1. 数据容器入门
学习数据容器,就是为了批量存储或批量使用多份数据



2. 数据容器:list(列表)
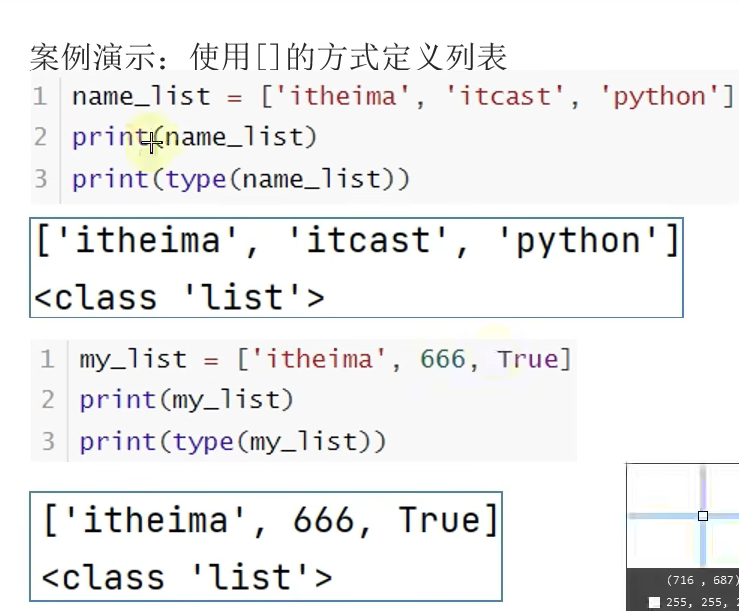
2.1 列表的定义


注意:列表可以一次存储多个数据,且可以为不同的数据类型,支持嵌套


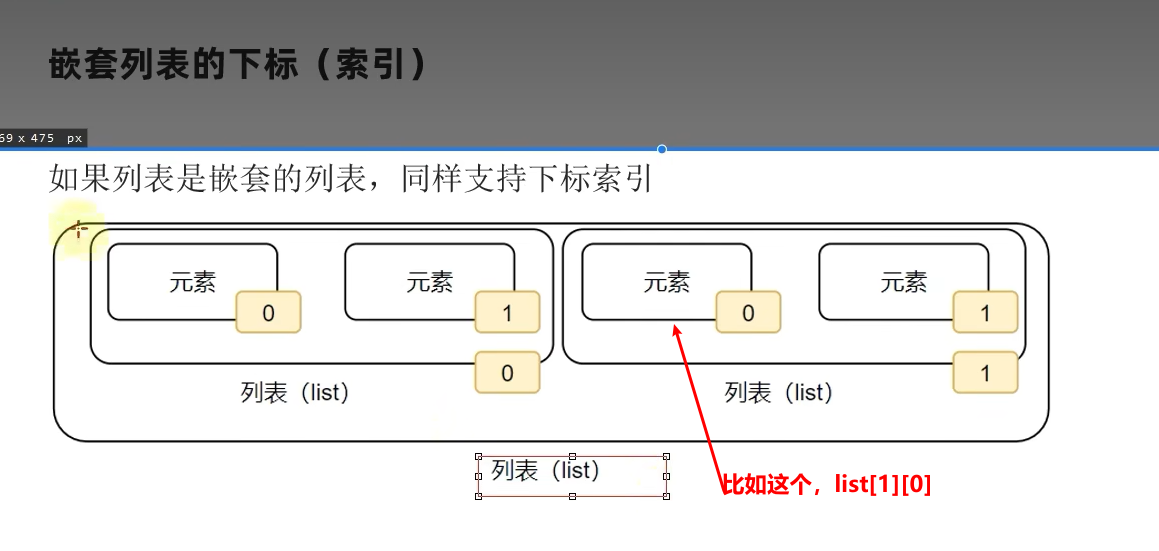
2.2 列表的下标索引



2.3 列表的常用操作


2.3.1 插入元素

append追加是整个塞进去;extend是拆分开


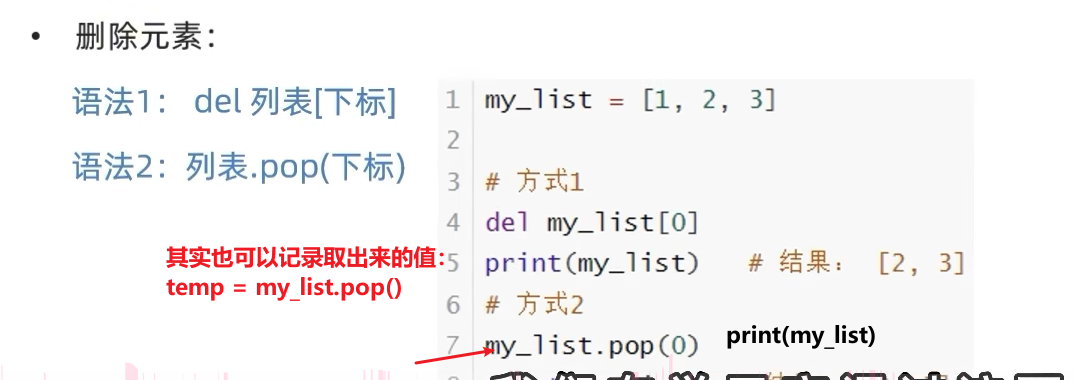
2.3.2 删除元素
两种删除方法:
1.使用索引删除
2.直接删除指定内容

2.3.3 清空元素

2.3.4 修改元素

2.3.5 统计元素个数
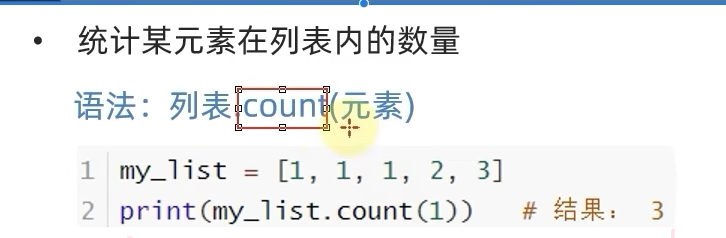

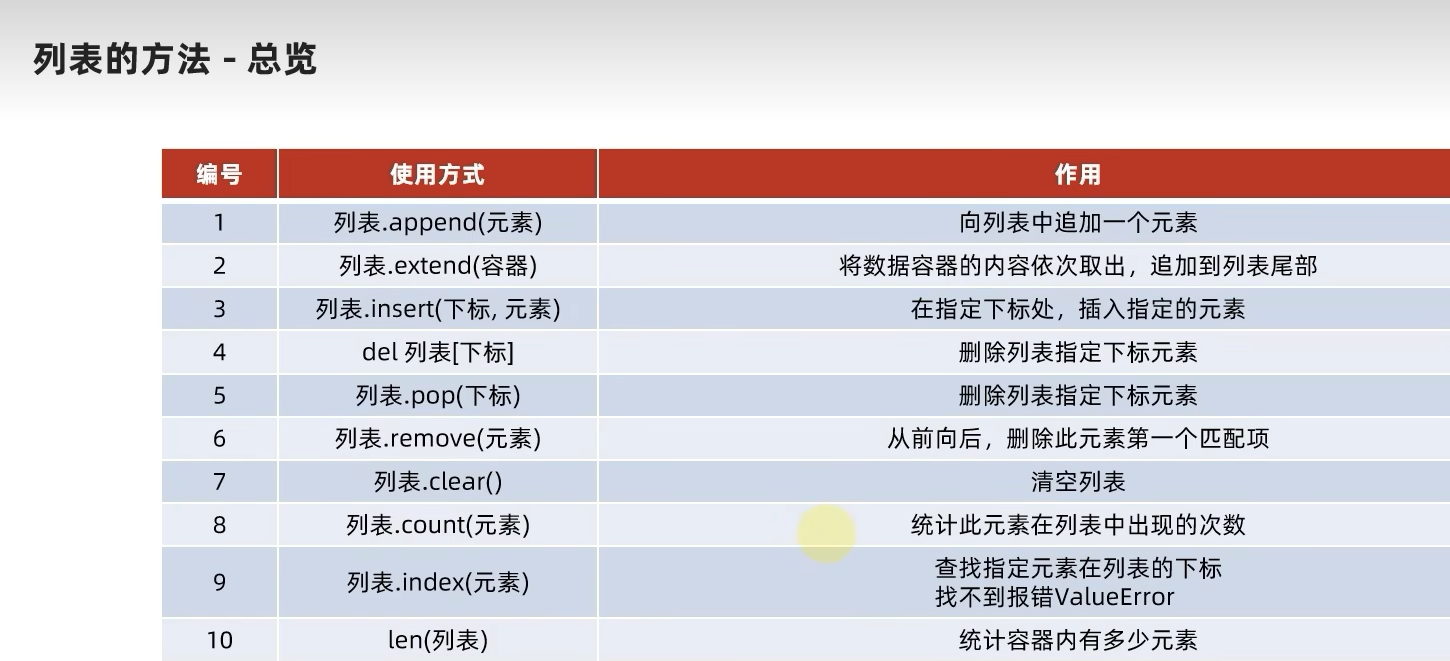
2.3.6 总结

3.list(列表)的遍历
3.1 while循环

3.2 for循环

python
age_list = [21,25,21,23,22,20]
def age_for():
for index in age_list:
print(index)
age_for()3.3 区别


4. 数据容器: tuple(元组)
4.1 元组的定义


python
t1 = (1,'haha',True)
t2 = ()
t3 = tuple()
# t1的类型是<class 'tuple'>,内容是(1, 'haha', True)
print(f"t1的类型是{type(t1)},内容是{t1}")
t4 = ('haha')
# t4的类型是<class 'str'>,内容是haha;
# t4是一个字符串,不是元组;因此对于单个元素的元组,后面也需要加逗号
print(f"t4的类型是{type(t4)},内容是{t4}")
#元组的嵌套
t5 = ((1,2,3),(4,5,6))
# t5的类型是<class 'tuple'>,内容是((1, 2, 3), (4, 5, 6))
print(f"t5的类型是{type(t5)},内容是{t5}")4.2 元组的相关操作


4.3 元组的特点


4.4 元组的小案例

python
my = ('周杰伦',11,['football','music'])
print(f"年龄下标的位置是{my.index(11)}")
print(f"学生的姓名是{my[0]}")
del my[2][0]
my[2].append("coding")
print(my)5. 数据容器: str(字符串)
5.1 字符串的定义

5.2 字符串的常用操作
5.2.1 查找特定字符串的下标索引

5.2.2 字符串的替换

python
str1 = "nihao haha zhang"
new = str1.replace("haha","xixi")
# 替换前是nihao haha zhang,替换后是nihao xixi zhang
print(f"替换前是{str1},替换后是{new}")5.2.3 字符串的分割

python
str1 = "nihao haha zhang"
# 括号里写根据什么进行分割
new_list = str1.split(" ")
# 将字符串nihao haha zhang,进行split切割后得到['nihao', 'haha', 'zhang'],类型是<class 'list'>
print(f"将字符串{str1},进行split切割后得到{new_list},类型是{type(new_list)}")5.2.4 字符串的规整操作
1.不会在原字符串上改,而是要赋予到新的字符串
2。从首和尾开始依次判断每个字符是否是参数中包含的字符,如果是就继续去除,否额就停止判断,和参数字符串顺序没有关系

5.2.5 字符串的遍历

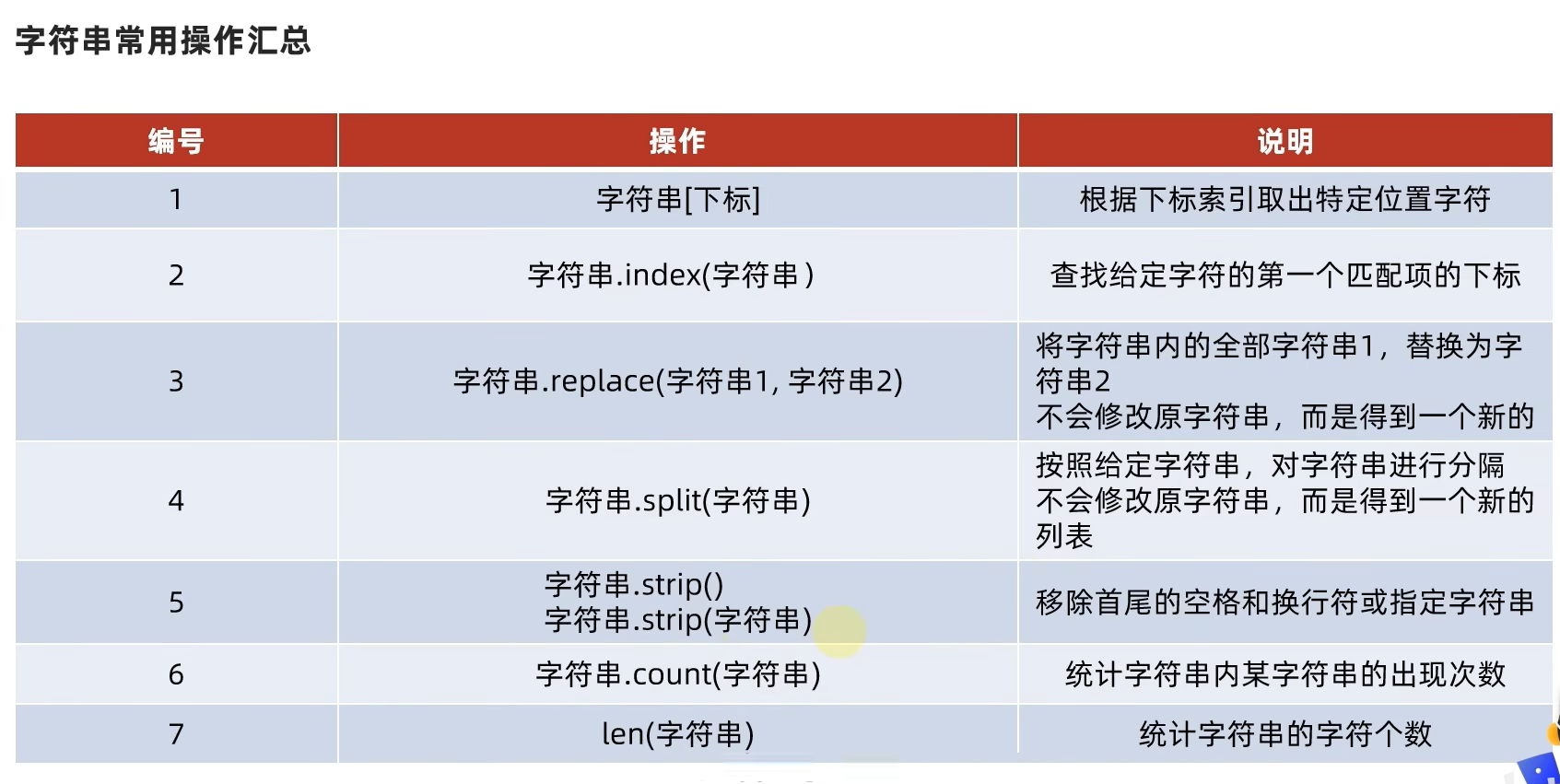
5.2.6 总结
python
str1 = "itheima itcast boxuegu"
num = str1.count("it")
# 字符串it出现了3次
print(f"字符串it出现了{num}次")
str2 = str1.replace(" ","|")
#将字符串itheima itcast boxuegu,进行replace替换空格后得到itheima|itcast|boxuegu
print(f"将字符串{str1},进行replace替换空格后得到{str2}")
str3 = str2.split("|")
# 将字符串itheima|itcast|boxuegu,进行split切割后得到['itheima', 'itcast', 'boxuegu'],类型是<class 'list'>
print(f"将字符串{str2},进行split切割后得到{str3},类型是{type(str3)}")
6. 数据容器(序列)的切片
6.1 序列的定义
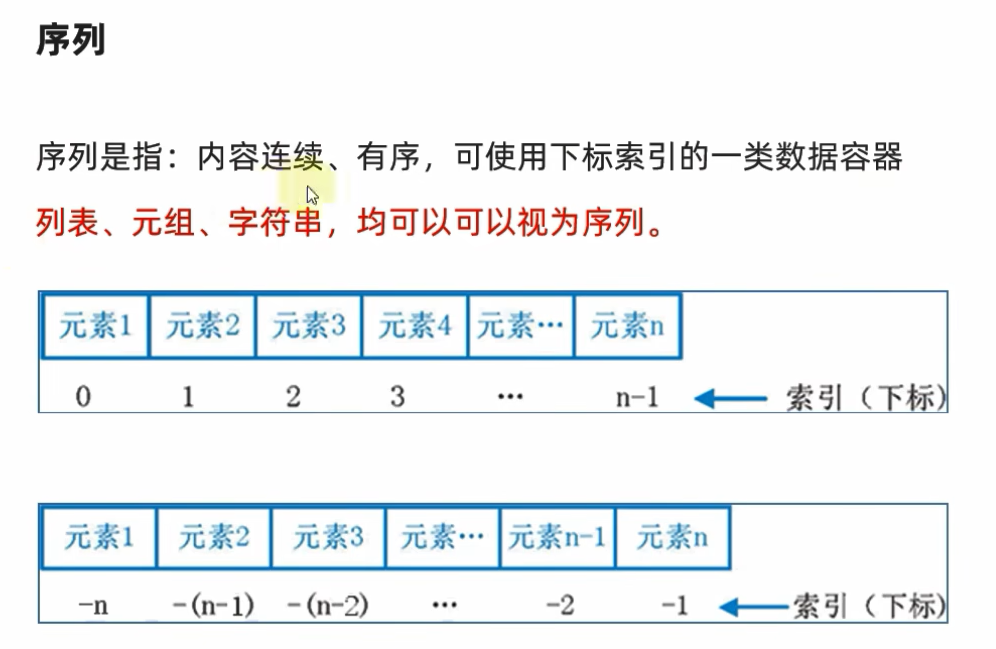
6.2 序列的常用操作--切片


步长为负数,可以将字符串进行反转
python
# 左闭右开区间,包含左边的索引,不包含右边的索引
# 对list进行切片,从1开始,4结束,步长1
my_list = [0,1,2,3,4,5,6]
result1 = my_list[1:4]#步长默认是1,所以可以省略不写
print(f"结果1:{result1}")# 结果1:[1, 2, 3]
# 对tuple进行切片,从头开始,到最后结束,步长1
my_tuple = (0,1,2,3,4,5,6)
result2 = my_tuple[:]# 起始和结束不写表示从头到尾
print(f"结果2:{result2}")# 结果2:(0, 1, 2, 3, 4, 5, 6)
# 对str进行切片,从头开始到最后结束,步长2
str = "01234567"
result3 =str[::2]
print(f"结果3:{result3}")# 结果3:0246
#对str进行切片,从头开始到最后结束,步长-1
result4 = str[::-1]
print(f"结果4:{result4}")# 结果4:76543210
#对列表进行切片,从3开始,到1结束,步长-1
result5 = my_list[3:1:-1]
print(f"结果5:{result5}")# 结果5:[3, 2]
#对元组进行切片,从头开始到最后结束,步长-2
result6 = my_tuple[::-2]
print(f"结果6:{result6}")# 结果6:(6, 4, 2, 0)7.数据容器:set(集合)
7.1 定义


python
my_set = {"hei","ha","hei","ni","ha"}
#my_set的内容是{'ha', 'hei', 'ni'},类型是<class 'set'>
# 所以元素不重复,且无序
print(f"my_set的内容是{my_set},类型是{type(my_set)}")
# 定义空集合
empty_set = set()
#empty_set的内容是set(),类型是<class 'set'>
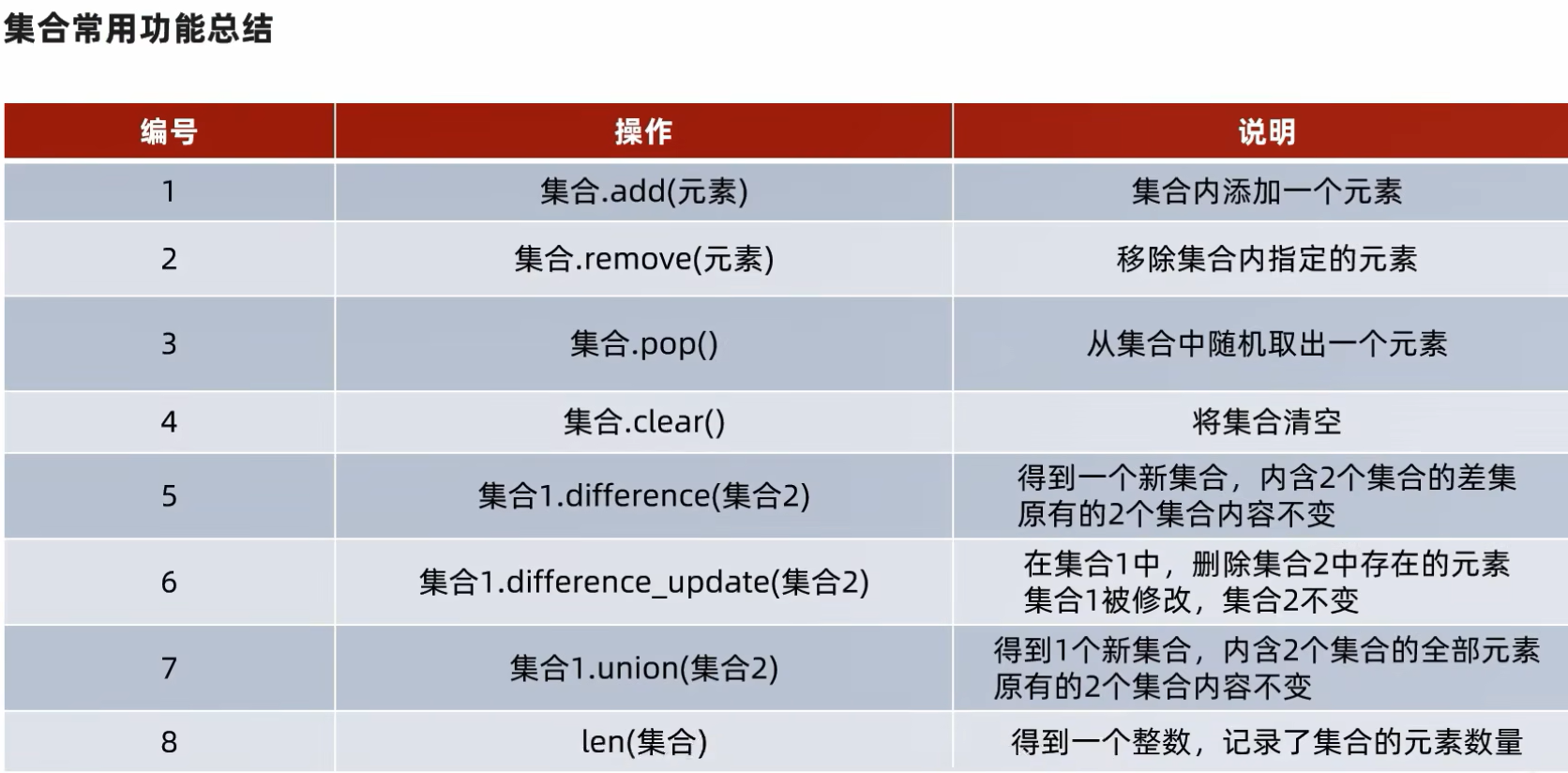
print(f"empty_set的内容是{empty_set},类型是{type(empty_set)}")7.2 集合的常用操作
7.2.1 添加新元素

7.2.2 移除元素

7.2.3 从集合中随机取出元素

7.2.4 清空集合

7.2.5 取出2个集合的差集

7.2.6 消除2个集合的差集

7.2.7 2个集合合并

7.2.8 计算集合的长度
python
set = {1,2,3,4,5,1,2,3,4,5}
num =len(set)
#set的元素个数是5
print(f"set的元素个数是{num}")7.2.9 集合的遍历
不可以使用while遍历
python
set = {1,2,3,4,5,1,2,3,4,5}
for i in set:
print(i)7.2.10 总结
7.3 集合的特点

8. 数据容器:dict(字典、映射)
8.1 字典的定义


这就是为什么集合在定义空集合时,为什么不能写my_set = {};因为被字典用了


8.2 字典的嵌套

python
my_dict = {
"王力宏":{
"年龄":18,
"性别":"男",
"手机号":"0000"},
#元素之间要有逗号
"周杰伦":{
"年龄":12,
"性别":"男",
"手机号":"1382"},
"张三":{
"年龄":2,
"性别":"女",
"手机号":"1280"}
}
print(my_dict)
#看周杰伦的性别
print(my_dict["周杰伦"]["性别"])8.3 字典的常用操作
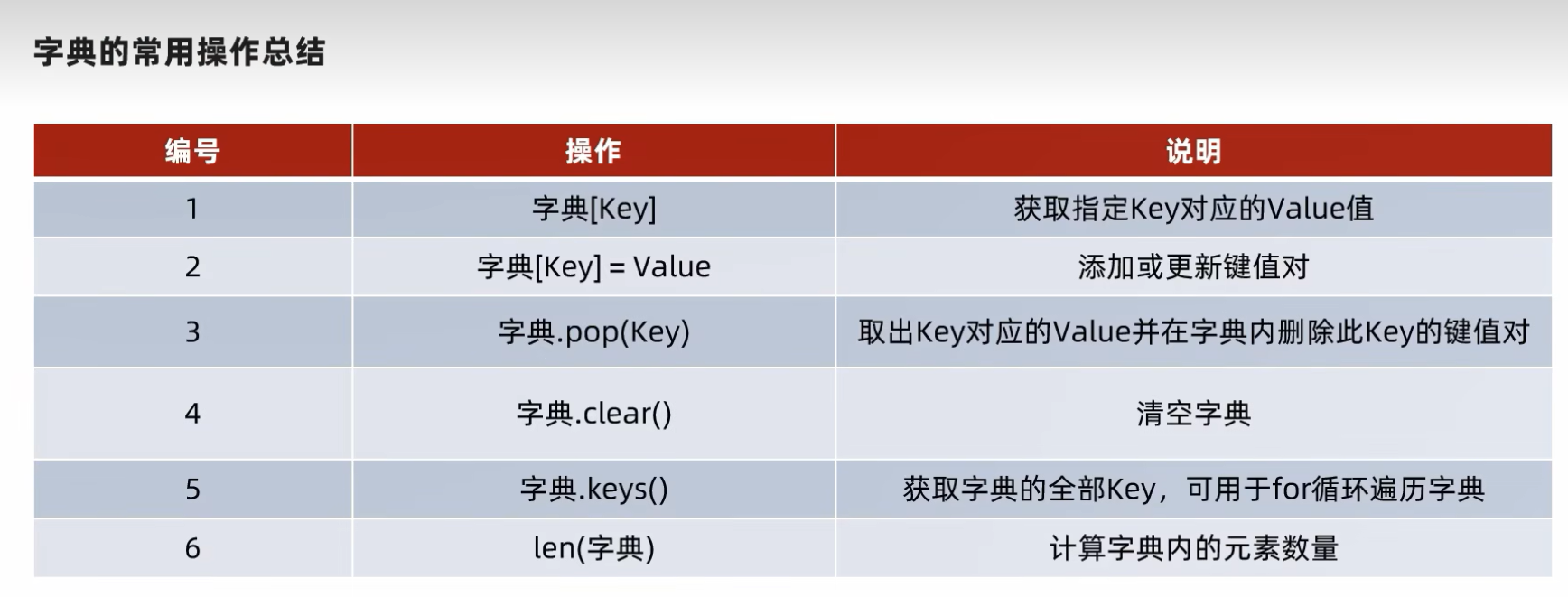
8.3.1 新增元素

8.3.2 更新元素

8.3.3 删除元素

8.3.4 获取全部的key

8.3.4 清空字典

8.3.5 字典遍历
python
#方式一:通过获取到全部的key来完成遍历
keys = my_dict.keys()
print(keys)
for key in keys:
print(f"字典的key1是{key}")
print(my_dict[key])
# 方式二:直接遍历字典序
for i in my_dict:
print(f"字典的key2是{i}")
print(my_dict[i])8.3.6 字典的数量
python
num = len(my_dict)
print(f"字典中元素数量是{num}")8.3.7 总结

8.4 案例

python
my_dict = {
"王力宏":{
"部门": "科创部",
"工资": 3000,
"级别": 1
},
"林俊杰": {
"部门": "科创部",
"工资": 1000,
"级别": 3
},
"周杰伦": {
"部门": "市场部",
"工资": 5000,
"级别": 2
}
}
for i in my_dict:
my_dict[i]["工资"] += 1000
my_dict[i]["级别"] += 1
print(my_dict)9.数据容器对比总结
9.1 数据容器的分类

9.2 特点对比
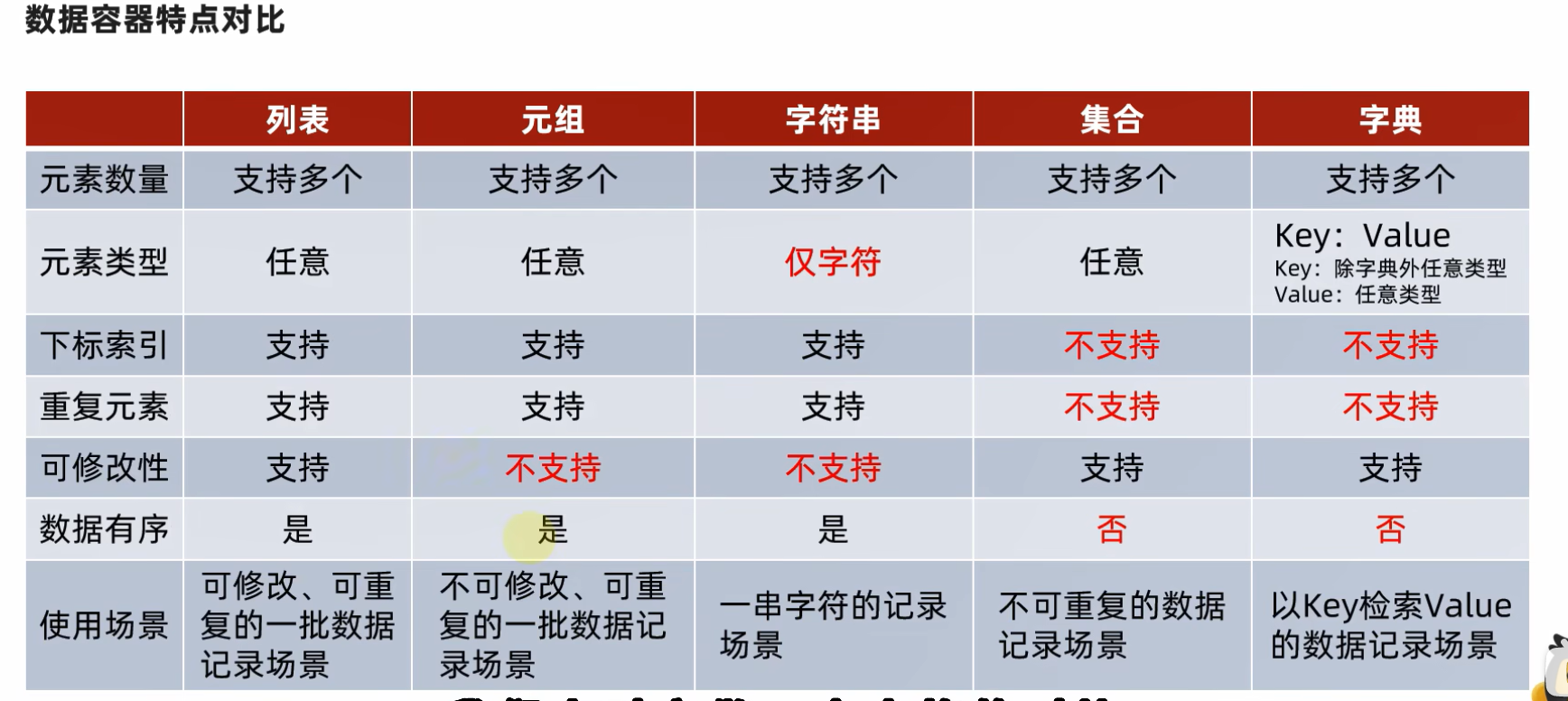
9.3 使用场景

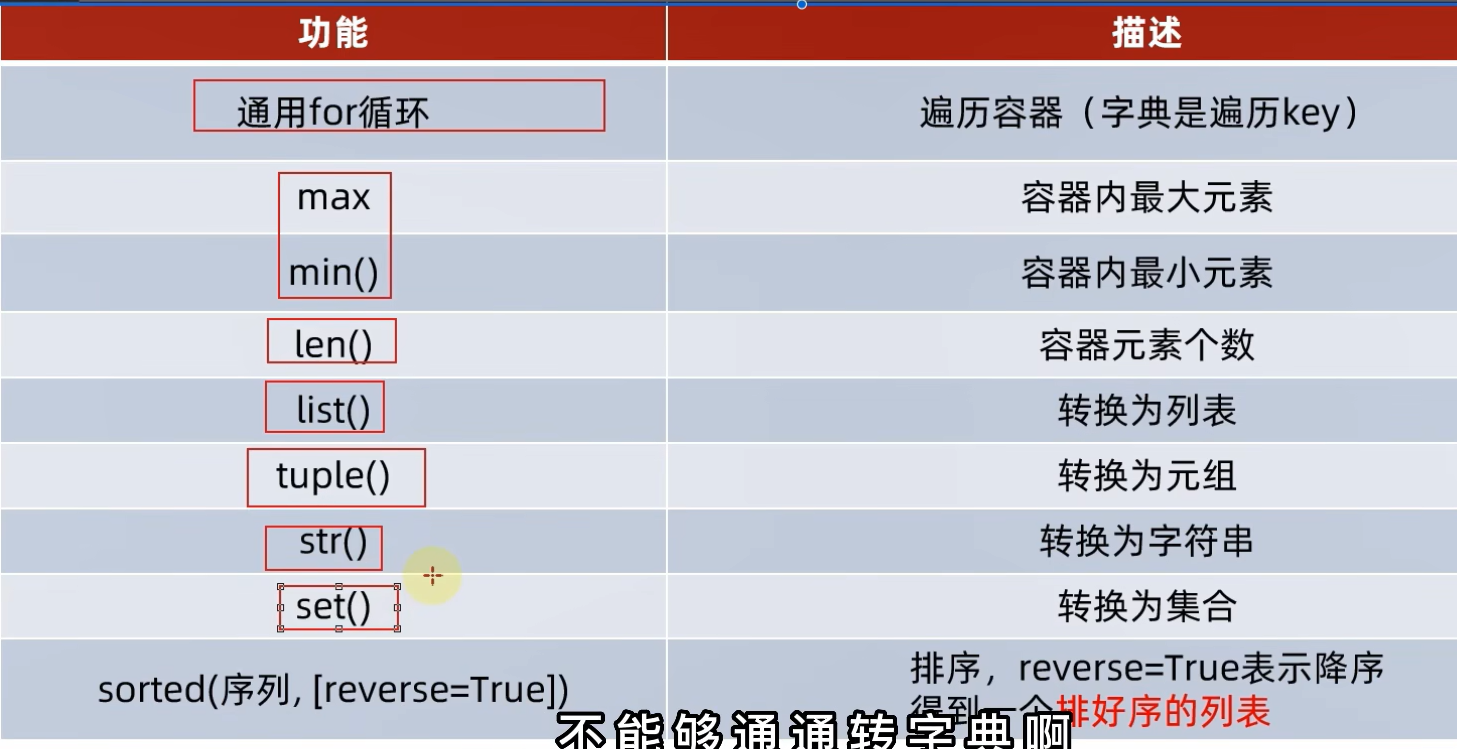
10. 数据容器的通用操作
10.1 遍历

10.2 统计

10.3 转换功能

python
my_list = [1,2,3,4,5]
my_tuple = (1,2,3,4,5)
my_str = "abcdefg"
my_set ={1,2,3,4,5}
my_dict = {"key1":1,"key2":2,"key3":3,"key4":4,"key5":5}
#容器转为列表
print(f"列表转为列表的结果是:{list(my_list)}")
print(f"元组转为列表的结果是:{list(my_tuple)}")
#字符串转为列表的结果是:['a', 'b', 'c', 'd', 'e', 'f', 'g']
print(f"字符串转为列表的结果是:{list(my_str)}")
print(f"集合转为列表的结果是:{list(my_set)}")
#字典转为列表的结果是:['key1', 'key2', 'key3', 'key4', 'key5']
print(f"字典转为列表的结果是:{list(my_dict)}")
#字典在转换为列表、元组、集合的时候,他的value会丢失
# 但转换为字符串时,所有元素都能够保留下来10.4 排序

python
my_list = [3,1,2,5,4]
my_tuple = (3,1,2,5,4)
my_str = "bcdaefg"
my_set ={3,1,2,5,4}
my_dict = {"key1":3,"key2":1,"key3":2,"key4":5,"key5":4}
#排完序之后都变成了列表对象
# [1, 2, 3, 4, 5]
print(f"列表排序后的结果是:{sorted(my_list)}")
print(f"元组排序后的结果是:{sorted(my_tuple)}")
print(f"字符串排序后的结果是:{sorted(my_str)}")
print(f"集合排序后的结果是:{sorted(my_set)}")
# 字典排序后的结果是:['key1', 'key2', 'key3', 'key4', 'key5']
print(f"字典排序后的结果是:{sorted(my_dict)}")
#反向排序
print(f"列表反向排序后的结果是:{sorted(my_list,reverse=True)}")
print(f"元组反向排序后的结果是:{sorted(my_tuple,reverse=True)}")
# 字符串反向排序后的结果是:['g', 'f', 'e', 'd', 'c', 'b', 'a']
print(f"字符串反向排序后的结果是:{sorted(my_str,reverse=True)}")
print(f"集合反向排序后的结果是:{sorted(my_set,reverse=True)}")
# 字典反向排序后的结果是:['key5', 'key4', 'key3', 'key2', 'key1']
print(f"字典反向排序后的结果是:{sorted(my_dict,reverse=True)}")10.5 总结
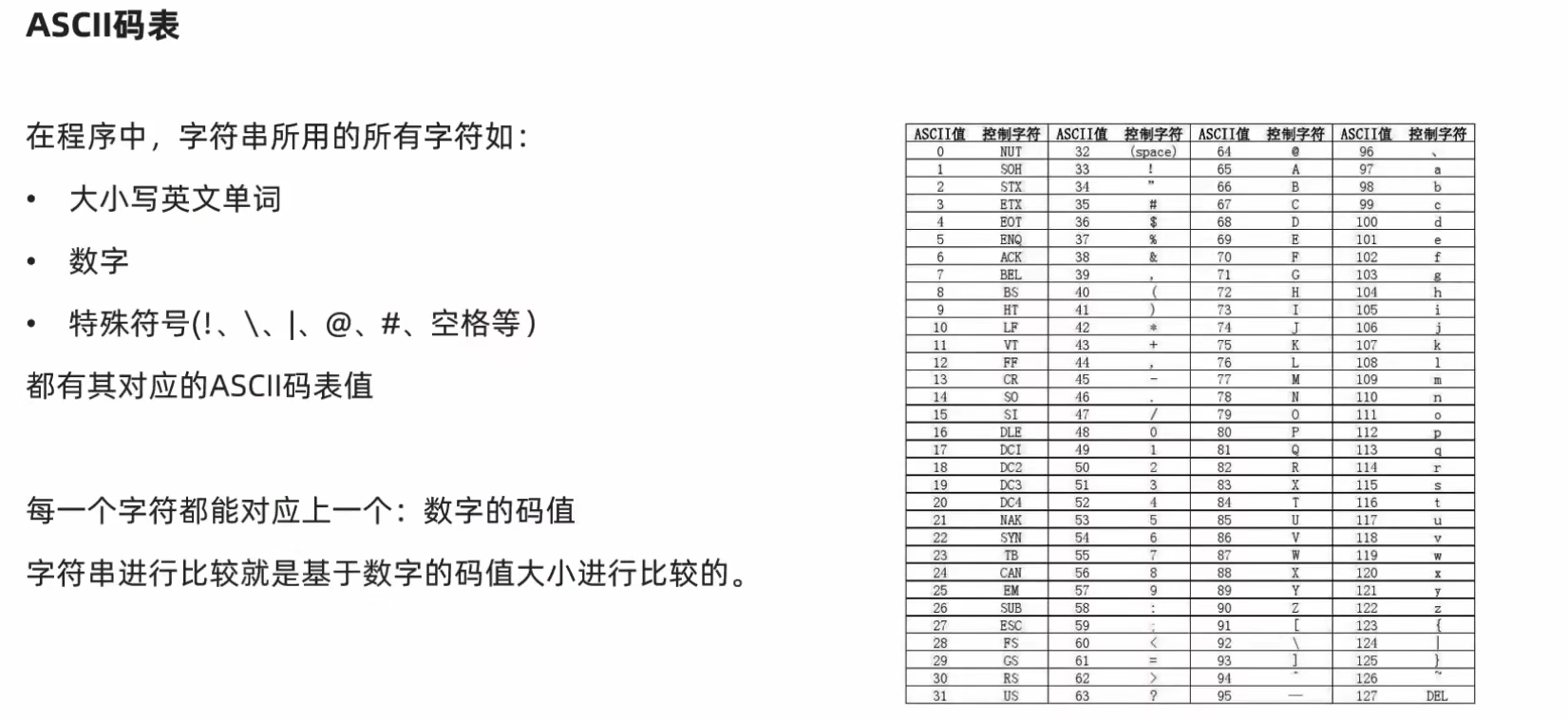
11.拓展:字符串大小比较的方式