Qwen2.5是阿里云最新推出的开源大型语言模型系列,相比Qwen2,新版本在多个方面实现了显著提升,包括知识掌握、编程能力、数学能力以及指令执行等。
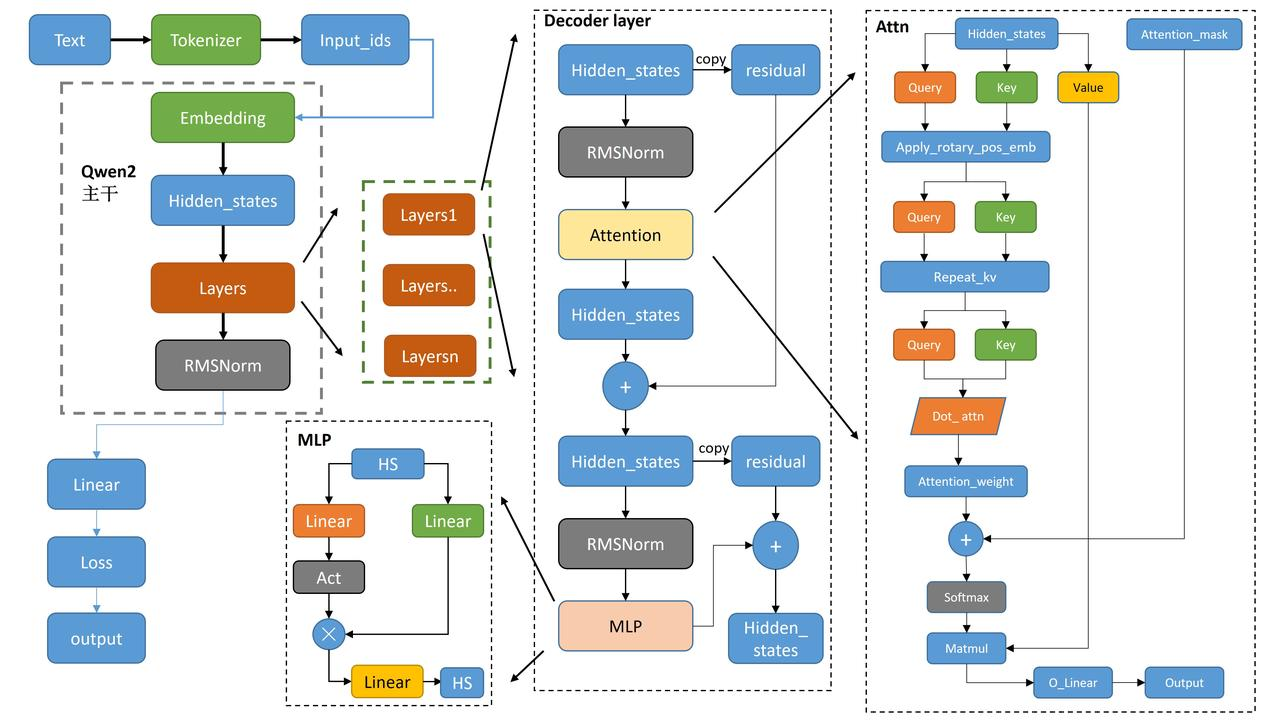
1. Qwen2 整体结构(左侧部分)
1. 文本输入 → Tokenizer → input_ids
-
输入是一串文本
-
Tokenizer 转成整数:
input_ids: (batch, seq_len)
2. input_ids → Embedding 层
将 token id 查表得到向量:
hidden_states: (batch, seq_len, hidden_size)这是 Transformer 第 0 层的初始特征。
3. hidden_states 传入多个 Transformer Layers
每层结构:
RMSNorm
→ Self-Attention
→ 残差连接
→ RMSNorm
→ FFN(MLP)
→ 残差连接每层都更新 hidden_states:
hidden_states = Layer_i(hidden_states)4. Transformer 最后一层输出 → Final RMSNorm
Qwen2(LLaMA 系)在所有层结束后会再加一次最终 RMSNorm:
hidden_states = FinalRMSNorm(hidden_states)作用:
让最后阶段的数值更加稳定(作为 logits 的输入)。
5. Final hidden_states → 线性投影(LM Head)
最后一层的 hidden_states 通过一个线性层(权重与 embedding 通常共享):
logits = hidden_states @ W_vocab^T形状:
logits: (batch, seq_len, vocab_size)例如 vocab_size = 151,000(Qwen2 实际大小)。
6. logits → Softmax → 预测下一个 token
取所有batch的最后一个token在 vocab 上的所有概率 logits。:
probs = softmax(logits[:, -1, :])
next_id = argmax(probs)📌 (伪代码版)
input_ids
↓
token_embedding
↓
hidden_states (layer0)
for layer in transformer_layers:
hidden_states = RMSNorm(hidden_states)
hidden_states = hidden_states + Attention(hidden_states)
hidden_states = hidden_states + FFN(RMSNorm(hidden_states))
# 最后一层输出:
decoder_hidden = hidden_states
logits = decoder_hidden @ token_embedding.weight.T # shape: (batch, seq_len, vocab_size)
# 取最后一个 token logits
last_token_logits = logits[:, -1, :] # shape: (batch, vocab_size)
# Softmax → next token
probs = softmax(last_token_logits, axis=-1)
next_id = argmax(probs, axis=-1) # shape: (batch,)2. Decoder Layer 结构
- Hidden_states 经过 RMSNorm 正则化后,传递给 Attention 模块。
- 在 Attention 模块内,输入分为 Query、Key 和 Value,用于注意力机制的计算。
- 经过 Attention 后的输出再经过另一个 RMSNorm 处理,并通过 MLP(多层感知器)进一步处理。
- 每一步都有残差连接(Residual),保证信息流动不会丢失。
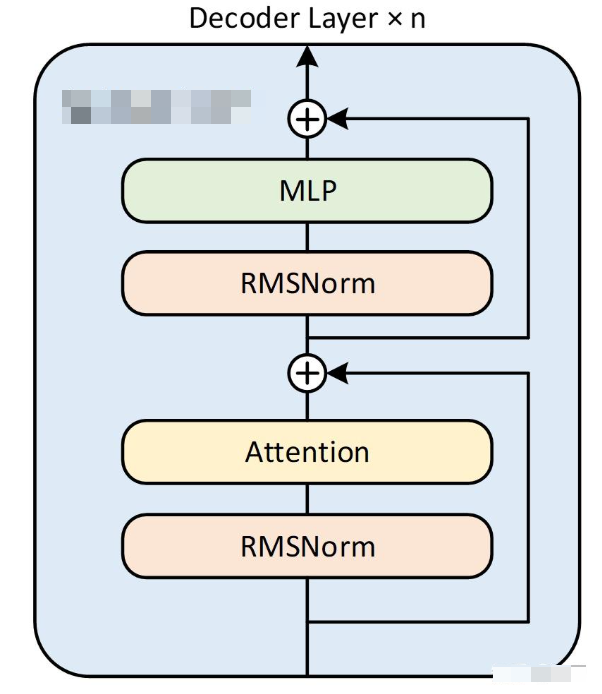
📌 (伪代码版)
powershell
hidden = hidden
hidden = hidden + Attention(RMSNorm(hidden))
hidden = hidden + MLP(RMSNorm(hidden))📌 换成一句话解释:
Decoder Layer 做两件事:
- Attention:让 token "互相看见"
- MLP:非线性建模能力
并且每一步前面都有 RMSNorm、每一步后面都有残差。
3.Attention机制
- Hidden_states 分别生成 Query、Key 和 Value,Q和K应用 Rotary positional embedding
进行位置编码。 - 这些编码后的 Query、Key 和 Value 经过注意力计算,生成 Attention_weight。
- Attention_weight 通过 Softmax 归一化,并与 Value 相乘(Matmul),最后输出为 O_Linear。
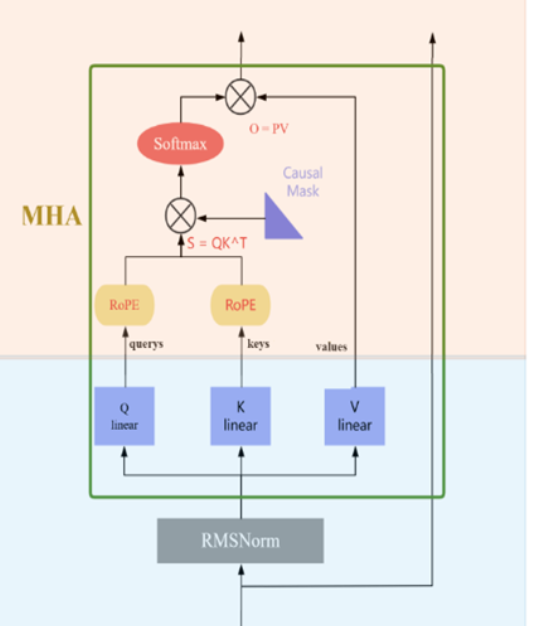
Qwen2 使用 GQA 通过减少 K/V 头数来节省显存并加速推理,同时保持 Query 头数不变,用更少的代价获得接近 MHA 的性能。
| 方案 | Query heads | KV heads | 显存/速度 | 性能 |
|---|---|---|---|---|
| MHA | 32 | 32 | 显存最大、最慢 | 最强 |
| MQA | 32 | 1 | 显存最小、最快 | 有性能损失 |
| GQA | 32 | 8 | 节省 4 倍 KV 缓存 | 接近 MHA 性能 |
4.MLP
Qwen 的 MLP 是一种 门控前馈网络(Gated MLP / SwiGLU MLP),结构如下:
(hidden_size → intermediate_size → hidden_size)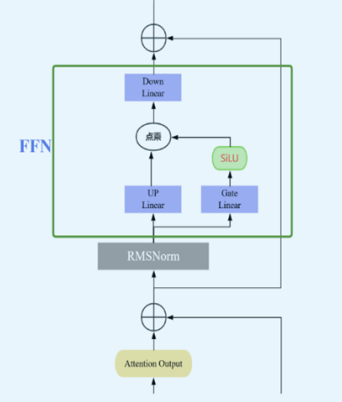
包含三层 Linear 和一个激活函数:
- gate_proj:Linear(hidden → intermediate)
- up_proj:Linear(hidden → intermediate)
- act_fn:SiLU(或其他 activation)
- down_proj:Linear(intermediate → hidden)
Forward 计算流程
MLP 的 forward 逻辑是:
python
hidden = act(gate_proj(x)) * up_proj(x)
output = down_proj(hidden)也就是:
gate_proj(x)送入激活函数(如 SiLU)- 与
up_proj(x)做逐元素相乘(门控) - 再送入
down_proj回到原维度
核心思想
-
不是普通 MLP
不是常规的
Linear → Act → Linear,而是使用 GLU 结构(Gated Linear Unit)。 -
两个上投影:
gate_proj&up_proj其中
gate_proj控制信息的"通过量",相当于一个门(gate)。 -
更强的表达能力,但参数几乎不变
Gated MLP(SwiGLU)在 LLM 中效果显著更好,因此被 LLaMA、Qwen、GPT-NeoX 等广泛使用。
5.输出层
Qwen2 输出层 = RMSNorm(稳定 hidden_states)→ Linear(映射到词表)→ Softmax(得到概率),最终生成 logits,用于预测下一个 token。

| 模块 | 作用 | 输入形状 | 输出形状 |
|---|---|---|---|
| RMSNorm | 对 hidden_states 做尺度归一化 | (batch, seq_len, hidden_size) | (batch, seq_len, hidden_size) |
| Linear (lm_head) | 映射到词表维度 | (batch, seq_len, hidden_size) | (batch, seq_len, vocab_size) |
| Softmax | 生成概率分布 | (batch, seq_len, vocab_size) | (batch, seq_len, vocab_size) |
2.Qwen2-7B的配置参数
powershell
{
"architectures": [
"Qwen2ForCausalLM"
],
"attention_dropout": 0.0,
"bos_token_id": 151643,
"eos_token_id": 151645,
"hidden_act": "silu",
"hidden_size": 3584,
"initializer_range": 0.02,
"intermediate_size": 18944,
"max_position_embeddings": 32768,
"max_window_layers": 28,
"model_type": "qwen2",
"num_attention_heads": 28,
"num_hidden_layers": 28,
"num_key_value_heads": 4,
"rms_norm_eps": 1e-06,
"rope_theta": 1000000.0,
"sliding_window": 131072,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.43.1",
"use_cache": true,
"use_sliding_window": false,
"vocab_size": 152064
}| 参数 | 值 | 说明 |
|---|---|---|
| architectures | "Qwen2ForCausalLM" | 模型类,Qwen2 的自回归语言模型 |
| model_type | "qwen2" | 模型类型标识,用于 Transformers 框架 |
| bos_token_id | 151643 | 句首 token ID(Begin of Sentence) |
| eos_token_id | 151645 | 句尾 token ID(End of Sentence) |
| vocab_size | 152064 | 模型词表大小,也决定输出 logits 维度 |
| tie_word_embeddings | false | 输入 embedding 和输出 lm_head 是否共享权重 |
| hidden_size | 3584 | Transformer 隐层维度 d_model |
| intermediate_size | 18944 | MLP 中间层维度(FeedForward hidden size) |
| hidden_act | "silu" | MLP 激活函数(SiLU / SwiGLU 类型) |
| num_hidden_layers | 28 | Transformer 层数 |
| num_attention_heads | 28 | Query 头数 |
| num_key_value_heads | 4 | Key/Value 头数(GQA,Query 多头共享少量 KV) |
| attention_dropout | 0.0 | 注意力权重 Dropout 概率 |
| rms_norm_eps | 1e-06 | RMSNorm 的 epsilon 防止除零 |
| rope_theta | 1000000.0 | RoPE(旋转位置编码)频率缩放参数 |
| max_position_embeddings | 32768 | 模型最大支持 token 长度 |
| max_window_layers | 28 | 滑动窗口/长序列允许参与的最大层数 |
| sliding_window | 131072 | 滑动窗口总长度(长序列生成时使用) |
| use_sliding_window | false | 是否开启滑动窗口上下文 |
| initializer_range | 0.02 | 权重初始化范围 |
| torch_dtype | "bfloat16" | PyTorch 数据类型,用 bfloat16 节省显存 |
| use_cache | true | 是否在推理时缓存 KV 提升自回归生成速度 |
| transformers_version | "4.43.1" | Transformers 框架版本,用于兼容性 |
3.Qwen源码
1.RMS归一化类
1️⃣ 稳定训练
- RMSNorm 可以 保持每个样本的特征向量在一个稳定的尺度上,避免梯度在深层网络中爆炸或消失。
- 与传统的 LayerNorm 不同,它 不减均值,只归一化均方根,计算更简单,训练更稳定。
2️⃣ 加速收敛
- 归一化后,网络的输入特征分布更均匀,使得优化器更容易更新参数。
- 在 Transformer 类模型中,RMSNorm 可以让模型更快收敛,尤其是在大模型(如 Qwen2)中。
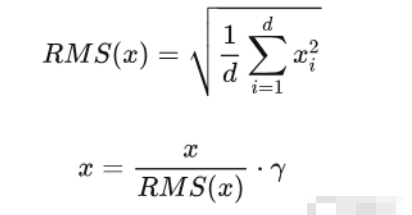
powershell
class Qwen2RMSNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-6):
"""
Qwen2RMSNorm is equivalent to T5LayerNorm
"""
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.variance_epsilon = eps
def forward(self, hidden_states):
input_dtype = hidden_states.dtype
hidden_states = hidden_states.to(torch.float32)
variance = hidden_states.pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
return self.weight * hidden_states.to(input_dtype)2.Attention
python
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
"""
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
"""
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
if n_rep == 1:
return hidden_states
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)1️⃣ 功能
-
作用 :将多组 key/value 张量(
num_key_value_heads)扩展到多头注意力所需的总头数(num_attention_heads)。 -
输入:
hidden_states:形状(batch, num_key_value_heads, seq_len, head_dim)n_rep:每个 key/value head 需要重复的次数
-
输出:
- 形状
(batch, num_key_value_heads * n_rep, seq_len, head_dim) - 逻辑上把每个 key/value head 重复
n_rep次
- 形状
2️⃣ 核心逻辑
python
hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)- 新增维度
None:在 key/value head 后增加一个维度,用于重复 - expand :逻辑上重复
n_rep次 不占用额外显存,共享原始数据
python
.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)- reshape :把
(num_key_value_heads, n_rep)展平为总头数num_key_value_heads * n_rep,方便矩阵乘法计算
3️⃣ 特点
- 高效 :使用
expand + reshape,不会立刻增加显存 - 逻辑复制:每个 key/value head 对应多个 query head(分组注意力)
- 通用性 :适用于多头注意力中 key/value head 少于 query head 的情况
4️⃣ 举例
python
import torch
x = torch.arange(2*2*3*4).reshape(2, 2, 3, 4) # batch=2, kv_heads=2, seq_len=3, head_dim=4
y = repeat_kv(x, 3) # 每个 head 复制3次
print(y.shape) # (2, 6, 3, 4)- 每个 key/value head 被逻辑上重复 3 次,总头数变为 6
- 底层内存仍然是原来的 2 个 key/value head,没有占用 3 倍显存
总结一句话:
repeat_kv用expand + reshape将少量 key/value head 逻辑上复制到多头注意力所需的总头数,高效共享内存,便于分组注意力计算。
python
def eager_attention_forward(
module: nn.Module,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
attention_mask: Optional[torch.Tensor],
scaling: float,
dropout: float = 0.0,
**kwargs,
):
key_states = repeat_kv(key, module.num_key_value_groups)
value_states = repeat_kv(value, module.num_key_value_groups)
attn_weights = torch.matmul(query, key_states.transpose(2, 3)) * scaling
if attention_mask is not None:
causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
attn_weights = attn_weights + causal_mask
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query.dtype)
attn_weights = nn.functional.dropout(attn_weights, p=dropout, training=module.training)
attn_output = torch.matmul(attn_weights, value_states)
attn_output = attn_output.transpose(1, 2).contiguous()
return attn_output, attn_weights经典的GQA,无需多说。
3.MLP
powershell
import torch
import torch.nn as nn
# 定义激活函数映射
ACT2FN = {
"relu": nn.ReLU(),
"gelu": nn.GELU(),
"silu": nn.SiLU(), # Swish 激活
}
# 配置类
class Config:
def __init__(self, hidden_size=8, intermediate_size=16, hidden_act="silu"):
self.hidden_size = hidden_size
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
# Qwen2MLP 模块
class Qwen2MLP(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.intermediate_size = config.intermediate_size
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
self.act_fn = ACT2FN[config.hidden_act]
def forward(self, x):
# GLU 前向传播
return self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
# 测试函数
def test_qwen2mlp():
# 使用 config 创建模型
config = Config(hidden_size=8, intermediate_size=16, hidden_act="silu")
mlp = Qwen2MLP(config)
# 随机输入: batch_size=2, seq_len=4, hidden_size=8
x = torch.randn(2, 4, config.hidden_size)
# 前向传播
output = mlp(x)
print("输入形状:", x.shape)
print("输出形状:", output.shape)
print("输出示例:", output)
# 运行测试
if __name__ == "__main__":
test_qwen2mlp()