
|----------------|
| 你好,我是安然无虞。 |
文章目录
- LoadRunner简介
- 脚本录制方案和优化
- 脚本编写
-
- 脚本参数化
- 内置参数
-
- 1.LoadGN
- [2.User ID](#2.User ID)
- 3.table表格参数(重要)
- 4.file文件参数(重要)
- 5.迭代编号
- 6.日期时间
- 7.随机数字
- 8.唯一编号(重要)
- 9.xml参数
- 10.自定义参数(重要)
- 规则关联
- 事务定义
- 结果检查
- 脚本编写小结

LoadRunner简介
1.总体介绍
-
LoadRunner 是一种预测系统行为和性能的负载测试工具,通过模拟上千万用户来确认和查找问题 (
支持高并发) -
LoadRunner 能够对整个企业架构进行测试,能最大限度地缩短测试时间,加速应用系统的发布周期 (
便捷性) -
LoadRunner 可适用于各种体系架构的自动负载测试,能预测系统行为并评估系统性能 (
多协议)
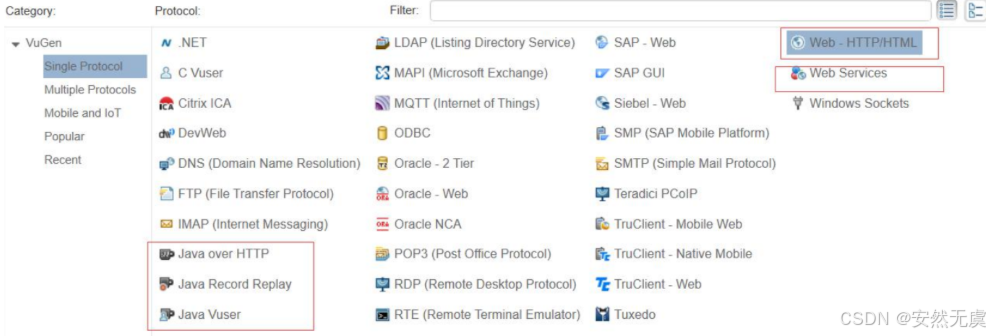
2.功能模块
1.VGenerator·虚拟用户生成器
-
虚拟用户生成器
-
该引擎能够生成虚拟用户, 以虚拟用户的方式模拟真实用户的业务操作行为.
-
录制脚本, 编写脚本 (脚本参数化、变量关联、业务优化), 调试脚本等.
2.Controller·负载控制器/调度器
-
负载控制器/调度器
-
按计划, 按目标来控制用户数量, 通过脚本组合设计负载场景和方案.
-
Controller 提供一个互动的环境, 在其中我们既能建立起持续且循环的负载, 又能管理和驱动负载测试方案.
-
LoadRunner 内含集成的实时监测器, 在负载测试过程的任何时候, 我们都可以观察到应用系统的运行性能.
3.Analysis·结果分析器
- 结果分析器
- 提供高级的分析和报告工具, 以便迅速查找到性能问题并追溯原由
4.压力机
- 在运行时可远程安装和管控的虚拟用户生成器
- 使用于大规模压测和大量用户负载, 可以安装多个
3.运行视图
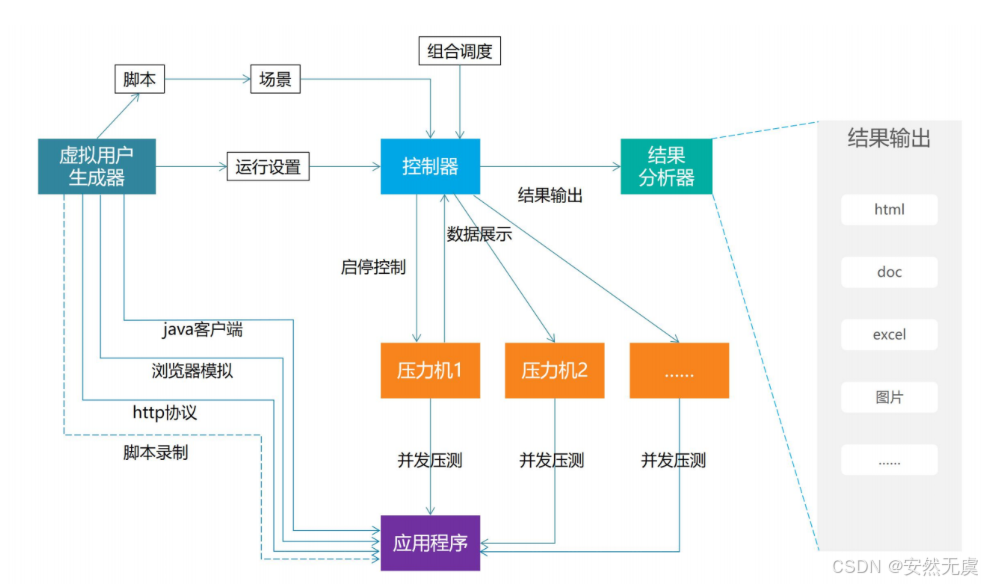
- 采用虚拟用户生成器进行脚本录制、脚本编写、脚本调试, 完成脚本的准备工作
- 通过脚本组合设计压测场景
- 调试压力机进行场景分布式压测
- 性能结果分析、图表分析
脚本录制方案和优化
脚本录制方案
脚本录制的意义:
- 能够将可视化操作转为脚本代码, 并且能够进行重复性的操作
- 简化操作, 大大降低工作量和难度
脚本录制方式有多种, 可以分为:
- 直接录制
- 只支持 IE,Microsoft Edge
- 本地代理录制
- 支持 IE,Microsoft Edge,Google Chrome,Mazilla Firefox
- 离线流量录制
- 几乎支持所有浏览器, 因为大部分浏览器支持转 har 文件
- 手动代理录制
- 几乎支持所有浏览器
- 第三方代理
- 采用 Fiddler 进行辅助生成脚本
1.直接录制
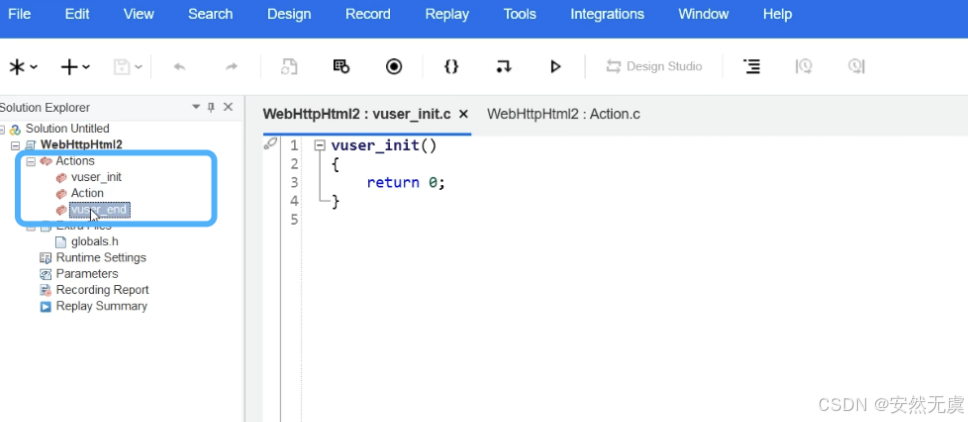
首先在 虚拟用户生成器 当中新建一个 解决方案和脚本:
其中:
- vuser_init: 初始化, 压测的时候只执行一次
- 比如登录
- Action: 动作, 压测的时候循环执行
- vuser_end: 结束, 压测的时候只执行一次
- 比如登出
OK, 现在我们进行 录制配置:
- 首先点击录制按钮
- 选择录制的行为
- 比如说是录制 初始化、动作还是结束
- 这里录制的是 动作
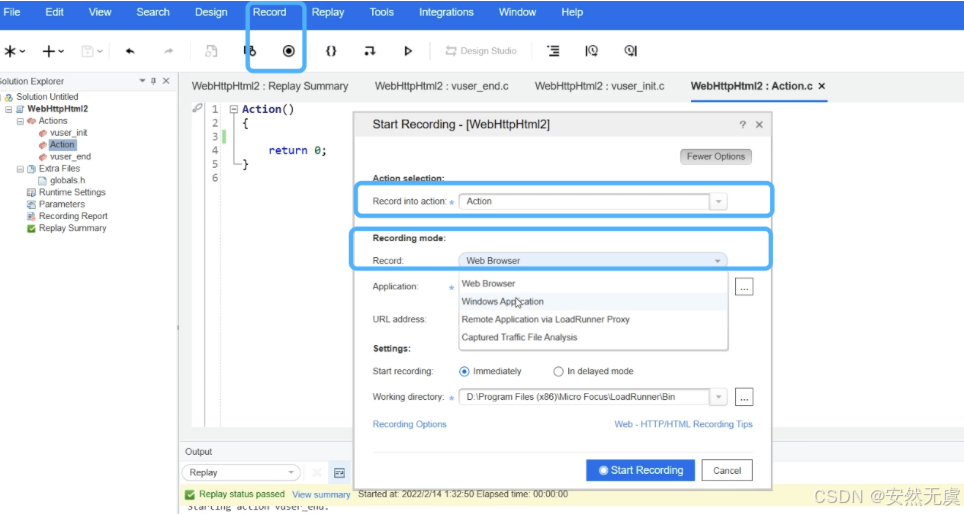
- 然后选择录制方式: 这里是 Web端的浏览器录制
- 选择对应的应用: 浏览器
- 输入目标URL网址
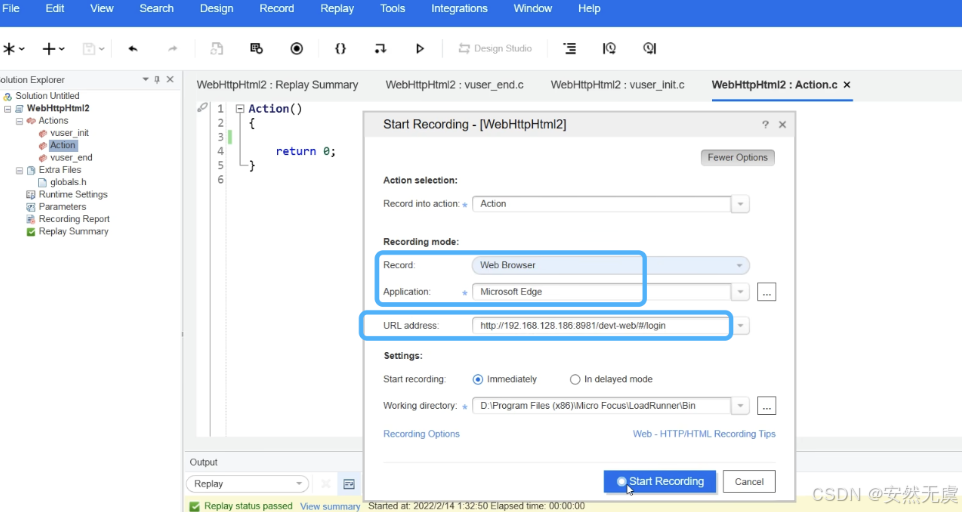
- 点击开始录制
2.本地代理录制
和前面一样, 首先在 虚拟用户生成器 中新建一个 解决方案和脚本, 接下来开始进行录制配置:
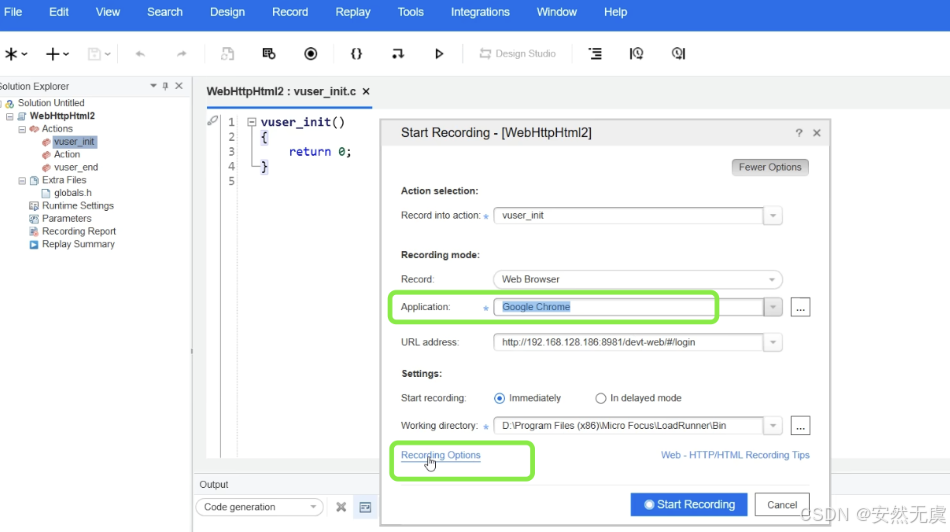
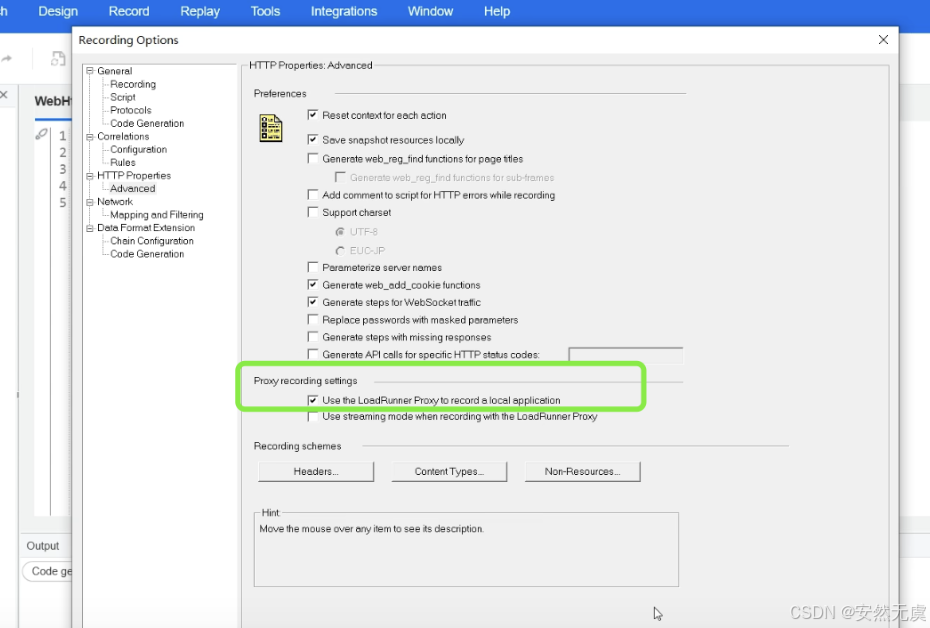
因为是 本地代理录制, 所以需要配置录制选项:
- 勾选代理配置选项
3.离线流量录制
这种方式比较简单, 直接使用浏览器的F12打开控制台, 然后保存HAR文件的方式 进行录制, 并不需要事先打开LoadRunner工具.
OK, 具体操作如下:
- 我们打开浏览器, 输入对应的网址
- 按F12打开控制台, 看到很多网络请求
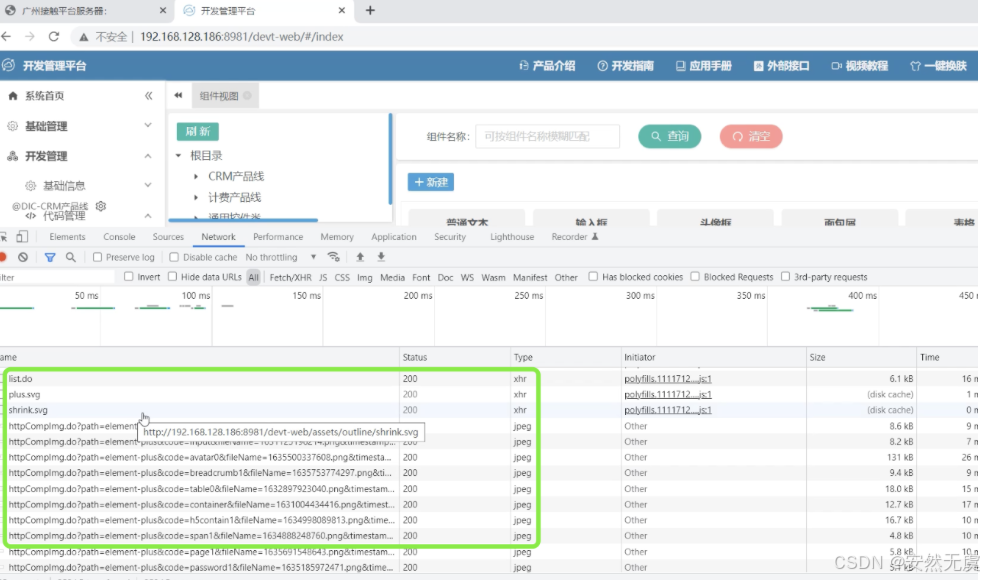
- 不用管, 我们再进行其他的操作
- 然后将所有的网络请求都保存为 HAR文件
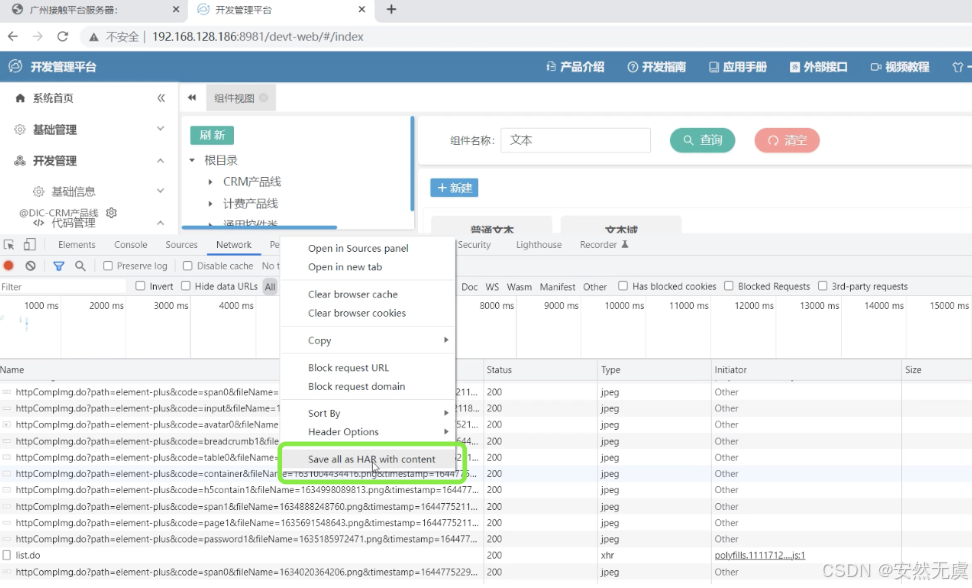
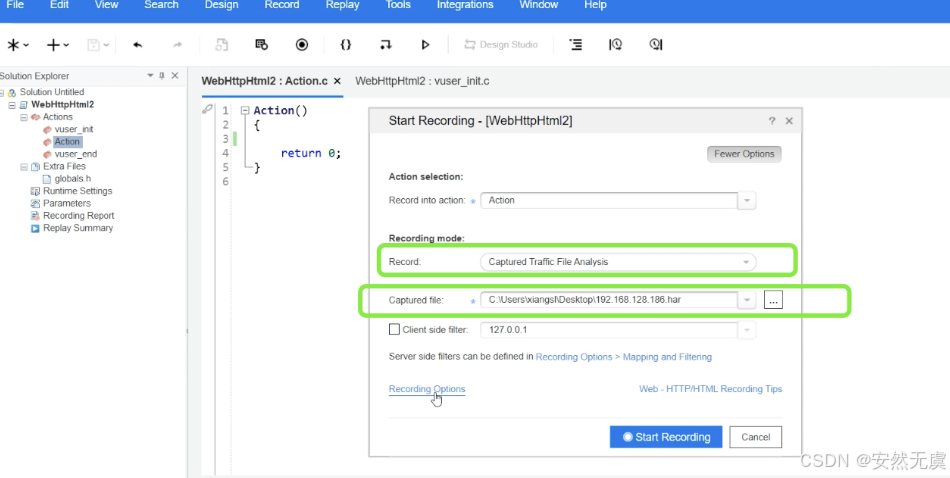
- 保存好HAR文件后, 打开LoadRunner工具
- 在LoadRunner中进行录制配置
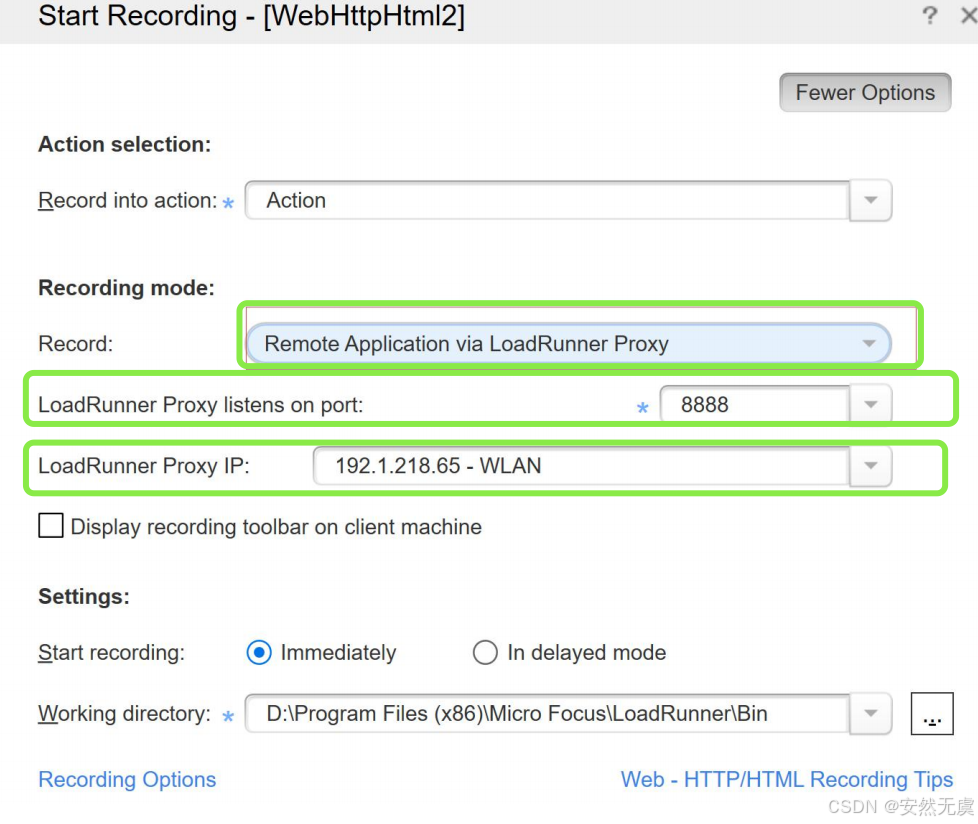
4.远程代理录制
录制方式选择 远程应用LoadRunner代理 模式, 选择监听端口和代理IP:
启动之后, 会在LoadRunner控制台上看到:
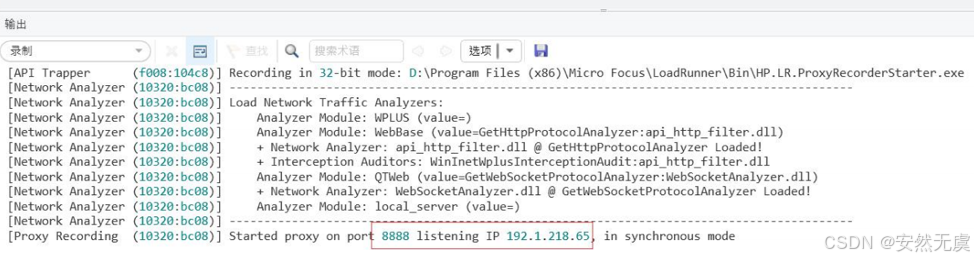
然后配置浏览器的代理服务器为对应的IP和端口:
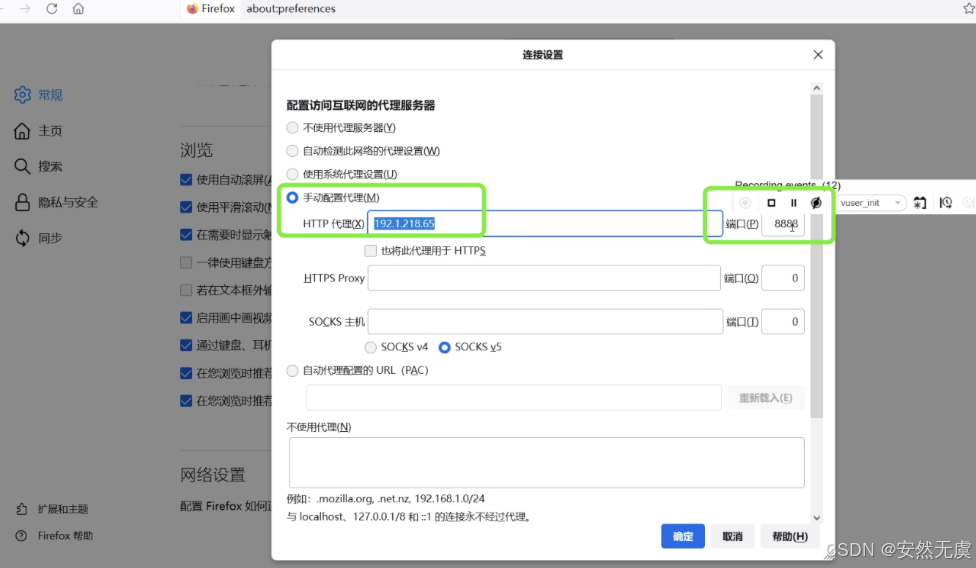
5.第三方代理
第三方代理需要 Fiddler 软件, 即采用 Fiddler 作为代理, 也能达到脚本录制的目的. Fiddler 提供代理地址, 能将所有的网络请求转化为 saz包, 再利用虚拟用户转化为 lr 脚本.
Fiddler不仅能抓取浏览器的 HTTP请求, 也可以抓取其他的进程, 比如 postman中发出的请求, 利用这个功能, 我们可以将请求转换为 lr 脚本.
Fiddler和浏览器一样, 具有离线流量保存的功能.
-
首先设置Fiddler过滤的请求 (这样可以只抓取特定的请求) 以及配置监听的端口
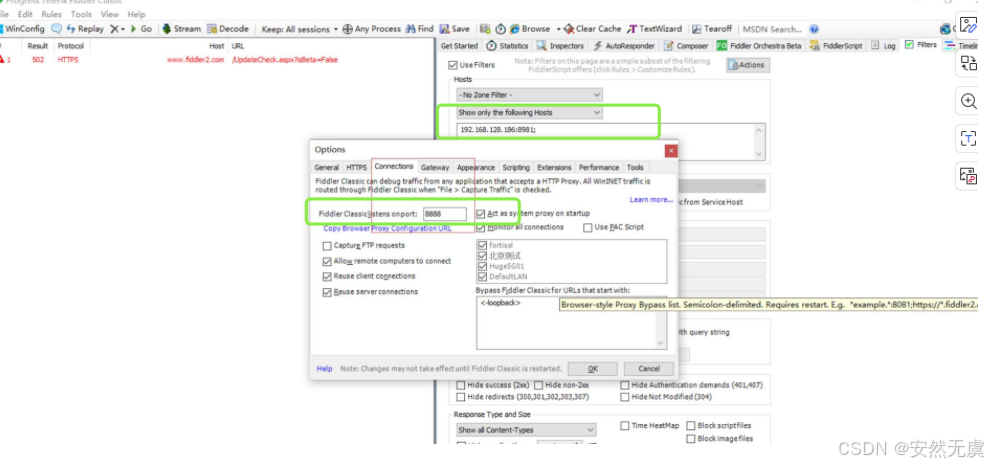
-
设置Fiddler能够捕获所有的HTTPS请求
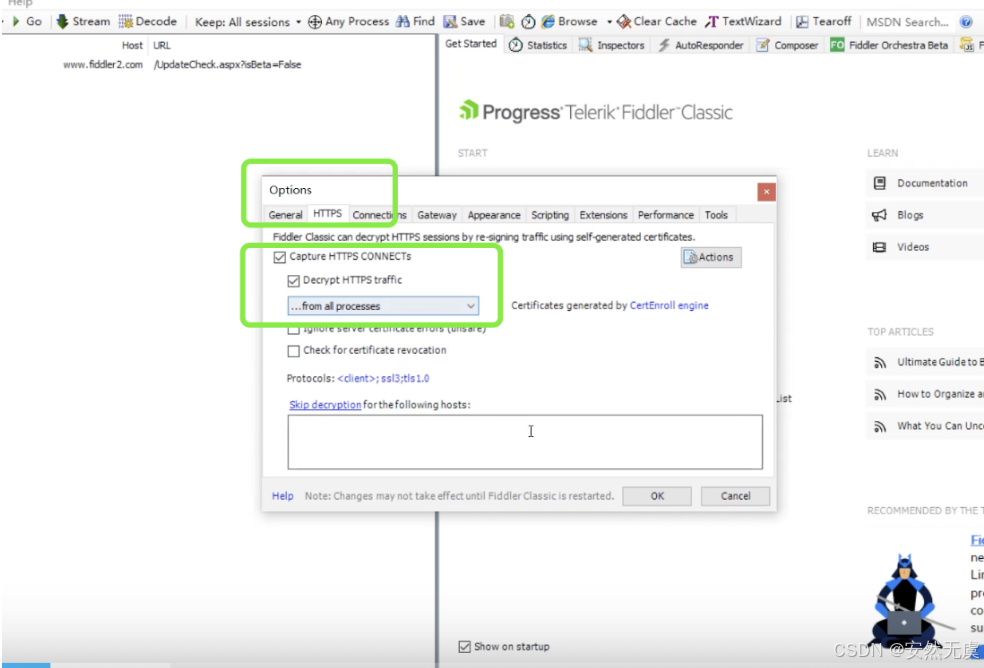
-
在浏览器中的操作被抓取下来后保存为 saz包
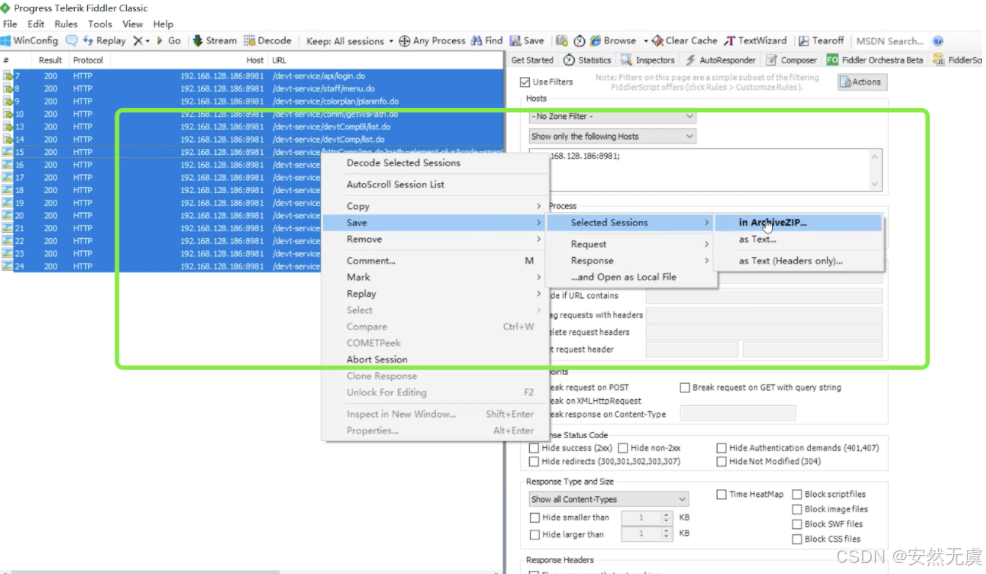
-
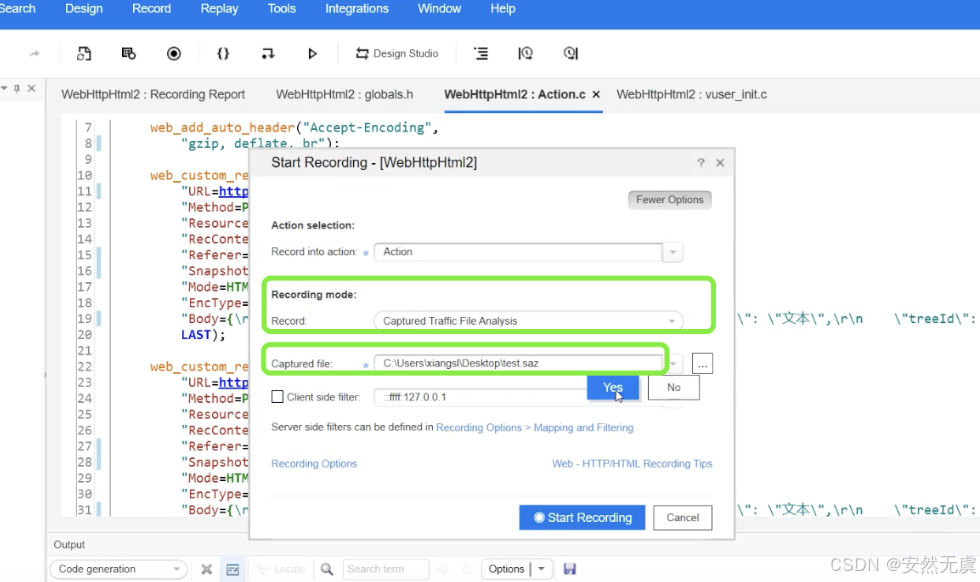
然后在LoadRunner中选择该文件解析成对应的脚本
脚本录制优化
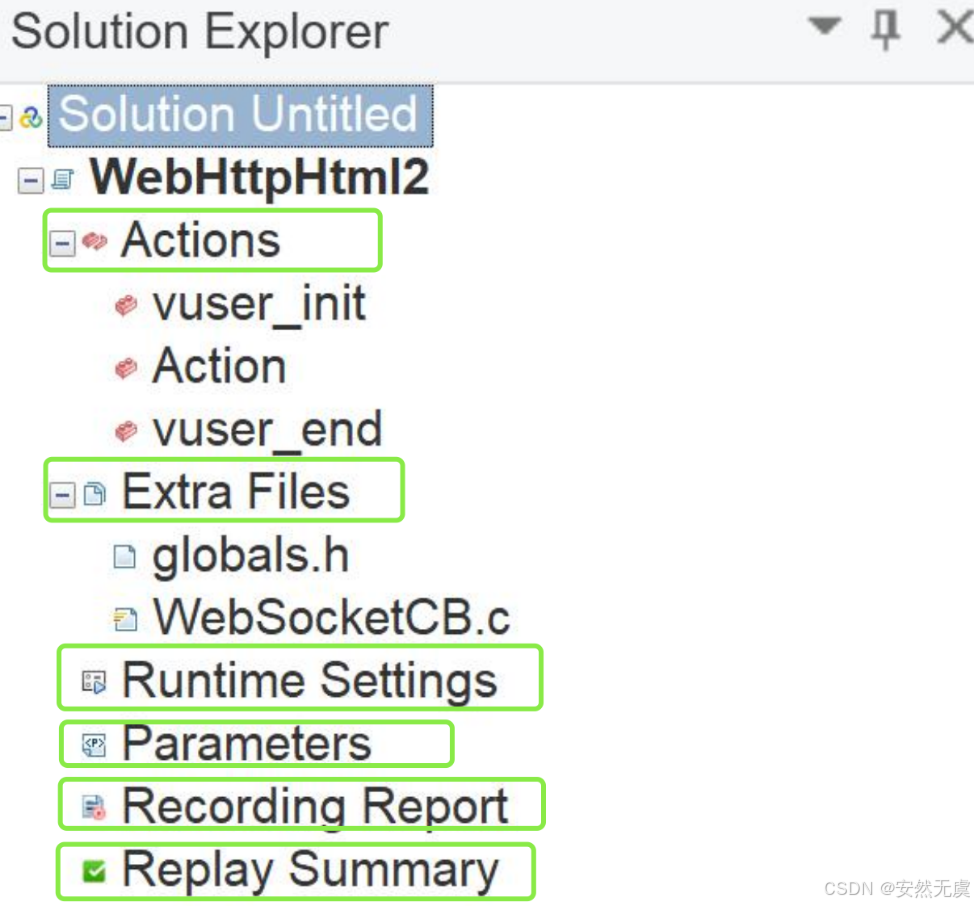
1.脚本结构认识
- Actions: 脚本区
- Extra Files: 头文件区
- Runtime Settings: 运行时设置
- Parameters: 参数设计
- Recording Report: 录制报告
- Replay Summary: 回放总结
脚本区的运行结果也是:
- vuser_init
- Action1
- Action2
- ...
- vuser_end
也就是先初始化, 再执行动作, 最后再执行结束动作.
2.录制报告优化
录制报告结果详解:
- 主机的过滤 (用来剔除掉脚本中不需要的请求)
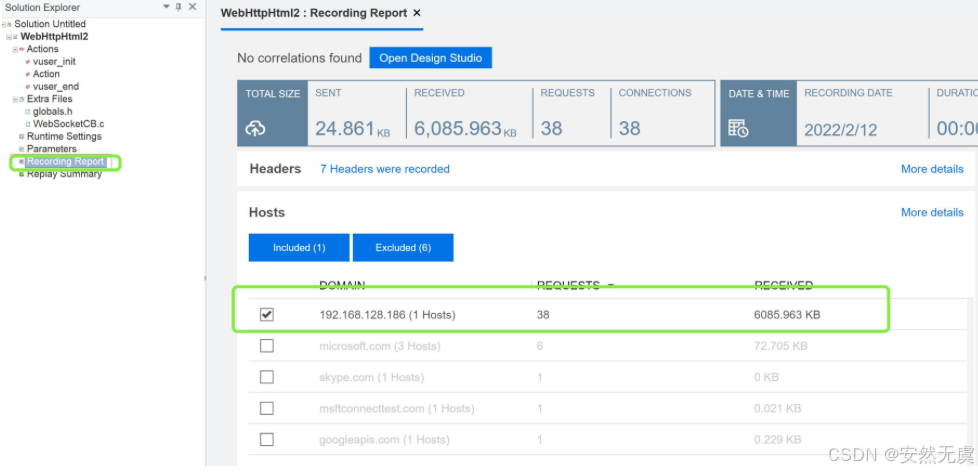
- 资源与非资源的区别 (如图片这些都属于静态资源)
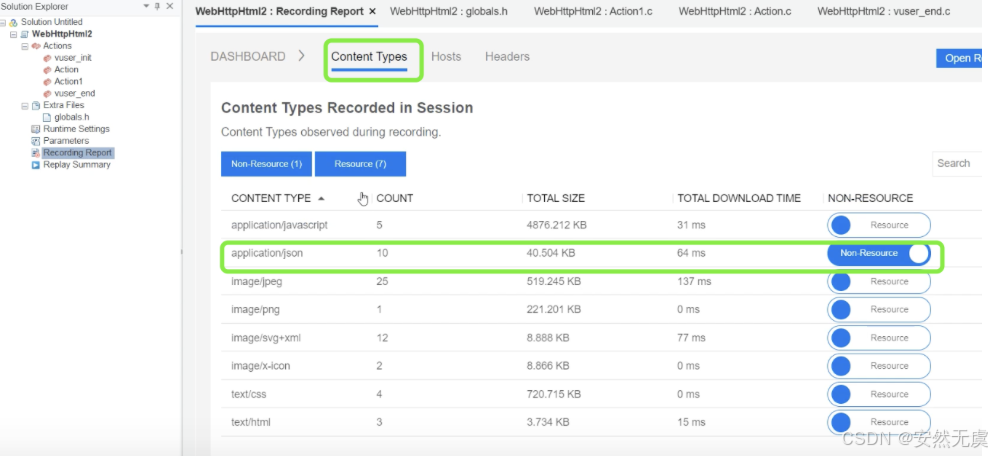
- 会话头部
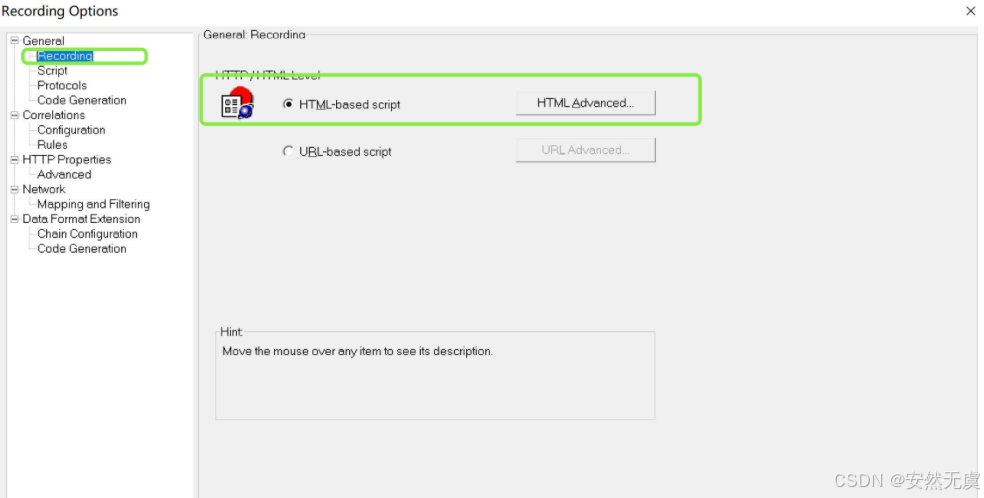
3.录制选项优化
- 选择基于 HTML脚本 (这样的好处是静态资源请求都被集中放到了一起)
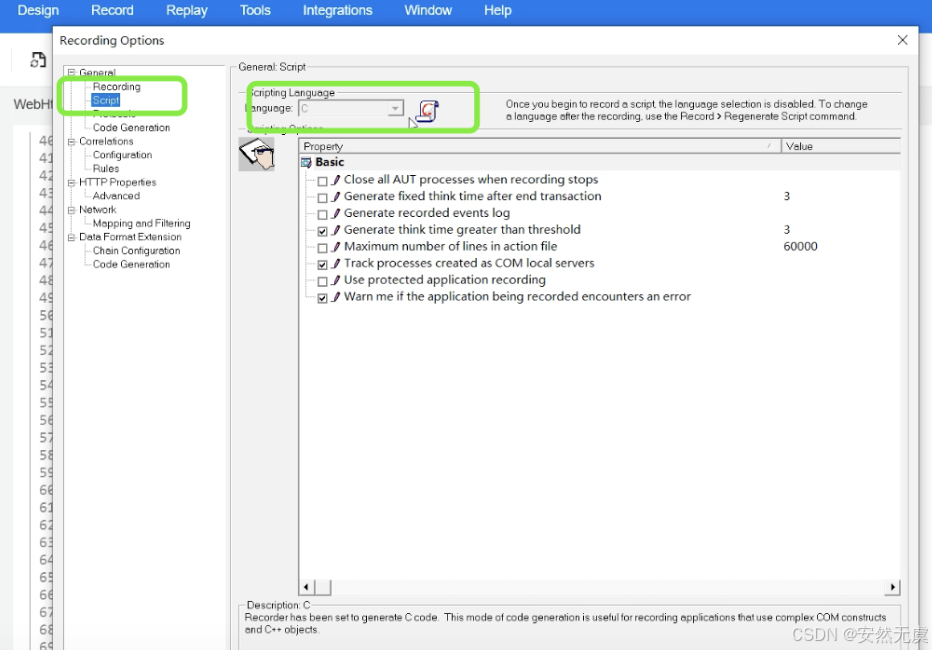
- 录制脚本语言有两种选择
- C语言
- JavaScript语言
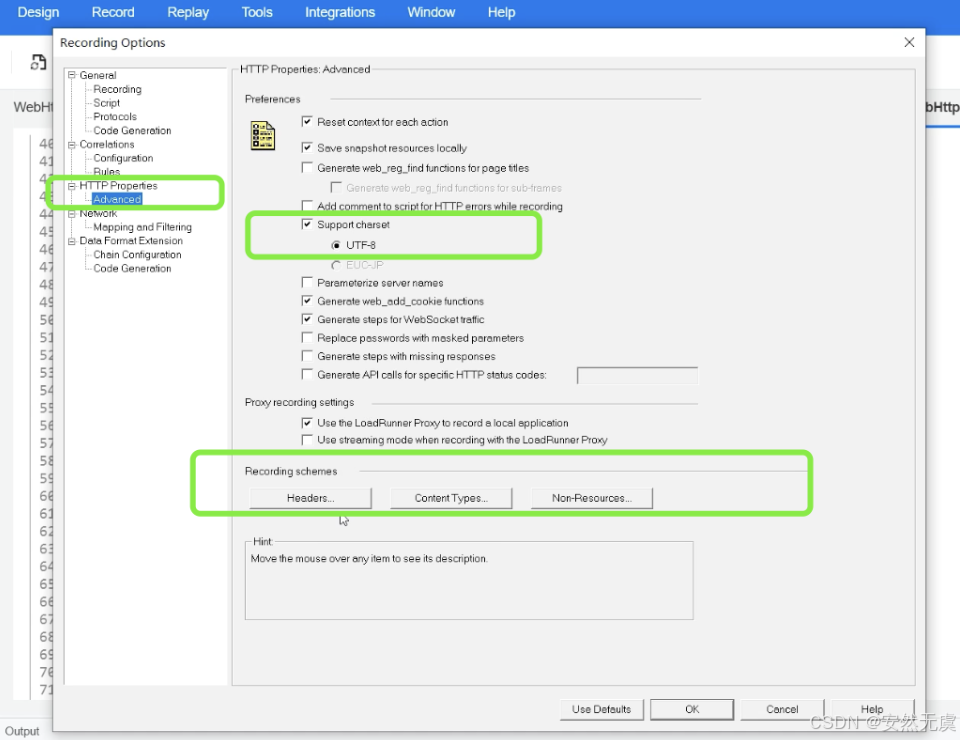
-
HTTP高级属性配置
- 编码选择utf-8 (支持中文)
- 录制方案中的 请求头、内容类型和资源与非资源设置
- 比如可以让脚本中的请求是否包含想要的请求头或者像图片这样的资源请求等等
4.脚本回放优化
单步回放与一键回放
脚本录制好了之后, 可以对该脚本进行回放, 脚本回放可以查看对应请求的响应结果.
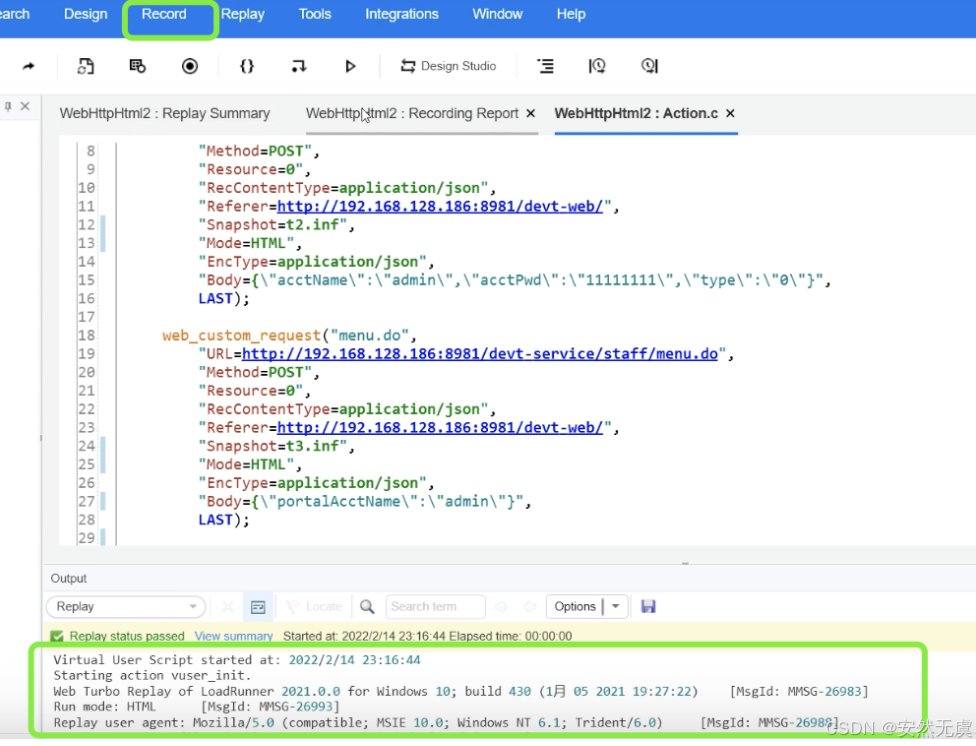
脚本回放时也可以选择单步和一键回放, 我们要学会采用回放日志的方式去解决问题, 以及熟悉压测业务逻辑.
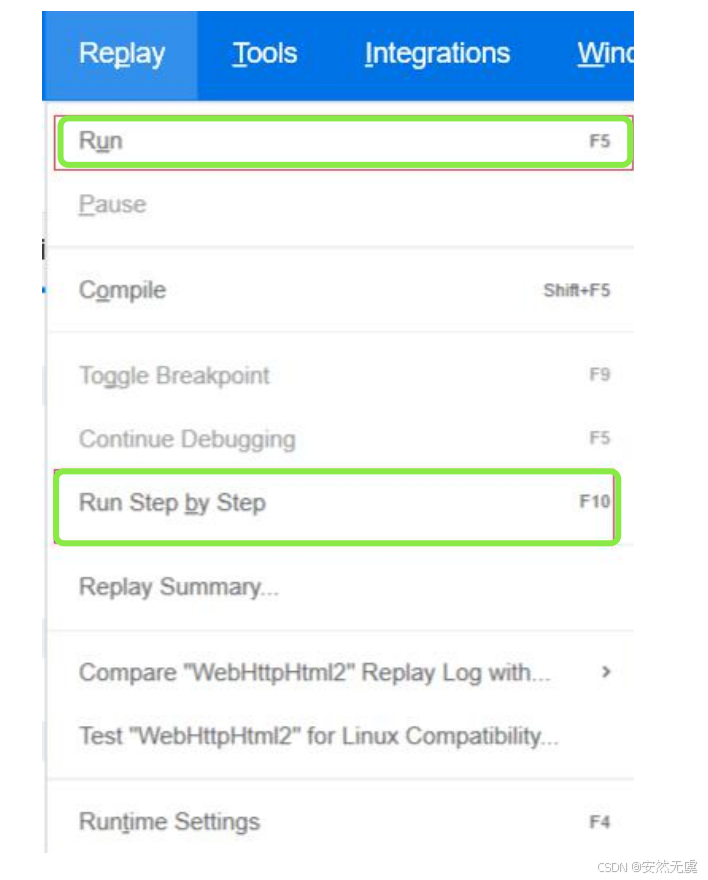
我们来看一下运行时设置 (Runtime Settings):
日志功能
关于日志: 我们在进行压测之前, 也就是在录制脚本调试脚本的阶段, 要按照下面的配置对日志功能进行设置, 在执行压测的时候把日志功能关闭, 这样的话不会影响磁盘性能.
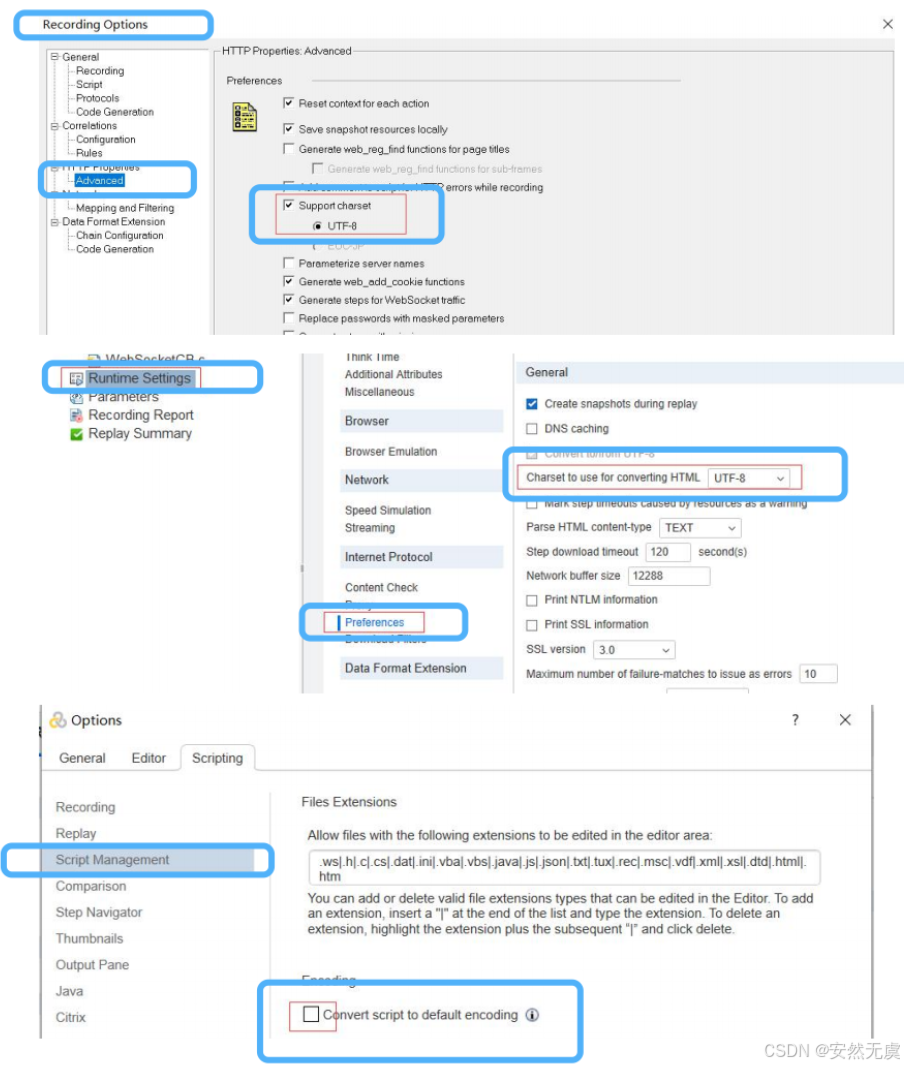
中文乱码解决
- 在录制选项中选择 utf-8
- 在回放选项中选择utf-8
- 在工具选项中将转换脚本编码去掉
脚本录制小结
-
进行脚本录制之前, 设置好编码, 以防中文乱码.
-
关于脚本录制:
脚本录制有多种方法, 看个人喜好, 一般我们倾向于
本地代理录制和离线流量录制. 录制过程中要对脚本进行基本的过滤和处理, 剔除一些无用的静态请求和业务上认为无关的请求, 让脚本最终处于最简洁的状态, 降低后续的难度. -
结构优化
针对录制好的脚本, 我们要进行结构整理, 设计好初始脚本、迭代脚本、退出脚本这三个最基本的环节, 针对复杂的脚本, 我们要将迭代部分进行逻辑分拆, 让其尽可能简化.
-
关于脚本回放:
录制好的脚本要记得进行回放, 并学会用回放日志分析业务, 进一步确认我们的脚本逻辑.
脚本编写
脚本参数化
在各种业务场景中, 我们将多个常量用统一的变量进行替换的过程称之为脚本参数化.
- 脚本参数化加强了代码的可读性, 非常方便地看出关联性
- 脚本参数化降低了测试代码的维护难度, 非常方便我们快速修改, 降低低级错误的发生
- 比如 主机、端口, 查询条件 以及 其他的业务数据, 可根据需要进行参数化

内置参数
在 LoadRunner 当中, 内置了很多不同类型的参数, 合理的采用会降低脚本的难度和提升脚本设计效率.
1.LoadGN
全称为 LoadGeneratorName, 该参数是以压力机名称为基础, 可按不同格式生成.
c
// 定义一个 LoadGeneratorName 参数
char* NewParam = lr_eval_string("{NewParam}");
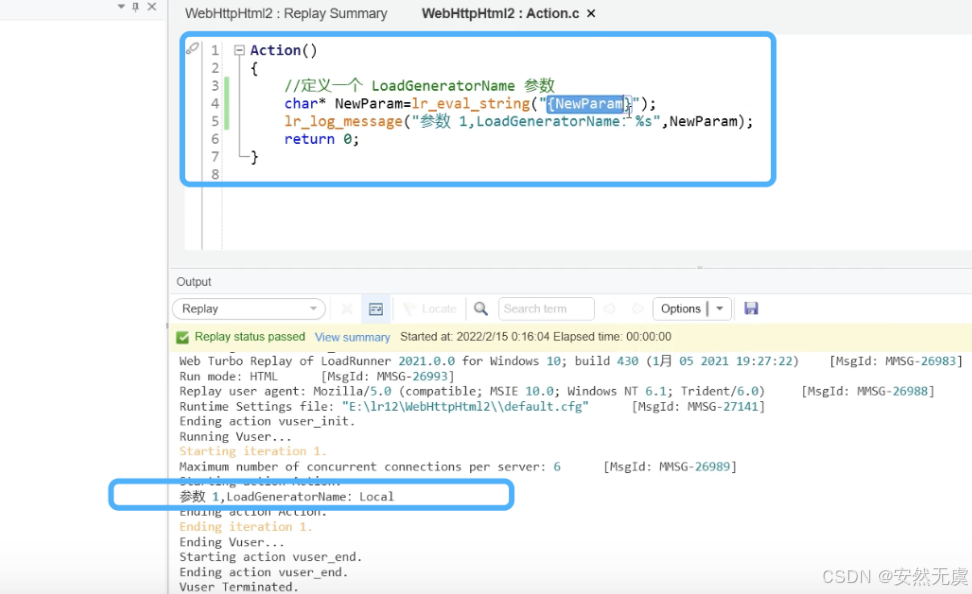
lr_log_message("参数1, LoadGeneratorName: %s", NewParam);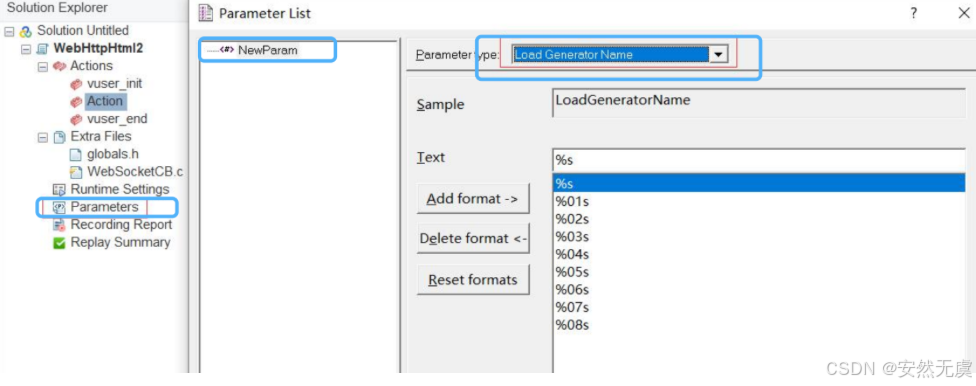
看看执行结果:
2.User ID
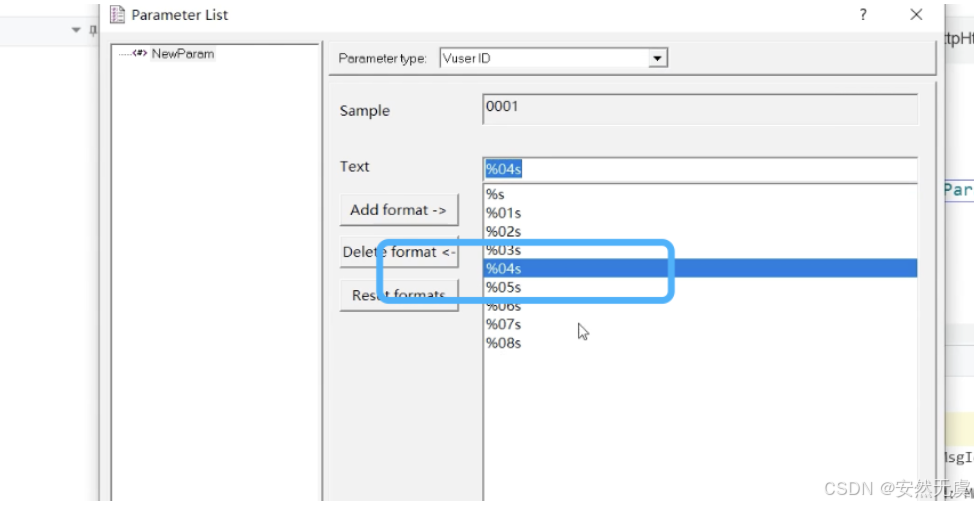
该参数是以虚拟用户的序号为基础, 可按不同格式生成.
c
// 定义一个 User ID 参数
char* NewParam = lr_eval_string("{NewParam}");
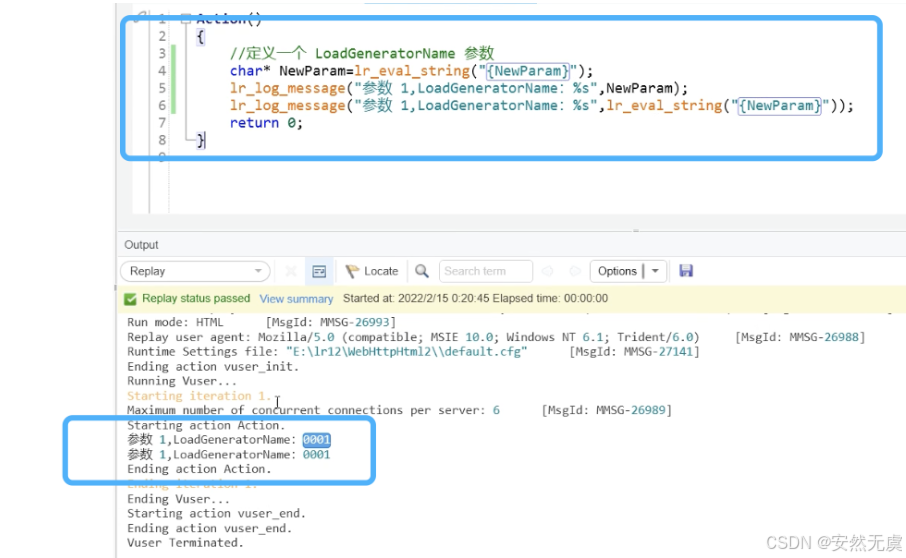
lr_log_message("参数1, User ID: %s", NewParam);比如这里生成长度为4的User ID:
看看执行结果(代码有误, get到意思即可):
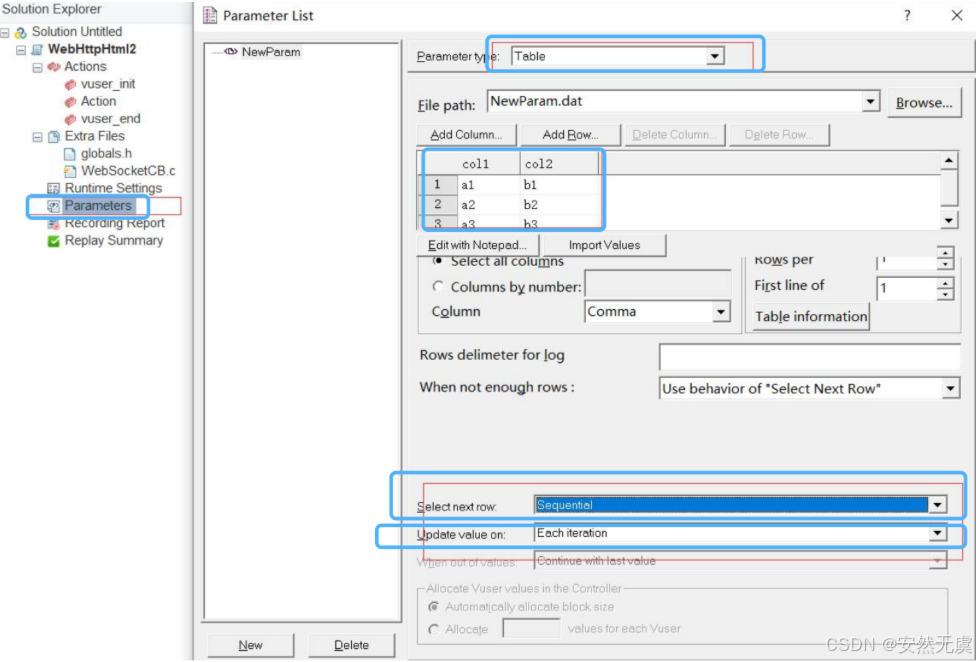
3.table表格参数(重要)
以表格中的行数据为基础生成的参数, 支持记事本编辑以及从CSV等文件中导入, 每一行各列之间的数据可以设置分隔符.
下面重点理解表格中取数的6中组合规则:
取 下一行 数据方法有三种:
- Sequential 顺序: 按照参数化的顺序一个一个的来取
- Random 随机: 参数化中的数据, 每次随机的从中选取数据
- Unique 唯一: 为每个虚拟用户分配一个唯一的一条数据
更新值的规则:
- Each iteration: 每一次迭代时更新
- Once: 运行场景中只更新一次
4.file文件参数(重要)
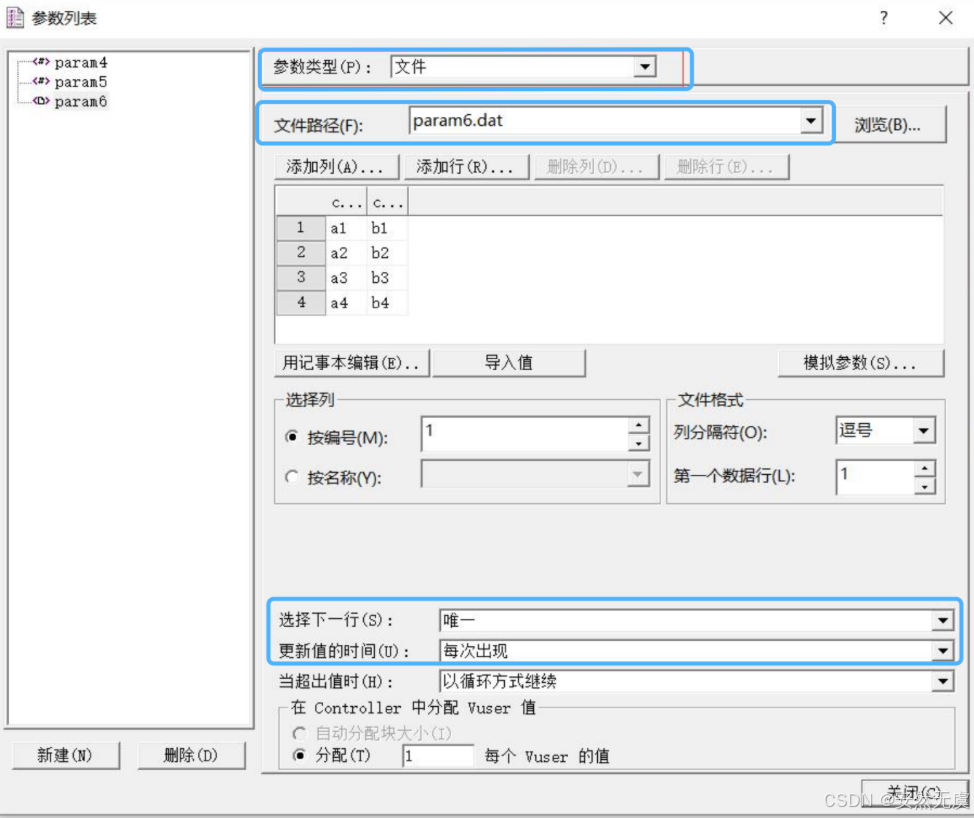
以文件为结构的参数, file参数可以有多列, 每次取一列.
下面重点理解文件取数的9种组合规则:
取 下一行 数据方法有三种:
- Sequential 顺序: 按照参数化的顺序一个一个的来取
- Random 随机: 参数化中的数据, 每次随机的从中选取数据
- Unique 唯一: 为每个虚拟用户分配一个唯一的一条数据
更新值的规则:
- Each iteration: 每一次迭代时更新
- Each occurrence: 每一次出现时更新
- Once: 运行场景中只更新一次
表格与文件参数的区别在于:
表格可以取整行数据, 文件一般只取一行中的一列数据
比如文件中的数据是这样的:

5.迭代编号
该参数是以运行逻辑的替代次数为基础, 可按不同格式生成.
c
// 定义一个迭代编号参数
char* NewParam = le_eval_string("{NewParam}");
lr_log_message("参数1, 迭代编号参数: %s", NewParam);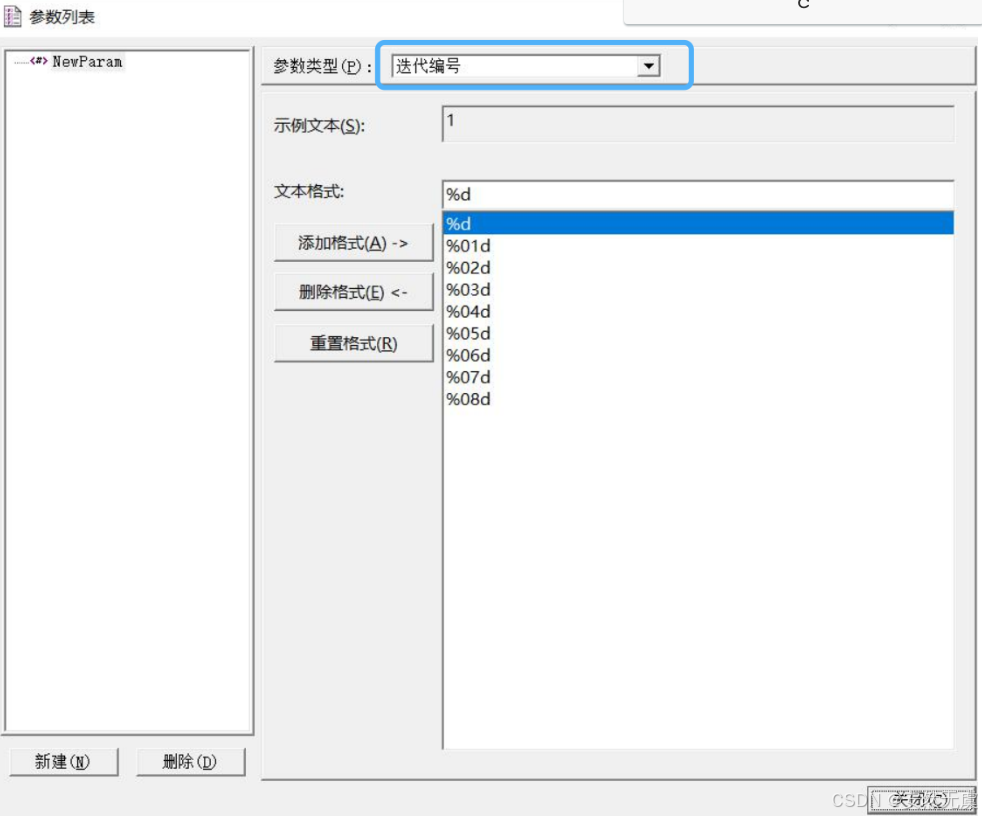
6.日期时间
能够按照时间生成不同格式的字符串.
更新值的规则:
- 每一次迭代时更新
- 每一次出现时更新
- 运行场景中更新一次
c
// 定义一个日期时间参数
lr_log_message("参数1,日期时间:%s", lr_eval_string("{NewParam}"));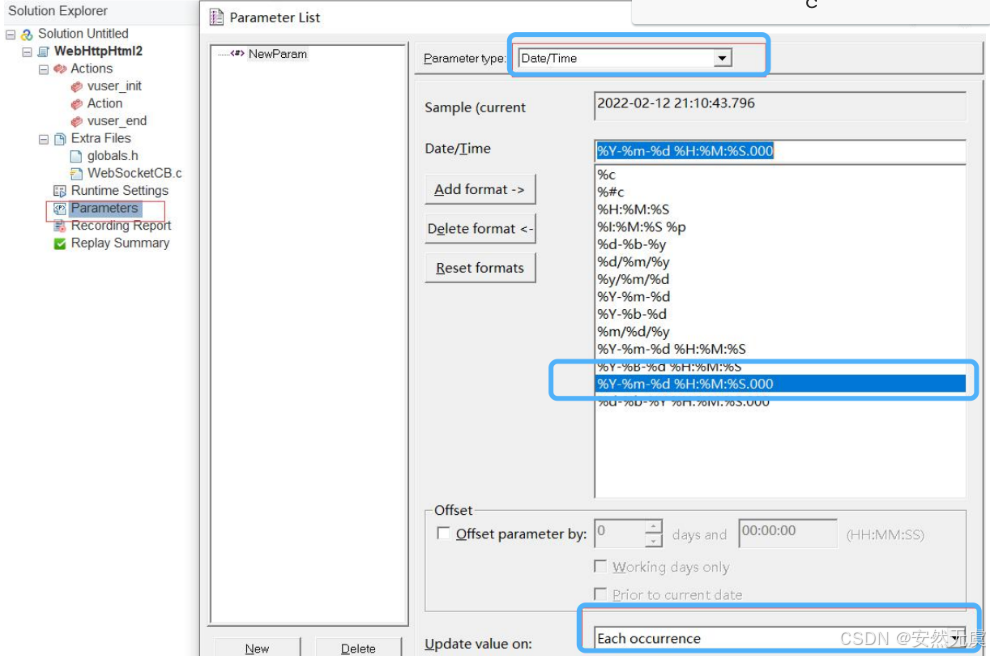
7.随机数字
能在范围内随机生成的不同数字.
更新值的规则:
- 每一次迭代时更新
- 每一次出现时更新
- 运行场景中更新一次
c
// 定义一个随机数字参数
lr_log_message("参数1,随机数字: %s", lr_eval_string("{NewParam}"));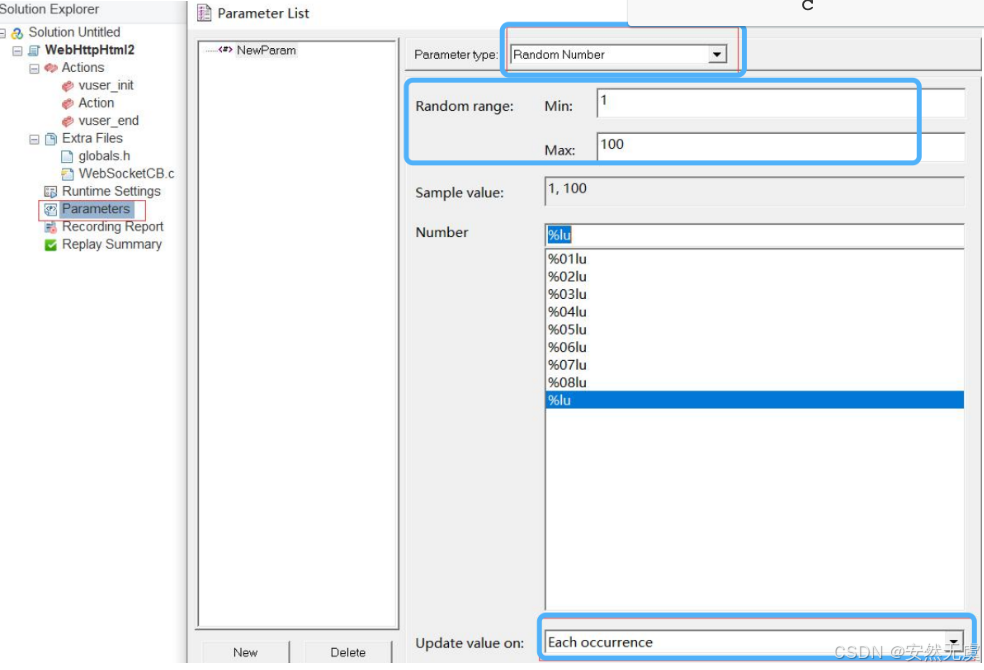
8.唯一编号(重要)
能够在范围内随机生成的唯一数字.
更新值的规则:
- 每一次迭代时更新
- 每一次出现时更新
- 运行场景中更新一次
c
// 定义一个唯一编号参数
lr_log_message("参数1,唯一编号参数: %s", lr_eval_string("{NewParam}"))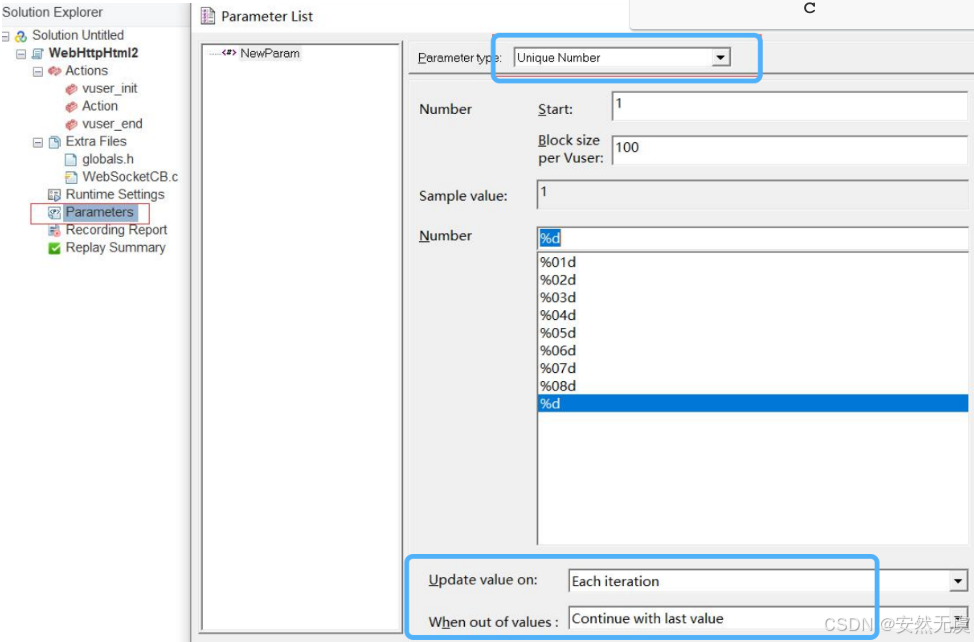
9.xml参数
以 xml 结构为基础的参数.
取 下一行数据 方法有三种:
- 顺序:按照参数化的顺序一个一个的来取
- 随机:参数化中的数据,每次随机的从中选取数据
- 唯一:为每个虚拟用户分配一个唯一的一条数据
更新值的规则:
- 每一次迭代时更新
- 每一次出现时更新
- 运行场景中更新一次
c
// 定义一个XML参数
lr_log_message("参数5,表参数: %s", lr_eval_string("{param5}"))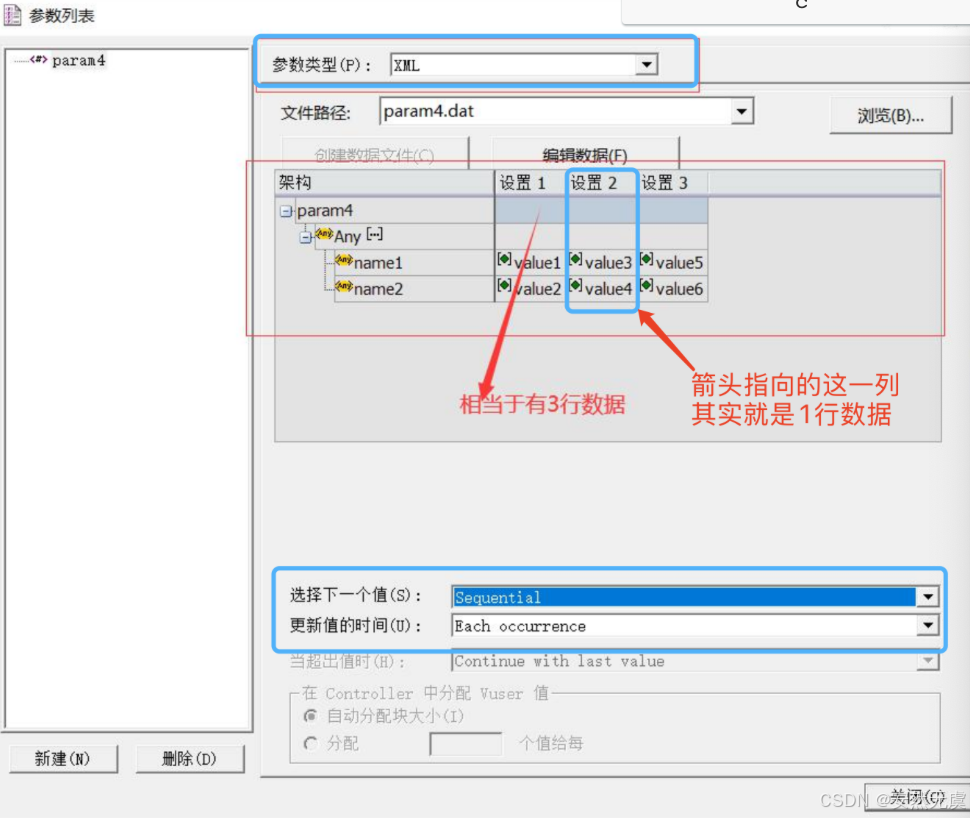
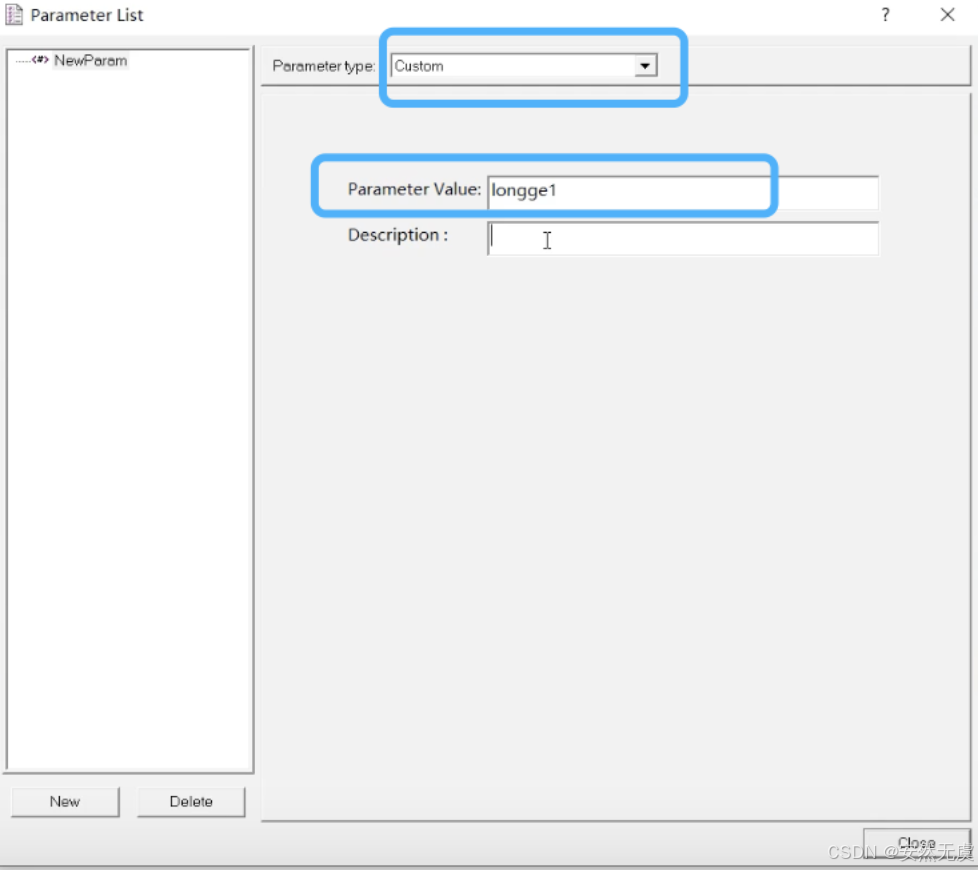
10.自定义参数(重要)
自定义参数一般是定义一些常量值.
用法和上面的差不多.
规则关联
一般在业务系统中, 我们在发起请求时, 有可能用到前面请求步骤的返回结果, lr 关联是指把服务器返回的数据 (部分数据) 以参数来表示, 同时作为后续请求的一个变量 这样的一个过程.
规则关联还分为手动关联和自动关联:
1.手动关联
- 找到前置请求中返回的需要的业务数据
- 将上述数据设置为参数
- 将后续条件采用参数化替代
比如这里是, 后续请求需要 登陆请求 返回的 devt_token值:
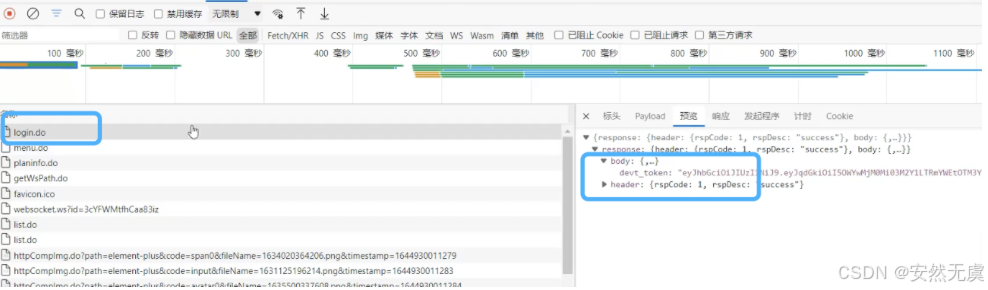
这时候我们需要使用 web_reg_save_param()函数:
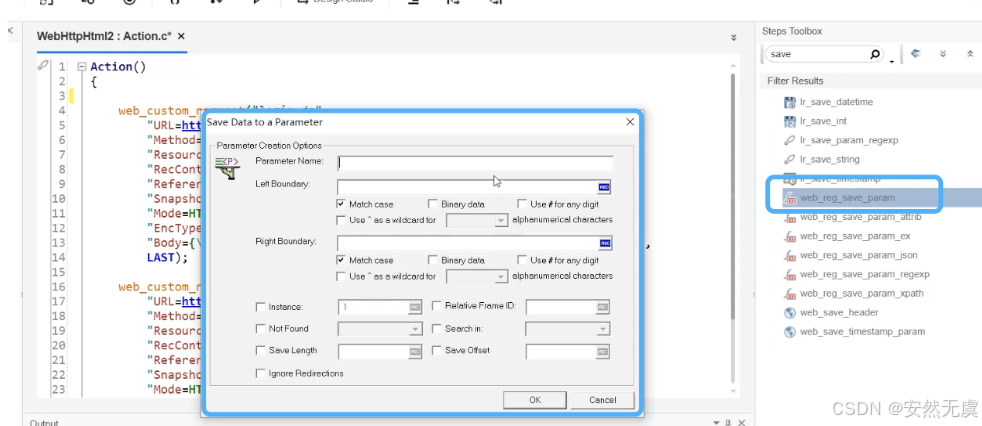
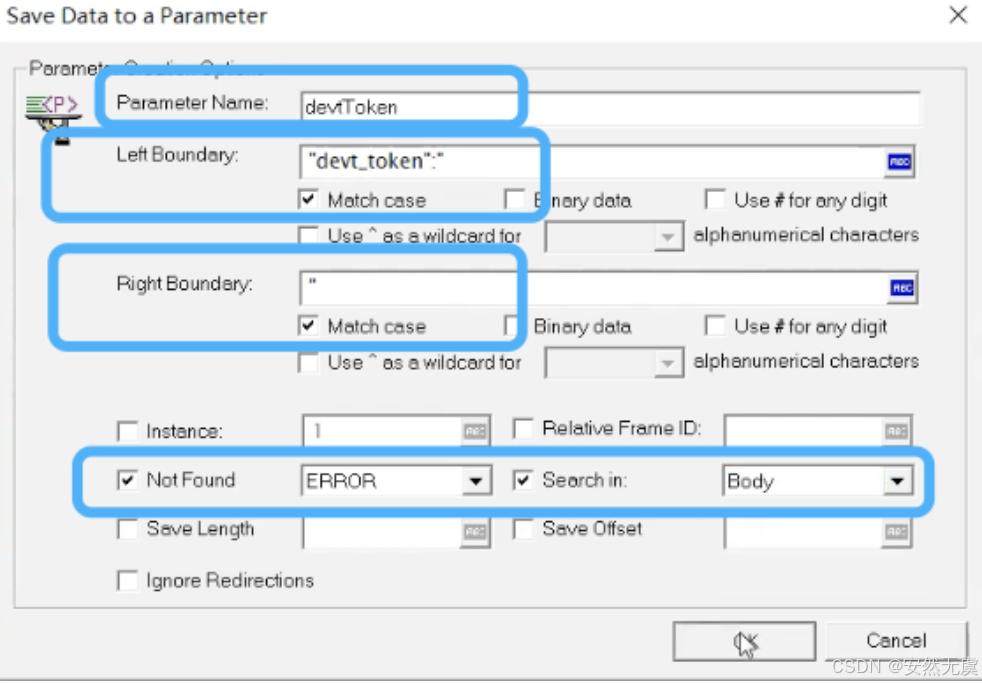
对这个函数进行配置(设置参数名字 并且 找到需要值的左右边界):
点击OK, 会生成这样的代码:
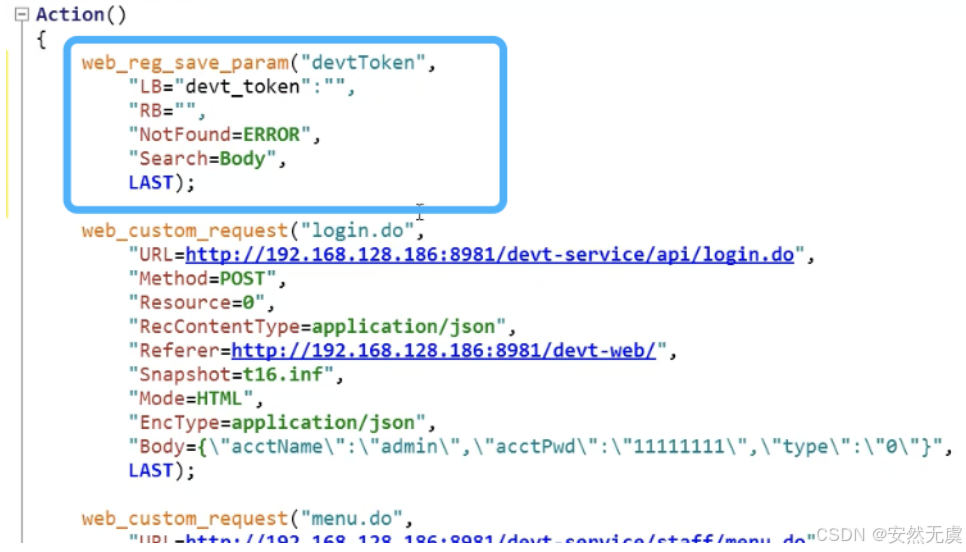
我们需要将双引号里面的引号用 \进行转义:
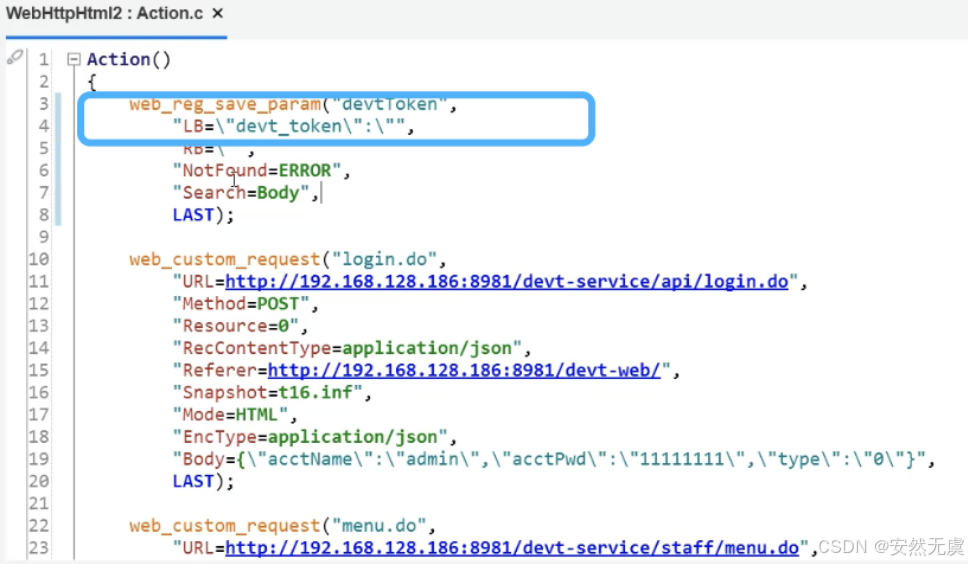
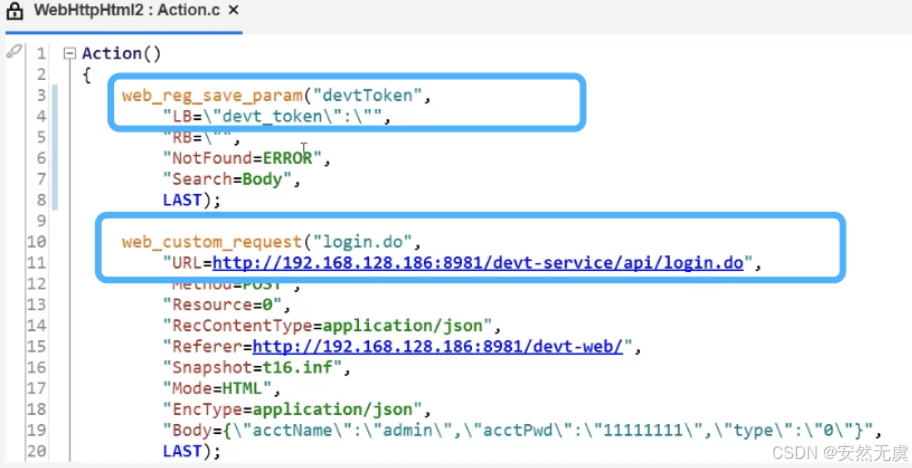
并且还有一点需要注意的是:
- 这个 web_reg_save_param() 函数需要放到 前置请求的前面一个, 比如这里要获取登陆请求的返回值, 那么这个函数就需要放到登陆接口的前面一个, 这样这个函数才能作用于登陆接口, 与后面的请求无关.
拿到前置请求中需要的返回值后, 将其添加为后续请求的请求头:
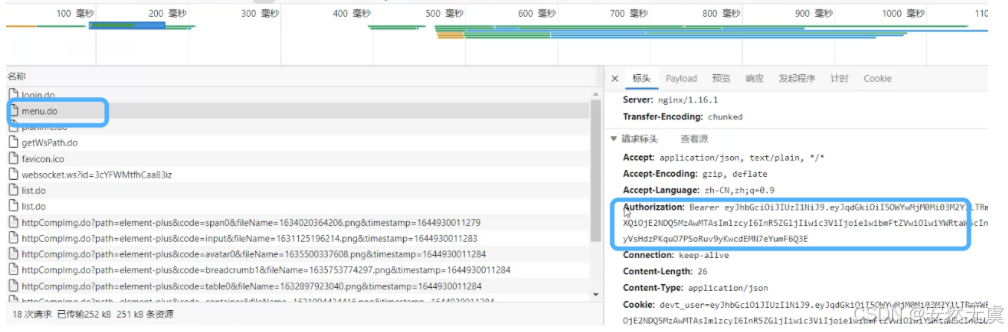
这个时候需要用到 web_add_auto_header() 函数:
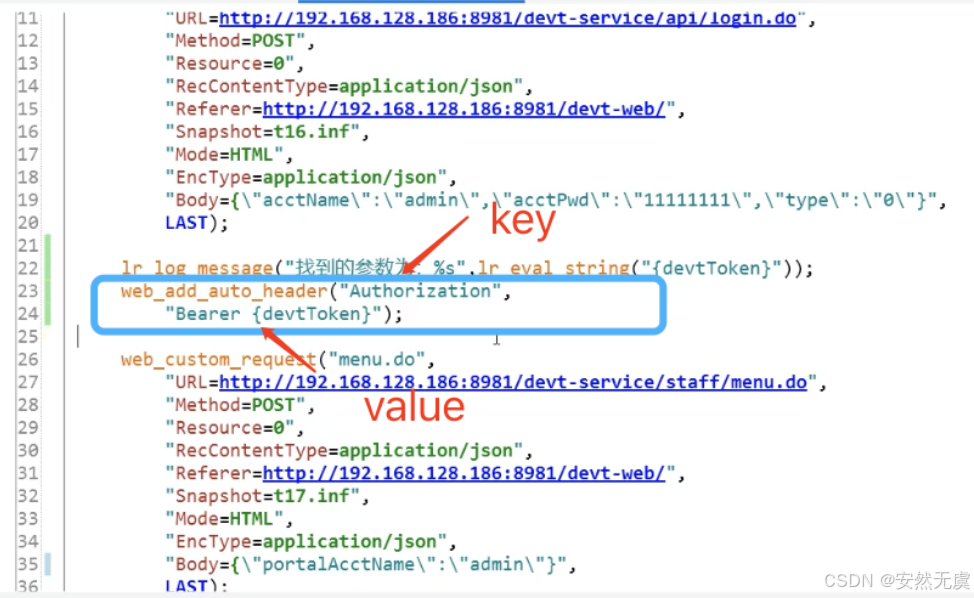
这样之后后续所有请求的请求头中都会有这对键值对.
2.自动关联
由 LoadRunner 内置规则在录制脚本时自动生成关联, 比如 cookie自动关联.
另外所有的自动关联都可以用手动关联代替, 因此手动关联是我们的学习重点.
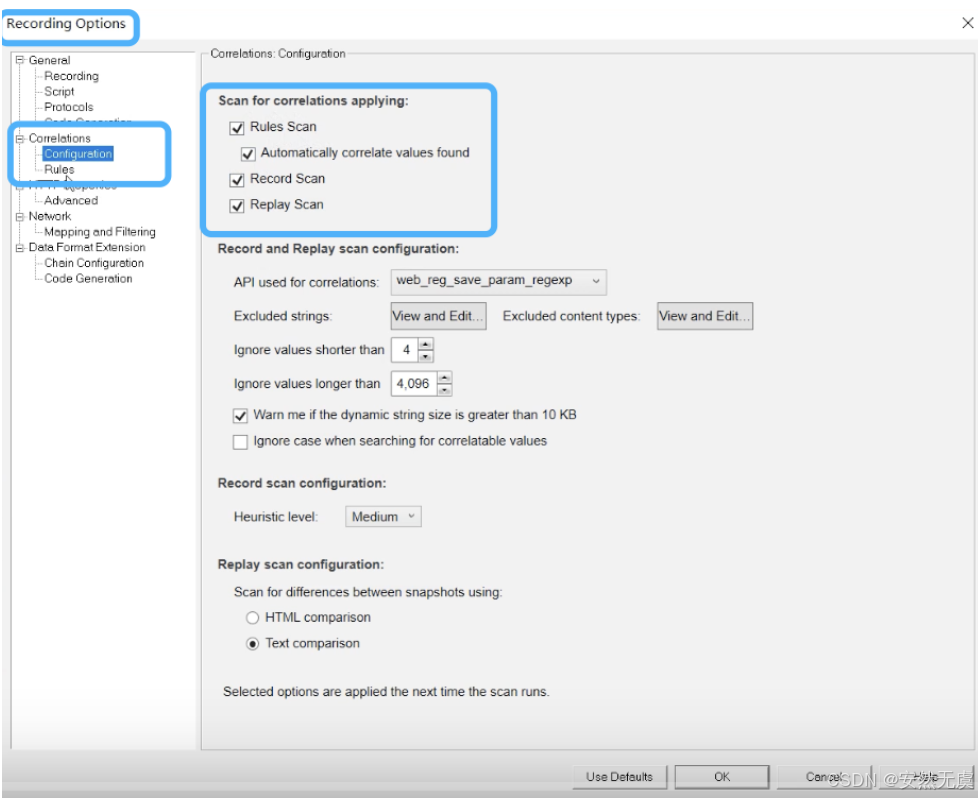
事务定义
事务 (Transaction) 用于模拟用户的一个相对完整的、有意义的业务操作过程, 例如登陆、查询、转账, 这些都可以作为事务, 而一般不会把每次HTTP请求作为一个事务.
- 开启事务: lr_start_transaction()
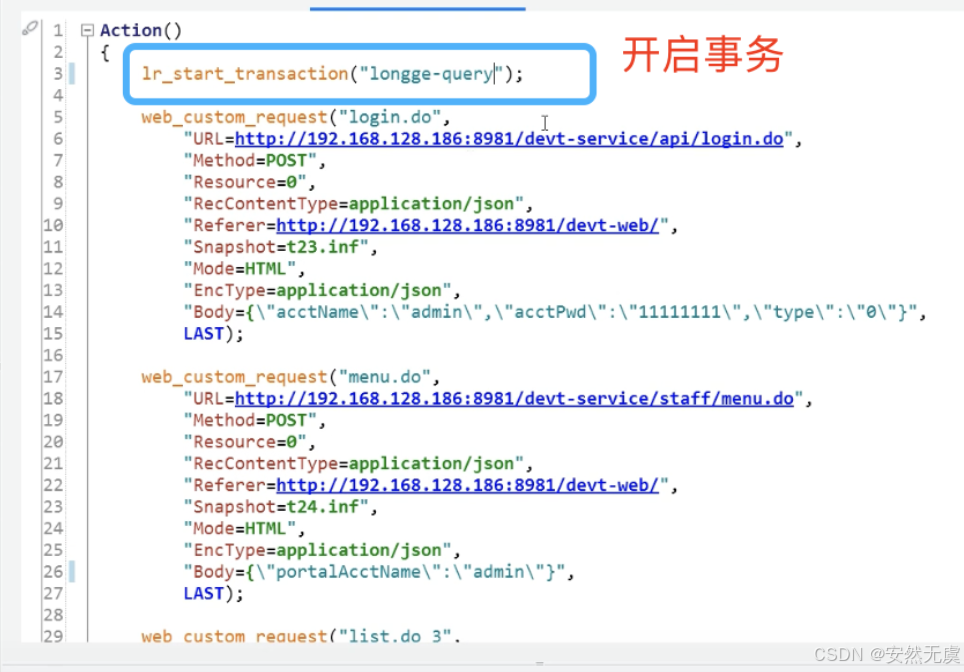
- 结束事务: lr_end_transaction()

如果我们要判断请求是否正常, 需要对其返回值做校验, 比如这里我们调用 web_reg_save_param()函数, 获取 rspCode值, 如果其大于0则正确, 否则请求错误.
这样的话, 事务结束时可以这样实现:
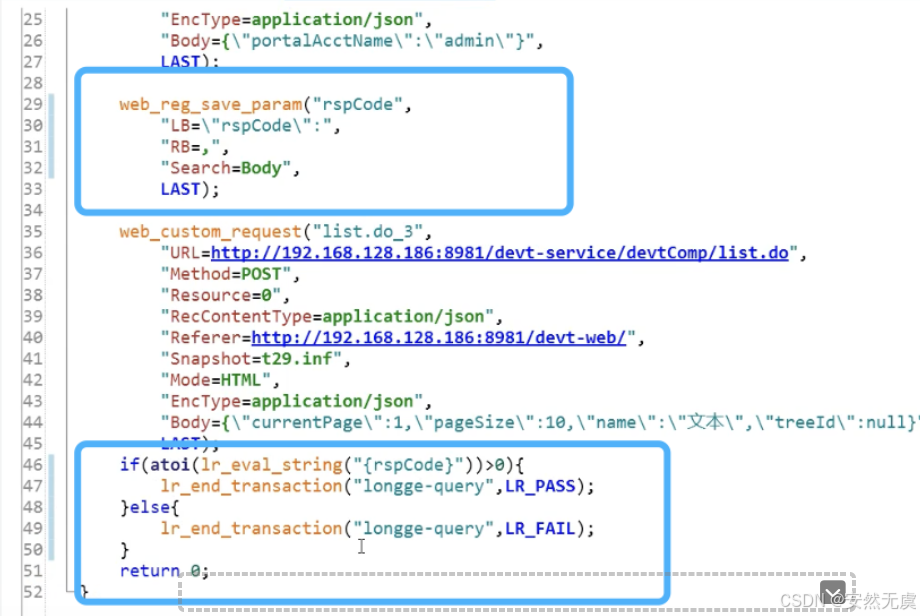
所以, 总结来说:
- 事务开始:
c
lr_start_transaction("devt-query");- 事务结束 (不检查结果, 自动结束):
c
lr_end_transaction("devt-query",LR_AUTO);- 事务成功结束:
c
lr_end_transaction("devt-query",LR_PASS);- 事务失败结束:
c
lr_end_transaction("devt-query",LR_FAIL);结果检查
利用结果检查函数, 这里是 web_reg_find()函数, 我们可以判断业务是否正确, 类似于断言.
有两种方式, 一种是 找特殊文本, 另外一种是类似于正则表达式, 找左右边界.
方式一: 找特殊文本
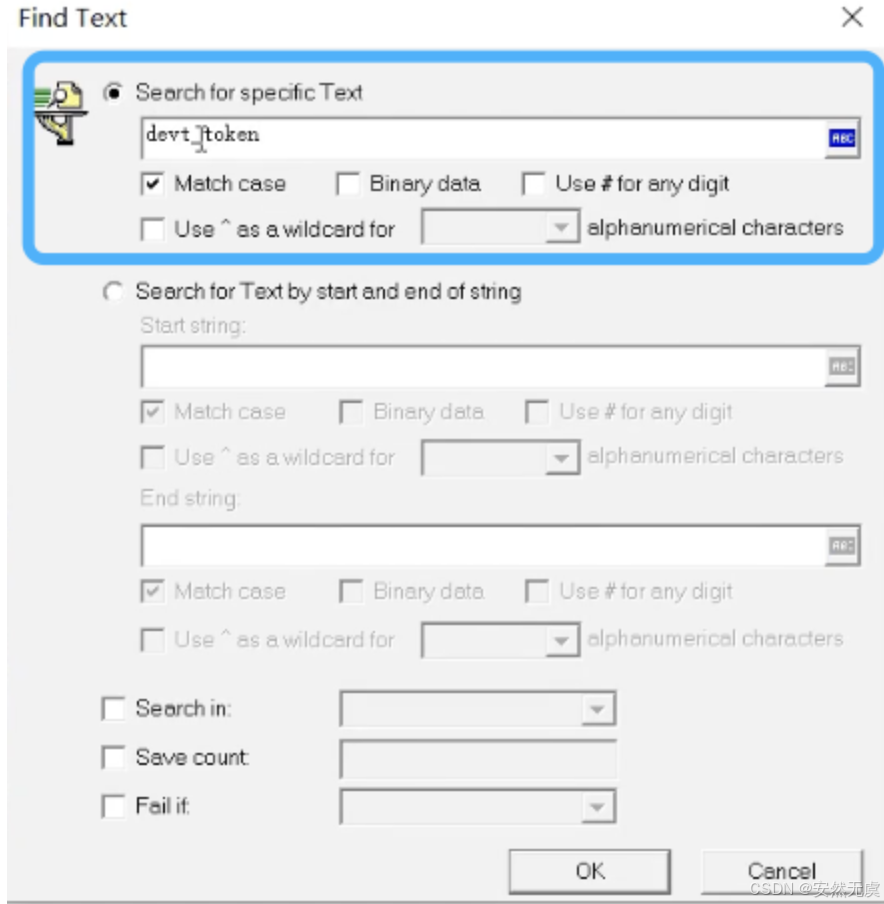
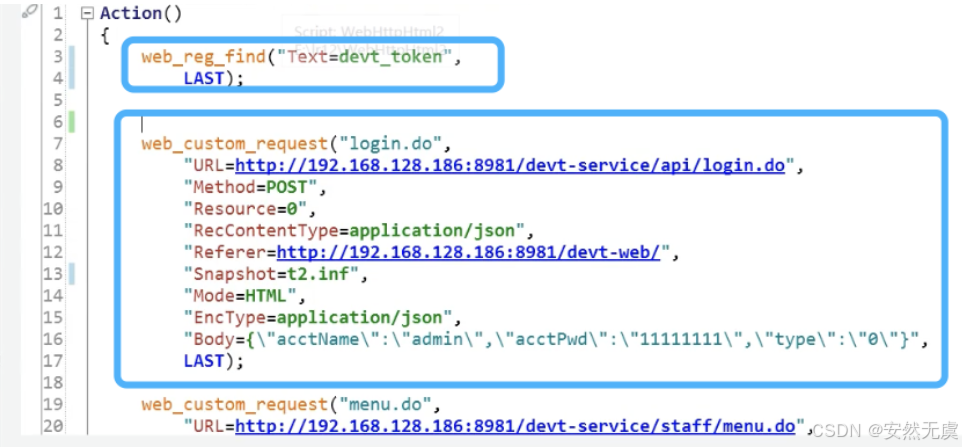
方式二: 类似于正则表达式
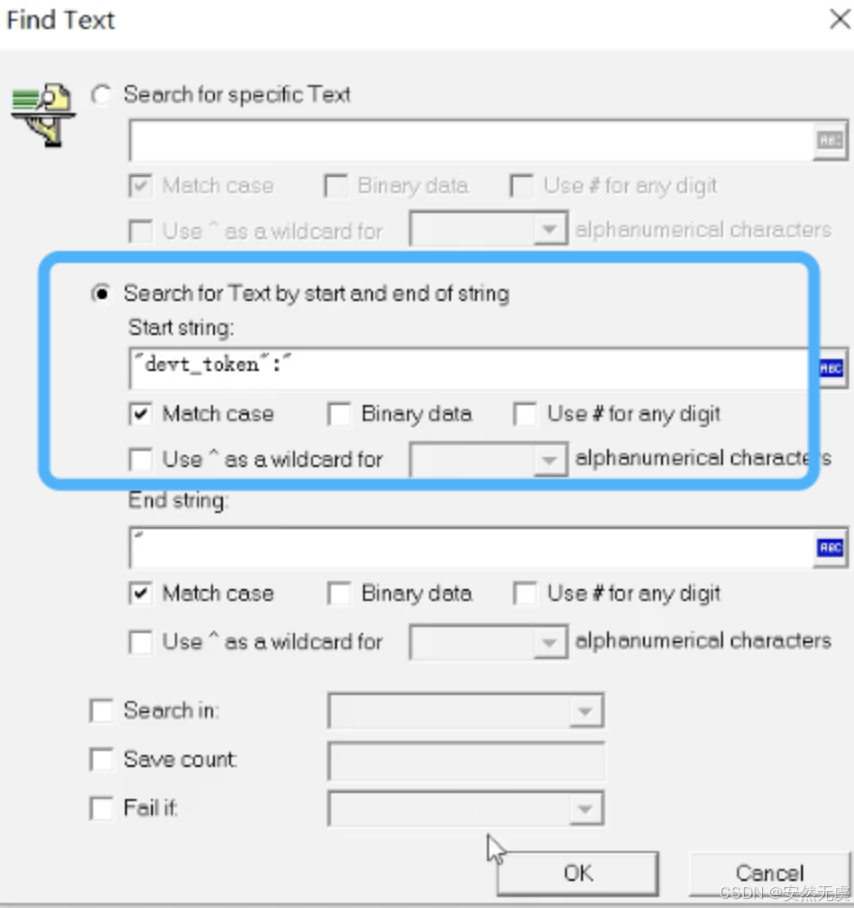
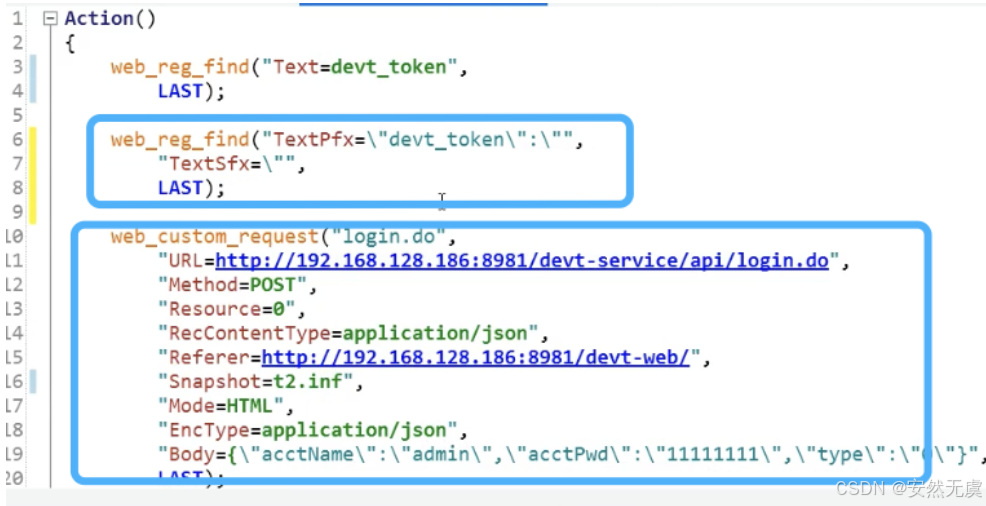
脚本编写小结
-
脚本参数化、规则关联、事务、结果检查 是脚本编写的几个核心场景
-
文件类、日期类、唯一编号、自定义参数 在脚本参数化中使用非常多,比如:
- 如我们想压测客户查询这个场景, 我们可以采用文件类, 按照自己的要求设计查询参数(比如 1000 个客户, 客户里面的数据有大有小)
- 在订单场景入库的时候,我们可以采用唯一编号,生成一些数据库序列
- 主机,端口等,我们可以采用自定义参数进行管理
-
通常我们的脚本在录完之后, 第一次运行很有可能报错, 这是由于一些关联没有做好, 我们可以打开日志, 按前面讲的的方法进行排查
- 找到请求中返回的业务数据
- 然后再利用脚本参数化进行处理
-
对于初学者, 我们一定要多写, 多练, 对于一些常用函数, 我们一定要熟悉
|----------------------|
| 遇见安然遇见你,不负代码不负卿。 |
| 谢谢老铁的时间,咱们下篇再见~ |