在计算机系统中,进程是操作系统资源分配和调度的基本单位,也是理解操作系统工作原理的关键。无论是日常使用的应用程序,还是后台运行的服务,本质上都是一个个进程在协同工作。本文将围绕进程的核心基础概念展开,结合 Linux 系统实操,带你从 0 到 1 理解进程的定义、描述方式、创建方法及查看手段。
1. 进程的概念
1.1 进程的基本概念
我们平时编写的 C/C++ 代码、执行的 Shell 脚本,在未运行时只是存放在磁盘上的可执行程序------ 它是静态的,仅包含指令、数据和资源描述,不占用系统运行资源。
而进程是程序的执行实例:当可执行程序被加载到内存后,操作系统会为其分配 CPU 时间、内存空间等资源,并创建专门的数据结构对其进行管理,此时静态的程序就变成了动态运行的进程。
简单来说:进程 = 可执行程序 + 操作系统分配的资源 + 进程管理数据结构(PCB)。
从操作系统内核的角度看,进程的核心价值是担当分配系统资源(CPU 时间、内存)的实体。内核通过统一的方式管理所有进程,实现资源的合理调度和高效利用。
关于操作系统分配的资源,本文不作详细的解释,可将进程简单理解为被加载到内存中的可执行程序和PCB
1.2 PCB(进程控制块)
操作系统要管理众多进程,首先需要清晰地描述每个进程的属性和状态 ------ 这个 "描述工具" 就是进程控制块(PCB,Process Control Block) ,它是进程存在的唯一标识。
打个比方,校长要管理学生,只需了解学生的信息即可进行各种操作,如让数学成绩最好的学生参加数学竞赛,让违纪最多的学生受到惩罚等,而PCB则是记录学生各种信息的结构体,如:
cpp
struct Student
{
string name; //学生姓名
int id; //学号
int score; //成绩
// ....各种信息
};在 Linux 系统中,PCB 对应的具体数据结构是task_struct,它会被加载到内存中,包含进程的所有关键信息。可以说,理解了task_struct,就理解了进程的核心属性。
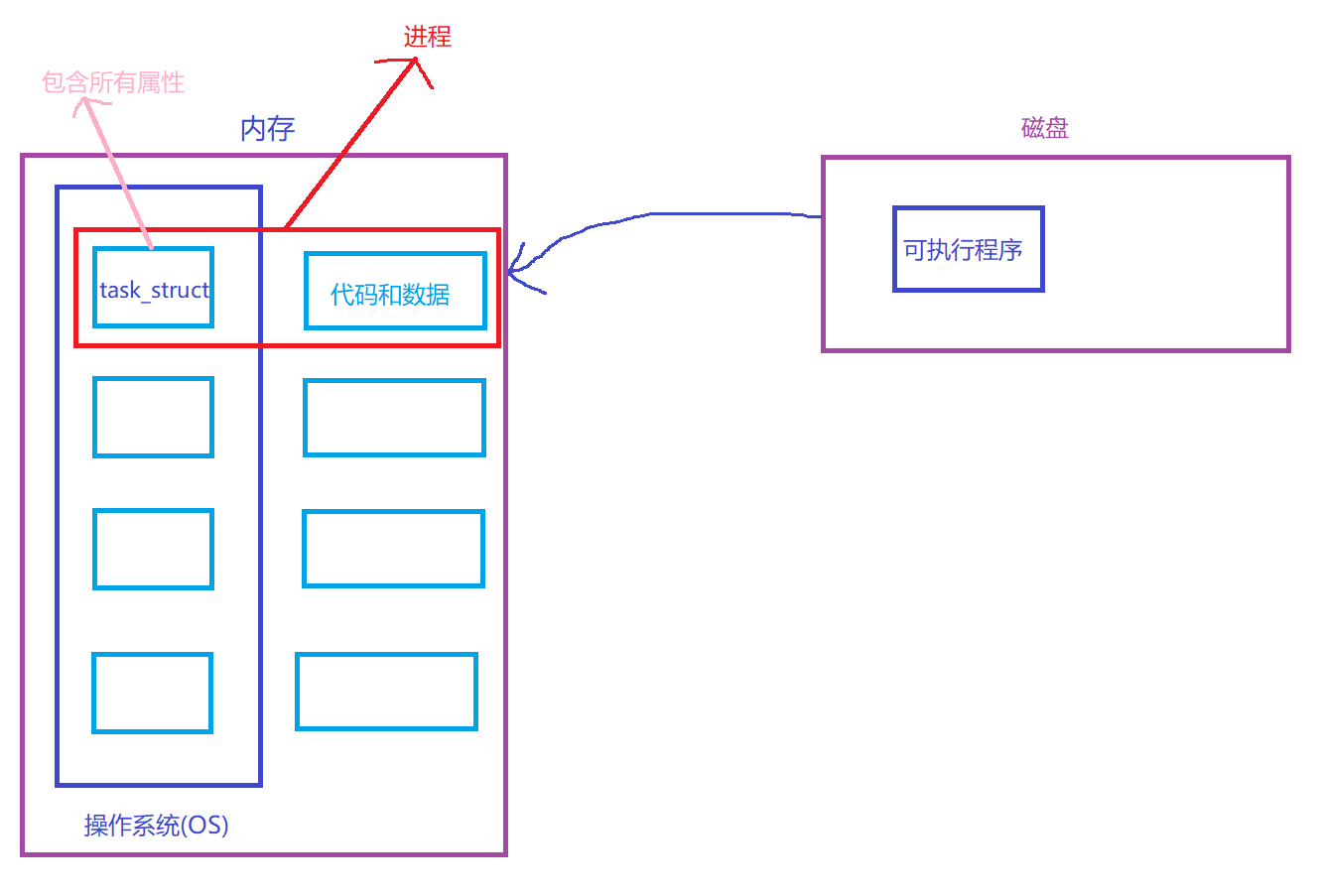
我们可以从三部分来理解图中的场景,也即 Linux 系统中进程在内存中的核心结构:
来源: 磁盘上的 "可执行程序" 被加载到内存后,会拆分为两部分 ------代码和数据(程序要执行的指令、要处理的内容) + 操作系统自动创建的task_struct(也就是 PCB,存储进程的 PID、状态、优先级等所有属性)。
进程的构成: task_struct + 加载到内存的代码和数据,共同组成了一个完整的进程(红色框标注的部分)。
**管理逻辑:**task_struct由操作系统(OS)统一管理(比如用链表把多个进程的task_struct串起来),这也是操作系统能调度、控制进程的关键。
简单来说:进程就是 "内存中的代码数据 + 描述它的 task_struct",而这一切都是从磁盘加载可执行程序开始的。
1.3 task_struct 的核心内容
task_struct是一个庞大的结构体,核心信息可分为以下几类:
进程标识符(PID): 进程的唯一 ID,用于区分系统中的所有进程(比如 PID=1 的进程是 init/systemd,系统初始化进程)。同时还包含父进程 ID(PPID),记录进程的创建者。
进程状态: 标记进程当前的运行状态(如运行、睡眠、停止等),后续会详细说明。
优先级: 决定进程获取 CPU 资源的先后顺序,优先级越高,越容易被调度。
程序计数器(PC 指针): 存储程序即将执行的下一条指令的地址,确保进程切换后能恢复执行进度。
内存指针: 指向进程的代码段、数据段、共享内存块等内存区域,明确进程资源在内存中的位置。
上下文数据: 进程执行时 CPU 寄存器中的数据。由于 CPU 寄存器只有一套,进程切换时需将上下文数据保存到task_struct,恢复运行时再从这里读取,保证执行逻辑不中断。
I/O 状态信息: 记录进程打开的文件、申请的 I/O 设备等,比如进程操作的磁盘文件、网络套接字等。
**记账信息:**统计进程占用的 CPU 时间、内存使用量等资源消耗数据,用于系统监控和资源调度。
1.4 进程的组织方式
系统中所有运行的进程,其task_struct会通过双向链表的形式组织起来。当创建新进程时,会生成新的task_struct并插入链表;当进程退出时,会将对应的task_struct从链表中移除。这种组织方式能让操作系统高效地遍历、查找和管理所有进程。

2. 查看进程
在 Linux 系统中,我们可以通过多种工具查看进程的详细信息,以下是最常用的方法:
2.1 查看 /proc 文件系统
Linux 系统在/proc目录下提供了进程的实时信息,每个进程对应一个以 PID 命名的子目录。

查看 PID 为 1 的进程(init/systemd)信息:ls /proc/1

该目录下的cmdline文件存储进程启动命令,status文件存储进程状态,maps文件存储内存映射信息。
2.2 使用 ps 指令查看进程
ps是最常用的进程查看工具,结合不同参数可获取不同维度的信息:
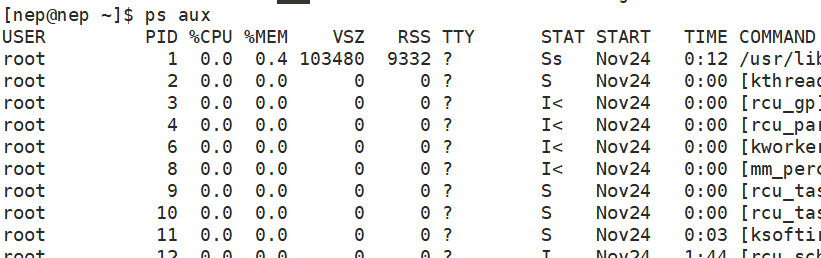
ps aux:查看系统中所有进程的详细信息(包括其他用户的进程)
a: 显示终端下的所有进程
u: 以用户为中心,显示进程的 CPU、内存占用率等
**x:**显示无控制终端的进程(如后台守护进程)
ps -l:查看当前终端的进程,重点关注优先级相关字段(PRI、NI)

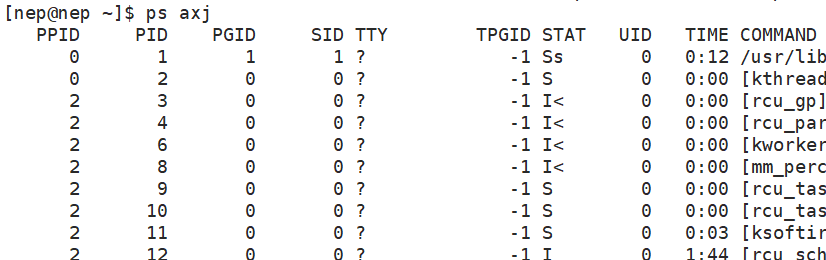
ps axj:显示进程的 PID、PPID、进程组 ID(PGID)等,方便查看进程间的父子关系(PPID为父进程ID)
2.3 结合 grep 过滤特定进程
如果要查找某个特定进程(如名为test的进程),可结合grep指令:
ps aux | grep test | grep -v grep
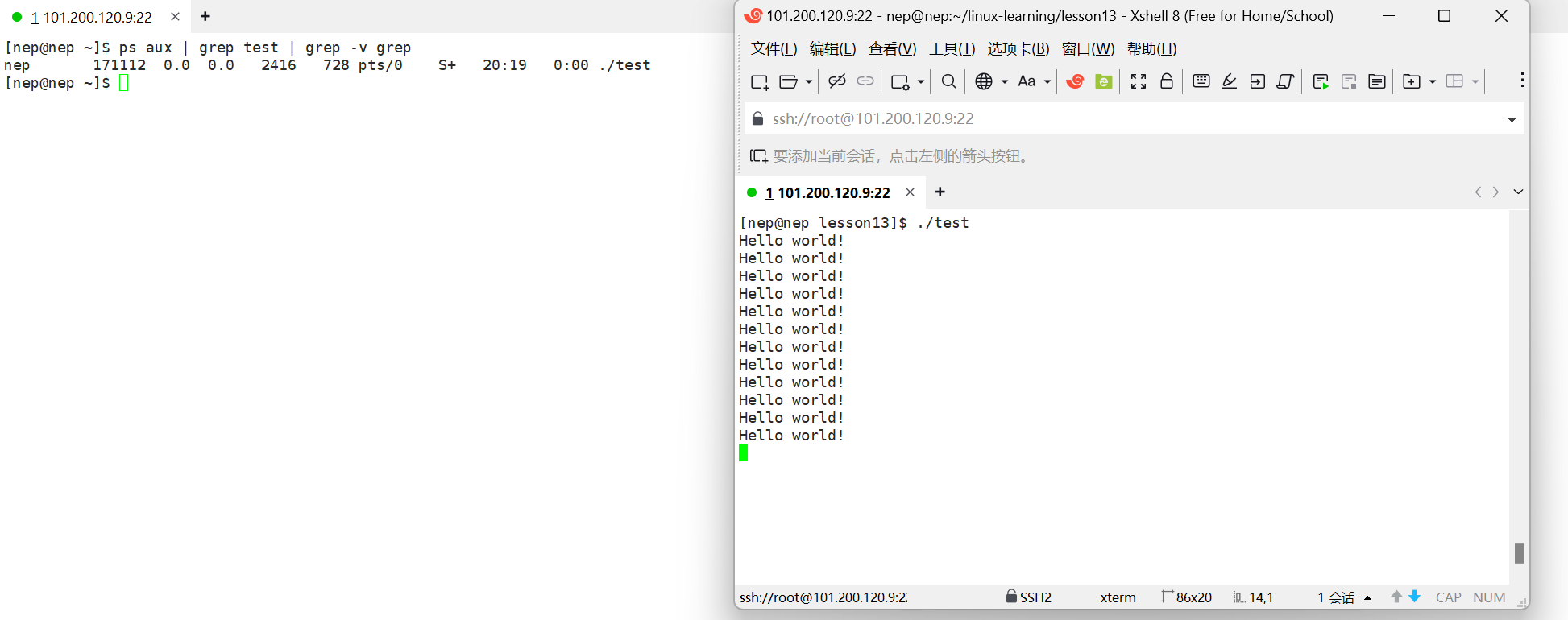
grep -v grep:排除grep命令本身对应的进程,避免干扰结果
这里注意grep本身也是一个进程,当你用grep去查找test的时候,grep进程信息中包含"test"关键词,进而会被搜索出来,如果不想让grep显示就用 grep -v grep 命令。
3 进程的创建
3.1 进程ID的查看
通过系统调用函数getpid() 和getppid() 可以分别获取进程的PID(进程ID) 和PPID(父进程ID)。
我们运行以下代码:
cpp
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
printf("pid: %d\n", getpid());
printf("ppid: %d\n", getppid());
return 0;
}
我们可以使用Ctrl + C 或kill -9 进程PID来杀死对应的进程(停止进程)。
3.2 fork () 的核心特性
在 Linux 中,创建新进程的核心系统调用是fork(),它能基于当前进程(父进程)创建一个全新的子进程。

核心理解:
**父子进程关系:**调用fork()后,系统会复制父进程的task_struct、内存空间等资源(数据采用 "写时拷贝" 机制,初始时共享,修改时才复制,提高效率)。
**代码共享:**父子进程共享父进程的代码段,即fork()之后的代码会被父子进程同时执行。
两个返回值: fork()是唯一会返回两次的系统调用:
• 父进程中返回子进程的 PID(便于父进程管理子进程)
• 子进程中返回0(子进程可通过getppid()获取父进程 PID)
• 若创建失败,父进程中返回 **-1**(如资源不足)
我们来执行以下代码进行观察:
cpp
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
pid_t ret = fork(); // 创建子进程
if (ret < 0)
{
perror("fork"); // 创建失败,打印错误信息
return 1;
}
else if (ret == 0)
{
// 子进程执行逻辑
while (1)
{
printf("我是子进程:PID=%d,父进程PPID=%d\n", getpid(), getppid());
sleep(1);
}
}
else
{
while (1)
{
// 父进程执行逻辑
printf("我是父进程:PID=%d,子进程PID=%d\n", getpid(), ret);
sleep(1);
}
}
return 0;
}输出结果:

子进程的PPID为父进程的PID,而父进程(当前进程)的父进程为bash(bash 是终端的 Shell 进程,负责启动命令行中的程序),一般而言,在命令行上运行的指令,父进程基本都是bash。
fork() 之前的代码被父进程执行,fork之后的代码由父子进程共同执行,父子进程虽然代码共享,但如果其中一个进程更改了数据呢?其实这里采用了写时拷贝,即父子进程各自开辟数据空间,保证数据修改互不影响。
注意:使用fork函数创建子进程后就有了两个进程,但这两个进程被操作系统调度的顺序是不确定的,这取决于操作系统调度算法的具体实现。
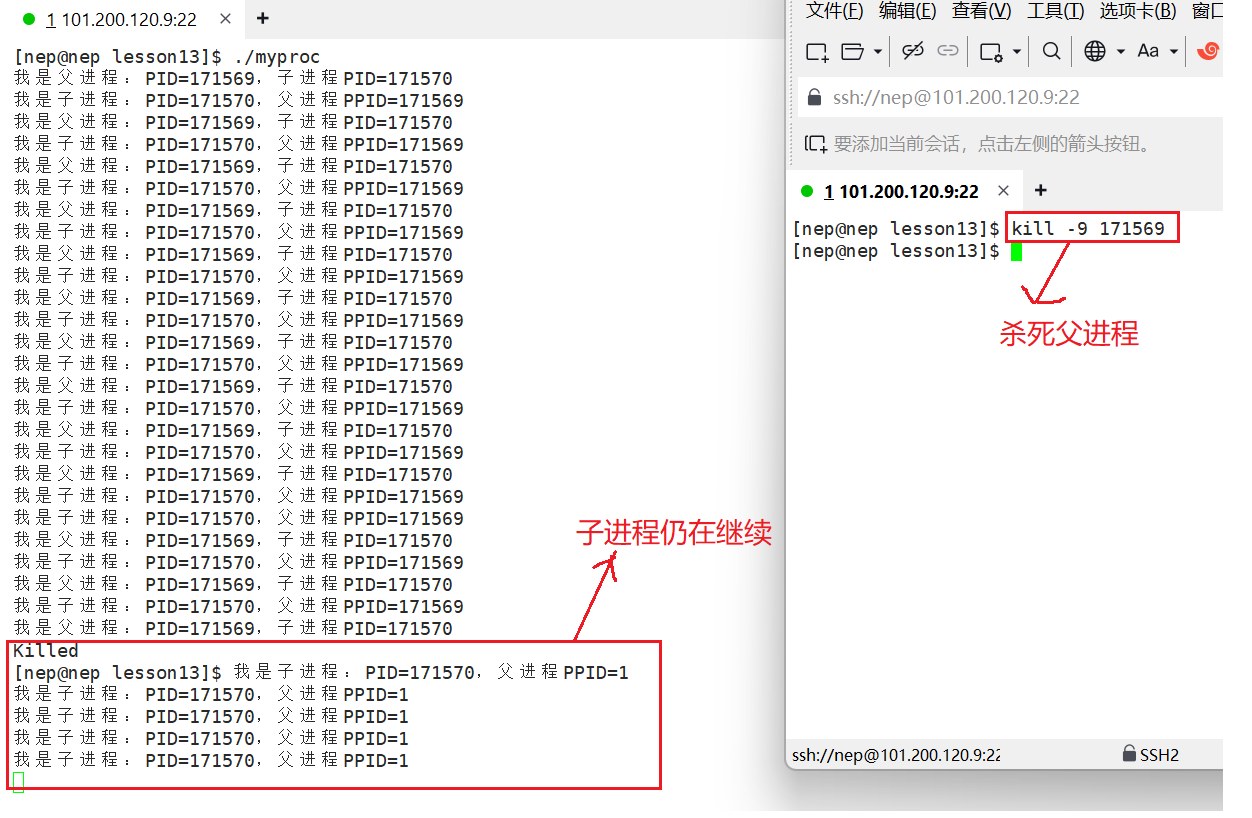
进程之间的运行是互相独立的,即使一个进程异常退出,也不会影响另一个进程的运行。例如,杀死父进程后,子进程仍然会继续运行(后续"孤儿进程"会详细讲解)。
结语
好好学习,天天向上!有任何问题请指正,谢谢观看!