前言
Linux 系统中运行 C 程序是每一位开发者的基本功,而 openEuler 作为一款由华为主导、社区驱动的开源操作系统,不仅兼容主流的 Linux 生态,还为开发者提供了高性能、安全性与可扩展性兼备的运行环境。
本文将以 openEuler 25.09 为基础系统,详细演示从查看系统信息、安装 GCC 编译器,到编写、编译和运行 C 程序的全过程。通过本次实战,你将熟悉 openEuler 的命令行操作方式,并掌握如何在该系统上完成一个 C 程序的生命周期管理。
openEuler 介绍
openEuler 华为主导、社区共同建设的开源操作系统,打造一个面向多样性计算架构的统一平台,基于 Linux 内核深度优化,兼容 x86、ARM、RISC-V 等多种硬件,具备高性能、高安全性和强扩展能力,广泛应用于云计算、AI、边缘计算等领域,openEuler 不仅拥有完善的软件生态和活跃的开发者社区,还通过持续创新与协同共建,成为操作系统的重要代表,助力构建开放、可靠、智能的数字基础底座。
高性能与多架构支持:openEuler 深度优化 Linux 内核,支持 x86、ARM、RISC-V 等多种硬件架构,具备卓越的系统调度与资源管理能力,在云计算、AI 推理及高并发场景下表现出色
高安全与高可靠性:系统内置多层安全防护机制,支持安全启动、访问控制与系统完整性验证,已通过多项国家级安全认证,可广泛应用于金融、电信、能源等关键行业
开放生态与智能化创新: openEuler 拥有活跃的全球开源社区,融合容器、虚拟化、AI 调优等创新技术,配套丰富的开发工具与软件仓库,为开发者提供灵活、高效、可持续的操作系统生态
环境准备与系统确认
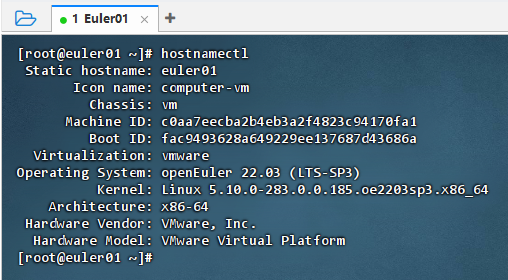
1、进行 C 程序开发之前,首先需要确认系统环境是否配置正确
plain
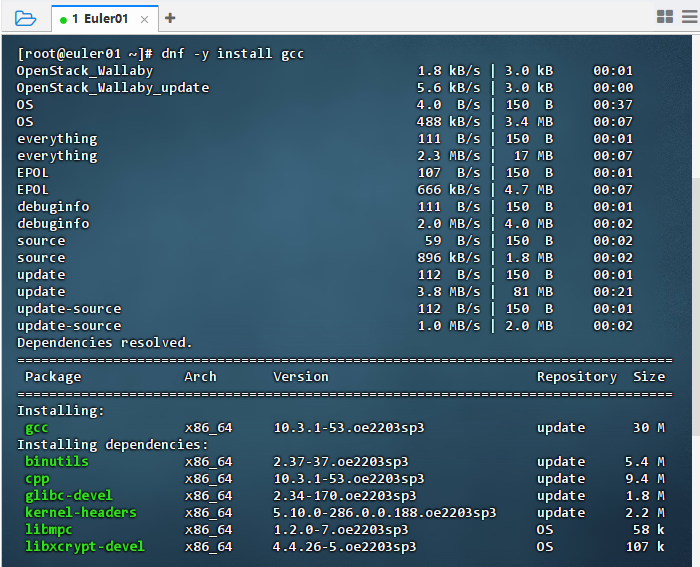
hostnamectl2、安装 GCC 编译器(该命令会自动下载并安装 GNU 编译器集合(GCC),包括编译器核心文件与相关依赖包。安装过程中,dnf 将显示依赖关系解析与安装进度)
plain
sudo dnf -y install gcc3、安装完成后,使用以下命令验证安装是否成功
plain
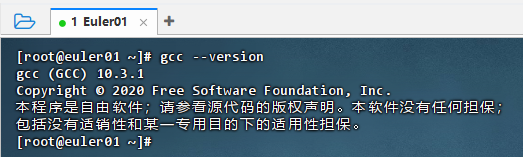
gcc --version4、验证编译环境与依赖库(在安装完 GCC 后,可通过编译一个简单的测试程序来验证环境是否正常工作)
plain
echo 'int main(){return 0;}' > test.c
gcc test.c -o test
./test && echo "✅ C 编译环境正常"5、安装 Vim / nano 编辑器(为方便编写 C 程序代码,可以安装一个文本编辑器,openEuler 默认带有 vi,但推荐安装更强大的 vim)
plain
sudo dnf -y install vimC 程序实战任务
- 执行命令:hostnamectl,查看主机信息
1、当编译器安装完毕后,我们就可以编写第一个 C 语言程序,C 语言的源文件后缀通常为 .c,我们以最经典的 "Hello World" 程序为例
plain
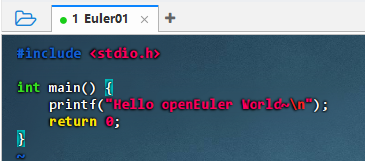
vim hello.c2、入编辑器后,按下 i 进入插入模式,然后输入以下内容
plain
#include <stdio.h>
int main() {
printf("Hello, openEuler World~\n");
return 0;
}安装GCC
执行命令:dnf -y install gcc
执行命令:gcc --version,验证是否安装成功,显示gcc版本号:10.3.1
编写C程序
- 执行命令:vim hello.c
编译C程序
- 执行命令:gcc hello.c -o hello,生成可执行文件hello
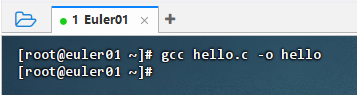
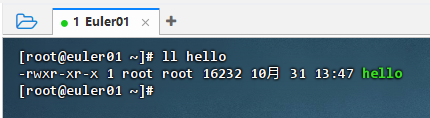
执行命令:ll hello,查看可执行文件hello信息
运行C程序
- 执行命令:./hello
openEuler Hadoop 集群部署基准测试
FT2000+ arm64 架构服务器与 openEuler 操作系统的适配场景,核心围绕 Hadoop 单机伪集群的部署实施与基准性能测试展开。通过梳理适配性部署流程、明确关键配置要点,结合标准基准测试方案,验证 Hadoop 在该软硬件环境下的运行稳定性与核心性能表现,为 arm64 架构下大数据平台的轻量化部署与性能评估提供实操参考
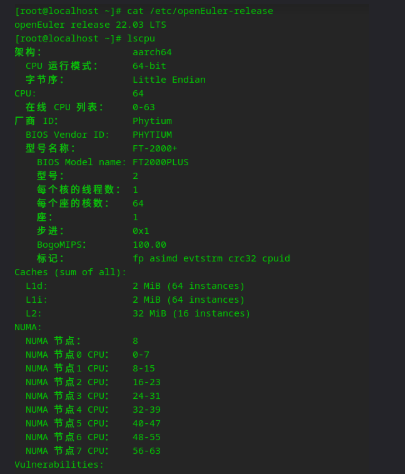
lscpu输出对应的是一台服务器:采用 ARM aarch64 架构,搭载飞腾 FT-2000+/64 64 核单线程处理器,分 8 个 NUMA 节点优化内存访问,配备 L1(每核 32KB)、L2 缓存,是典型 64 核服务器配置
前置条件
- 服务器已安装 Java 1.8(需确保 JAVA_HOME 路径正确)
- 已安装多线程下载工具 axel(未安装可执行 yum install axel -y 或 apt install axel -y)
- 拥有 root 权限(用于创建用户)
创建 Hadoop 用户并切换
plain
# 创建 hadoop 用户(root 权限执行)
useradd hadoop
# (可选)设置 hadoop 用户密码(避免后续操作权限问题)
passwd hadoop
# 切换到 hadoop 用户
su - hadoop
# 进入 hadoop 用户主目录
cd ~下载 Hadoop 镜像
plain
# 800 线程下载 aarch64 架构 Hadoop 3.3.1 镜像(北外镜像源,速度稳定)
axel -n 800 https://mirrors.bfsu.edu.cn/apache/hadoop/core/hadoop-3.3.1/hadoop-3.3.1-aarch64.tar.gz解压 Hadoop 安装包
plain
# 解压下载的压缩包
tar -xvf hadoop-3.3.1-aarch64.tar.gz
# 进入 Hadoop 安装目录
cd hadoop-3.3.1单机伪集群核心配置
plain
# 编辑核心配置文件
vim etc/hadoop/core-site.xml将以下内容替换文件原有配置(指定 HDFS 主节点地址)
plain
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value> <!-- HDFS 访问地址:本地9000端口 -->
</property>
<!-- (可选)配置 Hadoop 临时目录(避免默认/tmp被清理) -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-tmp</value>
</property>
</configuration>配置 hdfs-site.xml
plain
# 编辑 HDFS 配置文件
vim etc/hadoop/hdfs-site.xml将以下内容替换文件原有配置(指定副本数、数据存储路径)
plain
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value> <!-- 伪集群模式,副本数设为1(默认3) -->
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/namenode</value> <!-- NameNode 元数据存储路径 -->
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/datanode</value> <!-- DataNode 数据存储路径 -->
</property>
<!-- (可选)关闭 HDFS 权限检查(方便单机测试) -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>创建数据存储目录
plain
# 按配置文件路径创建目录(否则格式化/启动会失败)
mkdir -p /home/hadoop/namenode
mkdir -p /home/hadoop/datanode
mkdir -p /home/hadoop/hadoop-tmp # 对应 core-site.xml 中的临时目录配置 Java 环境变量
plain
# 声明 JAVA_HOME(需根据服务器实际 Java 路径修改!)
# 验证 Java 路径:执行 echo $JAVA_HOME 或 find /usr/lib/jvm -name "java-1.8.0*"
export JAVA_HOME=/usr/lib/jvm/java-1.8.0
# (可选)将 Java 环境变量写入 Hadoop 配置文件(永久生效)
echo "export JAVA_HOME=$JAVA_HOME" >> etc/hadoop/hadoop-env.sh格式化 NameNode
plain
# 格式化 HDFS namenode(仅需执行一次,重复执行会导致数据丢失)
./bin/hdfs namenode -format验证格式化结果
- 执行成功后,终端会显示 successfully formatted 关键字
- 查看 /home/hadoop/namenode 目录,会生成 current 文件夹及元数据文件
配置 SSH 免密登录
plain
# 生成 SSH 密钥对(一路回车,不设置密码)
ssh-keygen -t rsa -P ""
# 将公钥复制到本地(免密登录 localhost)
ssh-copy-id hadoop@localhost
# 验证免密登录(无需输入密码即可登录)
ssh localhost
exit # 退出登录,返回原终端启动 HDFS 服务
plain
# 启动 HDFS 相关进程(NameNode、DataNode、SecondaryNameNode)
./sbin/start-dfs.sh查看进程状态
plain
jps -lv
plain
netstat -lnetp | grep java
TestDFSIO 吞吐性能测试
plain
./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.1-tests.jar TestDFSIO -write -nrFiles 500 -size 100MB -bufferSize 8388608 -resFile /tmp/testDFSIOwrite.log
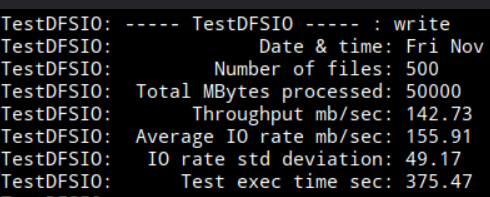
这是 Hadoop HDFS 的 TestDFSIO 写性能测试结果:本次测试完成了 500 个文件共 50GB 数据的写入,总吞吐量 142.73MB/s、单文件平均写速 155.91MB/s,耗时约 6.26 分钟,写速波动 49.17;作为单机伪集群的测试表现,该性能符合普通机械硬盘的持续写能力,速率波动则源于单机内多 HDFS 进程的资源共享,整体处于合理水平
openEuler 系统信息与版本查看命令
1、查看系统版本信息
plain
cat /etc/os-release2、查看内核版本
plain
uname -r3、查看系统架构
plain
uname -m4、查看主机信息
plain
hostnamectl5、查看 CPU 信息
plain
lscpu6、查看内存使用情况
plain
free -h总结
操作系统 openEuler 25.09,完成了两项核心实操:一是基于 openEuler 搭建 C 语言开发环境,通过安装 GCC 编译器、编写 "Hello World" 程序并编译运行,验证了 openEuler 对传统 C 开发生态的良好兼容性;二是在飞腾 FT2000+/64 arm64 架构服务器的 openEuler 环境中,完成了 Hadoop 单机伪集群的部署,从用户创建、镜像下载、配置文件调整,到 SSH 免密配置、HDFS 服务启动,最终通过 TestDFSIO 测试验证了集群的写性能 50GB 数据写入吞吐量 142.73MB/s,证明软硬件组合能稳定支撑大数据组件的轻量化部署