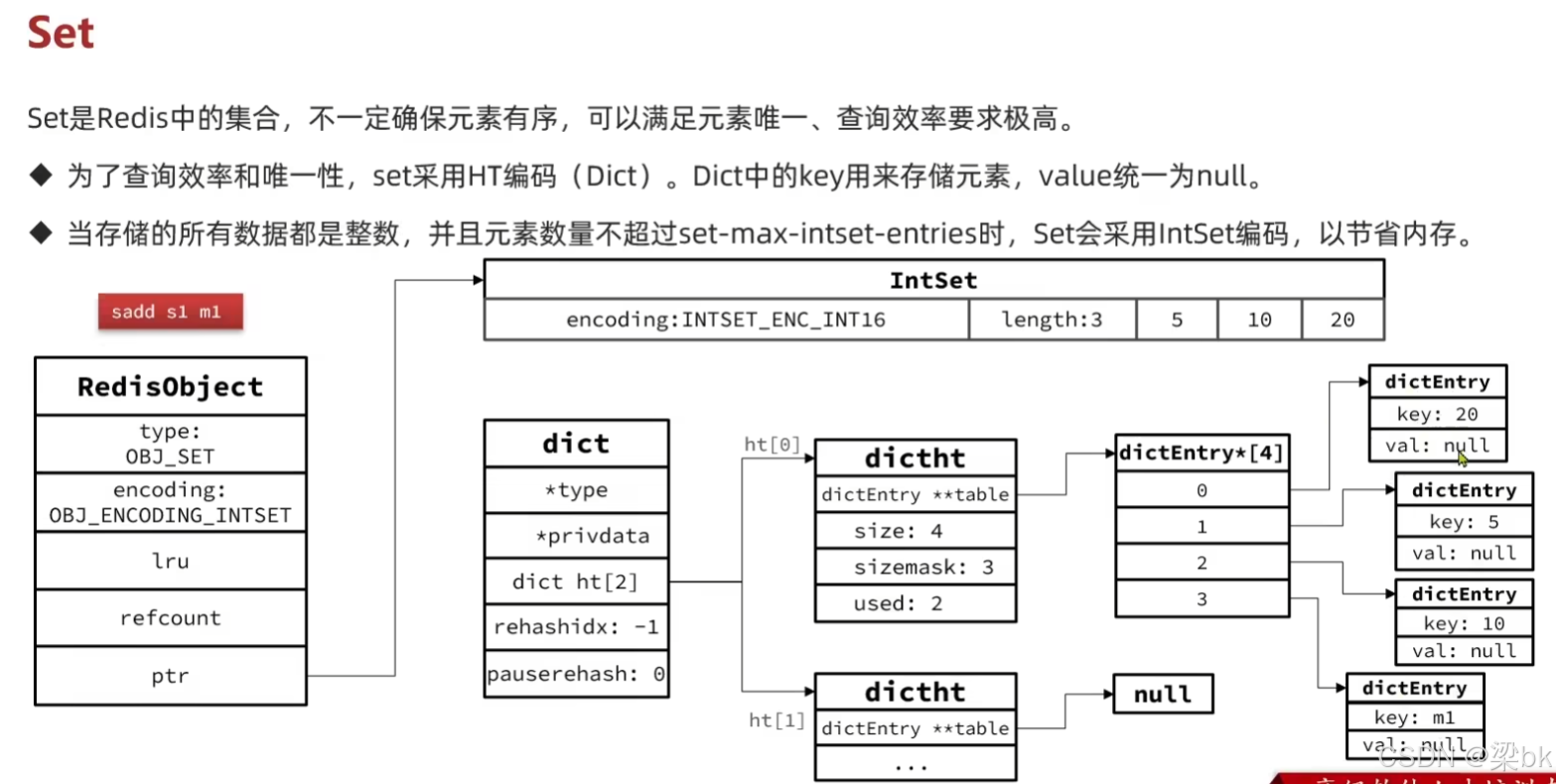
结构示意:
RedisObject(type=OBJ_SET, encoding=OBJ_ENCODING_INTSET)
↓
IntSet
├ encoding(int16/int32/int64)
├ length
└ contents[](升序排列整数)特点:
- 紧凑高效(连续内存)
- 查找用二分查找(O(logN))
- 插入 O(N)
- 内存使用非常低
适合:
- 用户 ID、商品 ID 集合
- 小集合场景
超过阈值或包含非整数 → 自动升级为 dict。
3.2 dict 结构(OBJ_ENCODING_HT)
当不满足 intset 条件时,升级成 hashtable(dict):
结构示意(图 3):
RedisObject(type=OBJ_SET, encoding=OBJ_ENCODING_HT)
↓
dict
↓ ht[0], ht[1](渐进式 rehash)
↓
dictEntry(key=value元素, val=null)Set 的 value 统一为 null。
dict 特点:
- 查询 O(1)
- 支持渐进式 rehash(不会阻塞)
- 大集合适用
适合:
- 大规模集合(上万、百万)
- 频繁添加删除的业务
四、三种数据类型结构对比总结表
| 数据类型 | 底层编码 | 结构特点 | 使用场景 |
|---|---|---|---|
| String | INT | 直接存 long long | 计数器、数字值 |
| EMBSTR | RedisObject + SDS 连续内存 | 短字符串、高性能 | |
| RAW | RedisObject 与 SDS 分离 | 长字符串、大 JSON | |
| List | quicklist | ziplist + linkedlist | 队列、日志、分页读取 |
| Set | intset | 升序数组 + 二分查找 | 小整数集合 |
| dict | 哈希表 | 大规模集合 |
五、常考面试点总结
1. String 为什么有三种编码?
因为:
- 整数更省内存(int)
- 短字符串更快(embstr)
- 长字符串更灵活(raw)
2. List 为什么使用 quicklist?
因为:
- ziplist 内存紧凑但扩容慢
- linkedlist 插入快但浪费空间
- quicklist 结合两者优点
3. Set 为什么用 intset/dict 两种?
因为:
- 小整数集合 → intset(内存极其小)
- 大集合/复杂元素 → dict(复杂度 O(1))
4. Set 如何从 intset 切换到 dict?
触发条件:
- 插入非整数
- 集合大小超过阈值 (默认 512)
六、总结(背诵版)
String:RAW / EMBSTR / INT
- INT:整数
- EMBSTR:短字符串(一次分配)
- RAW:长字符串(两次分配,可扩容)
List:quicklist
- 链表节点 + 每个节点是 ziplist
- 内存节省、插入删除快
Set:intset / dict
- 小整数集合 → intset
- 大集合或非整数 → dict