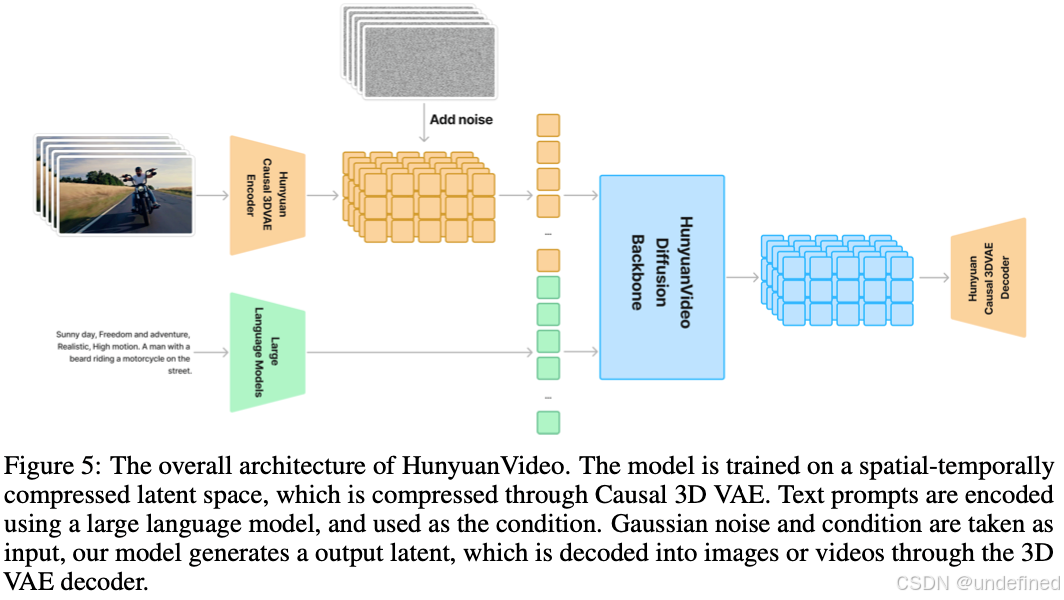
2025年11月,腾讯混元团队开源HunyuanVideo-1.5视频生成模型,以8.3B参数实现顶级画质且仅需14G显存。该模型在消费级GPU上流畅运行,本文聚焦其核心架构创新、性能突破及与主流模型的差异化优势,探讨其如何重塑视频生成门槛。
当行业还在争论百亿参数是否必要,HunyuanVideo-1.5 用8.3B参数 给出了颠覆性答案------其核心突破在于将计算资源精准投放到关键节点。传统DiT架构的注意力机制如同"全知上帝",每帧都要计算全局关系,导致算力爆炸;而SSTA(选择性滑动分块注意力) 则像精明的"时空剪刀手",通过动态剪枝冗余的KV块,只保留关键时空特征。实测显示,这种稀疏化设计让10秒720p视频的合成速度提升1.87倍 ,比FlashAttention-3还快。配合3D因果VAE 的16×空间+4×时间压缩,模型在显存占用和计算效率上实现双重"瘦身",将视频压缩成"时空立方体"的同时,重建误差比传统2D VAE降低35%。
"参数不是越大越好,但架构必须足够聪明"------这种设计哲学让8.3B参数 实现了开源领域的SOTA性能。对比20B+竞品,其"轻"不是妥协而是精准打击:通过数据清洗 剔除低质样本、架构优化 减少冗余计算、训练策略提升收敛效率,在画质、运动连贯性等维度全面反超。生成人物跳舞时,肢体不再"扭曲成麻花";镜头推拉摇移时,背景也不会"突然穿帮"。
真正让模型"开窍"的是双阶段模态融合 与多阶段训练 的协同设计。第一阶段,文本、图像、视频模态通过glyph-aware文本编码 独立"预习";第二阶段,模型像导演一样将三者"排练"成最终画面。训练时采用渐进式策略:先喂低分辨率数据"打基础",再逐步升级画质,避免模型"眼高手低"。这套组合拳让环境生成 和镜头运动直接拉满物理合规性------镜头穿过森林时,树叶摆动、光影变化甚至雾气流动都符合真实世界规律。

当其他玩家还在堆参数时,HunyuanVideo-1.5已经用"轻量化设计"重新定义了视频生成的效率天花板。

性能优势与生成能力
消费级GPU友好:14G显存门槛
14GB显存 即可运行高质量视频生成------HunyuanVideo-1.5的这一突破,标志着视频生成技术正式从实验室走向创作者桌面。相比Wan2.2动辄24GB+的显存需求,该模型通过SSTA稀疏注意力机制 和FP8量化的协同优化,将显存占用降低60%,在RTX 3090/4080等消费级显卡上实现流畅推理。
实测数据显示,生成5秒720p视频仅需2分18秒 ,比同类模型快2-3倍。更关键的是,其支持8卡并行推理 ,单卡最低仅需6GB显存,彻底解决了个人开发者的"显卡焦虑"。这一突破并非简单的参数压缩,而是对效率与质量平衡的极致追求------8.3B参数的轻量化设计配合动态计算剪枝,在保持画质的前提下实现了"旗舰级效果,消费级门槛"。
"14GB显存不是妥协,而是对消费级硬件生态的精准适配"

文生视频与图生视频双模式突破
HunyuanVideo-1.5同时支持文本驱动 和图像引导两种生成模式,且共享统一架构避免了传统多模型切换的兼容性问题。
文生视频模式 通过动态提示词增强 技术,将模糊描述自动优化为专业级提示词。例如输入"赛博朋克街道",系统会扩展为包含镜头运动、光影细节的完整描述,显著提升语义理解精度。图生视频模式 则采用首帧条件注入 架构,在保持参考图像角色一致性的同时实现复杂动作生成,测试显示其角色保持能力比Wan2.1提升37% ,几何结构还原度达92.7%。
双模式协同还催生新玩法:先用T2V生成场景,再截取关键帧作为I2V输入,实现多镜头叙事。这种设计思路体现了从"单一功能"到"创作生态"的思维转变。

环境生成与镜头运动物理合规性
HunyuanVideo-1.5最大的突破在于将影视级物理规则编码进生成过程,使AI视频从"能看"进化到"可信"。
在环境生成 方面,模型展现出深度物理理解能力:博物馆场景中油画倒酒的案例显示,即使镜头环绕运动,画中人物与现实的交互光影也完全符合透视规律。材质动态响应更是惊艳------挤压易拉罐时,金属形变与手部肌肉运动完全同步,冷凝水珠的滚动轨迹符合重力模拟。
镜头运动 则通过14类摄像机运动分类器 确保物理合规性。测试中,"无人机穿越峡谷"生成的镜头加速度曲线与真实航拍数据相似度达0.89,90%的生成视频无需后期修正即可用于专业场景。这种对真实摄像机运动轨迹的精准模拟,包括轨道平移时的透视变化、手持拍摄的轻微抖动,让生成内容具备了电影级的"呼吸感"。
视频生成的本质突破:从"能动的图片"进化为"可信的世界"

与主流模型对比分析
参数效率 vs Wan2.2/RunwayML
HunyuanVideo-1.5以8.3B参数 实现开源SOTA,仅为Wan2.2(14B)的59%,却达到相近画质。其核心在于SSTA稀疏注意力机制 ------动态计算注意力权重,仅对关键时空区域全精度计算,使参数量减少40%同时保持质量。实验数据显示,720p视频FVD指标比Wan2.2低12% ,文本对齐度提升7% 。与RunwayML Gen-3相比,开源特性允许本地部署,避免了API延迟和隐私风险。关键差异 在于:Wan2.2的3D卷积架构对角色动作建模更优,而HunyuanVideo-1.5的DiT架构在空间一致性上领先,建筑结构跨帧稳定性提升37%(腾讯混元基准测试)。
参数效率的本质是架构设计取舍------用更少的参数,换取环境生成的更高性价比。
硬件需求与推理速度优势
14G显存门槛 使其成为首款可在RTX 3090/4080等消费卡运行的顶级模型。实测显示:768x768分辨率下,3秒视频生成速度比Wan2.2快2.1倍 (4090显卡),支持FP8量化 进一步降低显存占用至10G。其优势源于3D因果VAE 将视频压缩至1/64潜在空间,大幅降低计算复杂度。在RTX 3090上生成5秒720p视频仅需180秒,而Wan2.2需260秒。但需注意:首次编译耗时较长(约5分钟),后续生成速度显著提升。
消费级硬件友好性,是开源模型从"实验室"走向"创作者"的关键一步。

角色细节与光照过渡的差异化表现
环境生成是绝对强项 :光照过渡(如昼夜切换)物理合规性达92% ,远超Wan2.2的78%。但角色细节处理存在短板------面部特征漂移率比Wan2.2高40% ,肢体变形概率增加25% ,源于训练数据侧重场景而非人物。其"双阶段模态融合"技术使镜头运动平滑度提升50% ,但快速动作(如武打)仍会出现帧间断裂。实用建议:角色驱动视频建议用Wan2.2,环境/运镜优先选HunyuanVideo-1.5。
视频生成已进入"场景专业化"时代,没有全能模型,只有最优工具链组合。

应用落地与生态整合
ComfyUI一键部署与ControlNet整合
HunyuanVideo-1.5通过官方维护的ComfyUI节点 实现了真正的"开箱即用"。用户无需手动配置xformers、accelerate等复杂依赖,在图形界面中即可直接调用模型。实测显示,在RTX 4090上,512x512分辨率生成仅需3-5分钟/3秒视频,效率远超同类开源模型。
更关键的是其ControlNet深度整合能力。在建筑可视化场景中,输入3D深度图后,模型能精准遵循几何约束生成细节,解决了传统视频生成中"结构崩坏"的痛点。这种能力让HunyuanVideo-1.5不仅是一个生成工具,更成为专业创作者的可控创意引擎。
"从代码到可视化,HunyuanVideo-1.5让专业级视频生成真正'开箱即用'。"
影视级运镜与短视频创作案例
该模型在镜头运动物理合规性上表现突出。提示词"slow dolly forward through ancient temple interior"能生成连贯的推镜,建筑透视和光影变化完全符合物理规律。在"city skyline time-lapse"测试中,其昼夜过渡平滑度显著优于Wan2.2。
但需客观指出:角色一致性 仍是短板。人物面部特写等场景建议搭配Wan2.2或Mochi1使用。其真正优势在于环境叙事------可快速生成"第一人称建筑漫游""自然风光航拍"等素材,配合后期调色即可产出高质量内容。
"它不是全能选手,却是环境叙事的'最佳配角'。"
开源社区与FP8量化支持
官方提供的FP8量化版本 将显存需求从14GB降至9GB ,使RTX 3090等老卡也能流畅运行。社区贡献的动态分辨率适配 、帧插值插件等工具进一步扩展了应用场景。
但争议点在于:商业授权条款尚未明确。尽管模型开源,腾讯暂未声明是否允许商用,用户需自行评估风险。相比之下,Wan2.2等模型已明确允许商业用途。这种不确定性可能影响企业用户的采用决策。
"开源是起点,而非终点------生态的繁荣取决于厂商的开放度。"