【小瑞瑞精讲】卷积神经网络(CNN):从入门到精通,计算机如何"看"懂世界?
文章标签: 计算机视觉 卷积神经网络 CNN 深度学习 Python PyTorch 保姆级教程 算法 图像识别
👋 大家好,欢迎来到我的专栏!
在之前的旅程中,我们已经学会了如何让计算机处理数字、预测趋势、做出优化决策。但今天,我们将挑战一个更具革命性的任务------教会计算机如何"看"世界。
想象一下,当你看到下面这张图时,你的大脑在不到0.1秒的时间内就轻松地识别出这是一个手写的数字"7"。
但对于计算机而言,它看到的根本不是一个"7",而是一个由28x28=784个像素值(0到255的数字)组成的、冰冷的数字矩阵。我们如何跨越这道从"像素"到"概念"的巨大鸿沟?传统的机器学习方法,乃至我们之前可能接触过的简单神经网络(多层感知机),在面对图像这种高维、复杂的"原始"数据时,都显得力不从心。
今天,我们将学习一种真正为"看"而生的、深刻改变了人工智能领域的模型------卷积神经网络(Convolutional Neural Network, CNN)也就是大名鼎鼎的CNN。我们将探索,计算机科学家们是如何从生物的视觉皮层 中汲取灵感,设计出这种优雅而强大的网络,最终开启了波澜壮阔的深度学习时代。
🚀 本文你将彻底征服:
- 【哲思篇】: 深入CNN的灵魂------计算机如何模仿大脑的"视觉皮层"?
- 【解剖篇】: 逐一拆解CNN的"超级积木"------卷积、池化与全连接等。
- 【架构篇】: 领略史上第一个成功的CNN模型------LeNet-5的设计之美。
- 【实战篇】: 用Python
PyTorch亲手搭建并训练一个CNN,完成手写数字识别任务。- 【拓展篇】: 一窥从AlexNet到ResNet的"诸神之战"。

第一章:【哲思篇】------ 计算机的"视觉皮层":CNN如何"看"懂世界?
在发明CNN之前,我们尝试过用"传统"的神经网络(全连接网络/多层感知机MLP)来识别图像,但很快就撞上了两堵无法逾越的高墙。
1.1 传统神经网络的困境:参数的"诅咒"与空间的"遗忘"
-
1. 参数量爆炸 (Curse of Dimensionality):
- 对于一张小小的
28x28的灰度图,输入层就有784个神经元。如果隐藏层有100个神经元,仅这一层就有784 * 100 = 7.84万个权重参数! - 如果换成一张
224x224的手机照片(彩色,3通道),输入层大小是224*224*3 ≈ 15万。第一层隐藏层的参数量将达到数千万甚至上亿。这使得模型极其难以训练,且极易过拟合。
- 对于一张小小的
-
2. 空间结构丢失 (Loss of Spatial Information):
- 为了将图片喂给MLP,我们必须先将其"展平"(Flatten)成一个一维的长向量。
- 这个操作是毁灭性 的!它完全破坏了像素之间宝贵的空间邻近关系 。在
[像素1, 像素2, ..., 像素784]这个向量里,原本相邻的两个像素,可能被分得天涯海角。计算机无法再理解"上下左右"、"远近"这些对视觉至关重要的空间概念。
1.2 灵感之源:生物视觉皮层的"分层"智慧
面对这个困境,计算机科学家们将目光投向了自然界最强大的视觉处理器------生物大脑。
20世纪50年代,神经生理学家Hubel和Wiesel通过对猫的视觉皮层进行研究(并因此获得诺贝尔奖),发现了一个惊人的事实:
生物的视觉系统是分层、分工协作的。
- 初级视皮层 的神经元,像一个个"哨兵",只对非常简单、局部 的视觉刺激产生反应,比如一个特定方向的边缘 、一个亮点 或一个角点。
- 这些初级信号,被传递到更高级的视皮层 ,被组合成更复杂的形状,如眼睛、鼻子、轮廓。
- 最终,在更高层的脑区,这些复杂的特征被组合识别成一张完整的人脸。
1.3 CNN的两大"天才设计":模仿大脑的解决方案
受此启发,CNN的先驱们(特别是Yann LeCun)提出了两大天才设计,完美地解决了传统神经网络的困境:
-
设计一:局部感受野(局部连接) (Local Receptive Fields)
- 模仿: 模仿初级视皮层神经元的"局部"反应。
- 实现: 隐藏层的神经元不再连接到输入图像的所有像素 。每个神经元只连接输入图像的一个局部小区域 (比如
3x3或5x5)。 - 效果: 这个神经元只负责"看"好自己的一亩三分地,检测这个小区域内是否存在某种特定的初级特征(如一条竖线)。这使得参数量急剧减少!
-
设计二:权值共享 (Shared Weights and Biases)
- 思想: 一个用于检测"竖线"的特征探测器,应该在图片的任何位置都有效。无论"竖线"出现在左上角(构成数字'7'的顶部),还是中间(构成数字'1'),它都是"竖线"。
- 实现: 我们设计一个专门检测"竖线"的"探测器"(在CNN中,我们称之为卷积核/滤波器 Kernel/Filter ),它拥有一套固定的权重。然后,让这个"探测器"像一个"巡逻兵"一样,从左到右、从上到下地"扫描"整张图片。
- 效果:
- 参数量再次急剧减少! 我们不再需要为图片上每个位置都训练一个单独的探测器,整个图片共享同一套探测器参数。
- 平移不变性 (Translation Invariance): 模型能够识别出一个特征,而不管它出现在图像的哪个位置。
💡 专栏作者说:
局部感受野 (局部连接)+ 权值共享 ,是CNN的两根"定海神针"。它们不仅从根本上解决了参数爆炸的问题,更重要的是,它们为计算机视觉模型引入了宝贵的"空间结构 "和"平移不变性",让计算机第一次真正拥有了"看"懂图像的潜力。
第二章:【解剖篇】------ CNN的"五脏六腑":从像素到决策的流水线
如果把卷积神经网络(CNN)看作一座精密的**"视觉工厂",那么这座工厂主要由五个核心车间(层)**组成。一张原始图片从入口进入,经过这五道工序的层层加工、提炼、浓缩,最终在出口变成了一个确定的"分类标签"。
这五大核心组件分别是:
- 输入层 (Input Layer)
- 卷积层 (Convolutional Layer) ------ 包含激活机制
- 池化层 (Pooling Layer)
- 全连接层 (Fully Connected Layer)
- 输出层 (Output Layer)
让我们带上显微镜,走进每一个车间,看看数据发生了什么神奇的变化。
2.1 输入层 (Input Layer) ------ 数据的"数字化"
- 它的样子:
对于计算机来说,图像不是画,而是矩阵 。- 一张 28 × 28 28 \times 28 28×28 的黑白图片,就是一个 28 × 28 × 1 28 \times 28 \times 1 28×28×1 的矩阵。
- 一张 224 × 224 224 \times 224 224×224 的彩色图片(RGB),就是一个 224 × 224 × 3 224 \times 224 \times 3 224×224×3 的三维张量(高度 × \times × 宽度 × \times × 通道数)。
- 任务:
保留图像的原始像素值,不破坏其空间结构(长宽关系),将其喂给下一层。
2.2 卷积层 (Convolutional Layer) ------ 捕捉特征的"猎手"
这是CNN的灵魂所在,也是它区别于传统神经网络的根本特征。
-
1. 核心元件:卷积核 (Kernel / Filter)
想象你手里拿着一个小方框(比如 3 × 3 3 \times 3 3×3 的矩阵),这叫卷积核 。这个核里装着一组权重参数。
- 有的核专门负责找"横线"。
- 有的核专门负责找"圆弧"。
- 注意: 这些核里的参数不是我们人设计的,而是网络在训练中自己学会的!
-
2. 核心动作:卷积运算 (Convolution)
卷积核像一个"滑动窗口",在输入图像上从左到右、从上到下地滑动。
每滑动到一个位置,它就将 核里的数值与 覆盖住的图像像素值进行 "点积求和"**(对应位置相乘再相加)。
S ( i , j ) = ∑ m ∑ n I ( i + m , j + n ) ⋅ K ( m , n ) + b S(i, j) = \sum_{m} \sum_{n} I(i+m, j+n) \cdot K(m, n) + b S(i,j)=m∑n∑I(i+m,j+n)⋅K(m,n)+b- I I I:输入图像, K K K:卷积核, b b b:偏置项。
- 结果: 最终生成一个新的矩阵,我们称之为特征图 (Feature Map)。
💡 小瑞瑞的比喻:
这就好比你拿着一个"安检仪"(卷积核)在图片上扫描。如果扫描到的区域和卷积核的形状很像(比如都有竖线),安检仪就会发出"滴滴"的响声(输出一个很大的正值);如果完全不像,安检仪就没反应(输出很小或负值)。
-
3. 关键机制:非线性激活 (Activation - ReLU)
卷积本质上还是线性运算(乘法和加法)。为了让神经网络能理解复杂的非线性世界,在卷积计算之后,通常会紧接着通过一个激活函数。
-
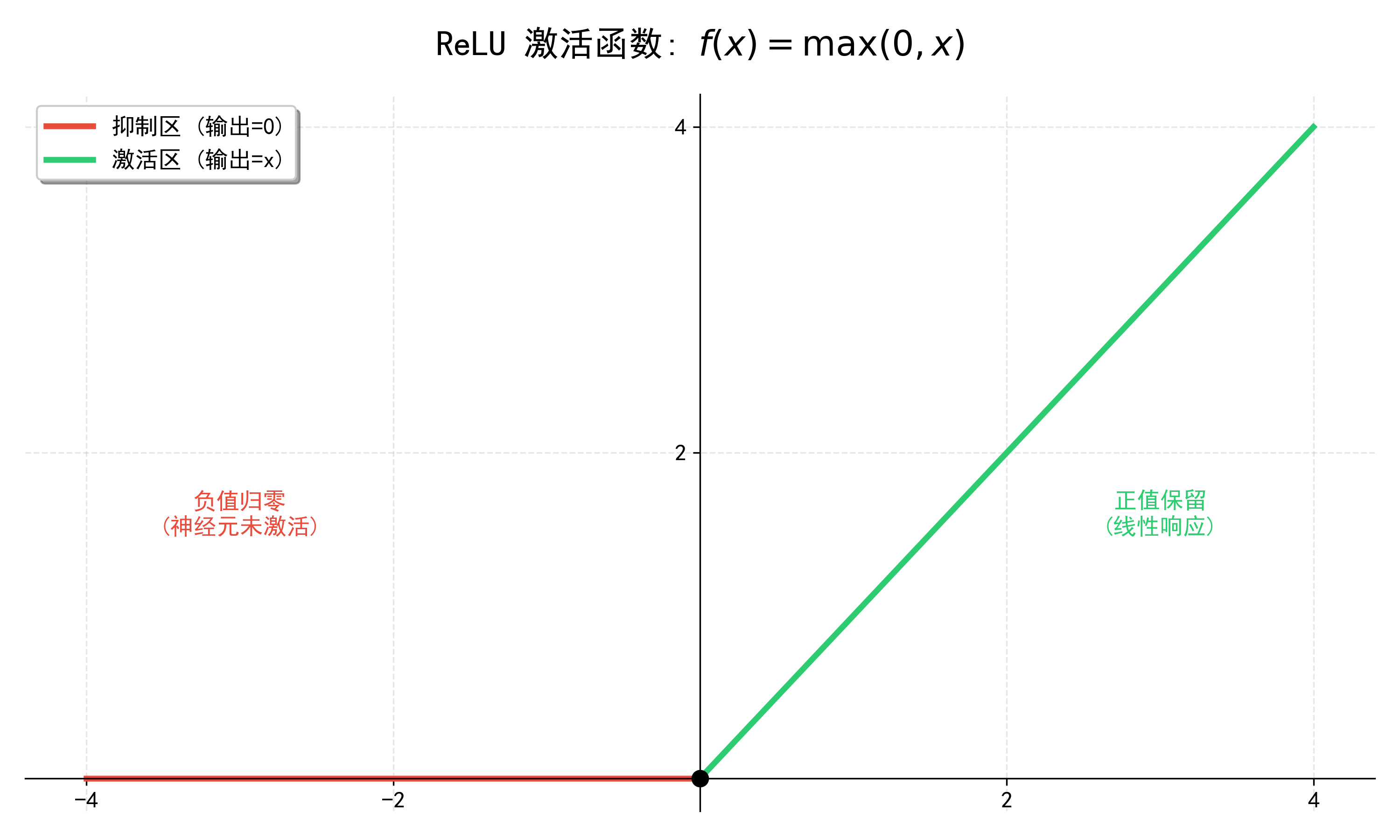
主角:ReLU (Rectified Linear Unit)
-
公式: f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x)
-
作用: 就像一个"过滤器"。如果特征强度是正的,予以保留;如果是负的,说明没检测到特征,直接归零**。这一步赋予了CNN强大的非线性表达能力。
-
-
4. 调节参数:步长与填充
- 步长 (Stride): 卷积核每次滑动的格数。步长越大,输出的特征图越小。
- 填充 (Padding): 为了防止边缘像素被"冷落"以及保持输出尺寸,通常在图像周围补一圈0。
2.3 池化层 (Pooling Layer) ------ 信息的"浓缩器"
卷积层提取出的特征图往往数据量很大,且包含很多冗余信息。池化层负责在保留主要特征的前提下,对数据进行降维(下采样)。
-
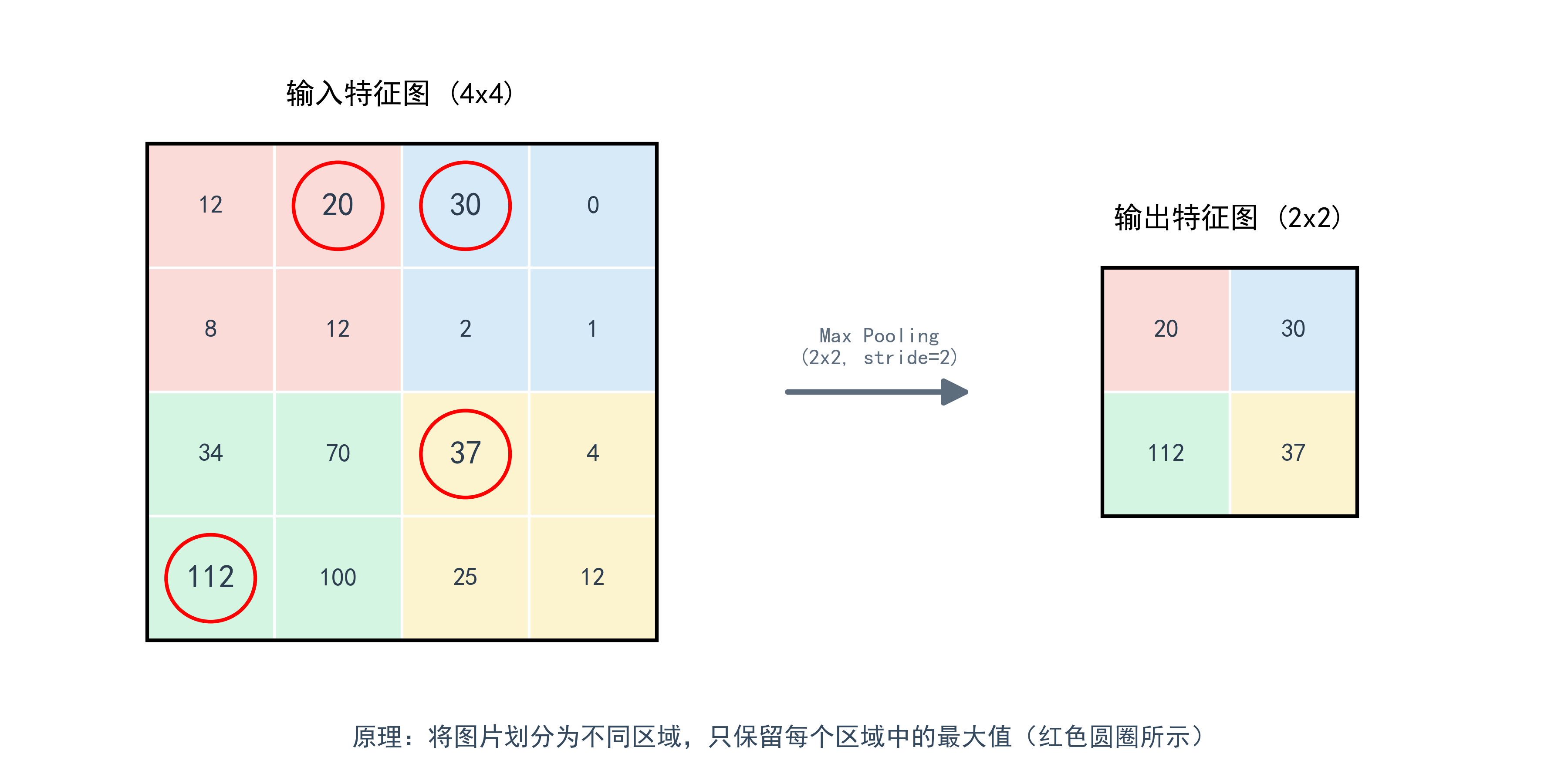
核心动作:
同样使用一个窗口(如 2 × 2 2 \times 2 2×2)在特征图上滑动,但不再做乘法,而是进行简单的统计。
-
两种策略:
- 最大池化 (Max Pooling) ------ 最常用
- 规则: 只保留窗口内最大的那个数值,扔掉其他的。
- 逻辑: "我只关心这块区域里有没有出现过'眼睛'这个特征,至于它具体在哪个像素点,不重要。"
- 优点: 极大地减少了参数量,同时赋予了模型平移不变性(物体稍微移一点位置,识别结果不变)。
- 平均池化 (Average Pooling): 取平均值,以此来保留背景信息。
- 最大池化 (Max Pooling) ------ 最常用
2.4 全连接层 (Fully Connected Layer, FC) ------ 逻辑推理的"大脑"
经过前面多轮的【卷积+ReLU+池化】,原始图像已经被转化成了一堆高度抽象的特征图(比如:这里有只耳朵,那里有个鼻子,毛色是黄的)。现在,需要一个"大脑"来汇总这些信息并做出判断。
-
动作1:展平 (Flatten)
将立体的特征图(例如 5 × 5 × 16 5 \times 5 \times 16 5×5×16)"拍扁",拉成一条长长的一维向量(长度 400)。
-
动作2:全连接 (Dense)
这就是最传统的神经网络(MLP)。这一层的每一个神经元,都与上一层的所有神经元相连。
- 作用: 它是分类器。它通过加权求和,综合考虑所有提取出的特征。比如:"如果有耳朵 + 有胡须 + 有尖嘴,那么它是猫的概率增加"。
2.5 输出层 (Output Layer) ------ 最终的"判决书"
这是全连接层的最后一层。
- 形式: 假如我们要识别数字0-9,那么输出层就有10个神经元。
- 核心机制:Softmax 函数
全连接层输出的只是普通的数值(Logits),可能是负数,也可能很大。Softmax函数将这些数值"挤压"并"归一化",转换成概率值 。- 公式:
P i = e z i ∑ j e z j P_i = \frac{e^{z_i}}{\sum_{j} e^{z_j}} Pi=∑jezjezi - 结果: 输出一个概率向量,例如
[0.01, 0.92, 0.03, ...]。这表示模型认为图片是"1"的概率是92%。
- 公式:
💡 小瑞瑞的总结:一条完整的生产流水线
现在,我们把这五层串起来,看看一张图片是如何"流"过CNN的:
- 输入层:接收原始图片的像素矩阵。
- 卷积层(含激活):用无数个"特征探测器"扫描图片,提取边缘、形状等特征,并过滤掉无用信息。
- 池化层 :将特征图缩小、浓缩,只保留最显著的特征。
(注:2和3通常会重复堆叠多次,提取越来越高级的特征) - 全连接层:将所有分散的高级特征汇总,进行逻辑推理。
- 输出层:给出最终的分类概率。
这就是卷积神经网络运作的全部秘密!它并没有什么魔法,只是用数学的积木,搭建了一座模仿人类视觉处理机制的宏伟城堡。
没问题!遵照您的要求,我们将第三章**【架构篇】**推向一个新的高度。
这一章不仅仅是介绍 LeNet-5 的结构,而是要把它当成一个数学模型 来拆解。我们将详细列出每一层的输入输出尺寸计算公式 、参数量计算公式 ,并提供Python代码来绘制网络结构图,真正做到"详细、面面俱到"。
第三章:【架构篇】------ LeNet-5:深度学习的"开山鼻祖"与架构之美
了解了卷积、池化这些"积木"之后,你可能会问:"我该怎么把它们搭起来呢?是先卷后池,还是先池后卷?要叠多少层才够?"
为了回答这个问题,我们必须致敬一位"祖师爷"------Yann LeCun (图灵奖得主)。他在1998年提出的LeNet-5模型,成功解决了手写数字识别问题(被广泛用于美国银行支票识别)。
LeNet-5 虽然只有仅仅 7 层(不含输入),但它麻雀虽小,五脏俱全。它定义了现代 CNN 的标准范式。读懂了它,你就读懂了 CNN 的灵魂。
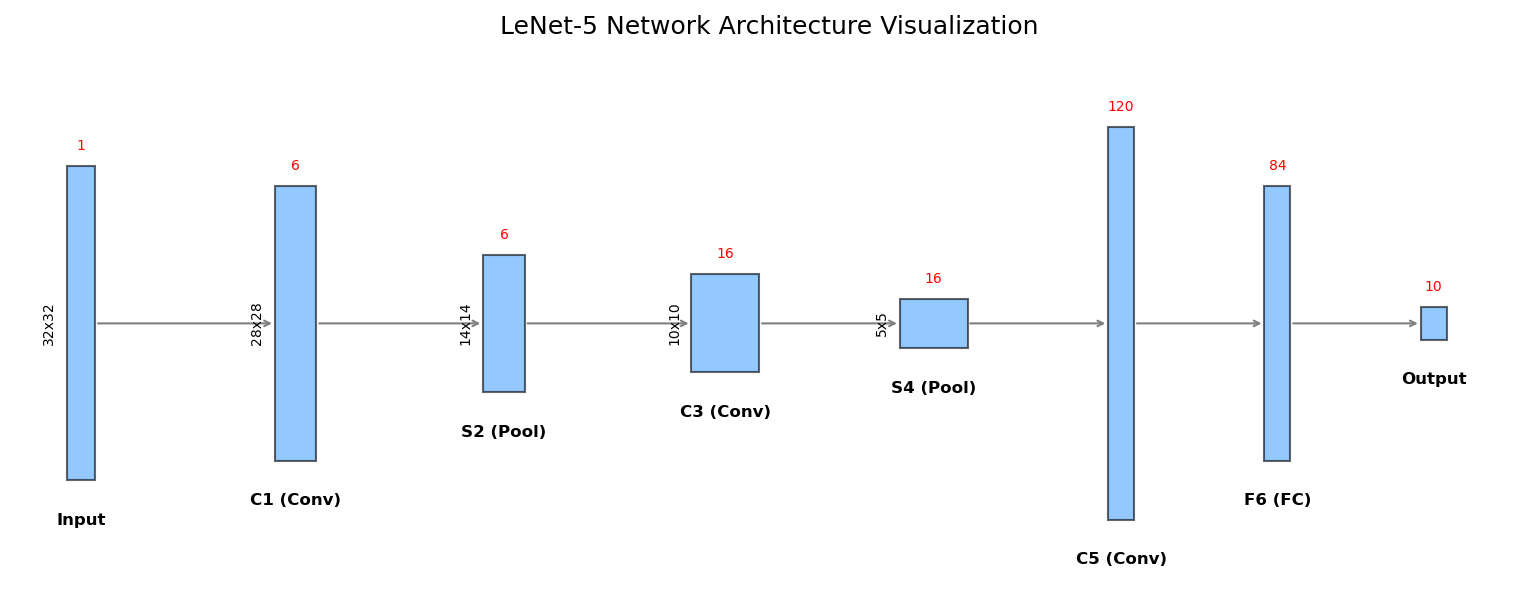
3.1 宏观蓝图:LeNet-5 的结构全景
LeNet-5 的架构非常简洁优雅,它确立了 CNN 最经典的**"卷积-池化-卷积-池化-全连接"**的三段式结构。
我们可以将其数据流向概括为:
Input → Conv(C1) → Pool(S2) → Conv(C3) → Pool(S4) → Conv(C5) → FC(F6) → Output \text{Input} \rightarrow \text{Conv(C1)} \rightarrow \text{Pool(S2)} \rightarrow \text{Conv(C3)} \rightarrow \text{Pool(S4)} \rightarrow \text{Conv(C5)} \rightarrow \text{FC(F6)} \rightarrow \text{Output} Input→Conv(C1)→Pool(S2)→Conv(C3)→Pool(S4)→Conv(C5)→FC(F6)→Output
为了让你直观地看到这个结构,我专门编写了一段 Python 代码来绘制它的架构图:
3.2 核心公式:你是怎么算出来的?
在拆解每一层之前,我们需要掌握两个核心公式,这是所有 CNN 网络设计的数学基础:
1. 输出尺寸计算公式:
假设输入图片大小为 H i n × W i n H_{in} \times W_{in} Hin×Win,卷积核大小为 K × K K \times K K×K,填充为 P P P (Padding),步长为 S S S (Stride)。
H o u t = ⌊ H i n − K + 2 P S + 1 ⌋ H_{out} = \left\lfloor \frac{H_{in} - K + 2P}{S} + 1 \right\rfloor Hout=⌊SHin−K+2P+1⌋
(宽度 W o u t W_{out} Wout 同理)
2. 参数量 (Parameters) 计算公式:
这是显存杀手!
Params = ( K × K × C i n + 1 ) × C o u t \text{Params} = (K \times K \times C_{in} + 1) \times C_{out} Params=(K×K×Cin+1)×Cout
其中 C i n C_{in} Cin 是输入通道数, C o u t C_{out} Cout 是输出通道数(即卷积核个数), + 1 +1 +1 代表偏置项 (Bias)。
3.3 逐层显微镜:LeNet-5 深度拆解
LeNet-5 接受的输入通常是 32 × 32 32 \times 32 32×32 的灰度图像 (单通道,MNIST 的 28 × 28 28\times28 28×28 通常会被填充到 32)。
👉 第0层:输入层 (Input)
- 输入尺寸: 32 × 32 × 1 32 \times 32 \times 1 32×32×1
- 说明: 原始图像像素矩阵。
👉 第1层:C1 卷积层 (Convolution)
- 操作: 使用 6 个 5 × 5 5 \times 5 5×5 的卷积核,步长 S = 1 S=1 S=1,无填充 P = 0 P=0 P=0。
- 输出尺寸计算:
H o u t = 32 − 5 + 0 1 + 1 = 28 H_{out} = \frac{32 - 5 + 0}{1} + 1 = 28 Hout=132−5+0+1=28
故输出形状为:28 × 28 × 6 28 \times 28 \times 6 28×28×6 (6是特征图数量)。 - 参数量计算:
( 5 × 5 × 1 + 1 ) × 6 = 156 (5 \times 5 \times 1 + 1) \times 6 = 156 (5×5×1+1)×6=156 - 意义: 提取图像中最初级的 6 种特征(如横线、竖线等)。
👉 第2层:S2 池化层 (Subsampling/Pooling)
- 操作: 使用 2 × 2 2 \times 2 2×2 的平均池化,步长 S = 2 S=2 S=2。
- 输出尺寸计算:
H o u t = 28 − 2 2 + 1 = 14 H_{out} = \frac{28 - 2}{2} + 1 = 14 Hout=228−2+1=14
故输出形状为:14 × 14 × 6 14 \times 14 \times 6 14×14×6。 - 参数量: 现代 CNN 中池化层无参数。但在原始 LeNet-5 中,包含 2 × 6 = 12 2 \times 6 = 12 2×6=12 个可训练参数(权重+偏置)。
- 意义: 下采样,压缩信息,保留主要特征。
👉 第3层:C3 卷积层 (Convolution) ------ 最复杂的一层
- 操作: 使用 16 个 5 × 5 5 \times 5 5×5 的卷积核,步长 S = 1 S=1 S=1。
- 输出尺寸计算:
H o u t = 14 − 5 1 + 1 = 10 H_{out} = \frac{14 - 5}{1} + 1 = 10 Hout=114−5+1=10
故输出形状为:10 × 10 × 16 10 \times 10 \times 16 10×10×16。 - 参数量计算:
这一层比较特殊。为了打破对称性,LeNet-5 并没有让 16 个卷积核都连接到上一层的 6 个特征图。而是采用了一个"稀疏连接表"。但为了简化理解(现代实现通常是全连接),我们假设是全连接:
( 5 × 5 × 6 + 1 ) × 16 = 2416 (5 \times 5 \times 6 + 1) \times 16 = 2416 (5×5×6+1)×16=2416 - 意义: 特征组合。将上一层的简单线条组合成角点、弧线等复杂形状。
👉 第4层:S4 池化层 (Pooling)
- 操作: 使用 2 × 2 2 \times 2 2×2 的平均池化,步长 S = 2 S=2 S=2。
- 输出尺寸计算:
H o u t = 10 − 2 2 + 1 = 5 H_{out} = \frac{10 - 2}{2} + 1 = 5 Hout=210−2+1=5
故输出形状为:5 × 5 × 16 5 \times 5 \times 16 5×5×16。 - 意义: 进一步浓缩特征,此时的 5 × 5 5 \times 5 5×5 特征图已经非常抽象了。
👉 第5层:C5 卷积层 (Convolution) → \rightarrow → 实际上是全连接
- 操作: 使用 120 个 5 × 5 5 \times 5 5×5 的卷积核。
- 输出尺寸计算:
H o u t = 5 − 5 1 + 1 = 1 H_{out} = \frac{5 - 5}{1} + 1 = 1 Hout=15−5+1=1
故输出形状为:1 × 1 × 120 1 \times 1 \times 120 1×1×120。 - 参数量计算:
( 5 × 5 × 16 + 1 ) × 120 = 48120 (5 \times 5 \times 16 + 1) \times 120 = 48120 (5×5×16+1)×120=48120 - 解读: 因为卷积核大小和输入大小一样(都是 5 × 5 5 \times 5 5×5),这本质上就是将 5 × 5 × 16 5 \times 5 \times 16 5×5×16 的数据拉平,然后全连接到 120 个神经元上。
👉 第6层:F6 全连接层 (Fully Connected)
- 操作: 84 个神经元。
- 参数量计算:
( 120 + 1 ) × 84 = 10164 (120 + 1) \times 84 = 10164 (120+1)×84=10164
👉 输出层:Output
- 操作: 10 个神经元(对应数字 0-9),通常接 Softmax 激活函数。
- 参数量计算:
( 84 + 1 ) × 10 = 850 (84 + 1) \times 10 = 850 (84+1)×10=850
好的,遵命!这是激动人心的一刻------我们将从理论的"云端"降落到代码的"地面"。
第四章**【实战篇】**将是整个专栏中最具"获得感"的一章。我们将使用目前最流行、最优雅的深度学习框架 PyTorch,亲手复现 Yann LeCun 的杰作。
我不只是给你一段代码,我会像**"手把手教写字"**一样,逐行解释代码背后的含义,确保你不仅能跑通,还能看懂。
第四章:【实战篇】------ PyTorch 手撕 LeNet-5:30分钟搞定手写数字识别
在上一章,我们拆解了 LeNet-5 的精密结构。现在,是时候让它"活"过来了!
我们将使用深度学习领域的"Hello World"级数据集------MNIST 。它包含了 60,000 张手写数字图片(0-9)。我们的目标是:训练一个 LeNet-5 模型,让它像人类一样,看一眼图片就能准确说出上面的数字。
4.1 准备工作:我们的"武器库"
首先,我们需要导入 PyTorch 及其相关的工具箱。
torch: PyTorch 核心库。torch.nn: 神经网络构建工具箱 (Neural Network)。torchvision: 专门处理图像的工具库,里面有现成的数据集和图像变换工具。
python
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
# 设置随机种子,保证结果可复现
torch.manual_seed(42)
# 检查是否有 GPU,如果有就用 GPU 跑,没有就用 CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"🚀 当前使用的计算设备是: {device}")4.2 数据准备:喂给模型的"燃料"
MNIST 的原始图片大小是 28 × 28 28 \times 28 28×28,而 LeNet-5 的标准输入是 32 × 32 32 \times 32 32×32。所以我们需要做一个小小的填充 (Padding)。
python
# 定义图像预处理的操作序列
transform = transforms.Compose([
transforms.Pad(2), # 1. 四周各填充2个像素,28x28 -> 32x32
transforms.ToTensor(), # 2. 将图片转换为 PyTorch 张量 (Tensor)
transforms.Normalize((0.1307,), (0.3081,)) # 3. 标准化 (均值, 标准差),让数据分布更稳定
])
# 下载并加载训练集 (60000张)
train_dataset = torchvision.datasets.MNIST(root='./data', train=True,
download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
# 下载并加载测试集 (10000张)
test_dataset = torchvision.datasets.MNIST(root='./data', train=False,
download=True, transform=transform)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)
print(f"✅ 数据加载完毕!训练集: {len(train_dataset)} 张, 测试集: {len(test_dataset)} 张")4.3 搭建模型:用代码"盖房子"
这是本章的核心!我们将按照第三章的架构图,一行行把 LeNet-5 翻译成代码。
回顾结构:
Input(32x32) -> C1(6@28x28) -> S2(6@14x14) -> C3(16@10x10) -> S4(16@5x5) -> C5(120) -> F6(84) -> Out(10)
python
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
# --- 特征提取部分 (卷积 + 池化) ---
self.features = nn.Sequential(
# 第一层:C1 卷积层
# 输入: 1通道(灰度图), 输出: 6通道, 核大小: 5x5
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5),
nn.ReLU(), # 激活函数
nn.MaxPool2d(kernel_size=2, stride=2), # S2 池化层 (2x2)
# 第三层:C3 卷积层
# 输入: 6通道, 输出: 16通道, 核大小: 5x5
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2) # S4 池化层 (2x2)
)
# --- 分类决策部分 (全连接) ---
self.classifier = nn.Sequential(
# 第五层:C5 全连接层 (输入是 16 * 5 * 5 = 400)
nn.Linear(in_features=16*5*5, out_features=120),
nn.ReLU(),
# 第六层:F6 全连接层
nn.Linear(in_features=120, out_features=84),
nn.ReLU(),
# 输出层:Output (10个数字)
nn.Linear(in_features=84, out_features=10)
)
# 定义数据流向 (前向传播)
def forward(self, x):
# 1. 先经过特征提取器 (卷积+池化)
x = self.features(x)
# 2. 展平 (Flatten): 将立体特征图拉成一维向量
# x.size(0) 是 batch_size, -1 表示自动计算剩余维度 (16*5*5)
x = x.view(x.size(0), -1)
# 3. 再经过分类器 (全连接)
x = self.classifier(x)
return x
# 实例化模型并移至设备 (GPU/CPU)
model = LeNet5().to(device)
print(model) # 打印模型结构4.4 训练模型:开始"炼丹"
有了模型(身体)和数据(燃料),我们需要定义损失函数(指导方向)和优化器(动力引擎),然后开始循环训练。
python
# 1. 定义损失函数:交叉熵损失 (CrossEntropyLoss)
# 它会自动计算 Softmax 并比较预测值与真实标签的差距
criterion = nn.CrossEntropyLoss()
# 2. 定义优化器:Adam
# 相比传统的 SGD,Adam 能够自适应调整学习率,收敛更快
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 3. 开始训练循环
epochs = 5 # 训练 5 轮
print("🔥 开始训练...")
for epoch in range(epochs):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
# 获取输入和标签
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
# A. 梯度清零 (PyTorch 默认会累加梯度,所以每次反向传播前要清零)
optimizer.zero_grad()
# B. 前向传播 (Forward): 给模型看图片,算结果
outputs = model(inputs)
# C. 计算损失 (Loss): 算算结果离正确答案差多少
loss = criterion(outputs, labels)
# D. 反向传播 (Backward): 找出谁该为错误负责
loss.backward()
# E. 参数更新 (Step): 修改权重,争取下次对
optimizer.step()
# 打印统计信息
running_loss += loss.item()
if i % 200 == 199: # 每 200 个 batch 打印一次
print(f'[Epoch {epoch + 1}, Batch {i + 1}] Loss: {running_loss / 200:.4f}')
running_loss = 0.0
print("✨ 训练完成!")4.5 测试与可视化:是骡子是马,拉出来溜溜
模型训练好了,它到底聪不聪明?我们用测试集(模型没见过的图片)来考考它。
python
# 1. 整体准确率测试
correct = 0
total = 0
# 不计算梯度,节省显存
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
# torch.max 返回 (最大值, 最大值索引),我们只需要索引(即预测的数字)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'📊 模型在 10000 张测试图片上的准确率: {100 * correct / total:.2f}%')
# 2. 可视化预测结果 (抓几个典型看看)
def imshow(img, title):
# 反标准化以便显示
img = img * 0.3081 + 0.1307
npimg = img.numpy()
plt.imshow(npimg, cmap='gray')
plt.title(title)
plt.axis('off')
plt.show()
# 获取一个 batch 的测试数据
dataiter = iter(test_loader)
images, labels = next(dataiter)
images, labels = images.to(device), labels.to(device)
# 进行预测
outputs = model(images)
_, predicted = torch.max(outputs, 1)
# 显示前 5 张图片和预测结果
plt.figure(figsize=(10, 4))
for i in range(5):
ax = plt.subplot(1, 5, i+1)
# 移回 CPU 进行绘图
img = images[i].cpu().squeeze()
# 标题显示:预测值 (真实值)
title = f"Pred: {predicted[i].item()}\n(True: {labels[i].item()})"
# 如果预测错,标题标红;对,标绿
color = 'green' if predicted[i] == labels[i] else 'red'
plt.imshow(img, cmap='gray')
plt.title(title, color=color, fontweight='bold')
plt.axis('off')
plt.tight_layout()
plt.savefig('Lenet5_Prediction_Result.png', dpi=300)
plt.show()4.6 结果解读与小瑞瑞的"复盘"
当你运行完上述代码:
-
准确率: 你应该会看到准确率达到了 98% - 99% 左右。这意味着,对于手写的数字,LeNet-5 几乎达到了人类的识别水平!

-
Loss 曲线: 在训练过程中,你会看到 Loss 值从 2.3 左右迅速下降到 0.1 以下,这说明模型正在快速"学习"数字的特征。
-
可视化: 看着那些潦草的数字被计算机准确地识别出来,是不是有一种"赋予机器智慧"的成就感?

💡 思考题:
虽然 LeNet-5 在数字识别上表现完美,但如果你给它一张猫的图片 ,它会怎么做?
答案是:它依然会强行告诉你这是 0-9 中的某一个数字(而且可能还很自信)。因为它的世界观里只有数字。这引出了我们下一章的话题------如何处理更复杂、更通用的图像分类任务?
好的!遵命!
我们已经成功复现了 LeNet-5,它就像汽车工业里的"福特 T 型车",虽然经典,但毕竟是 1998 年的产物。面对今天高清、复杂的彩色照片,我们需要更强大的引擎。
第五章**【拓展篇】**,我们将穿越到深度学习爆发的黄金年代(2012-2015),见证 CNN 家族的"诸神之战"。我们将领略那些霸榜 ImageNet、改变了 AI 历史进程的传奇模型。
第五章-拓展篇------ 从 AlexNet 到 ResNet:CNN 的"诸神之战"与深度变革
👋 大家好,我是小瑞瑞!
恭喜你,你已经亲手训练出了你的第一个卷积神经网络!LeNet-5 在手写数字识别上表现完美。但是,如果你把一张猫的照片扔给它,它可能会一脸茫然。
为什么?因为 LeNet-5 太浅了(只有 5 层),参数太少了。现实世界中的物体千变万化,光线、角度、姿态各不相同,我们需要更深、更宽、更复杂的网络来捕捉这些特征。
于是,从 2012 年开始,一年一度的 ImageNet 图像识别挑战赛 (ILSVRC) 成为了 AI 界的"奥林匹克"。各路神仙打架,诞生了一系列传奇模型。
今天,我们就来快速浏览这短短几年间,CNN 是如何从"几层"进化到"上百层",并最终超越人类识别能力的!
5.1 王者归来:AlexNet (2012) ------ 深度学习的引爆点
在 2012 年之前,计算机视觉领域其实处于"寒冬"。大家普遍认为神经网络这东西"中看不中用",参数太多,训练不动。
直到 Alex Krizhevsky (Hinton 的学生)带着 AlexNet 横空出世,以碾压第二名 10% 的巨大优势夺冠,全世界都沸腾了!深度学习时代正式开启。
- 架构特点: 8 层网络(5个卷积层 + 3个全连接层)。
- 核心创新(也是今天的标配):
- ReLU 激活函数: 抛弃了 Sigmoid,解决了深层网络梯度消失的问题,训练速度快了 6 倍。
- Dropout: 在训练时随机"关掉"一半神经元,防止模型"死记硬背"(过拟合)。
- GPU 加速: 首次利用显卡(GTX 580)进行并行计算,把训练时间从几个月缩短到几天。
- 数据增强 (Data Augmentation): 对图片进行随机裁剪、翻转,强行增加数据量。
💡 小瑞瑞说: 如果 LeNet 是老爷车,AlexNet 就是第一辆法拉利。它证明了:只要数据够多、算力够强,神经网络可以战胜一切传统算法。
5.2 暴力美学:VGG (2014) ------ 更深、更简、更强
2014 年,牛津大学的 VGG 团队提出了一个简单粗暴的哲学:别整那些花里胡哨的,把网络做深!
- 架构特点: 16 层 (VGG-16) 或 19 层 (VGG-19)。
- 核心创新:
- 统一使用 3 × 3 3 \times 3 3×3 小卷积核:
在此之前,大家喜欢用 7 × 7 7 \times 7 7×7 甚至 11 × 11 11 \times 11 11×11 的大卷积核。VGG 证明了:堆叠两个 3 × 3 3 \times 3 3×3 的卷积层,视野(感受野)等于一个 5 × 5 5 \times 5 5×5,但参数量更少,非线性更强! - 像搭积木一样规整: 结构非常有规律,特别适合作为后续任务(如目标检测、风格迁移)的特征提取器(Backbone)。
- 统一使用 3 × 3 3 \times 3 3×3 小卷积核:
💡 小瑞瑞说: VGG 告诉我们:小就是大,深就是好。 直到现在,很多教程和工程项目依然喜欢用 VGG 作为基础网络。
5.3 宽度制胜:GoogLeNet / Inception (2014) ------ 上帝视角
同一年,Google 推出的 GoogLeNet 获得了冠军。它走了一条完全不同的路:不只做深,还要做宽。
- 痛点: 我们在设计网络时,总是纠结:这一层到底该用 1 × 1 1 \times 1 1×1 的核,还是 3 × 3 3 \times 3 3×3,还是 5 × 5 5 \times 5 5×5?
- 核心创新:Inception 模块(盗梦空间结构)
- 小孩才做选择,我全都要!
- 在一个层级里,同时并行使用 1 × 1 1 \times 1 1×1、 3 × 3 3 \times 3 3×3、 5 × 5 5 \times 5 5×5 的卷积核以及池化操作,然后把它们的结果拼起来 (Concat)。
- 这样,网络就能同时捕捉到"细节"和"概貌"。
💡 小瑞瑞说: GoogLeNet 就像一个拥有"多重影分身"的专家,能同时从不同角度观察图片。
5.4 登峰造极:ResNet (2015) ------ 解决"越深越傻"的悖论
随着网络越来越深(比如到了 20 层以上),科学家们发现了一个诡异的现象:网络越深,效果反而越差! 这不是过拟合,而是因为梯度消失------信号传着传着就丢了。
大神 Kaiming He (何恺明) 提出了 ResNet (残差网络) ,一举将网络深度干到了 152 层 ,甚至 1001 层!
- 核心创新:残差块 (Residual Block) / 跳跃连接 (Skip Connection)
- 思想: 既然深层网络容易把信息丢了,那我就修一条**"高速公路"**。
- 公式: H ( x ) = F ( x ) + x H(x) = F(x) + x H(x)=F(x)+x
- 解释: 这里的 + x +x +x 就是那条"短路连接"。意思就是:如果这一层学不到什么新东西 ( F ( x ) ≈ 0 F(x) \approx 0 F(x)≈0),至少把上一层传过来的信息 ( x x x) 原封不动地传下去!
- 这保证了深层网络至少不会比浅层网络差。
💡 小瑞瑞说: ResNet 是深度学习历史上的绝对里程碑。现在的 GPT、AlphaFold 等超级模型,背后都有残差连接的影子。它是真正让深度神经网络"深不见底"的功臣。
5.5 实战:在 PyTorch 中一键调用"诸神"
在 PyTorch 中,我们不需要像上一章那样一行行手写这些复杂的网络。torchvision.models 库里已经为我们封装好了这些"神级"模型。
代码示例:调用 ResNet-18 进行迁移学习
python
import torchvision.models as models
import torch.nn as nn
# 1. 一键加载预训练好的 ResNet-18 模型
# weights='DEFAULT' 表示使用在 ImageNet 上训练好的参数(拥有了识别1000种物体的能力)
resnet18 = models.resnet18(weights='DEFAULT')
print("🔒 原模型最后的全连接层:", resnet18.fc)
# 2. 修改最后的一层 (迁移学习)
# 假设我们要分类的是 2 种动物 (猫和狗),而不是 ImageNet 的 1000 类
# 我们把最后一层替换掉,输入特征数保持不变(512),输出改为 2
num_ftrs = resnet18.fc.in_features
resnet18.fc = nn.Linear(num_ftrs, 2)
print("🔓 修改后的全连接层:", resnet18.fc)
# 3. 接下来就可以像训练 LeNet-5 一样训练这个 ResNet 了!
# ... (训练代码略)终章:视觉的未来
从 1998 年的 LeNet-5 (几千参数),到 2015 年的 ResNet (几千万参数),再到如今的 Vision Transformer (ViT,几十亿参数),计算机视觉的发展速度令人咋舌。
- LeNet 教会了我们卷积。
- AlexNet 证明了深度学习可行。
- VGG 告诉我们要用小卷积核。
- ResNet 告诉我们要加短路连接。
现在,你已经掌握了这把开启 AI 视觉大门的钥匙。无论是人脸识别、自动驾驶,还是医疗影像诊断,它们背后的原理,都逃不过我们这两章所学的 CNN 核心机制。
🏆 最后的思考题:
我们今天介绍的模型主要用于**"图像分类"(判断图片里是什么)。但自动驾驶汽车不仅要知道前面是人还是车,还要知道 它具体在图片的哪个位置**(目标检测),甚至要精确勾勒出它的轮廓(语义分割)。
你认为,CNN 该如何改进,才能从输出一个简单的"标签",变成输出"坐标框"或者"像素级掩码"呢?
我是小瑞瑞,感谢你陪伴我完成了【计算机视觉】的入门之旅。如果这篇文章让你觉得热血沸腾,别忘了点赞👍、收藏⭐、关注!我们下一篇,不见不散!