涉及并发操作时,必然会面临共享资源的抢占问题,而锁正是解决这一问题的核心同步机制。
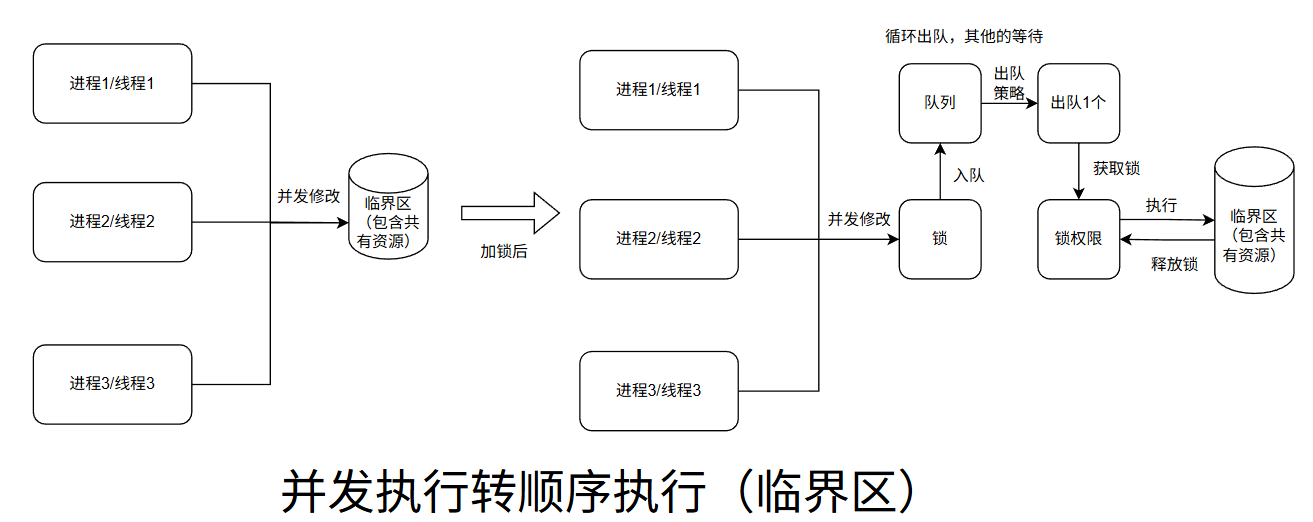
核心原理就是把并发操作,改为顺序执行操作。
一、简介
"锁"是一种用于控制对共享资源访问 的机制,广泛应用于计算机系统、操作系统、数据库、多线程编程、分布式系统 等领域。其核心目标是保证数据一致性、防止竞态条件(Race Condition)和避免并发错误。
举个例子:
想象一个公共洗澡间,一次只能容纳一个人使用。当有人进入时,会从内部上锁,防止其他人闯入;只有当前使用者洗完离开并解锁后,下一位人才能进入。
这正是锁(Lock)的基本原理 :当多个线程(或进程)竞争同一个有限且不可同时共享的资源(如内存、文件、设备等)时,通过"加锁"确保同一时刻仅有一个访问者,从而避免混乱和数据错误;使用完毕后"释放锁",允许其他等待者继续使用。
软件锁的发展:
| 时间 | 里程碑事件 / 技术 | 贡献者 / 系统 | 核心思想与意义 |
|---|---|---|---|
| 1965年 | 信号量(Semaphore) 提出 | Edsger W. Dijkstra | 首次形式化解决进程互斥与同步问题,引入 P/V 操作(wait/signal),成为并发控制基石。 |
| 1967年 | 管程(Monitor) 概念提出 | Per Brinch Hansen(后由 C.A.R. Hoare 完善) | 将共享数据与操作封装在一起,自动提供互斥访问,影响后续高级语言设计(如 Java)。 |
| 1970年代初 | 临界区(Critical Section) 与 互斥锁(Mutex) 在操作系统中实现 | Unix、THE 操作系统 | 内核提供基本互斥原语,用于保护共享资源,成为多任务系统标配。 |
| 1981年 | Peterson 算法发表 | Gary L. Peterson | 纯软件实现双线程互斥,无需硬件原子指令,在理论层面证明软件可解决互斥问题。 |
| 1980s | 自旋锁(Spinlock) 广泛用于多处理器内核 | BSD Unix、Linux 内核早期版本 | 适用于短临界区,避免上下文切换开销,但消耗 CPU。 |
| 1980s--1990s | 读写锁(Read-Write Lock) 引入 | 多种 Unix 变体 | 支持多读者并发,提升读密集型场景性能。 |
| 1990s | 条件变量(Condition Variable) 成为标准同步原语 | POSIX Threads (pthreads) | 与互斥锁配合,实现线程等待/唤醒机制(如生产者-消费者模型)。 |
| 1995年 | Java 1.0 引入 synchronized 关键字 |
Sun Microsystems | 基于 JVM 的内置管程机制,自动加锁/释放,简化线程安全编程。 |
| 2004年 | JDK 5 发布 java.util.concurrent 包 |
Doug Lea 等 | 引入 ReentrantLock、ReadWriteLock、Semaphore 等高级锁,支持公平性、可中断、超时等特性。 |
| 2000s 中期 | 无锁编程(Lock-Free Programming) 兴起 | 多家高性能系统(如数据库、交易系统) | 利用 CPU 原子指令(如 CAS - Compare-and-Swap)构建无锁队列、计数器,避免锁开销与死锁。 |
| 2010s | 分布式锁成为微服务基础设施 | Redis、ZooKeeper、etcd | 解决跨节点资源竞争问题,如:Redis 的 SET key value NX PX + RedLock;ZooKeeper 临时顺序节点。 |
| 2010s--至今 | 替代锁的并发模型普及 | Go(goroutine + channel)、Erlang(Actor)、Rust(所有权模型) | "不要通过共享内存来通信,而要通过通信来共享内存",减少对传统锁的依赖。 |
二、锁分类
2.1 按重量级分类
| 重量级层级 | 包含的锁 / 同步机制 | 说明 |
|---|---|---|
| 1. 无锁(Lock-Free / No Locking) | • CAS(Compare-And-Swap)原子操作 • AtomicInteger / AtomicReference 等原子类 • 无锁队列(Lock-Free Queue) • 无锁栈、无锁哈希表 • Disruptor 环形缓冲区 |
不使用传统锁,依赖 CPU 提供的原子指令(如 x86 的 cmpxchg)实现线程安全。线程永不阻塞,但冲突时需重试。适用于简单状态更新或高性能并发数据结构。 |
| 2. 轻量级锁(Lightweight Lock) | • 自旋锁(Spin Lock) • JVM 轻量级锁(Lightweight Locking) • Ticket Lock(票锁) • MCS Lock • 读写自旋锁(Read-Write Spinlock) • 用户态互斥(User-space Mutex,无竞争时) | 在用户态通过忙等(自旋)或 CAS 实现互斥,不触发线程挂起或内核切换。适合临界区极短、竞争低的场景。高竞争时通常会"膨胀"为重量级锁。 |
| 3. 重量级锁(Heavyweight Lock) | • 操作系统 Mutex(如 pthread_mutex) • JVM 重量级锁(即 synchronized 在竞争激烈时的状态) • Linux futex(Fast Userspace Mutex) • 信号量(Semaphore,当用作互斥且涉及阻塞时) • 条件变量(Condition Variable) • ReentrantLock(默认非公平模式,在阻塞等待时) • 文件锁(flock, lockf) |
依赖操作系统内核调度,线程在无法获取锁时被挂起(阻塞) ,由 OS 唤醒。涉及 用户态 ↔ 内核态切换,开销大,但适合长时间持有锁或高竞争环境,避免 CPU 空 |
根据具体场景的时候选择决定使用什么级别的锁。
| 特性 | 无锁 | 轻量级锁 | 重量级锁 |
|---|---|---|---|
| 是否阻塞线程 | 否 | 否(忙等) | 是(挂起) |
| 是否进入内核 | 否 | 否 | 是 |
| CPU 开销 | 低(但冲突时重试多) | 中(自旋消耗 CPU) | 高(上下文切换) |
| 延迟 | 极低 | 低(短临界区) | 高(唤醒有延迟) |
| 适用场景 | 简单原子操作、高频低冲突 | 短临界区、低竞争 | 长临界区、高竞争或必须阻塞 |
| 典型代表 | AtomicInteger、CAS 操作 |
JVM 轻量级锁、自旋锁 | synchronized(竞争时)、pthread_mutex |
2.2 按作用范围分类
分类依据:竞争主体是谁?资源在哪个层级共享?
作用范围决定了"锁如何被感知和传递" 。
不同范围的锁,底层实现完全不同,不能混用。例如,Java 的 ReentrantLock 对分布式场景完全无效。
| 类型 | 说明 | 典型场景 |
|---|---|---|
| 线程级锁(Thread-level Lock) | 用于同一进程内多个线程之间的互斥访问,保护共享内存中的临界区,是多线程编程中最基础的同步机制。 | Java synchronized、C++ std::mutex |
| 进程级锁(Process-level Lock) | 用于同一台机器上不同进程之间协调对共享资源(如文件、设备)的访问,通常依赖操作系统提供的 IPC 机制实现。 | 文件锁(flock)、System V 信号量、Windows Mutex |
| 分布式锁(Distributed Lock) | 用于跨多台服务器的分布式系统中,确保在集群环境下对全局唯一资源(如任务调度、库存扣减)的互斥访问,需解决网络延迟、节点故障等挑战。 | Redis 锁、ZooKeeper 临时节点、etcd lease |
按"作用范围"分类,是从系统架构层面回答:"这把锁能管住谁?"
2.2.1 . 线程级锁(Thread-level Lock)
用于同一进程内多个线程之间的互斥同步,保护共享内存中的临界区资源。
原理
- 所有线程共享同一地址空间,可直接访问同一把锁对象(如内存中的 mutex 变量)。
- 加锁/解锁操作通常由语言运行时或操作系统线程库(如 pthread)提供。
- 不涉及进程间通信或网络,开销最小。
典型实现
| 语言/平台 | 实现方式 |
|---|---|
| Java | synchronized、ReentrantLock、ReadWriteLock |
| C++ | std::mutex、std::shared_mutex(C++17) |
| Python | threading.Lock、RLock |
| Go | 虽鼓励 channel,但提供 sync.Mutex、RWMutex |
| POSIX | pthread_mutex_t |
适用场景
- 多线程修改全局变量、单例初始化、线程安全集合等。
- 示例:Web 服务器中多个请求线程并发更新用户会话缓存。
* 注意事项
- 仅对同进程内的线程有效,跨进程无效。
- 死锁、优先级反转等问题仍需防范。
伪代码(java)
// 共享资源
int counter = 0;
Object lock = new Object(); // 锁对象
// 多个线程执行以下逻辑
void increment() {
synchronized (lock) { // ← 获取线程级锁
counter = counter + 1; // ← 临界区(受保护)
} // ← 自动释放锁
}synchronized是 JVM 提供的线程级互斥锁。- 所有线程运行在同一个 JVM 进程内 ,共享
counter和lock。 - 跨进程无效(如另一个 Java 进程无法感知此锁)。
2.2.2 进程级锁(Process-level Lock)
用于同一台机器上多个独立进程之间协调对共享资源(如文件、设备、共享内存)的访问。
原理
- 进程内存空间隔离,无法直接共享普通锁变量。
- 必须依赖操作系统提供的 IPC(进程间通信)机制实现锁语义。
- 锁状态通常存储在内核或文件系统中,所有进程可感知。
典型实现
| 类型 | 说明 |
|---|---|
| 文件锁(File Lock) | 使用 flock()(BSD)或 fcntl()(POSIX)对文件加锁;简单可靠,常用于脚本防重复执行。 |
| System V / POSIX 信号量 | 内核维护的计数器,可用于互斥或限流(如 sem_open, sem_wait)。 |
| 命名互斥体(Named Mutex) | Windows 中通过名称创建跨进程 Mutex;Linux 可通过 /dev/shm + futex 模拟。 |
| 共享内存 + 自旋锁 | 高性能场景下,将锁变量放在共享内存中,配合原子操作实现(需谨慎处理崩溃恢复)。 |
适用场景
- 多个独立程序实例访问同一数据库文件(如 SQLite)。
- 后台守护进程确保单实例运行(如
crond、日志收集器)。 - 多进程 Web 服务器(如 Apache prefork 模式)共享监听套接字。
*注意事项
- 进程异常退出可能导致锁未释放(死锁),需配合超时或看门狗机制。
- 性能低于线程级锁(涉及系统调用)。
伪代码(python)
import fcntl
import time
import sys
LOCK_FILE = "/tmp/myapp.lock"
def main():
with open(LOCK_FILE, "w") as f:
try:
# 尝试获取排他文件锁(进程级)
fcntl.flock(f.fileno(), fcntl.LOCK_EX | fcntl.LOCK_NB)
print("获得锁,开始执行任务...")
time.sleep(10) # 模拟任务
print("任务完成")
except IOError:
print("另一个实例正在运行,退出。")
sys.exit(1)
finally:
# 文件关闭时自动释放锁(或显式 flock(LOCK_UN))
pass
if __name__ == "__main__":
main()fcntl.flock()是 Linux/Unix 的文件锁,由内核管理,对所有进程可见。- 即使脚本由不同用户启动,只要访问同一文件路径,锁就生效。
- 若进程崩溃未释放锁,重启后可手动清理
/tmp/myapp.lock。
2.2.3. 分布式锁(Distributed Lock)
用于跨多台服务器的分布式系统中 ,确保集群内对全局唯一资源的互斥访问。
原理
- 节点间无共享内存,必须依赖外部协调服务作为"第三方仲裁者"。
- 锁状态存储在高可用、强一致(或最终一致)的中间件中。
- 需解决:网络分区、节点宕机、时钟漂移、锁续期等分布式难题。
典型实现
| 中间件 | 实现方式 | 一致性模型 |
|---|---|---|
| Redis | SET key value NX PX timeout + Lua 脚本释放;RedLock 算法增强可靠性 |
最终一致(单机 Redis) 强一致(Redis Cluster + RedLock 争议较大) |
| ZooKeeper | 创建临时顺序节点(Ephemeral Sequential Node),最小序号者获得锁 | 强一致(ZAB 协议) |
| etcd | 利用 Lease(租约)+ Compare-and-Swap(CAS)实现锁 | 强一致(Raft 协议) |
| 数据库 | SELECT ... FOR UPDATE 或唯一索引 + 插入竞争 |
强一致(依赖 DB 事务) |
适用场景
- 分布式任务调度(如 Quartz 集群模式):确保定时任务只在一个节点执行。
- 秒杀系统:防止超卖,保证库存扣减原子性。
- 分布式 ID 生成器:避免 ID 重复。
- 配置中心变更通知:串行化处理配置更新。
*注意事项
- 必须设置超时(自动过期),防止客户端崩溃导致死锁。
- 锁续期(Watchdog) :长时间任务需后台线程定期延长锁有效期(如 Redisson 的
watchdog机制)。 - 释放锁需原子性:避免误删他人锁(Redis 中用 Lua 脚本校验 value)。
- CAP 权衡:强一致锁(ZK/etcd)可能牺牲可用性;高性能锁(Redis)可能牺牲一致性。
伪代码(redis+lua)
import redis
import time
import uuid
redis_client = redis.StrictRedis(host='redis-cluster', port=6379)
LOCK_KEY = "inventory:product_123"
LOCK_VALUE = str(uuid.uuid4()) # 唯一标识当前实例
LOCK_TIMEOUT = 10000 # 10秒过期(毫秒)
def acquire_lock():
# SET key value NX PX timeout ------ 原子加锁
return redis_client.set(
LOCK_KEY,
LOCK_VALUE,
nx=True, # only set if not exists
px=LOCK_TIMEOUT # auto expire
)
def release_lock():
# Lua 脚本:仅当 value 匹配时才删除(防误删)
lua_script = """
if redis.call("GET", KEYS[1]) == ARGV[1] then
return redis.call("DEL", KEYS[1])
else
return 0
end
"""
redis_client.eval(lua_script, 1, LOCK_KEY, LOCK_VALUE)
def deduct_stock():
if acquire_lock():
try:
stock = int(redis_client.get("stock:product_123") or 0)
if stock > 0:
redis_client.decr("stock:product_123")
print("扣减成功")
else:
print("库存不足")
finally:
release_lock() # 必须释放
else:
print("获取分布式锁失败,可能正在处理")
# 多个服务实例并发调用 deduct_stock()fcntl.flock()是 Linux/Unix 的文件锁,由内核管理,对所有进程可见。- 即使脚本由不同用户启动,只要访问同一文件路径,锁就生效。
- 若进程崩溃未释放锁,重启后可手动清理
/tmp/myapp.lock。
- 锁状态存储在 Redis 集群 中,所有服务节点共享。
NX + PX保证原子性;Lua 脚本保证释放安全性。- 必须设置超时,防止服务宕机导致死锁。
- 更高可靠方案:ZooKeeper(临时顺序节点)、etcd(lease + CAS)。
2.3 按功能与行为分类
分类依据:锁在运行时表现出什么样的控制语义和调度行为?
功能与行为决定了"锁如何管理访问顺序和并发粒度"。
| 类型 | 说明 | 适用场景 |
|---|---|---|
| 互斥锁(Mutex / Exclusive Lock) | 最基本的独占锁,保证同一时刻只有一个线程能进入临界区,适用于所有需要排他访问的场景。 | 保护临界区,如修改全局变量 |
| 读写锁(Read-Write Lock) | 允许多个读操作并发执行,但写操作必须独占;在"读多写少"场景下显著提升并发性能 | 读多写少场景(如缓存、配置) |
| 可重入锁(Reentrant Lock) | 允许同一线程多次获取同一把锁而不会死锁,内部通过持有者线程 ID 和计数器实现,适合递归调用或复杂嵌套逻辑。 | 避免递归调用导致死锁(如 Java ReentrantLock) |
| 公平锁 vs 非公平锁 | 公平锁按请求顺序分配锁,避免线程饥饿;非公平锁允许新线程"插队"抢锁,吞吐更高但可能造成某些线程长期等待。 | 公平锁防饥饿,非公平锁吞吐更高 |
| 自旋锁(Spin Lock) | 获取失败时不挂起线程,而是循环检查(忙等),适用于临界区极短、上下文切换成本高于 CPU 空转的场景(如内核或高性能库)。 | 临界区极短、上下文切换成本高(如内核) |
| 信号量(Semaphore) | 控制最多 N 个线程同时访问某类资源,本质是计数器,可用于限流、连接池管理或模拟互斥锁(当 N=1 时)。 | 连接池、限流、资源池管理 |
| 条件变量(Condition Variable) | 与互斥锁配合使用,让线程在特定条件不满足时主动挂起,并在条件达成时被唤醒,实现高效的线程协作(如生产者-消费者模型)。 | 生产者-消费者、线程协作 |
按"功能与行为"分类,是从编程模型层面回答:"这把锁怎么工作?"
2.3.1互斥锁(Mutex / Exclusive Lock)
| 项目 | 说明 |
|---|---|
| 定义 | 最基本的独占锁,确保同一时刻仅一个线程可进入临界区。 |
| 原理 | 线程尝试获取锁 → 成功则执行临界区;失败则阻塞(或自旋)等待。释放后唤醒等待者。 |
| 典型实现 | Java: synchronized, ReentrantLock C++: std::mutex POSIX: pthread_mutex_t |
| 适用场景 | 保护共享变量、单例初始化、资源独占访问等通用互斥需求。 |
| 优点 | 简单、通用、语义清晰。 |
| 缺点 | 串行化执行,高竞争时性能下降;可能死锁。 |
所有并发控制的"基石"。
伪代码:(java)
// 共享资源
int balance = 100;
Object mutex = new Object();
void withdraw(int amount) {
synchronized (mutex) { // ← 获取互斥锁
if (balance >= amount) {
balance -= amount; // ← 临界区
}
} // ← 自动释放锁
}本质:最基础的排他锁,synchronized 或 std::mutex 即为此类。
2. 读写锁(Read-Write Lock)
| 项目 | 说明 |
|---|---|
| 定义 | 支持多读单写:多个读线程可并发,写线程必须独占。 |
| 原理 | 内部维护两个锁:读锁(共享)和写锁(互斥)。写锁优先级通常更高(防写饥饿)。 |
| 典型实现 | Java: ReentrantReadWriteLock C++: std::shared_mutex (C++17) Go: sync.RWMutex |
| 适用场景 | 读多写少场景:缓存、配置中心、统计信息更新。 |
| 优点 | 显著提升读并发吞吐。 |
| 缺点 | 写操作可能被大量读阻塞(需注意写饥饿);实现比互斥锁复杂。 |
为"读多写少"量身定制的高性能锁。
伪代码(java)
允许多读并发,写操作独占。
ReadWriteLock rwLock = new ReentrantReadWriteLock();
Map<String, String> cache = new HashMap<>();
// 读操作
String get(String key) {
rwLock.readLock().lock(); // ← 获取读锁(可多个线程同时持有)
try {
return cache.get(key); // ← 并发安全读
} finally {
rwLock.readLock().unlock();
}
}
// 写操作
void put(String key, String value) {
rwLock.writeLock().lock(); // ← 获取写锁(独占)
try {
cache.put(key, value); // ← 独占写
} finally {
rwLock.writeLock().unlock();
}
}适用:缓存、配置等 读多写少 场景。
3. 可重入锁(Reentrant Lock)
| 项目 | 说明 |
|---|---|
| 定义 | 允许同一线程多次获取同一把锁,不会导致自死锁。 |
| 原理 | 内部记录持有者线程 ID + 重入计数器。每次加锁计数+1,释放-1,归零才真正释放。 |
| 典型实现 | Java: ReentrantLock(显式)、synchronized(隐式) Python: threading.RLock |
| 适用场景 | 递归调用、嵌套方法同步、复杂业务逻辑中多次进入同一临界区。 |
| 优点 | 避免同一线程死锁,编程更安全。 |
| 缺点 | 略微增加内存开销(需存储线程ID和计数)。 |
让"自己不卡自己"的智能锁。
示例(java):
同一线程可多次获取同一把锁,避免自死锁。
ReentrantLock lock = new ReentrantLock();
void outer() {
lock.lock();
try {
System.out.println("outer");
inner(); // ← 递归调用
} finally {
lock.unlock();
}
}
void inner() {
lock.lock(); // ← 同一线程再次加锁(成功!)
try {
System.out.println("inner");
} finally {
lock.unlock();
}
}关键:内部维护 线程ID + 重入计数器,计数归零才真正释放。
4. 公平锁 vs 非公平锁
| 项目 | 公平锁(Fair Lock) | 非公平锁(Non-fair Lock) |
|---|---|---|
| 定义 | 按请求顺序分配锁(FIFO) | 允许新线程"插队"抢锁 |
| 原理 | 维护等待队列,唤醒按序 | 新线程先尝试直接获取,失败再入队 |
| 典型实现 | Java: new ReentrantLock(true) |
Java: synchronized、ReentrantLock()(默认) |
| 优点 | 避免线程饥饿,行为可预测 | 吞吐更高(减少上下文切换) |
| 缺点 | 性能略低(需维护队列) | 可能导致某些线程长期等待 |
| 适用场景 | 对响应时间公平性要求高(如金融交易) | 追求高吞吐、低延迟(如 Web 服务) |
公平锁保"秩序",非公平锁拼"效率"。
示例(java):
是否按请求顺序分配锁。
// 公平锁:按 FIFO 顺序唤醒等待线程
ReentrantLock fairLock = new ReentrantLock(true);
// 非公平锁(默认):新线程可"插队"抢锁
ReentrantLock unfairLock = new ReentrantLock(); // 默认 false
void accessResource() {
unfairLock.lock();
try {
// 临界区
} finally {
unfairLock.unlock();
}
}- 公平锁:吞吐略低,但无饥饿;
- 非公平锁:吞吐高,但可能有线程长期等待。
5. 自旋锁(Spin Lock)
| 项目 | 说明 |
|---|---|
| 定义 | 获取失败时不挂起线程,而是循环检查(忙等)直到成功。 |
| 原理 | 用户态 CPU 循环执行 CAS 或 test-and-set 指令,持续尝试获取锁。 |
| 典型实现 | Linux 内核:spinlock_t Java:JVM 轻量级锁底层(短暂自旋) 用户态库:DPDK、高性能中间件 |
| 适用场景 | 临界区极短(< 1μs)、低竞争、多核环境(如内核、网络驱动)。 |
| 优点 | 无上下文切换开销,响应快。 |
| 缺点 | 浪费 CPU(空转);高竞争或长临界区会导致严重性能问题。 |
用 CPU 换时间,只适合"闪电战"。
示例(c):
忙等(不挂起线程),适合极短临界区。
// C 伪代码(用户态原子操作)
volatile int spinlock = 0;
void spin_lock() {
while (!__sync_bool_compare_and_swap(&spinlock, 0, 1)) {
// 忙等:持续尝试 CAS(Compare-And-Swap)
// 可加入 pause 指令优化 CPU
}
}
void spin_unlock() {
__sync_store(&spinlock, 0); // 释放锁
}
// 使用
void critical_section() {
spin_lock();
// 极短操作(如更新 flag)
spin_unlock();
}注意:仅适用于临界区 < 1μs 且低竞争场景,否则浪费 CPU。
6. 信号量(Semaphore)
| 项目 | 说明 |
|---|---|
| 定义 | 控制最多 N 个线程同时访问某类资源的计数器(N ≥ 1)。 |
| 原理 | 内部维护一个整型计数器: - acquire():计数 -1,若 <0 则阻塞 - release():计数 +1,唤醒等待者 |
| 典型实现 | Java: Semaphore POSIX: sem_wait/sem_post Python: threading.Semaphore |
| 适用场景 | 连接池、线程池、限流、生产者-消费者缓冲区大小控制。 |
| 优点 | 灵活控制并发度;可模拟互斥锁(N=1 时即为二值信号量)。 |
| 缺点 | 不记录持有者,无法实现可重入;易误用导致资源泄漏。 |
不是"门锁",而是"入场券发放机"。
示例(java):
控制最多 N 个线程同时访问资源。
// 最多 3 个线程同时访问数据库连接池 为1的时候为互斥锁
Semaphore dbPool = new Semaphore(3);
void accessDatabase() {
dbPool.acquire(); // ← 获取许可(若无则阻塞)
try {
// 使用数据库连接(最多3个并发)
} finally {
dbPool.release(); // ← 释放许可
}
}扩展:当 N=1 时,等价于互斥锁(二值信号量)。
7. 条件变量(Condition Variable)
| 项目 | 说明 |
|---|---|
| 定义 | 与互斥锁配合,实现线程"等待-通知"协作机制。 |
| 原理 | - wait():原子释放锁 + 挂起线程 - signal()/notify():唤醒一个等待者 - broadcast()/notifyAll():唤醒所有 |
| 典型实现 | Java: Object.wait()/notify()、Condition POSIX: pthread_cond_wait Python: threading.Condition |
| 适用场景 | 生产者-消费者、线程池任务调度、状态变更等待(如"等数据就绪")。 |
| 优点 | 高效协作,避免轮询浪费 CPU。 |
| 缺点 | 必须与互斥锁配对使用;易出现"虚假唤醒"(需用 while 循环检查条件)。 |
让线程"睡到条件满足再醒",是协作的桥梁。
示例(java):
线程等待某条件成立后再继续(配合互斥锁使用)。
ReentrantLock lock = new ReentrantLock();
Condition notEmpty = lock.newCondition();
Queue<String> queue = new LinkedList<>();
// 消费者
String take() {
lock.lock();
try {
while (queue.isEmpty()) {
notEmpty.await(); // ← 释放锁 + 挂起,等待通知
}
return queue.poll();
} finally {
lock.unlock();
}
}
// 生产者
void put(String item) {
lock.lock();
try {
queue.add(item);
notEmpty.signal(); // ← 唤醒一个等待者
} finally {
lock.unlock();
}
}- 必须在持有锁时调用
await(); - 使用
while而非if(防虚假唤醒); signal()唤醒一个,signalAll()唤醒全部。
2.4 按实现策略分类
分类依据:系统对并发冲突的基本假设是什么?采用何种哲学来保证正确性?
实现策略反映了系统对"并发本质"的理解与权衡(正确性 vs 性能 vs 复杂度)。
| 类型 | 说明 | 代表技术 |
|---|---|---|
| 悲观锁(Pessimistic Locking) | 假设并发冲突频繁,每次访问共享数据前都先加锁,确保安全但可能降低并发效率;典型如数据库行锁、Java synchronized。 |
数据库行锁、synchronized |
| 乐观锁(Optimistic Locking) | 假设冲突较少,不加锁直接操作,仅在提交时通过版本号或 CAS 检查是否被修改;若冲突则重试,适用于低竞争高吞吐场景。 | 数据库 version 字段、CAS(Compare-And-Swap) |
| 无锁(Lock-Free) | 不依赖传统锁机制,而是利用原子指令(如 CAS)构建数据结构,保证至少有一个线程能 progress,避免死锁和优先级反转。 | AtomicInteger、无锁队列(如 Disruptor) |
| 免锁(Wait-Free) | 无锁的更强形式,保证每个线程都能在有限步内完成操作,不受其他线程影响,实现复杂,多用于实时系统。 | 更强的无锁保证,实现复杂 |
按"实现策略"分类,是从并发理论和系统设计哲学层面回答:"我们相信世界是怎样的?"
2.4.1. 悲观锁(Pessimistic Locking)
| 项目 | 说明 |
|---|---|
| 核心思想 | "世界充满危险"------假设并发冲突一定会发生 ,因此在访问共享数据前先加锁,确保安全。 |
| 工作方式 | - 读/写前获取排他锁 - 操作完成后再释放锁 - 其他线程必须等待锁释放 |
| 典型实现 | - 数据库:SELECT ... FOR UPDATE - Java:synchronized、ReentrantLock - 操作系统:互斥锁(Mutex) |
| 适用场景 | - 写操作频繁 - 冲突概率高 - 要求强一致性(如金融交易) |
| 优点 | - 逻辑简单,正确性高 - 避免重试开销 |
| 缺点 | - 串行化执行,吞吐低 - 可能死锁、阻塞、优先级反转 - 锁竞争激烈时性能急剧下降 |
宁可错杀一千,不可放过一个------先锁再做事。
示例(java):
银行转账(强一致性要求)(数据库 + 应用层)
// 开启事务
beginTransaction();
try {
// 1. 加悲观锁(SELECT ... FOR UPDATE)
Account from = db.query("SELECT * FROM accounts WHERE id = ? FOR UPDATE", fromId);
Account to = db.query("SELECT * FROM accounts WHERE id = ? FOR UPDATE", toId);
// 2. 检查余额
if (from.balance < amount) throw new InsufficientFundsException();
// 3. 执行转账
from.balance -= amount;
to.balance += amount;
db.update("UPDATE accounts SET balance = ? WHERE id = ?", from.balance, fromId);
db.update("UPDATE accounts SET balance = ? WHERE id = ?", to.balance, toId);
commit(); // 提交事务,释放行锁
} catch (Exception e) {
rollback();
}- 数据库在
FOR UPDATE时对行加排他锁; - 其他事务读/写该行会被阻塞,直到当前事务提交;
- 适合写多、冲突高、强一致场景
2.4.2. 乐观锁(Optimistic Locking)
| 项目 | 说明 |
|---|---|
| 核心思想 | "世界基本和平"------假设冲突很少发生 ,因此不加锁直接操作,仅在提交时检查是否被修改,冲突则重试。 |
| 工作方式 | - 读取数据 + 版本号(或时间戳) - 在本地修改 - 提交时比对版本号: ✓ 相同 → 更新成功 ✗ 不同 → 失败重试 |
| 典型实现 | - 数据库:version 字段 + UPDATE ... WHERE version = ? - Java:AtomicInteger.compareAndSet(expected, newValue) - MVCC(多版本并发控制):PostgreSQL、MySQL InnoDB |
| 适用场景 | - 读多写少 - 冲突概率低 - 高吞吐需求(如电商浏览、配置更新) |
| 优点 | - 无锁开销,高并发性能好 - 避免死锁 |
| 缺点 | - 冲突高时重试成本大(CPU 浪费) - 不适合长事务(重试代价高) - 无法保证实时一致性 |
先做事,后验货;不行就重来。
示例代码(java):
商品信息编辑(多人可能同时查看,但少人同时修改)带 version 字段【不加锁,提交时检查版本是否被修改。】
class Product {
long id;
String name;
int version; // 乐观锁版本号
}
boolean updateProduct(Product newProd) {
Product old = db.query("SELECT id, name, version FROM products WHERE id = ?", newProd.id);
if (old == null) return false;
// 尝试更新:仅当 version 未变时才成功
int rows = db.update(
"UPDATE products SET name = ?, version = version + 1 WHERE id = ? AND version = ?",
newProd.name, newProd.id, old.version
);
if (rows == 0) {
// 冲突!别人已修改
throw new OptimisticLockException("数据已被他人修改,请重试");
}
return true;
}
// 调用方需处理重试
void editProductSafely(long id, String newName) {
int maxRetries = 3;
for (int i = 0; i < maxRetries; i++) {
try {
Product p = new Product(id, newName, 0);
if (updateProduct(p)) return; // 成功
} catch (OptimisticLockException e) {
if (i == maxRetries - 1) throw e;
Thread.sleep(10); // 短暂等待后重试
}
}
}- 无锁,高并发读性能好;
- 冲突时需应用层重试;
- 适合读多写少、冲突低场景。
2.4.3. 无锁(Lock-Free)
| 项目 | 说明 |
|---|---|
| 核心思想 | 完全摒弃传统锁 ,利用原子指令(如 CAS) 构建数据结构,保证至少有一个线程能 progress(不会全部卡住)。 |
| 工作方式 | - 使用 CPU 提供的原子操作(如 x86 的 cmpxchg) - 多线程通过循环 + CAS 更新共享状态 - 失败线程重试,但系统整体始终前进 |
| 典型实现 | - Java:AtomicInteger、ConcurrentLinkedQueue - C++:std::atomic - 高性能框架:Disruptor(无锁环形缓冲区) |
| 适用场景 | - 高频简单操作(计数器、指针切换) - 低延迟系统(交易引擎、实时日志) - 避免死锁/优先级反转的关键路径 |
| 优点 | - 无死锁、无优先级反转 - 高吞吐、低延迟(无上下文切换) |
| 缺点 | - 编程复杂,调试困难 - ABA 问题需额外处理(如加版本戳) - 重试可能浪费 CPU |
没有门卫,但大家靠"原子礼仪"自觉排队。
示例代码(java):
用原子指令(如 CAS)实现线程安全,系统整体始终 progress。高并发计数器
import java.util.concurrent.atomic.AtomicLong;
AtomicLong counter = new AtomicLong(0);
void increment() {
long current, next;
do {
current = counter.get(); // 读当前值
next = current + 1;
// CAS:仅当值仍为 current 时才更新为 next
} while (!counter.compareAndSet(current, next));
// 失败则重试,但至少有一个线程会成功 → Lock-Free
}
// 或直接使用内置方法(内部也是 CAS 循环)
void incrementSimple() {
counter.incrementAndGet(); // 原子自增
}- 无阻塞、无死锁;
- 适用于简单状态更新(计数器、指针切换);
- ABA 问题 需注意(可用
AtomicStampedReference解决)。
2.4.4. 免锁(Wait-Free)
| 项目 | 说明 |
|---|---|
| 核心思想 | 比 Lock-Free 更强:每个线程都能在有限步内完成操作,不受其他线程影响。 |
| 特点 | - 无任何等待、重试或依赖 - 实时系统理想选择 |
| 实现难度 | 极高,通常仅用于特定数据结构(如某些队列、栈) |
| 典型应用 | 航空航天、工业控制等硬实时系统 |
人人独立,永不等待;
示例代码(java):
每个线程都能在有限步内完成操作,完全不受其他线程影响。Wait-Free 队列(理论模型)基于环形缓冲区 + 原子索引
// Wait-Free Queue(简化版,假设单生产者单消费者)
class WaitFreeQueue<T> {
private final T[] buffer = (T[]) new Object[CAPACITY];
private final AtomicLong head = new AtomicLong(0); // 出队位置
private final AtomicLong tail = new AtomicLong(0); // 入队位置
boolean enqueue(T item) {
long currentTail = tail.get();
long currentHead = head.get();
if (currentTail - currentHead >= CAPACITY) {
return false; // 队列满
}
// 直接写入,无需重试(因 tail 是原子递增)
buffer[(int)(currentTail % CAPACITY)] = item;
tail.lazySet(currentTail + 1); // 最终一致性写入
return true;
}
T dequeue() {
long currentHead = head.get();
long currentTail = tail.get();
if (currentHead == currentTail) {
return null; // 队列空
}
T item = buffer[(int)(currentHead % CAPACITY)];
buffer[(int)(currentHead % CAPACITY)] = null;
head.lazySet(currentHead + 1);
return item;
}
}- 此例为 单生产者-单消费者 的 Wait-Free 实现(无竞争);
- 真正的多生产者 Wait-Free 队列(如 Michael-Scott)需更复杂算法;
三、锁
3.1 锁和临界区
"临界区"和"锁"是并发编程中两个紧密关联的核心概念。它们共同解决多个执行单元(线程/进程)同时访问共享资源时可能导致的数据不一致或竞态条件(Race Condition)问题。
临界区:指程序中访问共享资源(如变量、文件、设备等)的一段代码 ,这段代码必须被互斥执行------即同一时刻只能有一个线程/进程在执行它。
锁(Lock):是一种同步机制 ,用于控制对临界区的访问,确保同一时间只有一个执行单元能进入临界区。
锁的作用就是保护临界区。没有锁,临界区就无法安全并发;没有临界区,锁就失去了存在的意义。
在实际编程中,临界区的划分直接影响锁的性能与安全性。若临界区划分过小,可能导致频繁加锁解锁,增加开销;若划分过大,则会过度限制并发,降低程序吞吐量。例如,在处理用户订单数据时,若将"查询订单信息"和"修改订单状态"都纳入同一个临界区,会导致多个读请求无法并发;而合理的做法是将"修改订单状态"作为临界区加锁保护,"查询订单信息"通过读写锁的读模式允许并发访问,平衡安全性与效率。
此外,临界区的原子性保障依赖锁的正确使用。必须确保锁的粒度与临界区完全匹配,即"进临界区前加锁,出临界区后解锁",且加锁与解锁必须成对出现。若出现"加锁后未解锁"的情况,会导致锁永久持有,其他线程无法进入临界区,引发死锁;若"未加锁就进入临界区",则无法避免竞态条件,导致数据错误。在 Java 中,synchronized 关键字会自动完成加锁与解锁(异常时也会释放锁),而 ReentrantLock 则需要手动通过 try-finally 块保证解锁,避免异常场景下的锁泄漏。
3.2 锁的核心特性
理解锁的特性是正确使用锁的前提,除了前文分类中提及的可重入性、公平性等,锁还具备以下核心特性:
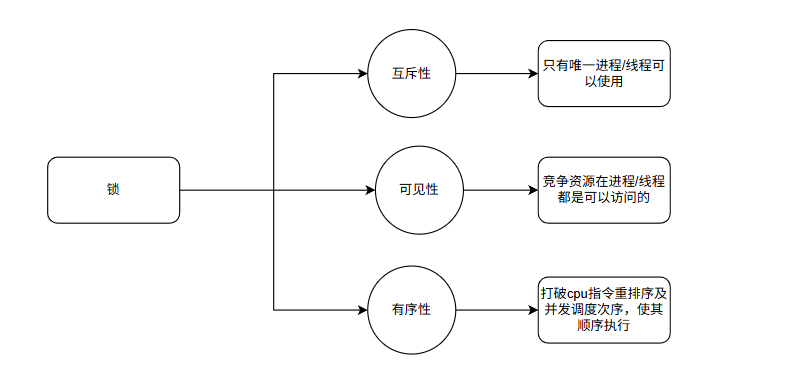
1. 互斥性:这是锁最基础的特性,确保同一时刻只有一个线程(或进程)能持有锁并进入临界区。互斥性是保证数据一致性的核心,无论是互斥锁、读写锁的写模式,还是分布式锁,都严格遵循互斥性原则。需要注意的是,读写锁的读模式不具备互斥性,其设计初衷是在读多写少场景下提升并发,通过"读-读兼容、读-写互斥、写-写互斥"的规则平衡互斥与并发。
2. 可见性:锁不仅能控制临界区的访问权限,还能保证共享资源的可见性。在多线程环境中,线程会将共享变量缓存到本地工作内存,若未加锁,一个线程修改的变量可能无法及时被其他线程感知,导致脏读。而加锁操作会强制线程刷新本地缓存,将修改后的变量同步到主内存;解锁操作则会确保本地缓存中的修改已同步到主内存,从而保证后续获取锁的线程能读取到最新的变量值。例如,Java 中的 synchronized 和 ReentrantLock 都能保证可见性,这也是它们区别于普通变量的关键特性之一。
3. 有序性:并发环境中,CPU 可能会对指令进行重排序以提升执行效率,这可能导致程序执行顺序与代码逻辑顺序不一致,引发潜在问题。锁能禁止指令重排序,确保临界区内的代码按逻辑顺序执行。例如,在单例模式的双重检查锁定实现中,若未使用 volatile 关键字或锁机制,可能因指令重排序导致创建出多个实例;而通过锁包裹实例创建逻辑,可强制指令有序执行,避免该问题。
3.3 锁的常见风险与规避策略
锁的使用虽能解决并发问题,但不当使用会引入新的风险,常见的有死锁、活锁、饥饿以及性能损耗等,需针对性采取规避策略。
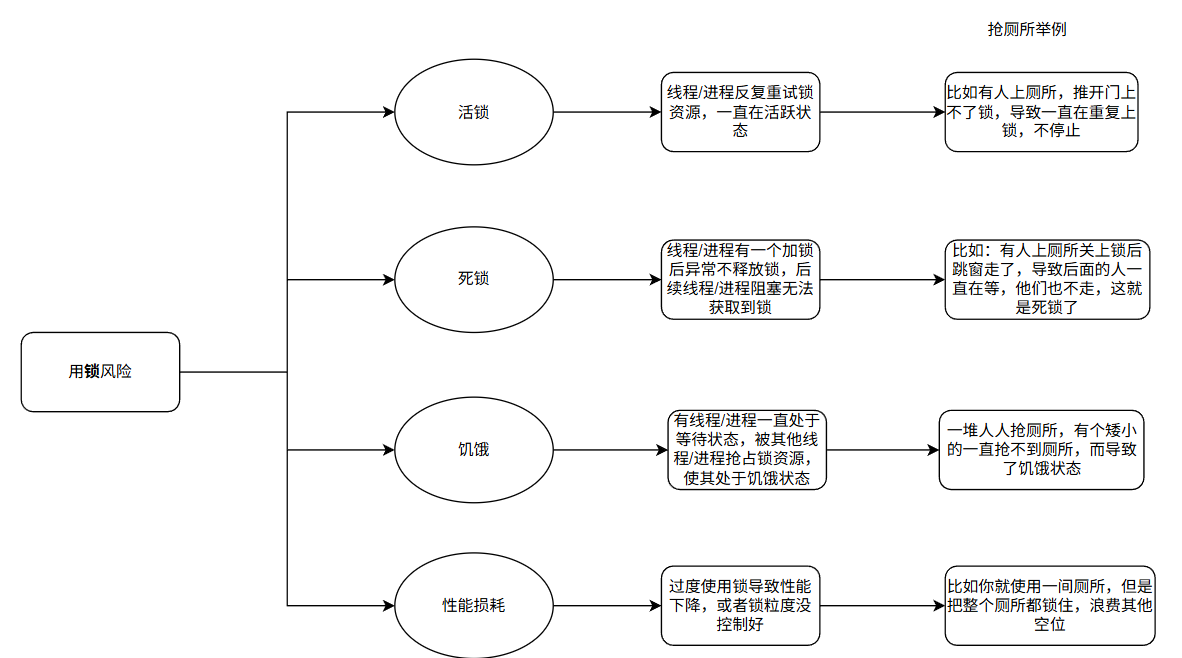
1. 死锁:
指两个或多个线程互相持有对方所需的锁,且都不主动释放,导致所有线程永久阻塞。例如,线程 A 持有锁 1 并等待锁 2,线程 B 持有锁 2 并等待锁 1,此时两者陷入死锁。
规避死锁的核心原则包括:
一是按固定顺序加锁,确保所有线程获取锁的顺序一致,避免循环等待;
二是设置锁超时时间,若线程在指定时间内未获取到锁,则主动释放已持有的锁,打破阻塞状态(如 ReentrantLock 的 tryLock 方法);
三是使用可中断锁,允许线程在等待锁的过程中响应中断信号,主动退出等待(如 ReentrantLock 的 lockInterruptibly 方法);
四是定期检测死锁,通过工具(如 Java 的 jstack)排查死锁线程,及时优化锁的使用逻辑。
2. 活锁:
指线程虽未阻塞,但因不断重试操作而无法推进执行。例如,两个线程同时获取锁失败后,都立即释放自身资源并重新尝试获取,导致两者反复重试却始终无法获取到锁。活锁与死锁的区别在于,活锁中的线程处于活跃状态,而死锁中的线程处于阻塞状态。
规避活锁的策略包括:
一是引入随机延迟,线程获取锁失败后,随机等待一段时间再重试,避免多个线程同步重试;
二是设置重试次数上限,若超过次数则暂停重试或降级处理,避免无限循环;
三是优化锁的竞争逻辑,减少不必要的重试操作。
3. 饥饿:
指某个线程长期无法获取锁,始终处于等待状态。常见原因包括锁的非公平性、线程优先级不合理等。例如,在非公平锁机制下,新线程可能频繁"插队"获取锁,导致老线程长期等待;若高优先级线程持续竞争锁,低优先级线程可能永远无法获取锁。
规避饥饿的策略包括:
一是使用公平锁,按线程请求锁的顺序分配锁,确保每个线程都有机会获取锁;
二是合理设置线程优先级,避免优先级倒置;
三是限制锁的持有时间,避免线程长时间占用锁,给其他线程获取锁的机会。
4. 性能损耗:
锁的加锁、解锁操作以及线程阻塞/唤醒都会带来开销,过度使用锁或锁粒度不当会严重影响程序性能。
优化策略包括:
一是减小锁粒度,将大临界区拆分为多个小临界区,降低锁的竞争概率(如 Java 中的 ConcurrentHashMap 采用分段锁机制,将哈希表分为多个段,每个段单独加锁,提升并发性能);
二是使用合适的锁类型,根据场景选择无锁、轻量级锁或重量级锁,读多写少场景优先使用读写锁;
三是避免锁的嵌套,减少重入锁的使用次数,降低锁管理开销;四是采用锁消除优化,编译器或 JVM 会自动消除不必要的锁(如对局部变量加锁,因局部变量不共享,锁无实际意义,会被自动消除)。
3.4 使用场景
| 典型业务场景 | 核心并发问题 | 推荐锁 / 同步机制 | 推荐理由 |
|---|---|---|---|
| 单例模式懒加载(双重检查) | 多线程同时初始化实例 | synchronized + volatile 或 ReentrantLock |
保证实例创建的原子性与可见性;JVM 对 synchronized 优化后性能良好 |
| 高并发计数器(如 PV 统计) | 多线程对整型变量自增 | AtomicLong / LongAdder |
无锁 CAS 操作,避免重量级锁开销;LongAdder 在高竞争下性能更优 |
| 缓存读多写少(如配置、热点数据) | 多读一写,需保证一致性 | ReentrantReadWriteLock(读写锁) |
允许多个线程并发读,写时独占,显著提升读吞吐 |
| 数据库连接池 / 线程池资源管理 | 限制同时使用的资源数量 | Semaphore(信号量) |
精确控制并发访问数(如最多 10 个连接),天然匹配资源池模型 |
| 生产者-消费者模型(任务队列) | 生产满时阻塞生产者,消费空时阻塞消费者 | BlockingQueue(内部用 ReentrantLock + Condition) |
JDK 提供成熟实现(如 ArrayBlockingQueue),无需手写锁逻辑 |
| 递归方法中的同步(如遍历树并修改) | 同一线程多次进入临界区 | ReentrantLock 或 synchronized |
两者均支持可重入,避免自死锁 |
| 短临界区、低竞争(如更新标志位) | 需要极低延迟的互斥 | 自旋锁(Spin Lock)或 JVM 轻量级锁 | 避免线程挂起/唤醒开销,适合微秒级操作 |
| 跨 JVM 实例的分布式任务调度 | 多服务实例争抢唯一任务 | 分布式锁(Redis + RedLock / ZooKeeper) | 确保集群中仅一个节点执行关键任务(如定时批处理) |
| 秒杀/库存扣减(高并发写) | 超卖风险,需强一致性 | 数据库悲观锁(SELECT ... FOR UPDATE) + 本地缓存预减 |
悲观锁保证 DB 层原子性;缓存层用 Redis incr/decr + Lua 脚本防超卖 |
| 日志写入(多线程追加) | 多线程写同一文件乱序 | synchronized 块 或 ReentrantLock |
保证写操作原子性;若性能敏感,可改用异步日志框架(如 Logback AsyncAppender) |
| 状态机变更(如订单状态流转) | 防止并发修改导致状态错乱 | 乐观锁(version 字段) | 通过版本号校验更新是否成功,失败则重试,避免长时间持锁 |
| 高性能无锁队列(如 Disruptor) | 极致吞吐,避免锁竞争 | 无锁环形缓冲区(CAS + 内存屏障) | 适用于金融交易、高频事件处理等场景,延迟可降至纳秒级 |
总结:
没有"最好"的锁,只有"最合适"的锁 。
综合考虑:
- 资源特性(是否可共享、读写比例)
- 竞争强度(低/高并发)
- 临界区长度(短/长)
- 系统架构(单机/分布式)
- 一致性要求(强一致/最终一致)
实际开发中,最常用的核心锁不超过 6 种如下:
- 互斥锁(Mutex)
- 读写锁(Read-Write Lock)
- 可重入锁(Reentrant Lock)
- 信号量(Semaphore)
- 自旋锁(Spin Lock)
- 分布式锁(Distributed Lock)