第 2 章 程序组织
GCN 内核是由 GCN 处理器执行的程序。从概念上讲,内核在每个 Work-item 【注,cuda thread】上独立执行,但实际上 GCN 处理器将 64 个工作项分组为一个 Wavefront【注,cuda warp】,一次性在所有 64 个工作项上执行该内核。
GCN 处理器包含:
-
一个标量 ALU ,它对每个 Wavefront 【注,warp 内共享】的一个值(所有工作项共有的)进行操作。
-
一个向量 ALU,它对每个 Work-item 独有的值进行操作。
-
本地数据存储( Local data storage**)** ,允许 Workgroup 内的 Work-item 进行通信和共享数据。【注,cuda 中的 shared memory】
-
标量内存,可以通过缓存实现 SGPR 与内存之间的数据传输。
-
向量内存,可以实现 VGPR 与内存之间的数据传输,包括采样纹理贴图。
所有内核控制流都使用标量 ALU 指令处理 。这包括 if/else、分支和循环 。标量 ALU 和内存指令对整个 Wavefront 进行操作,最多可操作两个 SGPR 以及字面常量。
向量内存和 ALU 指令一次性对 Wavefront 中的所有工作项进行操作。为了支持分支和条件执行,每个 wavefront 都有一个 EXEC 掩码 ,用于确定当前哪些 work-item 处于活动 状态,哪些处于休眠 状态。活动工作项执行向量指令,休眠工作项则将该指令视为空操作。++标量 ALU 指令可以随时更改 EXEC 掩码。++
向量 ALU 指令****最多可以接受三个参数,这些参数可以来自 VGPR、SGPR 或指令流中包含的字面常量。它们对 EXEC 掩码启用的所有 work-items 进行操作。向量比较和带进位的加法操作会向 SGPR 返回一个按工作项分布的掩码,以指示每个工作项的比较结果是"真",或者产生了进位。
向量内存指令在 VGPR 和内存之间传输数据。每个 work-item 提供自己的内存地址,并提供或接收其独有的数据。这些指令同样受EXEC 掩码 的约束。
2.1. 计算着色器
计算内核(着色器)是可以在 GCN 处理器上运行的通用程序,它们从内存中获取数据,进行处理,然后将结果写回内存。计算内核由一次dispatch(**分派)**创建,dispatch 会驱使 GCN 处理器在一个一维、二维或三维数据网格的所有工作项上运行该内核。GCN 处理器遍历此网格并生成 wavefront ,然后这些 wavefront 运行计算内核。每个 work-item 都以其在网格中的唯一地址(索引)进行初始化。基于这个索引,work-item 计算它需要处理的数据地址以及如何处理结果。
2.2. 数据共享
AMD GCN 流处理器设计用于在不同工作项之间共享数据。数据共享可以提升性能。下图展示了每个工作项可用的内存层次结构。
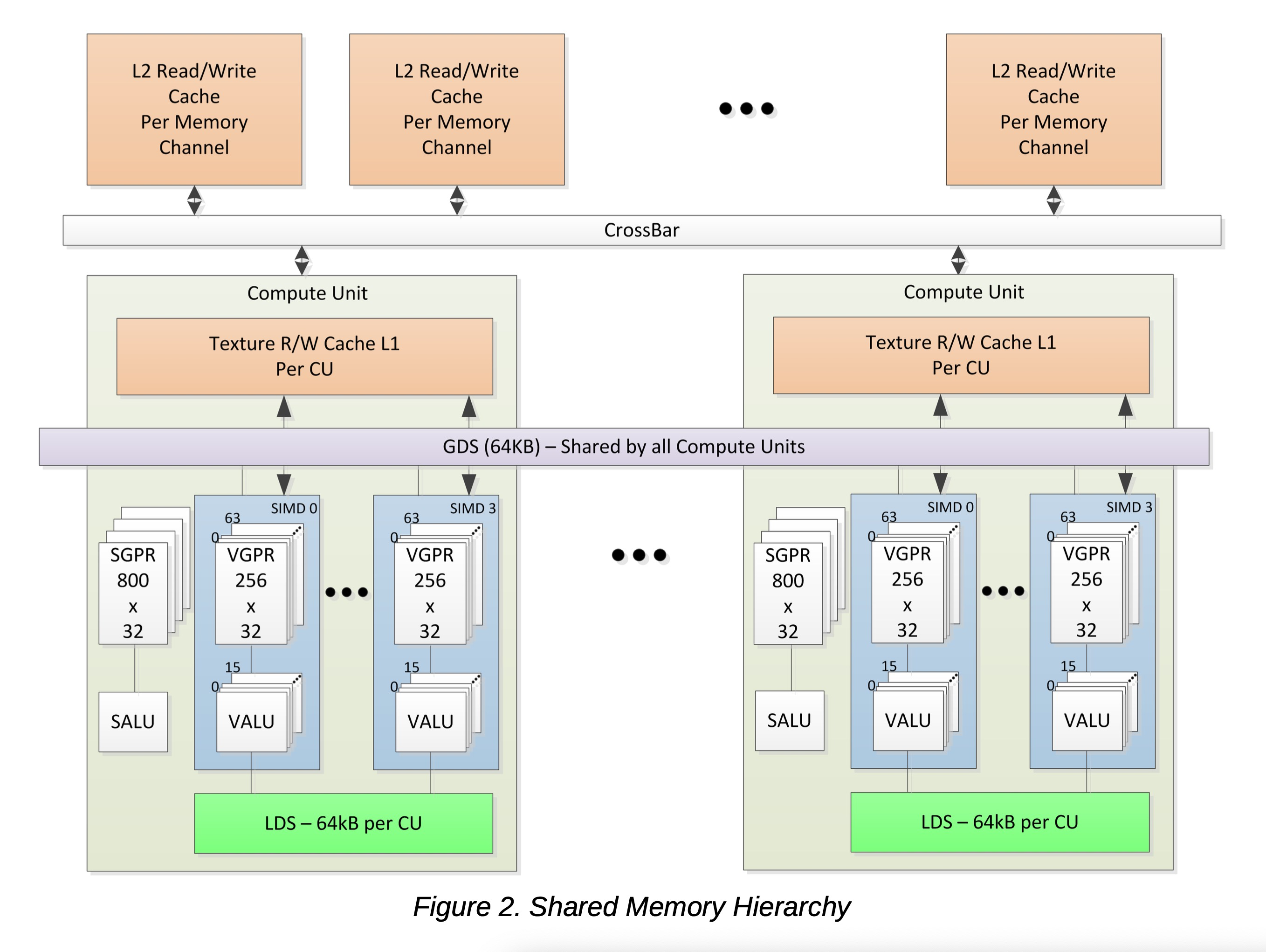
2.2.1. 本地数据共享
每个计算单元【注,CU,对应 cuda 的 sm,是一个block/workgroup 占用的最大物理单元】拥有一个 64 kB 的内存空间,用于在 workgroup 内的 work-item 之间或 workfront 内的 work-item 之间进行低延迟通信;这称为本地数据共享 【注,对应 cuda sharedMem+L1 cache】。此内存配置为32 个 banks(存储体) ,每个 bank 有 512 个 4 字节条目。AMD GCN 处理器为每个计算单元(CU) 使用 64 kB 的 LDS 内存;这为处理元件提供了 64 kB 的低延迟带宽。这些共享的内存包含 32 个整数原子单元,以支持快速的无序原子操作。此内存可用作可预测数据重用的软件缓存、workgroup 内 work-item 的数据交换机器,或作为高效访问片外内存的协作方式。
2.2.2. 全局数据共享
AMD GCN 设备使用一个 64 kB 的全局数据共享 内存(GDS),可由所有计算单元上的内核 wavefront 使用。此内存为所有处理元件提供每周期 128 字节的访问带宽。GDS 配置为 32 个 bank (存储体),每个 bank 有 512 个 4 字节条目。它旨在为任何处理器提供对任意位置的全方位访问 。这些共享的内存包含 32 个整数原子单元 ,以支持快速的无序原子操作 。此 GDS 内存可用作软件缓存来存储计算内核的重要控制数据、归约操作或小的全局共享 surface。数据可以在内核启动前从内存预加载,并在内核完成后写回内存 。GDS 块包含支持逻辑,用于内存中缓冲区的无序追加/消费以及域启动有序追加/消费操作 。这些专用电路支持在内存中快速压缩数据或创建复杂数据结构。【注,没用过,GDS 是amd gpu 跟cuda arch 不一样的地方,不明白这是什么】
2.3. 设备内存
AMD GCN 设备提供了多种方法,供每个计算单元(CU)内的处理元件访问片外内存。在主读路径上,设备由多个 L2 只读缓存通道组成,这些通道为每个计算单元(CU)提供数据给 L1 缓存。
特定的无缓存加载指令 可以强制在加载子句执行期间从设备内存检索数据。子句内重叠的加载请求会相对于彼此进行缓存。
输出缓存由两级缓存构成:第一级是写合并缓存(收集分散存储操作并将其合并,以提供对内存的良好访问模式) ;第二级是带有原子单元的读/写缓存,允许每个处理元件完成无序原子访问并返回初始值。每个处理元件提供原子操作的目标地址、原子操作中要使用的数据,以及读/写原子单元 用于在内存中存储操作前值的返回地址**。** 每个存储或原子操作都可以设置为在返回值(目标地址的原子操作前值)被存储到设备内存并收到写入确认后,向请求的处理元件返回一个确认。
此确认有两个目的:
-
允许一个处理元件在收到写入确认后,通过从其返回地址执行无缓存加载,来从原子操作中恢复操作前值。
-
允许系统维持一个宽松的一致性模型。
从给定处理元件到给定内存通道的每个分散写入都保持顺序。该确认使一个处理元件能够通过确保在完成后续写入之前,所有写入都已提交到内存,来实现一个栅栏以维持串行一致性。通过这种方式,系统可以在所有并行 work-item 之间维持一个宽松的一致性模型。
【注,
问:
但是,文中指出的顺序保持,仅仅针对同一个PE到同一个内存通道的分散写入。所以,是否可以认为,这种保序与确认的机制,并不能保证全局的内存写入都已经完成呢?从而不能实现保序效果?
答:
您的问题非常精准,这触及了GPU并行内存体系设计的核心权衡。您的理解完全正确:
是的,这种机制确实无法保证所有并行线程(所有PE)之间的全局写入顺序,但它能非常高效地实现程序员所需的"保序效果"。 这是一个"有限范围的保序 "与"按需建立全局同步"的经典设计。
让我们更清晰地分解这个问题:
1. "保序"的范围界定:局部有序 vs 全局无序
-
局部有序(文中所指)
-
仅限于 "从单个PE到单个内存通道" 的写入流。
-
如果同一个线程(PE)先后发出两个写入请求到内存的同一块区域(由同一内存通道控制器管理),那么硬件保证先发出的请求先被内存控制器处理。这对于单个线程内操作的逻辑正确性至关重要。
-
类比:像一个单车道收费站,从同一辆车(PE)出来的请求,先到的先处理。
-
-
全局无序
-
来自不同PE (不同线程)的写入请求,无论是到相同还是不同的内存通道,默认是没有顺序保证的。它们的完成顺序是乱序的、不确定的。
-
来自同一PE到不同内存通道的写入,顺序也可能无法保证,因为可能由不同的控制器异步处理。
-
类比:像有多个并行的收费站,不同车道的车辆到达目的地(内存)的先后顺序是随机的。
-
2. 确认机制的作用:从"局部保序"到"可控的全局同步"
确认机制本身不创造全局顺序,但它为程序员提供了一个强大的工具,可以在需要时主动构建出全局同步点。
-
**机制上,**每次写入(或原子操作)完成后,会向发起请求的PE发送一个确认。
-
如何实现"保序效果":
-
线程内顺序的强化 :一个PE可以等待自己发出的所有 相关写入操作的确认。当它收到所有确认后,它就知道自己之前的所有写入都已被内存系统确认接收。这对于该线程后续的操作(例如,通知其他线程数据已就绪)是一个可靠的里程碑。
-
构建内存栅栏 :这正是段落最后一句"
The acknowledgment enables one processing element to implement a fence..."的含义。-
如果一个PE执行了以下逻辑:
- 发出写入A -> 等待A的确认 -> 发出写入B
-
那么,对于任何其他同样使用确认机制来观察顺序 的线程来说,它们将看到写入A先于写入B生效(因为B只有在A完成后才会发出)。这就在该PE的操作序列中建立了一个"释放-获取"语义的栅栏。
-
-
跨线程同步需要显式操作 :要实现所有线程的全局写入都对彼此可见,不能仅依赖硬件自动保序。程序员必须使用:
-
原子操作 (如
atomicAdd)在特定地址上进行同步。 -
内存栅栏指令 (如
__threadfence()),其内部实现很可能就是基于这种确认机制------该指令会冲刷该线程的所有待处理写入,并等待它们的确认,从而在全局内存中建立一个所有线程都能观察到的同步点。 -
工作组同步 (如
barrier),它保证组内所有线程都到达该点,并且组内所有线程在此之前的LDS和全局内存操作对组内其他线程可见。
-
-
结论:设计的哲学
这不是设计的缺陷,而是为性能做出的主动设计选择。
-
性能优先 :强制全局顺序会严重限制内存控制器的并行性和流水线深度,导致性能大幅下降。GPU是为吞吐量而生的,默认采用宽松内存模型是行业标准做法。
-
正确性可保障 :通过提供确认 、原子操作 、栅栏 这些底层原语 ,硬件将控制权交给了软件(程序员或编译器) 。程序员在确实需要顺序保证的"关键区域"(如同步点、数据发布)主动插入同步指令,而在其他大规模的并行计算部分,则享受乱序执行带来的极致性能。
-
"保序效果"是软件构建的 :最终程序表现出的正确"保序效果",是程序员正确使用同步原语的结果,而非硬件自动提供的全局保证。硬件提供的是高效的工具(局部保序+确认机制),软件用这些工具来搭建出正确的执行顺序。
所以,回到您的问题:
这种机制本身不能保证全局写入完成顺序,因此不能自动实现全局保序效果 。但正是因为它不自动保证,才换来了高性能。而它提供的确认机制,正是让程序员能够在必要时,以可观的性能代价,主动、精确地构建出所需保序效果 的基石。这是一种非常经典且高效的"默认宽松,按需严格"的并行内存设计哲学。
】