目录
引入Kafka
诞生背景
假如你是Linkedln2010年的首席工程师。这时,网站每天有海量的事件在发生:用户的点击、搜索、状态更新... ...,这些大量的数据产生了一个危机:
- 数据生产者太多:前端、后端、移动端的无数服务在产生数据;
- 数据消费者也太多:实时分析、监控、广告系统、数据仓库等都要获取这些数据以便做出实时反应;
在Kafka出现之前,是如何解决的这个问题的?
- 点对点直连:最原始的方式。每个数据生产者为每一个数据的消费者单独提供一个接口。结果就是系统之间形成一个复杂紧密的蜘蛛网。任何一个消费者系统变更或宕机都可能影响生产者;而且每新增一个新的消费者,就需要修改生产者的代码,重新部署。
- 传统消息队列:引入了一个"中间人"(消息代理),生产者将消息发送到代理,消费者从代理获取消息。这样生产者和消费者就解耦了。但是当面对海量实时数据时,局限性就体现出来了:
- 吞吐量瓶颈:传统消息队列设计重点是可靠传递,而不是高吞吐量。当消息量大时,队列容易瓶颈;
- 消息堆积能力弱:传统队列通常将消息放在内存中,即使持久化也不是为海量数据存储设计。如果消费者消费速度慢,消息积压会导致内存爆满。
- 扩展性弱:传统队列难以水平扩展。
所以,Linkedln需要一个新的系统来解决以下问题:
- 高吞吐量:能处理每秒数百万条消息读写。
- 水平可扩展:通过简单地增加机器来提升容量和性能。
- 持久化存储:消息不能只存在内存里,要持久化后允许消费者延迟消费。
- 高容错:不能因为一台机器挂了就丢失数据或服务不可用。
- 支持多消费者:一条消息可以被多个不同的消费者独立消费且互不影响。
于是,Kafka就诞生了。它被设计为一个分布式、基于发布---订阅模式的、可以持久化海量数据的流平台。不仅是一个消息队列,更是一个实时数据流的中枢。
Kafka的定义
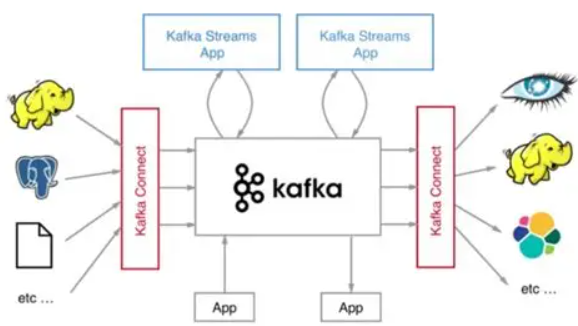
简单就是一个分布式流处理平台。从三个层面理解:
- 一个分布式发布---订阅消息系统:这是最基本的功能。生产者发布消息到某个主题,消费者订阅这些主题来接收信息。它起到解耦、缓冲、异步通信的作用。
- 一个高吞吐、可持久化的分布式日志系统:将所有消息以追加日志的形式顺序写入磁盘。这种结构简单高效,且信息可以被长期保留,供后续多个消费者按需读取。
- 一个实时流处理平台:Kafka不仅传递数据,还提供了流处理库(Kafka Streaming)和流式SQL引擎(ksqlDB),允许在数据流动过程中进行实时处理、聚合和分析。
综合起来:Kafka 是一个以高吞吐、持久化和水平扩展为设计目标的分布式事件流平台,它充当了现代数据架构中实时数据流的中枢。
Kafka的架构设计
图片来自网络
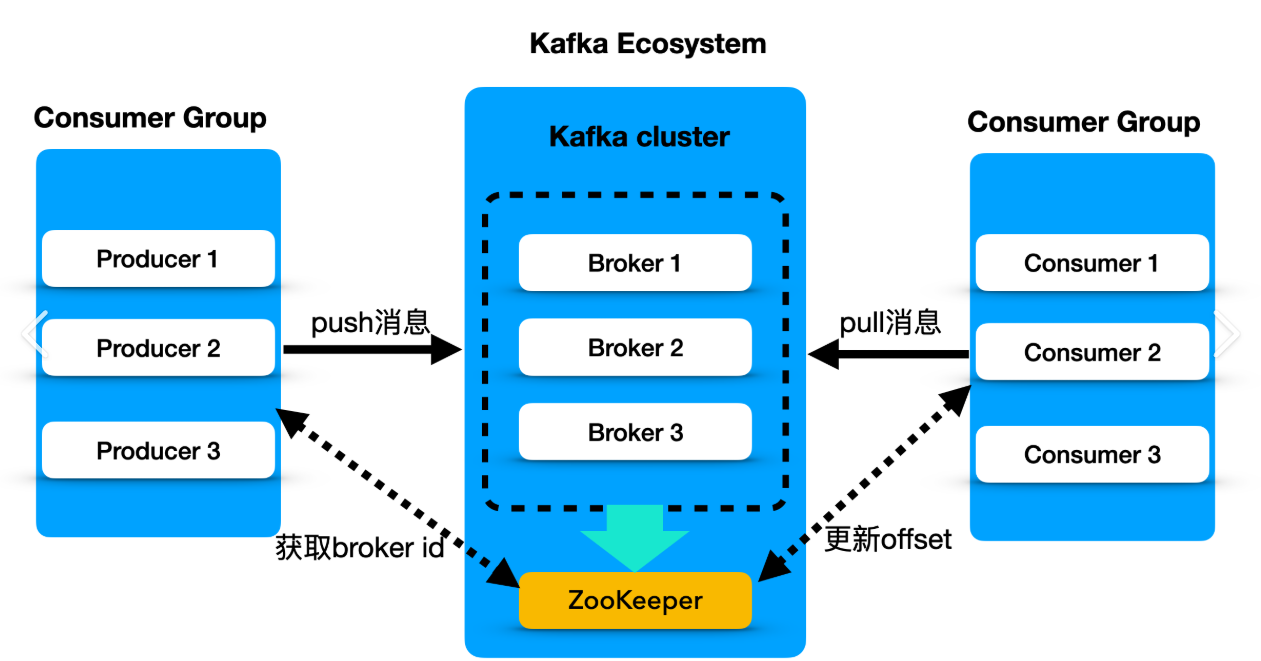
架构角色:
- Producer(生产者):向Kafka发送信息的客户端应用
- Consumer(消费者):从Kafka读取信息的客户端应用
- Broker(代理):Kafka集群中的一个服务节点。一个集群由多个Broker组成,负责接收、存储和提供信息。
元数据管理者:
- ZooKeeper(旧):早期版本,Kafka重度依赖zookeeper,它负责管理Kafka集群的元数据,比如:有哪些Broker活着?每个Topic有多少分区?分区的Leader是谁?等。但也带来了复杂性,因为需要维护两个系统。
- KRaft(新):从Kafka3.0开始,引入了KRaft模式。它是基于Raft共识算法实现的,让Kafka自己管理元数据。
抽象:
- Topic(主题):消息的类别或流的名字。比如user_click(用户点击主题)。生产者发送消息到特定主题,消费者订阅主题来获取信息。
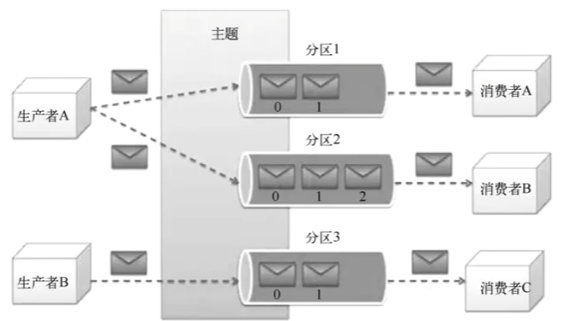
- Partition(分区):
- 每个Topic在物理上被划分为一个或多个Partition。一个分区就是一个有序的、不可变的消息序列。
- 消息在分区内被分配一个唯一的、递增的ID,叫做Offset(偏移量)
- 分区实现并行读写:不同分区可以分布在不同的Broker上,一个Topic的数据就可以被分散到多台机器上,实现了负载均衡和并行处理。生产者和消费者可以同时和多个分区交互,吞吐量自然上去。
- 分区实现水平扩展:当一个Topic吞吐量不够时可以增加它的分区数,将这些分区分布到新的Broker上。
副本机制:
光有分区还不够,如果存放某个分区的 Broker 宕机了,数据就丢失了,服务就中断了。所以 Kafka 引入了副本。
- 每个分区的数据有多个副本,分布在不同的Broker上
- 这些副本中,有一个被选举为Leader,所有读写请求都只与Leader交互。其他副本称为Follower,它们的工作就是不停从Leader同步数据,保持与Leader一致。
- 如果 Leader 所在的 Broker 挂了,Kafka 会自动从 Follower 中选举一个新的 Leader,继续提供服务。这个过程对用户是透明的。这样就保证了高可用性。
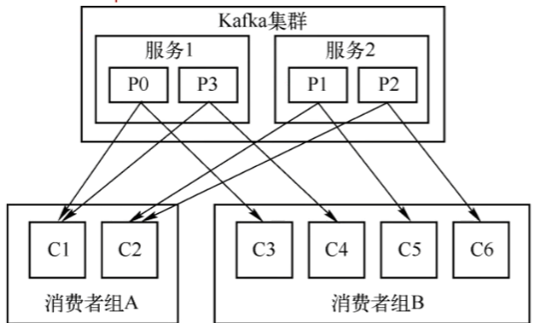
消费者组:
如果只有一个消费者来消费一个有多个分区的Topic,拿着这个消费者就要负责所有分区的数据,可能会成为瓶颈。Kafka使用Consumer Group来实现并行消费和负载均衡。
- 多个消费者可以组成一个消费者组,共同消费一个Topic。
- 规则:一个分区在同一时间只能被同一个消费者组内的一个消费者消费。但一个消费者可以消费多个分区。
- 好处:
- 横向扩展:如果一个消费者组处理速度太慢,可以增加组内的消费者数量(但不能超过分区数),Kafka会自动将分区重新分配,让新的消费者分担工作。
- 负载均衡:分区被平均分配给组内的消费者。
- 多订阅:不同消费者组可以独立消费同一个Topic的全量数据,互不影响,各自维护自己的消费进度。
Kafka的工作原理
一条消息从生产到消费的完整生命周期:
- 生产消息
- 一个Producer应用想要发送一条用户点击信息。
- Producer知道要发送到哪个Topic,并且选择一个Key。如果指定了Key,Kafka会根据Key的哈希值将消息路由发送到对应分区,如果没有Key,则采用轮询策略均匀分布到各个分区。
- Producer连接到任意一个Broker,将消息发送给目标分区的Leader Broker
- 存储信息:
- Leader Broker接收到消息后,将其以追加方式写入该分区的日志文件。
- 消息被赋予一个在该分区内唯一的Offset。
- 同时,该分区的Follower副本会从Leader拉取这条消息,并写入它们自己的日志。一旦所有同步副本都写入成果,这条消息才被认为是"已提交"的。
- 消息会按照配置策略持久化到磁盘上,不会被立即删除。
- 消费信息:
- 一个Consumer Group中的某个Consumer启动,它订阅了这个Topic。
- Kafka会为该消费者组协调,分配它应该消费哪些分区。
- 消费者连接到分区的Leader Broker,告诉它要从确定的Offset位置开始读取
- Broker将消息发送给消费者。消费者处理完这批消息后,会提交当前的Offset。这个Offset提交信息会存储在Kafka的一个特殊内部Topic中,由消费者自己管理。意味着可以回溯到之前的Offset重新消费数据。
- 总结
生产者 -> (根据规则选分区)-> 分区Leader(顺序写入磁盘,同步副本)-> 消费者组(按分配规则拉取,自己管理Offset)-> 消费者应用处理。