
高质量 PDF 转 JPG 批量转换工具:模块拆解与深度解析
在日常办公和开发中,PDF 转图片是高频需求,本文将深度拆解基于 PyMuPDF(fitz)和 PIL 实现的 PDF 转 JPG 批量转换工具,从模块设计、核心逻辑、使用场景到优化建议,全方位解析该脚本的设计思路与实践价值。
一、脚本整体架构
该脚本采用模块化设计,核心分为「单 PDF 转换模块」「批量转换模块」「命令行参数解析模块」三大核心部分,整体架构如下:
| 模块名称 | 核心函数 | 功能定位 | 依赖库 |
|---|---|---|---|
| 单 PDF 转换核心模块 | pdf_to_jpg() |
实现单 PDF 文件到 JPG 的转换 | fitz、PIL、os |
| 批量转换控制模块 | batch_convert() |
处理单文件 / 多文件批量转换逻辑 | os |
| 命令行参数交互模块 | 主函数(main) | 解析用户输入参数,触发转换流程 | argparse |
脚本核心特性:
- 支持单 PDF 文件 / 多 PDF 目录批量转换;
- 自定义输出目录、图片 DPI(分辨率)、JPG 质量;
- 自动处理图片通道问题(如 RGBA 转 RGB);
- 实时输出转换进度,异常友好提示。
二、核心模块深度解析
2.1 环境依赖与前置说明
脚本运行前需安装依赖库:
pip install pymupdf pillow # PyMuPDF(fitz)+ PIL(Pillow)PyMuPDF(fitz):轻量高效的 PDF 处理库,支持 PDF 页面渲染、像素提取;PIL(Pillow):Python 图片处理库,负责格式转换、通道处理、质量调整;os:系统路径 / 文件操作;argparse:命令行参数解析。
2.2 单 PDF 转换核心模块:pdf_to_jpg ()
该函数是脚本的核心,实现从 PDF 到 JPG 的完整转换流程,参数与逻辑拆解如下:
2.2.1 函数参数说明
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
pdf_path |
str | 无 | 待转换 PDF 文件的绝对 / 相对路径 |
output_dir |
str | None | 图片输出目录,默认与 PDF 文件同目录 |
dpi |
int | 300 | 图片分辨率(DPI),默认 72DPI 为基准缩放 |
quality |
int | 95 | JPG 质量(1-100),数值越高质量越好 |
2.2.2 核心执行流程
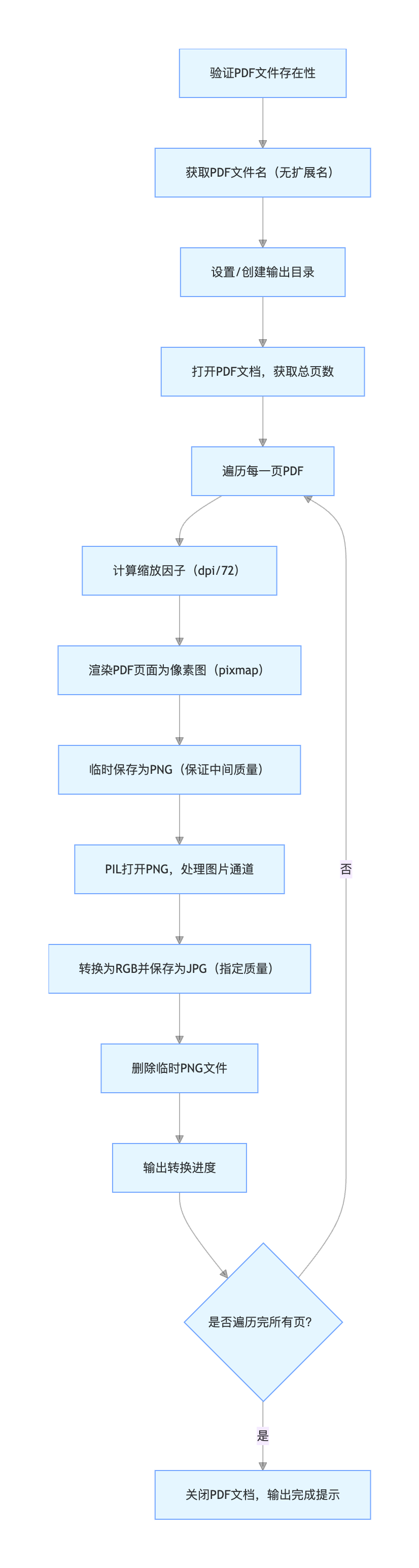
2.2.3 关键逻辑详解
-
文件与目录校验
if not os.path.exists(pdf_path): print(f"错误:文件 {pdf_path} 不存在") return os.makedirs(output_dir, exist_ok=True) # 不存在则创建,存在则不报错先验证 PDF 文件是否存在,避免无效操作;自动创建输出目录,提升用户体验。
-
**PDF 页面渲染(核心)**PyMuPDF 默认渲染分辨率为 72DPI,通过缩放因子实现自定义 DPI:
zoom = dpi / 72 mat = fitz.Matrix(zoom, zoom) # 构建缩放矩阵 pix = page.get_pixmap(matrix=mat) # 渲染页面为像素图缩放因子 = 目标 DPI / 默认 DPI,保证图片分辨率符合预期。
-
**图片通道处理(避坑关键)**PDF 渲染的图片可能包含 Alpha 通道(RGBA/LA)或调色板模式(P),而 JPG 不支持透明通道,需转换为 RGB:
if img.mode in ('RGBA', 'LA'): # 白色背景填充透明区域 background = Image.new(img.mode[:-1], img.size, (255, 255, 255)) background.paste(img, img.split()[-1]) # 按alpha通道粘贴 img = background elif img.mode == 'P': img = img.convert('RGB') # 调色板模式直接转RGB该逻辑避免了 "转换后图片背景透明 / 发黑" 的常见问题。
-
临时文件与进度输出
-
先保存为 PNG(无损格式)再转 JPG,避免直接转 JPG 的质量损耗;
-
实时输出转换进度(
end="\r"实现单行刷新):progress = (page_num + 1) / total_pages * 100 print(f"转换进度:{progress:.1f}% ({page_num + 1}/{total_pages})", end="\r")
-
2.3 批量转换控制模块:batch_convert ()
该函数是 "调度器",根据用户输入的input_path类型(文件 / 目录),触发对应的转换逻辑:
2.3.1 核心分支逻辑
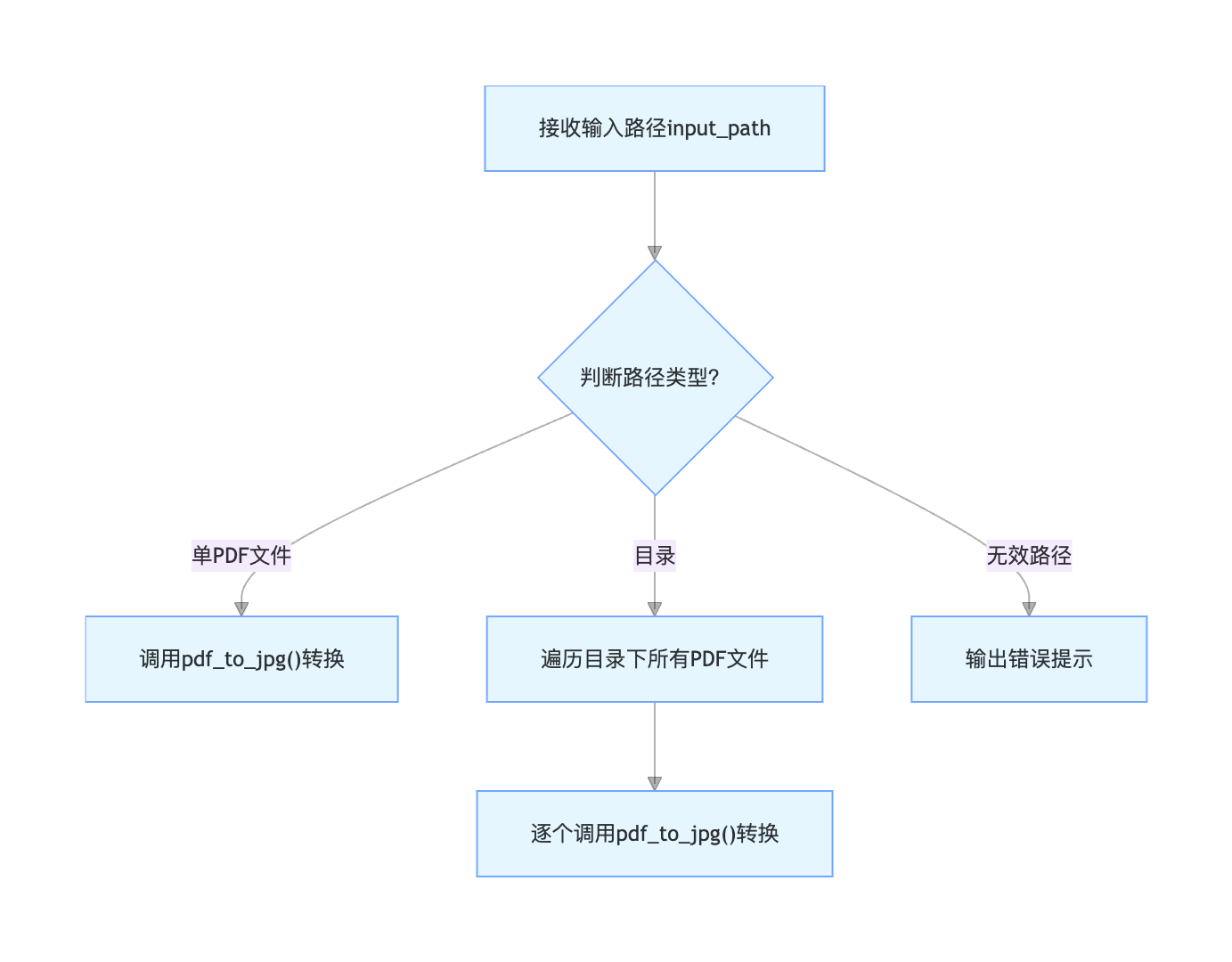
2.3.2 关键逻辑详解
-
路径类型判断
if os.path.isfile(input_path) and input_path.lower().endswith('.pdf'): # 单PDF文件 pdf_to_jpg(input_path, output_dir, dpi, quality) elif os.path.isdir(input_path): # 目录:筛选所有PDF文件 pdf_files = [f for f in os.listdir(input_path) if os.path.isfile(os.path.join(input_path, f)) and f.lower().endswith('.pdf')]兼容大小写后缀(如
.PDF/.pdf),提升兼容性。 -
批量进度管理对目录下的 PDF 文件计数,输出 "当前处理第 N 个文件",清晰展示批量转换进度:
print(f"\n处理第 {i + 1}/{total_files} 个文件:{filename}")
2.4 命令行参数交互模块:主函数(main)
该模块负责解析用户从命令行输入的参数,验证参数有效性后,调用batch_convert()触发转换。
2.4.1 参数解析配置
parser = argparse.ArgumentParser(description='PDF转JPG批量转换工具(直接保存到目录)')
parser.add_argument('input', help='输入PDF文件或目录路径') # 必选参数
parser.add_argument('-o', '--output', help='输出目录路径,默认为PDF同目录', default=None)
parser.add_argument('-d', '--dpi', type=int, help='图片分辨率,默认300', default=300)
parser.add_argument('-q', '--quality', type=int, help='JPG质量(1-100),默认95', default=95)参数设计遵循 "必选 + 可选" 原则:input为必选(文件 / 目录路径),其余为可选(有合理默认值)。
2.4.2 参数有效性验证
if args.dpi <= 0:
print("错误:DPI必须为正数")
exit(1)
if args.quality < 1 or args.quality > 100:
print("错误:图片质量必须在1-100之间")
exit(1)提前校验参数合法性,避免转换过程中因无效参数报错。
三、脚本使用指南
3.1 基础使用示例
示例 1:转换单个 PDF 文件(默认参数)
python pdf2jpg.py test.pdf- 输出目录:
test.pdf同目录; - 分辨率:300DPI;
- JPG 质量:95;
- 输出文件名:
test_page_1.jpg、test_page_2.jpg...
示例 2:转换单个 PDF 并指定输出目录、DPI、质量
python pdf2jpg.py test.pdf -o ./output -d 600 -q 90- 输出目录:
./output; - 分辨率:600DPI(高清);
- JPG 质量:90。
示例 3:批量转换目录下所有 PDF
python pdf2jpg.py ./pdf_dir -o ./jpg_output- 输入:
./pdf_dir目录下所有 PDF 文件; - 输出:
./jpg_output目录(所有 PDF 的页面图片直接保存在该目录,无子文件夹)。
3.2 输出示例
发现 2 个PDF文件,开始批量转换...
处理第 1/2 个文件:demo1.pdf
开始转换:demo1.pdf 共 5 页
转换进度:100.0% (5/5)
转换完成!图片已保存至:./jpg_output
处理第 2/2 个文件:demo2.pdf
开始转换:demo2.pdf 共 3 页
转换进度:100.0% (3/3)
转换完成!图片已保存至:./jpg_output
所有文件转换完成!四、优化建议与扩展方向
4.1 现有脚本的可优化点
-
临时文件优化 :当前使用固定名称的临时 PNG,多线程 / 多进程场景下会冲突,建议使用
tempfile模块生成唯一临时文件:import tempfile with tempfile.NamedTemporaryFile(suffix='.png', delete=False) as temp_file: temp_png = temp_file.name pix.save(temp_png) # 用完后删除 os.unlink(temp_png) -
异常处理增强:增加更细分的异常捕获(如权限错误、PDF 损坏、磁盘满):
try: # 转换逻辑 except PermissionError: print(f"错误:无权限写入目录 {output_dir}") except fitz.FileDataError: print(f"错误:{pdf_path} 不是有效的PDF文件或文件已损坏") except Exception as e: print(f"\n转换失败:{str(e)}") -
多进程加速 :批量转换时,单线程处理慢,可引入
multiprocessing并行处理多个 PDF:from multiprocessing import Pool def process_pdf(pdf_file): pdf_path = os.path.join(input_path, pdf_file) pdf_to_jpg(pdf_path, output_dir, dpi, quality) if __name__ == "__main__": # 批量转换时 with Pool(processes=os.cpu_count()) as pool: pool.map(process_pdf, pdf_files) -
文件名去重 :多个 PDF 转换后可能出现文件名冲突(如
test_page_1.jpg),可在文件名前增加 PDF 文件的唯一标识(如哈希值)。
4.2 扩展功能方向
- 支持指定页码范围转换(如只转换 PDF 的 1-5 页);
- 支持输出图片格式扩展(PNG/PNG/WebP);
- 增加图片压缩选项(按大小 / 比例压缩);
- 生成转换报告(转换文件数、页数、耗时、失败列表);
- 图形化界面(基于 tkinter/Qt),降低非技术用户使用门槛。
五、总结
该脚本以模块化、高易用性为核心设计原则,完美解决了 PDF 转 JPG 的批量处理需求,核心优势在于:
- 轻量高效:基于 PyMuPDF,转换速度远快于传统 PDF 处理库;
- 鲁棒性强:自动处理图片通道、文件校验、异常提示;
- 灵活配置:支持分辨率、质量、输出目录自定义;
- 易于扩展:模块化设计便于增加新功能(如多进程、格式扩展)。
无论是日常办公批量转换 PDF,还是集成到自动化工作流中,该脚本都能满足核心需求,通过本文的优化建议,还可进一步提升其稳定性和性能。