本文是「DINO 系列」的第二篇:
- 第一篇:DINOv1 原理的详细介绍(self-distillation with no labels)
- 第二篇:DINOv2 原理的详细介绍(你现在看到的这篇)
- 第三篇:DINOv3 原理的详细介绍(下一篇
DINOv2 这篇工作可以直接理解成:把 DINOv1、iBOT 等一堆自监督技巧「凑成一个最强配方」,然后在「超大干净数据集 + 超大 ViT」上把配方拉满,从而得到一套「啥都能用、跨任务泛化很强」的视觉基础特征(visual foundation features)。
本文尽量站在工程实践视角来讲清楚:
- DINOv2 想解决什么问题?
- LVD-142M 数据集是怎么自动构建出来的?
- 模型结构、损失函数到底长啥样?
- 训练时为了「能训得动」做了哪些工程优化?
- 在下游项目(分类 / ReID / 检索 / 分割 / 深度估计)里该怎么用?
- 和 DINOv1 相比,选型上有什么差异?
0. 从 DINO 到 DINOv2:问题背景
0.1 DINOv1 回顾(超简)
在第一篇里我们已经说过:DINOv1 的核心是 Student--Teacher 自蒸馏 + 多视角增强:
- Student 和 Teacher 结构基本一致(通常是 ViT);
- Teacher 参数是 Student 的 指数滑动平均(EMA);
- 给同一张图片做多种增强(global / local crop),送入 Student 和 Teacher;
- 让 Student 在不同视角下的输出对齐 Teacher 的输出(交叉熵);
- 再配合 Centering、Temperature 等 trick,避免塌缩。
DINOv1 的几个关键现象:
- 无需监督就能学出清晰的语义分割 / 部件掩码;
- ViT 特征在 kNN / 线性评估上表现非常强;
- 但整体还是在 ImageNet 这类中等规模数据 上验证,规模和「基础模型」还有距离。
0.2 DINOv2 想进一步做到什么?
DINOv2 的目标可以一句话概括:
用纯自监督,在大规模「干净」图像上预训练 ViT,得到一套「冻住就能直接用」的视觉基础特征。
具体来说,它要同时满足:
-
高性能 & 高鲁棒性
- ImageNet 线性评估接近甚至追平强监督 / OpenCLIP 等;
- 各种 ImageNet 变种(ImageNet-V2/-A/-R/-Sketch 等)上 OOD 性能很强;
- 对下游数据分布变化不过分敏感。
-
多任务通吃
- 图像级:分类、检索、动作识别等;
- 像素级:语义分割、深度估计等;
- 最好是 冻住 backbone,只训一个简单 head 就能打遍天下。
-
规模可扩展
- 数据:从传统的 ImageNet-1K/22K 跳到 1.4 亿级别 LVD-142M;
- 模型:从 ViT-S/B/L 拉到 ViT-g(10 亿参数量级);
- 训练:要能在合理时间和资源内训完。
DINOv2 的一系列设计,基本都围绕这三个目标展开。

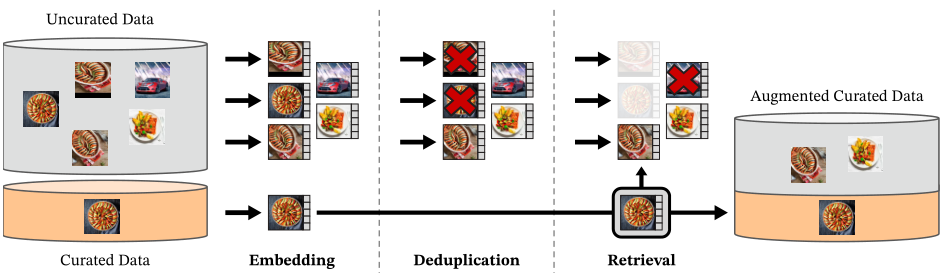
1. 数据:自动构建的大规模无监督数据集 LVD-142M
DINOv2 提出了一条数据管线,构建一个约 1.42 亿张图片 的无标签数据集,称为 LVD-142M 。核心思想:从多源图像中「自动」筛出高质量、多样、去重的数据。大致步骤:
-
数据来源多样化
- 已有的高质量标注数据集(例如 ImageNet-22K、ADE20K、Places 等);
- 海量 Web 抓取的未标注图像(噪声大,但覆盖面广)。
-
先用现有模型做特征提取
- 选一个已经训练好的强特征模型(例如旧版自监督模型);
- 对所有候选图片提取全局 embedding。
-
去重与数据清洗
- 在 embedding 空间做近邻搜索:
- 去除几乎相同的图片(如重复抓取、轻微缩放/裁剪版);
- 严格去掉与各种公开评测集(ImageNet val/test、下游基准等)的重叠,防止泄漏。
- 在 embedding 空间做近邻搜索:
-
基于检索的「自动扩充」
- 把高质量小数据集的图片当作 query;
- 从海量 web 图片 embedding 库中检索相似图片;
- 类似于「用已有干净数据当种子,从 web 里拉一圈相似分布的图」。
-
多任务 / 多域覆盖
- 通过选取不同 seed 数据集 + 检索策略,刻意让数据覆盖:
- 分类、细粒度分类、场景理解;
- 分割 / 深度相关场景;
- 不同风格(照片、插画、艺术品等)、不同拍摄条件。
- 通过选取不同 seed 数据集 + 检索策略,刻意让数据覆盖:
这条 pipeline 有几个工程上的好处:
- 不依赖文本描述或人工标注,完全靠视觉 embedding 构建;
- 和「随便抓 web 图 + 自监督」相比,
- 更容易控制 分布和难度(比如细粒度 / 城市场景等);
- 更容易做数据去重和隐私控制;
- 也为后来的视觉基础模型(SAM、Depth Anything 等)提供了一个通用套路:先搞一个大而干净的视觉预训练集 。
2. 模型结构:ViT + Student--Teacher + patch 预测
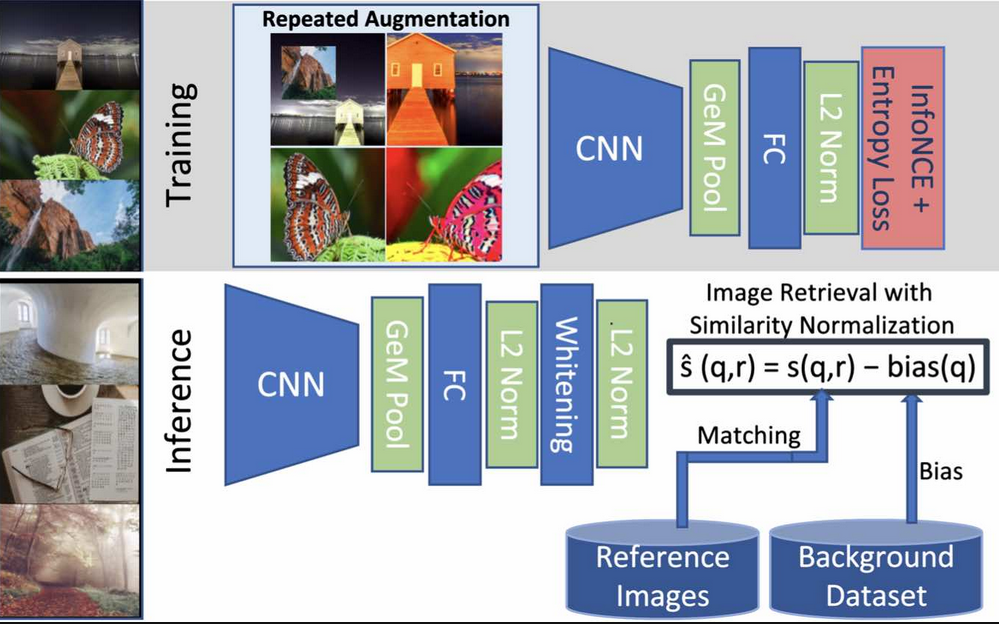
2.1 Backbone:一整族 ViT 模型
DINOv2 主要使用 ViT / ViT with registers 作为 backbone:
- Patch size 通常是 14×14(S/B/L/g 全家桶);
- 输入图像先被切成 patch,线性投影后加上位置编码;
- Transformer Encoder 输出:
- CLS token / register token(做全局表示);
- 所有 patch token(做局部 / 像素级任务)。
实际开源模型包括:
- ViT-S/14、ViT-B/14、ViT-L/14、ViT-g/14;
- 每个又有「带 register」和「不带 register」两个版本。
从工程视角看,你可以简单把它当成:一套用自监督训练好的 ViT backbone,不同规模的模型适配不同算力预算。
2.2 Student--Teacher 框架 & EMA 更新
DINOv2 延续了 DINOv1 / iBOT 的套路:使用 Student--Teacher 自蒸馏框架:
- Student:负责反向传播和参数更新;
- Teacher:用来提供稳定的「软标签」;
- Teacher 的参数是 Student 的 EMA:
ablahetastudentL ext用于更新Student abla_{ heta_{\mathrm{student}}} L \;\; ext{用于更新 Student}ablahetastudentLext用于更新Student
hetateacher←mhetateacher+(1−m)hetastudent heta_{\mathrm{teacher}} \leftarrow m heta_{\mathrm{teacher}} + (1 - m) heta_{\mathrm{student}}hetateacher←mhetateacher+(1−m)hetastudent
其中:
- ( heta_{\mathrm{student}} ):学生网络参数;
- ( heta_{\mathrm{teacher}} ):教师网络参数;
- ( m ):动量系数(接近 1,且随训练进度缓慢增大)。
这样一来:
- Student 每次都朝着一个 「平滑历史平均」的 Teacher 学习;
- Teacher 自身不接受梯度,因此比 Student 更稳定;
- 在大规模训练中,有利于避免训练震荡和模式塌缩。
3. 自监督目标:图像级 + Patch 级 + 正则项
DINOv2 的损失可以理解为三个部分:
- 图像级 DINO loss(global);
- Patch 级 iBOT 风格 masked prediction(local);
- 防止特征塌缩 / 促进多样性的正则项。
3.1 图像级 DINO loss
和 DINOv1 类似,图像级目标是对齐 Student 与 Teacher 的「类别分布」,但这里的「类别」是自监督学出来的 prototype,不是真实标签。
设:
- ( p^{\mathrm{teacher}} \in \mathbb{R}^{K} ):Teacher 对某个全局视角的 softmax 输出;
- ( p^{\mathrm{student}} \in \mathbb{R}^{K} ):Student 对另一个视角的 softmax 输出;
则 DINO loss 为:
LDINO=−∑k=1KpkteacherlogpkstudentL_{\mathrm{DINO}} = - \sum_{k=1}^{K} p^{\mathrm{teacher}}_k \log p^{\mathrm{student}}_kLDINO=−k=1∑Kpkteacherlogpkstudent
- 实际训练时,会对同一张图片构造多种 global view(大 crop);
- Teacher 只看部分视角,Student 看所有视角;
- 对所有「视角对」的 cross-entropy 求平均。
3.2 Patch 级目标:iBOT 风格 masked prediction
相比 DINOv1,DINOv2 的另一大升级是:加入 patch 级目标(iBOT 思路):
- 对 Student 输入的 patch 序列做随机 mask(比如 mask 掉 40% patch);
- Teacher 看到的是 没被 mask 掉 的完整图像;
- 对于被 mask 掉的位置:
- Student 仍会输出一个 token 表示这个位置;
- 让 Student 的该 token 去匹配 Teacher 对应位置 token 的 cluster 分布。
设:
- ( M ):被 mask 的 patch 数量;
- ( qmteacherq^{\mathrm{teacher}}_{m}qmteacher ):Teacher 在第 ( m ) 个 mask 位置的 soft 分布;
- ( qmstudentq^{\mathrm{student}}_{m}qmstudent ):Student 在对应位置的预测分布;
则 patch 级 loss:
LiBOT=−1M∑m=1M∑k=1Kqm,kteacherlogqm,kstudentL_{\mathrm{iBOT}} = - \frac{1}{M} \sum_{m=1}^{M} \sum_{k=1}^{K} q^{\mathrm{teacher}}{m,k} \log q^{\mathrm{student}}{m,k}LiBOT=−M1m=1∑Mk=1∑Kqm,kteacherlogqm,kstudent
直观理解:
- 把「预测被遮挡 patch」这个任务,从像素级重建(MAE)变成了「预测语义 cluster」;
- 和 MAE 相比,更关注语义层面的一致性,而不是低层细节;
- 又保留了 MAE 那种「通过遮挡促使模型理解上下文」的能力。
3.3 Centering:防止输出塌缩
像 DINOv1 一样,DINOv2 在 Teacher 端也做了 在线 centering:
- 维护一个缓慢更新的全局中心向量 ( c );
- 对 Teacher 的 logits 做平移:
zteacher←zteacher−cz^{\mathrm{teacher}} \leftarrow z^{\mathrm{teacher}} - czteacher←zteacher−c
中心更新:
c←λc+(1−λ)1B∑b=1Bg(vb)c \leftarrow \lambda c + (1 - \lambda)\frac{1}{B} \sum_{b=1}^{B} g(v_b)c←λc+(1−λ)B1b=1∑Bg(vb)
其中:
- ( B ):batch size;
- ( g(v_b) ):Teacher 对第 ( b ) 张图片的某个中间表示的函数(论文中采用简单的线性映射);
- ( lambda ):动量系数。
Centering 的作用:
- 避免所有样本都被挤到同一个原型(cluster)上;
- 在大规模训练下保持输出分布的多样性。
3.4 KoLeo 正则:让特征空间「铺开」
DINOv2 还加入了一个叫 KoLeo regularizer 的东西,目的同样是防止特征挤在一起:
- 对 batch 内每个特征向量 ( x_i ),找到它与其它样本的最近邻距离 ( d_i );
- 惩罚这些最近邻距离太小的情况:
LKoLeo=−1n∑i=1nlogdiL_{\mathrm{KoLeo}} = -\frac{1}{n} \sum_{i=1}^{n} \log d_iLKoLeo=−n1i=1∑nlogdi
其中 ( n ) 是 batch 大小。
直观上,相当于:
- 鼓励最近邻距离变大;
- 让样本在特征空间中更加均匀地铺开,避免「一团糊」。
3.5 总损失
综合起来,DINOv2 的整体损失可以写成:
L=λimgLDINO+λpatchLiBOT+λKoLeoLKoLeoL = \lambda_{\mathrm{img}} L_{\mathrm{DINO}} + \lambda_{\mathrm{patch}} L_{\mathrm{iBOT}} + \lambda_{\mathrm{KoLeo}} L_{\mathrm{KoLeo}}L=λimgLDINO+λpatchLiBOT+λKoLeoLKoLeo
其中每个 ( \lambda ) 是对应 loss 的权重,实际训练中通过经验和 ablation 调整。
4. 训练技巧与工程细节
DINOv2 的一个重要贡献是:把各种工程 trick 系统性地整合起来,让「大模型 + 大数据」变得可训练。
4.1 Multi-crop & 高分辨率收尾
和 DINOv1 一样,DINOv2 也使用了多视角 / 多尺度 crop:
- 若干个 global crop(例如 224×224);
- 若干个 local crop(例如 96×96);
- Student 看所有 crop,Teacher 只看部分 global crop。
除此以外,DINOv2 还引入了一个 高分辨率收尾阶段:
- 大部分训练在标准分辨率(如 224×224)上进行;
- 在训练的最后一小段 iteration(比如总 625k 中最后 10k),提升到高分辨率(如 518×518);
- 主要目的是提升 像素级任务(分割 / 深度) 的表现,而避免从头就用高分辨率带来的巨大算力消耗。
4.2 高效 Attention 与序列打包
为了解决 ViT 在大分辨率下 attention 太吃显存 / 时间的问题,DINOv2 使用了:
- FlashAttention:更高效的 attention kernel,实现 O(N²) 时间、O(N) 近似显存;
- Sequence Packing:把不同分辨率的 patch 序列打包成一个长序列,在同一 batch 中处理;
- Efficient Stochastic Depth:对被 drop 的 residual branch 直接跳过计算,节省算力。
这些改动本身不改变算法,只是 engineering 层面把训练速度提升到了一个可接受的范围。
4.3 大模型并行:FSDP + 混合精度
DINOv2 的最大模型 ViT-g/14 有接近 10 亿参数,如果用常规 Data Parallel 很难塞进显存。论文采用:
-
FSDP(Fully-Sharded Data Parallel):
- 参数、梯度和优化器状态在多卡之间切分;
- 训练时动态加载需要的 shard。
-
混合精度训练(FP16 / BF16):
- 降低显存占用;
- 在不牺牲太多精度的情况下加速训练。
搭配前面的高效 attention 和序列打包,使得在若干台大卡机器上训练 ViT-g / ViT-L 变得可行。
4.4 Teacher 冻结蒸馏:从 ViT-g 到 ViT-S/B/L
一个有趣的设计是:
- 先用完整的 SSL 框架训练一个 最大号 ViT-g/14;
- 然后把它当作 Frozen Teacher ,对小模型(ViT-S/B/L)再做一轮蒸馏:
- Teacher 不再更新,只负责给出目标分布;
- Student 用和自监督类似的损失去拟合 Teacher。
这样可以:
- 让小模型「继承」大模型的表现;
- 比直接从头训小模型效果更好、收敛更稳。
5. 实验结果与「Emerging Properties」
5.1 图像级任务:线性评估 & 下游分类
在 ImageNet-1K 线性评估上:
- DINOv2 的 ViT-B/L/g 在不微调 backbone 的前提下,线性分类可以达到 80%+ 甚至更高 的 top-1;
- 在 ImageNet-ReaL / ImageNet-V2 等分布偏移数据集上,性能优于多数自监督与弱监督模型;
- 在 iNaturalist、Places 这类细粒度 / 场景分类任务上,也能保持领先。
这说明:DINOv2 提取的特征确实比较「通用」,而不是只对 ImageNet 这种单一分布 overfit。
5.2 检索 / 匹配任务:Instance Retrieval & Dense Matching
在 Oxford / Paris 等经典 instance retrieval benchmark 上:
- 直接用 DINOv2 的 patch / global 特征做检索,就能打平或超越大量专门为检索设计的模型;
- Dense matching(图像间像素级匹配)上,DINOv2 提取的 patch 特征可以很自然地对应到物体部位,跨视角对齐能力很强。
这些性质对于你做:
- ReID(行人 / 车辆 / 室内人脸-人体多模态匹配);
- 多视角几何 / SfM / SLAM;
- 跨模态图像匹配;
都非常有参考价值。
5.3 像素级任务:分割 & 深度估计
在 ADE20K、Cityscapes 等语义分割,NYU / KITTI 等深度估计数据集上,论文展示了:
- 冻住 DINOv2 backbone,只在上面接一个线性 / 简单解码头;
- 即可达到接近或优于专门模型的性能;
- 特别是深度估计任务,受益于 patch-level 预测和高分辨率收尾策略,结果非常亮眼。
对于工程上想做 单目深度 + 语义分割 的场景,可以直接把 DINOv2 当作 encoder。
5.4 Emerging Properties:语义显式化
类似 DINOv1,DINOv2 的 patch 特征也存在非常漂亮的「Emerging Properties」:
- 对一段视频或多张图片,做 patch 特征的 PCA,可视化成伪色:
- 同一物体的不同部件会显现出稳定的颜色区域;
- 不同帧里,头 / 躯干 / 四肢等部位会被持续关注;
- 不同物种 / 不同风格(真实照片 / 卡通 / 雕塑)的图片中,对应的物体部位在特征空间里可以对齐。
这进一步证明了:DINOv2 不只是「搞定分类」,而是真正在学习「视觉世界的结构」。
6. 工程实践:如何在项目中使用 DINOv2?
下面这一节更偏「工程落地」视角,结合你的日常工作场景(ReID、检索、特征抽取等),讲讲怎么用。
6.1 用 PyTorch Hub 加载 DINOv2 backbone
最简单的方式是使用官方 PyTorch Hub:
python
import torch
# 加载 DINOv2 backbone(ViT-B/14 为例)
model = torch.hub.load('facebookresearch/dinov2', 'dinov2_vitb14', pretrained=True)
model.eval()通常这个 model 会输出一个 全局特征向量(比如 CLS / register token 经过投影之后)。
如果你想获取中间 patch 特征,可以:
- 查看官方仓库中
dinov2/models的源码,找到 forward 的返回结构; - 或者自己包装一个小模块,从中间层把 patch token 抠出来。
6.2 特征抽取 + L2Norm + 简单 Head
典型的下游使用方式:
python
import torch
from torchvision import transforms
from PIL import Image
# 预处理,与 DINOv2 预训练时保持一致
transform = transforms.Compose([
transforms.Resize(256, interpolation=transforms.InterpolationMode.BICUBIC),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225],
),
])
def extract_feat(model, img_path, device='cuda'):
img = Image.open(img_path).convert('RGB')
x = transform(img).unsqueeze(0).to(device)
with torch.no_grad():
feat = model(x) # (1, C)
feat = torch.nn.functional.normalize(feat, dim=-1) # L2Norm
return feat.squeeze(0).cpu()对于 ReID / 检索 / 相似图搜索:
- 用上面的函数抽取所有图库图片的特征;
- 存成矩阵,离线做 L2Norm;
- 在线查询时抽取 query 特征,做余弦/欧氏距离检索即可。
6.3 冻住 DINOv2 + 训练一个轻量分类头
对于分类 / 属性识别 / 行为识别等任务:
- 冻住 DINOv2 backbone:
python
for p in model.parameters():
p.requires_grad = False- 在 DINOv2 输出之上接一个两层 MLP 或单层线性:
python
import torch.nn as nn
class DinoLinearHead(nn.Module):
def __init__(self, in_dim, num_classes):
super().__init__()
self.fc = nn.Linear(in_dim, num_classes)
def forward(self, x):
return self.fc(x)- 只训练 head,即可在少量标注数据上获得不错的效果。
你也可以:
- 在 ReID 任务中,把 DINOv2 当 backbone + embedding head(ArcFace / CircleLoss);
- 在室内多姿态 ReID 中,把 patch 特征 reshape 成 feature map,再做局部池化 / 注意力(和你现在的局部注意力思路可以直接结合)。
6.4 像素级任务:把 DINOv2 当 Encoder
如果要做分割 / 单目深度等:
- 把 DINOv2 视作 encoder,输出 patch token;
- reshape 成 H×W×C 的 feature map;
- 接一个简单的 U-Net / FPN 风格 decoder;
- 前期可以完全冻住 encoder,只训 decoder,观察上限;
- 如果有足够标注,再对前几层 encoder 做少量微调。
实务上,对你目前在做的「室内摄像头人物检测 / ReID / 姿态相关任务」,DINOv2 适合用在:
- 初始化一个更强的 backbone;
- 对小数据集上的多任务头进行微调;
- 甚至直接把开源 DINOv2 作为特征提取器 + 自家小模型做轻量 distillation 到端侧。
7. DINOv1 vs DINOv2:如何在项目里选型?
下面用一个简化对比来总结:
| 维度 | DINOv1 | DINOv2 |
|---|---|---|
| 核心思路 | Student--Teacher 自蒸馏,global 对齐 | DINOv1 + iBOT:global + patch 预测 |
| 主干结构 | CNN / ViT | ViT-S/B/L/g(支持 register) |
| 数据规模 | 以 ImageNet 为主(百万级) | LVD-142M(亿级,无标签、自动构建) |
| 训练目标 | 图像级 DINO loss | 图像级 DINO + patch 级 iBOT + 正则 |
| 工程优化 | 多 crop + EMA + centering | 再加 FlashAttention / FSDP / 高分辨率收尾等 |
| 强项 | ViT 上的自监督分割能力、简洁框架 | 泛化强、任务覆盖面广、真正意义上的视觉基础特征 |
| 适用场景 | 中小规模数据上自监督预训练 | 希望直接用现成 backbone 做各种任务 |
工程选型建议(个人向):
-
如果你自己要在 自家数据 上从头预训练一个 SSL 模型:
- 想要 框架简单、参数少,可以参考 DINOv1;
- 想要更强的 patch 表征和 dense task 支持,可以参考 DINOv2 的 iBOT 部分。
-
如果你更关心 下游任务效果 / 交付时间:
- 直接 把官方 DINOv2 当 backbone,搭个 head 上去用就行;
- 对于室内多姿态 ReID / 特殊人群检测 / 车辆重识别等任务,非常值得一试。
8. 小结与 DINOv3 预告
本文我们从三个层面把 DINOv2 拆开来看:
- 数据层:通过 LVD-142M 数据 pipeline,把「大而干净」的视觉预训练数据集自动构建出来;
- 算法层:把 DINOv1 的自蒸馏和 iBOT 的 masked patch prediction 结合起来,再加上 centering、KoLeo 正则等稳定训练;
- 工程层:借助 FlashAttention、FSDP、sequence packing 等一系列技巧,让 ViT-g/14 级别的大模型在亿级数据上训得动。
最终得到的 DINOv2:
- 在图像分类、检索、分割、深度估计等 30+ benchmark 上表现强势;
- 在 OOD 和细粒度、多域任务中鲁棒性很高;
- 对我们这种「想直接拿来当特征抽取器 / backbone 的工程场景」非常友好。
在下一篇 「DINO 系列(v1/v2/v3)之三:DINOv3 原理的详细介绍」 中,我们可以继续聊:
- DINOv3 如何在 DINOv2 基础上继续演进;
- ViT registers / 文本对齐(vision-language)等新特性;
- 以及和 SAM、CLIP 等大模型之间的生态关系。