最近在写 Next.js + Supabase 的一个练手项目,突然又接触到了 SQL(虽然 Supabase 是通过类似 ORM 来操作数据库的),突然感觉 SQL 语法又陌生了。
真是学了不用,等于白学。
之前写过一篇一个前端小白,学习 SQL 语句,现在回头看,自己都看懵了,真的尬住了。
算了,重新整理一遍吧,并通过一个实战案例来巩固基础。
邂逅
SQL: Structured Query Language,称为结构化查询语句,简称 SQL。
SQL 编写规范
- 关键词建议使用大写,比如
CREATE、TABLE(小写也可以,但大写更规范) - 语句末尾加分号
- 如果表名或字段名是 SQL 关键词,用反引号 ````` 包裹
- 表名用单数,字段名用蛇形命名(下划线分隔,如
user_id)
SQL 分类
| 分类 | 描述 | 常见命令/关键字 |
|---|---|---|
| DDL | 定义 或修改数据库结构(库、表、索引、视图等) | CREATE、DROP、ALTER、TRUNCATE、RENAME |
| DML | 对表中的记录进行增、删、改 | INSERT、UPDATE、DELETE、MERGE |
| DQL | 对表中的记录进行查询 | SELECT(以及配套子句 WHERE、GROUP BY、ORDER BY、JOIN 等) |
| DCL | 权限 与访问控制(授予、回收) | GRANT、REVOKE |
- DDL(Data Definition Language):数据定义语言,-----> 管"结构"
- DML(Data Manipulation Language):数据操作语言,-----> 管"改数据"
- DQL(Data Query Language):数据查询语言,-----> 管"查数据"
- DCL(Data Control Language):数据控制语言,-----> 管"权限"
为了阅读方便,下面的 SQL 语句都用小写,但实际开发中推荐关键词用大写
SQL 类型
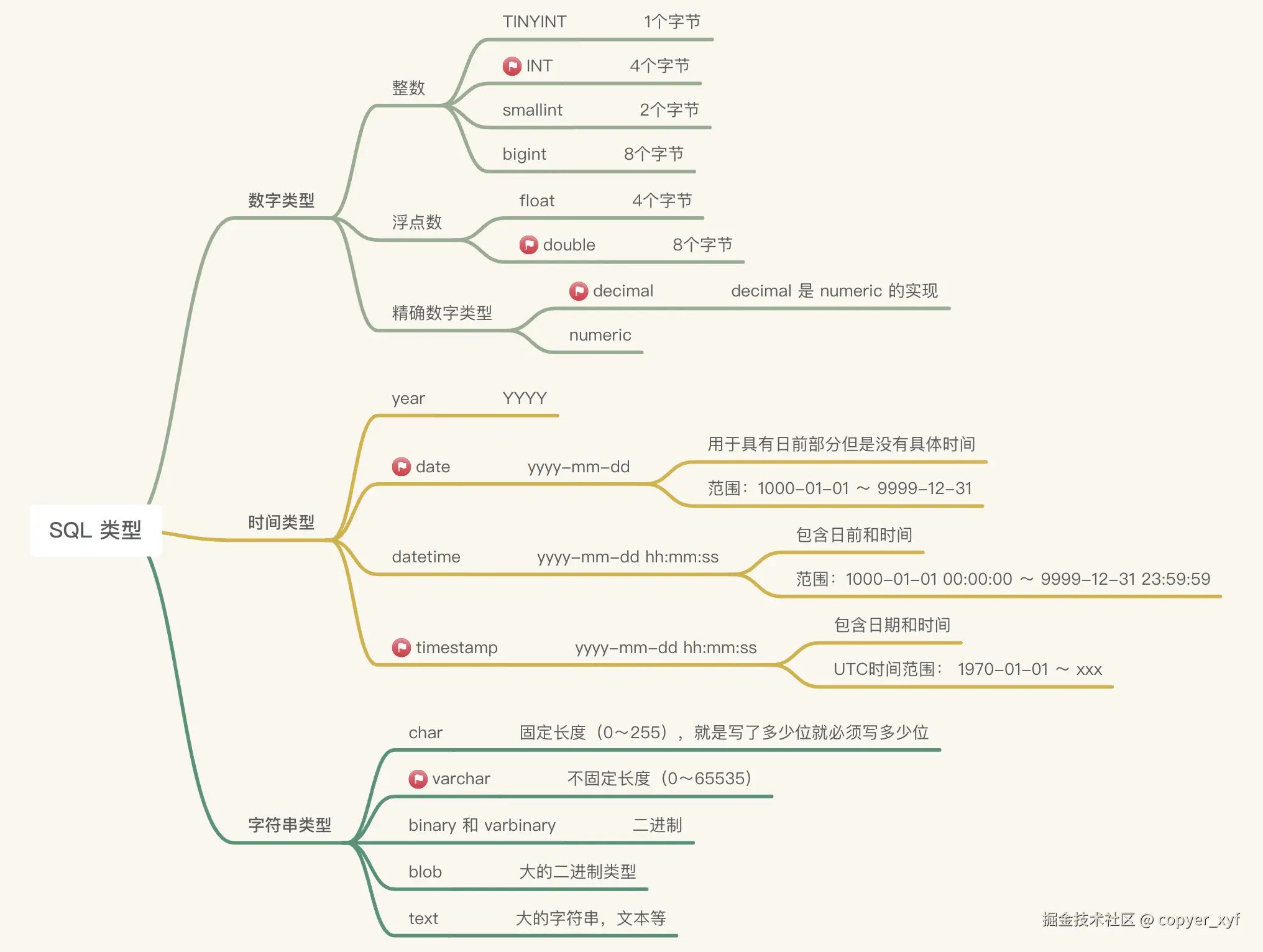
实际开发中常用的类型:
int:存储整数varchar(100): 存储变长字符串,可以指定长度char:定长字符串,不够的自动在末尾填充空格double:存储浮点数date:存储日期 2023-05-27time:存储时间 10:13datetime:存储日期和时间 2023-05-27 10:13timestamp:存储日期时间的,但是范围小一点,而且会转为中央时区 UTC 的时间来存储text:存储长文本
SQL 设计了这么多数据类型,一是为了存储更丰富的信息,二是为了节省存储空间。不常用的类型,用到时再查就行。
表约束
-
primary key: 主键- 主键是表中唯一的索引
- 必须是 not null; 如果没有设置,mysql 也会自动设置;
- 联合主键,多个字段合成的主键
- 尽量不要使用业务主键
-
unique: 唯一;除了主键以外,针对某些字段,也是唯一的。 -
not null: 字段不能为空 -
default: 默认值 -
auto_increment: 自动增长; -
foreign key: 外键,与其他表的字段关联
sql
create table if not exists yyy(
id int primary key,
`name` varchar(50) unique not null,
age int default 18,
num int auto_increment,
homeId int, -- 外键
foreign key (homeId) references home(id) -- 关联 home 表的 id
)DDL(管结构)
库操作
sql
-- 查看所有数据库
show databases;
-- 使用数据库 co_blog
use co_blog;
-- 查看选择的数据库
select database();
-- 创建数据库
create database if not exists co_blog; -- 先判断 co_blog 库是否存在,不存在则创建
create database co_blog; -- 若存在,会报错;
-- 删除数据库
drop database if exists co_blog;
drop database co_blog; -- 数据库不存在,会报错
use co_blog; -- 使用 co_blog 库,后续表操作都在这个库下表操作
sql
-- 查看库中所有的表
show tables;
-- 创建一张表
create table if not exists user(
id int primary key auto_increment,
name varchar(10),
age int
);
-- 查看表结构
desc user; -- 显示表的字段定义信息
-- 删除 user 表
drop table if exists user;
-- 修改 user 表
alter table user rename to users; -- 修改表名 user 变成 users
alter table user add height int; -- 添加 height 字段,为 int 类型;
alter table user change height newHeight int; -- height 改为 newHeight, 类型也可以重新定义
alter table user modify height bigint; -- 类型 int 变为 bigint
alter table user drop height; -- 删除 height 字段DML(管改数据)
增删改
插入数据
sql
-- 插入单条数据
insert into user(username, emails) values('admin', 'xxxx@xxxx.com');
-- 插入多条数据
insert into user(username, emails)
values
('admin', 'xxxx@xxxx.com'),
('admin2', 'xxxx@xxxx.com'),
('admin3', 'xxxx@xxxx.com');更新数据
sql
update `user` set name = '张三1', age = 19 where id = 1;删除数据
sql
delete from `user` where id = 1;DQL(管查询)
查询语句的执行顺序:先筛选数据,再分组过滤,然后排序,最后分页。
sql
SELECT *
FROM table_name
WHERE xxx
GROUP BY xxx
HAVING xxx
ORDER BY xxx
LIMIT xxx;取别名 as
sql
-- 查询所有字段
select * from user;
-- 查询指定字段并取别名
select name, age as c_age from user;
-- 别名的作用:多表查询时避免字段名冲突比较运算符
sql
-- 比较运算符:>、<、=、!=、>=、<=
select * from users where age > 20; -- 年龄大于 20
select * from users where age != 20; -- 年龄不等于 20逻辑运算符
sql
-- name 为 张三,且 age 大于 10
select * from users where name = '张三' and age > 10;
select * from users where name = '张三' && age > 10;
-- name 为 张三,或者 age 大于 10
select * from users where name = '张三' or age > 10;
select * from users where name = '张三' || age > 10;
-- age 在 10 到 20 岁间的
select * from users where age between 10 and 20;
select * from users where age >=10 && age <= 20;
-- age 为 10 或 20 的(in 的相反是 not in)
select * from users where age in (10, 20);
select * from users where age = 10 or age = 20;模糊搜索 like
%: 任意多个字符_: 任意一个字符
sql
select * from users where name like 't%'; -- 以 t 开头
select * from users where name like '%t%'; -- 包含 t
select * from users where name like '_t%'; -- 第二个字符是 t排序 order by
asc:升序(默认,可省略)desc:降序
sql
select * from users order by age asc; -- 年龄升序
select * from users order by age desc; -- 年龄降序限制分页 limit
- limit 数据条数 offset 偏移量 (推荐)
- limit 偏移量,数据条数 (不推荐)
sql
-- limit 数据条数 offset 偏移量 (推荐)
select * from users limit 30 offset 10;
-- limit 偏移量,数据条数 (不推荐)
select * from users limit 10, 30;
-- 前端格式
const pages = {
current: 3,
pageSize: 10,
};
-- 后端查询
const offsetNum = (pages.current - 1) * pages.pageSize;
const limitNum = pages.pageSize;
-- sql
const sql = `select * from users limit ${limitNum} offset ${offsetNum}`;聚合函数
聚合函数: 先收集到一起,然后对收集的结果进行操作。(看成一组)
avg:平均值max:最大值min:最小值sum:求和count:计数(统计行数)
sql
-- 平均值
select avg(age) as avg_age from users;
-- 计算人数
select count(*) as count from users;
-- 最大值
select max(age) as maxAge from users;
-- 求和
select sum(age) as sumAge from users;SQL 还有很多内置函数:
- 聚合函数:avg、count、sum、min、max
- 字符串函数:concat、substr、length、upper、lower
- 数值函数:round、ceil、floor、abs、mod
- 日期函数:year、month、day、date、time
- 条件函数:if、case
- 系统函数:version、database、user
- 类型转换函数:convert、cast、date_format、str_to_date
- 其他函数:nullif、coalesce、greatest、least
实际开发中,聚合函数最常用的是统计 和分组,其他函数用到时再查就行。
分组 group by
聚合函数看成一组;有时需要进行分组,然后进行操作。
使用建议:group by 一定要配合聚合函数使用,不然分组没有意义(除非整张表都看成一个聚合函数,就不需要使用 group by)。
sql
-- 统计男女个数
select sex, count(*) as num from users group by sex;分组筛选条件 having
在进行分组的时候,有时也需要过滤条件。
但是 group by 与 where 不能一起使用,语法报错。取而代之的是 having。
sql
-- 根据 sex 性别进行分组,然后筛选出 count 大于 2
select count(*) as count, sex from users group by sex having count > 2;去重 distinct
sql
select distinct age from users;多表
外键添加
创建表时添加外键:
sql
create table if not exists users(
id int primary key,
name varchar(255) not null,
role_id varchar(255) not null,
foreign key (role_id) references role(id)
);已有表添加外键:
sql
alter table users add role_id int;
alter table users add foreign key (role_id) references role(id);外键删除(更新)
表之间有关联后,不能直接删除或更新,否则会影响关联表。需要设置级联操作:要么一起更新,要么一起删除。
sql
-- 一起更新一起删除
alter table user add foreign key (role_id) references role(id) ON DELETE CASCADE ON UPDATE CASCADE;删除外键
sql
show create table users; -- 查看外键名称
alter table users drop foreign key users_ibfk_1;如果存在多个外键:
- users_ibfk_1
- users_ibfk_2
- ...
重新绑定外键
sql
alter table users add foreign key (role_id) references role(id)
on delete cascade
on update cascade;多表查询
多表查询时,表之间必须有联系(通常是外键)。
csharp
select * from users, team;这样查询会产生大量无用数据,因为这是笛卡尔积(每行数据都会组合)。
表连接
- 左连接(
left join): 常用 - 右连接(
right join): 不常用 - 内连接(
[cross/inner] join): 常用 - 全连接(mysql 不支持全连接,需要 union): 不常用
左右指的是以哪张表为主,展示该表的所有数据。
sql
from 左表 [left/right] join 右表其实
left join和right join可以等价,换一下表的顺序就行
左连接
sql
-- 左连接 LEFT JOIN. ON 连接条件
select * from user left join role
on user.role_id = role.id;
-- 筛选出 role_id 不为 null 的(左连接以左表为主,如果右表没有匹配数据,右表字段为 null)
select * from user left join role
ON user.role_id = role.id
WHERE role_id IS NOT NULL;内连接
内连接只返回两表都匹配的数据,不以哪张表为主。
sql
select * from user join role on user.role_id = role.id;针对多对多的查询出现时,就是多次采用连接即可。
子查询
SQL 支持嵌套查询,也就是在查询中嵌套另一个查询(子查询)。
sql
-- 查询年龄最大的人
-- 方式一:分两步
select max(age) from user; -- 先查出最大年龄
select name, age from user where age = xxx; -- 再根据年龄查数据
-- 方式二:用子查询(推荐)
select name, age from user where age = (select max(age) from user);子查询还有个特有的语法 EXISTS、NOT EXISTS。
sql
-- 查询所有有角色的用户
select name from user where EXISTS (select * from role where role.id = user.role_id);
-- 查询所有没有角色的用户
select name from user where NOT EXISTS (select * from role where role.id = user.role_id);子查询可以在 select、insert、update、delete 中使用。
事务
修改多个关联表时,必须使用事务,保证要么全部成功,要么全部失败(回滚)。
sql
start transaction; -- 开启事务
insert into role(id, name) VALUES (4, '群众');
insert into user(name, age, sex) VALUES ('james', 18, 4);
-- 提交事务,执行之后就不能 rollback 了
commit;
-- 回滚事务
rollback;如果想回滚到某个中间点,可以使用 savepoint 设置保存点。
savepoint a1;:回滚到 a1 时,a1 之前的操作保留,a1 之后的操作被撤销。
sql
start transaction; -- 开启事务
savepoint a1; -- savepoint 这一刻前面的依旧活着,这一刻后面的都被抹除
insert into role(id, name) VALUES (4, '群众');
savepoint a2;
insert into user(name, age, sex) VALUES ('james', 18, 4);
savepoint a3;
rollback to a2; -- 回滚到 a2 的那一刻事务隔离级别(有四种级别,比较复杂,自己也有点懵,一般用默认的就行)
sql
select @@transaction_isolation; -- 查看隔离级别DCL(管权限)
权限管理在实际开发中较少用到,等遇到时再补充(其实自己也不知道)。
案例演示(Blog 的 CRUD)
用一个博客系统的增删改查来演示 SQL 的实际应用。
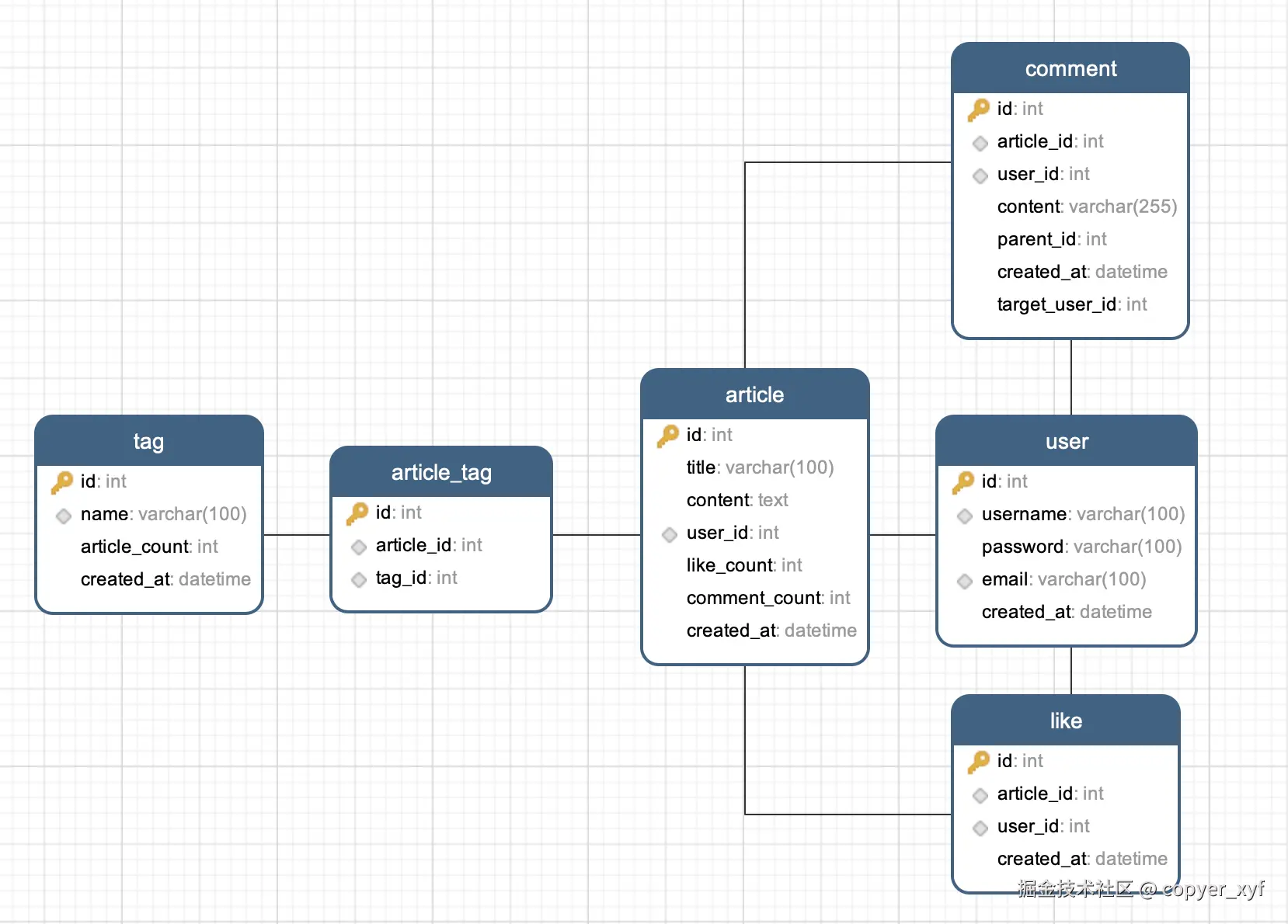
先设计表结构
sql
CREATE TABLE `user`(
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '主键',
username VARCHAR(100) UNIQUE NOT NULL COMMENT '用户名',
password VARCHAR(100) NOT NULL COMMENT '密码',
email VARCHAR(100) UNIQUE NOT NULL COMMENT '邮箱',
created_at DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间'
);
-- 标签表
CREATE TABLE `tag`(
id int NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '主键',
name varchar(100) UNIQUE NOT NULL COMMENT '标签名',
article_count int DEFAULT 0 COMMENT '文章数量',
created_at datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间'
);
-- 文章表
CREATE TABLE `article`(
id int NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '主键',
title varchar(100) NOT NULL COMMENT '标题',
content text NOT NULL COMMENT '内容',
user_id int NOT NULL COMMENT '作者id',
like_count int NOT NULL DEFAULT '0' COMMENT '点赞数',
comment_count int NOT NULL DEFAULT '0' COMMENT '评论数',
created_at datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
FOREIGN KEY (user_id) REFERENCES user(id) ON DELETE CASCADE ON UPDATE CASCADE
);
-- 文章标签表(中间表的级联方式要设置为 CASCADE,这个是固定的)
CREATE TABLE `article_tag`(
id int NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '主键',
article_id int NOT NULL COMMENT '文章id',
tag_id int NOT NULL COMMENT '标签id',
FOREIGN KEY (article_id) REFERENCES article(id) ON DELETE CASCADE ON UPDATE CASCADE,
FOREIGN KEY (tag_id) REFERENCES tag(id) ON DELETE CASCADE ON UPDATE CASCADE
);
-- 点赞表
CREATE TABLE `like`(
id int NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '主键',
article_id int NOT NULL COMMENT '文章id',
user_id int NOT NULL COMMENT '用户id',
created_at datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
FOREIGN KEY (article_id) REFERENCES article(id) ON DELETE CASCADE ON UPDATE CASCADE,
FOREIGN KEY (user_id) REFERENCES user(id) ON DELETE CASCADE ON UPDATE CASCADE
)
-- 评论表
CREATE TABLE `comment`(
id int NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '主键',
article_id int NOT NULL COMMENT '文章id',
user_id int NOT NULL COMMENT '用户id',
target_user_id int NOT NULL COMMENT '被回复人id',
content varchar(255) NOT NULL COMMENT '内容',
parent_id int DEFAULT 0 COMMENT '父级id',
created_at datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
FOREIGN KEY (article_id) REFERENCES article(id) ON DELETE CASCADE ON UPDATE CASCADE,
FOREIGN KEY (user_id) REFERENCES user(id) ON DELETE CASCADE ON UPDATE CASCADE
)ER 图为:
用户和标签的 CRUD
以用户表(user)为例,标签表(tag)同理
sql
-- 创建用户
insert into user(username, password, email) VALUES ('admin', '123456', 'admin@163.com');
-- 查询用户
select * from user;
-- 更新用户
update user set password = '123456' where id = 1;
-- 删除用户
delete from user where id = 1;文章的 CRUD
创建文章
sql
start transaction;
-- 创建文章,获取文章 id(代码中获取 id 后执行下一步)
insert into article(title, content, user_id, like_count, comment_count) VALUES ('标题', '内容', 1, 0, 0);
-- 遍历 tagIds,与文章 id 一起插入中间表(代码中遍历 tagIds,组装 SQL)
insert into article_tag(article_id, tag_id)
VALUES
('文章id', '标签id1'),
('文章id', '标签id2');
-- 更新 tag 表的文章数量
update tag set article_count = article_count + 1 where id in ('标签id1', '标签id2');
commit;删除文章
sql
delete from article where id = '文章id';
-- 因为采用的是 cascade,所以 article_tag 等会自动删除查询文章列表
sql
SELECT id,
title,
user_id,
like_count,
comment_count,
created_at
FROM article
ORDER BY created_at DESC
LIMIT 10 OFFSET 0;
-- 分页查询,按创建时间倒序
-- like_count 和 comment_count 采用计数器冗余方案,简单性能好,但可能数据不一致更新文章
sql
-- 1. 开启事务
START TRANSACTION;
-- 2. 更新文章表
UPDATE article
SET
title = '新标题',
content = '新内容'
WHERE id = 123 AND article.user_id = '用户id';
-- 3. 根据文章 id,在中间表 article_tag 中拿到旧标签(a,b), 然后根据用户传递的新标签(a,c), 找出删除的标签(b),然后再 tag 表中更新文章数量(-1)
UPDATE tag
SET article_count = article_count - 1
WHERE id IN (
SELECT tag_id
FROM article_tag
WHERE article_id = '文章id'
AND tag_id NOT IN ('新标签id1', '新标签id2') -- 新标签列表
);
-- 4. 查找旧标签,然后使用 in 和 not in 交集,找出新增的标签,然后在 tag 表中更新文章数量(+1)
UPDATE tag
SET article_count = article_count + 1
WHERE id IN ('新标签id1', '新标签id2')
AND id NOT IN (SELECT tag_id FROM article_tag WHERE article_id = '文章id');
-- 5. 更新中间表:先删除文章的所有标签,再插入新标签
DELETE FROM article_tag WHERE article_id = '文章id';
INSERT INTO article_tag(article_id, tag_id) VALUES
('文章id', '新标签id1'),
('文章id', '新标签id2');
COMMIT;点赞
无论是点赞还是取消点赞, 第一步是先判断是否已经点过赞
sql
SELECT * FROM `like` WHERE article_id = '文章id' AND user_id = '用户id' LIMIT 1;如果查询到记录,说明已点赞,执行取消点赞;否则执行点赞。
sql
-- 点赞
START TRANSACTION;
-- 1. 更新 like 表数据
INSERT INTO `like`(article_id, user_id) VALUES ('文章id', '用户id');
-- 2. 更新 article 表数据(+1)
UPDATE article SET like_count = like_count + 1 WHERE id = '文章id';
COMMIT;
-- 取消点赞
START TRANSACTION;
-- 1. 删除 like 表数据
DELETE FROM `like` WHERE article_id = '文章id' AND user_id = '用户id';
-- 2. 更新 article 表数据(-1)
UPDATE article SET like_count = like_count - 1 WHERE id = '文章id';
COMMIT;评论
写到这里发现,最初表设计有问题。本想用一个
parent_id实现无限层级,但看了掘金和 B 站的评论设计,发现评论最多 2 层,其他都是平铺回复。
B 站的评论:
掘金的评论:
都是两层模型:
- 第 1 层:顶级评论(
parent_id = NULL) - 第 2 层:对顶级评论的回复(
parent_id = 顶级.id) - 第 3 层及以后:不再嵌套,把目标人 @nick 写进内容,
parent_id仍等于顶级评论 id,按时间平铺
新增评论
sql
START TRANSACTION;
-- 情况一:顶级评论
INSERT INTO comment(article_id, user_id, parent_id, target_user_id, content)
VALUES ('文章id', '用户id', NULL, NULL, '一级评论');
-- 情况二:回复顶级评论或回复某人
INSERT INTO comment(article_id, user_id, parent_id, target_user_id, content)
VALUES ('文章id', '用户id', '顶级评论id', '被回复人id', '二级评论');
-- 3. 更新 article 表评论数(+1)
UPDATE article SET comment_count = comment_count + 1 WHERE id = '文章id';
COMMIT;删除评论
sql
-- 1. 查看是否有子评论
SELECT 1 FROM comment WHERE parent_id = '评论id' LIMIT 1;
-- 情况一:如果没有子评论
-- 情况一:没有子评论,直接删除
START TRANSACTION;
DELETE FROM comment WHERE id = '评论id' AND user_id = '用户id';
-- 2. 更新 article 表评论数(-1)
UPDATE article SET comment_count = comment_count - 1 WHERE id = '文章id';
COMMIT;
-- 情况二:有子评论,一起删除
START TRANSACTION;
-- 1. 获取所有子评论 id(二级评论的 parent_id 都是顶级评论 id)
select id as ids from comment where parent_id = '评论id';
-- 2. 代码中组装 ids:[...ids, '评论id'](包含所有子评论 id 和顶级评论 id)
-- 3. 根据 id 批量删除
delete from comment where id in ('ids');
-- 4. 更新 article 表评论数(减去 ids.length)
UPDATE article SET comment_count = comment_count - 'ids.length' WHERE id = '文章id';
COMMIT;这里使用代码 + SQL 语法的组合,纯粹用 SQL 实现需要使用存储过程,目前还不会
查询评论列表
这里查询主要还是看评论的交互流程是怎么样设计的。
- 情况一:直接查询所有评论(在代码中组装成一个二级树结构),缺点数据量不能太大
- 情况二:分页查询(先分页查询顶级的,展示时再不分页查询子评论),可能存在交互的迟钝感
- 情况三:xxxx(我也不知道了,总感觉上面的两种方案都不是最佳的, 我看了掘金返回的结构是顶级评论分页(20 条)+ 子评论随着顶级评论一起返回,万一子评论的量也很多呢?)
sql
-- 情况一:查询所有评论
-- 1. 获取所有顶级评论的 ids
SELECT id from comment where article_id = '文章id' AND parent_id IS NULL;
-- 2. 获取所有评论
SELECT c.id,
c.parent_id,
c.user_id,
u.name AS user_name,
c.target_user_id,
tu.name AS target_user_name,
c.content,
c.created_at
FROM comment c
LEFT JOIN user u ON u.id = c.user_id -- 连接用户表,查询用户名称
LEFT JOIN user tu ON tu.id = c.target_user_id -- 连接用户表,查询用户名称
WHERE c.article_id = '文章id'
AND (c.parent_id IS NULL -- 找出顶级评论(parent_id = NULL)和子评论(parent_id 在 ids 里面)
OR
c.parent_id IN ('ids'))
ORDER BY c.parent_id IS NULL DESC,
c.created_at ASC;通过代码进行组装成树
js
// 针对情况一:拿到所有数据之后,在代码中组装成一个树结构
function buildTree(list) {
const topMap = new Map(); // 顶级评论容器
const replyMap = new Map(); // 二级评论容器
list.forEach((item) => {
if (item.parent_id === null) {
item.replies = []; // 创建一个空数组,用来存放子评论
topMap.set(item.id, item);
} else {
const arr = replyMap.get(item.parent_id) || [];
arr.push(item);
replyMap.set(item.parent_id, arr);
}
});
topMap.forEach((top) => {
// 添加子评论
top.replies = replyMap.get(top.id) || [];
});
const tree = Array.from(topMap.values()).sort(
(a, b) => new Date(b.created_at) - new Date(a.created_at)
);
return tree;
}
sql
-- 情况二: 先分页查询顶级的,展示时再不分页查询子评论
-- 1. 分页获取顶层评论
SELECT c.id,
c.parent_id,
c.user_id,
u.name AS user_name,
c.target_user_id,
tu.name AS target_user_name,
c.content,
c.created_at
FROM comment c
LEFT JOIN user u ON u.id = c.user_id
LEFT JOIN user tu ON tu.id = c.target_user_id
WHERE c.article_id = '文章id' AND c.parent_id IS NULL
ORDER BY c.created_at DESC
LIMIT 20 OFFSET '页码 * 20';
-- 2. 获取所有子评论
SELECT c.id,
c.parent_id,
c.user_id,
u.name AS user_name,
c.target_user_id,
tu.name AS target_user_name,
c.content,
c.created_at
FROM comment c
LEFT JOIN user u ON u.id = c.user_id
LEFT JOIN user tu ON tu.id = c.target_user_id
WHERE c.article_id = '文章id' AND c.parent_id = '顶层评论id'
ORDER BY c.created_at ASC;其他的情况,就先不考虑了。
最后
SQL 这东西,多写几遍就熟了。语法虽然多,但常用的就那些,上面这些算是入门。
前端平时接触不到,但想往全栈发展,SQL 是必须了解的。虽然实际开发用 ORM,但底层还是 SQL(就像用 Vue,JavaScript 还是要懂的)。