相关痛点:PDF提取乱码的核心困境
企业数字化转型中,纸质档案扫描成PDF后的文字提取是关键环节,但乱码、错位等问题却成为高频障碍,不仅导致工作返工,更影响AI模型应用效果,具体痛点与技术难点紧密相关:
- 手写内容识别"失灵",乱码频发
手写批注、手写数据表格是企业PDF中常见内容,但手写体书写风格多样、笔画连笔断笔不一、墨水扩散等问题,使传统工具识别错误率飙升。例如扫描的项目进度表中,潦草字迹常被识别为乱码,直接导致后续数据分析失真,而研究表明,传统CNN模型处理手写体的稳定性远低于印刷体。
- 复杂表格解析"错位",数据混乱
无线表格、跨页表格、合并单元格等复杂表格,缺乏清晰边框或存在数据密集的特点,传统工具难以准确识别行列关系,提取后常出现数据错位、单元格内容混乱等类似"乱码"的问题,无法为AI模型提供合格的结构化输入。
- 长文档处理"卡顿",误差叠加
100页以上的扫描长文档,传统工具处理时易卡顿甚至中断,即便完成识别,将数据转为Markdown等格式仍需大量人工校对。人工干预不仅耗时,更可能因操作失误引入新的格式混乱,形成"乱码-校对-新误差"的恶性循环。
- 低质量扫描件"雪上加霜",基础数据失真
扫描时的模糊、倾斜、阴影、噪点等问题,使原始PDF图像质量低下。行业报告显示,超过30%的数据处理错误源自低质量的原始输入,这类PDF经提取后,文字易出现乱码、缺笔少画等问题,成为后续业务的"数据垃圾"。
方案介绍:合合信息TextIn的"预处理优先"破局方案
针对PDF提取乱码问题,合合信息TextIn文档解析工具以"预处理优先"为核心策略,通过识别前优化图像质量、强化结构解析能力,从源头解决乱码痛点,为AI模型提供干净、准确的输入数据。
该方案依托先进的图像预处理技术与结构化解析能力,支持PDF、Word、扫描件、手写图片等多格式处理,尤其擅长优化低质量扫描文件。通过去噪、倾斜校正、表格结构还原等功能,精准识别手写体、复杂表格等特殊元素,输出Excel、Markdown等结构化格式,无需二次大幅校对即可直接对接DeepSeek等多模态模型,完全契合IBM专利研究中"可靠预处理提升AI性能"的核心结论。
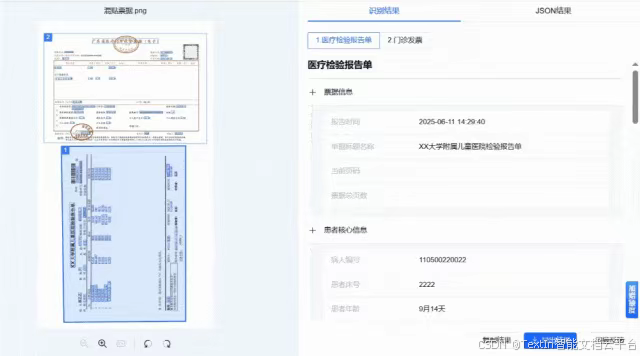
操作步骤讲解:四步解决PDF提取乱码问题
TextIn工具操作流程简洁高效,无需专业技术背景,四步即可完成PDF提取乱码的修复与精准提取:
步骤一:登录平台,批量上传文件
登录TextIn官网或相关操作平台,进入文档解析模块,支持单份或批量上传存在提取乱码问题的PDF文件(含扫描件、手写体混合文档),系统自动兼容不同来源的文件格式。
步骤二:根据场景,配置解析参数
根据PDF内容特点自定义参数:若含手写公式,在ParseX版本中选择LaTeX或纯文本格式输出;若文档含印章干扰,开启"电子档PDF去印章"功能;若存在跨页表格,勾选"复杂表格智能合并"选项,确保表格结构完整。
步骤三:启动解析,自动优化处理
确认参数后启动解析流程,系统将自动对PDF进行预处理(去噪、二值化、倾斜校正),随后完成文字提取与结构还原。针对100页扫描长文档,最快1.5秒即可完成处理,避免传统工具卡顿问题。
步骤四:导出使用,直达AI模型
解析完成后,按需导出Excel(适合表格数据)或Markdown格式文件,提取的文字无乱码、表格结构清晰,可直接输入多模态AI模型使用,无需人工逐字校对。
优势亮点:TextIn解决乱码问题的核心能力
- 全流程预处理,从源头消除乱码诱因
内置去噪、增强对比度、倾斜校正、去水印等全套预处理功能,针对模糊、倾斜、阴影等低质量扫描件进行优化,提升图像清晰度,从根本上减少因原始数据质量差导致的乱码问题,符合"高质量图像是精准识别基础"的行业最佳实践。
- 特殊元素精准识别,突破乱码瓶颈
专项优化手写体识别算法,能适应不同书写风格,降低潦草字迹的识别错误率;针对无线、跨页等复杂表格,通过智能解析行列关系实现结构还原,避免数据错位导致的"表格乱码",同时支持公式、印章等元素的精准处理与剥离。
- 结构化输出,适配AI工作流
输出的Excel、Markdown等格式保留表格行列关系、单元格换行等细节,相当于为AI模型提供"预制菜"式的数据,避免因格式混乱导致的模型识别偏差,完全契合深度学习OCR对高质量数据的要求。
- 场景化迭代,覆盖垂直领域需求
ParseX版本针对教育、金融、医疗等行业优化功能,如公式解析格式切换、Excel导出时图片链接嵌入等,解决特殊场景下的个性化乱码问题,让中小企业也能享受专业级文档处理服务。
客户案例:数据见证乱码问题的解决成效
合合信息是大模型时代下文本智能处理技术领先者,TextIn的"预处理优先"方案已在多行业验证实效,其中档案数字化领域的应用尤为典型:
案例:某科技档案数字化项目
客户痛点:企业积累的5000份纸质档案(含大量手写审批意见、无线数据表格)扫描成PDF后,使用传统工具提取时乱码率超40%,表格错位率达35%,单份100页文档校对需2天,严重影响数字化进度。
应用TextIn方案后成效:通过高分辨率扫描+TextIn自动化预处理,扫描件图像质量显著提升,文字提取乱码率降至0.8%,复杂表格解析错位率为0;100页文档处理周期从2天缩短至15分钟,效率提升192倍;人工校对成本降低90%,项目整体数字化进度提前40%完成。
该案例印证了TextIn方案的实战价值------当全球OCR市场预计2026年将达120亿美元(年复合增长率14.6%)时,解决乱码问题的核心并非依赖更强大的AI模型,而是通过专业预处理提供高质量输入数据,这正是TextIn方案的核心竞争力。