DeepSeek-OCR 是 DeepSeek-AI 推出的多模态端到端 OCR 模型 ,核心创新在于提出 "上下文光学压缩" 范式。将文字Token 转化为视觉Token,几千字的文档可从数千文本 token 压缩至 256 个视觉 token,为大型语言模型处理长上下文问题提供全新解决方案。
在开源的github仓库中我们可以看到Deepseek-OCR有两种使用方式,即可以通过 Transformers 进行推理,又可以通过vLLM 进行推理。接下来我们按照步骤进行部署与调用。
下载Deepseek-OCR模型
首先我们登录modelscope.cn/models/deep... 魔塔社区的官网进行OCR模型的下载
js
#首先我们通过命令安装ModelScope
pip install modelscope
#使用modelscope下载模型,我使用的是SDK进行下载,并指定下载到vllm目录中。
model_dir = snapshot_download('deepseek-ai/DeepSeek-OCR',cache_dir='/vllm')下载后如图所示
对仓库实例代码进行克隆
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git
Deepseek-OCR-hf 是直接使用Hugging Face的transformer直接进行调用,仅支持单张图片的OCR解析,但可以通过降精度的方式,让显存小于8G的电脑也能调用。我们重点关注vllm调用。
虚拟环境的构建
本项目我是使用uv进行虚拟环境的管理,我指定创建了python3.12.9的虚拟环境。 并使用source进行环境的激活。
bash
uv venv ds-ocr -- python3.12.9
source ds-ocr/bin/activate依赖包的安装
CUDA我使用的是11.8版本,经测试在4090和3080ti都可以正常运行,若是50系显卡要将CUDA版本改为对应的12.8版本
js
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url
https://download.pytorch.org/whl/cu118
pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl
pip install -r requirements.txt
pip install flash-attn==2.7.3 --no-build-isolation注意:若需在相同环境中运行 vLLM 和 transformers 代码,无需担心此类安装报错:vllm 0.8.5+cu118 要求 transformers>=4.51.1 其中requirements.txt需要cd到对应DeepSeek-OCR-master的路径下。
代码config模型路径的修改
我们点开DeepSeek-OCR-vllm 目录,其中config.py是Tiny、Small、Base、Large、Gundam五种尺寸配置、模型路径、输入输出、默认提示词等的设置文件
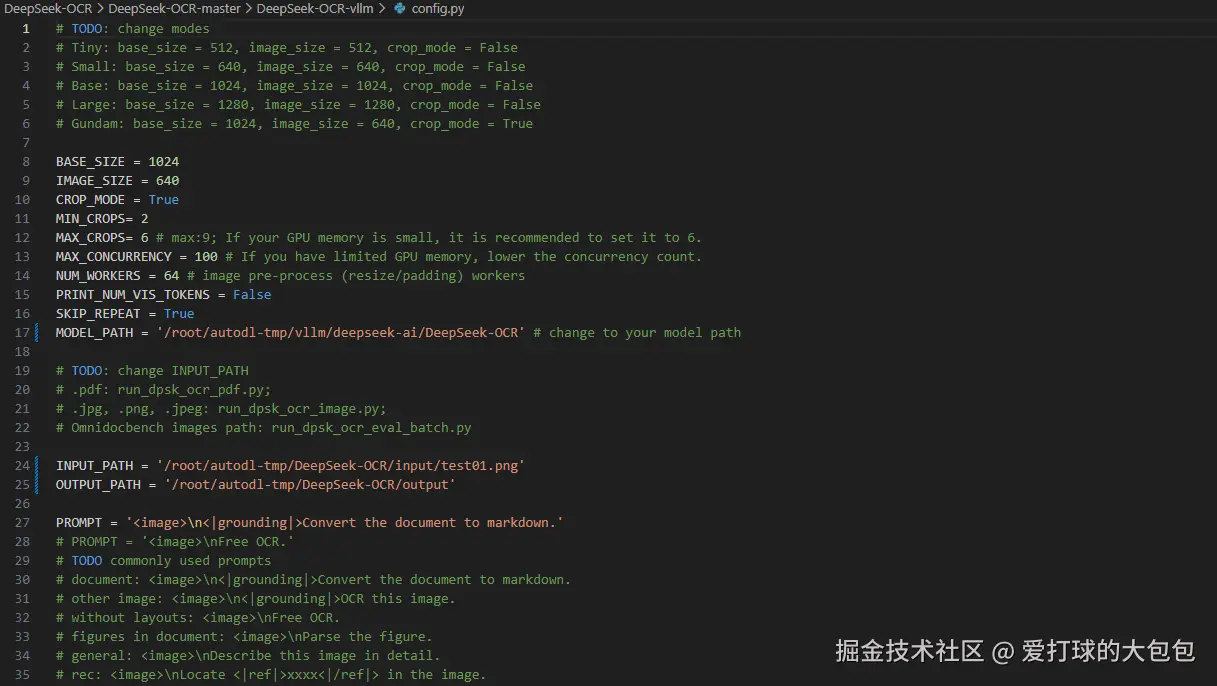 其中我们要将MODEL_PATH 改为模型下载的路径。 接下来我们就可以通过
其中我们要将MODEL_PATH 改为模型下载的路径。 接下来我们就可以通过
python run_dpsk_ocr_image.py 进行图片的解析和markdown的输出。
