LlamaIndex
LlamaIndex 是一个用于 LLM 应用程序的数据框架,用于注入,结构化,并访问私有或特定领域数 据。
我们知道数据存在的形式有很多种,比如嵌入到网页中、以api接口的形式存在、以文档的形式存在。如何让AI与这些多样化的数据对接,这是之前AI应用的一个复杂点。LlamaInde就是解决大模型和数据之间的衔接问题。
相关组成
LlamaIndex 提供了5大核心工具:
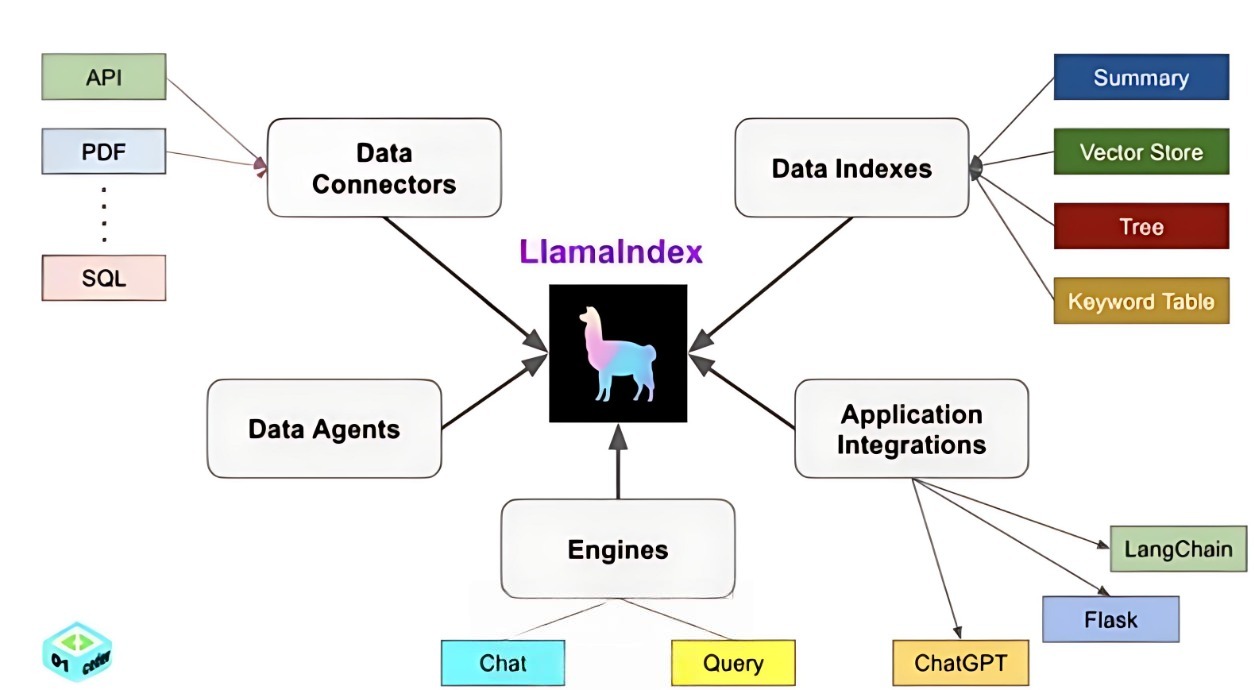
Data connectors:
LlamaIndex通过数据连接器自动把各种各样的数据解析成同一种标准,交付给LlamaIndex。(简单来说就是一个能够解析市面上所有数据格式的插件)
Data indexes:
现在通过Data connectors把数据变成了同一标准的文本。现在要给到大模型做处理之前,要把文本转成向量(文本------>向量)。Data indexes中核心要做的事也就是Vector Store(向量化)通过一个embedding模型将文本转为向量存储下来。向量存储下来之后要拿来使用,再围绕这些向量 构建可快速检索的索引结构 。我们通过索引值就可以之间操作向量。
Engines:
现在我有了大模型可以使用的数据,并且转化为向量的形式存储。接下来大模型就要使用。现在就是通过Engines来加载模型,大模型无非就是去检索和处理数据。Engines中有两个核心的接口query和chat。query是单次的查询,chat可以多轮的对话。Engines就是用来连接大模型的。
其实以上三个类就是核心内容,但LlamaIndex本身做了一些扩展。
Data agents:
Data Agents = 「能够"动态"决定调用哪一步工具、查询哪一段数据,并循环"观察-思考-行动"直到任务完成的 LLM 智能体」。
-
Engines 是"静态流水线":人问 → 检索 → 生成 → 答完结束。
-
Agents 是"动态推理机":LLM 可以在运行时
-
选择调用哪一个 Data Connector(再去外部抓新数据)
-
选择调用哪一个 Tool(计算器、SQL、API、搜索)
-
甚至把结果再写回索引或触发下一次检索
整个流程由 LLM 自己编排,不预先固定。
-
Application integrations:
LlamaIndex可以接入到一些第三方框架中。可以把这个数据增强接入到其他的第三方框架中做一个辅助的插件。