Markdown碎片处理
在大模型SSE流式输出的时候,往往返回的是Markdown字符串。其他类型比如 # * -等,实时渲染的时候抖动是比较小的,但是像图片链接、表格、块级数学公式在渲染的时候往往会造成剧烈的页面抖动,用户体验不友好。接下来我们就一一这三个场景。
不完整图片链接
md
//完整图片链接

//不完整图片链接

处理这种不完整的链接我们可以直接正则匹配替换掉不完整的图片链接为空,等链接完整后再做渲染
js
/**
* 处理图片流式碎片
* @param {string} markdown - 原始 Markdown 字符串
* @returns {string} 清理后的 Markdown 字符串
*/
function stripBrokenImages(md) {
if(typeof(md) !== 'string') {
console.log('%c v3-markdown-stream:请传正确的md字符串~ ','background:#ea2039;color:#ffffff;padding:2px 5px;')
return '';
}
if(!md) {
return '';
}
md = md.replace(
/^\s*\[([^\]]+)\]:[ \t]*(\S+)(?:[ \t]+(["'])(?:(?!\3)[\s\S])*?)?$/gm,
(s, id, src, quote) => {
// 如果捕获到开启引号却没闭合,或者 src 后直接换行(缺引号),都认为不完整
if (quote && !s.endsWith(quote)) return ""; // 引号没闭合
if (!quote && /["']$/.test(src)) return ""; // src 结尾多余引号,也视为异常
return s; // 完整定义,保留
}
);
md = md.replace(
/!\[([^\]]*)\]\(([^)]*(?:\([^)]*\)[^)]*)*)\)/g,
(s, alt, body) => {
const open = (body.match(/\(/g) || []).length;
const close = (body.match(/\)/g) || []).length;
if (open !== close) return ""; // 括号不匹配 → 不完整
if (body.includes('"') && (body.match(/"/g) || []).length % 2) return "";
if (body.includes("'") && (body.match(/'/g) || []).length % 2) return "";
return s; // 完整,保留
}
);
return md.replace(/!\[[^\]]*\]\([^)]*$/g, "");
}不完整表格字符串
md
//完整表格字符串
| 姓名 | 年龄 | 职业 |
|------|------|------|
| 张三 | 25 | 工程师 |
| 李四 | 30 | 设计师 |
| 王五 | 28 | 产品经理 |
//不完整表格字符串
| 姓名 | 年龄 | 职业 |
|------|-----渲染效果:
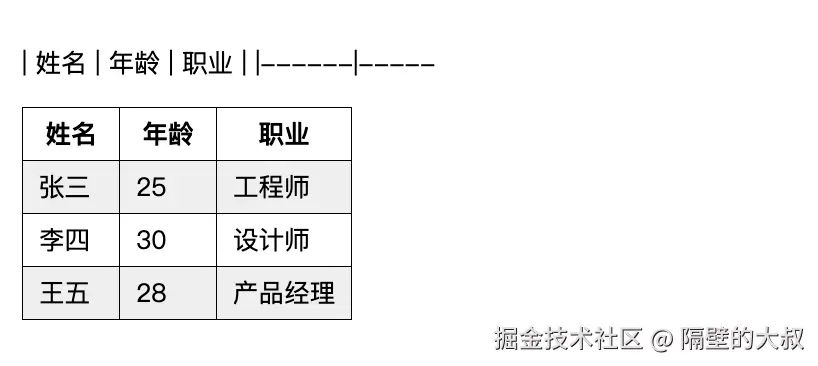
处理这种不完整的表格字符串,我们也可以使用正则替换掉不完整的表格字符串
注意:一旦分隔符和表头数量一致后就可以放行渲染,避免等待时间过长
js
/**
* 过滤流式输出中结构不完整的表格字符串
* @param {string} content - 流式输出的原始内容
* @returns {string} 过滤后的内容(仅保留合法表格,非法表格替换为空)
*/
function filterInvalidTables(content) {
// 表头加载完成后过滤
// const tableRegex = /(?:^\|(?:\s*.+?\s*)?\|?$[\n\r]?)+(?:^\|(?:\s*[-:]+)+(?:\s*\|\s*[-:]+)*\s*\|?$[\n\r]?)+(?:^\|(?:\s*.+?\s*)?\|?$[\n\r]?)*(?=\n|$)/gm;
//宽松模式过滤
const tableRegex = /^\|(?:\s*.+?\s*)?\|?$(?:\r?\n^\|(?:\s*[-:]+)+(?:\s*\|\s*[-:]+)*\s*\|?$(?:\r?\n^\|(?:\s*.+?\s*)?\|?$)*)?/gm;
return content.replace(tableRegex, (match) => {
// 分割表头行和分隔符行
const lines = match.trim().split(/[\r\n]+/).filter(line => line.trim());
if (lines.length < 2) return ''; // 至少需要表头行 + 分隔符行
// 最后一行表头(处理多行表头场景)
const headerLine = lines[0].trim();
// 分隔符行
const separatorLine = lines[1].trim();
// 提取表头列数:分割 | 后,过滤空字符串(处理前后 | 的情况)
const headerColumns = headerLine.split('|').map(col => col.trim()).filter(col => col);
const headerCount = headerColumns.length;
// 提取分隔符列数:分割 | 后,过滤空字符串,且必须包含至少1个 -
const separatorColumns = separatorLine.split('|')
.map(col => col.trim())
.filter(col => col && /-/.test(col)); // 分隔符必须包含 -
const separatorCount = separatorColumns.length;
// 仅当列数完全一致时保留表格,否则替换为空
return (headerCount === separatorCount && headerCount>0 && separatorCount>0) ? match : '';
});
}不完整的数学公式
md
//完整的数学公式
$$
\\frac{n!}{k!(n-k)!} = \\binom{n}{k}
$$
//不完整的数学公式
$$
\\frac{n!}{k!(n-k)!渲染效果:
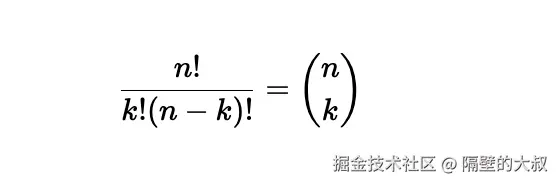

针对这种也可以使用正则替换不完整的代码块为空
js
/**
* 清除 Markdown 中未闭合的块级公式($$ 开头未闭合)
* @param {string} markdown - 原始 Markdown 字符串
* @returns {string} 处理后的 Markdown 字符串
*/
function clearUnclosedBlockMath(markdown) {
// 正则说明:
// 1. /\$\$(?!.*?\$\$).*$/s - 核心正则
// 2. \$\$ - 匹配块级公式开始标记
// 3. (?!.*?\$\$) - 正向否定预查:确保后面没有 $$ 闭合(非贪婪匹配任意字符)
// 4. .*$ - 匹配从 $$ 开始到字符串结束的所有内容
// 5. s 修饰符 - 让 . 匹配换行符(支持多行公式)
// 6. g 修饰符 - 全局匹配(处理多个未闭合公式的极端情况)
return markdown.replace(/\$\$(?!.*?\$\$).*$/gs, '');
}结语
正则在处理这种问题的时候,简单粗暴但有用,有点俄式美学的味道~ 最后,如果你觉得这个文章对你有帮助,不妨点个赞并分享给更多的开发者朋友,让我们一起让 Markdown 解析变得更简单、更强大!
GitHub源码仓库地址 如果觉得好用,欢迎给个Star ⭐️ 支持一下!