一、为什么需要全局唯一ID
传统的单体架构的时候,我们基本是单库然后业务单表的结构。每个业务表的ID一般我们都是从1增,通过AUTO_INCREMENT=1设置自增起始值,但是在分布式服务架构模式下分库分表的设计,使得多个库或多个表存储相同的业务数据。这种情况根据数据库的自增ID就会产生相同ID的情况,不能保证主键的唯一性。
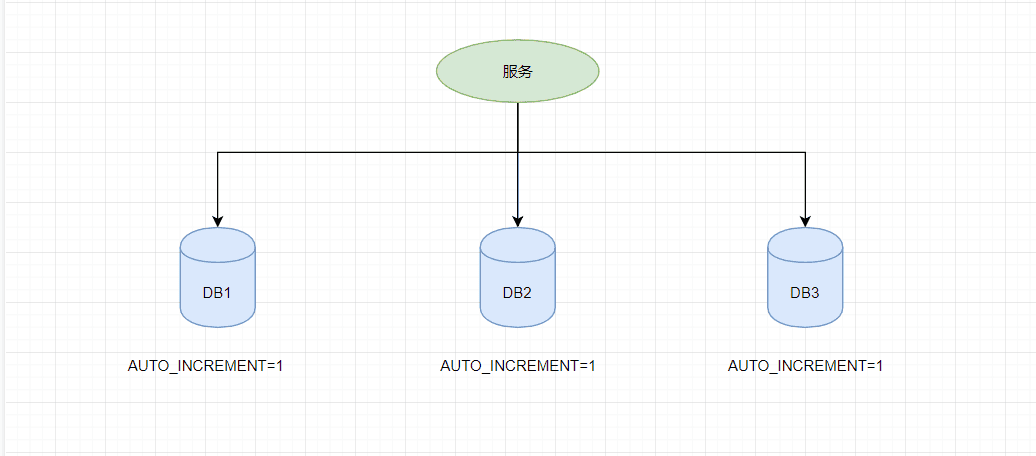
如上图,如果第一个订单存储在 DB1 上则订单 ID 为1,当一个新订单又入库了存储在 DB2 上订单 ID 也为1。我们系统的架构虽然是分布式的,但是在用户层应是无感知的,重复的订单主键显而易见是不被允许的。那么针对分布式系统如何做到主键唯一性呢?
二、UUID
UUID是最直接的主键生成方案,也是面试中必须能够回答出来的基础策略。虽然UUID实现简单,但如果我们想在面试中脱颖而出,就需要深入分析UUID的弊端。UUID主要有两个明显的缺陷。第一个是长度问题,UUID通常占用36个字符,存储空间较大,不过在实际采用UUID的场景中,这个缺点通常不是主要考虑因素。第二个缺陷更为关键,那就是UUID不是递增的,这个弊端是面试时需要重点阐述的内容。
2.1 页分裂
要讲清楚UUID不是递增的弊端,我们需要先理解为什么数据库倾向于使用自增主键。这里的关键词是页分裂。
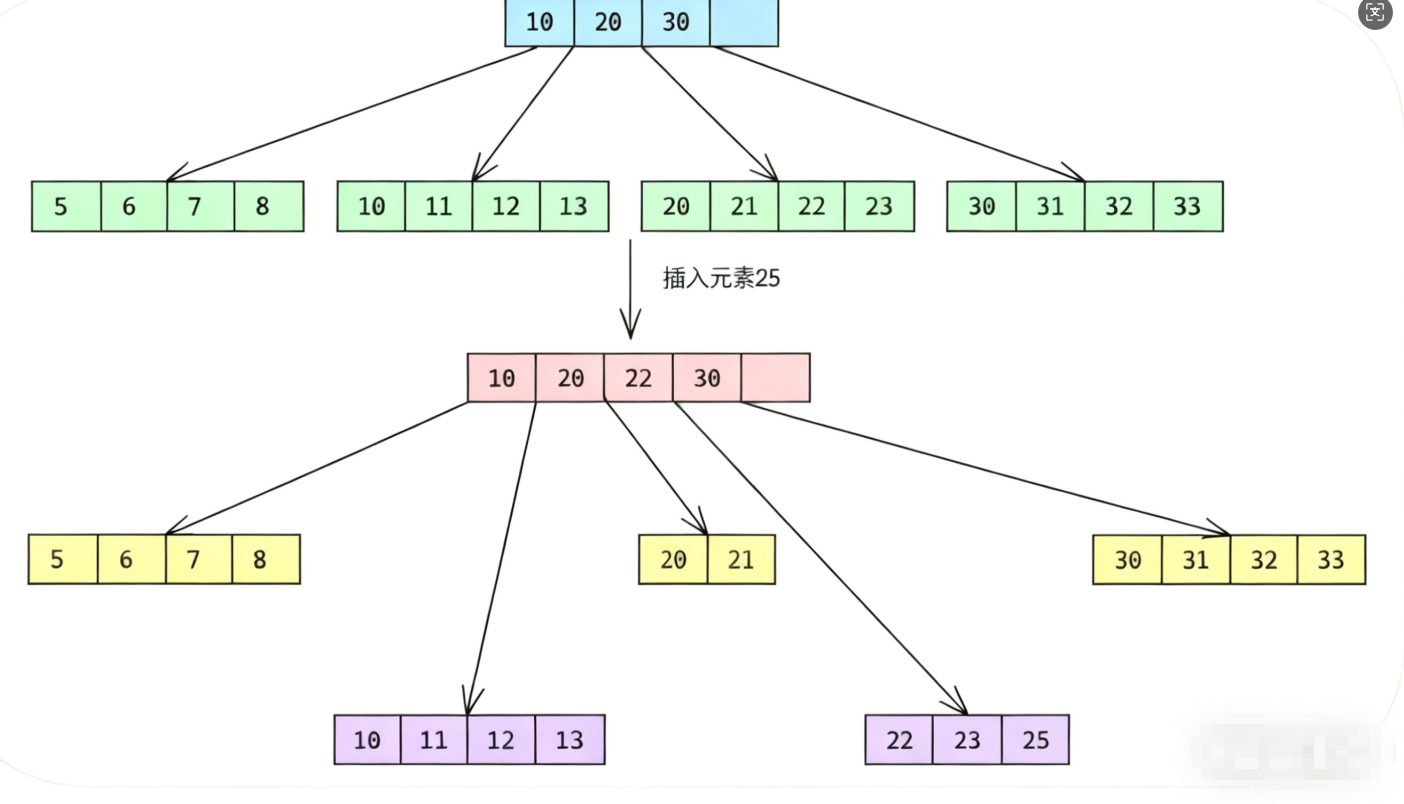
数据库的B+树索引结构中,数据按照主键大小有序存储在叶子节点上。当我们需要插入一条新记录时,如果这条记录的主键值恰好位于某个已满的叶子节点中间,就会触发页分裂操作。比如图中所示,当尝试在23之后插入25时,由于叶子节点已经放满,数据库不得不将这个节点分裂成两个节点,分别存储(20,21)和(22,23,25)。更严重的是,这种分裂可能会引发连锁反应,从叶子节点一直向上分裂到根节点,导致整个树结构都需要调整。
因此,UUID最大的缺陷在于它产生的ID不是递增的。我们倾向于在数据库中使用自增主键,是因为自增主键可以迫使数据库的B+树朝着一个方向增长,新数据总是追加到树的末尾,避免了中间节点的分裂,从而获得最佳的插入性能。而UUID生成的ID在整体上可以看作是随机的,这会导致数据频繁地插入到页的中间位置,引起更加频繁的页分裂操作。在极端情况下,这种分裂可能引发连锁反应,整棵B+树的结构都会受到影响,严重影响插入性能。
三、数据库步长自增方案
除了UUID方案,还有一种常见的方案也叫做自增,不过这种自增比较特殊,它是设置了步长的自增。
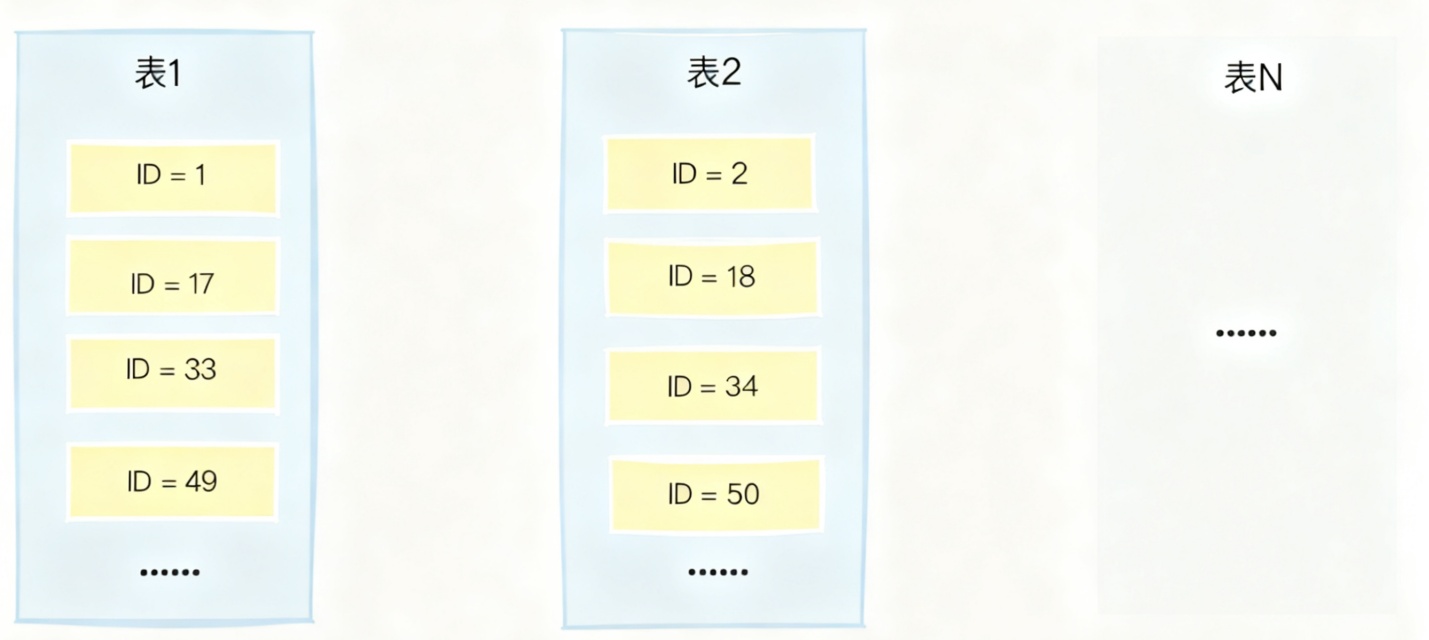
我们可以通过一个具体例子来说明这种方案。假设经过分库分表后,我们有16张表,那么可以让每张表按照不同的步长来生成自增ID。比如第一张表生成1、17、33、49这样的ID序列,第二张表生成2、18、34、50这样的ID序列,以此类推,每张表的起始值不同,但步长都是16。
这种方案的最大优势在于实现简单,应用层基本不需要做任何额外工作,只需要在创建表时指定好不同的起始值和步长即可。虽然生成的ID并不是严格全局递增的,但在单张表内部,ID肯定是递增的,这在一定程度上保证了插入性能。这个方案的性能主要取决于数据库本身的性能,应用层无需过多关注。
四、雪花算法
除了UUID和数据库自增,雪花算法是分布式场景下最经典的主键生成方案。需要注意的是,在当前的技术面试环境中,仅仅答出雪花算法可能已经不够突出,我们需要在理解雪花算法的基础上,找到更多的亮点。
雪花算法的核心思想并不复杂,关键在于分段设计。
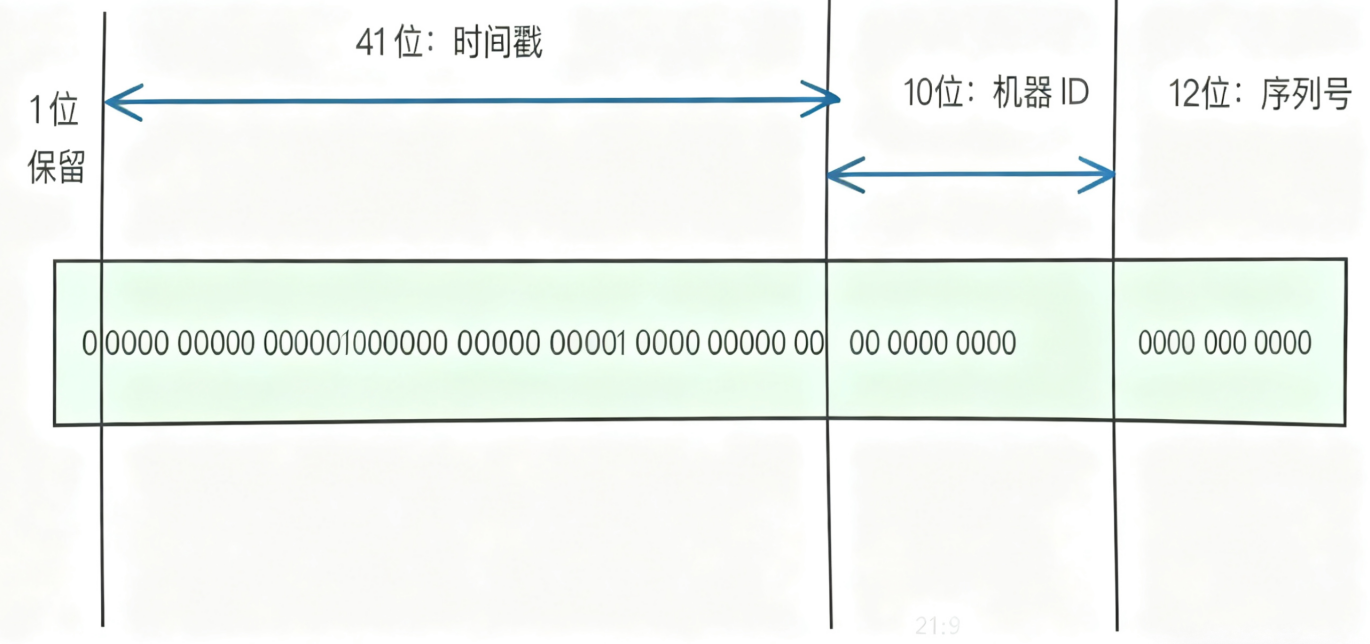
雪花算法采用64位来表示一个ID,其中1位保留未使用,41位表示时间戳,10位作为机器ID,12位作为序列号。这种设计保证了ID的唯一性:时间戳是递增的,不同时刻产生的ID肯定不同;机器ID是不同的,同一时刻不同机器产生的ID肯定不同;同一时刻同一机器上,可以通过序列号来区分不同的ID。
基本解释清楚之后,我们可以从多个方向来展现技术深度,你可以根据自己掌握知识的程度来选择合适的方向。
4.1 灵活调整分段设计
第一个方向是深入讨论每个字段的含义和长度,关键点是根据实际需求自定义各个字段的含义和长度。
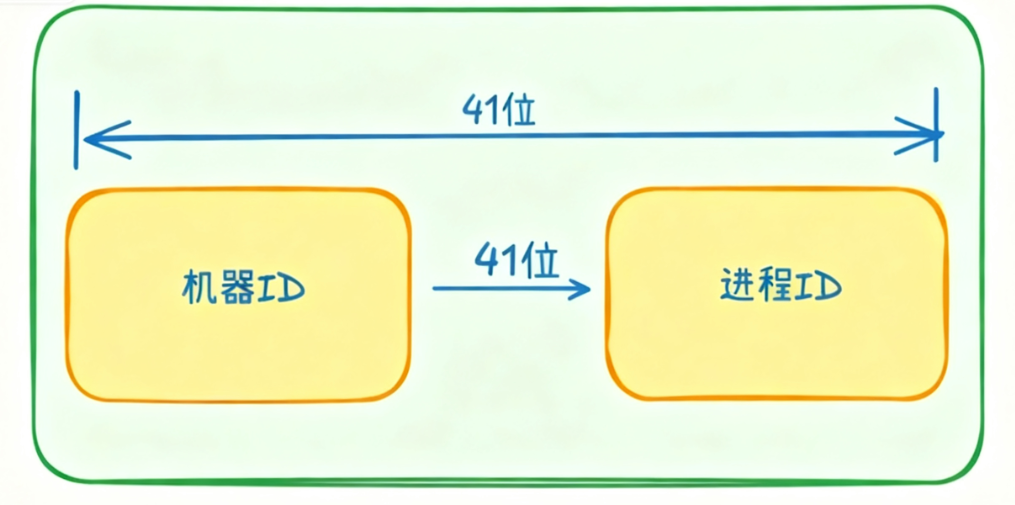
大多数情况下,如果自己设计类似的算法,每个字段的含义和长度都是可以灵活控制的。比如时间戳的41位可以调整得更短或更长,39位也能表示十几年,对于大多数业务场景来说已经足够。机器ID虽然名称上是机器ID,但实际上指的是算法实例,而不是物理机器。比如一台物理机器可以部署多个进程,每个进程的机器ID是不同的;或者进一步细分,机器ID的前半部分表示物理机器,后半部分可以表示该机器上用于产生ID的进程、线程或协程。甚至机器ID也可以不表示机器,而是引入特定的业务含义。序列号的长度同样可以根据实际并发需求进行调整。
总结来说,雪花算法可以看作是一种设计思想,借助时间戳和分段机制,我们可以自由切割ID的不同比特位,赋予其不同的含义,灵活设计符合自己业务场景的ID生成算法。
4.2 序列号耗尽的处理策略
无论怎么设计雪花算法,序列号长度都有可能不够用。比如标准的12位序列号,在并发量极高的场景下,有可能在某个特定时刻,同一台机器上的序列号全部用完。
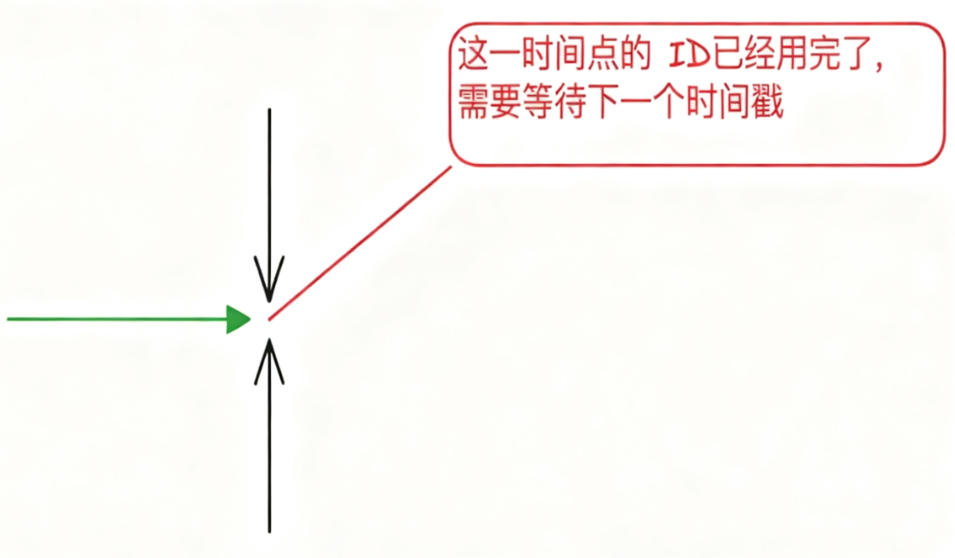
显然,理论上确实存在这种可能性,所以我们需要准备解决方案。解决思路其实并不复杂。如果12位不够用,可以增加序列号的位数,这部分位数可以从时间戳中拿出来。如果还不够,可以让业务方等待到下一个时间戳,时间戳变化后自然又可以生成新的ID了,这实际上是一种变相的限流机制。
一般来说,可以考虑加长序列号的长度,比如缩减时间戳的位数,将节省出来的位数分配给序列号。当然也可以更直接地将64位的ID扩展为128位,甚至更多,这样序列号就可以有三四十位,即便是超大规模的系统也不可能用完。不过,彻底的兜底方案还是要有的。我们可以考虑引入类似限流的做法,在当前时刻的ID已经耗尽之后,让业务方等待下一个时间戳。由于时间戳通常是毫秒级的,业务方最多只需要等待一毫秒。
4.3 数据堆积问题的解决
假设有这样一个场景:你的分库分表策略是按照ID对64取模来进行的,如果业务非常低频,以至于每个时刻都只生成了尾号为7的ID,那么是不是所有数据都会分到同一张表中呢?
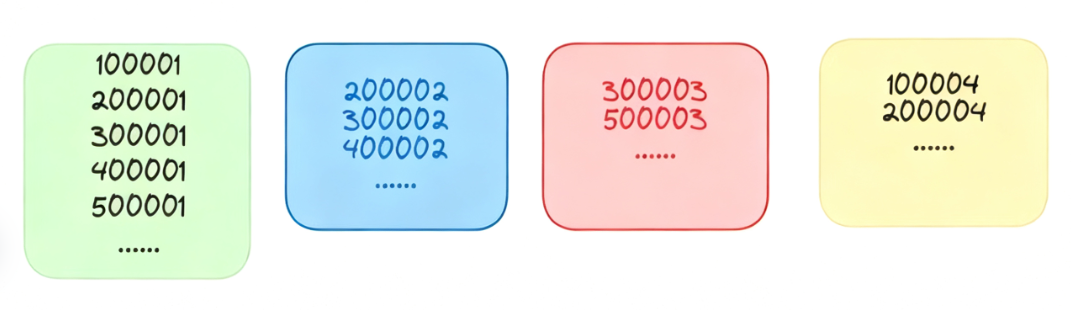
确实会出现这种情况,不过解决方案也很简单。第一种方案是在每个时刻使用随机数作为序列号的起点,而不是每次都从0开始计数。第二种方案是使用上一个时刻的序列号作为起点,比如上一个时刻的序列号只增长到5,那么下一个时刻的序列号就从6开始。如果上一个时刻的序列号已经很大了,就可以退化为从0开始。
看起来第一种方案比较合理常规,但是相比之下第二种实际上更加可控,性能也更好。
因为在低频场景下,很容易出现序列号几乎没有增长的情况,从而导致数据在经过分库分表后只落到某一张表中。为了解决这个问题,可以让序列号部分不再从0开始增长,而是从一个随机数开始增长。还有一个策略是序列号从上一时刻的序列号开始增长,但如果上一时刻序列号已经很大了,就可以退化为从0开始增长。这样比随机数更可控,性能也更好。
五、时钟回拨问题
时钟回拨是指系统时钟由于某种原因(如人为调整、NTP同步错误等)突然倒退,这可能导致雪花算法生成的ID重复。处理时钟回拨的常见策略包括:
- 记录上一次生成ID的时间戳:每次生成ID时,比较当前时间戳与上一次的时间戳,如果检测到回拨,则拒绝生成ID或等待时间追上。
- 使用逻辑时钟:逻辑时钟保证总是递增,不依赖系统时钟。但需要额外的机制来同步和持久化逻辑时钟。
5.1 Java实现雪花算法
以下是雪花算法的Java实现,包括处理时钟回拨的逻辑:
java
java复制代码
public class SnowflakeIdGenerator {
// 起始时间戳(2020-01-01 00:00:00 的 Unix 时间戳)
private final long twepoch = 1577836800000L;
// 机器ID所占的bit数
private final long workerIdBits = 10L;
// 数据中心ID所占的bit数
private final long datacenterIdBits = 10L;
// 支持的最大机器ID数量,结果为1024 (这个位数的机器ID最多1024个(0-1023))
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 支持的最大数据中心ID数为1024
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
// 序列在ID中占的位数
private final long sequenceBits = 12L;
// 机器ID向左移12位
private final long workerIdShift = sequenceBits;
// 数据中心ID向左移22位
private final long datacenterIdShift = sequenceBits + workerIdBits;
// 时间戳向左移22位
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
// 生成序列的掩码,这里位运算保证只取12位
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
private long workerId;
private long datacenterId;
private long sequence = 0L;
private long lastTimestamp = -1L;
public SnowflakeIdGenerator(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
// 产生下一个ID
public synchronized long nextId() {
long currentTimestamp = timeGen();
if (currentTimestamp < lastTimestamp) {
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - currentTimestamp));
}
if (currentTimestamp == lastTimestamp) {
// 如果在同一毫秒内
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
// 阻塞到下一个毫秒
currentTimestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = currentTimestamp;
return ((currentTimestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence;
}
// 阻塞到下一个毫秒,直到获得新的时间戳
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
// 获取当前时间戳
private long timeGen() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
SnowflakeIdGenerator idWorker = new SnowflakeIdGenerator(1, 1);
for (int i = 0; i < 10; i++) {
long id = idWorker.nextId();
System.out.println(id);
}
}
}六、小结
雪花算法通过时间戳、机器ID和序列号的组合,在分布式环境下生成全局唯一的64位ID。本文介绍了雪花算法的原理、处理了时钟回拨问题的策略,并提供了Java实现。这种算法不仅高效,而且保证了ID的有序性,是大数据量系统中常用的分布式ID生成方案。
Tips: 为了大家快速高效的学习,已经将文章提交到了git仓库,涵盖后端大部分技术,以及后端学习路线,仓库内容会持续更新,建议 Star 收藏 以便随时查看https://gitee.com/bxlj/java-article。