文章目录
- 前言
- 一、C++概述
-
- [1.1 什么是 C++?](#1.1 什么是 C++?)
- [1.2 C++ 发展史](#1.2 C++ 发展史)
- [1.3 C++ 的重要性](#1.3 C++ 的重要性)
-
- [为什么 C++ 如此重要?](#为什么 C++ 如此重要?)
- [C++ 的主要应用领域](#C++ 的主要应用领域)
- 二、命名空间
-
-
- [2.1 为什么我们需要命名空间?](#2.1 为什么我们需要命名空间?)
- [2.2 基础语法与定义](#2.2 基础语法与定义)
- [2.3 如何访问命名空间成员](#2.3 如何访问命名空间成员)
-
- [方式一:完全限定名 ------ **最推荐**](#方式一:完全限定名 —— 最推荐)
- [方式二:`using` 声明 ------ 使用using将命名空间中某个成员引入](#方式二:
using声明 —— 使用using将命名空间中某个成员引入) - [方式三:`using` 指令 ------ **谨慎使用**](#方式三:
using指令 —— 谨慎使用)
- [2.4 进阶特性](#2.4 进阶特性)
-
- [A. 嵌套命名空间](#A. 嵌套命名空间)
- [B. 匿名命名空间 ------ **重点**](#B. 匿名命名空间 —— 重点)
- [C. 命名空间别名](#C. 命名空间别名)
- [D. 内联命名空间 ------ **C++11 版本控制神器**](#D. 内联命名空间 —— C++11 版本控制神器)
- [2.5 `std` 命名空间](#2.5
std命名空间) - [2.6 行业最佳实践 (Best Practices) & 禁忌](#2.6 行业最佳实践 (Best Practices) & 禁忌)
-
- [🚫 禁忌:永远不要在头文件 (.h/.hpp) 中写 `using namespace ...;`](#🚫 禁忌:永远不要在头文件 (.h/.hpp) 中写
using namespace ...;) - [✅ 建议:使用具体的 `using`](#✅ 建议:使用具体的
using) - [✅ 建议:ADL (Argument Dependent Lookup) 参数依赖查找](#✅ 建议:ADL (Argument Dependent Lookup) 参数依赖查找)
- [✅ 建议:命名规范](#✅ 建议:命名规范)
- [🚫 禁忌:永远不要在头文件 (.h/.hpp) 中写 `using namespace ...;`](#🚫 禁忌:永远不要在头文件 (.h/.hpp) 中写
-
- [三、 C++ 标准输入输出](#三、 C++ 标准输入输出)
-
- [3.1 核心库与命名空间](#3.1 核心库与命名空间)
- [3.2 标准输出流 (std::cout)](#3.2 标准输出流 (std::cout))
-
- [1\. 基本用法](#1. 基本用法)
- [2\. 自动类型识别 (核心特性)](#2. 自动类型识别 (核心特性))
- [3\. 链式编程](#3. 链式编程)
- [3.3 标准输入流 (std::cin)](#3.3 标准输入流 (std::cin))
-
- [1\. 基本用法](#1. 基本用法)
- [2\. 自动类型匹配与引用传参](#2. 自动类型匹配与引用传参)
- [3\. 空白符处理机制](#3. 空白符处理机制)
- [4\. 链式输入](#4. 链式输入)
- [3.4 std::endl 与 \\n 的区别 (专业细节)](#3.4 std::endl 与 \n 的区别 (专业细节))
- [3.5 扩展:标准错误与日志流](#3.5 扩展:标准错误与日志流)
- [3.6 深度对比:C++ I/O vs C I/O](#3.6 深度对比:C++ I/O vs C I/O)
- [3.7 性能优化](#3.7 性能优化)
- [四、 C++ 缺省参数](#四、 C++ 缺省参数)
-
- [4.1 缺省参数的分类](#4.1 缺省参数的分类)
-
- [1\. 全缺省参数](#1. 全缺省参数)
- [2\. 半缺省参数](#2. 半缺省参数)
- [4.2 核心规则 (重点与考点)](#4.2 核心规则 (重点与考点))
- [4.3 高级陷阱:与函数重载的冲突](#4.3 高级陷阱:与函数重载的冲突)
- [五、 函数重载](#五、 函数重载)
-
- [5.1 重载的构成条件](#5.1 重载的构成条件)
-
- [✅ 正确的代码示例](#✅ 正确的代码示例)
- [❌ 常见的误区 (面试陷阱)](#❌ 常见的误区 (面试陷阱))
- [5.2 重载的二义性](#5.2 重载的二义性)
-
- [1\. 隐式类型转换导致的二义性](#1. 隐式类型转换导致的二义性)
- [2\. 缺省参数导致的二义性 (复习上一章)](#2. 缺省参数导致的二义性 (复习上一章))
- [5.3 底层原理:名字修饰与符号表](#5.3 底层原理:名字修饰与符号表)
- [1\. 核心机制:符号表](#1. 核心机制:符号表)
- [2\. C 语言的死结](#2. C 语言的死结)
- [3\. C++ 的魔法:名字修饰详解](#3. C++ 的魔法:名字修饰详解)
- [4\. 链接阶段的"相亲"过程](#4. 链接阶段的“相亲”过程)
- [5\. 两个高频面试盲区](#5. 两个高频面试盲区)
-
- [Q1: 为什么返回值不参与名字修饰?](#Q1: 为什么返回值不参与名字修饰?)
- [Q2: `extern "C"` 到底做了什么?](#Q2:
extern "C"到底做了什么?)
- [5.4 扩展:extern "C"](#5.4 扩展:extern "C")
- [5.5 总结](#5.5 总结)
- [补充:`CALL` 指令](#补充:
CALL指令) -
-
- [1\. `CALL` 指令的核心动作](#1.
CALL指令的核心动作) - [2\. 配套指令:`RET`](#2. 配套指令:
RET) - [3\. 图解执行流程](#3. 图解执行流程)
- [4\. `CALL` 的几种常见形式](#4.
CALL的几种常见形式) -
- [A. 相对近调用](#A. 相对近调用)
- [B. 绝对间接调用](#B. 绝对间接调用)
- [5\. 汇编代码示例 (x86 风格)](#5. 汇编代码示例 (x86 风格))
- [6\. 关键注意事项](#6. 关键注意事项)
- 总结
- [1\. `CALL` 指令的核心动作](#1.
-
- [六、 引用](#六、 引用)
-
- [6.1 什么是引用?](#6.1 什么是引用?)
- [6.2 引用的三个"铁律" (语法特性)](#6.2 引用的三个“铁律” (语法特性))
- [6.3 常引用 (const 引用)](#6.3 常引用 (const 引用))
- [6.4 使用场景与效率对比](#6.4 使用场景与效率对比)
-
- [1\. 做函数参数 (输出型参数)](#1. 做函数参数 (输出型参数))
- [2\. 做函数参数 (减少拷贝,提高效率)](#2. 做函数参数 (减少拷贝,提高效率))
- [3\. 做函数返回值](#3. 做函数返回值)
- [6.5 深度剖析:引用与指针的区别](#6.5 深度剖析:引用与指针的区别)
-
- [A. 语法层面的区别 (给程序员看的)](#A. 语法层面的区别 (给程序员看的))
- [B. 底层汇编层面的区别 (给机器看的)](#B. 底层汇编层面的区别 (给机器看的))
- 注意:引用底层开空间,语法上不开空间
-
- [1、 语法层面:不开空间 (给程序员看的)](#1、 语法层面:不开空间 (给程序员看的))
- [2、 底层层面:开空间 (给机器执行的)](#2、 底层层面:开空间 (给机器执行的))
- [3、 总结:这一矛盾如何统一?](#3、 总结:这一矛盾如何统一?)
- [6.6 总结](#6.6 总结)
- [七、 内联函数 (inline)](#七、 内联函数 (inline))
-
- [7.1 基本语法与原理](#7.1 基本语法与原理)
- [7.2 核心痛点:C 语言宏函数 vs C++ 内联函数](#7.2 核心痛点:C 语言宏函数 vs C++ 内联函数)
-
- [1. 宏函数的四大缺陷](#1. 宏函数的四大缺陷)
- [2. C++ 内联函数的优势](#2. C++ 内联函数的优势)
- [7.3 空间换时间](#7.3 空间换时间)
- [7.4 编译器的"一票否决权"](#7.4 编译器的“一票否决权”)
- [7.5 工程实践:声明与定义分离的问题](#7.5 工程实践:声明与定义分离的问题)
-
- [❌ 错误示范 (分离写)](#❌ 错误示范 (分离写))
- 原理分析 (结合上一章的编译链接)
- [✅ 正确示范](#✅ 正确示范)
- [7.6 总结](#7.6 总结)
- [八、 auto 关键字 (C++11)](#八、 auto 关键字 (C++11))
-
- [8.1 基本用法](#8.1 基本用法)
- [8.2 推导规则 (核心考点)](#8.2 推导规则 (核心考点))
-
- [1\. 指针与 `auto`](#1. 指针与
auto) - [2\. 引用与 `auto` (重点)](#2. 引用与
auto(重点)) - [3\. const 与 `auto` (难点)](#3. const 与
auto(难点))
- [1\. 指针与 `auto`](#1. 指针与
- [8.3 最佳应用场景](#8.3 最佳应用场景)
-
- [1. 替代冗长的迭代器类型](#1. 替代冗长的迭代器类型)
- [2. 范围 for 循环](#2. 范围 for 循环)
- [8.4 限制与禁忌](#8.4 限制与禁忌)
- [8.5 总结](#8.5 总结)
- [九、 范围 for 循环](#九、 范围 for 循环)
-
- [9.1 基本语法](#9.1 基本语法)
- [9.2 三种核心写法 (最佳实践)](#9.2 三种核心写法 (最佳实践))
-
- [1. 传值遍历](#1. 传值遍历)
- [2. 引用遍历](#2. 引用遍历)
- [3. 常引用遍历 ------ **最推荐**](#3. 常引用遍历 —— 最推荐)
- [9.3 底层原理:它是怎么工作的?](#9.3 底层原理:它是怎么工作的?)
- [9.4 常见陷阱:数组退化为指针](#9.4 常见陷阱:数组退化为指针)
- [十、 typeid 运算符(可暂时忽略)](#十、 typeid 运算符(可暂时忽略))
-
- [10.1 基本准备](#10.1 基本准备)
- [10.2 核心用法](#10.2 核心用法)
- [10.3 静态 vs 动态 (核心考点)](#10.3 静态 vs 动态 (核心考点))
-
- [1\. 静态绑定 (Static Binding)](#1. 静态绑定 (Static Binding))
- [2\. 动态绑定 (Dynamic Binding)](#2. 动态绑定 (Dynamic Binding))
- [10.4 常见陷阱与细节](#10.4 常见陷阱与细节)
-
- [1\. 忽略顶层 const 和引用](#1. 忽略顶层 const 和引用)
- [2\. 名字修饰 (Name Mangling)](#2. 名字修饰 (Name Mangling))
- [10.5 深度对比:typeid vs decltype](#10.5 深度对比:typeid vs decltype)
- 十一、C++中的NULL
-
-
- [1\. `NULL` 的本质](#1.
NULL的本质) - [2\. `NULL` 带来的"二义性"问题](#2.
NULL带来的“二义性”问题) - [3\. 现代解决方案:`nullptr` (C++11)](#3. 现代解决方案:
nullptr(C++11)) - [4\. 总结与对比表](#4. 总结与对比表)
- [5\. 最佳实践建议](#5. 最佳实践建议)
- [1\. `NULL` 的本质](#1.
-
- [注意: `const` 修饰 `typedef` 定义的指针别名](#注意:
const修饰typedef定义的指针别名) -
-
- [1\. 核心陷阱:不是简单的文本替换](#1. 核心陷阱:不是简单的文本替换)
- [2\. 为什么会这样?](#2. 为什么会这样?)
- [3\. 代码演示带来的后果](#3. 代码演示带来的后果)
- [4\. 解决方案](#4. 解决方案)
-
- [方案 A:不要依赖 `const` 修饰别名,直接在 `typedef` 里写清楚](#方案 A:不要依赖
const修饰别名,直接在typedef里写清楚) - [方案 B:使用 C++11 的 `using`(别名声明)](#方案 B:使用 C++11 的
using(别名声明)) - [方案 C:显式书写(在不复杂的场景下)](#方案 C:显式书写(在不复杂的场景下))
- [方案 A:不要依赖 `const` 修饰别名,直接在 `typedef` 里写清楚](#方案 A:不要依赖
- 总结
-
前言
本文介绍c++入门的相关内容。
(【由浅入深】是一个系列文章,它记录了我个人作为一个小白,在学习c++技术开发方向计相关知识过程中的笔记,欢迎各位彭于晏刘亦菲从中指出我的错误并且与我共同学习进步,作为该系列的第一部曲-c语言,大部分知识会根据本人所学和我的助手------通义,等以及合并网络上所找到的相关资料进行核实誊抄,每一篇文章都可能会因为一些错误在后续时间增删改查,因为该系列按照我的网络课程学习笔记形式编写,我会使用绝大多数人使用的讲解顺序编写,所以基础框架和大部分内容案例会与他人一样,基础知识不会过于详细讲述)
一、C++概述
1.1 什么是 C++?
简单来说,C++ 是一门通用的、静态类型的、编译型的编程语言。它由 C 语言发展而来,保留了 C 语言的高效性,同时引入了面向对象(OOP)等现代编程特性。
核心特性
你可以把 C++ 理解为一把"瑞士军刀",它功能强大且多用途:
- 多范式支持 (Multi-paradigm):
- 面向过程: 像 C 语言一样,通过函数一步步执行指令。
- 面向对象 (OOP): 通过 类 (Class) 和 对象 (Object) 来封装数据和行为,支持继承 (Inheritance) 和多态 (Polymorphism)。这是 C++ 最著名的特性。
- 泛型编程 (Generic Programming): 通过 模板 (Templates) 编写可重用于不同数据类型的代码(如 STL 标准模板库)。
- 中级语言 (Mid-level Language): 它既有高级语言的抽象能力(让代码更易读),又有低级语言的硬件操作能力(如直接管理内存、指针操作)。
- 零开销抽象 (Zero-overhead Abstraction): C++ 的设计哲学是"你不用为你不使用的特性付费"。如果你使用了某种高级抽象,它的效率应该和手写汇编代码一样高。
比喻: 如果说 Python 是全自动驾驶汽车(易上手,但限制多),C 语言是手动挡赛车(速度快,但简陋),那么 C++ 就是一辆改装过的 F1 赛车------它拥有极其复杂的仪表盘和控制系统,一旦你掌握了它,你就能跑出极限速度。
1.2 C++ 发展史
C++ 的历史就是编程范式演进的缩影。它并非一成不变,而是随着计算机硬件的发展不断进化。
诞生与早期 (1979 - 1983)
- 起源: 1979年,Bjarne Stroustrup (本贾尼·斯特劳斯特卢普) 在贝尔实验室工作时,为了分析 UNIX 内核,需要一门既高效(像 C)又有良好组织结构(像 Simula)的语言。
- C with Classes: 他创造了"带类的 C",这是 C++ 的前身。
- 命名: 1983年,该语言正式更名为 C++("++"是 C 语言中的自增运算符,寓意为 C 的进化版)。
标准化演进 (Timeline)
C++ 的发展主要通过 ISO 标准委员会的标准化来推动。我们可以将其分为"传统 C++"和"现代 C++"两个阶段:
| 年份 | 版本/标准 | 关键里程碑与特性 |
|---|---|---|
| 1998 | C++98 | 第一个 ISO 标准。 确立了语言的核心,引入了标准模板库 (STL)。 |
| 2003 | C++03 | 主要是对 C++98 的 bug 修复,没有重大新特性。 |
| 2011 | C++11 | 革命性更新 (现代 C++ 的开端)。 引入了 auto 类型推导、Lambda 表达式、智能指针 (Smart Pointers)、右值引用 (Move Semantics)。极大地简化了代码编写,提升了安全性。 |
| 2014 | C++14 | 对 C++11 的完善和小幅扩展。 |
| 2017 | C++17 | 引入了结构化绑定、std::filesystem、并行算法等,进一步提升生产力。 |
| 2020 | C++20 | 又一次重大飞跃。 引入了 Modules (模块) (替代头文件)、Concepts (概念) (约束模板)、Coroutines (协程)。 |
| 2023 | C++23 | 最新标准,继续完善标准库和语言特性。 |
1.3 C++ 的重要性
尽管 Python、Java、Go 等语言非常流行,但在许多关键领域,C++ 依然具有不可替代的霸主地位。
为什么 C++ 如此重要?
- 极致的性能 (Performance): C++ 允许程序员直接管理内存和硬件资源。在对速度要求极高的场景下,C++ 几乎没有对手。
- 确定性 (Determinism): C++ 没有像 Java 或 Python 那样不可控的"垃圾回收 (GC)"停顿,这对于实时系统(如自动驾驶、高频交易)至关重要。
- 庞大的生态系统: 经过 40 年的积累,C++ 拥有无数成熟的库和框架。
C++ 的主要应用领域
- 🎮 游戏开发 (Game Development):
- 3A 大作的核心引擎几乎都是用 C++ 写的(如 Unreal Engine, Unity 的底层)。因为它需要实时渲染复杂的 3D 图形,每毫秒的延迟都不可接受。
- 💻 系统软件与操作系统:
- Windows、macOS、Linux 的核心部分以及各种驱动程序,大量使用 C 和 C++ 编写。
- 🌐 浏览器引擎:
- Chrome (V8 引擎)、Firefox 等浏览器的底层核心都是 C++,为了保证网页加载和 JS 执行的速度。
- 📉 金融高频交易 (HFT):
- 华尔街的交易系统需要以纳秒级的速度处理订单,C++ 是这里的绝对标准。
- 🤖 人工智能与深度学习底层:
- 虽然大家用 Python 写 AI 模型,但 TensorFlow、PyTorch 等框架的底层运算核心 (Backend) 全部是用 C++ (和 CUDA) 编写的,以确保计算效率。
- 🚀 嵌入式与航空航天:
- 从火星探测器到你的智能冰箱,C++ 在资源受限的硬件上运行良好。
二、命名空间
在大型 C++ 项目开发中,命名空间是组织代码、防止命名冲突的核心机制 。理解它不仅仅是为了看懂
using namespace std;,更是为了构建高质量、模块化的软件架构。
2.1 为什么我们需要命名空间?
在 C++ 发明早期,所有的全局标识符(变量名、函数名、类名)都存在于同一个"全局作用域"中。
想象一下,你的项目里写了一个函数叫 init(),你引入了一个第三方库,里面也碰巧有一个函数叫 init()。
这时候,编译器就会报错:重定义 (Redefinition) 。这就是著名的命名冲突 或 全局作用域污染。
命名空间 就像是文件系统中的文件夹。
- 在同一个文件夹下,不能有两个名为
report.txt的文件。 - 但是,如果分别在
Folder_A和Folder_B中,两个report.txt就可以和平共存。
2.2 基础语法与定义
注意:
1.命名空间里面不能包含预处理符号(如#include、#define等),预处理指令(#include、#define等)在编译前由预处理器处理,命名空间是编译器在编译过程中处理的机制
- 编译默认查找变量/函数等顺序:查找路径: 先局部域找 -> 后全局域(包含展开的命名空间)。
3.命名空间是C++中作用域的一种,而不是全局作用域。它提供了一个子作用域来组织代码,避免命名冲突。命名空间本身是全局的,但命名空间内部的标识符(变量、函数、类等)是在命名空间作用域中,而不是全局作用域
使用关键字 namespace 来定义。
cpp
namespace MyProject {
// 命名空间中可以定义变量/函数/类型;
int value = 10;
void func() {
// ...
}
class MyClass {
// ...
};
} // 注意:namespace 结尾不需要分号,这与 class 不同特性:命名空间是"开放"的
你可以在多个地方(甚至多个文件)声明同一个命名空间,编译器会自动把它们合并。
cpp
// File1.h
namespace Audio {
void playSound();
}
// File2.h
namespace Audio { // 并没有重新定义,而是向 Audio 中添加新成员
void stopSound();
}2.3 如何访问命名空间成员
有三种主要方式,按照"推荐程度"从高到低排列:
方式一:完全限定名 ------ 最推荐
使用 作用域解析运算符 ::。这是最清晰、最安全的方式,永远不会产生歧义。
cpp
int main() {
MyProject::func();
int x = MyProject::value;
return 0;
}方式二:using 声明 ------ 使用using将命名空间中某个成员引入
只引入你需要的特定成员。
cpp
using MyProject::func; // 只引入 func,不引入 value
int main() {
func(); // 可以直接使用
// value = 20; // 错误!value 未声明,必须用 MyProject::value
return 0;
}方式三:using 指令 ------ 谨慎使用
引入整个命名空间的所有成员。这是很多初学者最熟悉但最容易滥用的方式。
cpp
using namespace MyProject; // 把 MyProject 里所有东西都倒进当前作用域
int main() {
func();
value = 20;
return 0;
}2.4 进阶特性
作为专业开发者,你需要掌握以下高级用法:
A. 嵌套命名空间
命名空间可以层层嵌套,模拟库的层次结构。
传统写法:
cpp
namespace Game {
namespace Graphics {
namespace Rendering {
void renderFrame();
}
}
}
// 调用:Game::Graphics::Rendering::renderFrame();C++17 简化写法 (Modern C++):
cpp
namespace Game::Graphics::Rendering {
void renderFrame();
}B. 匿名命名空间 ------ 重点
如果定义命名空间时不给名字,它就是匿名的。
作用: 里面的成员只能在当前文件 (编译单元)内访问,外部文件看不见。
专业意义: 这完全替代了 C 语言中 static 全局变量/函数的用法(Internal Linkage)。在现代 C++ 中,推荐用匿名命名空间替代 static。
cpp
namespace {
int internalVal = 42; // 只有当前文件能看到,不会污染外部链接
void internalHelper() { }
}C. 命名空间别名
当嵌套太深或者名字太长时,可以起个短名。
cpp
namespace fs = std::filesystem; // C++17 常用
void checkFile() {
fs::path p = "test.txt"; // 等同于 std::filesystem::path
}D. 内联命名空间 ------ C++11 版本控制神器
使用 inline namespace 定义的子命名空间,其成员会被直接"提升"到父命名空间中。这常用于库的版本控制。
cpp
namespace MyLib {
inline namespace V2 { // 最新版本设为 inline
void foo() { /* V2 implementation */ }
}
namespace V1 {
void foo() { /* V1 implementation */ }
}
}
int main() {
MyLib::foo(); // 默认调用 V2::foo(),因为 V2 是 inline 的
MyLib::V1::foo(); // 显式调用旧版本
}2.5 std 命名空间
C++ 标准库的所有内容(vector, string, iostream 等)都定义在 std 命名空间中。
这也是为什么你在写 cout<<Hello World 时需要 std::cout。
2.6 行业最佳实践 (Best Practices) & 禁忌
这是区分新手和专家的关键点:
🚫 禁忌:永远不要在头文件 (.h/.hpp) 中写 using namespace ...;
如果你在 common.h 里写了 using namespace std;,那么任何 #include "common.h" 的文件都会被迫引入整个 std,这会导致灾难性的全局污染,且极难排查 Bug。
✅ 建议:使用具体的 using
在 .cpp 文件中,为了偷懒可以写 using namespace std;(虽然也不太建议),但在任何地方,更好的习惯是:
cpp
using std::cout;
using std::endl;
using std::string;✅ 建议:ADL (Argument Dependent Lookup) 参数依赖查找
C++ 有一个特殊规则:如果函数参数是某个命名空间里的类型,编译器会自动去那个命名空间找函数。
cpp
// 这就是为什么我们写:
std::cout << "Hello";
// 而不需要写:
std::operator<<(std::cout, "Hello"); // << 其实是 std 里的函数✅ 建议:命名规范
C++ 标准倾向于命名空间全小写(如 std, boost, folly),以区别于类名(通常 CamelCase 如 MyClass)。
三、 C++ 标准输入输出
在 C++ 编程中,输入输出(I/O)并非语言核心语法的一部分,而是由C++ 标准库(Standard Library)提供的。C++ 使用 "流"(Stream)的概念来处理 I/O 操作,数据被视为字节的序列,像水流一样在设备(如键盘、屏幕、文件)和内存之间流动。
3.1 核心库与命名空间
要使用标准输入输出功能,必须包含头文件 <iostream>。
- 头文件:
#include <iostream>- io 代表 Input/Output,stream 代表流。
- 命名空间: 所有的标准库对象都定义在
std命名空间中。- 因此,我们通常使用
std::cout,或者在文件开头使用using namespace std;(注:在大型工程项目中,建议显式使用std::以避免命名冲突)。
- 因此,我们通常使用
3.2 标准输出流 (std::cout)
std::cout 是 ostream 类的对象,代表标准输出,通常指向控制台(屏幕)。
「C++ 输出格式控制 (如 std::fixed, std::setprecision)」较为复杂,建议使用printf
1. 基本用法
使用 流插入运算符 << 将数据发送到 cout。
cpp
#include <iostream>
int main() {
// 输出字符串
std::cout << "Hello C++";
// 输出数字
int age = 18;
std::cout << age;
return 0;
}2. 自动类型识别 (核心特性)
这是 C++ cout 与 C 语言 printf 最大的区别之一。
- C 语言 (
printf): 需要手动指定格式控制符(如%d,%s,%f),容易出错。 - C++ (
cout): 能够自动识别变量的类型,并调用相应的输出重载函数。你不需要告诉它是整数还是浮点数,编译器会自动处理。
3. 链式编程
<< 运算符可以连续使用,这使得在一行代码中输出混合类型的数据非常方便。
cpp
int a = 10;
double b = 3.14;
// 连续输出字符串、整数、字符串、浮点数
std::cout << "Integer: " << a << ", Double: " << b << std::endl;注意:每一个 << 后面紧跟着的,只能是一个单独的数据(或者表达式)。
如果你想连续输出多个不同类型的数据,不能共用同一个 <<,而必须使用多个 << 将它们连接起来。
3.3 标准输入流 (std::cin)
std::cin 是 istream 类的对象,代表标准输入(Standard Input),通常指向键盘。
1. 基本用法
使用 流提取运算符 >> 从 cin 获取数据并存储到变量中。
cpp
#include <iostream>
using namespace std;
int main() {
int x;
// 从键盘读取一个整数放入 x 中
cin >> x;
return 0;
}2. 自动类型匹配与引用传参
与 cout 类似,cin 也会自动识别变量类型。
cin >> x;本质上是调用了函数,并且由于需要修改变量x的值,它是以引用的方式传递参数的。
3. 空白符处理机制
这是 cin 最重要的特性之一:cin 在读取数据时,会自动过滤掉前导的空白字符(空格、Tab 制表符、换行符)。
- 当它读取到有效字符后开始接收,直到再次遇到空白字符时停止读取。
- 示例: 如果你输入
100(前后有空格),cin会准确提取出100。
4. 链式输入
cpp
int a;
double b;
// 用户输入:10 3.14
cin >> a >> b; 3.4 std::endl 与 \n 的区别 (专业细节)
在输出换行时,我们经常看到 std::endl 和 \n,它们虽然都能换行,但在底层机制上有区别:
\n: 仅仅是一个转义字符,只负责将光标移动到下一行。std::endl: 是一个操纵符。- 功能 1: 输出一个换行符
\n。 - 功能 2: 强制刷新缓冲区 (Flush Buffer)。这意味着它会强迫数据立即显示在屏幕上,而不是停留在内存缓冲区中等待。
- 功能 1: 输出一个换行符
专业建议: 在追求高性能的场景(如算法竞赛或大量日志输出)中,建议使用
\n。因为频繁刷新缓冲区(使用endl)会显著降低 I/O 效率。
3.5 扩展:标准错误与日志流
除了 cin 和 cout,<iostream> 还定义了另外两个对象:
std::cerr: 用于输出错误信息。- 特点: 无缓冲 。发送给
cerr的数据会立即显示,确保在程序崩溃前错误信息能被看到。
- 特点: 无缓冲 。发送给
std::clog: 用于输出日志信息。- 特点: 有缓冲 。效率比
cerr高,适合输出非紧急的日志数据。
- 特点: 有缓冲 。效率比
3.6 深度对比:C++ I/O vs C I/O
| 特性 | C++ (cin/cout) |
C (scanf/printf) |
|---|---|---|
| 类型安全 | 高。编译器自动处理类型,不会发生类型不匹配错误。 | 低 。如果 %d 对应了 double 变量,结果未定义甚至崩溃。 |
| 易用性 | 高。无需记忆繁琐的格式控制符。 | 中 。需要记忆 %d, %lf, %s 等。 |
| 扩展性 | 强 。可以通过重载 << 和 >> 支持自定义对象(如输出一个 Student 对象)。 |
弱。只能处理基本数据类型。 |
| 性能 | 默认情况下较慢(为了兼容 C 的 I/O 同步)。 | 较快,直接操作缓冲区。 |
3.7 性能优化
虽然 cin/cout 极其方便,但在默认情况下,为了保证与 C 语言的 stdio 混用时不冲突,C++ 的流会与 C 的流保持同步,这导致了性能损耗。
在算法竞赛 或海量数据读写 场景下,通常使用以下代码来关闭同步,大幅提升速度(提速后性能接近甚至超过 scanf/printf):
cpp
int main() {
// 1. 关闭 C++ 标准流与 C 标准流的同步
std::ios::sync_with_stdio(false);
// 2. 解除 cin 和 cout 的绑定 (防止 cin 自动刷新 cout 缓冲区)
std::cin.tie(nullptr);
// 正常的业务代码...
return 0;
}四、 C++ 缺省参数
在 C 语言中,如果函数定义了 3 个参数,调用时就必须传 3 个参数,少一个都会报错。
C++ 引入了缺省参数 机制,允许在声明或定义函数时为函数的参数指定一个默认值。在调用该函数时,如果没有指定实参,则采用该默认值;否则使用用户传递的实参。
简单理解:这就好比很多软件安装时的"默认安装路径",如果你不自己修改,它就用默认的;如果你指定了新路径,就用你指定的。
4.1 缺省参数的分类
根据默认值的设置情况,主要分为以下两类:
1. 全缺省参数
即函数的所有参数都指定了默认值。
cpp
#include <iostream>
using namespace std;
void Func(int a = 10, int b = 20, int c = 30) {
cout << "a = " << a << ", b = " << b << ", c = " << c << endl;
}
int main() {
// 1. 不传参:全部使用默认值
Func(); // 输出: 10, 20, 30
// 2. 传一个参:a接收1,b、c用默认值
Func(1); // 输出: 1, 20, 30
// 3. 传两个参:a接收1,b接收2,c用默认值
Func(1, 2); // 输出: 1, 2, 30
// 4. 传三个参:全部使用实参
Func(1, 2, 3); // 输出: 1, 2, 3
return 0;
}2. 半缺省参数
即函数只有部分参数指定了默认值。
注意: 这里的"半"并不是指一半,而是指"部分"。
cpp
// 正确的半缺省:必须从右往左给
void Func(int a, int b = 10, int c = 20) {
cout << "a = " << a << ", b = " << b << ", c = " << c << endl;
}
int main() {
Func(100); // a=100, b=10, c=20
Func(100, 200); // a=100, b=200, c=20
// Func(); // 错误!因为 a 没有默认值,必须传参
}4.2 核心规则 (重点与考点)
规则一:必须"从右往左"依次给出
缺省参数不能间隔着给 ,必须从右向左连续赋值。
- 原因: C++ 函数传参是从左往右依次匹配的。如果允许间隔(例如中间缺省,两边有值),编译器在调用时无法判断你传的实参到底是给谁的。
cpp
// ❌ 错误写法 1:中间断开了
void Func(int a = 10, int b, int c = 20);
// ❌ 错误写法 2:左边给了,右边没给
void Func(int a = 10, int b = 20, int c);
// ✅ 正确写法:右边都给了,左边可以不给
void Func(int a, int b = 20, int c = 30);规则二:声明与定义不能同时出现(只能在声明和定义中的某一个位置指定默认值,不能同时指定)
如果函数声明(在 .h 文件)和函数定义(在 .cpp 文件)分开写,缺省参数只能出现在函数声明中,而不能在定义中再次出现(即使值一样也不行)。
- 原因: 编译器会认为你重定义了默认参数。
- 惯例: 我们通常将缺省参数写在声明(头文件)里,因为头文件是对外展示的接口,调用者需要看到默认值。
cpp
// --- test.h ---
// ✅ 声明中给默认值
void Func(int a = 10);
// --- test.cpp ---
// ❌ 定义中如果再写 "= 10" 会报错
// void Func(int a = 10) { ... } -> Error
// ✅ 正确写法:定义时像普通函数一样写
void Func(int a) {
cout << a << endl;
}规则三:缺省值必须是常量或全局变量
默认值必须在编译时就能确定,或者是全局变量。通常我们使用字面量常量(如 10, 3.14, nullptr)。
规则四:C语言不支持
C 语言编译器(如 gcc)不支持缺省参数,这是 C++ 的特性。
4.3 高级陷阱:与函数重载的冲突
缺省参数虽然好用,但如果和函数重载 混用,极易造成二义性,导致编译报错。
场景演示:
cpp
#include <iostream>
using namespace std;
// 函数 1:无参函数
void func() {
cout << "func()" << endl;
}
// 函数 2:带缺省参数的函数
void func(int a = 10) {
cout << "func(int a)" << endl;
}
int main() {
// func(1); // ✅ 调用函数 2,没问题
// ❌ 编译报错:Call to 'func' is ambiguous
// func();
return 0;
}分析:
当你调用 func() 时:
- 它可以匹配函数 1(本身就无参)。
- 它也可以匹配函数 2(虽然有一个参数,但有默认值,可以不传)。
- 编译器无法判断你想调用哪一个,只能报错。
结论: 在设计接口时,尽量避免"无参函数"和"全缺省参数函数"同时存在。
总结
C++ 缺省参数极大地提高了函数调用的灵活性,减少了大量的冗余代码。但在使用时必须谨记 "从右往左" 的原则,并注意在多文件编程中只在声明处指定。
五、 函数重载
在自然语言中,一个词往往有多种含义。比如"洗",我们可以"洗衣服"、"洗车"、"洗碗"。虽然动作名词都叫"洗",但因为对象不同,具体的操作方式也不同。
在 C 语言中,函数名必须唯一,不能重复。这导致了如果我们要实现"计算整数加法"和"计算浮点数加法",必须分别起名为 add_int 和 add_float,非常不便。
C++ 引入了函数重载 机制:在同一作用域中,允许存在多个功能类似但同名的函数,只要它们的参数列表不同即可。 这是一种静态多态。
5.1 重载的构成条件
要构成重载,必须满足以下条件之一(参数列表不同):
- 参数类型不同
- 参数个数不同
- 参数类型顺序不同
✅ 正确的代码示例
cpp
#include <iostream>
using namespace std;
// 1. 参数类型不同
void Add(int a, int b) {
cout << "Add(int, int): " << a + b << endl;
}
void Add(double a, double b) {
cout << "Add(double, double): " << a + b << endl;
}
// 2. 参数个数不同
void Func(int a) {
cout << "Func(int a)" << endl;
}
void Func(int a, int b) {
cout << "Func(int a, int b)" << endl;
}
// 3. 参数类型顺序不同
// 注意:是类型顺序不同,不是形参名字不同
void Print(int a, char b) {
cout << "Print(int, char)" << endl;
}
void Print(char a, int b) {
cout << "Print(char, int)" << endl;
}
int main() {
Add(10, 20); // 自动匹配 Add(int, int)
Add(1.1, 2.2); // 自动匹配 Add(double, double)
Print(10, 'a'); // 自动匹配 Print(int, char)
Print('a', 10); // 自动匹配 Print(char, int)
return 0;
}❌ 常见的误区 (面试陷阱)
注意:仅返回值不同,不能构成重载。
cpp
// 错误示范
int foo(int a) { return a; }
void foo(int a) { } - 原因: 尽管返回值不同,但调用者可以忽略返回值(例如直接写
foo(10);)。此时,编译器无法判断应该调用哪一个函数,因此会产生二义性报错。
5.2 重载的二义性
即使函数定义符合重载规则,调用时也可能报错。主要有两种情况:
1. 隐式类型转换导致的二义性
cpp
void func(int a) {}
void func(float a) {}
int main() {
// func(1.1); // ❌ 报错
}- 分析:
1.1默认是double类型。编译器发现:double转int可以(精度丢失)。double转float也可以(精度丢失)。- 两者代价一样,编译器无法抉择,报错。
- 修正:
func(1.1f)(指定为 float) 或func((int)1.1)(强转为 int)。
2. 缺省参数导致的二义性 (复习上一章)
cpp
void test(int a) {}
void test(int a, int b = 10) {}
int main() {
// test(100); // ❌ 报错
}- 分析: 编译器不知道是调用第一个函数,还是调用第二个函数并使用默认值。
5.3 底层原理:名字修饰与符号表
要真正理解为什么 C++ 支持重载而 C 不支持,我们需要把视角从代码层面移到二进制层面 。在计算机眼中,没有"函数名"这个概念,只有"内存地址"。而连接"名字"和"地址"的桥梁,就是符号表 。
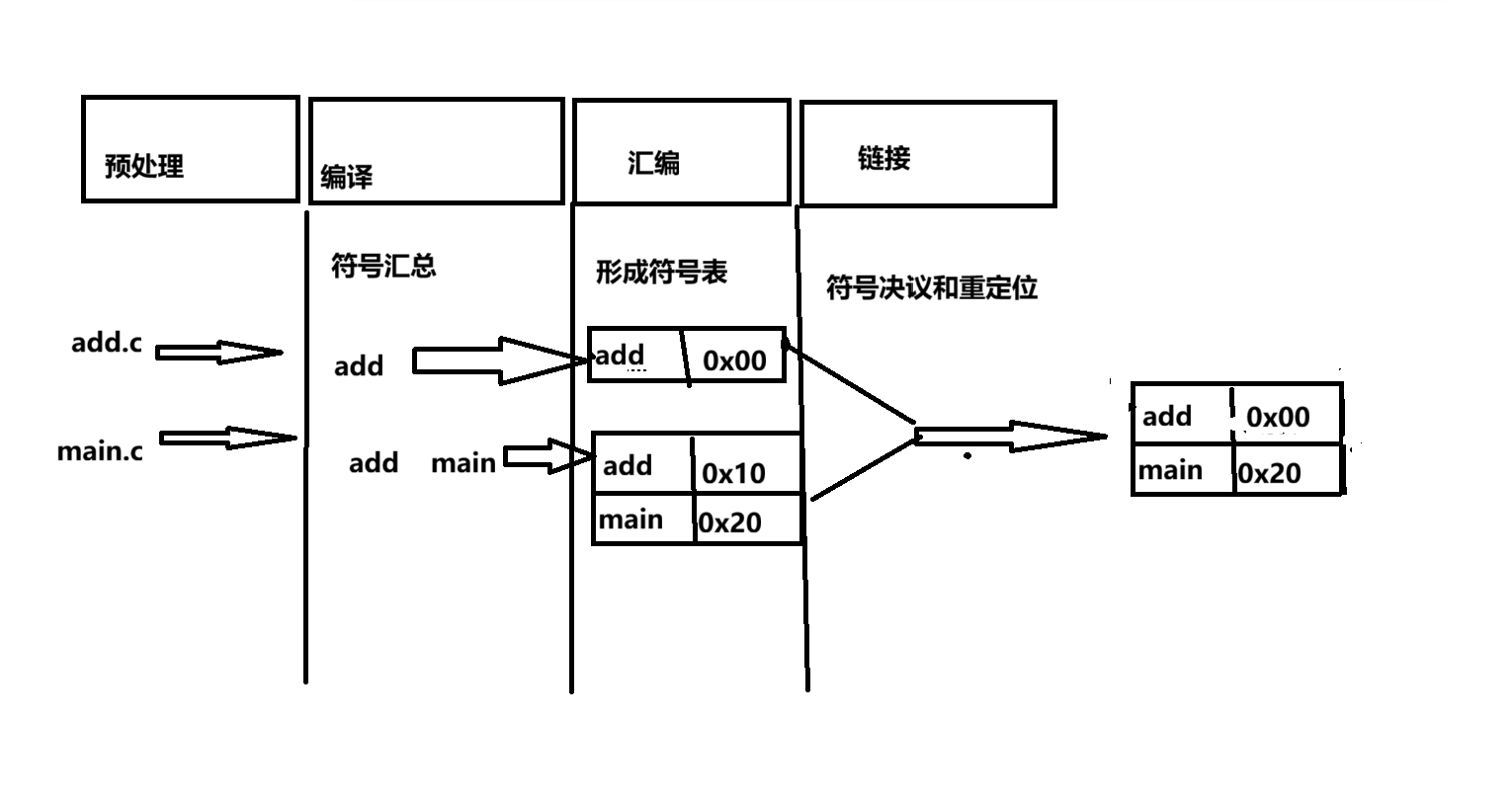
1. 核心机制:符号表
每一个 .cpp 文件被编译成 .o (或 .obj) 目标文件后,内部都维护着两张至关重要的表:
- 定义表 : "我有什么"。
- 记录当前文件定义了哪些函数和全局变量,以及它们在当前文件中的地址偏移量。
- 引用表 : "我缺什么"。
- 记录当前文件调用了哪些外部函数,这些函数的地址目前是空的(或者填了假地址),需要链接器帮我找。
2. C 语言的死结
在 C 语言的规范中,函数名称就是符号名称。
假设你写了两个函数:
void func(int a)void func(double a)
编译器在生成定义表 时,规则非常简单:直接用函数名(或者加个下划线 _)。
- 函数 1 生成符号:
_func - 函数 2 生成符号:
_func
链接器的困境:
当链接器扫描到这两个符号时,发现它们一模一样。链接器无法通过符号名区分参数类型(因为它不记录参数信息),只能报出 "Symbol Redefined"(符号重定义) 错误。
这就是 C 语言无法重载的物理限制。
3. C++ 的魔法:名字修饰详解
C++ 为了支持重载,修改了生成符号的规则。它把函数名 和参数列表 (类型、顺序、个数)编码成了一个独一无二的字符串。这个过程就叫名字修饰。
不同的编译器(GCC vs MSVC)有不同的"加密算法",我们以 Linux 标准(Itanium C++ ABI)为例,因为它最有逻辑性:
规则拆解 (以 GCC 为例)
修饰后的名字通常结构为:_Z + 函数名长度 + 函数名 + 参数类型缩写
| C++ 源代码 | 符号名 (Mangled Name) | 细节拆解 |
|---|---|---|
void func(int x); |
_Z4funci |
_Z: 前缀 4: 函数名长度 func: 原名 i: 第一个参数是 int |
void func(double x); |
_Z4funcd |
d: 第一个参数是 double |
void func(int a, char* b); |
_Z4funcic |
i: 第一个参数 int c: 第二个参数 char (简化示意) |
void Class::foo(int); |
_ZN5Class3fooEi |
N...E: 嵌套作用域(Namespace/Class) 5Class: 类名 3foo: 函数名 |
细节深究:
- 参数类型: 基础类型(
int,float等)有固定字母代码;指针、引用、自定义类会有更复杂的编码。 - const 属性: 如果参数是
const int*,const属性也会被编码进去,导致符号名改变。 - 作用域: 如果函数在类中或命名空间中,类名和空间名也会拼接到符号里。
4. 链接阶段的"相亲"过程
现在我们模拟一下链接器的工作逻辑,看看它是如何精准匹配的:
场景:
main.cpp调用了func(10)。lib.cpp定义了void func(int)和void func(double)。
Step 1: 编译 main.cpp
编译器看到 func(10),参数是 int。根据修饰规则,它生成一条汇编指令:
call _Z4funci (注意:这里直接把需求写成了修饰后的名字)
并在引用表 里记下:"我急需 _Z4funci 的地址!"
Step 2: 编译 lib.cpp
编译器生成两个函数体,并在定义表里记下:
- "我有
_Z4funci,地址是 0x1000。" - "我有
_Z4funcd,地址是 0x2000。"
Step 3: 链接 (Linking)
链接器登场。它拿着 main.o 的需求单(_Z4funci),去 lib.o 的定义表里找。
- 它忽略了
_Z4funcd(名字对不上)。 - 它找到了
_Z4funci,匹配成功! - 它把
0x1000这个地址填回main.o的call指令中。
结论:
对于链接器来说,根本不存在"重载"这回事。它看到的只是两个名字完全不同 的函数(_Z4funci 和 _Z4funcd),就像处理 print_int 和 print_double 一样自然。
5. 两个高频面试盲区
Q1: 为什么返回值不参与名字修饰?
你可能会发现,int func(int) 和 void func(int) 依然会冲突。
深层原因: 虽然技术上可以把返回值编码进符号名(有些小众编译器确实这么干),但在 C++ 语法层面,调用函数时可以忽略返回值。
cpp
func(10); // 既可以是 int func(int),也可以是 void func(int)如果只有返回值不同,编译器在**语法分析阶段(编译早期)**就无法确定调用者到底想调用哪一个,连符号修饰这一步都走不到,直接报"二义性"错误。
Q2: extern "C" 到底做了什么?
当你在 C++ 中写:
cpp
extern "C" void func(int a);你实际上是在告诉 C++ 编译器:"生成这个函数的符号时,请关掉名字修饰开关,使用 C 语言的原始规则(只加下划线)。"
这样,生成的符号就是 _func,而不是 _Z4funci,从而让 C 语言的链接器也能识别并链接它。
5.4 扩展:extern "C"
既然 C++ 修改了函数名,那么:
- 如果 C++ 程序想要调用已经编译好的 C 语言库(如
mylib.lib),怎么办? - C 库里的函数名是
_Add,但 C++ 编译器期待的是_Z3Addii,链接时会报错"无法解析的外部符号"。
这时候就需要使用 extern "C"。
作用: 告诉 C++ 编译器,大括号里包含的函数,请按照 C 语言的规则去编译和链接(不要进行名字修饰)。
cpp
#ifdef __cplusplus
extern "C" {
#endif
// 这里面的函数,编译器会按 C 的规则处理,不修饰名字
void method_in_c_lib(int x, int y);
#ifdef __cplusplus
}
#endif这也是为什么很多 C 语言的官方库头文件里都有这段宏定义的原因(为了兼容 C++)。
5.5 总结
- 定义: 允许同名函数存在,前提是参数列表不同(类型、个数、顺序)。
- 禁区: 仅返回值不同不构成重载。
- 陷阱: 缺省参数和隐式转换容易导致二义性。
- 原理: 名字修饰 (Name Mangling)。C++ 编译器将参数类型编码进符号名中,使得底层符号唯一。
- 应用:
extern "C"用于 C++ 和 C 的混合编程。
补充:CALL 指令
在汇编语言(这里主要以最常见的 x86/x64 架构 为例)中,CALL 指令是实现子程序(函数)调用的核心指令。
它的作用简单来说就是:暂时离开当前执行的代码位置,跳去执行一段子程序,并且保证将来能"找路回来"。
以下是关于 CALL 指令的详细原理解析、执行流程和示例。
1. CALL 指令的核心动作
汇编语言中函数地址 = 函数执行的第一条指令的地址。
当 CPU 执行 CALL 指令时,它并不是简单地跳转(Jump),而是在幕后连续做了两个动作:
- 保存返回地址 :
CPU 会将 紧接着CALL指令后面的那条指令的地址(即当前的指令指针寄存器EIP或RIP的值)压入**栈(Stack)**中。- 目的: 确保子程序执行完后,CPU 知道该回到哪里继续执行。
- 跳转到目标地址:
CPU 将指令指针寄存器(EIP或RIP)修改为目标函数的起始地址。- 目的: 开始执行子程序的代码。
2. 配套指令:RET
CALL 必须和 RET(Return)指令配合使用。
CALL:压栈返回地址 -> 跳转。RET:弹栈(Pop)取出返回地址 -> 赋值给指令指针(EIP/RIP) -> 跳回原处。
3. 图解执行流程
假设我们有如下代码:
assembly
地址 指令
0x1000 MOV EAX, 10
0x1005 CALL 0x2000 <-- 执行这句时
0x100A MOV EBX, EAX <--这是"返回地址"
...
0x2000 FUNC_START: <-- 子程序入口
...
0x2010 RET <-- 子程序结束执行 CALL 0x2000 时的详细步骤:
- 压栈: CPU 看到
CALL指令长 5 个字节(假设),下一条指令在0x100A。CPU 把0x100A这个数值压入堆栈栈顶(ESP 减小)。 - 跳转: CPU 把
EIP寄存器设置为0x2000。 - 执行子程序: CPU 开始从
0x2000处执行代码。 - 返回: 当执行到
RET时,CPU 从栈顶弹出0x100A,将其塞回EIP,程序这就回到了MOV EBX, EAX继续运行。
4. CALL 的几种常见形式
根据目标地址的给出方式,CALL 有几种不同的变体:
A. 相对近调用
这是最常用的形式(如 call MyFunction)。
- 原理: 机器码中存储的是偏移量(目标地址 - 当前地址)。
- 优点: 代码是"位置无关"的(PIC),程序加载到内存任何位置都能运行。
B. 绝对间接调用
目标地址存放在寄存器或内存中。这在 C++ 的虚函数(多态)或函数指针中非常常见。
-
寄存器间接调用:
assemblyMOV EAX, 0x12345678 CALL EAX ; 跳转到 EAX 存储的地址 -
内存间接调用:
assemblyCALL [EBX] ; 跳转到 EBX 指向的内存地址中存储的位置
5. 汇编代码示例 (x86 风格)
这是一个完整的简单示例,展示如何在 main 中调用 add_func。
assembly
section .text
global _start
_start:
; 1. 准备参数 (假设是非标准的寄存器传参)
mov eax, 5
mov ebx, 10
; 2. 调用函数
call add_func ; 此时会将下一行指令地址压栈,并跳到 add_func
; 3. 函数返回后继续执行 (此时 eax 应该是 15)
; 这里可以添加退出程序的代码 (略)
; --- 子程序定义 ---
add_func:
add eax, ebx ; eax = eax + ebx
ret ; 弹出返回地址,跳回 call 的下一行6. 关键注意事项
-
栈平衡 (Stack Balance):
在
CALL之前和RET之后,程序员(或编译器)必须保证堆栈的状态是一致的。如果你在函数里PUSH了很多数据但没有POP干净就调用RET,RET指令就会错误地把数据当成返回地址,导致程序崩溃(Segmentation Fault)。 -
调用约定 (Calling Convention):
CALL只负责跳转和存地址。至于参数怎么传 (是放在寄存器里还是压入栈里?)、返回值放在哪 、栈由谁清理 ,这取决于"调用约定"(如cdecl,stdcall,fastcall等)。- C/C++ 中: 编译器会自动帮我们处理这些
PUSH参数和POP清理的工作。
- C/C++ 中: 编译器会自动帮我们处理这些
总结
CALL=PUSH 下一条指令地址+JMP 目标地址- 它是高级语言中所有函数调用、方法调用的底层实现基础。
六、 引用
在 C 语言中,我们习惯说:"把变量的地址传过去"。
在 C++ 中,我们引入了一个新概念:给变量起个别名。
6.1 什么是引用?
引用 不是新定义一个变量,而是给已存在的变量取了一个别名 。编译器不会为引用变量开辟新的内存空间,它和它引用的变量共用同一块内存空间。
- 生活类比:
- 本名: 李白
- 字(别名): 太白
- 无论是叫"李白"还是叫"太白",指的都是同一个人。你打"太白"一顿,"李白"也会疼。
语法格式:
cpp
类型& 引用变量名 = 引用实体;1.& 左边的部分(例如 int): 是"被引用的实体的类型",也就是原始数据的类型。整体(例如 int&): 才是"引用本身的类型"
2.引用自增自减或者加减乘除运算都是被引用的值进行运算
6.2 引用的三个"铁律" (语法特性)
这是引用使用中必须遵守的规则,也是它和指针在语法层面的核心区别:
-
引用在定义时必须初始化
- 指针可以先定义再赋值,但引用必须"出生即绑定"。
int& b;// ❌ 错误int& b = a;// ✅ 正确
-
一个变量可以有多个引用
- 一个人可以有多个外号。
int& b = a; int& c = a;// b 和 c 都是 a 的别名
-
引用一旦引用一个实体,再不能引用其他实体 (从一而终)
- 这是引用和指针最大的不同。指针可以改变指向,引用一旦绑定,终身不改。
cppint x = 10; int y = 20; int& ref = x; // ref 绑定了 x ref = y; // ⚠️ 陷阱:这里不是让 ref 变成 y 的引用。 // 而是把 y 的值(20)赋值给 ref 绑定的对象(x)。 // 结果:x 变成了 20,ref 依然指向 x。
6.3 常引用 (const 引用)
这是开发中使用频率极高的特性,主要涉及权限控制 和临时对象。
1. 权限的放大与缩小
原则:引用的权限只能缩小或平移,不能放大。
-
权限放大 (错误):
cppconst int a = 10; // a 是只读的 // int& b = a; // ❌ 错误:b 是可读可写的,通过 b 修改 a 会破坏 const 规则。 -
权限缩小 (正确):
cppint x = 20; // x 是可读可写的 const int& y = x; // ✅ 正确:y 是只读的。也就是你可以通过 x 修改,但不能通过 y 修改。
2. 绑定"临时变量" (核心底层细节)
这是一个极容易踩的坑。当引用的类型和源数据的类型不匹配,或者引用一个常量时,会发生什么?
cpp
void Test() {
double d = 3.14;
// int& i = d; // ❌ 错误
const int& i = d; // ✅ 正确!为什么?
}底层原理解析:
当发生类型转换(如 double 转 int)时,中间会产生一个临时变量。
- 编译器把
d的整数部分取出来,放在一个临时变量里。 - 如果不加
const,int& i实际上引用的是这个临时变量。C++ 规定临时变量具有"常性"(即它是临时的,你不应该修改它,修改它没有意义)。 - 所以,必须加
const,让引用变成"只读",才能绑定这个临时变量。
结论:
const引用具有极强的兼容性,它既能接收普通变量,也能接收常量,还能接收不同类型的变量(只要能发生隐式类型转换)。
补充:
在大多数情况下,引用&的左边的类型就是被取别名的变量类型,必须严格相同。但是,存在两个极其重要的"特例",这两个特例恰恰是 C++ 高级特性的基石。**
1. 普通引用 (非 const):必须严格匹配
对于普通的、可读可写的引用(没有 const 修饰),左边的类型必须和右边的变量类型完全一致。
- 原因: 如果类型不同(比如
int和double),它们在内存中的存储方式(二进制位)是完全不同的。如果允许double&引用一个int变量,当你试图通过这个引用去修改数据时,会按照 double 的格式去写 int 的内存,导致内存错乱。
cpp
int a = 10;
// ✅ 类型匹配:正确
int& b = a;
// ❌ 类型不匹配:报错
double& c = a;
// 报错信息通常是:non-const lvalue reference to type 'double' cannot bind to a value of type 'int'2. 特例一:const 引用 (允许类型转换)
const 引用具有极强的兼容性。左边的类型可以和右边不同,只要右边能"被转换"为左边即可。
- 原理: 编译器会生成一个临时变量 。
- 先把
a(int) 转换成double。 - 把结果存到一个临时的
double空间中。 - 让
const double& ref指向这个临时空间。
- 先把
cpp
int a = 10;
// ✅ 允许:const 引用允许不同类型
const double& d = a;
// 本质上编译器做了这件事:
// double temp = (double)a;
// const double& d = temp;3. 特例二:父类引用指向子类对象 (多态的核心)-------(暂时忽略)
这是面向对象编程(OOP)中最重要的特性之一,称为**"向上转型" (Upcasting)**。
- 规则: 父类的引用,可以绑定子类的对象。
- 逻辑: "猫"也是"动物"。所以用"动物"的标签(引用)去指代一只"猫"是合乎逻辑的。
- 左边类型: 父类 (Base)
- 右边类型: 子类 (Derived)
cpp
class Animal { ... };
class Cat : public Animal { ... };
int main() {
Cat myCat;
// ✅ 允许:左边是 Animal,右边是 Cat
// 这种机制让 C++ 实现了"多态"
Animal& ref = myCat;
}总结
| 引用类型 | 左边类型 vs 右边变量类型 | 是否允许不同? | 备注 |
|---|---|---|---|
普通引用 (T&) |
必须严格相同 | ❌ 不允许 | 必须精准匹配,保证内存安全 |
常引用 (const T&) |
可以不同 | ✅ 允许 | 前提是能发生隐式类型转换 (生成临时变量) |
父类引用 (Base&) |
可以是子类类型 | ✅ 允许 | 多态的基础 (向上转型) |
所以,你的理解"左边类型就是被取别名的变量类型"是基础规则 ,但一定要记住 C++ 为了灵活性和多态性开启的这两个后门。
注意: 这里的
&不是"取地址",而是引用类型标识符。
代码验证:
cpp
void Test() {
int a = 10;
int& b = a; // b 是 a 的引用(别名)
1. 值是一样的
// 修改 b,a 也变了;修改 a,b 也变了
b = 20;
// 输出: a=20, b=20
2. 地址是一样的 (核心证据)
// 打印地址会发现完全相同,说明它们对应同一块内存
cout << &a << endl;
cout << &b << endl;
}6.4 使用场景与效率对比
1. 做函数参数 (输出型参数)
C 语言中想在一个函数里修改外面的变量,必须传地址(指针)。C++ 直接传引用。
cpp
// 交换两个数:引用版
// 逻辑清晰,没有任何解引用(*p)操作,像用普通变量一样方便
void Swap(int& r1, int& r2) {
int tmp = r1;
r1 = r2;
r2 = tmp;
}2. 做函数参数 (减少拷贝,提高效率)
当参数是很大的对象(如结构体、类对象)时,传值会发生深拷贝 (没有错,对C++而言),效率极低。传引用相当于只传了个"别名"(底层是地址),没有拷贝代价。
建议: 如果函数内部不需要修改参数,建议写成
const Type&,既保护了数据,又提升了效率。
3. 做函数返回值
作用: 可以让函数调用结果作为"左值"(即放在等号左边被赋值)。
cpp
int x = 10;
// 这个函数返回 x 的"引用"(即 x 的别名/本体)
// 此时,GetRef() 这个函数调用,在逻辑上等同于变量 x 本身
int& GetRef() {
return x;
}
int main() {
// ✅ 正确!
// GetRef() 等价于 x。
// 这行代码相当于:x = 20;
GetRef() = 20;
// 验证一下
cout << "x = " << x << endl; // 输出 20
return 0;
}危险陷阱: 绝对不能返回局部变量的引用!
cpp
int& Add(int a, int b) {
int c = a + b;
return c; // ❌ 严重错误!
}
int main() {
int& ret = Add(1, 2);
// Add 函数结束,栈帧销毁,变量 c 的空间已还给操作系统。
// ret 现在引用的是一块"非法"或"脏"内存。
// 虽然有时候运气好能打印出 3,但这属于"未定义行为",程序随时崩溃。
}规则: 只有当变量的生命周期大于 函数周期(如全局变量、静态变量 static、堆上变量)时,才能返回引用。
6.5 深度剖析:引用与指针的区别
这是面试中最经典的问题。我们需要从语法层面 和底层汇编层面两个角度来回答。
A. 语法层面的区别 (给程序员看的)
| 特性 | 引用 | 指针 |
|---|---|---|
| 初始化 | 必须初始化 | 可以不初始化 (不建议) |
| 指向 | 从一而终,不可改变 | 可以随时改变指向 |
| NULL | 没有空引用 | 可以指向 nullptr |
| sizeof | 结果是引用对象类型的大小 | 结果是地址的大小 (4或8字节) |
| 有多级吗 | 没有二级引用 (&&是右值引用,不是二级) |
有二级指针 (int**) |
| 自增(++) | 引用的实体值 +1 | 指针向后偏移一个类型的大小 |
B. 底层汇编层面的区别 (给机器看的)
这是最颠覆认知的真相:
在汇编代码(机器码)中,引用和指针是完全一模一样的!
- 引用 在底层,实际上就是通过指针来实现的。
- 编译器在编译时,会把引用自动转换为"指针常量"(即指针指向不可变)。
代码对比:
cpp
// 源代码
int& b = a;
b = 20;
int* p = &a;
*p = 20;汇编代码 (伪代码示意):
你会发现,这两段代码生成的汇编指令是一样的,都是:
lea eax, [a](把 a 的地址放入寄存器)mov [b], eax(把地址存起来)- 访问时,都要先取地址,再解引用。
总结:
- 物理上 (底层): 引用就是指针。
- 逻辑上 (语法): 引用是一个不占空间(概念上)、必须初始化、不可改变指向的"别名"。
注意:引用底层开空间,语法上不开空间
1、 语法层面:不开空间 (给程序员看的)
在 C++ 的语法标准概念中,引用只是一个别名。
- 没有独立身份: 它不是一个独立的对象,依附于原变量存在。
- 没有独立大小: 也就是你不需要为这个"别名"额外付费(内存)。
证据 1:sizeof 的欺骗
编译器会刻意向你隐瞒引用占空间的事实。
cpp
double d = 3.14;
double& rd = d;
// 理论上:如果 rd 是底层指针,它应该占 4或8 字节。
// 实际上:sizeof(rd) == 8 (即 double 的大小)。
// 编译器:嘘,别问,它就是 d。
cout << sizeof(rd) << endl; 证据 2:& 取地址的欺骗
你甚至无法获取"引用变量本身"的地址。
cpp
cout << &d << endl; // 0x001
cout << &rd << endl; // 0x001
// 编译器:你要找 rd 的地址?rd 就是 d,所以我给你 d 的地址。2、 底层层面:开空间 (给机器执行的)
虽然编译器在语法上骗了你,但在生成汇编代码(机器码)时,它是诚实的。机器不认识什么"别名",机器只认识地址。
事实:
引用在底层的实现,通常 就是一个指针(常量指针) 。
既然是指针,它当然需要占用空间(32位系统占 4 字节,64位系统占 8 字节)来存储它所指变量的地址。
证据:汇编代码对比 (硬核铁证)
我们写两段代码,一段用指针,一段用引用,看看生成的汇编指令是否一样。
cpp
int main() {
int a = 10;
// 1. 引用操作
int& ra = a;
ra = 20;
// 2. 指针操作
int* pa = &a;
*pa = 20;
return 0;
}对应的汇编代码 (VS2022 x86 也就是 32位环境下):
asm
; --- int& ra = a; ---
lea eax, [a] ; 1. 把变量 a 的地址取出来,放在寄存器 eax 中
mov dword ptr [ra], eax ; 2. 把 eax 里的地址,存入 ra 的内存空间里!
; 【注意】这里证明了 ra 是有自己独立的内存空间的!
; --- ra = 20; ---
mov eax, dword ptr [ra] ; 3. 把 ra 里的地址取出来
mov dword ptr [eax], 14h; 4. 往这个地址指向的地方写入 20 (14h)
; ==========================================================
; --- int* pa = &a; ---
lea eax, [a] ; 1. 把变量 a 的地址取出来
mov dword ptr [pa], eax ; 2. 把地址存入 pa 的内存空间里
; --- *pa = 20; ---
mov eax, dword ptr [pa] ; 3. 把 pa 里的地址取出来
mov dword ptr [eax], 14h; 4. 往这个地址指向的地方写入 20结论:
你会发现,引用的汇编代码和指针的汇编代码是完全一模一样的!
在 CPU 眼里,引用就是一个指针。它确实开辟了空间(栈上的 4 个字节)用来存地址。
3、 总结:这一矛盾如何统一?
| 视角 | 是否开空间 | 解释 |
|---|---|---|
| C++ 语法 (Language) | 不开 | 引用是别名,sizeof(引用) == sizeof(实体),&引用 == &实体。 |
| 底层实现 (Implementation) | 开 | 编译器用指针实现引用,它占用 4 或 8 字节来存地址。 |
为什么 C++ 要这么设计?
是为了简化心智负担。
- 如果 C++ 告诉你引用占用 8 字节,那你就要像管理指针一样去思考它。
- C++ 希望你把它当成"原变量"直接用,把"解引用"和"取地址"的繁琐细节交给编译器在背后偷偷处理(自动解引用)。
唯一的一个例外 (编译器优化):
如果引用仅在局部很少的范围内使用(比如就在几行代码内),聪明的编译器可能会直接把这个引用优化掉,放在符号表里映射一下,这时候可能真的就不开辟内存空间了。但作为通用的底层理解,**"引用底层就是指针"**是绝对没问题的。
6.6 总结
引用是 C++ 对指针的一种"安全封装"。它保留了指针的高效(传地址),摒弃了指针的危险(野指针、空指针)和晦涩(解引用)。
在 C++ 开发中:
- 能用引用,尽量用引用。
- 必须改变指向,或者指向可能为空时,才用指针。
七、 内联函数 (inline)
在讲解内联函数之前,我们需要先了解"函数调用"是有代价的。
当程序调用一个函数时,CPU 需要建立栈帧(Stack Frame)、保存寄存器状态、传递参数、跳转指令......这些步骤都需要时间。
如果一个函数非常短小(比如只有一行代码),但被频繁调用(比如循环调用 100 万次),那么调用函数的开销 甚至可能超过执行函数体本身的时间。
为了解决这个问题,C++ 提供了 inline 关键字。
7.1 基本语法与原理
内联函数 是指在编译时,编译器将函数体直接展开 到调用它的地方,从而消除了函数调用的开销。
- 语法: 在函数定义前加上
inline关键字。
cpp
// 定义内联函数
inline int Add(int x, int y) {
return x + y;
}
int main() {
int ret = Add(10, 20);
// 编译阶段,上面这行代码会被替换为类似这样的直接运算:
// int ret = 10 + 20;
// (没有 call 指令,没有建立栈帧)
return 0;
}7.2 核心痛点:C 语言宏函数 vs C++ 内联函数
这是本章的重中之重 ,也是面试高频考点。
在 C 语言中,为了优化这种小函数,我们通常使用宏函数 (#define) 。但宏函数是由预处理器处理的,只是简单的文本替换,存在巨大的安全隐患。
1. 宏函数的四大缺陷
假设我们要写一个两数相加的宏:
错误写法 1:优先级问题
cpp
#define ADD(x, y) x + y
// 调用:
int ret = ADD(1, 2) * 3;
// 预处理替换后: 1 + 2 * 3 -> 结果是 7
// 预期结果: (1+2)*3 = 9错误写法 2:加括号也不行 (副作用问题)
即使你写成 #define ADD(x, y) ((x) + (y)) 依然有坑:
cpp
#define ADD(x, y) ((x) + (y))
int a = 10, b = 20;
int ret = ADD(a++, b);
// 替换后: ((a++) + (b))
// 宏只是替换,看起来没问题。但如果是 MAX 宏呢?
#define MAX(a, b) ((a) > (b) ? (a) : (b))
int ret = MAX(a++, b);
// 替换后: ((a++) > (b) ? (a++) : (b))
// ⚠️ a 被自增了两次!这是严重的逻辑错误。缺陷 3:没有类型检查
宏不检查参数类型,你是传 int 还是传 char*,宏照单全收,容易引发不可预知的错误。
缺陷 4:无法调试
宏在预处理阶段就被替换没了,调试时你看到的是源代码,但实际执行的是替换后的乱七八糟的代码,断点经常打不准。
2. C++ 内联函数的优势
C++ 的 inline 完美解决了上述所有问题:
- 是真正的函数: 它有参数类型检查,安全。
- 由编译器处理: 不是简单的文本替换,编译器会处理好运算优先级和副作用(比如
a++只会执行一次)。 - 可调试: 在 Debug 版本下,编译器通常默认不内联,方便你单步调试;在 Release 版本下才会展开优化。
总结对比表:
| 特性 | C 语言宏函数 (#define) |
C++ 内联函数 (inline) |
|---|---|---|
| 处理阶段 | 预处理阶段 (Pre-processor) | 编译阶段 (Compiler) |
| 实现机制 | 字符串文本替换 | 代码逻辑展开 |
| 安全性 | 低 (优先级、副作用陷阱) | 高 (严格的类型检查) |
| 调试 | 不可调试 | 可调试 |
| 复杂性 | 写起来极其痛苦 (全是括号) | 像写普通函数一样简单 |
7.3 空间换时间
内联函数并不是百利而无一害的。它的本质是**"以空间换时间"**。
- 普通函数: 代码在内存中只有一份,大家都要跳转过去执行。
- 优点:节省内存(可执行文件小)。
- 缺点:慢(有跳转开销)。
- 内联函数: 如果一个函数被调用 100 次,它的代码就会在 100 个地方被复制一遍。
- 优点:快(无跳转)。
- 缺点:代码膨胀,导致可执行文件变大。
7.4 编译器的"一票否决权"
这一点非常重要:inline 关键字对编译器来说,只是一个"建议" ,而不是"命令" 。
编译器非常聪明,它会评估:
- 如果函数很长: (例如超过 100 行,或者包含复杂的循环、递归),编译器会无视 你的
inline请求,把它当成普通函数处理。- 原因: 此时函数执行的时间已经远大于调用的开销了,内联没有任何意义,反而会导致代码极度膨胀。
- 如果函数很短: 即使你没写
inline,现代编译器开启优化(如-O2)后,也可能自动把它内联。
7.5 工程实践:声明与定义分离的问题
这是内联函数在使用时最大的"坑"。
规则:内联函数的声明和定义必须在同一个头文件中,不能分离到 .cpp 文件中。
❌ 错误示范 (分离写)
cpp
// --- Test.h ---
inline void Func(); // 声明
// --- Test.cpp ---
#include "Test.h"
inline void Func() { ... } // 定义
// --- Main.cpp ---
#include "Test.h"
int main() {
Func(); // ❌ 链接错误 (LNK2019)
}原理分析 (结合上一章的编译链接)
- 内联函数不需要地址: 因为内联的目的是在调用处直接展开,所以编译器通常不会 把内联函数放入符号表 中(因为它不需要被
call,也就没有地址)。 - 链接不到: 当
Main.cpp编译时,只能看到.h里的声明,不知道具体代码,无法展开。它寄希望于链接器去连接。但Test.cpp里的函数因为是inline,也没有生成符号。结果就是:大家都不认识它,链接失败。
✅ 正确示范
直接把内联函数的定义写在 .h 文件中。
cpp
// --- Test.h ---
inline void Func() {
// 直接在这里写函数体
cout << "我是内联函数" << endl;
}7.6 总结
- 目的: 替代 C 语言的宏函数,解决小函数的调用开销问题。
- 区别: 宏是预处理替换(无类型检查,有副作用);内联是编译阶段展开(安全,有类型检查)。
- 代价: 可执行文件变大(空间换时间)。
- 注意: 不要对大函数、递归函数使用内联;定义和声明不要分离,直接写在头文件里。
你只需要记住:
小函数(1-5行,无复杂逻辑)适合内联。
直接写在头文件 (.h) 里,不用担心重复定义报错,C++ 链接器会帮你搞定一切。
不要在 .h 声明,在 .cpp 定义(会导致链接找不到)。
八、 auto 关键字 (C++11)
在 C++98/03 中,auto 只是一个极其鸡肋的关键字(用于声明局部变量是自动存储的,但默认就是自动的,所以几乎没人用)。
到了 C++11 ,标准委员会赋予了它全新的含义:自动类型推导。
它的核心思想是:既然编译器在编译时已经知道了赋值号右边是什么类型,为什么还要程序员在左边再写一遍类型呢?让编译器自己去推导吧!
8.1 基本用法
使用 auto 声明变量时,必须立即初始化。编译器会根据初始化表达式的类型,推导出变量的实际类型。
cpp
int main() {
int a = 10;
auto b = a; // b 自动推导为 int
auto c = 'c'; // c 自动推导为 char
auto d = 10.5; // d 自动推导为 double
// 我们可以用 typeid 查看实际类型
// 注意:name() 的输出取决于编译器,i代表int, d代表double
cout << typeid(b).name() << endl;
cout << typeid(d).name() << endl;
// auto e; // ❌ 错误!没有初始化,编译器无法推导
return 0;
}注意:
auto是在**编译阶段 ** 完成推导的。它不是动态类型(如 Python 的变量),一旦推导完成,类型就固定了,不会影响运行效率。
8.2 推导规则 (核心考点)
auto 的推导虽然智能,但有几个"隐形规则"必须掌握,特别是指针、引用和 const 的处理。
1. 指针与 auto
对于指针类型,auto 和 auto* 的效果通常是一样的,但 auto* 强制要求右边必须是指针。
cpp
int x = 10;
auto a = &x; // a 推导为 int*
auto* b = &x; // b 推导为 int* (推荐写法,强调是指针)
// auto* c = x; // ❌ 错误!右边不是地址2. 引用与 auto (重点)
auto 默认会忽略引用属性。 如果你希望推导出一个引用变量,必须显式加上 &。
cpp
int x = 1;
int& y = x; // y 是 x 的引用
// --- 情况 A: 不加 & ---
auto z = y;
// 这里的 z 是什么?是 int& 还是 int?
// 答案:z 是 int。
// 解释:编译器只把 y 当作一个值(1)赋给了 z。z 是一个新的变量。
// --- 情况 B: 加 & ---
auto& ref = y;
// ref 是 int&,它是 x 的新别名。3. const 与 auto (难点)
auto 在推导时,通常会 丢弃顶层 const 。
- 顶层 const: 指针/变量本身是常量。
- 底层 const: 指针指向的内容是常量。
cpp
const int a = 10;
// 1. 丢弃 const
auto b = a;
// b 的类型是 int (const 被丢弃了)。
// 因为 b 是新拷贝的一份数据,修改 b 不会影响 a,所以 b 没必要是 const。
b = 20; // ✅ 合法
// 2. 显式保留 const
const auto c = a; // c 是 const int
// 3. 引用自动保留 const (底层 const)
auto& d = a;
// d 的类型是 const int&。
// 因为 d 引用了 a,而 a 是只读的,所以 d 必须也是只读的,否则不安全。
// d = 20; // ❌ 报错8.3 最佳应用场景
既然写 int 和 auto 差不多,为什么要用 auto?因为在处理复杂类型时,它简直是神器。
1. 替代冗长的迭代器类型
在 STL 容器遍历中,类型名往往非常长,写起来痛苦且易错。
未使用 auto:
cpp
#include <vector>
#include <string>
std::vector<std::string> v;
// 写法繁琐,容易手抖写错
std::vector<std::string>::iterator it = v.begin(); 使用 auto:
cpp
// 清爽、直观
auto it = v.begin(); 2. 范围 for 循环
这是 C++11 另一个语法糖,配合 auto 使用效果极佳。
cpp
int array[] = {1, 2, 3, 4, 5};
// 1. 拷贝遍历 (修改 e 不影响数组)
for (auto e : array) {
cout << e << " ";
}
// 2. 引用遍历 (修改 e 会改变数组,且无拷贝开销) -> 推荐
for (auto& e : array) {
e++;
}8.4 限制与禁忌
虽然 auto 好用,但它不是万能的。
-
auto 不能作为函数参数 (在 C++20 之前)
void func(auto a)// ❌ C++11/14/17 报错- 原因:函数参数需要确定的类型来生成符号名(回顾重载章节),这会导致编译解析困难。
-
auto 不能直接用来声明数组
auto arr[] = {1, 2, 3};// ❌ 报错
-
auto 不能定义类的非静态成员变量
- 在类
class中,不能直接写auto m_var = 10;。
- 在类
8.5 总结
- 本质: 编译时根据右值推导类型,不影响运行效率。
- 规则: * 默认丢弃引用 (
&)。- 默认丢弃顶层
const。 - 想保留引用,用
auto&。
- 默认丢弃顶层
- 建议: * 对于简单的
int,bool,建议直接写明确类型,可读性更好。- 对于复杂的 STL 迭代器、模板返回值、Lambda 表达式,强烈建议使用 auto。
九、 范围 for 循环
在 C++98 中,我们要遍历一个数组或容器,通常需要写繁琐的 for 循环,还要手动控制索引或迭代器,稍不留神就会越界。
C++11 引入了范围 for,它能自动推导范围的开始和结束,自动迭代。
9.1 基本语法
cpp
for (元素声明 : 范围表达式) {
// 循环体
}- 元素声明: 通常结合
auto使用,用于接收当前遍历到的元素。 - 范围表达式: 必须是一个数组 ,或者是一个提供了
begin()和end()的容器 (如vector,string等)。
9.2 三种核心写法 (最佳实践)
虽然语法简单,但根据 auto 的修饰不同(值、引用、常引用),会有三种完全不同的行为。这是面试和实际开发的重点。
1. 传值遍历
cpp
int arr[] = {1, 2, 3, 4, 5};
// 这里的 e 是 arr 中元素的副本
for (auto i : arr) {
i*= 2; // ❌ 修改 e 不会影响原数组 arr
cout << i << " ";
}- 特点: 会发生拷贝。
- 缺点: 无法修改原数组;如果元素是大对象(如
string),效率低(涉及深拷贝)。
2. 引用遍历
如果你想修改原数组的内容,或者避免大对象的拷贝,必须加 &。
cpp
// 这里的 e 是 arr 中元素的引用(别名)
for (auto& e : arr) {
e *= 2; // ✅ 修改 e 就是修改原数组
}- 特点: 无拷贝,可修改原数据。
- 建议: 需要"写"操作时使用。
3. 常引用遍历 ------ 最推荐
如果你只是想读取数据,不想修改,且不想发生拷贝(特别是针对大对象)。
cpp
vector<string> strs = {"apple", "banana"};
// const auto& : 既高效(无拷贝),又安全(只读)
for (const auto& s : strs) {
// s = "pear"; // ❌ 报错:只读
cout << s << endl;
}- 建议: 这是遍历 STL 容器(如
vector,map)时的默认首选写法。
9.3 底层原理:它是怎么工作的?
你可能会好奇,为什么它知道什么时候停止?
范围 for 本质上是语法糖 。在编译阶段,编译器会把它替换成传统的迭代器 (Iterator) 循环。
源代码:
cpp
vector<int> v = {1, 2, 3};
for (auto& e : v) {
cout << e;
}编译器眼中的代码 (伪代码):
cpp
{
auto && __range = v;
// 获取开始和结束的迭代器
auto __begin = __range.begin();
auto __end = __range.end();
// 传统的迭代器遍历
for ( ; __begin != __end; ++__begin) {
auto& e = *__begin; // 解引用,赋值给 e
cout << e;
}
}结论:
只要一个对象(类)内部实现了 begin() 和 end() 方法,并且返回了迭代器,它就可以支持范围 for 循环。这也是为什么原生数组支持(编译器特化处理)而标准库容器也支持的原因。
9.4 常见陷阱:数组退化为指针
这是范围 for 最容易报错的地方。范围 for 必须知道数组的确切大小。
当数组作为函数参数传递时,它会退化 (Decay) 为指针。指针只包含了地址,丢失了长度信息,所以不能用范围 for。
cpp
void Test(int arr[]) { // 虽然写着 arr[],但本质是 int* arr
// ❌ 错误!
// 编译器报错:'begin' was not declared in this scope
// 原因:arr 只是个指针,编译器不知道它有多长,无法生成 begin/end
for (auto& e : arr) {
cout << e << endl;
}
}
int main() {
int arr[] = {1, 2, 3};
Test(arr);
}十、 typeid 运算符(可暂时忽略)
在 C++ 中,auto 和 decltype 主要是编译期的类型推导。如果我们想在程序运行的时候 知道一个变量到底是什么类型(特别是面对多态父子类指针时),就需要用到 typeid。
10.1 基本准备
要使用 typeid,必须包含标准库头文件:
cpp
#include <typeinfo>typeid 操作符返回的是一个 const std::type_info& 类型的对象。这个对象里包含了类型的相关信息(如名字、哈希码等)。
10.2 核心用法
typeid 主要有两个用途:
- 获取类型名称 (
.name()) - 类型判断/比较 (
==,!=)
代码示例:
cpp
#include <iostream>
#include <typeinfo> // 必须包含
using namespace std;
class Person {};
int main() {
int a = 10;
Person p;
// 1. 获取类型名称 (name)
cout << "a 的类型: " << typeid(a).name() << endl;
cout << "p 的类型: " << typeid(p).name() << endl;
// 2. 类型对比
if (typeid(a) == typeid(int)) {
cout << "a 是 int 类型" << endl;
}
// 甚至可以对比两个变量
float f = 3.14;
if (typeid(a) != typeid(f)) {
cout << "a 和 f 类型不同" << endl;
}
return 0;
}10.3 静态 vs 动态 (核心考点)
这是 typeid 最复杂也是最重要的部分。它的行为取决于对象是否具有多态性(即是否有虚函数)。
1. 静态绑定 (Static Binding)
场景: 如果类没有虚函数 ,或者操作的是基础数据类型。
行为: 编译器在编译阶段就已经确定了类型。
cpp
class Base { /* 没有虚函数 */ };
class Derived : public Base {};
void Func(Base* ptr) {
// 编译时 ptr 被声明为 Base*
// 所以 typeid(*ptr) 永远是 Base,哪怕它实际指向 Derived
cout << typeid(*ptr).name() << endl;
}
int main() {
Derived d;
Func(&d); // 输出 Base (或者 class Base)
}2. 动态绑定 (Dynamic Binding)
场景: 如果类有虚函数 (构成了多态)。
行为: 编译器无法在编译时确定,必须推迟到运行时。程序会去查找对象的虚函数表(vptr),从而找到真正的类型。
cpp
class Base {
public:
virtual void vfunc() {} // ✅ 有虚函数
};
class Derived : public Base {};
void Func(Base* ptr) {
// 运行时检查:ptr 到底指向谁?
// 如果指向 Derived,结果就是 Derived
cout << typeid(*ptr).name() << endl;
}
int main() {
Derived d;
Func(&d); // ✅ 输出 Derived (或者 class Derived)
}注意: 在动态绑定情况下,如果
ptr是空指针 (nullptr),对它解引用使用typeid(*ptr)会抛出std::bad_typeid异常。
10.4 常见陷阱与细节
1. 忽略顶层 const 和引用
typeid 在判断类型时,会忽略 变量的 const 修饰符(顶层 const)和引用修饰符 &。它只看"裸"类型。
cpp
int a = 10;
const int b = 20;
int& c = a;
// 下面三个结果完全相同,都是 "int"
cout << typeid(a).name() << endl;
cout << typeid(b).name() << endl; // const 被忽略
cout << typeid(c).name() << endl; // & 被忽略2. 名字修饰 (Name Mangling)
typeid(...).name() 返回的字符串在不同编译器下是不一样的:
- MSVC (Windows): 比较人性化,通常显示
int,class Base。 - GCC/Clang (Linux): 会进行名字修饰(压缩)。
int->ifloat->fclass MyClass->7MyClass(数字代表长度)- 注:Linux 下可以使用
c++filt -t命令来还原这些名字。
10.5 深度对比:typeid vs decltype
这是面试中常让你区分的两个工具:
| 特性 | typeid | decltype |
|---|---|---|
| 执行时期 | 运行时 (多态时) / 编译时 (非多态) | 编译时 (永远) |
| 处理引用 | 忽略引用 (int& 变为 int) |
保留引用 (int& 还是 int&) |
| 处理 const | 忽略顶层 const | 保留 const |
| 用途 | 主要用于日志打印 、运行时类型检查 | 主要用于模板编程 、推导返回类型 |
总结
typeid是一个操作符,不是函数。- 它最强大的地方在于多态场景 下,能识别基类指针指向的真实子类对象。
- 它会忽略引用和
const。 - 不要依赖
.name()返回的字符串格式,不同编译器不一样。
十一、C++中的NULL
1. NULL 的本质
在 C++ 标准库头文件(如 <cstddef> 或 <cstdio>)中,NULL 通常被定义为整数 0。
-
C 语言中的定义:
c#define NULL ((void *)0) // C 语言:可以直接把 void* 赋值给任意指针 -
C++ 中的定义:
cpp#define NULL 0 // C++:不允将 void* 隐式转换为其他指针,所以定义为 0
为什么 C++ 要把它定义为 0?
因为 C++ 是强类型语言,它不允许 void* 隐式转换为具体的指针类型(例如 int*)。如果像 C 语言那样定义为 (void*)0,在 C++ 中赋值给 int* 会报错。因此,C++ 只能妥协,将其定义为整数字面量 0。
2. NULL 带来的"二义性"问题
由于 NULL 本质上是整数 0,这在函数重载(Function Overloading)时会引发严重的逻辑错误。
示例代码:
cpp
#include <iostream>
void func(int i) {
std::cout << "调用了 func(int)" << std::endl;
}
void func(int* p) {
std::cout << "调用了 func(int*)" << std::endl;
}
int main() {
func(0); // 输出:调用了 func(int) -> 正常
func(NULL); // 输出:调用了 func(int) -> 【错误!】预期应该是指针版本
// func((int*)NULL); // 必须强制转换才能调用指针版本,非常麻烦
return 0;
}分析:
- 程序员的意图是:传递一个空指针,调用
func(int* p)。 - 编译器的行为是:
NULL被替换为0(整数),所以它完美匹配了func(int i)。 - 后果: 这会导致难以排查的 Bug。
3. 现代解决方案:nullptr (C++11)
为了解决 NULL 的类型不安全问题,C++11 引入了新的关键字 nullptr。
- 类型安全:
nullptr的类型是std::nullptr_t,它不是整数。 - 自动转换: 它可以隐式转换为任意类型的指针(如
int*,char*,Obj*)。 - 拒绝整数: 它不能隐式转换为整数。
使用 nullptr 修复上面的例子:
cpp
func(nullptr); // 输出:调用了 func(int*) -> 【正确!】4. 总结与对比表
| 特性 | 0 |
NULL |
nullptr (C++11及以后) |
|---|---|---|---|
| 本质 | 整数常量 | 预处理宏 (通常是 0) |
关键字 (类型为 std::nullptr_t) |
| 类型 | int |
int (在 C++ 中) |
std::nullptr_t |
| 能否赋值给指针 | 能 | 能 | 能 |
| 能否赋值给整数 | 能 | 能 | 不能 (类型安全) |
| 重载时的行为 | 优先匹配 int 参数 |
优先匹配 int 参数 (危险) |
只匹配指针参数 (安全) |
| 推荐程度 | 不推荐表示指针 | 已废弃,不推荐 | 强烈推荐 |
5. 最佳实践建议
- 在现代 C++ (C++11/14/17/20/23) 开发中,彻底忘记
NULL,始终使用nullptr。 - 只有在需要兼容极老的 C++ 编译器(如 VC6.0)或者编写纯 C 语言代码时,才使用
NULL。
注意: const 修饰 typedef 定义的指针别名
在 C++ 中,用 const 修饰 typedef 定义的指针别名 时,最大的缺点(或者说陷阱)是:产生的语义往往与人的直觉背道而驰,容易导致严重的理解错误。
具体来说,它会导致顶层 const(指针本身常量)和底层 const(指针所指对象常量)的混淆。
以下是详细的分析:
1. 核心陷阱:不是简单的文本替换
很多人误以为 typedef 像 #define 一样是简单的文本替换,但实际上 typedef 声明了一个新的类型。
示例分析
假设我们要定义一个指向 char 的指针别名:
cpp
typedef char* PStr;现在,我们用 const 修饰这个别名:
cpp
const PStr p = "hello";大多数人的直觉预期(错误):
- 以为它等同于:
const char* p; - 含义:
p是一个指向常量的指针(即:不能通过p修改字符 "hello")。
实际的编译器行为(正确):
- 它等同于:
char* const p; - 含义:
p是一个常量指针 (即:p这个变量里存的地址不能变,但它可以修改指向的字符)。
2. 为什么会这样?
因为对于编译器来说,PStr 已经是一个完整的类型(指针类型)。当你写 const PStr 时,const 修饰的是 PStr 这个类型本身。
PStr是 "指向 char 的指针"。const PStr就是 "指向 char 的常量指针"。
这符合 const 修饰基本类型的规则(例如 const int 修饰的是 int)。但在指针语境下,这直接导致了语义反转。
3. 代码演示带来的后果
这种混淆会导致你以为数据是安全的(只读的),但实际上数据是可以被修改的。
cpp
typedef char* PStr;
int main() {
char s[] = "World";
// 这里的 cstr 实际上是 char* const cstr
const PStr cstr = s;
// 1. 试图修改指针指向(编译器报错,符合预期)
// cstr = nullptr; // Error: assignment of read-only variable 'cstr'
// 2. 试图修改数据(编译器允许!这可能违背了你的初衷)
cstr[0] = 'H'; // OK! s 变成了 "Horld"
return 0;
}如果你原本是想保护数据不被修改,上面的代码就造成了安全漏洞。
4. 解决方案
为了避免这种歧义,通常有以下建议:
方案 A:不要依赖 const 修饰别名,直接在 typedef 里写清楚
如果你需要一个指向常量的指针别名,直接定义进去:
cpp
typedef const char* ConstPStr; // 明确这是指向常量的指针
ConstPStr p = "hello"; // p 是 const char*方案 B:使用 C++11 的 using(别名声明)
虽然 using 遇到 const 的行为和 typedef 是一模一样的(也会遇到上述陷阱),但 using 的语法通常更易读,且配合模板使用更灵活。不过,解决本问题的核心还是在于不要试图用外部的 const 去改变指针内部的指向属性。
cpp
using PStr = char*;
// const PStr 依然是 char* const方案 C:显式书写(在不复杂的场景下)
如果指针类型不复杂,直接写 const char* 或 char* const,不仅没有任何歧义,而且阅读代码的人一眼就能看懂。
总结
const 修饰 typedef 指针别名的缺点在于:
- 直觉欺骗 :它产生的是常量指针 (
T* const),而不是指向常量的指针 (const T*)。 - 可读性差 :维护者必须去查看
typedef的原始定义才能确定const到底锁定了什么。 - 潜在 Bug:误以为数据是只读的,导致意外修改数据。