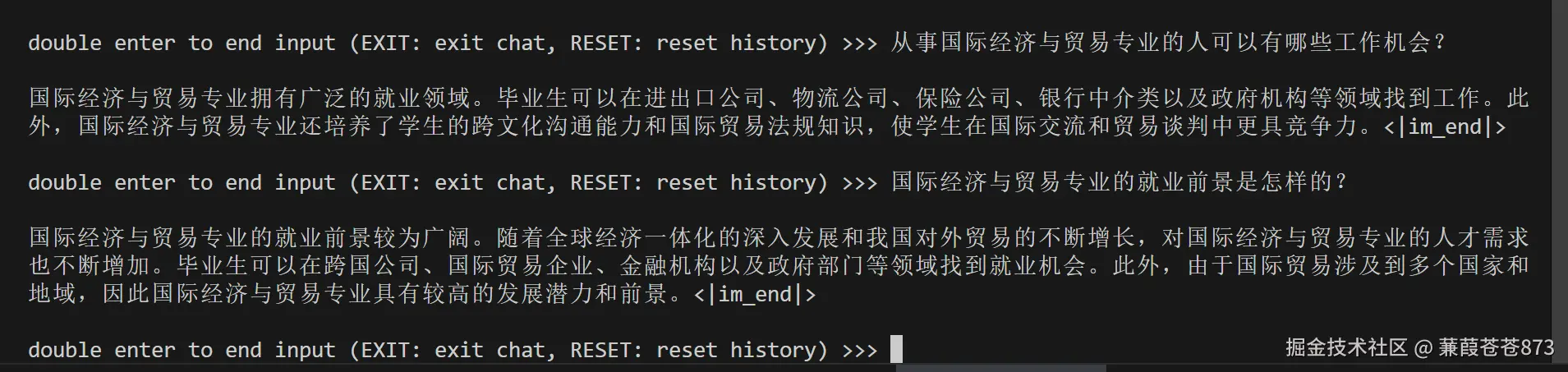
大模型分布式微调 & Xtuner
我们传统意义上把分布式微调叫做多卡训练,多卡训练干嘛用的呢?其实它是为了解决两个问题:
-
显存不足的问题;
-
计算资源不足的问题;
现阶段模型的规模在急速的增大,模型的参数量越大,模型能够解决的问题就越复杂,模型的表现就更好。那么这就导致一个问题,当模型的参数量过大的情况下,目前的单张显卡是没有办法存储这个模型的。
现阶段的显卡不可能有很大的显存,所以说我们如何把一个模型拆成多个部分,让它能够在多张显卡上面实现模型的训练和推理就显得非常有必要了。所以说这里面所谓的大模型的分布式处理,实际上换言之就是将我们的一个模型给它进行拆分和分解,然后实现用多张显卡去处理这个模型的各个部分。
当然分布式其实分为两个阶段,第一个阶段是模型微调时用到的分布式训练,另一个是模型部署时用到的分布式部署。我们今天先介绍模型微调时用到的分布式训练。
一、大模型分布式微调的基本概念
现阶段我们微调大模型的时候,不需要刻意操作大模型的分布式微调训练,因为现在的这个分布式微调训练是集成在我们所选用的这个微调框架里面的。比如说前面用过的 Llama Factory,如果部署 Llama Factory的硬件环境本身就有多张显卡,那么它会自动的检测并调用分布式训练。
1.1 为需要分布式训练
模型规模爆炸 :现代大模型(如GPT-3、LLaMA等)参数量达千亿级别,单卡GPU无法存储完整模型。
计算资源需求 :训练大模型需要海量计算(如GPT-3需数万GPU小时),分布式训练可加速训练过程。
内存瓶颈:单卡显存不足以容纳大模型参数、梯度及优化器状态。
在我们的分布式训练过程中,其实核心是为了解决两个问题。第一个问题就是在于单张显卡无法加载这个模型,那么我们一般就会采用这个分布式去做处理了;第二个问题就是分布式要解决模型的训练加速过程,把多张显卡同时同时参与训练,加速我模型的这个训练过程。
Deepseek模型比较大,官方当时给出来的结论:推理时使用8张A100的显卡。这要注意:训练时所需要的显存要比推理要大得多。
1.2 分布式训练的核心技术
前提条件:分布式训练所用的显卡型号必须相同。
1、数据并行(Data Parallelism)
-
原理:将数据划分为多个批次,分发到不同设备,每个设备拥有完整的模型副本。
-
同步方式:通过
All-Reduce操作同步梯度(如PyTorch的DistributedDataParallel)。 -
挑战:通信开销大,显存占用高(需存储完整模型参数和优化器状态)。
-
适用场景:单卡可跑整个模型,想提高训练速度的情况;
2、模型并行(Model Parallelism)---建议使用
-
原理:将模型切分到不同设备(如按层或张量分片)。
-
优点:每张显卡的算力、显存要求大幅度减少,节约算力
-
拆分类型:
-
横向并行(层拆分):将模型的层分配到不同设备。
-
纵向并行(张量拆分):如
Megatron-LM将矩阵乘法分片。
-
-
挑战:设备间通信频繁,负载均衡需精细设计(每次的计算需要同时开始同时结束)。
-
适合场景:每张显卡的算力/显存不高,训练超出单张卡上限的模型;
3、流水线并行(Pipeline Parallelism)
-
原理:将模型按层划分为多个阶段(
stage),数据分块后按流水线执行。(将模型和数据都拆开) -
优化:微批次(
Micro-batching)减少流水线气泡(Bubble)。 -
挑战:需平衡阶段划分,避免资源闲置。
4、混合并行(3D并行)
-
组合策略:结合数据并行、模型并行、流水线并行,典型应用:如训练千亿级模型的预训练。
-
案例:微软
Turing-NLG、Meta的LLaMA-2。
二、deepspeed框架介绍
2.1 框架概述
微软开源了一个分布式训练deepspeed框架,目前来讲,主流微调工具支持的分布式训练框架都是基于deepseed来实现的,这个框架的特点就是它支持千亿级参数模型的训练,基本上可以适配目前英伟达下面的主流显卡。
deepspeed 框架的核心目标是降低大模型训练成本,提升显存和计算效率。它其实基于 PyTorch 这个框架来构建的,支持Hugging Face 库。
2.2 核心技术
1、
ZeRO(Zero Redundancy Optimizer)优化器
原理: 通过分片优化器状态、梯度、参数,消除数据并行中的显存冗余。(如果训练的这个设备上有多张卡,那么优化器不会选择使用Adaw,而是使用ZeRO优化器从而更加节省显存)
阶段划分:
-
ZeRO-1: 优化器状态分片;它的本质原理是每张显卡上面放的是完整的模型,但是在进行优化更新的时候,它是只更新模型其中一部分的参数,剩余的这部分参数在当前显卡上相当于是冗余部分,这部分的参数是不参与计算的,这样一来就可以极大的提升我们模型在反向传播过程中性能问题。
现阶段在 llamaFactory 框架中 none 就是 ZeRO-1;
-
ZeRO-2:梯度分片 + 优化器状态分片;(推荐)梯度就是模型在反向传播过程中的参数
-
ZeRO-3:参数分片 + 梯度分片 + 优化器状态分片;- 优势:显存占用随设备数线性下降,支持训练更大模型。
ZeRO-1的处理方式是每张卡上面加载完整的模型,如果只有一张卡,那用和不用是没有区别的,必须体现在是多张卡上面。
ZeRO-2和ZeRO-3本质上是要把模型做切分,如果只有一张卡,相当于把模型切成多个部分后放到一张卡上,相较于之前的状态,所占的显存会变得更高,并且每个模块之间需要单独的通信,那么在更新的时候所花的时间会更长,所以在一张卡上配置ZeRO-2或ZeRO-3反而会减缓模型的训练过程。
ZeRO-1是最普通的并行运算,它的加速的效果是最差的;在多卡上面最节约显存的配置方法是ZeRO-3,但是ZeRO-3训练是最慢的,所以不推荐ZeRO-3;一般推荐使用ZeRO-2。
2、显存优化技术
梯度检查点(Activation Checkpointing):用时间换空间,减少激活值显存占用。
-
CPU Offloading:将优化器状态和梯度卸载到CPU内存,在进行优化过程中,临时把优化器的状态由GPU加载到内存中,这样极大的降低显存的占用,但是会减缓运算速度,因为训练时每个批次需要用到优化器的状态和梯度的时候,就得在下一个批次重新从内存再加载到GPU,内存和显存之间要通信是需要花时间的,除非万不得已用了ZeRO-3之后显存还不够,但是内存很大还想要勉强的去跑模型可以使用这种方式; -
混合精度训练:
FP16/BP16动态损失缩放(LossScaling),pytorch本身是支持混合精度训练的,而DeepSpeed是无缝兼容于pytorch,所以DeepSpeed本身也支持混合精度训练;
3、其他特性
-
大规模推理支持:模型并行推理(如
ZeRO-Inference) -
自适应通信优化:自动选择最佳通信策略(如
Al-Reducevs.All-Gather)
2.3 优势与特点
显存效率高: ZeRO-3 可将显存占用降低至1/设备数;
- 假设这台服务器上面有八张卡,如果我们用的是
DeepSpeed的ZeRO-3的优化模式,那么它每张卡上面的显存会降为原来的8分之1,不同的GPU架构上面,它的显存的节约力度不一样。
易用性强: 通过少量代码修改即可应用(如 DeepSpeed 配置 JSON 文件);
扩展性优秀: 支持千卡级集群训练;
开源社区支持: 持续更新,与 HuggingFace 等生态深度集成;
2.4 使用场景
训练百亿/千亿参数模型(如 GPT-3、Turing-NLG)
- 一般模型规格在
8B以上就需要分布式训练了;
资源受限环境:单机多卡训练时通过 Offloading
- 一般不推荐,速度很慢;
扩展模型规模快速实验:通过 ZeRO-2 加速中等规模模型训练
三、LLamaFactory多卡微调大模型
LLaMA-Factory 支持单机多卡和多机多卡分布式训练。同时也支持 DDP、DeepSpeed 和 FSDP 三种分布式引擎。本文只介绍deepseed引擎。
3.1 单机多卡情况
bash
$ pip install deepspeed
# 补充:导出虚拟环境包
$ pip list --format=freeze > requirement.txt
# 补充:导入虚拟环境包
$ pip install -r requirement.txt常见报错:
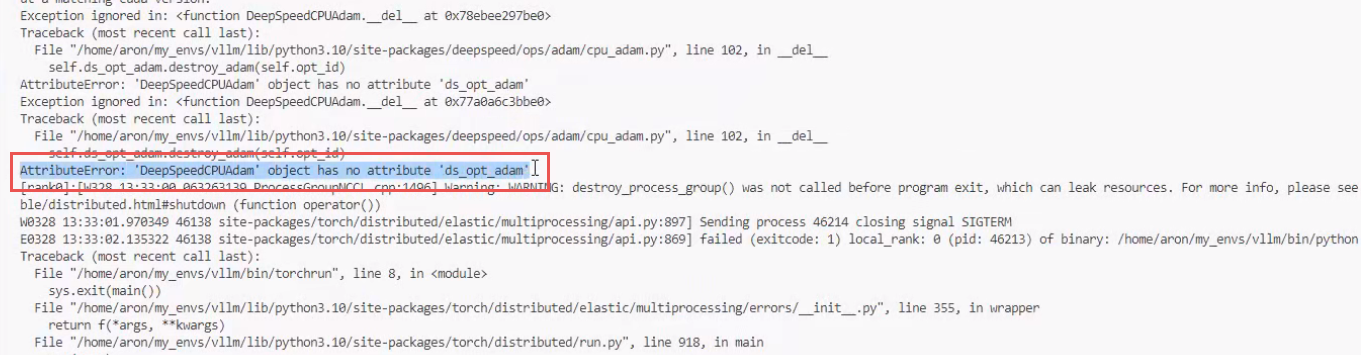
一般导致错误原因有两个点:
-
当前的
CPU内存和GPU显存之间不支持的deepspeed通信,deepspeed对通信是有要求的,通信太慢不允许操作; -
CUDA的版本和要求的版本不匹配;
llamaFactory 多卡配置:

-
LlamaFactory自动识别显卡数量,所以设备数量不需要修改; -
DeepSeed stage:ZerO优化器的阶段none就是不启用,等价于zero-1;- 2就是
zero-2; - 3就是
zero-3;
3.2 多机多卡情况
例如:
bash
$ FORCE_TORCHRUN=1 NNODES=2 NODE_RANK=0 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 \
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
$ FORCE_TORCHRUN=1 NNODES=2 NODE_RANK=1 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 \
llamafactory-cli train examples/train_lora/llama3_lora_sft.yamlMASTER_ADDR:主节点的地址MASTER_PORT:主节点的端口
公司里面基本很少会用多机多卡的训练。现在企业里一般一台服务器上面插八张卡完全够训练了,用不到服务器集群。
四、XTuner微调大模型
与
LamaFactory框架对比:XTuner不支持web界面,且更加节约显存。
4.1 创建xtuner环境
构建虚拟环境
bash
$ conda create -n xtuner python==3.10 -y
$ conda activate xtuner安装xtuner
bash
#### 1.使用pip安装 ####
# autodl算力云学术加速:source /etc/network_turbo
# 如果不再需要建议关闭学术加速,因为该加速可能对正常网络造成一定影响:unset http_proxy && unset https_proxy
$ pip install -U 'xtuner[deepspeed]'
#### 2.从源码安装(推荐) ####
$ git clone https://github.com/InternLM/xtuner.git
# 然后安装依赖的软件,这步需要的时间比较长。
$ cd xtuner
$ pip install -e '.[deepspeed]'等以上所有步骤完成后,验证xtuner:
bash
# 验证安装是否正确:
# 验证是否能打印配置文件列表
$ xtuner list-cfg4.2 下载模型
xtuner支持的微调模型在xtuner/configs下:
python
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-1.5B-Instruct',cache_dir="/root/lanyun-tmp/LLM/")4.3 数据集转换
XTuner支持使用自定义数据集进行指令微调,只需要将数据集转换成XTuner支持的格式即可。
大语言模型 Supervised Finetune(SFT)旨在通过有监督的微调来提高预训练模型在特定任务上的性能。为支持尽可能多的下游任务,XTuner 支持了增量预训练、单轮对话、多轮对话三种数据集格式。
- 增量预训练数据集用于提升模型在特定领域或任务的能力。
- 单轮对话和多轮对话数据集则经常用于指令微调(
instruction tuning)阶段,以提升模型回复特定指令的能力。
4.3.1 OpenAI 格式的数据
微调前需先准备数据集。XTuner 默认支持 OpenAI 格式的数据,只需将数据整理为 jsonl 格式即可使用:
json
[{
"messages": [
{ "role": "system", "content": "xxx."},
{ "role": "user", "content": "xxx." },
{ "role": "assistant", "content": "xxx."}
]
},
{
"messages": [
{ "role": "system", "content": "xxx." },
{ "role": "user", "content": "xxx." },
{ "role": "assistant", "content": "xxx.", "loss": False},
{ "role": "user", "content": "xxx." },
{ "role": "assistant", "content": "xxx.", "loss": True}
]
}]- 每条数据除了
OpenAI标准格式中的role字段和content字段外,XTuner还额外扩充了一个loss字段,用于控制某轮assistant的输出不计算loss。 system和user的loss默认为Falseassistant的loss默认为True
4.3.2 自定义数据集
为了统一增量预训练、单轮对话和多轮对话三种数据集格式,我们将数据集格式设置为以下形式:
json
[{
# 单轮对话
"conversation":[
{
"system": "xxx",
"input": "xxx",
"output": "xxx"
}
]
},
{
# 多轮对话
"conversation":[
{
"system": "xxx",
"input": "xxx",
"output": "xxx"
},
{
"input": "xxx",
"output": "xxx"
}
]
}]- 单轮对话转换代码如下:
python
import json
# 源数据文件路径
source_file = 'data/ruozhiba_qaswift.json'
# 目标数据文件路径
target_file = 'data/convert_ruozhiba.json'
# 读取源数据
with open(source_file, 'r', encoding='utf-8') as f:
source_data = json.load(f)
# 转换数据
target_data = []
for item in source_data:
conversation = {
"conversation": [
{
"input": item["query"],
"output": item["response"]
}
]
}
target_data.append(conversation)
# 保存转换后的数据
with open(target_file, 'w', encoding='utf-8') as f:
json.dump(target_data, f, ensure_ascii=False, indent=4)
print(f"数据已成功转换并保存到 {target_file}")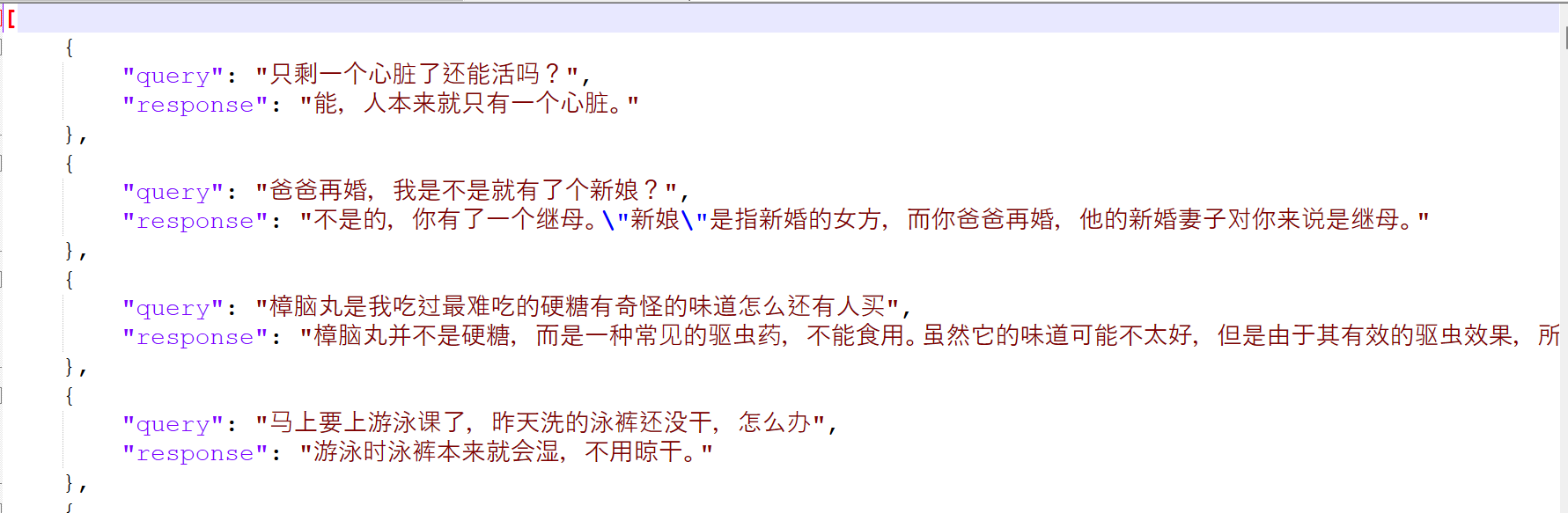
- 多轮对话转换代码如下:
python
import json
def convert_and_statistic(input_file):
with open(input_file, 'r', encoding='utf-8') as file:
data = json.load(file)
converted_data = []
entry_stats = {f"<=700": 0, "701-800": 0, "801-900": 0, "901-1000": 0, ">1000": 0}
max_length = 0
for entry in data:
conversation = []
# 处理history
if 'history' in entry and entry['history']:
for hist_entry in entry['history']:
hist_input, hist_output = hist_entry[0], hist_entry[1]
conversation.append({"input": hist_input, "output": hist_output})
update_entry_stats(hist_input, entry_stats)
update_entry_stats(hist_output, entry_stats)
max_length = max(max_length, len(hist_input), len(hist_output))
# 处理instruction和output
instruction = entry.get("instruction")
output = entry.get("output")
conversation.append({"input": instruction, "output": output})
if instruction is not None: # 确保instruction不是None
update_entry_stats(instruction, entry_stats)
if output is not None: # 确保output不是None
update_entry_stats(output, entry_stats)
max_length = max(max_length, len(instruction) if instruction is not None else 0, len(output) if output is not None else 0)
converted_data.append({"conversation": conversation})
# 计算总数据条目数
total_entries = sum(entry_stats.values())
# 计算各分段长度的数据条目占比
entry_stats_percentage = {key: (value / total_entries) * 100 for key, value in entry_stats.items() if total_entries != 0}
# 输出结果
return converted_data, entry_stats_percentage, max_length
def update_entry_stats(text, entry_stats):
if text is None:
return
length = len(text)
if length <= 700:
entry_stats["<=700"] += 1
elif 701 <= length <= 800:
entry_stats["701-800"] += 1
elif 801 <= length <= 900:
entry_stats["801-900"] += 1
elif 901 <= length <= 1000:
entry_stats["901-1000"] += 1
else:
entry_stats[">1000"] += 1
# 使用示例
converted_data, entry_stats_percentage, max_length = convert_and_statistic('data/fintech.json')
# 打印转换后的数据
print(json.dumps(converted_data, ensure_ascii=False, indent=4))
# 打印各分段长度的数据条目占比
print("\n各分段长度的数据条目占比:")
for key, value in entry_stats_percentage.items():
print(f"{key}: {value:.2f}%")
# 打印最大长度
print(f"\n最大长度: {max_length}")
# 如果需要将转换后的内容写入新的json文件,可以使用以下代码
with open('data/convert_fintech.json', 'w', encoding='utf-8') as new_file:
json.dump(converted_data, new_file, ensure_ascii=False, indent=4)这里做数据集合并是因为:xtuner并不会像llamaFactory一样他打乱数据集的方式是按文件打乱的,最好是把所有的数据集放进一个文件。
4.4 微调配置
创建微调训练相关的配置文件:复制xtuner微调脚本文件到 xtuner 根目录下,路径:xtruner ---> xtruner ---> configs ---> qwen ---> qwen1_5_0_5b_chat
-
qwen1_5_0_5b_chat_full_alpaca_e3.py:是全量预训练用的脚本 -
qwen1_5_0_5b_chat_qlora_alpaca_e3.py:是qlora微调用的脚本
打开这个文件,然后修改预训练模型地址,数据文件地址等。
bash
### PART 1 ###
# 预训练模型存放的位置
pretrained_model_name_or_path = '/root/lanyun-tmp/LLM/Qwen/Qwen2.5-1.5B-Instruct'
# 微调数据存放的位置
data_files = '/root/lanyun-tmp/xtuner/convert_merged.json'#基座模型路径
# 训练中最大的文本长度
max_length = 512
# 每一批训练样本的大小(根据显存大小设定)
batch_size = 2
# 最大训练轮数
max_epochs = 1000
# save
# 每500个step保存一次参数
save_steps = 500
# 只保留最后2次的参数
save_total_limit = 2
# Evaluate - 模型验证
# 500个step做一次验证
evaluation_freq = 500
# 主观验证:模型训练过程中会每隔evaluation_freq输入这些问题并输出,人为看微调效果
# 验证数据
evaluation_inputs = [
'只剩一个心脏了还能活吗?', '爸爸再婚,我是不是就有了个新娘?',
'樟脑丸是我吃过最难吃的硬糖有奇怪的味道怎么还有人买',
'马上要上游泳课了,昨天洗的泳裤还没干,怎么办',
'我只出生了一次,为什么每年都要庆生'
]
### PART 2 ###
# 量化微调需要修改load_in_4bit或者 load_in_8bit
model = dict(
type=SupervisedFinetune, # 指令微调,监督式微调模型
use_varlen_attn=use_varlen_attn, # 是否使用可变长度注意力
# QLara微调
llm=dict(
type=AutoModelForCausalLM.from_pretrained, # 加载因果语言模型
pretrained_model_name_or_path=pretrained_model_name_or_path,
trust_remote_code=True,
torch_dtype=torch.float16, # 使用半精度浮点数
quantization_config=dict( # 量化配置(QLoRA)
type=BitsAndBytesConfig,
load_in_4bit=False, # 4bit量化加载
load_in_8bit=True, # 8bit量化加载
llm_int8_threshold=6.0, # 8bit量化阈值
llm_int8_has_fp16_weight=False,
bnb_4bit_compute_dtype=torch.float16, # 计算时数据类型
bnb_4bit_use_double_quant=True, # 双重量化
bnb_4bit_quant_type="nf4", # 4bit量化类型
),
),
# Lora微调(与QLara微调二选一)
lora=dict( # LoRA配置
type=LoraConfig,
r=32, # LoRA秩
lora_alpha=64, # Alpha参数(缩放因子)
lora_dropout=0.1, # Dropout率
bias="none", # 偏置项处理方式
task_type="CAUSAL_LM", # 任务类型(因果语言模型)
),
)
### PART 3 ###
# path是json个格式的数据集
dataset=dict(type=load_dataset, path="json",data_files=data_files)
dataset_map_fn=None4.5 微调训练
4.5.1 单卡训练
bash
$ xtuner train /root/lanyun-tmp/xtuner/qwen2.5-1.5B-Instruct_qlora_alpaca_e3.py4.5.2 多卡训练
XTuner 内置了五种 DeepSpeed ZeRO 配置:
deepspeed_zero1deepspeed_zero2deepspeed_zero2_offloaddeepspeed_zero3deepspeed_zero3_offload
可一键启动 DeepSpeed 进行训练,通过 --deepspeed 来选择不同的 ZeRO 配置:
bash
# 以下命令根据需要任选其一
$ xtuner train xxx --deepspeed deepspeed_zero1
$ xtuner train xxx --deepspeed deepspeed_zero2
$ xtuner train xxx --deepspeed deepspeed_zero2_offload
$ xtuner train xxx --deepspeed deepspeed_zero3
$ xtuner train xxx --deepspeed deepspeed_zero3_offload例如:若想使用 DeepSpeed ZeRO2 显存优化算法微调 Qwen,可使用以下命令:
bash
# 单张显卡
xtuner train qwen2.5-1.5B-Instruct_qlora_alpaca_e3.py --deepspeed deepspeed_zero2
# 多张显卡
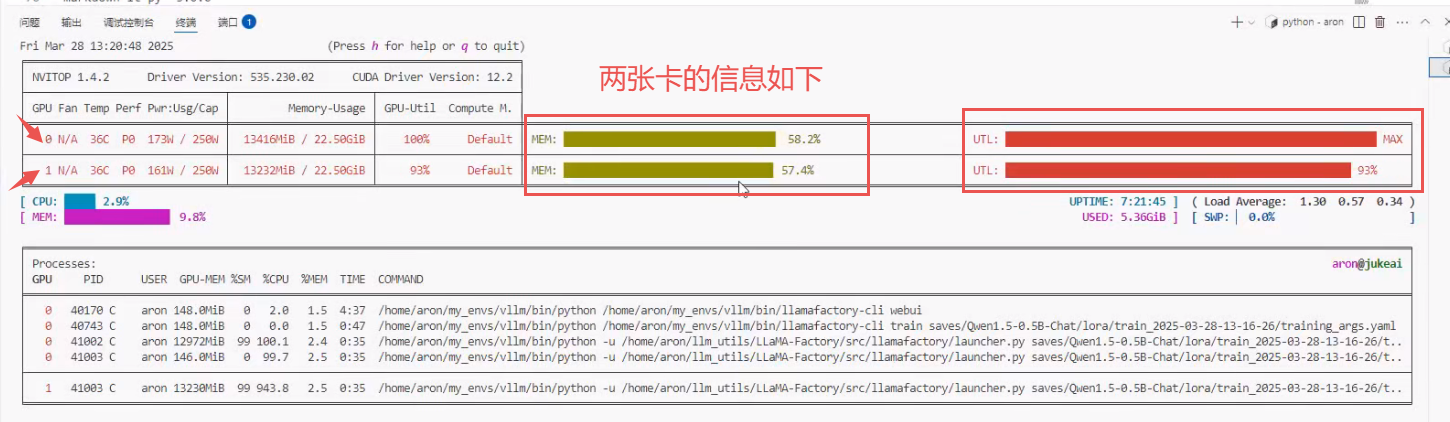
$ NPROC_PER_NODE=2 xtuner train qwen2.5-1.5B-Instruct_qlora_alpaca_e3.py --deepspeed deepspeed_zero2 --work-dir /root/xtuner/work_dirs/weightPYTORCH_CUDA_ALLOC_CONF 是 PyTorch 的内存管理环境变量,作用是通过允许显存段动态扩展来减少内存碎片,当显存碎片化严重时(即显存剩余总量足够,但因分配不连续导致大块显存请求失败)可以用下面命令。
bash
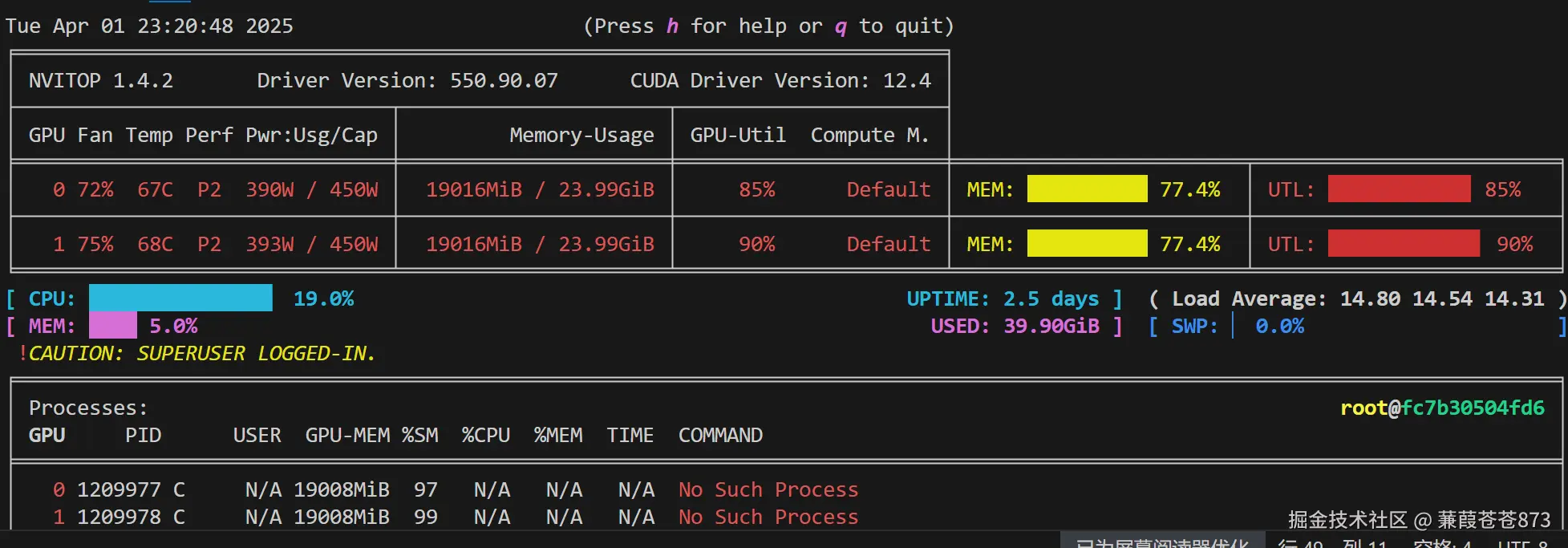
$ PYTORCH_CUDA_ALLOC_CONF=expandable_segments:Truenvitop命令查看如下:
4.6 模型转换
训练完成后会保留最近两个间隔步数的 PTH 模型(例如 iter_1000.pth、iter_1200.pth,如果使用了 DeepSpeed,则将会是一个文件夹),由后缀可知其是 pytorch 格式,我们需要利用 xtuner 将其转换成 HuggingFace 模型,以便后续推理框架部署(主流的格式是HuggingFace格式)
.pth 是 PyTorch 框架常用的模型保存格式,本质上是一个 序列化的 Python 字典(通过 torch.save() 保存)。
bash
# xtuner convert pth_to_hf 训练时的脚本{训练时的脚本} 训练时的脚本{pth文件的路径} ${要保存的路径}
# 例如
$ xtuner convert pth_to_hf qwen2.5-1.5B-Instruct_qlora_alpaca_e3.py ./iter_1200.pth ./iter_1200_4.7 模型合并
这个.pth文件只是训练出来的 lora模型的权重,不包含原模型的参数信息,所以要借助最开始训练的配置文件qwen2.5-1.5B-Instruct_qlora_alpaca_e3.py,因为这个配置文件里面就包含了 base模型的基础信息。如果期望获得合并后的模型权重(例如用于后续评测),那么可以利用 xtuner convert merge。
bash
# xtuner convert merge ${LLM} ${LLM_ADAPTER} ${SAVE_PATH}
# 举例
$ xtuner convert merge /root/LLM/Qwen/Qwen2.5-1.5B-Instruct /root/xtuner/work_dirs/weight/inerHf /root/xtuner/work_dirs/weight/merged转换后对话:
bash
$ xtuner chat /root/LLM/Qwen/Qwen2.5-1.5B-Instruct --adapter /root/xtuner/work_dirs/weight/inerHf --prompt-template qwen_chat