CREATE TABLE IF NOT EXISTS 表名 (
字段1 数据类型 约束,
字段2 数据类型 约束,
...
);
IF NOT EXISTS:避免重复创建表报错;
SQLite 常用数据类型:
INTEGER:整数(可存主键自增);
TEXT:字符串(文本、日期等);
REAL:浮点数(小数);
BLOB:二进制数据(图片、文件等);
常用约束:
PRIMARY KEY:主键(唯一标识,不可重复);
AUTOINCREMENT:自增(仅 INTEGER 类型可用);
NOT NULL:非空(字段必须有值);
UNIQUE:唯一(字段值不可重复)。
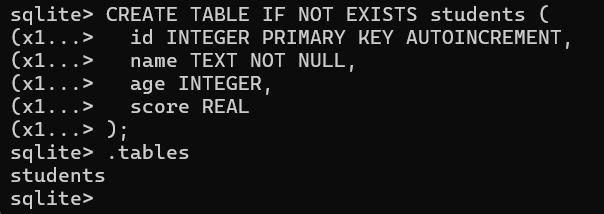
**示例:**创建学生表
sql复制代码
CREATE TABLE IF NOT EXISTS students (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
age INTEGER,
score REAL
);
执行后用 .tables 验证:会显示 students 表。
(2)插入数据(INSERT INTO)
语法1:指定字段插入(推荐,顺序可自定义)
sql复制代码
INSERT INTO 表名 (字段1, 字段2, ...) VALUES (值1, 值2, ...);
语法2:插入所有字段(需按表结构顺序,不推荐)
sql复制代码
INSERT INTO 表名 VALUES (值1, 值2, ...);
示例:插入3条学生数据(id 自增,可省略)
sql复制代码
-- 插入学生1:姓名张三,年龄18,成绩95.5
INSERT INTO students (name, age, score) VALUES ('张三', 18, 95.5);
-- 插入学生2:姓名李四,年龄19,成绩88.0
INSERT INTO students (name, age, score) VALUES ('李四', 19, 88.0);
-- 插入学生3:姓名王五,年龄17(成绩为空)
INSERT INTO students (name, age) VALUES ('王五', 17);
字符串值用单引号 ' ' 包裹;
空值可省略字段,或用 NULL 表示(如 score NULL)。
(3)查询数据(SELECT)
语法(核心,最常用):
sql复制代码
SELECT 字段1, 字段2... FROM 表名 WHERE 条件 GROUP BY 字段 HAVING 条件 ORDER BY 字段 ASC/DESC LIMIT 数量;
常用示例:
sql复制代码
-- 1. 查询所有学生的所有字段(* 表示所有字段)
SELECT * FROM students;
-- 2. 查询所有学生的姓名和成绩(只显示指定字段)
SELECT name, score FROM students;
-- 3. 查询成绩 ≥90 分的学生(WHERE 条件过滤)
SELECT name, score FROM students WHERE score >= 90;
-- 4. 查询年龄 18-20 岁的学生(范围查询)
SELECT name, age FROM students WHERE age BETWEEN 18 AND 20;
-- 5. 查询姓名包含「张」的学生(模糊查询,% 匹配任意字符)
SELECT * FROM students WHERE name LIKE '%张%';
-- 6. 按成绩降序排列(DESC 降序,ASC 升序,默认 ASC)
SELECT name, score FROM students ORDER BY score DESC;
-- 7. 只查询前2条数据(LIMIT 限制数量)
SELECT * FROM students LIMIT 2;
执行后会以表格形式显示结果(因之前启用了 .mode column 和 .header on)。
(4)更新数据(UPDATE)
语法:
sql复制代码
UPDATE 表名 SET 字段1=值1, 字段2=值2... WHERE 条件;
必须加WHERE****条件!否则会更新表中所有数据!
示例:
sql复制代码
-- 将王五的成绩改为92.0(按id更新,最安全,id唯一)
UPDATE students SET score = 92.0 WHERE id = 3;
-- 将张三的年龄改为19,成绩改为96.0
UPDATE students SET age = 19, score = 96.0 WHERE name = '张三';
(5)删除数据(DELETE)
语法:
sql复制代码
DELETE FROM 表名 WHERE 条件;
必须加WHERE****条件!否则会删除表中所有数据!
示例:
sql复制代码
-- 删除id=2的学生(李四)
DELETE FROM students WHERE id = 2;
-- 删除成绩 < 90 分的学生(若有)
DELETE FROM students WHERE score < 90;
(6)删除表(DROP TABLE)
语法:
sql复制代码
DROP TABLE IF EXISTS 表名;
**示例:**删除学生表
sql复制代码
DROP TABLE IF EXISTS students;
2.2、SQLite 进阶功能
1. 索引(提高查询效率)
当表中数据量大时,查询会变慢,可给常用查询字段创建索引(类似书籍目录)。
语法:
sql复制代码
-- 创建索引
CREATE INDEX IF NOT EXISTS 索引名 ON 表名 (字段);
-- 删除索引
DROP INDEX IF EXISTS 索引名;
示例: 给学生表的 name 字段创建索引
sql复制代码
CREATE INDEX IF NOT EXISTS idx_students_name ON students (name);
索引会加快 **WHERE name = 'xxx'**这类查询,但会减慢插入/更新/删除速度(需维护索引),按需使用。
-- 先创建账户表
CREATE TABLE IF NOT EXISTS account (
id INTEGER PRIMARY KEY,
user TEXT NOT NULL,
money REAL NOT NULL
);
-- 插入测试数据
INSERT INTO account VALUES (1, 'A', 1000), (2, 'B', 500);
-- 事务执行转账
BEGIN;
UPDATE account SET money = money - 100 WHERE user = 'A';
UPDATE account SET money = money + 100 WHERE user = 'B';
COMMIT; -- 无错误则提交,此时 A=900,B=600
-- 若执行中出错(如字段写错),执行 ROLLBACK; 撤销所有操作