第7章 减少填充的排序
填充最小化问题可以表述如下:给定矩阵 ,找到行和列置换
和
(对于稀疏Cholesky分解,附加约束
),使得
分解后的非零元数量,或计算它所需的工作量,最小化。该问题在实践中无法解决,因此使用启发式方法来尝试减少填充。存在三种基本策略;它们有时会结合使用以获得混合策略:(1)最小度及其变体(例如,最小填充),(2)嵌套剖分(递归图划分),以及(3)带宽缩减。第一种策略最常见,下面详细介绍。其他两种策略的特点会着重说明。Dulmage-Mendelsohn分解是一种置换,可以减少 LU 和 QR 分解所需的工作量。它包括两个主要步骤:一个置换以获得零自由对角线,另一个将矩阵置换为块三角形式。该方法也可用于将边分隔符转换为节点分隔符,这在许多嵌套剖分方法中使用。
7.1 最小度排序
最小度算法是一种广泛使用的启发式方法,用于寻找置换 ,使得
分解中的非零元比
少。它是一种贪婪方法,在right-looking稀疏Cholesky分解过程中选择最稀疏的主元行和列(参见第4.9节)。考虑以下MATLAB代码片段,它不进行主元选择:
Matlab
for k = 1:n
L (k,k) = sqrt (A (k,k)) ;
L (k+1:n,k) = A (k+1:n,k) / L (k,k) ;
A (k+1:n,k+1:n) = A (k+1:n,k+1:n) - L (k+1:n,k) * L (k+1:n,k)' ;
end第k步用外积L(:,k)*L(:,k)'更新A。设 表示第
次迭代开始时的矩阵A(k:n,k:n)。考虑
的无向图
,其中节点
,且如果
,则
。图
被称为消去图。如果
是 L(:,k) 的非零模式,则对
的更新对应于向
添加一个稠密子矩阵,并在
中添加一个团并移除节点
。商图
不是将
表示为简单图,而是隐式地表示这个团。节点
被替换为具有邻居
的元素
。术语"元素"借用自有限元方法,因为它们也是图中稠密子矩阵或团的集合。一个未被消去的节点
的邻接列表有两种与其相邻的节点:
是对应于原始非零元
的列表,
是与i相邻的元素列表。因此,行或列
的非零模式为:
(7.1)
不包括对角线(在a或g中不出现自环)。节点 的度
是集合(7.1)的大小。当节点
被消去时,与其相邻的任何元素不再需要表示
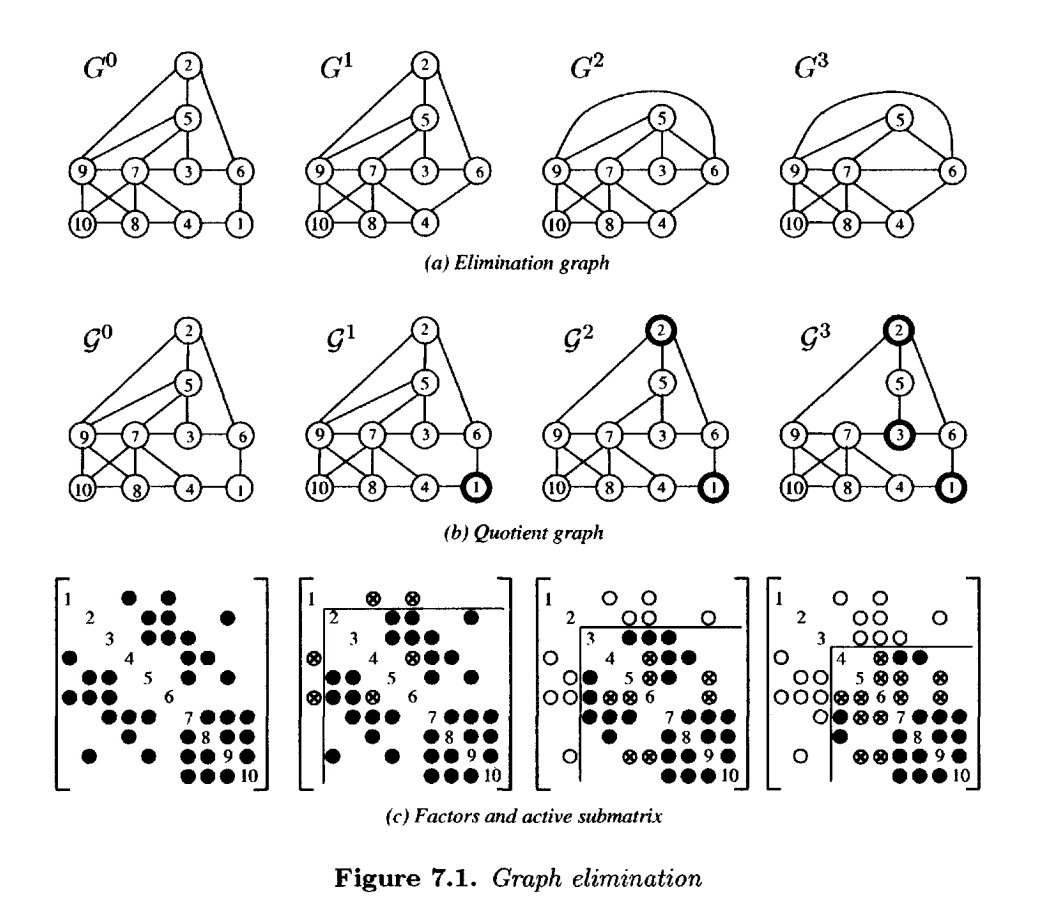
的非零模式(理论4.13的推论);这些元素可以被移除(称为元素吸收)。图7.1给出了图
和商图
的一个示例序列。在图中,普通圆圈代表
中的节点,而暗色圆圈代表元素。在矩阵中,实心圆代表
中两个节点之间的边,圆圈代表不再存在于
中的边,带圈的x是由
中的元素表示的
中的边。
中的额外项可以被剪枝。如果两个节点
和
都在主元元素
中,那么j和i可以分别从
和
中移除。它们可能由于原始条目
而相邻,并且在
中仍然相邻,因为它们都与元素
相邻。也就是说,对于所有
,
可以被替换为较小的集合
(这里称为剪枝)。通过元素吸收和
集的剪枝,图
可以在原地表示(其大小永远不会超过
)。
使用这种图表示 ,最小度算法简单地包括节点的贪婪重排序。该算法不是在第
步选择节点
,而是选择具有最小度的节点。当创建一个元素k时,必须使用(7.1)重新计算所有
的节点的度。这是算法中最耗时的部分。
通过利用超节点(也称为不可区分节点)可以降低成本。如果两个节点i和j变得相同( 且
),它们将保持相同,直到其中一个被消去(要么两者都与主元元素相邻,要么两者都不相邻)。当其中一个成为最小度节点时,另一个也是最小度节点,同时消去两者在
中引起的边不会比只消去其中一个多。因此,如果发现两个节点
和
不可区分,它们可以合并成一个代表两者的超节点。这是通过移除其中一个节点(比如
)并让
成为包含i和j的超节点的代表(
已被吸收到
中)来实现的。最小度算法选择一个最小度的超节点
并将其消去。所有节点一开始只代表自己。
被消去后,如果一个节点
只剩下与
的边(
且
为空),它可以被立即消去(称为批量消去)。令
表示超节点
代表的节点数。为简化符号,在处理集合表达式时,将i用作集合的成员应解释为
代表的节点集。
超节点和批量消减了必须评估(7.1)的次数。另一种技术是放弃使用(7.1),而是使用真实度 的近似值
,计算成本更低,其中
(7.2)
并且 是当前主元元素,并且假设
已经被剪枝。注意,如果
(其中
包括
),则
,因为在剪枝后
和
是不相交的。否则,
。使用
代替
得到近似最小度算法,或称 AMD 。乍一看,(7.2)看起来并不比计算集合(7.1)然后求其大小简单。下面的scan1算法展示了如何有效地计算集合差
。在(7.2)和随后的讨论中,
和
指的是它们所包含的节点
的
之和。
function scan1
assume w(e) < 0 for all e = 1, ... , n
for each node i ∈ Ck do
for each element e ∈ εi do
if (w(e) < 0) then w(e) = |Ce|
w(e) = w(e) - |i|那么如果 ,则
。如果
,则集合
和
是不相交的,且
。一旦知道了集合差,第二次遍历所有
,评估(7.2)以计算
。计算集合差、计算
和剪枝集合
的平摊时间是
。这远小于计算(7.1)所需的
。
最小度算法(AMD)是本书中介绍的最复杂的代码。下面以cs_amd函数的形式给出AMD的简明版本。它使用的临时空间比AMD略多,但代码更简单。它使用树后序cs_tdfs,而不是AMD自己的后序。它没有像AMD那样的控制参数,也不计算AMD所做的任何统计信息(如 和后续Cholesky分解的浮点运算次数)。它还有一个更简单的稠密节点移除策略。然而,即使有这些简化,cs_amd生成的排序质量与AMD相同,速度也一样快。
构造矩阵C :该函数接受矩阵A作为输入,并返回置换向量p。cs_amd函数作用于对称矩阵,因此会形成三个对称矩阵之一。如果order为0,则返回自然排序p=NULL。如果order为1且矩阵是方阵,则形成C=A+A',这适用于Cholesky分解或对角线有较大条目且非零模式大致对称的矩阵的LU分解(在cs_lu中使用tol<1)。如果order为2,则在从A中移除"稠密"行后形成C=A'*A。这适用于非对称矩阵的LU分解,类似于COLAMD计算的结果。如果order为3,则计算C=A'*A,这最适合用于QR分解或如果 A 没有稠密行的LU分解。"稠密"行是指条目数超过 的行。
对角线条目从 C 中移除(因为cs_amd需要一个没有自环的图),并通过cs_sprealloc在C->i中添加额外的"空间"。C 的内容将在消去过程中被破坏(它保存着 )。形成 C 后,分配输出 p 和大小为 8(n+1) 的工作空间。输入 A 不会被修改。为了简化后续讨论,省略了上标
。
初始化商图:商图G由数组Cp, Ci, w, nv, elen, 和 len, 以及 degree表示,每个数组大小为n+1,除了Ci的大小为nzmax。必须表示四种类型的节点和元素:
-
存活节点 是尚未被选为主元且尚未合并到另一个超节点中的节点 i(或超节点)。在这种情况下,
表示为 Ci Cp\[i ... Cpi+eleni-1],其中 eleni
-
死节点 是从图中移除的节点,已被吸收到节点r = CS_FLIP(Cpi)中,其中CS_FLIP(x)定义为-(x)-2。注意Cpi小于零。节点r本身可能又被吸收到另一个节点中。在这种情况下,Cp形成了一个组装树,与消去树非常相似。不存储i的邻接列表。eleni 设置为 -1 表示节点 i 已死。节点i的大小
-
存活元素 e是存在于图
-
死元素 e是已被吸收到后续元素s = CS_FLIP(Cpe)中的元素。elene为-2,并且we设置为零表示e是死元素。
cs_amd初始化商图 和两组 n 个链表:度链表和哈希桶。度链表 d 是一个双向链表,包含所有近似度为 d 的节点列表。链表 d 的头是headd。节点i在链表中的前驱和后继分别是lasti和nexti。哈希桶共享了部分工作空间;hheadh是第h个哈希桶的头,是一个单向链表。由于一个节点永远不会同时出现在两个链表中,nexti是节点i在链表中的下一个节点,而lasti是节点i的哈希键。度链表用于确定最小度节点,哈希桶用于超节点检测。
初始化度链表 :每个节点都被放入其度链表中。度为零的节点被立即消去。度 dense的节点也被消去并合并到一个占位节点 n 中,作为一个死元素。这些稠密节点将出现在输出置换 p 的最后。
选择最小近似度的节点:cs_amd现在准备好开始消去图。它首先找到一个最小度的节点k,并将其从其度链表中移除。变量nel跟踪已消去的节点数;消去k使此计数增加 = nvk。由于节点不是按0到 n-1 的顺序消去的,这个主元节点 k 并不等同于上面讨论的 k,但用途相同。
垃圾回收 :新元素 需要Ci中的空间。如果
,它将被放置在该数组的末尾,在Cicnz ... cnz +  -1 中(更准确地说,使用的空间会比这少;精确度
是上界,而
是更高的上界)。如果没有足够的空间,则执行垃圾回收以压缩 Ci 数组中的
。
存活节点和元素不需要以任何特定顺序出现在 Ci 中。为了有效地压缩 Ci,该方法依赖于这样一个事实:Ci 0 ... cnz-1 中的所有条目都是非负的,并且将为存活的节点和元素重新定义 Cp。for j 循环将每个存活节点和元素j的第一个条目复制到 Cpj 中,并将CS_FLIP(j)放置在每个存活对象的第一个位置。第二个循环扫描所有 Ci,寻找负条目。当找到负条目时,压缩存活节点或元素 j。垃圾回收很少发生。
构造新元素 :使用(7.1)构造新元素 。如果
,则就地构造。对于所有
,nvi被取反以标记它们为该集合的成员。每个节点 i 都从度链表中移除。所有
的元素都被吸收到元素
中。
查找集合差:现在scan1函数计算所有元素 的集合差
。扫描开始时,w 数组中没有任何条目大于或等于 mark。需要进行测试以确保 mark +
不会导致整数溢出。如果会溢出,则安全地重置 w 并继续算法。mark 的值用作偏移量;在代码中,scan1伪代码中的
被替换为we - mark。
度更新 :第二次遍历 使用(7.2)计算近似度
,剪枝集合
和
,并为
中的所有节点计算哈希函数
。哈希函数将在下一步用于超节点检测。如果发现一个存活元素
满足
,则执行激进元素吸收。元素
是
的子集,因此不需要表示
。此时,为节点 i 计算degreei = d =
(7.2)。
项稍后会在批量消去和超节点检测后添加。如果d 为零,则节点i与元素 k 一起被批量消去;否则,节点 i 保持存活。元素 k 被添加到
中,并且节点i被放置在第 h 个哈希桶中。最后,mark 增加
以确保w中的所有条目都小于 mark。
超节点检测 :超节点检测依赖于为每个节点 i 计算的哈希函数 。如果两个节点具有相同的邻接列表,它们的哈希函数将相同。考虑包含任何
的每个哈希桶。将哈希桶中的第一个节点
与所有其他节点j 进行比较;重复此操作直到哈希桶为空。为了将i 与一组其他节点j进行比较,为
或
中的每个节点或元素 s 设置 ws = mark 。这些列表已在
中剪枝掉了所有死节点和元素。如果 i 和 j 的相邻列表长度相同,并且
或
中的所有 s 都被标记,则 i 和j 相同。在这种情况下,j 被吸收到 i 中并从哈希桶中移除。mark 递增以清除数组 w 用于下一次迭代。
完成新元素:节点 k 的消去已接近完成。最后一次扫描 中的所有节点 i 。如果节点 i 已死(可能在超节点检测期间被吸收),则将其从
中移除。清除 nvi 的标记状态。度
最终确定,节点i被放置在其相应的度链表中。当节点放回度链表时,会找到新的最小度。注意,当前元素的度
,在此最终遍历期间最后添加到每个节点的度中,以完成(7.2)的近似度计算。该项在
中没有添加,因为由于批量消去,它在扫描期间被修改了。最后,更新 nvk 以反映k 代表的节点数(由于批量消去,这可能已增加,因为 k 被选为主元)。如果集合
为空,则元素 k 是组装树的根,并且元素 k 从图中移除。
后序 :消去完成,但尚未计算置换。图中剩下的只有组装树(Cp )和一组死节点和元素(如果nvi 为零,i是死节点;如果nvi > 0 ,i 是死元素)。仅根据这些信息计算最终置换。通过取消所有 Cp 的翻转来恢复树。现在它形成了一棵树;Cpx 是x 的父节点,如果 x 是根则为 -1。这不是消去树,但非常相似。
如果一个元素 e 已被吸收到其父节点 Cpe 中,则e 必须在输出置换 p 中出现在 Cpe 之前。同样,节点i必须出现在其父节点 Cpi 之前。必须在节点和元素之间做出区分。元素的父节点始终是一个元素。节点的父节点可以是另一个节点或元素,但节点永远不能是树的根。元素 e 的子节点必须在 p 中出现在它之前,但所有子元素必须出现在所有子节点之前,因为子节点(及其在组装树中的后代)反映了在 e 被选为主元时被吸收到超节点 e 中的一组节点。
组装树的后序给出了置换 p 。任何节点 x 的子节点列表被分区;子元素首先出现,然后是子节点。死元素 n 是 C 的任何稠密行和列的占位符,因此它也被包含在后序中;它及其后代将在最后排序,然后是 n 本身。因此,p 0 ... n-1 是最终减少填充的置换。这个后序比 AMD 中的后序简单得多,但同样有效。
cpp
int *cs_amd (int order, const cs *A) /* order 0:natural, 1:Chol, 2:LU, 3:QR */
{
cs *C, *A2, *AT ;
int *Cp, *Ci, *last, *W, *len, *nv, *next, *P, *head, *elen, *degree, *w,
*hhead, *ATp, *ATi, d, dk, dext, lemax = 0, e, elenk, eln, i, j, k, kl,
k2, k3, jlast, ln, dense, nzmax, mindeg = 0, nvi, nvj, nvk, mark, nvi,
ok, cnz, nel = 0, p, p1, p2, p3, p4, pj, pk, pkl, pk2, pn, q, n, m, t ;
unsigned int h ;
/* --- Construct matrix C ----------------------------------------------- */
if (!CS_CSC (A) || order <= 0 || order > 3) return (NULL) ; /* check */
AT = cs_transpose (A, 0) ; /* compute A' */
if (!AT) return (NULL) ;
m = A->m ; n = A->n ;
dense = CS_MAX (16, 10 + sqrt ((double) n)) ; /* find dense threshold */
dense = CS_MIN (n-2, dense) ;
if (order == 1 && n == m)
{
C = cs_add (A, AT, 0, 0) ; /* C = A+A' */
}
else if (order == 2)
{
ATp = AT->p ; /* drop dense columns from AT */
ATi = AT->i ;
for (p2 = 0, j = 0 ; j < m ; j++)
{
p = ATp [j] ; /* column j of AT starts here */
ATp [j] = p2 ; /* new column j starts here */
if (ATp [j+1] - p > dense) continue ; /* skip dense col j */
for ( ; p < ATp [j+1] ; p++) ATi [p2++] = ATi [p] ;
}
ATp [m] = p2 ; /* finalize AT */
A2 = cs_transpose (AT, 0) ; /* A2 = AT' */
C = A2 ? cs_multiply (AT, A2) : NULL ; /* C=A'*A with no dense rows */
cs_spfree (A2) ;
}
else
{
C = cs_multiply (AT, A) ; /* C=A'*A */
}
cs_spfree (AT) ;
if (!C) return (NULL) ;
cs_fkeep (C, &cs_diag, NULL) ; /* drop diagonal entries */
Cp = C->p ;
cnz = Cp [n] ;
P = cs_malloc (n+1, sizeof (int)) ; /* allocate result */
W = cs_malloc (8*(n+1), sizeof (int)) ; /* get workspace */
t = cnz + cnz/5 + 2*n ; /* add elbow room to C */
if (!P || !W || !cs_sprealloc (C, t)) return (cs_idone (P, C, W, 0)) ;
len = W ; nv = W + (n+1) ; next = W + 2*(n+1) ;
head = W + 3*(n+1) ; elen = W + 4*(n+1) ; degree = W + 5*(n+1) ;
w = W + 6*(n+1) ; hhead = W + 7*(n+1) ;
last = P ; /* use P as workspace for last */
/* --- Initialize quotient graph ---------------------------------------- */
for (k = 0 ; k < n ; k++) len [k] = Cp [k+1] - Cp [k] ;
len [n] = 0 ;
nzmax = C->nzmax ;
Ci = C->i ;
for (i = 0 ; i <= n ; i++)
{
head [i] = -1 ; /* degree list i is empty */
last [i] = -1 ;
next [i] = -1 ;
hhead [i] = -1 ; /* hash list i is empty */
nv [i] = 1 ; /* node i is just one node */
w [i] = 1 ; /* node i is alive */
elen [i] = 0 ; /* Ek of node i is empty */
degree [i] = len [i] ; /* degree of node i */
}
mark = cs_wclear (0, 0, w, n) ; /* clear w */
elen [n] = -2 ; /* n is a dead element */
Cp [n] = -1 ; /* n is a root of assembly tree */
w [n] = 0 ; /* n is a dead element */
/* --- Initialize degree lists ------------------------------------------ */
for (i = 0 ; i < n ; i++)
{
d = degree [i] ;
if (d == 0) /* node i is empty */
{
elen [i] = -2 ; /* element i is dead */
nel++ ;
Cp [i] = -1 ; /* i is a root of assembly tree */
w [i] = 0 ;
}
else if (d > dense) /* node i is dense */
{
nv [i] = 0 ; /* absorb i into element n */
elen [i] = -1 ;
nel++ ;
Cp [i] = CS_FLIP (n) ;
nv [n]++ ;
}
else
{
if (head [d] != -1) last [head [d]] = i ;
next [i] = head [d] ; /* put node i in degree list d */
head [d] = i ;
}
}
while (nel < n) /* while (selecting pivots) do */
{
/* --- Select node of minimum approximate degree -------------------- */
for (k = -1 ; mindeg < n && (k = head [mindeg]) == -1 ; mindeg++) ;
if (next [k] != -1) last [next [k]] = -1 ;
head [mindeg] = next [k] ; /* remove k from degree list */
elenk = elen [k] ; /* elenk = |Ek| */
nvk = nv [k] ; /* # of nodes k represents */
nel += nvk ; /* nv [k] nodes of A eliminated */
/* --- Garbage collection ------------------------------------------- */
if (elenk > 0 && cnz + mindeg >= nzmax)
{
for (j = 0 ; j < n ; j++)
{
if ((p = Cp [j]) >= 0) /* j is a live node or element */
{
Cp [j] = Ci [p] ; /* save first entry of object */
Ci [p] = CS_FLIP (j) ; /* first entry is now CS_FLIP(j) */
}
}
for (q = 0, p = 0 ; p < cnz ; ) /* scan all of memory */
{
if ((j = CS_FLIP (Ci [p++])) >= 0) /* found object j */
{
Ci [q] = Cp [j] ; /* restore first entry of object */
Cp [j] = q++ ; /* new pointer to object j */
for (k3 = 0 ; k3 < len [j]-1 ; k3++) Ci [q++] = Ci [p++] ;
}
}
cnz = q ; /* Ci [cnz... nzmax-1] now free */
}
/* --- Construct new element ---------------------------------------- */
dk = 0 ;
nv [k] = -nvk ; /* flag k as in Lk */
p = Cp [k] ;
pk1 = (elenk == 0) ? p : cnz ; /* do in place if elen[k] == 0 */
pk2 = pk1 ;
for (k1 = 1 ; k1 <= elenk + 1 ; k1++)
{
if (k1 > elenk)
{
e = k ; /* search the nodes in k */
pj = p ; /* list of nodes starts at Ci[pj]*/
ln = len [k] - elenk ; /* length of list of nodes in k */
}
else
{
e = Ci [p++] ; /* search the nodes in e */
pj = Cp [e] ;
ln = len [e] ; /* length of list of nodes in e */
}
for (k2 = 1 ; k2 <= ln ; k2++)
{
i = Ci [pj++] ;
if ((nvi = nv [i]) <= 0) continue ; /* node i dead, or seen */
dk += nvi ; /* degree[Lk] += size of node i */
nv [i] = -nvi ; /* negate nv[i] to denote i in Lk*/
Ci [pk2++] = i ; /* place i in Lk */
if (next [i] != -1) last [next [i]] = last [i] ;
if (last [i] != -1) /* remove i from degree list */
{
next [last [i]] = next [i] ;
}
else
{
head [degree [i]] = next [i] ;
}
}
if (e != k)
{
Cp [e] = CS_FLIP (k) ; /* absorb e into k */
w [e] = 0 ; /* e is now a dead element */
}
}
if (elenk != 0) cnz = pk2 ; /* Ci [cnz... nzmax] is free */
degree [k] = dk ; /* external degree of k - |Lk\i| */
Cp [k] = pk1 ; /* element k is in Ci[pk1..pk2-1] */
len [k] = pk2 - pk1 ;
elen [k] = -2 ; /* k is now an element */
/* --- Find set differences ----------------------------------------- */
mark = cs_wclear (mark, lemax, w, n) ; /* clear w if necessary */
for (pk = pk1 ; pk < pk2 ; pk++) /* scan 1: find |Le\Lk| */
{
i = Ci [pk] ;
if ((eln = elen [i]) <= 0) continue ; /* skip if elen[i] empty */
nvi = -nv [i] ; /* nv [i] was negated */
wnvi = mark - nvi ;
for (p = Cp [i] ; p <= Cp [i] + eln - 1 ; p++) /* scan Ei */
{
e = Ci [p] ;
if (w [e] >= mark)
{
w [e] -= nvi ; /* decrement |Le\Lk| */
}
else if (w [e] != 0) /* ensure e is a live element */
{
w [e] = degree [e] + wnvi ; /* 1st time e seen in scan 1 */
}
}
}
/* --- Degree update ------------------------------------------------ */
for (pk = pk1 ; pk < pk2 ; pk++) /* scan2: degree update */
{
i = Ci [pk] ; /* consider node i in Lk */
p1 = Cp [i] ;
p2 = p1 + elen [i] - 1 ;
pn = p1 ;
for (h = 0, d = 0, p = p1 ; p <= p2 ; p++) /* scan Ei */
{
e = Ci [p] ;
if (w [e] != 0)
{
dext = w [e] - mark ;
if (dext > 0)
{
d += dext ; /* sum up the set differences */
Ci [pn++] = e ; /* keep e in Ei */
h += e ; /* compute the hash of node i */
}
}
else
{
Cp [e] = CS_FLIP (k) ; /* aggressive absorb: e->k */
w [e] = 0 ; /* e is a dead element */
}
}
elen [i] = pn - p1 + 1 ; /* elen[i] = |Ei| */
p3 = pn ;
p4 = p1 + len [i] ;
for (p = p2 + 1 ; p < p4 ; p++) /* prune edges in Ai */
{
j = Ci [p] ;
if ((nvj = nv [j]) <= 0) continue ; /* node j dead or in Lk */
d += nvj ; /* degree(i) += |j| */
Ci [pn++] = j ; /* place j in node list of i */
h += j ; /* compute hash for node i */
}
if (d == 0) /* check for mass elimination */
{
Cp [i] = CS_FLIP (k) ; /* absorb i into k */
nvi = -nv [i] ;
dk -= nvi ; /* |Lk| -= |i| */
nvk += nvi ; /* |k| += nv[i] */
nel += nvi ;
nv [i] = 0 ;
elen [i] = -1 ; /* node i is dead */
}
else
{
degree [i] = CS_MIN (degree [i], d) ; /* update degree(i) */
Ci [pn] = Ci [p3] ; /* move first node to end */
Ci [p3] = Ci [p1] ; /* move 1st el. to end of Ei */
Ci [p1] = k ; /* add k as 1st element in Ei */
len [i] = pn - p1 + 1 ; /* new len of adj. list of i */
h %= n ; /* finalize hash of i */
next [i] = hhead [h] ; /* place i in hash bucket */
hhead [h] = i ;
last [i] = h ; /* save hash key for i */
}
} /* scan2 is done */
degree [k] = dk ; /* finalize |Lk| */
lemax = CS_MAX (lemax, dk) ;
mark = cs_wclear (mark+lemax, lemax, w, n) ; /* clear w */
/* --- Supernode detection ------------------------------------------ */
for (pk = pk1 ; pk < pk2 ; pk++)
{
i = Ci [pk] ;
if (nv [i] >= 0) continue ; /* skip if i is dead */
h = last [i] ; /* get hash key for i */
i = hhead [h] ; /* start in bucket at head */
hhead [h] = -1 ; /* clear hash bucket */
for ( ; i != -1 && next [i] != -1 ; i = next [i], mark++)
{
ln = len [i] ;
eln = elen [i] ;
for (p = Cp [i]+1 ; p <= Cp [i] + ln-1 ; p++) w [Ci [p]] = mark ;
jlast = i ;
for (j = next [i] ; j != -1 ; j = next [j])
{
ok = (len [j] == ln) && (elen [j] == eln) ;
for (p = Cp [j] + 1 ; ok && p <= Cp [j] + ln - 1 ; p++)
{
if (w [Ci [p]] != mark) ok = 0 ;
}
if (ok)
{
nv [i] += nv [j] ;
nv [j] = 0 ;
elen [j] = -1 ; /* node j is dead */
j = next [j] ; /* delete j from bucket */
next [jlast] = j ;
}
else
{
jlast = j ;
}
}
}
}
/* --- Finalize new element ---------------------------------------- */
for (pk = pk1 ; pk < pk2 ; pk++)
{
i = Ci [pk] ;
if ((nvi = -nv [i]) <= 0) continue ; /* skip if i is dead */
nv [i] = nvi ; /* restore nv[i] */
d = degree [i] + dk ; /* compute final degree(i) */
d = CS_MIN (d, n - nel - nvi) ;
degree [i] = d ;
Ci [p++] = i ; /* place i in Lk */
if (d == 0) /* mass elimination (do later) */
{
/* This can happen if node i is of zero degree and is not pivotal. */
/* It will be absorbed into the pivotal element k. */
Cp [i] = CS_FLIP (k) ;
nv [i] = 0 ;
elen [i] = -1 ;
nel++ ;
}
else
{
/* place i in degree list */
if (head [d] != -1) last [head [d]] = i ;
next [i] = head [d] ;
head [d] = i ;
}
}
len [k] = p - pk1 ;
if (len [k] == 0) /* k is a root of the tree */
{
Cp [k] = -1 ;
w [k] = 0 ;
}
if (elenk != 0) cnz = p ; /* free unused space in Lk */
nv [k] = nvk ; /* # nodes absorbed into k */
}
/* --- Postordering ----------------------------------------------------- */
for (i = 0 ; i < n ; i++) Cp [i] = CS_FLIP (Cp [i]) ; /* fix assembly tree */
for (j = 0 ; j <= n ; j++) head [j] = -1 ;
for (j = n ; j >= 0 ; j--) /* place unordered nodes in lists */
{
if (nv [j] > 0) continue ; /* skip if j is an element */
next [j] = head [Cp [j]] ; /* place j in list of its parent */
head [Cp [j]] = j ;
}
for (e = n ; e >= 0 ; e--) /* place elements in lists */
{
if (nv [e] <= 0) continue ; /* skip unless e is an element */
if (Cp [e] != -1)
{
next [e] = head [Cp [e]] ; /* place e in list of its parent */
head [Cp [e]] = e ;
}
}
for (k = 0, i = 0 ; i <= n ; i++) /* postorder the assembly tree */
{
if (Cp [i] == -1) k = cs_tdfs (i, k, head, next, P, w) ;
}
return (cs_idone (P, C, W, 1)) ;
}cs_wclear 函数在 cs_amd 中用于清除 w 数组。该条件在第一次调用 cs_wclear 时成立,然后在接近整数溢出时成立(在这种情况下,w 被安全重置,算法继续)。cs_diag用于删除对角线条目。
cpp
static int cs_wclear (int mark, int lemax, int *w, int n)
{
int k ;
if (mark < 2 || (mark + lemax < 0))
{
for (k = 0 ; k < n ; k++) if (w [k] != 0) w [k] = 1 ;
mark = 2 ;
}
return (mark) ; /* at this point, w [0..n-1] < mark holds */
}
static int cs_diag (int i, int j, double aij, void *other) { return (i != j) ; }在MATLAB中, 或 p=symamd(A) 计算本质上与 p=cs_amd (A) 相同的排序。由于平局决胜规则的不同,存在细微差异。输入矩阵 C 在 AMD 和 cs_amd 中的计算方式不同;邻接列表是相同的,但两者都不生成排序后的邻接列表
。这影响节点在度列表中替换的顺序,因此可能影响主元顺序。在度列表中,通常有多个具有相同最小度的节点,AMD 和 cs_amd 都简单地选择第一个非空度列表中的第一个节点。
7.2 最大匹配
最大匹配(也称为最大横贯)是任意矩阵 的一个置换,使得其 第
个对角线无零,并且
被唯一地最小化(除非
完全为零)。这个置换决定了矩阵的结构秩,并且是 LU 或 QR 分解或后续章节中描述的块三角形式和 Dulmage -Mendelsohn 分解的先导。通过这个最大匹配,一个矩阵具有结构满秩当且仅当
,否则结构秩亏。这个对角线上的条目数给出了矩阵
的结构秩,它是任何与
具有相同非零模式的矩阵的数值秩的上界。在 MATLAB 中是 sprank(A)。
考虑一个 m×n 矩阵 的二分图
,具有 m 个行节点,n 个列节点,以及无向边
;没有边连接行节点对或列节点对。设
表示列j 中的非零元,或者等价地,在
中与
相邻的行。注意,尽管边是无向的,
和
是不同的边。一个匹配是一组行
和列
,其中每个
的行与唯一的
配对,且
。行
称为匹配行,列
称为匹配列,边
其中
且
称为匹配边。所有其他行、列和边都是未匹配的。该匹配定义了置换子矩阵的零自由对角线(MATLAB 表示法中的 diag(A(r,c)) )。
的最大匹配的大小大于或等于
中任何其他匹配。如果所有行都被匹配,则匹配是行完美的;如果所有列都被匹配,则是列完美 的。一个图可以有多个最大匹配(一个方阵稠密矩阵的图有 n! 个最大匹配)。这个最大匹配的大小就是结构秩。幸运的是,这里介绍的算法和定理可以使用任何最大匹配,并且下面给出的匹配算法保证能找到其中一个。
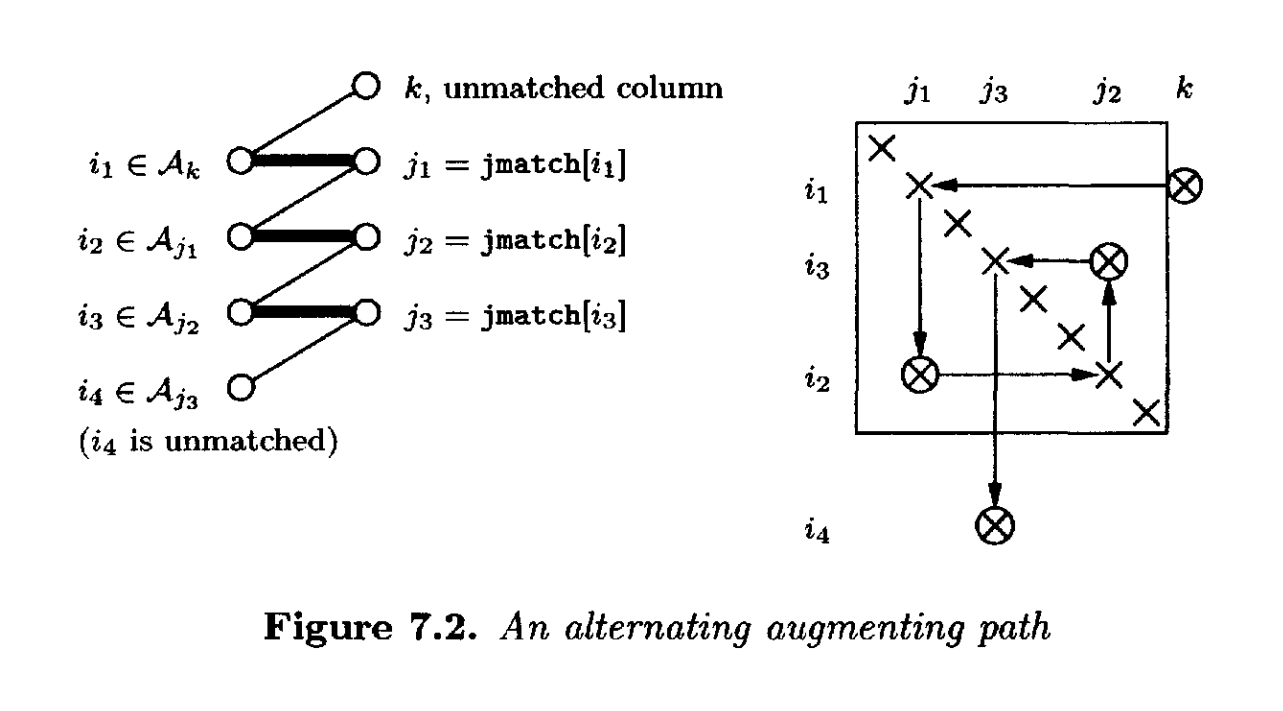
算法从一个空匹配开始。设 jmatchi 等于 j 如果行 匹配到列
,如果行
则为**-1** 。该算法通过一次一列地扩展匹配,每次为一个未匹配的列
寻找一条交替增广路径。该路径从一个未匹配的列 k 开始,然后遍历任意一条边到一个行
。由于 k 未匹配,这条边
不是匹配边。当到达一个未匹配的行时,路径停止。如果
已匹配,则路径遍历匹配边
,其中
,然后遍历一条未匹配边
。路径继续,直到它在一个未匹配的行处停止。该路径是交替的,因为路径中每隔一条边是匹配边。通常路径可以是任意奇数长度,并且没有节点或边在路径中出现两次。一条长度为7的交替增广路径,匹配边以粗体显示,
(7.3)
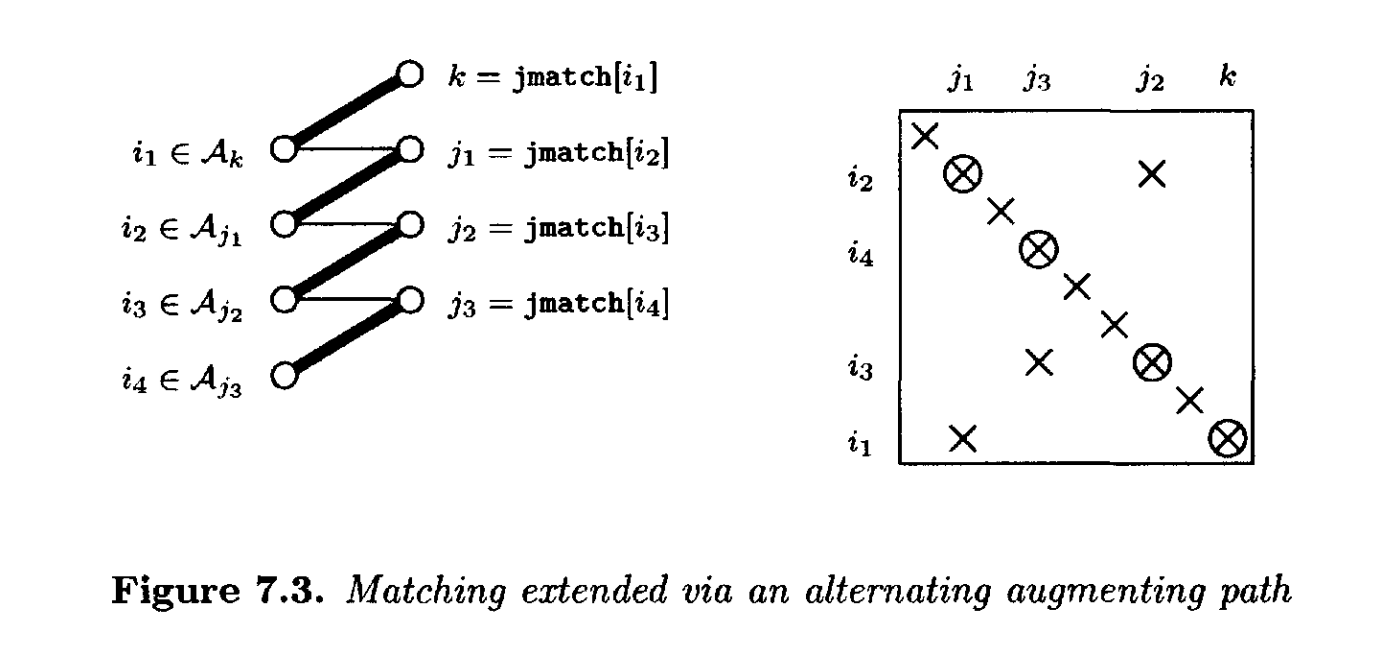
如图7.2所示。该图也给出了同一路径的矩阵视图。图中匹配的边以粗体显示;这些边对应于置换子矩阵的对角线元素(画成一个方框)。在矩阵视图中,对应于未匹配边的条目被圈出。为了扩展匹配(如图7.3所示),将 和
分别添加到
和
中,并改变沿路径的匹配,使得路径变为
(7.4)
也就是说,,
, 依此类推。匹配已经增加了一条额外的边。注意,任何匹配的行或列仍然保持匹配;
和
分别被添加到
和
中,没有节点从
或
中移除。如果未找到未匹配的行
,则不存在这样的路径,并且不扩展匹配(这仅当
结构秩亏时才会发生)。修改后的图和矩阵如图7.3所示。图7.2中圈出的四个条目在图7.3中仍然圈出;行已被置换以将它们放在对角线上,表示当前匹配的方框扩大了一行和一列。三个先前匹配的条目不再在对角线上。当然,可能有其他未匹配的边关联到这些 8 个节点,相应地矩阵中有更多的非对角线条目。为了图更清晰,它们被省略了。
可以通过对 进行深度优先搜索来找到路径(7.3),从一个未匹配的列
开始,仅遍历交替路径。如果每一步都搜索整个图,则找到整个方阵矩阵的最大匹配的时间复杂度为
,但通常只需要遍历
的一小部分就能找到一条交替路径(此时搜索停止)。为了降低找到一条路径的典型成本,在每列j进行一步广度优先搜索,然后再以深度优先方式继续(称为廉价匹配)。一旦一个行
被匹配,它保持匹配状态(尽管它匹配到的列
可能会改变)。广度优先搜索利用了这一事实,将
分成两部分,第一部分只包含匹配的行。当考虑一列
时,考虑
的第二部分中的行,并且扩展这种分割直到找到一个未匹配的行(如果有)。因此,在这种广度优先搜索中,每条边只被考虑一次,为找到整个最大匹配只增加了
的时间,但大大降低了算法的平均情况复杂度。
maxtrans 和 augment 函数不是 的一部分,因为它们依赖于递归深度优先搜索,对于非常大的矩阵可能导致栈溢出。然而,它们比非递归版本更容易理解,所以首先讨论它们。maxtrans 分配工作空间(w 和 cheap )和结果 jmatch 。最初,所有行都未匹配。wj 用于在深度优先搜索期间标记列节点 j;如果在算法的第 k 步中访问了列 j ,则wj=k ,否则 wj<k 。一步广度优先搜索的
分割由 cheapj 给出;AiAp\[j ... cheapj-1] 已知只包含匹配的行,而 Aicheap\[j ... Apj+1-1] 可能同时包含匹配和未匹配的行。
这些初始化之后,单行 for k 循环计算匹配。它搜索从列 k 开始的交替增广路径,如果找到这条路径,则扩展匹配。在第 k 次迭代开始时, 是
的子集,并且可以通过添加列
来扩展。当算法完成时,如果行 i 匹配到列 j ,则j=jmatchi ≥ 0 。如果行i 未匹配,则jmatchi = -1。
递归函数 augment 由 maxtrans 调用,从节点j = k 开始(当 augment 递归调用自身时,j 会被修改,但 k 保持不变)。当在节点 j 时,它首先尝试找到一个廉价匹配(第一个 for循环 )。cheapj 被修改为指向 的剩余部分。如果没有找到廉价匹配,则所有边
都以深度优先方式被考虑。所有这些行 i 必须已经匹配;否则,早就找到了廉价匹配,并且会跳过这个循环。如果在第 k 步中尚未考虑列jmatchi ,则进行递归调用以找到从列jmatchi 开始的增广路径(例如,对应于图7.2中的列
)。如果找到路径,则终止循环,并通过将这一新行 i 匹配到列j来修改匹配。
cpp
int *maxtrans (cs *A) /* returns jmatch [0..m-1] */
{
int i, j, k, n, m, *Ap, *jmatch, *w, *cheap ;
if (!A) return (NULL) ;
n = A->n ; m = A->m ; Ap = A->p ;
jmatch = cs_malloc (m, sizeof (int)) ; /* allocate result */
w = cs_malloc (2*n, sizeof (int)) ; /* allocate workspace */
if (!w || !jmatch) return (cs_idone (jmatch, NULL, w, 0)) ;
cheap = w + n ;
for (j = 0 ; j < n ; j++) cheap [j] = Ap [j] ; /* for cheap assignment */
for (j = 0 ; j < n ; j++) w [j] = -1 ; /* all columns unflagged */
for (i = 0 ; i < m ; i++) jmatch [i] = -1 ; /* no rows matched yet */
for (k = 0 ; k < n ; k++)
{
augment (k, A, jmatch, cheap, w, k) ;
}
return (cs_idone (jmatch, NULL, w, 1)) ;
}
int augment (int k, cs *A, int *jmatch, int *cheap, int *w, int j)
{
int found = 0, p, i = -1, *Ap = A->p, *Ai = A->i ;
/* --- Start depth-first-search at node j ------------------------------- */
w [j] = k ; /* mark j as visited for kth path */
for (p = cheap [j] ; p < Ap [j+1] && !found ; p++)
{
i = Ai [p] ;
found = (jmatch [i] == -1) ; /* try a cheap assignment (i,j) */
}
cheap [j] = p ; /* start here next time for j */
/* --- Depth-first-search of neighbors of j ----------------------------- */
for (p = Ap [j] ; p < Ap [j+1] && !found ; p++)
{
i = Ai [p] ; /* consider row i */
if (w [jmatch [i]] == k) continue ; /* skip col jmatch [i] if marked */
found = augment (k, A, jmatch, cheap, w, jmatch [i]) ;
}
if (found) jmatch [i] = j ;
return (found) ;
}正如第3.2节中描述的递归深度优先搜索算法 dfsr 一样,使用递归限制了 augment 只能解决规模适中的问题。下面的非递归 CS_maxtrans 本质上与 maxtrans 相同;它只是分配更多的工作空间并调用非递归的 cs_augment 。额外的工作空间是一个栈,用于保存递归 augment 中变量 j 、i 和 p 的中间值。对于行多于列的矩阵 ,该算法比 maxtrans更高效(在这种情况下它转置矩阵)。如果对角线已经是零自由的,它也很快返回。
cs_augment 函数执行与augment (k, ..., k) 相同的操作。首先,节点j 被放置在栈js 上。while 循环持续直到栈为空或找到增广路径中的最后一个节点。
cpp
int *cs_maxtrans (const cs *A, int seed) /* [jmatch [0..m-1]; imatch [0..n-1]] */
{
int i, j, k, n, m, p, n2 = 0, m2 = 0, *Ap, *jimatch, *w, *cheap, *js, *is,
*ps, *Ai, *Cp, *jmatch, *imatch, *q ;
cs *C ;
if (!CS_CSC (A)) return (NULL) ; /* check inputs */
n = A->n ; m = A->m ; Ap = A->p ; Ai = A->i ;
w = jimatch = cs_calloc (m+n, sizeof (int)) ; /* allocate result */
if (!jimatch) return (NULL) ;
for (k = 0, j = 0 ; j < n ; j++) /* count nonempty rows and columns */
{
n2 += (Ap [j] < Ap [j+1]) ;
for (p = Ap [j] ; p < Ap [j+1] ; p++)
{
w [Ai [p]] = 1 ;
k += (j == Ai [p]) ; /* count entries already on diagonal */
}
}
if (k == CS_MIN (m,n)) /* quick return if diagonal zero-free */
{
jmatch = jimatch ; imatch = jimatch + m ;
for (i = 0 ; i < k ; i++) jmatch [i] = i ;
for ( ; i < m ; i++) jmatch [i] = -1 ;
for (j = 0 ; j < k ; j++) imatch [j] = j ;
for ( ; j < n ; j++) imatch [j] = -1 ;
return (cs_idone (jimatch, NULL, NULL, 1)) ;
}
for (i = 0 ; i < m ; i++) m2 += w [i] ;
C = (m2 < n2) ? cs_transpose (A,0) : ((cs *) A) ; /* transpose if needed */
if (!C) return (cs_idone (jimatch, (m2 < n2) ? C : NULL, NULL, 0)) ;
n = C->n ; m = C->m ; Cp = C->p ;
jmatch = (m2 < n2) ? jimatch + n : jimatch ;
imatch = (m2 < n2) ? jimatch : jimatch + m ;
w = cs_malloc (5*n, sizeof (int)) ; /* get workspace */
if (!w) return (cs_idone (jimatch, (m2 < n2) ? C : NULL, w, 0)) ;
cheap = w + n ; js = w + 2*n ; is = w + 3*n ; ps = w + 4*n ;
for (j = 0 ; j < n ; j++) cheap [j] = Cp [j] ; /* for cheap assignment */
for (j = 0 ; j < n ; j++) w [j] = -1 ; /* all columns unflagged */
for (i = 0 ; i < m ; i++) jmatch [i] = -1 ; /* nothing matched yet */
q = cs_randperm (n, seed) ; /* q = random permutation */
for (k = 0 ; k < n ; k++) /* augment, starting at column q[k] */
{
cs_augment (q ? q [k] : k, C, jmatch, cheap, w, js, is, ps) ;
}
cs_free (q) ;
for (j = 0 ; j < n ; j++) imatch [j] = -1 ; /* find row match */
for (i = 0 ; i < m ; i++) if (jmatch [i] >= 0) imatch [jmatch [i]] = i ;
return (cs_idone (jimatch, (m2 < n2) ? C : NULL, w, 1)) ;
}
static void cs_augment (int k, const cs *A, int *jmatch, int *cheap, int *w,
int *js, int *is, int *ps)
{
int found = 0, p, i = -1, *Ap = A->p, *Ai = A->i, head = 0, j ;
js [0] = k ; /* start with just node k in jstack */
while (head >= 0)
{
/* --- Start (or continue) depth-first-search at node j ------------- */
j = js [head] ; /* get j from top of jstack */
if (w [j] != k) /* 1st time j visited for kth path */
{
w [j] = k ; /* mark j as visited for kth path */
for (p = cheap [j] ; p < Ap [j+1] && !found ; p++)
{
i = Ai [p] ; /* try a cheap assignment (i,j) */
found = (jmatch [i] == -1) ;
}
cheap [j] = p ; /* start here next time j is traversed*/
if (found)
{
is [head] = i ; /* column j matched with row i */
break ; /* end of augmenting path */
}
ps [head] = Ap [j] ; /* no cheap match: start dfs for j */
}
/* --- Depth-first-search of neighbors of j ------------------------- */
for (p = ps [head] ; p < Ap [j+1] ; p++)
{
i = Ai [p] ; /* consider row i */
if (w [jmatch [i]] == k) continue ; /* skip jmatch [i] if marked */
ps [head] = p + 1 ; /* pause dfs of node j */
is [head] = i ; /* i will be matched with j if found */
js [++head] = jmatch [i] ; /* start dfs at column jmatch [i] */
break ;
}
if (p == Ap [j+1]) head-- ; /* node j is done; pop from stack */
}
if (found) for (p = head ; p >= 0 ; p--) jmatch [is [p]] = js [p] ; /* augment the match if path found */
}在节点j开始(或继续)深度优先搜索:在 cs_augment 的 while循环 的每次迭代中,考虑栈顶的节点j。如果这是第一次考虑 j,则 wj 将不等于 k;这对应于 augment (k, ..., j) 调用的开始。因此,接下来的七行代码(从 wj=k 到 cheapj=p )与 augment 中的相同七行代码相同。如果找到了廉价匹配,则记录在栈is 中,并且"递归"将开始解开( while 循环终止)。否则,用于深度优先部分的Aj中的起始位置 p=Apj 保存在 ps 中,对应于 augment 中 for (p=Apj ... )循环的初始化。
节点j的邻居的深度优先搜索 :for (p=ps head ... ) 循环开始(或继续)augment 中相应的 for (p=Apj ... ) 循环。如果找到一个未标记的列 jmatchi,则节点j的迭代暂停,新的列 jmatchi 现在位于栈顶。break 语句终止 for 循环,以便最外层的 while 循环可以考虑栈顶的这个节点 jmatchi 。如果for 循环 在搜索了所有行 后终止,则(尚未)找到匹配,并且通过递减 head 将j从栈中弹出。最后,如果找到一条增广路径,则通过修改这条路径中所有未匹配 边(i, j) 的匹配来解开"递归",对应于 augment 中的 jmatchi=j 语句。
如果找到列完美匹配,则 imatch0 ... n-1 是 A 的列的子集(如果 A 是方阵,则是所有列)的一个置换,并且 A(imatch, :) 具有零自由对角线。MATLAB 语句 p=dmperm(A) 是相同的(即,p 是 imatch)。
cs_maxtrans 的最坏情况时间复杂度为 ,但这在实践中很少发生。cs_maxtrans 可以按逆序(从 n-1 到 0 )或随机顺序匹配 A 的列,这有助于避免这种最坏情况行为。cs_randperm 计算 cs_maxtrans 使用的随机置换。如果 seed 为零,则返回恒等置换(p=NULL)。如果 seed 为 -1,则返回逆序置换(MATLAB表示法中的 p=n-1: -1: 0)。否则,返回一个随机置换。
cpp
int *cs_randperm (int n, int seed)
{
int *p, k, j, t ;
if (seed == 0) return (NULL) ; /* return p = NULL (identity) */
p = cs_malloc (n, sizeof (int)) ; /* allocate result */
if (!p) return (NULL) ; /* out of memory */
for (k = 0 ; k < n ; k++) p [k] = n-k-1 ;
if (seed == -1) return (p) ; /* return reverse permutation */
srand (seed) ; /* get new random number seed */
for (k = 0 ; k < n ; k++)
{
j = k + (rand ( ) % (n-k)) ; /* j = rand int in range k to n-1 */
t = p [j] ;
p [j] = p [k] ;
p [k] = t ;
}
return (p) ;
}7.3 块三角形式
块三角形式及其推广 Dulmage-Mendelsohn 分解(在下一节中描述)是许多稀疏矩阵算法和理论的有用工具。它是矩阵A的一个置换,减少了 和
分解所需的工作量,并提供了结构秩亏矩阵的精确表征。
一个 m×n 矩阵具有 强 Hall 性质,如果对于所有
在 1 到
范围内,每组
列至少具有
行中的非零元。如果A是方阵且具有结构满秩但不是 强 Hall,它可以被置换为块三角形式,
(7.5)
其中每个对角块是方阵,具有零自由对角线,并且具有 强Hall 性质。强Hall 性质意味着满结构秩。块三角形式(7.5)是唯一的,除了有时块可以互换。块内的排序通常有选择余地(对角线必须保持零自由)。用 LU 分解求解 ,只需要分解对角块,然后对非对角块进行块回代求解。非对角块中不会出现填充。由于每个对角块都是强Hall的,第5章和第6章中的定理对因子的非零模式提供了更严格的界限。
一个强Hall矩阵的逆没有零条目(忽略数值对消),因此在实践中很少计算。
将具有零自由对角线的方阵置换为块三角形式等同于找到有向图 的强连通分量。有向图定义为
,其中
且
。也就是说,
的非零模式是有向图
的邻接矩阵。一个强连通分量是一个最大的节点集,使得对于该分量中的任意一对节点
和
,图中同时存在路径
和
。
图的强连通分量可以通过多种方式找到。最简单的方法是使用两次深度优先遍历,一次在 上,第二次在图
上。这在
中很简单,因为 cs_dfs 已经可以执行这种深度优先遍历。它是在有向无环图(
的图)的背景下介绍的,用于在第3.2节中找到稀疏三角求解的非零模式
,但 cs_dfs 的设计并不限于无环图。一般来说,
的图可以有环,这与
的图不同。
第一次深度优先搜索返回一个包含图中所有节点的集合 。作为一个集合,这不是很有趣。然而,节点出现在
中的顺序非常重要。节点
被放置在栈
中,其对应的
完成的顺序。第二次对
进行深度优先遍历,其中节点按照其完成时间的逆序(从栈
的顶部到底部)考虑,确定了强连通分量。在第二次遍历中,每次新的深度优先搜索找到的每个新节点
,以及从它在
中可到达的所有节点,定义了
的一个唯一强连通分量,记作
。下面给出了该算法及其实现(cs_scc )。分量实际上是按逆序计算的;这个细节在下面的
函数中没有包含。关于为什么它有效的更多细节,请参见第7.7节。
由于 以压缩列形式存储,
是图
中节点j的邻接列表。然而,
算法将找到一个置换,将图的邻接矩阵变为块下三角形式。对于稀疏矩阵计算,块上三角形式更常见,因此cs_scc 可以应用于转置。这两个转置相互抵消,所以 cs_scc 算法与伪代码
相同。它找到一个置换向量p ,使得
是块上三角形式(7.5),以及一个数组 r ,它决定了 C 中块的位置;第 k 个块在 MATLAB 表示法中是 C(k1:k2, k1:k2) ,其中 k1=rk 且 k2=rk+1-1。
function scc(A)
X = Reach_A({1...n})
b=0
for each node i ∈ X (in reverse order of X)
if i is unmarked
b=b+1
C_b = dfs(i) of the graph G(A^T)
cpp
csd *cs_scc (cs *A) /* matrix A temporarily modified, then restored */
{
int n, i, k, b, nb = 0, top, *xi, *pstack, *p, *r, *Ap, *ATp, *rcopy, *Blk ;
cs *AT ;
csd *D ;
if (!CS_CSC (A)) return (NULL) ; /* check inputs */
n = A->n ; Ap = A->p ;
D = cs_dalloc (n, 0) ; /* allocate result */
AT = cs_transpose (A, 0) ; /* AT = A' */
xi = cs_malloc (2*n+1, sizeof (int)) ; /* get workspace */
if (!D || !AT || !xi) return (cs_ddone (D, AT, xi, 0)) ;
Blk = xi ; rcopy = pstack = xi + n ;
p = D->p ; r = D->r ; ATp = AT->p ;
top = n ;
for (i = 0 ; i < n ; i++) /* first dfs(A) to find finish times (xi) */
{
if (!CS_MARKED (Ap, i)) top = cs_dfs (i, A, top, xi, pstack, NULL) ;
}
for (i = 0 ; i < n ; i++) CS_MARK (Ap, i) ; /* restore A; unmark all nodes */
top = n ;
nb = n ;
for (k = 0 ; k < n ; k++) /* dfs(A') to find strongly connected comp */
{
i = xi [k] ; /* get i in reverse order of finish times */
if (CS_MARKED (ATp, i)) continue ; /* skip node i if already ordered */
r [nb--] = top ; /* node i is the start of a component in p */
top = cs_dfs (i, AT, top, p, pstack, NULL) ;
}
r [nb] = 0 ;
for (k = nb ; k <= n ; k++) /* first block starts at zero; shift r up */
{
r [k-nb] = r [k] ;
}
D->nb = nb = n-nb ; /* nb = # of strongly connected components */
for (b = 0 ; b < nb ; b++) /* sort each block in natural order */
{
for (k = r [b] ; k < r [b+1] ; k++) Blk [p [k]] = b ;
}
for (b = 0 ; b <= nb ; b++) rcopy [b] = r [b] ;
for (i = 0 ; i < n ; i++) p [rcopy [Blk [i]]++] = i ;
return (cs_ddone (D, AT, xi, 1)) ;
}cs_scc 函数的最后一部分在线性时间()内对置换向量 p 进行排序,使得每个块中的行和列按其自然顺序出现。这不是必需的,但很有用,因为如果提供自然顺序的矩阵(如果矩阵由单个强连通分量组成,则
),后续的减少填充排序算法往往能给出稍好的结果,并且cs_dmspy 在
中看起来更美观。
cs_dalloc 、cs_dfree 和cs_ddone 函数分配、释放并返回一个 csd 对象,该对象表示 cs_scc找到的强连通分量。
cpp
typedef struct cs_dmperm_results
{
int *p ; /* size m, row permutation */
int *q ; /* size n, column permutation */
int *r ; /* size nb+1, block k is rows r[k] to r[k+1]-1 in A(p,q) */
int *s ; /* size nb+1, block k is cols s[k] to s[k+1]-1 in A(p,q) */
int nb ; /* # of blocks in fine dmperm decomposition */
int rr [5] ; /* coarse row decomposition */
int cc [5] ; /* coarse column decomposition */
} csd ;
csd *cs_dalloc (int m, int n)
{
csd *D ;
D = cs_calloc (1, sizeof (csd)) ;
if (!D) return (NULL) ;
D->p = cs_malloc (m, sizeof (int)) ;
D->r = cs_malloc (m+6, sizeof (int)) ;
D->q = cs_malloc (n, sizeof (int)) ;
D->s = cs_malloc (n+6, sizeof (int)) ;
return ((!D->p || !D->r || !D->q || !D->s) ? cs_dfree (D) : D) ;
}
csd *cs_dfree (csd *D)
{
if (!D) return (NULL) ; /* do nothing if D already NULL */
cs_free (D->p) ;
cs_free (D->q) ;
cs_free (D->r) ;
cs_free (D->s) ;
return (cs_free (D)) ;
}
csd *cs_ddone (csd *D, cs *C, void *w, int ok)
{
cs_spfree (C) ; /* free temporary matrix */
cs_free (w) ; /* free workspace */
return (ok ? D : cs_dfree (D)) ; /* return result if OK, else free it */
}在 MATLAB 中,将**P, q, r, s = dmperm (A)** 应用于具有零自由对角线的方阵A将返回相同的块三角形式A(p, p) (其中 p=q 且r=s ),但受该形式的非唯一性影响,如上所述。
7.4 Dulmage-Mendelsohn分解
Dulmage -Mendelsohn分解是(7.5)的推广。假设已经找到了 A 的最大匹配( A 不需要是方阵)。设 R 为匹配行的集合,C 为匹配列的集合。这个匹配将 A 的行和列划分为四个不相交的子集:
-
-
-
-
-
-
-
-
注意, 中的所有行都是匹配的;如果不是,则可以找到一条交替增广路径,扩展最大匹配(这是矛盾的)。同样,
中的所有列都是匹配的。还要注意,如果
和
有一个共同的列,则会有一条从
到
通过该列的交替增广路径。类似地,
和
是不相交的。
中的所有行都匹配到
中的某些行。因此,
被划分为三个不相交的子集
、
和
,列被划分为三个不相交的子集
、
和
。给定这种行列的四方划分,任何矩阵
都可以被置换为4×4块矩阵
(7.6)
其中 、
和
是具有零自由对角线的方阵。矩阵的转置
(7.7)
和矩阵
(7.8)
都是矩形且具有强Hall性质。矩阵(7.7)具有完美的行匹配,而矩阵(7.8)具有完美的列匹配。如果 为空,则矩阵
具有列完美匹配,并且
和
将为空。同样,如果
为空,则矩阵
具有行完美匹配,并且
和
将为空。因此,两个矩阵(7.7)和(7.8)可能为空(没有行和列)。如果它们存在,(7.7)将比行有更多的列,对应于系统
的结构欠定部分,而(7.8)将比列有更多的行,对应于系统
的结构超定部分。矩阵
不一定具有强Hall性质。如果没有,它可以被置换为块上三角形式,如第7.3节所述。它具有满结构秩,因为它是具有零自由对角线的方阵。因此,对于任何矩阵
,LU或QR分解可以应用于子矩阵,所有这些子矩阵都具有强Hall性质。
(7.6)中给出的 的置换和划分是唯一的,除了不同的最大匹配可以交换
和
之间的列,并交换
和
之间的行(但不能任意;
仍然必须能够匹配到集合
)。除此之外,八个集合及其大小是唯一的。这八个集合内的行或列顺序通常不是唯一的。
cs_dmperm 函数计算 Dulmage -Mendelsohn 分解。它返回一个 csd 对象,包含行和列置换向量 p 和 q 。这些置换向量的四个子集由 cc 和 rr给出;这决定了粗分解,如(7.6)所示。八个集合由下式给出:
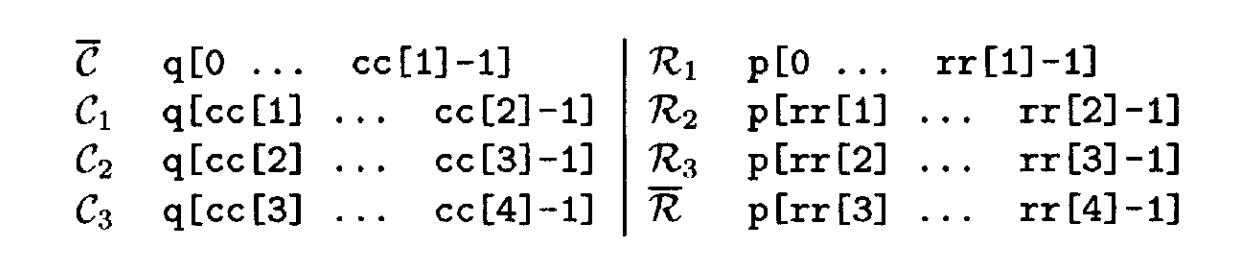
精细分解包括将 子矩阵置换为其强连通分量,如(7.5)所示。它由 r 和 s 给出。如果 C = A(p, q) ,则第k 个块由C 的行 rk 到 rk+1-1 和列 sk 到 sk+1-1 组成。第一个块是矩形矩阵(7.7),最后一个块是(7.8)(如果它们不是0×0)。中间的块是A23的强连通分量。注意,(7.7)可以有列但没有行(
是0-by-cc1,
是 0-by-0)。类似地,(7.8)可以有行但没有列。
最大匹配 :cs_dmperm 找到最大匹配 jmatchi = j 及其逆 imatch j = i。
粗分解 :从未匹配列 开始的广度优先搜索找到
和
R₁。使用矩阵
,从
中的行开始的另一个广度优先搜索确定
和
。在代码中,
和
分别是 C0 和 R0。此时,粗分解仅由标志数组 wi 和 wj 以及匹配 jmatch 和 imatch 确定。扫描这些数组以找到置换 p 和 q 以及粗集大小 cc 和 rr。
精细分解 :找到A(R2, C2) 子矩阵的强连通分量。A(R2, C2) 矩阵首先通过计算 C=A(p,q) 然后移除所有不在集合 R2 或 C2 中的行和列来形成。cs_fkeep 函数用于丢弃不在 R2 中的条目,然后从所有行索引中减去 R1 的大小。可以不显式形成 C=A(R2, C2) 而找到强连通分量,但这种方法使 cs_scc函数更简单。
组合分解 :将精细和粗分解组合到确定块边界的 r 和 s 向量中。来自粗分解的置换向量 p 和 q 与揭示 A(R2, C2) 强连通分量的置换scc->p 组合。
cpp
csd *cs_dmperm (const cs *A, int seed)
{
int m, n, i, j, k, cnz, nc, *jmatch, *imatch, *wi, *wj, *pinv, *Cp, *Ci,
*ps, *rs, nb1, nb2, *p, *q, *cc, *rr, *r, *s, ok ;
cs *C ;
csd *D, *scc ;
/* --- Maximum matching ------------------------------------------------- */
if (!CS_CSC (A)) return (NULL) ; /* check inputs */
m = A->m ; n = A->n ;
D = cs_dalloc (m, n) ;
if (!D) return (NULL) ;
p = D->p ; q = D->q ; r = D->r ; s = D->s ; cc = D->cc ; rr = D->rr ;
jmatch = cs_maxtrans (A, seed) ; /* max transversal */
imatch = jmatch + m ; /* imatch = inverse of jmatch */
if (!jmatch) return (cs_ddone (D, NULL, jmatch, 0)) ;
/* --- Coarse decomposition --------------------------------------------- */
wi = r ; wj = s ; /* use r and s as workspace */
for (j = 0 ; j < n ; j++) wj [j] = -1 ; /* unmark all cols for bfs */
for (i = 0 ; i < m ; i++) wi [i] = -1 ; /* unmark all rows for bfs */
cs_bfs (A, n, wi, wj, q, imatch, jmatch, 1) ; /* find C1, R1 from C0*/
ok = cs_bfs (A, m, wj, wi, p, jmatch, imatch, 3) ; /* find R3, C3 from R0*/
if (!ok) return (cs_ddone (D, NULL, jmatch, 0)) ;
cs_unmatched (n, wj, q, cc, 0) ; /* unmatched set */
cs_matched (n, wj, imatch, p, q, cc, rr, 1, 1) ; /* set R1 and C1 */
cs_matched (n, wj, imatch, p, q, cc, rr, 2, -1) ; /* set R2 and C2 */
cs_matched (n, wj, imatch, p, q, cc, rr, 3, 3) ; /* set R3 and C3 */
cs_unmatched (m, wi, p, rr, 3) ; /* unmatched set */
cs_free (jmatch) ;
/* --- Fine decomposition ----------------------------------------------- */
pinv = cs_pinv (p, m) ; /* pinv=p' */
if (!pinv) return (cs_ddone (D, NULL, NULL, 0)) ;
C = cs_permute (A, pinv, q, 0) ; /* C=A(p,q) (it will hold A(R2,C2)) */
cs_free (pinv) ;
if (!C) return (cs_ddone (D, NULL, NULL, 0)) ;
Cp = C->p ;
nc = cc [3] - cc [2] ; /* delete cols C0, C1, and C3 from C */
if (cc [2] > 0) for (j = cc [2] ; j <= cc [3] ; j++) Cp [j-cc[2]] = Cp [j] ;
C->n = nc ;
if (rr [2] - rr [1] < m)
{
cs_fkeep (C, cs_rprune, rr) ; /* delete rows R0, R1, and R3 from C */
cnz = Cp [nc] ;
Ci = C->i ;
if (rr [1] > 0) for (k = 0 ; k < cnz ; k++) Ci [k] -= rr [1] ;
}
C->m = nc ;
scc = cs_scc (C) ; /* find strongly connected components of C*/
if (!scc) return (cs_ddone (D, C, NULL, 0)) ;
/* --- Combine coarse and fine decompositions --------------------------- */
ps = scc->p ; /* C(ps,ps) is the permuted matrix */
rs = scc->r ; /* kth block is rs[k]..rs[k+1]-1 */
nb1 = scc->nb ; /* # of blocks of A(R2,C2) */
for (k = 0 ; k < nc ; k++) wj [k] = q [ps [k] + cc [2]] ;
for (k = 0 ; k < nc ; k++) q [k + cc [2]] = wj [k] ;
for (k = 0 ; k < nc ; k++) wi [k] = p [ps [k] + rr [1]] ;
for (k = 0 ; k < nc ; k++) p [k + rr [1]] = wi [k] ;
nb2 = 0 ;
r [0] = s [0] = 0 ;
if (cc [2] > 0) nb2++ ; /* leading coarse block A (R1, [C0 C1]) */
for (k = 0 ; k < nb1 ; k++) /* coarse block A (R2,C2) */
{
r [nb2] = rs [k] + rr [1] ; /* A (R2,C2) splits into nb1 fine blocks */
s [nb2] = rs [k] + cc [2] ;
nb2++ ;
}
if (rr [2] < m)
{
r [nb2] = rr [2] ; /* trailing coarse block A ([R3 R0], C3) */
s [nb2] = cc [3] ;
nb2++ ;
}
r [nb2] = m ;
s [nb2] = n ;
D->nb = nb2 ;
cs_dfree (scc) ;
return (cs_ddone (D, C, NULL, 1)) ;
}广度优先搜索由下面的 cs_bfs函数执行。
cpp
static int cs_bfs (const cs *A, int n, int *wi, int *wj, int *queue,
const int *imatch, const int *jmatch, int mark)
{
int *Ap, *Ai, head = 0, tail = 0, j, i, p, j2 ;
cs *C ;
for (j = 0 ; j < n ; j++) /* place all unmatched nodes in queue */
{
if (imatch [j] >= 0) continue ; /* skip j if matched */
wj [j] = 0 ; /* j in set C0 (R0 if transpose) */
queue [tail++] = j ; /* place unmatched col j in queue */
}
if (tail == 0) return (1) ; /* quick return if no unmatched nodes */
C = (mark == 1) ? ((cs *) A) : cs_transpose (A, 0) ; /* bfs of C=A' to find R3,C3 from R0 */
if (!C) return (0) ;
Ap = C->p ; Ai = C->i ;
while (head < tail) /* while queue is not empty */
{
j = queue [head++] ; /* get the head of the queue */
for (p = Ap [j] ; p < Ap [j+1] ; p++)
{
i = Ai [p] ;
if (wi [i] >= 0) continue ; /* skip if i is marked */
wi [i] = mark ; /* i in set R1 (C3 if transpose) */
j2 = jmatch [i] ; /* traverse alternating path to j2 */
if (wj [j2] >= 0) continue ; /* skip j2 if it is marked */
wj [j2] = mark ; /* j2 in set C1 (R3 if transpose) */
queue [tail++] = j2 ; /* add j2 to queue */
}
}
if (mark != 1) cs_spfree (C) ; /* free A' if it was created */
return (1) ;
}为了找到 和
,cs_bfs 从未匹配的列节点
开始,并根据 cs_maxtrans 找到的最大匹配遍历交替路径。
和
集合中节点的顺序不重要,因此可以使用更简单的广度优先搜索而不是更复杂的深度优先搜索。为了找到
和
,它从
中未匹配的行节点开始,并搜索
的图的转置。queue 数组是广度优先搜索队列的工作空间。cs_dmperm 将 p 和 q 传递给 cs_bfs,用作广度优先搜索队列的工作空间。
cs_matched 构造对应于匹配子矩阵( A (R1 R2 R3, C1 C2 C3) )的输出置换部分。
cpp
static void cs_matched (int n, const int *wj, const int *imatch, int *p, int *q,
int *cc, int *rr, int set, int mark)
{
int kc = cc [set], j ;
int kr = rr [set-1] ;
for (j = 0 ; j < n ; j++)
{
if (wj [j] != mark) continue ; /* skip if is not in C set */
p [kr++] = imatch [j] ;
q [kc++] = j ;
}
cc [set+1] = kc ;
rr [set] = kr ;
}cs_unmatched 构造 R0 和 C0 集合。cs_rprune 函数与 cs_fkeep 一起使用,以移除所有不在 R2集合中的行。
cpp
static void cs_unmatched (int m, const int *wi, int *p, int *rr, int set)
{
int i, kr = rr [set] ;
for (i = 0 ; i < m ; i++) if (wi [i] == 0) p [kr++] = i ;
rr [set+1] = kr ;
}
static int cs_rprune (int i, int j, double aij, void *other)
{
int *rr = (int *) other ;
return (i >= rr [1] && i < rr [2]) ;
}在MATLAB中,相应的分解是 p, q, r, s = dmperm (A) 。dmperm 的四个输出与 cs_dmperm 的相同输出相同。MATLAB 7.2中的 dmperm 函数不返回粗分解。由 cs_dmperm 置换的矩阵 A( R1 R2 R3, C1 C2 C3) 具有最大尺寸的零自由对角线。这与 dmperm 几乎相同,除了 dmperm 将 C0 和 C1 集合混杂在一起返回,没有特定顺序,R3 和 R0 集合也是如此。cs_dmperm 函数通过返回最大匹配作为方阵 A( R1 R2 R3, C1 C2 C3) 的对角线,更清晰地区分了这些集合。此外,MATLAB 中的 dmperm 不显式返回粗分解(cc和rr)。cs_dmperm 按自然顺序返回每个块的列,而 dmperm不这样做。这两个函数可能找不到相同的匹配,因为任何最大匹配都是有效的。两个函数都返回有效的 Dulmage-Mendelsohn 分解。
7.5 带宽和轮廓缩减
轮廓(也称为包络)是对称矩阵的一个度量,衡量其条目离对角线的接近程度。假设A的对角线非零,则A的轮廓是 。矩阵的带宽类似,为
。减少矩阵轮廓或带宽的置换可以为
的LU 或 Cholesky 分解提供一个良好的排序。最小化轮廓或带宽是 NP难题,因此使用启发式方法。
反向 Cuthill-McKee 算法是最简单的启发式方法之一。它从一个给定的节点开始,并首先对其进行排序。接下来,任何已排序节点的所有未编号邻居按递增度排序。这产生了 Cuthill-McKee排序 ;通过反转此排序可以进一步减少轮廓(反转不会增加轮廓)。找到一个好的起始节点对于获得良好排序至关重要。该方法从一个伪周边节点开始,通过重复广度优先搜索找到。选择一个任意的起始节点,广度优先搜索确定离该起始节点最远的节点。从这个最远节点开始重复广度优先搜索,重复此过程直到距离不再增加。伪周边节点是最后找到的节点,并成为反向 Cuthill-McKee 算法 的起始节点。MATLAB 中用于反向 Cuthill-McKee 的函数是 p=symrcm(A) 。 不包含此算法的 C版本。
对称矩阵 的 Fiedler 向量是与
的图的拉普拉斯矩阵的第二大特征值对应的特征向量(假设图是连通的)。拉普拉斯矩阵
具有与
相同的非零模式。非对角线条目被替换为 -1,第
个对角线被替换为第 k 列中非对角线条目的数量。通过对Fiedler向量 进行排序得到的置换
,矩阵
将倾向于具有较小的轮廓。可以使用 MATLAB 的 eigs 函数计算。eigs 函数使用移位-求逆技术;因此它计算半正定矩阵
的分解。对于 Fiedler向量,可以使用Lanczos方法代替,它不需要分解
。
Matlab
function [p,v,d] = cs_fiedler (A)
%CS_FIEDLER the Fiedler vector of a connected graph.
% [p,v,d] = cs_fiedler(A) computes the Fiedler vector v (the eigenvector
% corresponding to the 2nd smallest eigenvalue d of the Laplacian of the graph
% of A+A'). p is the permutation obtained when v is sorted. A should be a
% connected graph.
% See also CS_SCC, EIGS, SYMRCM, UNMESH.
n = size (A,1) ;
if (n < 2) p = 1 ; v = 1 ; d = 0 ; return ; end
opt.disp = 0 ; % turn off printing in eigs
opt.tol = sqrt (eps) ;
S = A | A' | speye (n) ; % compute the Laplacian of A
S = diag (sum (S)) - S ;
[v,d] = eigs (S, 2, 'SA', opt) ; % find the Fiedler vector v
v = v (:,2) ;
d = d (2,2) ;
[ignore p] = sort (v) ; % sort it to get p7.6 嵌套剖分
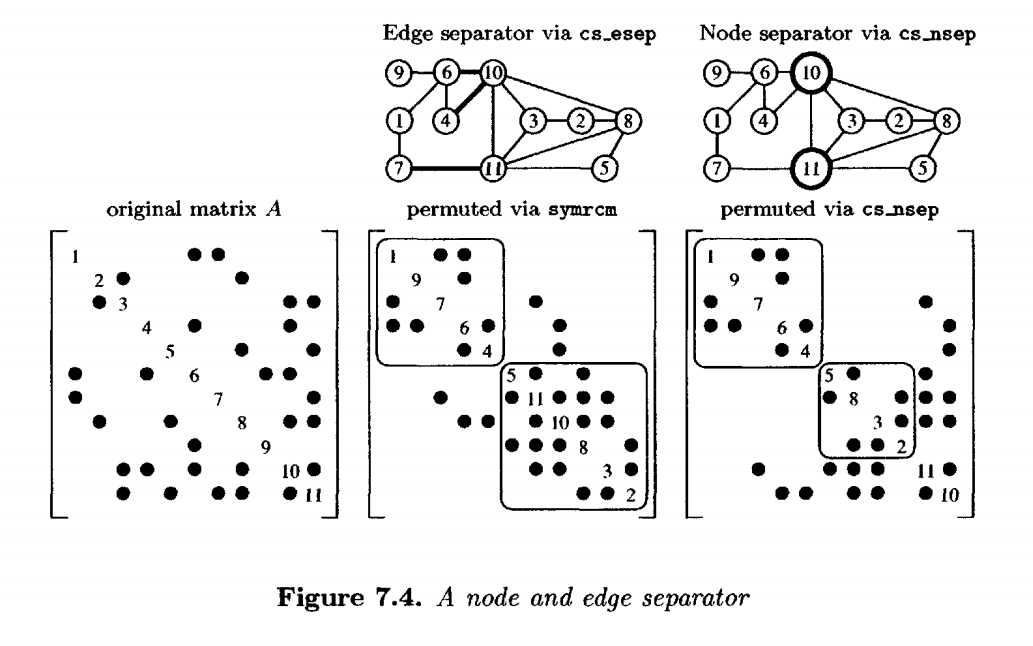
嵌套剖分是一种减少填充的排序,特别适用于由二维(2D )或三维(3D )几何问题离散化产生的矩阵。此排序的目标与最小度排序相同;它是一种减少填充的启发式方法,而不是轮廓或带宽。考虑具有对称非零模式的矩阵 的无向图。嵌套剖分找到一个节点分隔符,当从图中移除分隔符中的节点(及其关联的边)时,该分隔符将图分成两个或多个大致相等大小的子图(左和右)。然后,对于大的子图使用嵌套剖分递归排序,对于小的子图使用最小度排序。
使用单个节点分隔符,矩阵被分割成以下形式,其中 对应于节点分隔符中的节点的矩阵,
对应于左子图,
对应于右子图。由于左子图
和右子图
之间没有边相连,因此
为零。
有许多寻找好的节点分隔符的方法。一类方法从一个边分隔符开始,然后将其转换为节点分隔符。同样,边分隔符可以通过多种方式找到;这里讨论的方法基于上一节讨论的轮廓缩减方法。有许多寻找嵌套剖分排序的方法;选择此方法是因为其实现简单。最先进的方法在本节末尾会重点介绍。另请参见第7.7节。
假设已经找到了一个轮廓缩减排序 P 。将矩阵 分成其前 行和列以及后
行和列。由于
的轮廓已经减少,
中的条目数将很小。
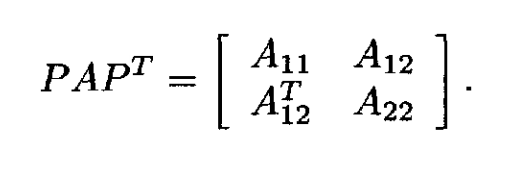
如果移除这些条目(图 中的边),图将分裂成两个大小相等的分量(如果
或
的图不连通,则可能分裂成多于两个连通分量)。
中的边是
的一个边分隔符。在实践中,矩阵不会被均分,因为如果允许两个子图大小不同,通常可以减小边分隔符的大小(它们保持大致相等的大小;否则,无法获得良好的排序)。下面显示的 cs_esep M文件使用 symrcm找到一个边分隔符。
Dulmage-Mendelsohn分解可以通过找到 中边的最小节点覆盖,将此边分隔符转换为节点分隔符。考虑
的二分图及其Dulmage-Mendelsohn分解,
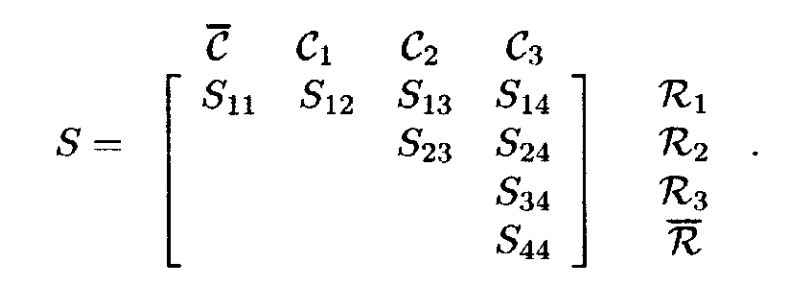
按行划分 R1, R2, R3 和列 C1, C2, C3
该方法可以选择节点覆盖为集合R₁ ∪ C₂ ∪ C₃或R₁ ∪ R₂ ∪ C₃,两者的大小都等于A12的最大匹配的大小(其结构秩)。S中的任何边都将至少与这两个集合中的一个节点相关联。cs_sep M文件选择R₁ ∪ C₂ ∪ C₃。在实践中,选择能最好地平衡左右子图大小的集合。CS_nsep M文件构造一个边分隔符并将其转换为节点分隔符。递归的CS_nd M文件使用CS_nsep找到一个节点分隔符,然后递归地对两个子图进行二分。小的图(阶数为500或更少)使用cs_amd排序。
Matlab
function [a,b] = cs_esep (A)
%CS_ESEP find an edge separator of a symmetric matrix A
% [a,b] = cs_esep(A) finds a edge separator s that splits the graph of A
% into two parts a and b of roughly equal size. The edge separator is the
% set of entries in A(a,b).
% See also CS_NSEP, CS_SEP, CS_ND, SYMRCM.
p = symrcm (A) ;
n2 = fix (size(A,1)/2) ;
a = p (1:n2) ;
b = p (n2+1:end) ;
Matlab
function [s,as,bs] = cs_sep (A,a,b)
%CS_SEP convert an edge separator into a node separator.
% [s,as,bs] = cs_sep (A,a,b) converts an edge separator into a node separator.
% [a b] is a partition of 1:n, thus the edges in A(a,b) are an edge separator
% of A. s is the node separator, consisting of a node cover of the edges of
% A(a,b). as and bs are the sets a and b with s removed.
% See also CS_DMPERM, CS_NSEP, CS_ESEP, CS_ND.
[p q r s cc rr] = cs_dmperm (A (a,b)) ;
s = [(a (p (1:rr(2)-1))) (b (q (cc(3):(cc(5)-1))))] ;
w = ones (1, size (A,1)) ;
w (s) = 0 ;
as = a (find (w (a))) ;
bs = b (find (w (b))) ;
Matlab
function [s,a,b] = cs_nsep (A)
%CS_NSEP find a node separator of a symmetric matrix A.
% [s,a,b] = cs_nsep(A) finds a node separator s that splits the graph of A
% into two parts a and b of roughly equal size. If A is unsymmetric, use
% cs_nsep(A|A'). The permutation p = [a b s] is a one-level dissection of A.
% See also CS_SEP, CS_ESEP, CS_ND.
[a b] = cs_esep (A) ;
[s a b] = cs_sep (A, a, b) ;
Matlab
function p = cs_nd (A)
%CS_ND generalized nested dissection ordering.
% p = cs_nd(A) computes the nested dissection ordering of a matrix. Small
% submatrices (order 500 or less) are ordered via cs_amd. A must be sparse
% and symmetric (use p = cs_nd(A|A') if it is not symmetric).
% See also CS_AMD, CS_SEP, CS_ESEP, CS_NSEP, AMD.
n = size (A,1) ;
if (n == 1)
p = 1 ;
elseif (n < 500) % use cs_amd on small graphs
p = cs_amd (A) ;
else
[s a b] = cs_nsep (A) ; % find a node separator
a = a (cs_nd (A (a,a))) ; % order A(a,a) recursively
b = b (cs_nd (A (b,b))) ; % order A(b,b) recursively
p = [a b s] ; % concatenate to obtain the final ordering
endFiedler向量或其他特征向量技术可以导致更小的节点分隔符和更低填充的排序,但计算它们对于大型图来说过于昂贵。为了克服这个问题,可以逐步粗化A的图G。A的粗图G_c中的一个节点代表G中的一个唯一节点集,节点权重等于其代表的节点数。边权重用于反映G中节点集之间的边数(其权重的总和)。找到一系列越来越粗的图G(原始图),G_1, G_2, ... , G_k,直到G_k足够小,可以有效地使用强大的边或节点分隔符方法。接下来,将边或节点分隔符映射到G_{k-1}的图,并使用细化技术(如Kernighan-Lin算法)来改进这个对G_{k-1}的划分。细化过程持续直到获得G的分隔符。
图7.4是第39页图4.2中矩阵的图,突出显示了节点和边分隔符。
如果应用于2D s×s网格,沿着最能均分图的网格线选择节点分隔符,嵌套剖分导致渐近最优的排序,L中有31(n log₂ n)/8 + O(n)个非零元,需要829(n^{3/2})/84 + O(n log n)次浮点运算来计算,其中n = s²是矩阵的维数。对于3D s×s×s网格,矩阵的维数为n = s³。L中有O(n^{4/3})个非零元,需要O(n²)次浮点运算来计算L,这也是渐近最优的。
7.7 进一步阅读
找到一个好的减少填充的排序对于减少稀疏分解方法的时间和内存需求至关重要。由于这是一个NP难题(Yannakakis 199),已经发展了许多启发式方法。这些启发式方法可以分为三大类:最小度、嵌套剖分和轮廓缩减。Dulmage-Mendelsohn分解 72 不是一种启发式方法,但它可以被视为排序方法的第四类,因为它将填充限制在对角块内。
最小度及其变体是最常用的方法,在绝大多数矩阵上提供低填充。对于来自2D和3D空间离散化(例如,有限元方法)的大型问题,特别是与用于排序小子图的最小度方法结合使用时,良好的嵌套剖分排序往往优于最小度。一种早期的非对称形式是Markowitz的方法 155,它选择aij以最小化行度i和列度j的乘积。HSL软件包中Duff和Reid 61 的MA28基于该方法的高效实现。有趣的是,Markowitz因其在投资组合理论方面的开创性工作获得了1990年诺贝尔经济学奖 79,其中一部分就是他的LU排序工作。
最小度是一种局部贪婪策略,或"自底向上"方法,因为它首先找到消去树的叶子。Tinney和Walker 196 开发了第一种用于对称矩阵的最小度方法。注意,他们论文标题中的"最优"一词用词不当,因为最小度是一种非最优方法。其最早的高效实现是由George和Liu的算法(SPARSPAK中的MMD及其前身 85, 87, 91)。其他实现包括YSMP(Eisenstat等人 73 和 Eisenstat, Schultz, and Sherman 76)和MA27(Duff, Erisman, and Reid 53 and Duff and Reid 62)。
由于计算精确度成本高昂,Amestoy、Davis和Duff开发了AMD,一种近似最小度排序 1, 2;Davis等人后来将其扩展到计算A^TA的列排序,而无需显式形成A^TA(COLAMD 33, 34)。近似度促使人们寻找对亏损的近似。节点的亏损是指如果该节点被选为主元将发生多少填充。基于近似亏损变体的方法由Rothberg和Eisenstat 176、Ng和Raghavan 161 以及Pellegrini、Roman和Amestoy 166 开发。
嵌套剖分是一种"自顶向下"方法,因为第一级分隔符包括消去树的根及其直接后代。Kernighan和Lin 140 提出了一种基于交换图中节点对的早期图划分技术。Fiduccia和Mattheyses提出了一种更高效的节点交换方法 77。Hager、Park和Davis将此思想扩展到交换节点块 126。第一个用于稀疏矩阵排序的嵌套剖分算法归功于George 81, 82。它依赖于找到一个好的伪周边节点,如George和Liu 86 所讨论的。另请参见Duff、Erisman和Reid对George嵌套剖分方法的讨论 52。
更近期的嵌套剖分方法基于多级方法和特征向量技术(特别是Fiedler向量 78)。这些包括Pothen、Simon和Liou 170、Karypis和Kumar(METIS 139)、Hendrickson和Leland(CHACO 131)、Pellegrini、Roman和Amestoy(SCOTCH 166)以及Walshaw、Cross和Everett(JOSTLE 197)的方法。由于许多矩阵出现在具有2D和3D几何的问题中,Heath和Raghavan 129 以及Gilbert、Miller和Teng(MESHPART 104)提出了基于图中节点几何位置的划分方法。CHOLMOD同时包含了AMD和一种将METIS与约束近似列最小度排序算法CCOLAMD 30 相结合的划分方法。
许多早期的稀疏矩阵分解方法使用轮廓或包络数据结构,因此减少矩阵的轮廓对方法的内存使用有直接影响。对于较新的分解技术,轮廓缩减仍然是一种有用的方法。它可以作为为图划分和嵌套剖分找到好的边或节点分隔符的第一步。Cuthill和McKee 25 开发了第一种技术,至今仍在使用。Liu和Sherman 153 表明,反转Cuthill-McKee排序永远不会增加轮廓,并且常常减少它。Chan和George 21 介绍了一种高效实现。其他轮廓缩减技术包括Crane等人 24、Gibbs 99、Gibbs、Poole和Stockmeyer 100、Hager 125、Reid和Scott 172, 173、Lewis 146 以及Sloan 187 的工作。特征向量技术也是减少轮廓的有效方法,如Barnard、Pothen和Simon 14、Pothen、Simon和Liou 170 以及Kumfert和Pothen 142 所讨论的。
Cormen、Leiserson和Rivest 23 描述了第7.3节讨论的scc算法。寻找图强连通分量的最早算法归功于Tarjan 194;Duff和Reid 59, 60 实现了该算法。Gustavson 120 讨论了最大匹配和Tarjan算法的一种实现。Duff 48, 49 提出了cs_maxtrans使用的O(|A|n)时间最大匹配算法。Duff和Wiberg 71 实现了Hopcroft和Karp 137 的O(|A|√n)时间最大匹配算法,该算法在实践中并不总是比O(|A|n)时间算法快。Pothen和Fan 169 比较了计算块三角形式的各种方法。Duff和Koster 57, 58 提出了一种最大加权匹配。
MATLAB中的排序方法在第10章中讨论。
练习
7.1. 从 www.siam.org/books/fa02(或从 www.acm.org 作为ACM Algorithm 837)下载一份AMD。将其与cs_amd进行比较,并列出两个代码之间的差异。在大量对称矩阵上比较它们的运行时间、内存使用情况和排序质量(在MATLAB中使用p=cs_amd(A)并与p=amd(A)进行比较)。MATLAB表达式 lnz=sum(symbfact (A(p ,p))) 给出了矩阵A(p,p)的Cholesky因子L中的非零元数量(忽略数值对消)。
7.2. 将MATLAB语句 q=cs_amd(A, 2) 与MATLAB语句 q=colamd(A) 计算的置换进行比较。比较排序时间和内存使用情况。使用列排序 L,U,P=lu(A(:,q)) 来比较排序质量(nnz(L)+nnz(U))。向cs_amd和COLAMD添加代码以计算它们的内存使用情况。COLAMD排序A^TA而不显式形成它,因此它倾向于使用比cs_amd(A)少得多的内存。两者都从A中丢弃稠密行。
7.3. 将MATLAB语句 p=cs_amd(A, 3) 与MATLAB语句 p=amd(A'*A) 计算的置换进行比较(参见问题7.1)。比较排序时间和内存使用情况。比较排序质量;使用 rnz = sum(symbfact(A(:,q), 'col'))(其中rnz与nnz(qr(A,0))相同,忽略数值对消,并假设A不是结构秩亏)。
7.4. 编写一个函数,通过将LU分解与块三角形式(精细Dulmage-Mendelsohn分解)相结合来求解Ax = b。使用cs_dmperm找到块,然后分别使用cs_sqr和cs_lu分析和分解每个块。接下来,通过块回代求解Ax = b。在具有多个对角块的矩阵(包括电路仿真和化学过程仿真中出现的矩阵)上与cs_lu进行比较。另请参见第8.4节。
7.5. 为什么块三角形式对稀疏Cholesky分解没有帮助?提示:考虑消去树后序。如果消去树是一个森林会发生什么?
7.6. 将大条目放置在矩阵对角线上的启发式方法是有用的方法,可以减少分解期间对partial pivoting的需求(例如,参见 57, 58)。尝试以下方法。首先,缩放矩阵A的副本,使得每列中的最大条目等于1。接下来,从矩阵中移除小条目,并使用cs_maxtrans找到一个零自由对角线。如果丢弃了太多条目,则降低丢弃容差并重试,或者简单地任意完成匹配。使用匹配作为列预排序Q,然后用最小度排序AQ + (AQ)^T。在cs_lu中使用小的主元容差,并确定找到了多少个非对角主元。
7.7. 在来自实际应用的大量矩阵上,比较cs_dmperm在不同seed值(0、-1和1)下的运行时间。来自优化问题的对称不定矩阵特别令人感兴趣(例如,UF稀疏矩阵集合中GHS_indef组中来自Gould、Hu和Scott 116 的许多矩阵)。找到随机顺序、逆序和自然顺序方法各自优于其他方法的例子(boyd2矩阵是一个极端的例子)。