KTransformers,由趋境科技与清华大学KVCache.AI团队联合研发。
项目论文:KTransformers: Unleashing the Full Potential of CPU/GPU Hybrid Inference for MoE Models
KTransformers:充分释放混合专家(MoE)模型 CPU/GPU 混合推理的全部潜力
作者及单位
陈鸿涛♠∗ 谢维宇♠∗ 张博鑫♠∗ 唐靖祺♥ 王家豪♥♣ 董建伟♠ 陈少远♠ 袁子薇♥♦ 林晨♠ 邱成宇♠ 朱悦宁♠ 欧清亮♥△ 廖佳琦♥⊳ 陈湘林♥ 艾志远♥ 吴永伟♠ 张明兴♠+♠清华大学 ♥趋近智能(Approaching.AI) ♣杭州电子科技大学 ♦电子科技大学 △北京邮电大学 ⊳北京理工大学∗本文前三作者贡献相同 + 通讯作者:zhang_mingxing@mail.tsinghua.edu.cn
摘要
混合专家(Mixture-of-Experts,MoE)模型具有稀疏特性,使其尤其适用于 CPU/GPU 混合推理场景,低并发场景下该优势尤为显著。这种混合推理方式既能利用 CPU/DRAM 大容量、高性价比的存储优势,又能发挥 GPU/VRAM 高带宽的计算优势。然而,现有混合推理方案仍受限于 CPU 计算能力瓶颈和 CPU-GPU 同步开销过高的问题,严重制约了其高效运行当前主流大尺度 MoE 模型(如 6710 亿参数的 DeepSeek-V3/R1)的能力。
本文提出 KTransformers------ 一款专为各类 MoE 模型高效异构计算设计的高性能推理系统。KTransformers 采用针对 AMX 指令集优化的专用计算内核,充分挖掘现代 CPU 的计算能力;同时引入异步 CPU-GPU 任务调度机制以最小化开销,相比现有系统,其预填充阶段速度提升 4.62~19.74 倍,解码阶段速度提升 1.25~4.09 倍。
此外,本文提出一种全新的 "专家延迟(Expert Deferral)" 机制,该机制能策略性地提升 CPU 与 GPU 计算的并行化潜力,将 CPU 利用率从通常不足 75% 提升至接近 100%。在上述优化基础上,该机制可进一步带来最高 1.45 倍的吞吐量提升,且在多类基准测试中模型平均精度损失不超过 0.5%。
最终实现的 KTransformers 系统大幅提升了大尺度 MoE 模型在本地场景的可及性(尤其适用于重视安全性或希望深入研究模型内部机制的本地用户),目前已被开源社区和工业界广泛采用。
关键词
混合专家、混合推理、大语言模型
ACM 引用格式
Hongtao Chen 等. 2025. KTransformers:充分释放混合专家(MoE)模型 CPU/GPU 混合推理的全部潜力。发表于《ACM SIGOPS 第 31 届操作系统原理研讨会》(SOSP '25),2025 年 10 月 13--16 日,韩国首尔. ACM,美国纽约州纽约市,16 页. https://doi.org/10.1145/3731569.3764843
1 引言
混合专家(MoE)大语言模型(LLMs)已在各类任务中展现出卓越性能 11,23,29,36,41。该类模型通过在每个前馈层仅激活部分专家子网络,实现了计算稀疏性,显著降低了训练和推理阶段的计算需求。近期推出的 DeepSeek-V3/R1 7,8 等模型借助这种稀疏性实现了当前最优的开源权重模型性能,也引发了社区对 MoE 模型实际部署场景的广泛关注。
得益于稀疏激活特性,MoE 模型尤其适配两种极端部署场景:(1)大规模云部署,特征是高并发(如每批次数万请求),频繁的专家激活可提升硬件利用率并最大化模型浮点运算利用率(MFU)7;(2)低并发本地部署(如每批次单个 / 少量请求),稀疏的专家激活能大幅降低内存访问开销。
尽管针对大规模云环境的工程优化已相对成熟,但 MoE 模型的本地部署仍面临巨大挑战 ------ 核心瓶颈是 GPU 显存限制,无法将完整模型部署在有限的 VRAM 中(图 1a)。解决该问题的有效方案是 CPU/GPU 混合推理:将部分模型参数卸载至 CPU,利用 DRAM 更大的容量和更低的成本优势。现有研究(最具代表性的是 Fiddler 24)表明,基于算术强度的分区策略可大幅降低 GPU 显存需求并提升硬件利用率:具体而言,算术强度最高的注意力层优先部署在 GPU,其次是通过离线分析专家调用频率识别出的高频专家。本文采用类似的分区策略进行 CPU/GPU 混合推理;特别地,本文聚焦于含共享专家的模型 ------ 这类模型中,共享专家天然是调用频率最高的专家,因此部署在 GPU 上,而设计为均衡激活的路由专家则卸载至 CPU(图 1b)。这一聚焦简化了部署配置且不损失通用性,因为对于无共享专家的模型,仍可通过 Fiddler 中的离线分析方法识别高频专家。
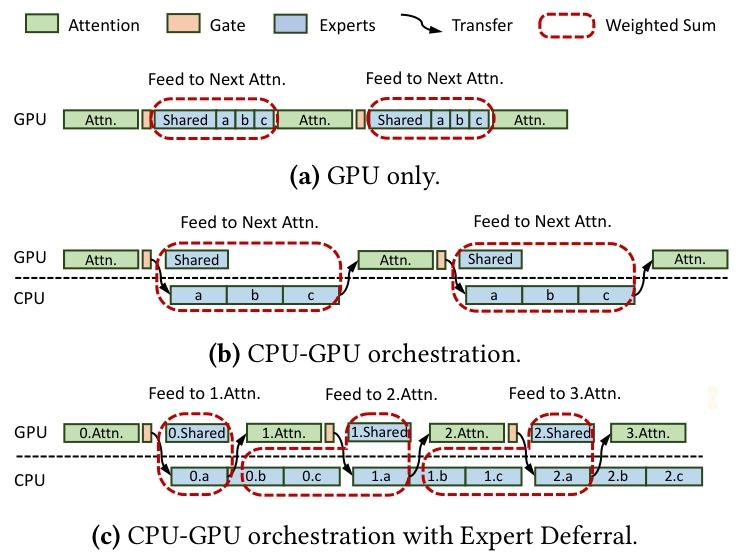
(a) 仅 GPU;(b) CPU-GPU 协同调度;(c) 引入专家延迟的 CPU-GPU 协同调度
然而,将上述 Fiddler 风格的混合推理技术应用于本地部署场景下的大尺度 MoE 模型(如 6710 亿参数的 DeepSeek-V3/R1,硬件配置为 1 张 NVIDIA A100 GPU+2 颗 Intel Xeon CPU)时,暴露出显著瓶颈:系统吞吐量极低(预填充阶段 70.02 个 token / 秒,解码阶段 4.68 个 token / 秒),且 GPU 利用率不足 30%------ 这清晰表明 CPU 受限操作是主要性能瓶颈。
为解决上述问题,实现资源受限硬件上 MoE 模型的高效实用推理,我们开展了全面的系统级分析以识别关键性能瓶颈,发现两大核心低效问题:
- 预填充阶段 CPU 计算未充分利用:MoE 模型预填充阶段需同时处理数千个 token,给 CPU 带来巨大计算负担。现有实现通常采用通用 SIMD 指令集(如 AVX-512),未能有效利用 Intel AMX、ARM SME 等先进 CPU 扩展指令。尽管 PyTorch 32 集成了硬件厂商提供的专用内核(如通过 oneDNN 库 43 调用 Intel AMX 内核),但其性能仅达到理论峰值的 7%。我们认为这一差距主要源于内存布局优化不足 ------ 导致缓存效率降低、有效内存带宽下降,并引入不必要的开销。
- 解码阶段 CPU-GPU/CPU 协同低效:与预填充阶段不同,解码阶段每个推理步骤通常仅处理少量 token(通常为 1 个),且每次仅激活少数专家。由此导致 CPU 和 GPU 内核执行时间极短(每层通常仅几毫秒或更短),加剧了 CPU 与 GPU 间的同步开销。传统同步方式引入大量内核启动延迟,限制了 CPU-GPU 执行并行度,且流水线并行性不足;此外,CPU 内存访问未对齐、跨 NUMA 节点数据传输成本高(即 CPU-CPU 协同低效)进一步降低系统吞吐量,大幅拉大硬件理论性能与实际性能的差距。
为应对这些挑战,实现大尺度 MoE-LLM 在资源受限本地硬件上的高效部署,本文提出 KTransformers------ 一款专为异构 CPU/GPU 环境设计的高性能推理系统。
KTransformers 引入 "算术强度感知的混合推理内核":这是一种为 CPU 上 MoE 负载优化的混合指令后端。通过分析不同任务的算术强度(ARI),KTransformers 在预填充阶段(如长提示词频繁激活多个专家)为高 ARI 专家计算选择性采用 Intel AMX 指令,并提出与 AMX 分块策略协同设计的专用内存布局(包含分块量化、64 字节对齐、分块感知的子矩阵访问模式),显著提升缓存局部性并降低内存带宽需求;反之,对于低 ARI 任务(如短提示词的解码阶段),KTransformers 默认采用轻量级 AVX-512 内核以实现更高效率。此外,KTransformers 设计了 "保持吞吐量的 NUMA 感知张量放置策略",确保多插槽 CPU 系统的可扩展性和高利用率。通过实现专为 AMX 指令优化的 MoE 专用内核,KTransformers 在各类微基准测试中相比现有方法实现了 1.69~4.30 倍的速度提升。
此外,KTransformers 采用基于 CUDA Graph 高级用法的异步 CPU-GPU 任务调度机制,有效实现 CPU 与 GPU 计算的并行化。尽管 CUDA Graph 已被广泛用于最小化内核启动开销 14,26,31,56,但现有方案无法充分支持动态张量形状,且通常需要为每层和每个批次大小单独创建 CUDA Graph 实例,导致显著的 VRAM 开销和低效。相比之下,KTransformers 通过基于 CUDA 的自旋机制将整个解码阶段封装为单个 CUDA Graph 实例,大幅降低内核启动开销并最大化 GPU 吞吐量 ------ 这一优化使解码阶段速度提升最高 1.23 倍。
然而,即便经过上述优化,超大规模 MoE 模型(如 DeepSeek-V3)的解码吞吐量仍仅为 5.87 个 token / 秒。为进一步优化资源利用率和性能,我们提出一种全新的执行策略 ------ 专家延迟(Expert Deferral)。
性能分析表明,混合部署架构下(尤其是单批次场景),CPU 和 GPU 利用率均较低,核心原因是 MoE 模块与注意力模块的串行执行导致硬件资源闲置。专家延迟机制通过重构执行流水线解决该问题:如图 1c 所示,在每个 MoE 层中,仅部分专家(即时专家)被立即处理,其余专家(延迟专家)被调度为与下一层(主要是注意力模块)的计算并发执行。通过精准确定延迟专家的数量,该机制在对模型行为影响极小的前提下,显著提升 CPU 和 GPU 的并行度。
在 DeepSeek-V3 的测试中,专家延迟机制将 CPU 和 GPU 利用率从 74%/28% 提升至 100%/37%,解码吞吐量提升 33%;在所有评估场景中,吞吐量最高提升 45%。关键的是,在 HumanEval 3、MBPP 2、GSM8K 4、StrategyQA 15 和 LiveBench 46 等多样化基准测试中,模型平均精度损失不超过 0.5%。
本文的主要贡献如下:
- 设计并实现 KTransformers------ 一款面向资源受限本地部署场景的高性能专家卸载式 MoE 推理系统。全精度实现版本相比现有系统,预填充速度提升 4.62~19.74 倍,解码速度提升 1.25~4.09 倍;
- 提出全新的专家延迟技术,通过重构模型执行顺序实现细粒度 CPU-GPU 并行化。该技术使解码性能进一步提升最高 1.45 倍,整体解码速度达到现有方案的 1.66~4.90 倍,且仅带来有限的精度损失;
- KTransformers 的核心性能组件包含 11000 行 C++ 扩展代码,集成层包含 2000 行 Python 脚本,可直接替换 HuggingFace 风格的 Transformer 推理模块。KTransformers 支持在仅配备单张消费级 GPU 的单台服务器上运行万亿参数级 MoE 模型,为本地部署场景提供了替代多 GPU 集群的高性价比方案。
KTransformers 的源代码已开源至https://github.com/kvcache-ai/ktransformers。由于其适配本地环境运行超大 MoE 模型的特性,该系统已被开源社区和工业界团队广泛采用,目前部署于数百台对本地部署有强需求(如安全性要求、模型内部机制研究)的机器上。
2 背景
2.1 混合专家模型
混合专家(MoE)将条件计算引入 Transformer 模型:在每层为每个 token 仅激活部分专用子网络(即 "专家")36。如图 2 所示,典型的 MoE 层中,稠密前馈模块被替换为大量专家网络,且一个学习到的门控机制会动态选择与每个 token 最相关的专家(通常为 top-k 或其变体,如 DeepSeek-V3/R1 中的分组 top-k)。近期的 DeepSeek 6-8、通义千问(Qwen)42,50 等架构进一步引入 "共享专家"------ 这类专家对所有 token 激活,确保每个 token 在接受更专业的处理前,先获得基础的语义理解能力。
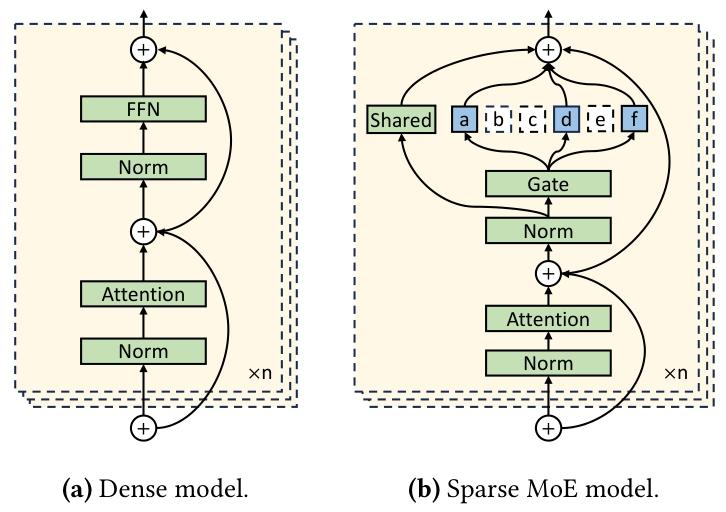
(a) 稠密模型;(b) 稀疏 MoE 模型
尽管 MoE 模型具备计算稀疏性,但其庞大的总参数量仍带来显著的内存挑战。常见的缓解方案是权重卸载 17,20,37,40:将专家权重存储在 CPU 内存中,按需传输至 GPU。但该方案很快受限于 PCIe 带宽(如 PCIe 4.0 的 32 GB/s)。为克服这一问题,计算卸载 24 成为更高效的替代方案:专家权重持久化存储在 CPU 内存中,计算直接在 CPU 上执行。该方案受益于现代 CPU 更高的内存带宽 ------ 例如,双插槽 Intel Xeon 系统搭配 DDR5 内存可提供 440 GB/s 的内存带宽,使 CPU 执行在低并发场景下极具优势。然而,这也将性能瓶颈转移至 CPU 端的内存访问和计算吞吐量,给系统设计带来新挑战。
2.2 先进 CPU 指令集
现代 CPU(尤其是高性能计算(HPC)场景)持续采用更复杂的指令集架构。Intel 高级矩阵扩展(AMX)、ARM 可扩展矩阵扩展(SME)等新兴指令集专为加速矩阵密集型任务设计,而 Transformer 模型推理是其典型应用场景。然而,我们的实验评估表明,当前软件实现未能充分利用这些加速能力。
例如,我们在配备 36 核 Intel Xeon 8452Y 处理器的机器上,对 DeepSeek-V3 的 MoE 层开展微基准测试 ------ 测试采用 PyTorch 实现(内部通过 oneDNN 库调用 AMX 和 AVX-512 指令集)。通过调整分配给每个专家的 token 数量,模拟不同算术强度(ARI)的场景。如图 3 所示,AMX 在高 ARI 场景下性能优于 AVX-512,峰值吞吐量可达 5.4 TFLOPS(AVX-512 仅为 1.8 TFLOPS);但即便如此,这也仅达到 AMX 理论峰值(73.7 TFLOPS)的约 7%。性能差距主要源于内存带宽限制和线程同步开销。
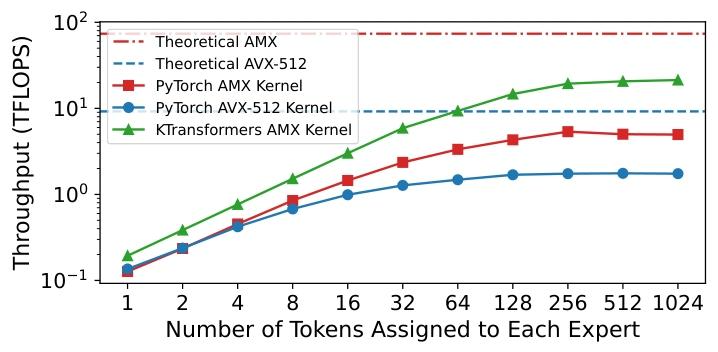
注:对比 PyTorch 的 AMX/AVX-512 内核与本文提出的 KTransformers AMX 内核在 DeepSeek-V3 MoE 层的吞吐量。
2.3 CPU-GPU/CPU 协同
2.3.1 CPU-GPU 协同
由 CPU 发起的传统 GPU 内核启动方式,在逐 token 解码场景下效率极低 ------ 频繁的同步和内核调用带来高昂开销 54。我们使用 NVIDIA NSight Systems 30 对基于 Fiddler 24 和 Llama.cpp 14 实现的 DeepSeek-V3 解码阶段进行性能分析(路由专家在 CPU 执行,其余模型部分在 NVIDIA A100 GPU 执行)。如图 4 所示,Fiddler 每解码一个 token 触发超过 7000 次 CUDA 内核启动,平均延迟 16 微秒,仅内核启动开销就占 GPU 执行时间的 73%;相比之下,Llama.cpp 通过激进的算子融合和底层优化将内核启动次数降至约 3000 次 /token,且其 C++ 实现避免了 Python 解释器的开销,将平均内核启动延迟降至 5 微秒。尽管如此,内核启动开销仍占总 GPU 执行时间的 21%。

Figure 4. GPU kernel launch and execution time analysis of DeepSeek-V3 inference using Fiddler and Llama.cpp.
为解决这一开销问题,现代 LLM 推理框架支持 CUDA Graph 31 优化 ------ 将多个 GPU 内核调用融合为单个可执行图,从而显著降低启动开销。但在 CPU/GPU 混合执行场景下,其效果受限:基于 CPU 的操作会引入同步和数据传输点,破坏 CUDA Graph 的连续性。尽管 PyTorch 的 torch.compile 等优化机制试图自动管理这些节点,但往往会在层边界处拆分图,抵消潜在的性能收益;类似地,Llama.cpp 为避免重复捕获开销,也禁用了 CUDA Graph 优化。
此外,GPU 上的共享专家计算与 CPU 上的路由专家计算并行执行,带来了传统 CUDA Graph 部署未解决的新挑战 ------ 需要专用策略实现 CPU 与 GPU 计算的有效并行化。
2.3.2 CPU-CPU 协同
除 CPU-GPU 同步外,现代系统通常包含多个 NUMA 节点,导致内存访问延迟和带宽的异构性,且 CPU-CPU 同步成本高昂 5。本地内存访问远快于远程(跨插槽)访问,这凸显了 NUMA 感知优化的必要性。然而,Fiddler、Llama.cpp 等现有推理框架忽略了这一差异,假设内存访问是均匀的。
我们使用 Fiddler 对 DeepSeek-V3 单个 MoE 层的解码过程进行分析:单插槽运行耗时 6.9 毫秒,而双插槽仅将延迟降至 5.8 毫秒 ------ 仅提升 16%。提速有限的主要原因是跨 NUMA 节点的内存访问低效,尤其是跨插槽访问时,框架级抽象与底层硬件拓扑不匹配。
3 KTransformers 系统
3.1 系统概述
本文提出 KTransformers------ 一款支持各类 MoE 模型高效异构计算的高性能系统。如图 5 所示,KTransformers 基于主流的 HuggingFace Transformers 47 实现扩展,允许灵活注入针对特定硬件优化的实现,以替换默认的 PyTorch 模块(详见第 5 节)。关键的是,KTransformers 完全兼容广泛使用的 HuggingFace 接口,无需终端用户修改代码,实现了易用性与性能的平衡。
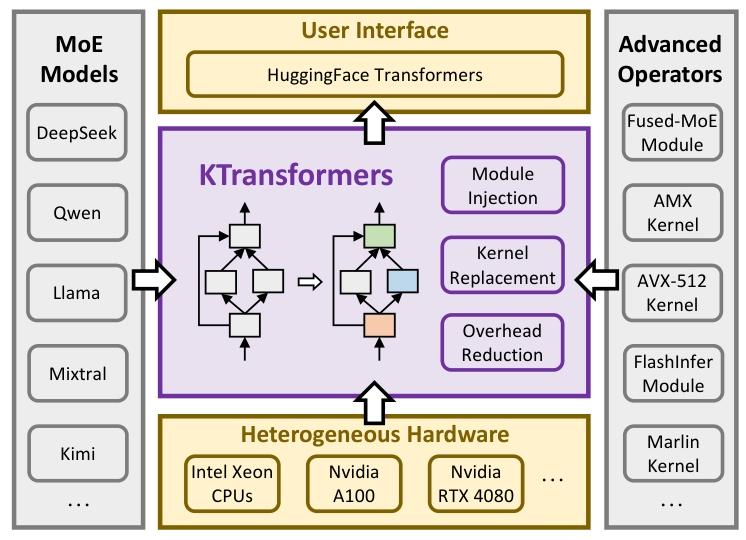
Figure 5. System overview of KTransformers.
针对本文核心关注的专家卸载场景,KTransformers 在 CPU 和 GPU 端均引入针对性优化:
- CPU 端:将 PyTorch 默认的 MoE 模块替换为自定义的融合 MoE 模块,大幅降低运行时开销;同时将标准 PyTorch GEMM 内核替换为高度优化的 AMX/AVX-512 内核,充分利用专用 CPU 指令提升计算效率;
- GPU 端:注入基于 FlashInfer 51 的高效注意力模块,并可选支持 Marlin 内核 13 等高效权重量化方案,实现可扩展的异构执行。
此外,KTransformers 采用异步任务调度协调跨设备计算,可将整个动态形状的 CPU/GPU 混合前向计算捕获到单个 CUDA 图中,有效消除 CUDA 内核启动开销,并确保异构平台的无缝集成。
3.2 充分释放 CPU 潜力
我们设计了一系列优化策略以提升大尺度 MoE 推理的 CPU 效率:首先,引入 AMX 分块感知的内存布局和缓存优化的 AMX 内核,突破内存瓶颈;其次,考虑到 AMX 在低算术强度任务中的低效性,实现轻量级 AVX-512 内核,可根据需求动态替换 AMX 指令;最后,采用算子级融合和动态任务调度,减少 MoE 执行中典型的同步开销和负载不均衡问题。
3.2.1 AMX 分块感知的内存布局
Intel 高级矩阵扩展(AMX)显著加速稠密矩阵乘法:每个支持 AMX 的核心提供 8 个 tile 寄存器,每个寄存器存储 16 行 ×64 字节的子矩阵。AMX 指令可高效乘这些 tile,并通过单条指令将整个 tile 从内存传输至寄存器(或反之)。然而,由于 AMX 吞吐量极高,内存访问效率成为关键 ------ 若未精心优化,极易成为瓶颈。
为充分利用 AMX 能力,我们主动将内存布局与 AMX tile 寄存器对齐:模型加载时,专家权重矩阵被预处理为兼容 AMX 的子矩阵,避免推理时耗时的转置或重塑操作;tile 按 64 字节缓存行对齐,优化缓存效率和预取性能。
我们对 Int8 和 Int4 格式采用对称分组线性量化,共享缩放因子单独存储以保持对齐;Int4 tile 被打包为 Int8 大小的块,并通过 SIMD 内置函数解包,确保开销最小。
3.2.2 缓存友好的 AMX 内核
基于优化的内存布局,我们的 AMX 内核充分利用 CPU 缓存层级。批处理矩阵乘法的执行步骤如下(图 6):
- 专家权重矩阵被动态划分为多个任务并调度至不同线程,输入激活通常驻留在共享 L3 缓存中;
- 每个任务将专家权重水平划分为恰好适配 L2 缓存的块;3-4. 每个块由 AMX tile 大小的子矩阵组成,输入和权重分别从 L3 缓存和 DRAM 加载至 L2 缓存(仅加载一次);
- 基于 tile 的计算通过 AMX 指令完成,结果直接在 tile 寄存器中累加,必要时将中间输出缓冲在 L1 缓存中。
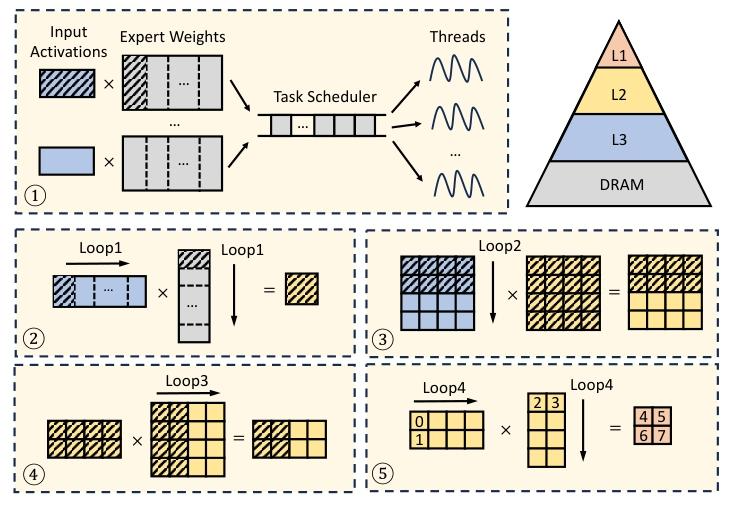
Figure 6. Execution process of KTransformers's AMX kernel.
该设计通过优化缓存输入、权重和中间结果,最大限度减少 DRAM 流量;动态任务调度优先调度针对同一专家的任务,进一步提升缓存利用率。如图 3 所示,我们的 AMX 内核在单插槽 CPU 上可达 21.3 TFLOPS,相比厂商优化的 oneDNN-based PyTorch 基线提升 3.98 倍。
3.2.3 低 ARI 场景的自适应 AVX-512 内核
尽管 AMX 在稠密计算中表现优异,但在低算术强度(ARI)场景(如解码阶段的向量 - 矩阵乘法)中效率低下 ------AMX 处理完整 tile 会引入过多开销。
为此,我们开发了与 AMX 内存布局完全兼容的轻量级 AVX-512 内核:该内核执行流程与 AMX 内核类似,但在低 ARI 计算时将 AMX 指令替换为更细粒度的 AVX-512 指令。微基准测试(通过调整每个专家的 token 数改变 ARI,图 7)显示,当每个专家的 token 数≤4 时,AVX-512 性能持续优于 AMX。因此,我们的混合方案根据 ARI 动态切换 AVX-512 和 AMX 内核:相比纯 AMX,解码阶段速度提升最高 1.20 倍;相比纯 AVX-512,预填充阶段速度提升最高 10.81 倍。
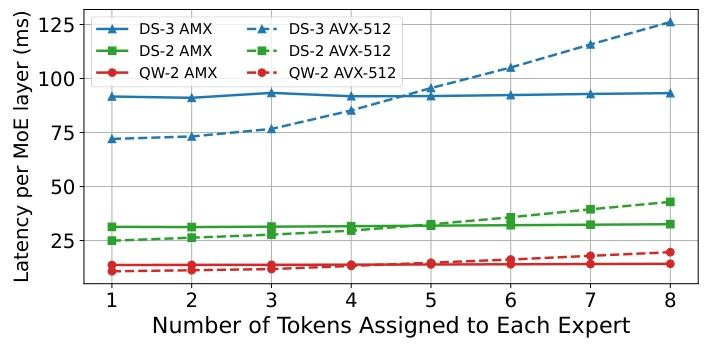
Figure 7. Microbenchmark results comparing the latency of the MoE layers across different models using KTransformers 's AMX kernel and AVX-512 kernel.
注:对比 KTransformers AMX 内核与 AVX-512 内核在不同模型 MoE 层的延迟。
3.2.4 融合 MoE 算子
基于上述内核,我们进一步通过算子级融合优化性能:MoE 层包含多个小型矩阵乘法(门控、上投影、下投影),导致频繁的同步开销。我们将跨专家的门控投影合并为一个更大的任务,同理独立融合上投影和下投影,并在无数据依赖的情况下合并门控与上投影。最终,MoE 执行被简化为两个融合批次,大幅降低线程开销。
此外,我们引入动态任务调度解决负载不均衡问题(尤其是预填充阶段专家激活不均的场景):与静态调度不同,动态调度将大任务拆分为更小的顺序子任务并放入轻量级任务队列,CPU 线程动态获取任务,显著减少负载失衡并最大化资源利用率。实验结果表明,动态调度使预填充阶段性能提升最高 1.83 倍。
3.3 CPU-GPU/CPU 协同
混合硬件上的低延迟 MoE 解码依赖 CPU 与 GPU 的流畅交互,以及 NUMA 架构的均衡利用。KTransformers 引入两项技术解决这些需求:异步 CPU-GPU 调度器和 NUMA 感知张量并行。
3.3.1 异步 CPU-GPU 任务调度机制
KTransformers 将共享专家部署在 GPU,路由专家部署在 CPU。GPU 的门控网络完成计算后,即可确定每个 token 对应的路由专家;随后,CPU 控制线程执行两项操作:(1)将路由专家任务推入无锁队列;(2)启动共享专家的 GPU 内核。后台工作线程并行执行队列中的任务;当 GPU 内核完成后,控制线程等待剩余 CPU 任务完成,合并两类激活结果,再进入下一层计算。
朴素设计需在每个 MoE 层同步两次:一次是 GPU 将激活值发送至 CPU(提交),另一次是 CPU 返回结果(同步)。这些同步屏障会破坏 CUDA Graph,并增加内核启动开销。为隐藏屏障开销,KTransformers 将提交和同步操作封装在 cudaLaunchHostFunc 中 ------ 该函数允许 CUDA 在当前流中调用回调函数。此时,单个 token 的整个解码路径可放入单个 CUDA Graph,消除主机中断,解码速度提升最高 1.23 倍。
3.3.2 NUMA 感知张量并行
非统一内存访问(NUMA)架构给 MoE 推理带来性能挑战 ------ 远程内存访问惩罚极高。大规模云部署通常采用专家并行(EP):将整个专家子网络分配给单个计算节点(图 8a)。但该策略常导致部分插槽闲置、部分插槽饱和。
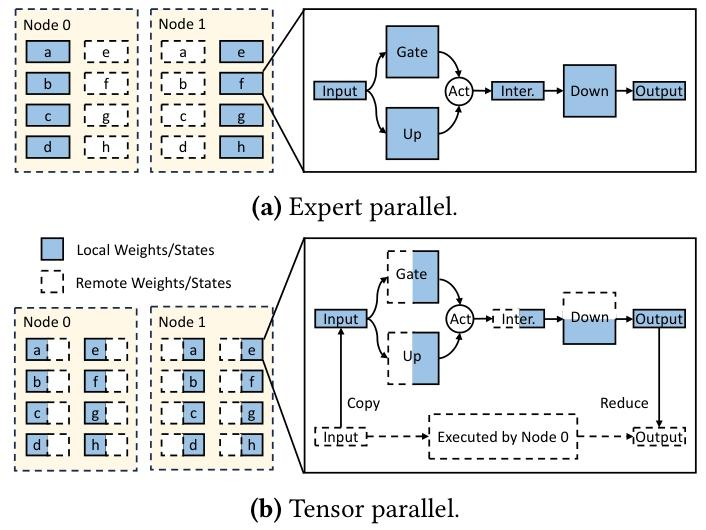
Figure 8. Workflow comparison between different parallel mechanisms.
(a) 专家并行;(b) 张量并行
KTransformers 则将每个专家的权重矩阵跨插槽分区(线性层按列 / 行分区):如图 8b 所示,每个插槽仅存储其分片,并执行本地计算;通过轻量级的 reduce-scatter 操作合并部分输出。该策略平衡负载,几乎消除所有远程内存流量,并随插槽数量扩展。在双插槽服务器上,相比将机器视为统一节点的 NUMA 无关基线,该策略使解码吞吐量提升最高 1.63 倍。
4 CPU-GPU 并行化
4.1 专家延迟机制
尽管 MoE 模型的稀疏结构天然适配 CPU/GPU 混合推理,但传统 Transformer 架构 44 的刚性计算序列严重限制了并行性。具体而言,注意力模块与 MoE 模块的交替执行常导致 CPU 停滞(CPU 需等待 GPU 端操作完成)。尽管 GPU 执行的共享专家可与 CPU 执行的路由专家部分并行,但它们对 GPU 负载的贡献极小 ------ 例如,在 DeepSeek-V3 中,共享专家仅占 GPU 执行时间的 18%(详见 4.2 节分析),并行执行带来的性能收益有限,导致硬件频繁闲置。
为克服路由专家与注意力层之间严格依赖导致的低效问题,我们提出一种全新的架构优化 ------ 专家延迟(Expert Deferral)。其核心思路是:现代 Transformer 模型因残差连接 16 具有对中间计算延迟的固有鲁棒性。与传统 MoE 层(第 k 层路由专家的输出直接输入第 k+1 层的注意力模块)不同,专家延迟机制策略性地将部分路由专家的输出延迟至第 k+2 层使用。该方法打破了专家计算与相邻注意力层之间的刚性依赖,实现更高的 CPU-GPU 并行度和硬件利用率。
我们根据输出使用时机,将路由专家分为两类:
- 即时专家(Immediate Experts):输出被下一层注意力模块立即使用,遵循标准 Transformer 流程;
- 延迟专家(Deferred Experts):输出被延迟,供后续层的注意力模块使用,以实现 CPU-GPU 并发执行。
图 9a 展示了传统 MoE 模型的工作流程:所有选中的路由专家(如 a、b、c、d)的输出直接输入下一层注意力模块;相比之下,图 9b 展示了专家延迟策略:第 k 层中路由得分最高的前 2 个专家(如 a、b)为即时专家,输出直接输入第 k+1 层;剩余 2 个专家(c、d)为延迟专家,输出延迟至第 k+2 层(红色粗箭头标注)。需注意的是,为保留关键信息,最后一层不应用专家延迟机制。
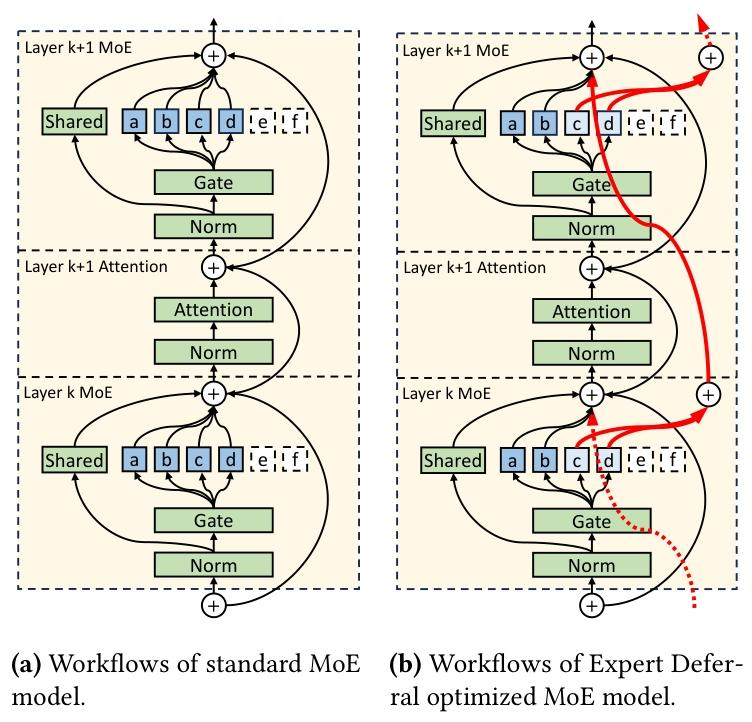
Figure 9. Workflow comparison between standard MoE model and Expert Deferral optimized MoE model.
(a) 标准 MoE 模型;(b) 专家延迟优化 MoE 模型
形式化定义:标准 MoE 模型中,第 k 层 MoE 模块的输出为:𝑂𝑘 = 𝐼𝑘 + 𝑆𝑘 (𝐼𝑘 ) + 𝑅all 𝑘 (𝐼𝑘 )
符号说明:
- L:模型中 MoE 层的总数;
- \(I_{k}\):第 k 层 MoE 模块的输入;
- \(O_{k}\):第 k 层 MoE 模块的输出;
- \(S_{k}(\cdot)\):第 k 层共享专家的计算;
- \(R_{k}^{imm}(\cdot)\):第 k 层即时专家的计算;
- \(R_{k}^{def}(\cdot)\):第 k 层延迟专家的计算;
- \(R_{k}^{all }(\cdot)\):第 k 层所有路由专家的计算(无延迟)。
引入专家延迟机制后,第 k 层 MoE 模块的输出定义为:
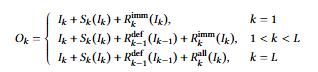
这一调整使 GPU 端操作(如注意力计算、门控、激活值传输)能与 CPU 端延迟专家的计算有效并行,大幅减少 CPU 闲置时间。此外,得益于 Transformer 架构固有的残差连接,延迟专家的输出仍能有效贡献于后续层计算,保持模型的表达能力和性能。因此,延迟部分专家计算以极小的模型行为变化为代价,提升了调度灵活性。
实证结果(详见 6.3 节)证实,专家延迟机制显著提升推理吞吐量,且精度基本保持。但需注意,该机制仅应用于解码阶段,而非预填充阶段:我们观察到,预填充阶段批次中的 token 通常选择多样化的专家,导致即时和延迟类别几乎覆盖所有专家 ------ 这会使内存访问足迹近乎翻倍,成为新的瓶颈,抵消并行化带来的收益;相反,解码阶段逐 token 处理,专家延迟机制能有效消除依赖,且无显著开销。
4.2 确定延迟专家数量
为优化配置专家延迟机制,我们在 6.1 节所述条件下,对 DeepSeek-V3 单一层采用 BF16 精度开展全面的性能分析。图 10 展示了执行时间线分析:初始无专家延迟时,CPU 利用率为 74%,GPU 利用率仅 28%,CPU-GPU 并行时间仅占总执行时间的 5%;此外,同步和激活值传输还导致 3% 的闲置时间 ------ 凸显硬件利用率极低。

Figure 10. CPU and GPU execution timelines under different Expert Deferral configurations in the MoE layer.
我们测试了延迟 2、3、4 个路由专家对吞吐量和硬件利用率的影响:
- 延迟 2 个专家:CPU 完成 6 个即时专家后,GPU 注意力计算立即启动,实现 CPU-GPU 并行,执行时间减少 19%;但延迟专家过早完成计算,导致 CPU 闲置;
- 延迟 3 个专家:延迟专家的计算可与下一层即时专家的处理启动阶段并发完成,CPU 达到完全饱和。这一最优配置消除了闲置周期,单层执行时间减少 26%,端到端解码吞吐量提升 33%;
- 延迟 4 个专家:因 CPU 已饱和,无额外吞吐量收益。
基于上述分析,我们确定了平衡的专家延迟配置:每层 5 个即时专家 + 3 个延迟专家。从分析中推导的通用启发式规则为:对于其他 MoE 模型,延迟最少数量的专家以实现 CPU 完全饱和,且每层至少保留 2 个即时专家以维持模型稳定性和精度。
5 灵活的模块注入框架
前文介绍了 KTransformers 为加速 MoE 模型推理所做的优化,涵盖从高度调优的计算内核到精细的层放置和并行化策略。在实践中,将这些技术集成到现有推理栈中既困难又耗时,阻碍了系统的进一步演进。为解决这一问题,KTransformers 直接基于 HuggingFace Transformers 构建,新增轻量级注入框架 ------ 将标准 PyTorch 模块替换为硬件专用的高性能实现。整个过程由单个 YAML 文件驱动,研究人员只需几行配置,即可组合新内核和放置策略。
具体而言,KTransformers 暴露用 C++ 编写并通过 pybind11 34 导出到 Python 的计算内核。这些内核被封装为普通 PyTorch 模块,可替代任何现有模块;单个 YAML 文件协调替换过程:文件包含多个 "匹配子句"(通过正则表达式名称匹配、类匹配或两者结合识别目标模块)和 "替换子句"(指定新类、执行设备及内核所需的关键字参数)。初始化时,框架遍历模型树;当模块满足匹配子句时,替换为对应替换子句指定的模块,并递归遍历新子模块。该过程轻量级,除构建阶段外无运行时开销,且保持 HuggingFace 公共接口不变。
例如,清单 1 展示了适配 Int4 量化 DeepSeek-V3 模型的简洁 YAML 配置:
- (第 1-9 行)通过类匹配,将所有 DeepseekV3MoE 实例替换为优化的自定义 FusedMoE 模块 ------ 该模块封装了与 CPU 后端的异步通信;通过关键字参数配置混合 AMX-AVX512 计算内核、对专家权重应用 Int4 量化,并启用 6 个延迟专家的专家延迟策略;
- (第 11-15 行)通过名称匹配,将自注意力模块替换为 FlashInferMLA 模块,以利用 FlashInfer 的高性能 CUDA 内核(支持矩阵吸收优化)高效计算 DeepSeek 的多头潜在注意力(MLA);
- (第 17-24 行)通过类和名称组合匹配,将所有 torch.nn.Linear 实现的线性投影(排除输出投影 lm_head)替换为 MarlinLinear 模块 ------ 这些模块在 CUDA 设备上执行,并采用 Int4 量化。
清单 1 适配 DeepSeek-V3 的配置示例
yaml
- match:
class: modeling_deepseek_v3.DeepseekV3MoE
replace:
class: operators.experts.FusedMoE
device: "cpu"
kwargs:
backend: "hybrid_AMX_AVX512"
data_type: "Int4"
n_deferred_experts: 6
- match:
name: "^model\\.layers\\..*\\.self_attn$"
replace:
class: operators.attention.FlashInferMLA
device: "cuda:0"
- match:
name: "^(?!lm_head$).*"
class: torch.nn.Linear
replace:
class: operators.linear.MarlinLinear
device: "cuda:0"
kwargs:
data_type: "Int4"上述注入框架大幅减少了适配不同模型的重复工作:对于 DeepSeek-V2 等相关模型,只需更新清单 1 第 2 行的模型类名即可实现无缝集成。除该示例外,注入框架还具备高度灵活性 ------ 通过简单编辑 YAML 文件,可精细控制模型行为,包括支持多 GPU 流水线、混合精度推理、KV 缓存卸载等技术,并为未来集成更多高级优化策略奠定基础。
通过将优化逻辑与模型代码分离,KTransformers 将定制化工程工作转化为简单配置。研究人员无需修改框架内部代码,即可快速原型验证新内核或放置策略、与现有方案组合,并评估端到端性能。这一能力既保证了终端用户的易用性,又降低了未来系统迭代的门槛 ------ 我们认为这对现代 LLM 研究的快速迭代至关重要。
6 评估
6.1 实验设置
6.1.1 硬件
所有实验在双插槽机器上进行:每个插槽配备 1 颗 Intel (R) Xeon (R) Platinum 8452Y 处理器(36 物理核),搭配 1TB DDR5 内存。通过 Intel MLC 22 测量,插槽内内存带宽为 220 GB/s,跨插槽内存带宽为 125 GB/s。机器配置两类 GPU:服务器级 NVIDIA A100(40GB 显存)和消费级 NVIDIA RTX 4080(16GB 显存);两类 GPU 均通过 PCIe 4.0 连接至 CPU,理论峰值带宽为 32 GB/s。
6.1.2 模型
我们在三款当前主流的开源混合专家(MoE)模型上评估系统:DeepSeek-V3-0324 7(DS-3)、DeepSeek-V2.5-1210 6(DS-2)和 Qwen2-57B-A14B 50(QW-2)。这些模型在架构和规模上各具特色,覆盖了多样化的 MoE 配置。表 1 总结了关键特征:对于每个模型,在 A100 上部署全精度(BF16/FP16)版本,在 RTX 4080 上部署 GPU 显存可容纳的最高精度量化版本(DS-3 量化为 Int4,DS-2 和 QW-2 量化为 Int8)。
表 1 所评估 MoE 模型的配置
| 模型 | DS-3 | DS-2 | QW-2 |
|---|---|---|---|
| 总参数量 | 6710 亿 | 2360 亿 | 570 亿 |
| GPU 参数量 | 170 亿 | 130 亿 | 80 亿 |
| CPU 参数量 | 6540 亿 | 2230 亿 | 490 亿 |
| MoE 层数 | 58 | 59 | 28 |
| 每层路由专家数 | 256 | 160 | 64 |
| 路由策略 | Top-8 | Top-6 | Top-8 |
6.1.3 负载
为评估性能,我们采用 Wikitext 语料库 28 作为输入提示词;所有实验批次大小设为 1(代表最典型的本地部署场景)。预填充性能评估中,提示词长度从 32 变化至 8192 token;解码性能评估中,提示词长度固定为 32 token,生成输出最大限制为 512 token。性能指标方面,预填充和解码阶段均报告吞吐量(token / 秒)。
为评估专家延迟机制对模型精度的影响,我们选择以下基准测试:
- 代码生成:HumanEval 3(0-shot)、MBPP 2(3-shot);
- 数学与常识推理:GSM8K 4(8-shot)、StrategyQA 15(4-shot);
- 针对 DS-3,额外在更具挑战性的 LiveBench 数据集 46(2024-11-25 最新版本)上评估,涵盖编码、数据分析、指令遵循、语言、数学、推理等子类别。
由于 HumanEval 和所有 LiveBench 子类别包含不超过 200 个问题,我们设置温度 t=0.3,并执行 10 次采样以获得更稳健的评估结果;其他基准测试采用贪心解码。遵循标准评估实践:HumanEval 和 MBPP 报告 pass@1,GSM8K 和 StrategyQA 报告精确匹配(EM),LiveBench 报告 avg@10。
6.1.4 基线
我们将 KTransformers 与两类主流基线对比:
- Fiddler 24:基于 PyTorch 的 CPU/GPU 混合服务系统;
- Llama.cpp 14:基于 C++ 的高性能框架,支持异构执行。
全精度推理时,KTransformers 和 Fiddler 运行 BF16 模型;由于 Llama.cpp 缺乏 BF16 CUDA 内核,改用 FP16 模型替代。此外,我们对比 KTransformers 和 Llama.cpp 在量化模型上的性能,使用 Llama.cpp 内置的量化功能。
两类基线均采用 Fiddler 风格的卸载策略:路由专家在 CPU 执行,其余计算在 GPU 执行。由于 Llama.cpp 原生仅支持逐层卸载,无专家级卸载能力,为保证公平对比,我们扩展 Llama.cpp 代码以实现与 Fiddler 类似的专家级卸载。
6.2 端到端性能
图 11 和图 12 分别展示了 KTransformers 与两类基线在预填充和解码阶段的吞吐量性能。
预填充阶段:短提示词场景下,Llama.cpp 因更优的算子融合策略性能优于 Fiddler;长提示词场景下,Fiddler 因 oneDNN 后端更好地利用 AMX 指令,性能反超 Llama.cpp。但无论提示词长度如何,KTransformers 在预填充阶段均持续优于两类基线 ------ 这主要得益于针对先进 CPU 指令优化的内核,以及 CPU 与 GPU 资源的协同优化。具体而言,如图 3 所示,KTransformers 的 CPU MoE 内核在 DS-3 上达到 21.3 TFLOPS,相比 PyTorch 实现提升 3.98 倍;这些提升源于 3.2 节详述的全面优化(6.4 节将进一步拆解)。
解码阶段:
- 全精度模型:无专家延迟的 KTransformers 相比 Fiddler 速度提升 2.42~4.09 倍,相比 Llama.cpp 提升 1.25~1.76 倍。性能提升不仅源于优化内核,还得益于 CUDA Graph 的高级应用 ------ 将 GPU 调用开销从超过 20%(图 4)降至近乎为零;
- 量化模型:KTransformers 相比 Llama.cpp 优势更显著,速度提升 1.77~1.93 倍。这主要归因于 CPU 和 GPU 内核执行时间大幅降低,放大了同步策略的效果。
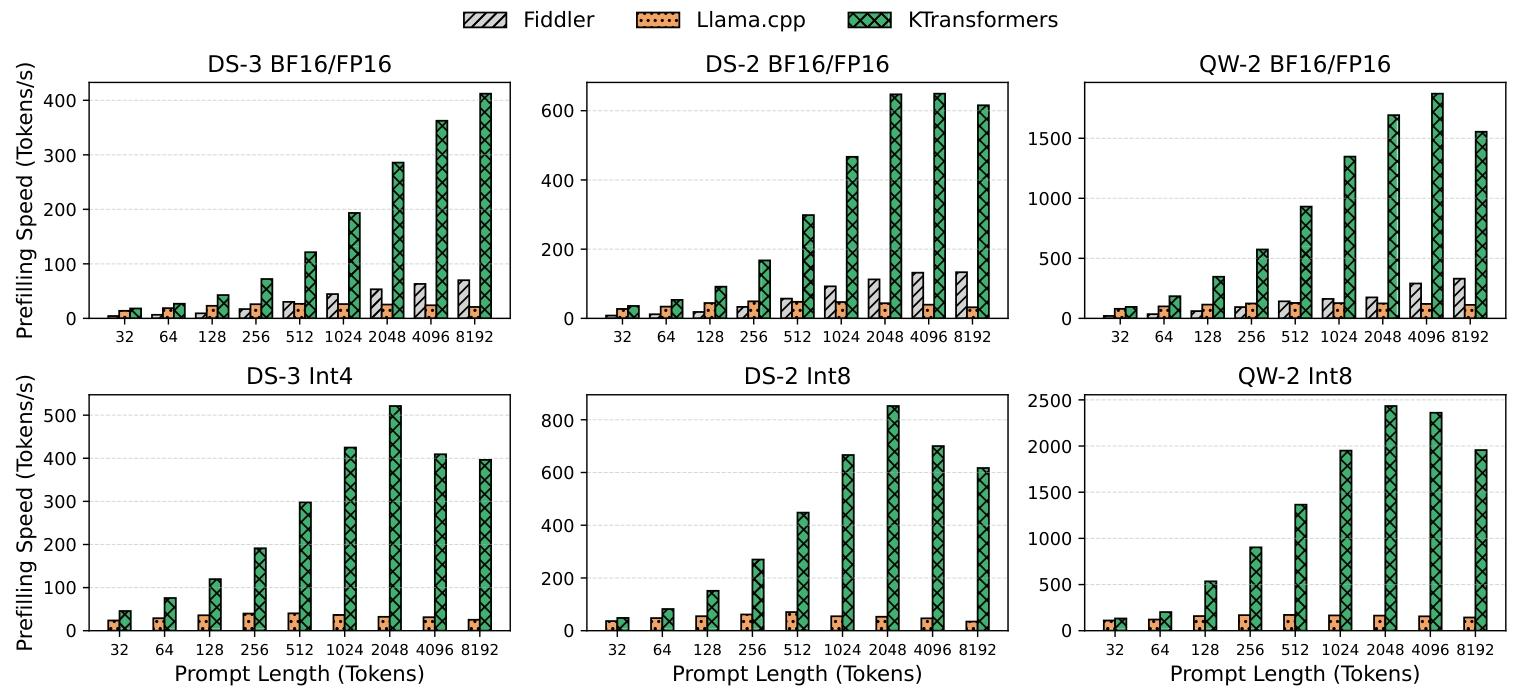
Figure 11. Comparison of prefilling speed between KTransformers and the state-of-the-art baselines.
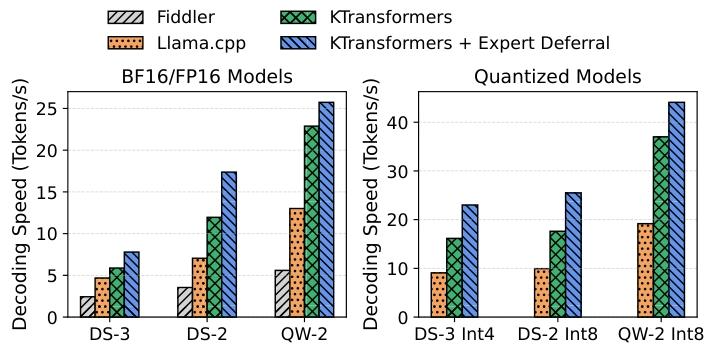
Figure 12. Comparison of decoding speed between KTransformers and the state-of-the-art baselines.
6.3 专家延迟机制
我们进一步评估专家延迟机制的影响:对于所有模型,遵循 4.2 节的参数选择策略(延迟最少数量的专家以饱和 CPU 利用率,且每层至少保留 2 个即时专家以维持模型稳定性)。具体配置:
- DS-3:BF16 模型延迟 3 个专家,量化模型延迟 6 个专家;
- DS-2:BF16 和量化模型均延迟 4 个专家;
- QW-2:BF16 模型延迟 2 个专家,量化模型延迟 4 个专家。
如图 12 所示,引入专家延迟优化后,吞吐量额外提升最高 45%,相比 Llama.cpp 的整体速度提升达 1.66~2.56 倍 ------ 这主要源于 CPU 与 GPU 计算并行度的提升。
**表 2 不同模型在各类基准测试中的精度(有无专家延迟)**注:配置表示为(I+D),I 为即时专家数,D 为延迟专家数。例如(8+0)表示无专家延迟,(2+6)表示 2 个即时专家 + 6 个延迟专家。
| 模型 | HumanEval | MBPP | GSM8K | StrategyQA |
|---|---|---|---|---|
| DS-3 (8+0) | 83.0 | 71.2 | 94.8 | 83.0 |
| DS-3 (2+6) | 83.0 | 70.2 | 95.2 | 82.9 |
| DS-2 (6+0) | 80.5 | 67.6 | 93.3 | 79.7 |
| DS-2 (2+4) | 82.5 | 66.8 | 92.8 | 80.4 |
| QW-2 (8+0) | 65.7 | 52.4 | 84.7 | 83.6 |
| QW-2 (4+4) | 67.4 | 53.4 | 83.4 | 82.5 |
由于专家延迟机制通过在解码阶段选择性延迟部分专家计算,对 MoE 模型结构进行了调整,我们需验证该策略对模型精度的影响:
首先,在 HumanEval、MBPP、GSM8K、StrategyQA 上评估三款模型(表 2):专家延迟仅导致精度微小波动,分数或小幅提升或下降(幅度不超过 2 分)。
其次,在 LiveBench 上评估 DS-3,并对比专家延迟与简单的 "专家跳过" 策略(直接丢弃路由得分最低的专家,而非在后续层合并其计算)。如图 13 所示,在影响专家数量相同的情况下,专家延迟在多数场景下性能优于专家跳过;尤其是默认配置(6 个受影响专家)下,专家延迟的平均精度损失仅 0.5%,而专家跳过达 13.3%。关键的是,当延迟专家的计算与 GPU 执行完全并行时,其开销极小,因此能实现与专家跳过相当的速度提升。这些结果表明,专家延迟机制以极小的精度损失为代价,实现了显著的解码速度提升。
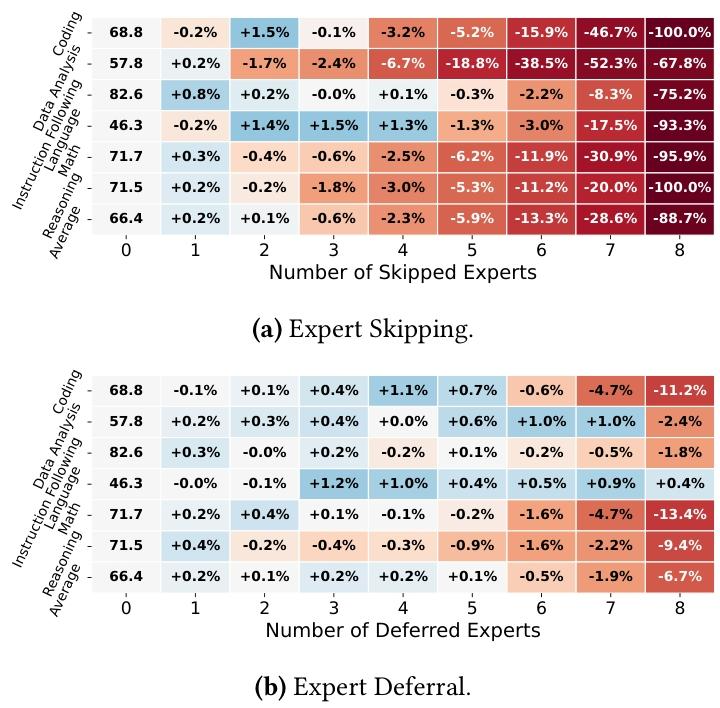
Figure 13. DS-3 accuracy on LiveBench under (a) Expert Skipping, which discards the lowest-scoring experts, and (b) Expert Deferral, which delays their computation. The first column shows the baseline scores (no experts affected); other columns report relative accuracy changes (%) with varying numbers of affected experts.
(a) 专家跳过(丢弃得分最低的专家);(b) 专家延迟(延迟专家计算)注:第一列为基线分数(无专家受影响);其他列报告不同受影响专家数量下的相对精度变化(%)。
6.4 性能拆解
为深入理解 KTransformers 优化带来的收益,我们对各类优化的性能提升进行详细拆解:评估所有模型的 BF16 版本(预填充阶段提示词长度 8192,解码阶段固定配置),从基于 PyTorch 的 Fiddler 基线出发,逐步融合本文提出的各项系统优化,归一化加速比如图 14 所示。
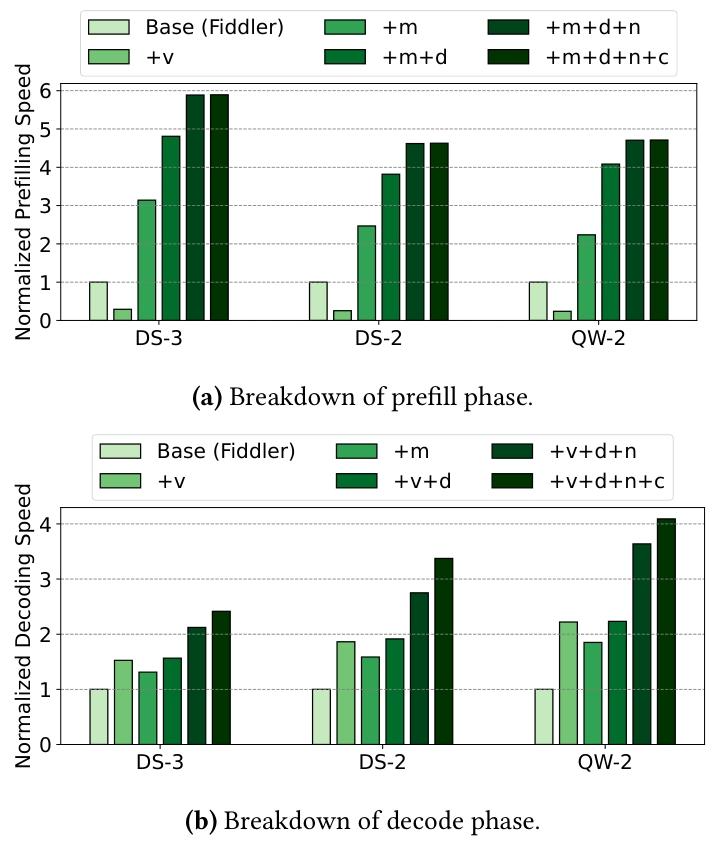
Figure 14. Normalized speed compared to Fiddler baseline, and the optimizations include the following abbreviations: v - MoE kernel with the AVX-512 instruction set, m - MoE kernel with the AMX instruction set, d - dynamic work scheduling, n - NUMA-aware tensor parallelism, c - CUDA Graph.
(a) 预填充阶段拆解;(b) 解码阶段拆解注:v - 基于 AVX-512 指令集的 MoE 内核;m - 基于 AMX 指令集的 MoE 内核;d - 动态任务调度;n - NUMA 感知张量并行;c - CUDA Graph。
第一轮优化:将 PyTorch 基线 MoE 模块替换为基于 AVX-512/AMX 指令集的两个融合 MoE 内核。预填充阶段,AVX-512 内核性能低于基线,而 AMX 内核提速显著(最高 3.14 倍)------ 这是因为 AVX-512 指令在计算密集型负载中效率低于 AMX;相反,解码阶段两类内核均优于基线,但 AVX-512 内核效率更高(相比基线提速最高 2.22 倍)------ 这是因为 AVX-512 指令在轻量级向量 - 矩阵乘法中延迟更低。
在预填充阶段使用 AMX 指令、解码阶段使用 AVX-512 指令的基础上,我们进一步引入降低开销的优化:
- 动态任务调度:预填充阶段收益更显著(提速最高 1.83 倍),解码阶段影响极小。原因是预填充阶段专家选择高度不均衡(部分线程分配到极重的任务),动态调度有效平衡负载;而解码阶段任务负载更均衡,动态调度收益有限;
- NUMA 感知张量并行:解码阶段影响显著(提速最高 1.63 倍),预填充阶段提速最高 1.22 倍。原因是解码阶段更受内存带宽限制,该优化避免了低效的跨 NUMA 内存访问。
最后,引入 CUDA Graph 优化:该优化对预填充阶段影响轻微(CUDA 启动开销被大量 token 分摊);但对解码阶段提升显著(提速最高 1.23 倍)。
7 相关工作
7.1 资源受限场景下的 MoE 模型推理
对 LLM 服务的需求增长推动了众多优化推理框架的发展 1,19,26,33,35,56,58。尽管这些框架主要为高吞吐量数据中心环境设计,但其对多台高端 GPU 服务器的依赖使其无法适用于资源受限的私有和边缘计算场景。部分方案(如 Llama.cpp 14、PowerInfer 38,49 和 Specexec 39)试图通过权重卸载技术,在消费级 GPU 上部署 LLM。但它们主要聚焦于稠密模型,未考虑 MoE 的特有属性,导致大尺度 MoE 模型服务性能下降。近期的系统 10,17,20,37,40,48,52 专为 MoE 模型推理优化,按需重新加载激活的专家。Fiddler 24 进一步推进该设计,通过卸载计算消除了专家重新加载带来的 PCIe 瓶颈。然而,这些方案因缺乏先进 CPU 指令利用、NUMA 感知架构设计等关键优化,性能仍不及 KTransformers。
7.2 MoE 模型量化
模型量化 9,12,13,45,55 将模型压缩至更低精度(如 BF16 至 Int8/Int4),降低内存需求并加速推理。Llama.cpp 14 等框架提供更通用的开箱即用量化方案(如 Int2、Int3、Int5)。量化技术被广泛用于 MoE 模型部署:MoQE 25 发现专家权重对量化的敏感度低于模型其他部分,可将专家参数激进量化至 Int2;部分研究探索更细粒度的精度选择 ------ 例如,EdgeMoE 52 通过离线分析专家的相对重要性和量化敏感度,为每个专家静态选择精度;MPTQS 21 和 HOBBIT 40 等方法存储不同精度的专家版本,并根据上下文信号动态选择运行时精度。这些方法与 KTransformers 正交,均可集成到 KTransformers 框架中。
7.3 自适应门控
另一类研究通过自适应门控减少每 token 激活的专家数量,降低推理成本:不再使用固定的 top-k 门控策略,而是为每个 token 和每层动态确定激活的专家数量。例如,NAEE 27 和 AdapMoE 57 基于门控得分分布设计启发式规则;MC-MoE 18 将注意力得分纳入决策过程。受 "不同 token 推理难度不同" 这一洞察启发,Ada-K 53 训练基于强化学习的分类器,预测每个 token 的最优激活专家数。尽管这些方法加速了推理,但专家信息的损失可能损害模型性能,需在效率与精度间谨慎权衡。相比之下,KTransformers 的专家延迟机制利用残差网络特性加速异构推理,精度损失远低于这类方法。
8 结论
本文提出 KTransformers------ 一款支持大尺度 MoE 模型在混合 CPU/GPU 平台上高效本地推理的系统。通过结合 AMX 优化内核、异步调度和专家延迟策略,KTransformers 最大化硬件利用率,吞吐量提升 1.66~19.74 倍。这些优化大幅缓解了 CPU 操作、内核启动开销、跨 NUMA 内存传输等长期存在的瓶颈。借助 KTransformers,资源受限的本地设备如今可部署超大 MoE 模型,为 LLM 的安全、透明、高性价比部署铺平了道路。