一、Canal官网文档

去到官方文档根据官网文档进行操作:

二、开启服务器中MySQL的binlog

[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
进行修改:

登录root
mysql -uroot -p
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;
改完后可以在MySQL命令行中使用下面的指令查看是否开启成功,value为ON就是开启成功:
show variables like 'log_bin';注意注意:记得修改后一定要重启MySQL,我就是因为忘记重启了找了一天的bug ,不记得重启会出现后面第八点那个问题。
三、将canal-deployer下载到服务器


cd /tmp/canal
tar zxvf canal.deployer-1.1.8-SNAPSHOT.tar.gz
解压后:

建议这边弄一个单独的文件夹把压缩包放进去再去解压,不然后面还有其他的会比较影响

弄一个类似这种文件夹,在对应的文件夹里面放压缩包,再去解压,后面我都是这种步骤,由于没有保留截图,上面那些还是最开始的演示,建议后面修改一下。
四、修改对应配置文件



五、启动canal 服务端
启动指令:
sh bin/startup.sh关闭指令:
sh bin/stop.sh
这个是我服务器jdk下载的位置,去找到自己对应的位置即可,后面我改用jdk11了,11是没问题的,记得17可能有些问题,可以参考下面这个步骤来就行,版本可以用11。
jdk下载可以参考这篇博客:

编辑下面这个文件

在这个文件内添加下面信息
export JAVA_HOME=/www/server/java/jdk-17.0.8/
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
修改完,重新加载一下:
source /etc/profile然后使用下面指令查看jdk版本,没问题即可:
java -version再次执行启动命令
sh bin/startup.sh
查看输出日志:



启动成功!服务端启动成功!
如果启动不成功,有下面这个报错:
Caused by: org.h2.jdbc.JdbcSQLDataException: Value too long for column "CHARACTER VARYING
可以参考这两个Issues:
Value too long for column "CHARACTER VARYING" · Issue #5086 · alibaba/canal · GitHubI have searched the issues of this repository and believe that this is not a duplicate. I have checked the FAQ of this repository and believe that this is not a duplicate. environment ubuntu20 canal version \*1.1.8-alpha mysql version mys...\[这里是图片027https://github.com/alibaba/canal/issues/5086\](https://github.com/alibaba/canal/issues/5086 "Value too long for column "CHARACTER VARYING" · Issue #5086 · alibaba/canal · GitHub")
我两个都没能解决,自己服务器可以,实习的服务器可能公司的表太多了,导致出问题,我是通过降低版本解决的,用1.1.16。如果有大佬解决了,欢迎评论区dd。
六、客户端
查看官方使用例子

引入依赖

<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.0</version>
</dependency>code如下:


修改后启动:

然后我插入一条数据,也是监听到了。
 测试成功。
测试成功。

七、同步ES(Sync ES)

将这个下载到服务器中某个位置:
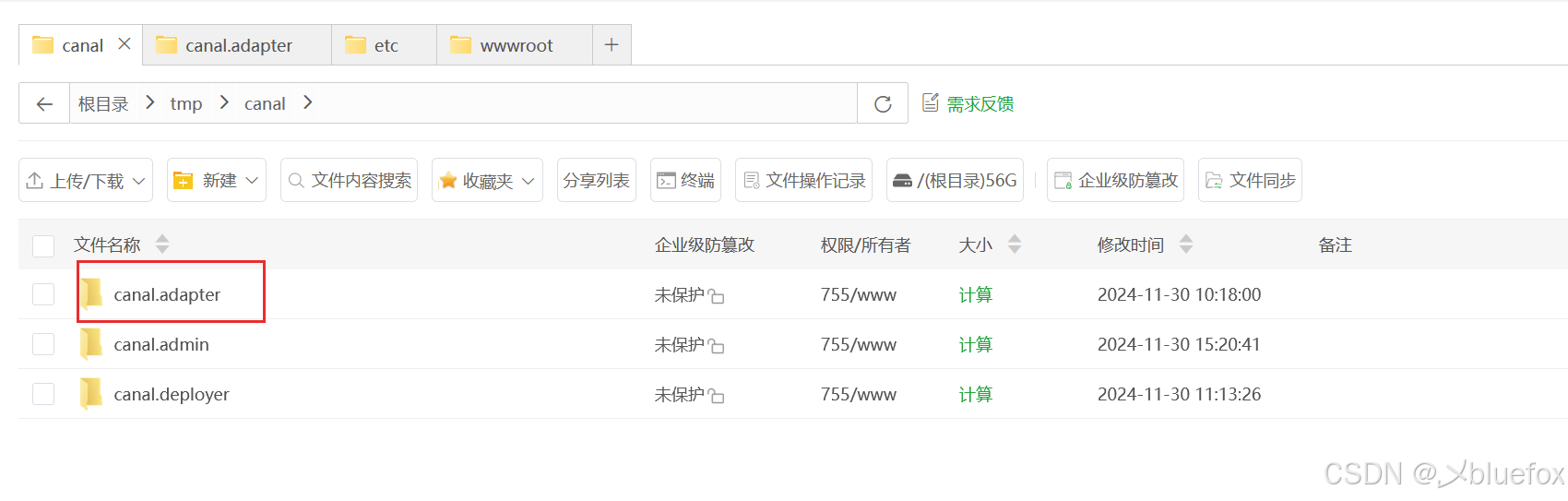
然后用下面这个命令解压
tar zxvf canal.adapter-1.1.8-SNAPSHOT.tar.gz
还有一处配置可以参考一下下面这位大佬的博客:
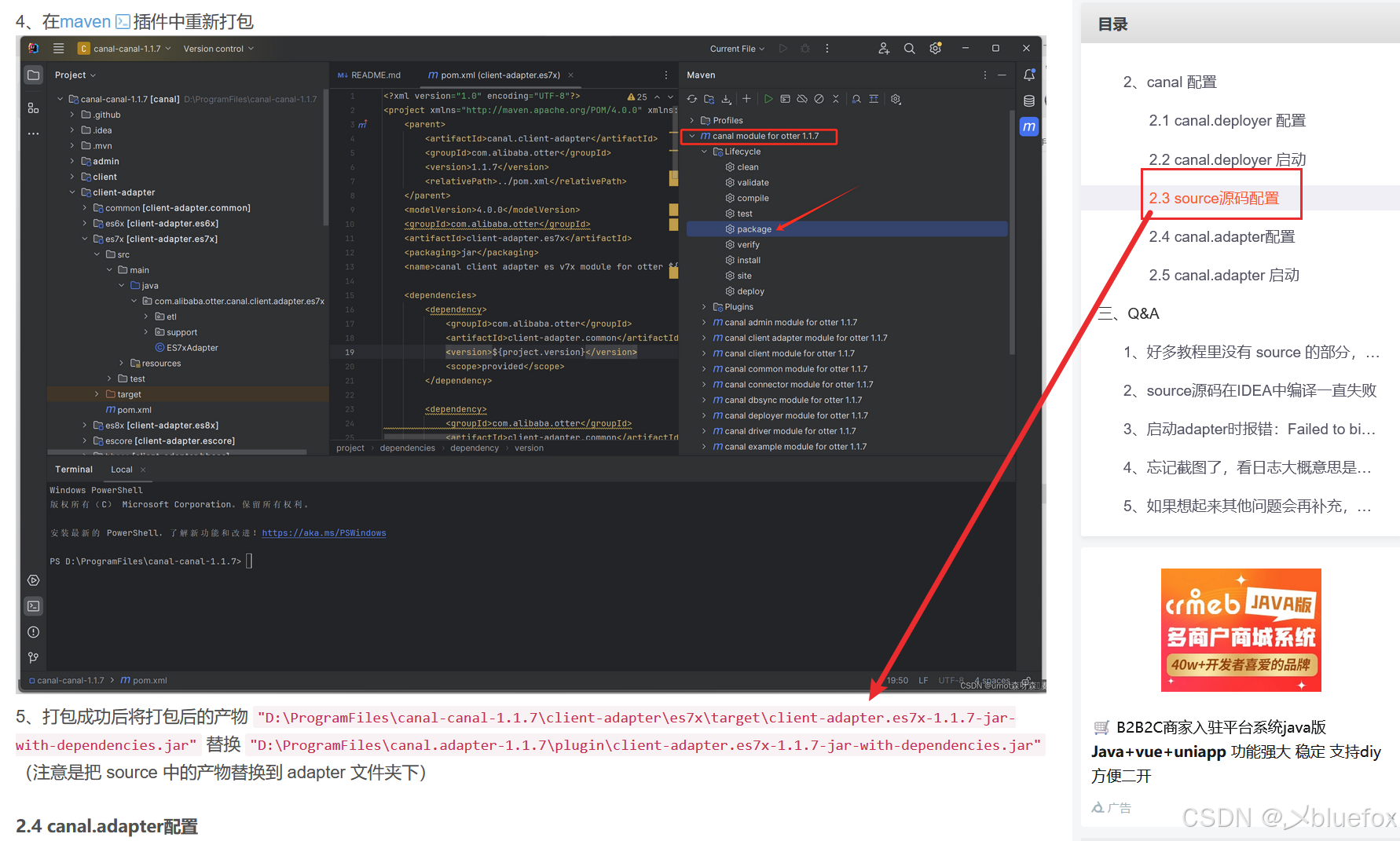
下面给出我的部分配置:


server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ
flatMessage: true
zookeeperHosts:
syncBatchSize: 1000
retries: -1
timeout:
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer
canal.tcp.server.host: 127.0.0.1:11111 #记得去防火墙开启这个端口
canal.tcp.zookeeper.hosts:
canal.tcp.batch.size: 500
canal.tcp.username:
canal.tcp.password:
# kafka consumer
kafka.bootstrap.servers: 127.0.0.1:9092
kafka.enable.auto.commit: false
kafka.auto.commit.interval.ms: 1000
kafka.auto.offset.reset: latest
kafka.request.timeout.ms: 40000
kafka.session.timeout.ms: 30000
kafka.isolation.level: read_committed
kafka.max.poll.records: 1000
# rocketMQ consumer
rocketmq.namespace:
rocketmq.namesrv.addr: 127.0.0.1:9876
rocketmq.batch.size: 1000
rocketmq.enable.message.trace: false
rocketmq.customized.trace.topic:
rocketmq.access.channel:
rocketmq.subscribe.filter:
# rabbitMQ consumer
rabbitmq.host:
rabbitmq.virtual.host:
rabbitmq.username:
rabbitmq.password:
rabbitmq.resource.ownerId:
srcDataSources:
defaultDS:
url: jdbc:mysql://你的服务器IP:3306/你的DataSource名?useUnicode=true&useSSL=false&serverTimezone=UTC
username: canal
password: canal
canalAdapters:
- instance: example # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: logger
- name: es7
hosts: http://你的服务器IP:9200
properties:
mode: rest #9200端口的话就写rest
cluster.name: elasticsearch

datasourceKey: defaultDS #源数据源的key,对应上面配置的srcDatasources中的值
destination: example #canal的instance或者MO的topic
groupId: g1 #对应MQ模式下的groupId,只会同步对应groupId的数据
esMapping:
_index: user #es 的索引名称
_id: _id #es 的 id,如果不配置该项必须配置下面的pk项 id则会由es自动分配
# 下面写你的MySQL需要配置表的查询语句(完整的语句)
sql: "SELECT
u.id AS _id,
u.id ,
u.openid,
u.quick_user_id,
u.mark_number,
u.brief_introduction
FROM
user u;" # sq1映射
commitBatch: 500 # 提交批大小开启服务:
1.进入对应目录
cd /tmp/canal/canal.adapter2.启动服务
sh bin/startup.sh
再去查看log日志:


启动成功
3.如果想要停止服务
sh bin/stop.sh如果发现运行不起来,运行了没有log日志,可以尝试下面两种解决办法:
1、降低jdk版本
2、修改分配虚拟机启动的内存

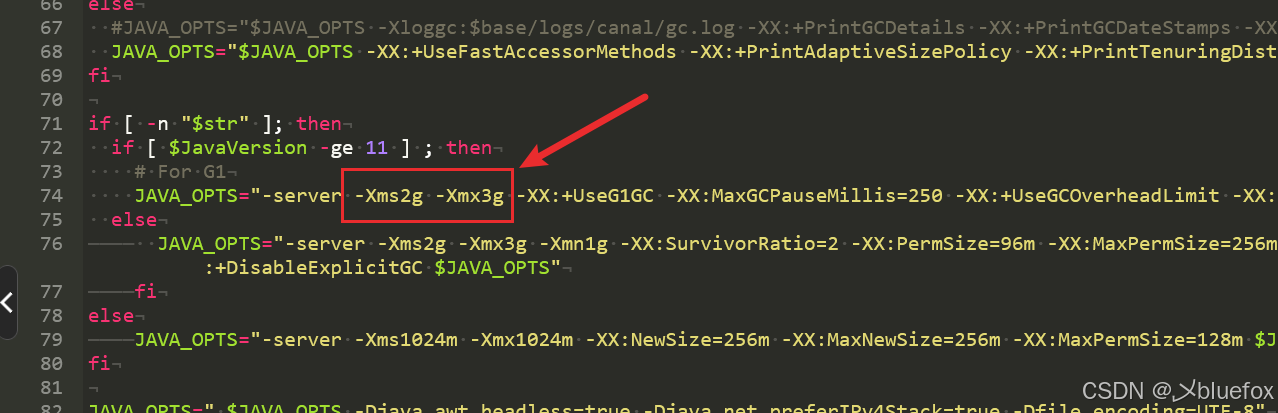
可以修改为:
-Xms512m -Xmx1024m八、测试同步

新增一条数据


更新一条数据


修改同步成功,注意上面一个配置文件中我写的查询语句并不完整,实际上是需要完整的,注意和自己表的查询语句一致,注意注意。。
九、曾遇过的bug
如果出现下面这种情况,可能是修改MySQL后没有重启MySQL。。。实习的时候被这这个问题折磨了一天,搜了各种办法,很逆天。
DEBuG c.a.0.canal.client.adapter.es,core.service.Essyncservice -ml: {"data":null,"database":"quick pickup","destination": "example","es":1732938564088,"groupId":"g1" "isDd1":false,"old":nul1,"okNames":[1,"sal

最后去重启了一下,结果发现成功了,成功监听到信息。
