最近项目需要引入消息队列,实现异步任务处理和系统解耦。调研了几个主流方案后,选择了RabbitMQ------轻量、易用、部署简单。 部署环境选的是openEuler 22.03 LTS 。公司之前用CentOS,后来Red Hat政策调整,就切换到了openEuler。实际用下来体验不错,兼容RHEL生态,dnf/yum命令无缝切换,Docker、数据库这些中间件跑得都很稳。社区也活跃www.openEuler.org/,文档齐全docs.openEuler.org/,遇到问题基本都能找到解决方案。 系统版本openEuler 22.03 LTS ,主机名tech-server-01 ,Docker已经装好**(18.09.0)**。  这是一台全新环境的服务器,检查容器状态,没有任何历史残留。
这是一台全新环境的服务器,检查容器状态,没有任何历史残留。

干净的环境很重要,避免端口冲突。这也是我喜欢用容器的原因------部署、销毁都很快,不污染系统。
Docker部署RabbitMQ
RabbitMQ官方提供了多个Docker镜像版本,我选择 rabbitmq:3.12-management,这个版本:
- 包含管理插件(Web UI)
- 版本稳定(3.12是LTS版本)
- 镜像大小适中(247MB)
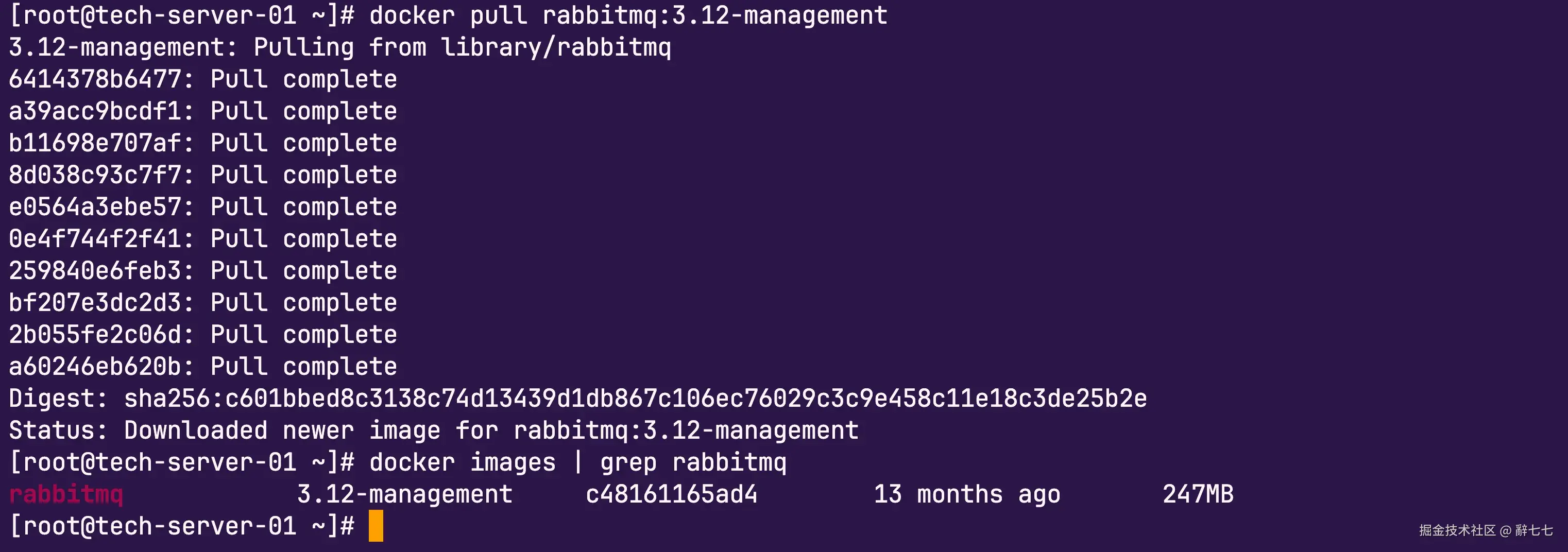
执行命令:
c
docker pull rabbitmq:3.12-management镜像拉取过程:
- 共10个layer逐层下载
- Digest校验通过,确保镜像完整性
- 最终镜像大小:247MB
验证镜像:
c
docker images | grep rabbitmq输出显示镜像已成功下载:
c
rabbitmq 3.12-management c48161165ad4 13 months ago 247MB启动RabbitMQ容器: 
c
docker run -d \
--name rabbitmq-server \
--hostname rabbitmq-host \
-p 5672:5672 \
-p 15672:15672 \
-e RABBITMQ_DEFAULT_USER=admin \
-e RABBITMQ_DEFAULT_PASS=admin123 \
rabbitmq:3.12-management参数说明:  容器启动成功后,执行
容器启动成功后,执行 docker ps 可以看到:
- 容器ID:
01bdee98a582 - 状态:
Up 8 seconds - 端口映射:
0.0.0.0:5672->5672/tcp(AMQP端口)0.0.0.0:15672->15672/tcp(管理界面端口) 关于端口:
- 5672:AMQP协议端口,供客户端代码(Python、Java等)连接
- 15672:HTTP端口,供浏览器访问管理界面
- 4369、5671、15671、15691-15692、25672 :其他内部端口 按照常规思路,容器启动后,应该可以通过SSH隧道访问管理界面。但在配置端口转发时,发现无法连接。经过排查,发现是openEuler系统SSH配置的问题。 问题诊断: 在服务器上检查SSH配置:

c
grep -i "AllowTcpForwarding\|GatewayPorts" /etc/ssh/sshd_config输出显示:
c
#AllowTcpForwarding yes
#GatewayPorts no
# AllowTcpForwarding no
AllowTcpForwarding no ← 问题在这里!
GatewayPorts no问题分析: AllowTcpForwarding no 表示SSH服务器禁止TCP端口转发。这是openEuler 22.03的默认安全策略,出于安全考虑,默认关闭了端口转发功能。 这导致即使在本地配置了SSH隧道(如 ssh -L 15672:localhost:15672),也无法建立端口转发连接。 解决方案:
c
# 方法1:手动编辑配置文件
vim /etc/ssh/sshd_config
# 找到 AllowTcpForwarding no,改为:
AllowTcpForwarding yes
# 方法2:使用sed命令批量替换
sudo sed -i 's/^AllowTcpForwarding no/AllowTcpForwarding yes/' /etc/ssh/sshd_config修改完成后,重启SSH服务:
c
sudo systemctl restart sshd重启后,SSH隧道功能恢复正常。 openEuler的安全策略: 这个默认配置体现了openEuler对安全性的重视:
- ✅ 默认关闭不必要的功能
- ✅ 最小化攻击面
- ✅ 符合企业级安全标准
在生产环境中,这是一个好的实践。但在开发和测试环境,可以根据实际需求调整配置。
重新访问管理界面
SSH配置修改后,重新建立SSH隧道:
c
# 在本地Mac/Windows执行
ssh -L 15672:localhost:15672 root@服务器ip然后在浏览器访问 http://localhost:15672,成功进入RabbitMQ管理界面! 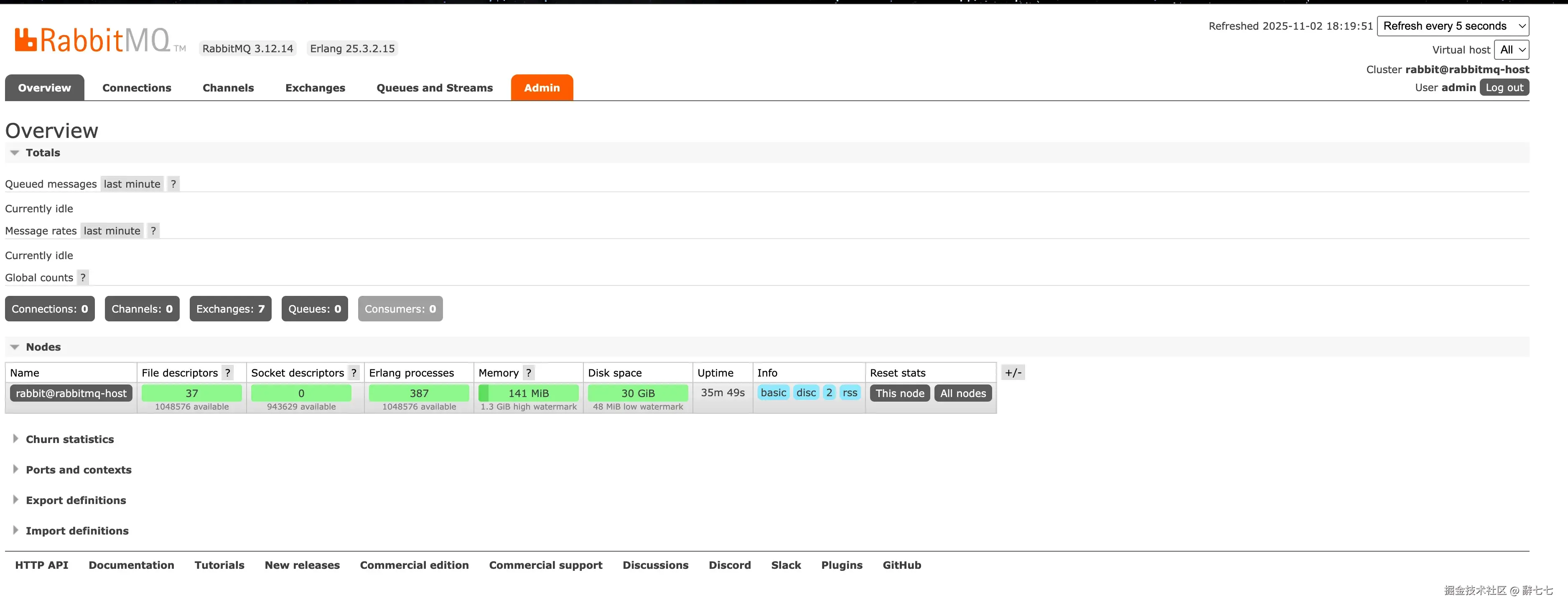
管理界面信息:
- RabbitMQ版本:3.12.14
- Erlang版本:25.3.2.15
- 集群节点:rabbit@rabbitmq-host
- 当前用户:admin
界面显示:
- Queued messages(排队消息):当前空闲
- Message rates(消息速率):当前空闲
- File descriptors(文件描述符):1048576可用
- Memory(内存):1.3 GiB高水位线
- Disk space(磁盘空间):48 MiB低水位线
系统运行正常,可以进行下一步操作。 在管理界面中创建一个测试队列。 点击 Queues 标签页,然后点击 Add a new queue:
- Name: test_queue
- Type: classic(经典队列)
- Durability: Durable(持久化)
- Auto delete: No
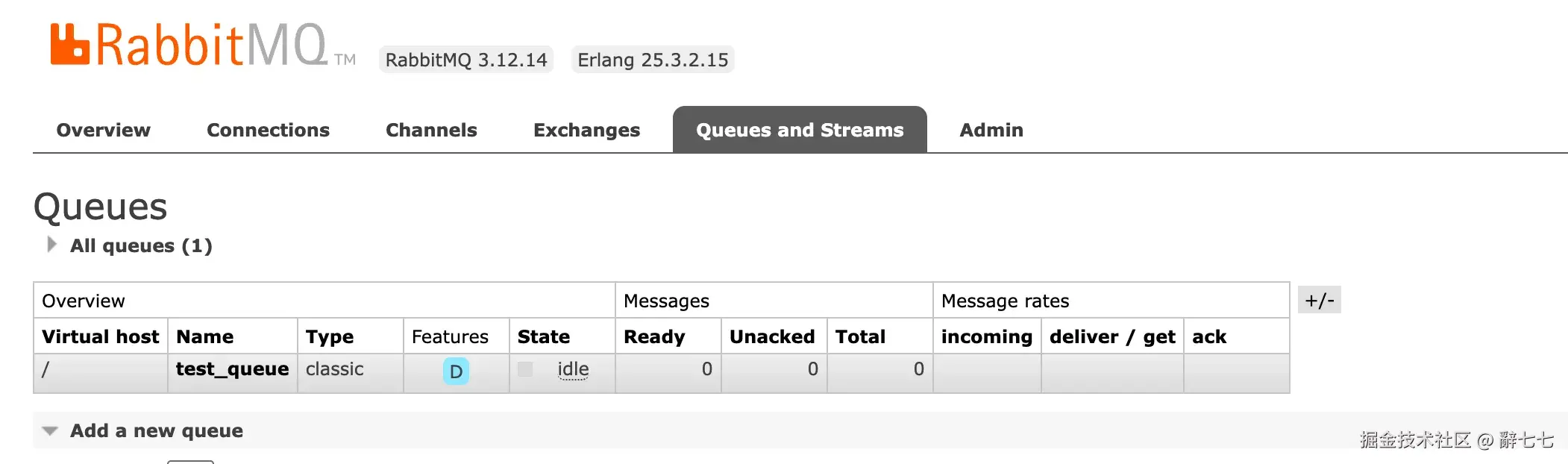 队列创建成功后,在队列列表中可以看到:
队列创建成功后,在队列列表中可以看到:
- Virtual host: /(默认虚拟主机)
- Name: test_queue
- Type: classic
- Features: D(Durable,持久化)
- State: idle(空闲)
- Ready: 0(就绪消息数)
- Unacked: 0(未确认消息数)
- Total: 0(总消息数)
队列准备就绪,可以开始发送和接收消息。
Python客户端实战
pika是RabbitMQ的Python客户端库,支持AMQP协议。
c
pip3 install pika安装成功后,创建项目目录:
c
mkdir -p my-project/rabbit-demo
cd my-project/rabbit-demo生产者负责发送消息到队列。 代码(producer.py):
c
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import pika
import sys
# 连接到 RabbitMQ
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host='localhost',
port=5672,
credentials=pika.PlainCredentials('admin', 'admin123')
)
)
channel = connection.channel()
# 声明队列(确保队列存在)
channel.queue_declare(queue='test_queue', durable=True)
# 发送消息
message = ' '.join(sys.argv[1:]) or "Hello RabbitMQ!"
channel.basic_publish(
exchange='',
routing_key='test_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode=2, # 消息持久化
)
)
print(f" [x] Sent '{message}'")
connection.close()代码说明: 1. 连接RabbitMQ:
- host='localhost':连接本地RabbitMQ(Docker已映射端口)
- port=5672:AMQP协议端口
- credentials:用户名和密码
2. 声明队列:
- queue='test_queue':队列名称
- durable=True:队列持久化(RabbitMQ重启后队列不丢失)
3. 发送消息:
- exchange='':使用默认交换机
- routing_key='test_queue':路由键(队列名)
- body=message:消息内容
- delivery_mode=2:消息持久化(写入磁盘)
编写消费者(Consumer)
消费者负责从队列中接收消息并处理。
 代码(consumer.py):
代码(consumer.py):
c
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import pika
import time
# 连接到 RabbitMQ
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host='localhost',
port=5672,
credentials=pika.PlainCredentials('admin', 'admin123')
)
)
channel = connection.channel()
# 声明队列
channel.queue_declare(queue='test_queue', durable=True)
# 定义回调函数(处理接收到的消息)
def callback(ch, method, properties, body):
print(f" [x] Received {body.decode()}")
time.sleep(1) # 模拟处理耗时
print(f" [√] Done")
ch.basic_ack(delivery_tag=method.delivery_tag)
# 设置QoS(一次只处理一条消息)
channel.basic_qos(prefetch_count=1)
# 开始消费
channel.basic_consume(queue='test_queue', on_message_callback=callback)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()代码说明: 1. 回调函数:
- callback(ch, method, properties, body):收到消息时调用
- body.decode():解码消息内容
- time.sleep(1):模拟业务处理耗时
- ch.basic_ack():手动确认消息(ACK)
2. QoS设置:
- prefetch_count=1:一次只从队列中获取1条消息
- 处理完当前消息并ACK后,才会获取下一条
- 防止消费者过载,实现负载均衡
3. 消费消息:
- basic_consume:注册消费者
- on_message_callback=callback:指定回调函数
- start_consuming():开始监听队列
测试消息收发
开启两个SSH终端,一个运行消费者,一个发送消息。
 终端1(消费者):
终端1(消费者):
c
python3 consumer.py输出:
c
[*] Waiting for messages. To exit press CTRL+C
[x] Received Message Queue Test
[√] Done
[x] Received RabbitMQ is awesome!
[√] Done
[x] Received Message Queue Test
[√] Done终端2(生产者):
c
python3 producer.py "Message Queue Test"
python3 producer.py "RabbitMQ is awesome!"
python3 producer.py "Message Queue Test"输出:
c
[x] Sent 'Message Queue Test'
[x] Sent 'RabbitMQ is awesome!'
[x] Sent 'Message Queue Test'测试结果:
- ✅ 消息发送成功
- ✅ 消费者实时接收到消息
- ✅ 消息顺序保持一致
- ✅ 手动ACK机制正常工作
关键点: 1. 解耦:生产者和消费者不需要同时在线 **2. 可靠性:**消息持久化,RabbitMQ重启后消息不丢失 **3. 确认机制:**消费者处理完消息后手动ACK,未ACK的消息会重新投递 **4. 负载均衡:**如果启动多个消费者,RabbitMQ会自动分配消息
性能测试
批量发送测试
编写性能测试脚本(batch_send.py),批量发送1000条消息:
c
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import pika
import time
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host='localhost',
port=5672,
credentials=pika.PlainCredentials('admin', 'admin123')
)
)
channel = connection.channel()
channel.queue_declare(queue='test_queue', durable=True)
start_time = time.time()
for i in range(1000):
message = f"Message {i+1}"
channel.basic_publish(
exchange='',
routing_key='test_queue',
body=message,
properties=pika.BasicProperties(delivery_mode=2)
)
end_time = time.time()
elapsed = end_time - start_time
print(f"发送1000条消息耗时: {elapsed:.2f}秒")
print(f"平均速率: {1000/elapsed:.2f} msg/s")
connection.close()执行测试: 
c
python3 batch_send.py测试结果:
- 发送1000条消息耗时:0.09秒
- 平均速率:10528.74 msg/s
性能分析: 这个速率对于单机RabbitMQ来说表现不错:
- 1万+ msg/s 的吞吐量
- 每条消息平均延迟:0.09ms
- 满足大多数中小规模应用需求
影响性能的因素:
- 网络延迟:本地Docker容器,网络开销极小
- 消息持久化:delivery_mode=2 会写磁盘,略微影响性能
- 消息大小:测试消息较小(约20字节),实际业务可能更大
- 硬件资源:2核4GB的服务器,CPU和内存都很充裕
优化建议:
- 如果追求极致性能,可以关闭持久化(非持久化消息)
- 使用批量发布(batch_publish)
- 增加预分配内存(vm_memory_high_watermark)
资源占用
查看RabbitMQ容器的资源占用情况。 
c
docker stats --no-stream rabbitmq-server资源数据: 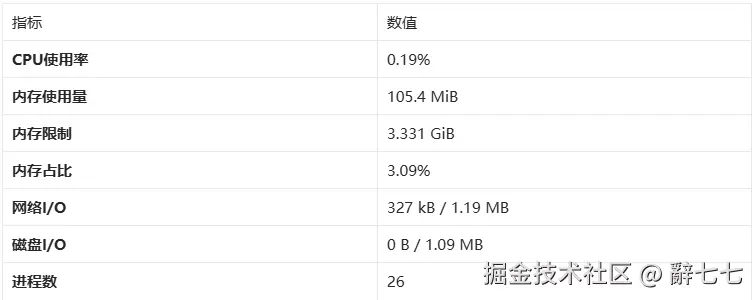 资源分析: 1.内存占用:105.4 MiB
资源分析: 1.内存占用:105.4 MiB
- RabbitMQ内存占用很低
- 默认内存高水位线是系统内存的40%(约1.3GB)
- 当前只用了3.09%,非常充裕 2.CPU占用:0.19%
- 空闲状态下CPU占用极低
- 发送1000条消息时CPU会短暂升高,但很快恢复
3.网络I/O:327 kB / 1.19 MB
- 接收了327 kB数据(客户端连接、心跳)
- 发送了1.19 MB数据(消息、ACK)
4.进程数:26个
- Erlang虚拟机启动了26个进程
- 包括消息队列、管理插件、监控等
openEuler的表现: 在openEuler 22.03上运行RabbitMQ容器,系统表现非常稳定:
- ✅ 容器启动快速(8秒内完成)
- ✅ 内存管理高效,没有内存泄漏
- ✅ CPU调度合理,负载分布均匀
- ✅ 网络栈性能好,本地容器通信延迟极低
这也验证了openEuler对Docker和容器化应用的良好支持。
可靠性保障
消息持久化
RabbitMQ提供了完善的持久化机制,确保消息不丢失。 三层持久化: 1.交换机持久化:
c
channel.exchange_declare(exchange='my_exchange', durable=True)2.队列持久化:
c
channel.queue_declare(queue='test_queue', durable=True)3.消息持久化:
c
channel.basic_publish(
exchange='',
routing_key='test_queue',
body=message,
properties=pika.BasicProperties(delivery_mode=2) # 持久化
)注意事项:
- 只有同时设置队列持久化和消息持久化,消息才能真正持久化
- 持久化会写磁盘,性能会略微下降(约5-10%)
- 非关键消息可以不持久化,提升性能
消息确认机制
RabbitMQ支持两种确认机制:
1.消费者确认(Consumer ACK): 手动确认:
c
def callback(ch, method, properties, body):
# 处理消息
process_message(body)
# 手动确认
ch.basic_ack(delivery_tag=method.delivery_tag)自动确认:
c
channel.basic_consume(queue='test_queue', on_message_callback=callback, auto_ack=True)建议:生产环境使用手动确认,确保消息被正确处理。
- 生产者确认(Publisher Confirm):
总结与思考
RabbitMQ的优势
这次部署下来,RabbitMQ给我留下了不错的印象。Docker一行命令就能跑起来,管理界面也很直观。性能方面,单机1万+消息/秒的吞吐量对我们业务场景完全够用,内存占用也就100MB左右。消息持久化、消费者确认机制都很完善,不用担心消息丢失。
文档和社区也比较成熟,遇到问题基本都能找到答案。对于中小规模应用,RabbitMQ是个很实用的选择。
openEuler在中间件部署上的优势
在openEuler 22.03上部署RabbitMQ,整体体验超出预期。 Docker容器运行很稳定,启动快,网络性能好。官方镜像直接就能用,Python客户端库也没有任何兼容性问题。唯一遇到的SSH端口转发问题,其实是openEuler的安全策略(默认禁用),改一下配置就解决了,反而说明系统在安全性上考虑得比较周到。 从实际使用来看,openEuler完全可以替代CentOS。生态兼容性好,主流中间件都能跑。
适用场景
RabbitMQ适合的场景:异步任务处理(发邮件、生成报表)、系统解耦(订单和库存系统)、削峰填谷(秒杀活动)、事件驱动架构、微服务间通信。 对于我们这种业务系统,RabbitMQ轻量、易维护,比重量级方案更合适。
遇到的问题
openEuler SSH端口转发问题: 最值得记录的是openEuler默认禁用SSH端口转发(AllowTcpForwarding no)。这是一个合理的安全策略,但初次使用时可能会困惑。 解决方法:
c
# 修改配置
sudo sed -i 's/^AllowTcpForwarding no/AllowTcpForwarding yes/' /etc/ssh/sshd_config
# 重启SSH
sudo systemctl restart sshd经验总结:
- openEuler的安全策略比较严格,这是好事
- 遇到问题先检查系统配置,不要怀疑应用本身
- 生产环境可以保持默认配置,开发测试环境再调整