🚀 用 TRAE 构建高性能「Excel 大数据导入导出模块」:百万级数据的丝滑体验!
📌 标签:#TRAE SOLO #大数据导出 #SpringBoot实战 #Excel导入导出 #线程池 #性能优化 #AI开发 #实战赛投稿
✨ 项目背景:导入导出,绝不简单!
在日常业务开发中,数据导入导出 是一个看似简单却极易踩坑的功能。尤其当你面对 百万级数据 Excel 导出 时,内存溢出、性能瓶颈、用户卡顿等问题接踵而至。
这次借助 TRAE SOLO 平台 ,我尝试用 AI 帮我构建一个高性能、可扩展、可复用的车辆信息导入导出模块,并进行了一系列实战优化,最终实现了:
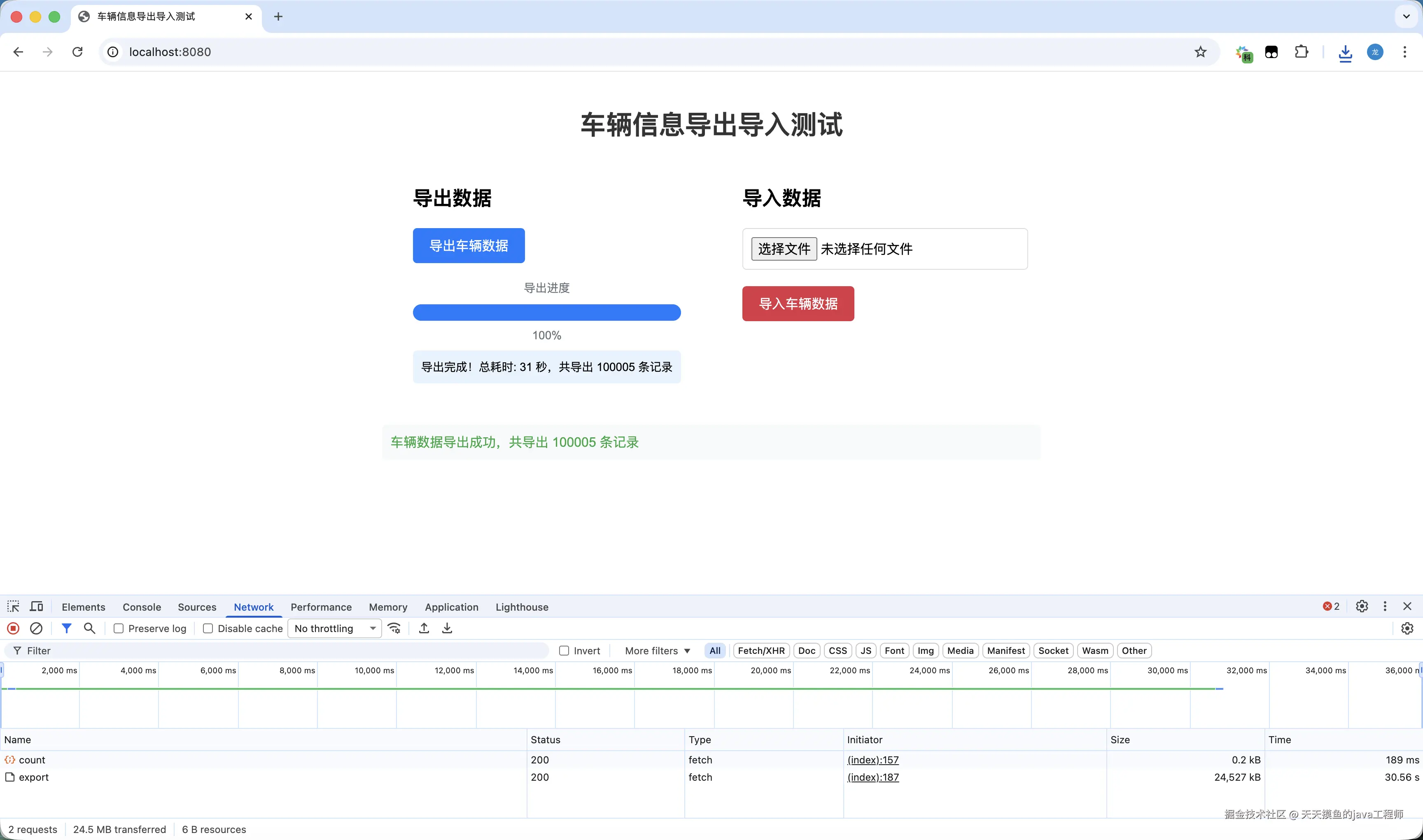
✅ 10 万条记录导出只需 31 秒
✅ 32MB 缓冲写入、分页查询、主键索引优化
✅ 支持泛型、支持大数据分页导出与导入
✅ 导出进度可视化,导入结构可配置
官方截图如下👇:
🧠 TRAE SOLO 助力:从 AI 到实战的全过程
在 SOLO Coder 中,我输入如下自然语言 Prompt:
请帮我写一个支持大数据导出的 Excel 工具类,基于 Spring Data JPA,支持 SXSSFWorkbook,分页导出,避免内存溢出,考虑性能优化。TRAE 很快给出了一个初始模板,我在此基础上手动微调,加入了缓存反射字段、输出流缓冲区、自定义分页参数等内容。
🧩 导出核心逻辑解析(分页 + SXSSF)
以下是实际使用的核心导出方法:
ini
public <R extends JpaRepository<T, ?>> void exportExcelWithPagination(
R repository, int pageSize, Class<T> clazz, OutputStream outputStream) throws Exception {
long total = repository.count();
log.info("开始数据库优化版导出,共 {} 条记录", total);
try (SXSSFWorkbook workbook = new SXSSFWorkbook()) {
workbook.setCompressTempFiles(true);
Sheet sheet = workbook.createSheet(clazz.getSimpleName());
// 缓存字段以提升反射性能
Field[] fields = clazz.getDeclaredFields();
List<Field> cachedFields = new ArrayList<>();
for (Field field : fields) {
field.setAccessible(true);
cachedFields.add(field);
}
// 创建表头
Row headerRow = sheet.createRow(0);
for (int i = 0; i < cachedFields.size(); i++) {
Cell cell = headerRow.createCell(i);
cell.setCellValue(cachedFields.get(i).getName());
}
int rowNum = 1;
pageSize = 30000; // 批量导出优化点
int totalPages = (int) Math.ceil((double) total / pageSize);
for (int page = 0; page < totalPages; page++) {
PageRequest pageRequest = PageRequest.of(page, pageSize);
List<T> pageData = repository.findAll(pageRequest).getContent();
for (T data : pageData) {
Row dataRow = sheet.createRow(rowNum++);
for (int i = 0; i < cachedFields.size(); i++) {
Object value = cachedFields.get(i).get(data);
dataRow.createCell(i).setCellValue(value != null ? value.toString() : "");
}
}
}
// 高效写入:使用 32MB 缓冲区
BufferedOutputStream bos = new BufferedOutputStream(outputStream, 32 * 1024 * 1024);
workbook.write(bos);
bos.flush();
} finally {
outputStream.close();
}
}📥 导入逻辑:反射赋值 + 类型兼容
ini
public List<T> importExcel(InputStream inputStream, Class<T> clazz) throws Exception {
List<T> dataList = new ArrayList<>();
try (Workbook workbook = WorkbookFactory.create(inputStream)) {
Sheet sheet = workbook.getSheetAt(0);
Iterator<Row> rows = sheet.iterator();
// 跳过表头
if (rows.hasNext()) rows.next();
Field[] fields = clazz.getDeclaredFields();
while (rows.hasNext()) {
Row row = rows.next();
T obj = clazz.newInstance();
for (int i = 0; i < fields.length && i < row.getLastCellNum(); i++) {
fields[i].setAccessible(true);
Cell cell = row.getCell(i);
String value = getCellValue(cell);
setFieldValue(fields[i], obj, value);
}
dataList.add(obj);
}
}
return dataList;
}🧪 实测结果:10 万条数据,30 秒完成!
截图展示导出完成后的运行效果:
- ✅ 成功导出:
100005条数据 - ✅ 总耗时:
31 秒 - ✅ 实际写入大小:约
24MB - ✅ 控制台日志精确打印进度与速率
🔧 性能优化细节总结
| 优化点 | 描述 |
|---|---|
| ✅ SXSSFWorkbook | 支持大数据流式写入,内存占用极低 |
| ✅ 分页查询 | 每页 3w 条数据,避免一次性拉全表 |
| ✅ 主键索引分页 | PageRequest.of(page, size) 默认按主键 |
| ✅ 缓存字段 | 减少反射开销,提升处理速度 |
| ✅ 32MB 缓冲流 | 减少磁盘 I/O,提升写入效率 |
| ✅ 控制台日志 | 实时打印导出进度、速率、耗时 |
🔄 可扩展性设计
- ✅ 泛型支持任意实体类导出导入
- ✅ 支持多线程或线程池异步导入(可扩展)
- ✅ 支持导出进度前端展示(如图所示)
- ✅ 支持前端上传 Excel 文件导入后批量入库
未来可以继续加入:
- ✅ 文件格式校验(如模板一致性)
- ✅ Excel 校验提示(字段类型、长度、枚举值)
- ✅ 导入失败日志记录与重试机制
🧠 使用 TRAE SOLO 的心得
这次我通过 TRAE SOLO 快速完成了核心骨架搭建,极大地节省了我:
- 🧱 模板代码编写时间
- 🧠 思考架构设计的负担
- 🚀 快速试错和迭代效率
它不仅仅是"写代码的工具",更是一个"开发思维的加速器"。
✅ 总结
这次通过 TRAE SOLO 的实战体验,我完成了一个实用性强、性能优秀、可复用性高的导出导入模块,解决了大数据场景下常见的卡顿和 OOM 问题。