一、卷积神经网络(CNN)
1、基本概念
(1)图像:三维张量(Tensor),其中一维代表图像的宽,另一维代表图像的高,还有一维代表图像的通道(channel)的数目。
(2)通道(channel):彩色图像的每个像素都可以描述为红色(red)、绿色(green)、蓝色(blue)的组合,这3种颜色就称为图像的3个色彩通道。这种颜色描述方式称为RGB色彩模型常用于在屏幕上显示颜色。
(3)输入:把三维张量转化为向量。例如:张量有100*100*3个数字,所以一张图像是由100*100*3个数字所组成的,把这些数字排成一排就是一个巨大的向量。这个向量可以作为网络的输入,而这个向量里面每一维里面存的数值是某一个像素在某一个通道下的颜色强度。

图像有大有小,而且不是所有图像尺寸都是一样的。常见的处理方式是把所有图像先调整成相同尺寸,再"丢"到图像的识别系统里面。
(4)更多的参数为模型带来了更好的弹性和更强的能力,但也增加了过拟合的风险。模型的弹性越大,就越容易过拟合。
2、观察1
检测模式不需要整张图像,它要做的就是检测图像里面有没有出现一些特别重要的模式(pattern),这些模式是代表了某种物体的。
3、简化1
(1)感受野(receptive):由自己设定,每一个神经元都只关心自己的感受野里面发生的事情,每个神经元会把感受野中的数值"拉直"变成一个长度为n*m*k维的向量,再把这个向量作为神经元的输入,这个神经元会给这个向量的每个维度一个权重,即有n*m*k个权重,再加上偏置(bias)得到输出,再把这个输出再送给下一层的神经元当作输入。
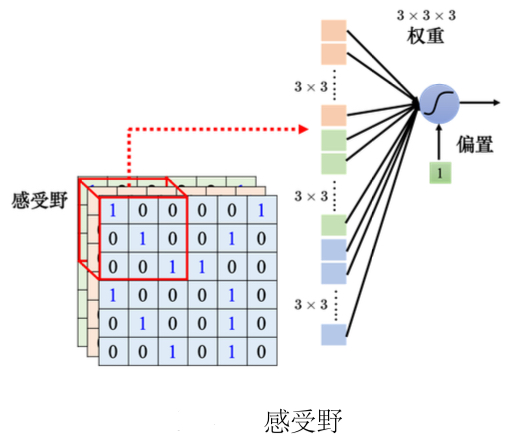
- 感受野可以有大有小,因为模式有的比较小,有的比较大。有的模式也许在3*3的范围内就可以被检测出来,有的模式也许要11*11的范围才能被检测出来。
- 感受野可以只考虑某些通道。目前感受野是RGB 三个通道都考虑,但也许有些模式只在红色或蓝色的通道会出现,即有的神经元可以只考虑一个通道。
- 感受野不仅可以是正方形的,例如3*3、11*11,也可以是长方形的,完全可以根据对问题的理解来设计感受野。
- 感受野的范围不一定要相连,理论上可以有一个神经元的感受野就是图像的左上角跟右上角,但是要考虑为什么要这么做,这么做有没有意义。
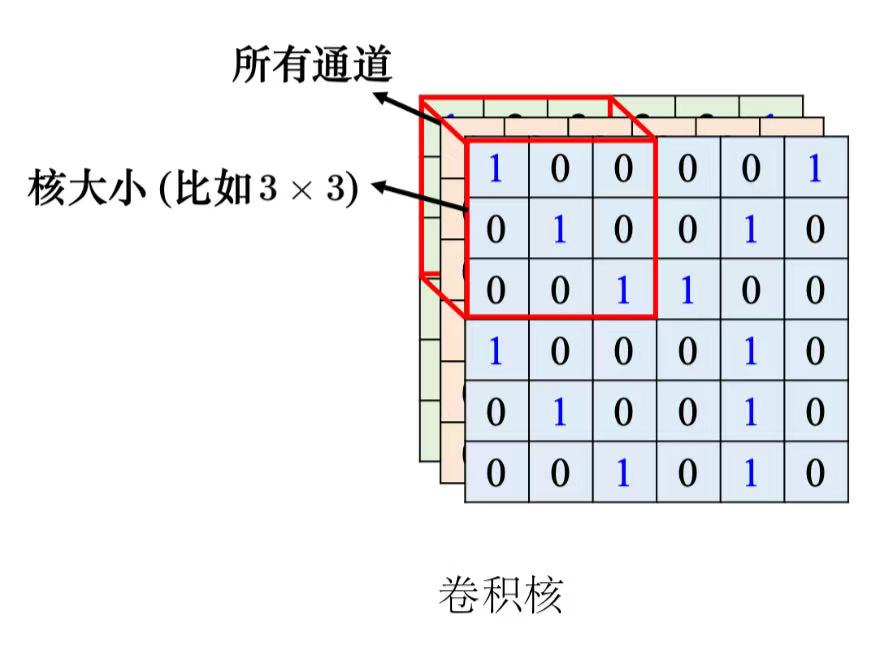
(2)经典的感受野设置
- all channels(深度),kernel size(高和宽合起来就是核大小);
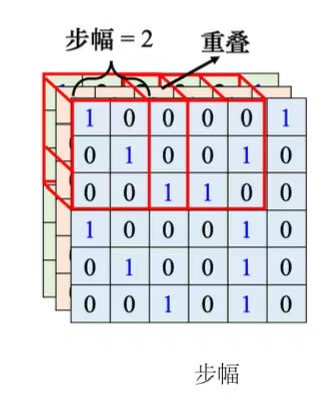
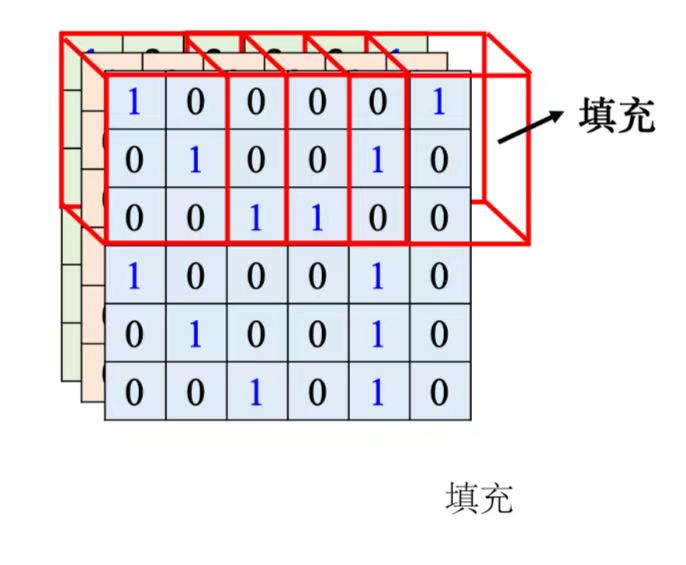
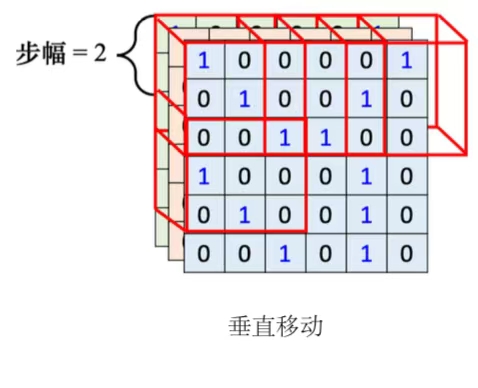
- 步幅(stride):感受野移动制造出新的感受野的移动量。
- 填充(padding):为超出图像范围的感受野补值,一般使用零填充(zero padding),也有别的补值的方法,比如补整张图像里面所有值的平均值或者把边界的这些数字拿出来补没有值的地方。
- 除了水平方向的移动,也会有垂直方向上的移动。就按照这个方式扫过整张图像。
- 一般同一个感受野会有一组神经元去守备这个范围,比如64个或者是 128 个神经元去守备一个感受野的范围。
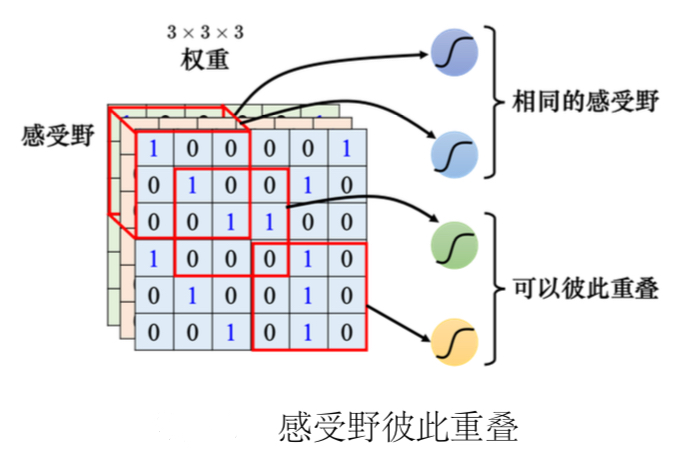
- 步幅是一个超参数需要人为调整。因为希望感受野跟感受野之间是有重叠的,所以步幅往往不会设太大,一般设为1或2。
- 假设感受野完全没有重叠,如果有一个模式正好出现在两个感受野的交界上面就没有任何神经元去检测它,这个模式可能会丢失,所以希望感受野彼此之间有高度的重肴。
4、观察2
同样的patterns可能会出现在图片的不同区域,如果每一个守备范围都有一个检测该pattern的神经元,参数量会太多。
5、简化2
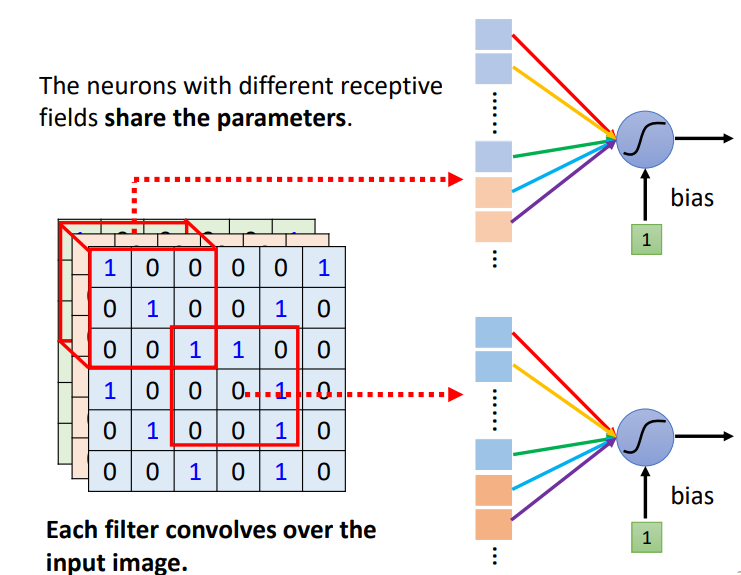
(1)共享参数(parameter sharing),即两个神经元守备的感受野不同,但是权重完全是一样的。
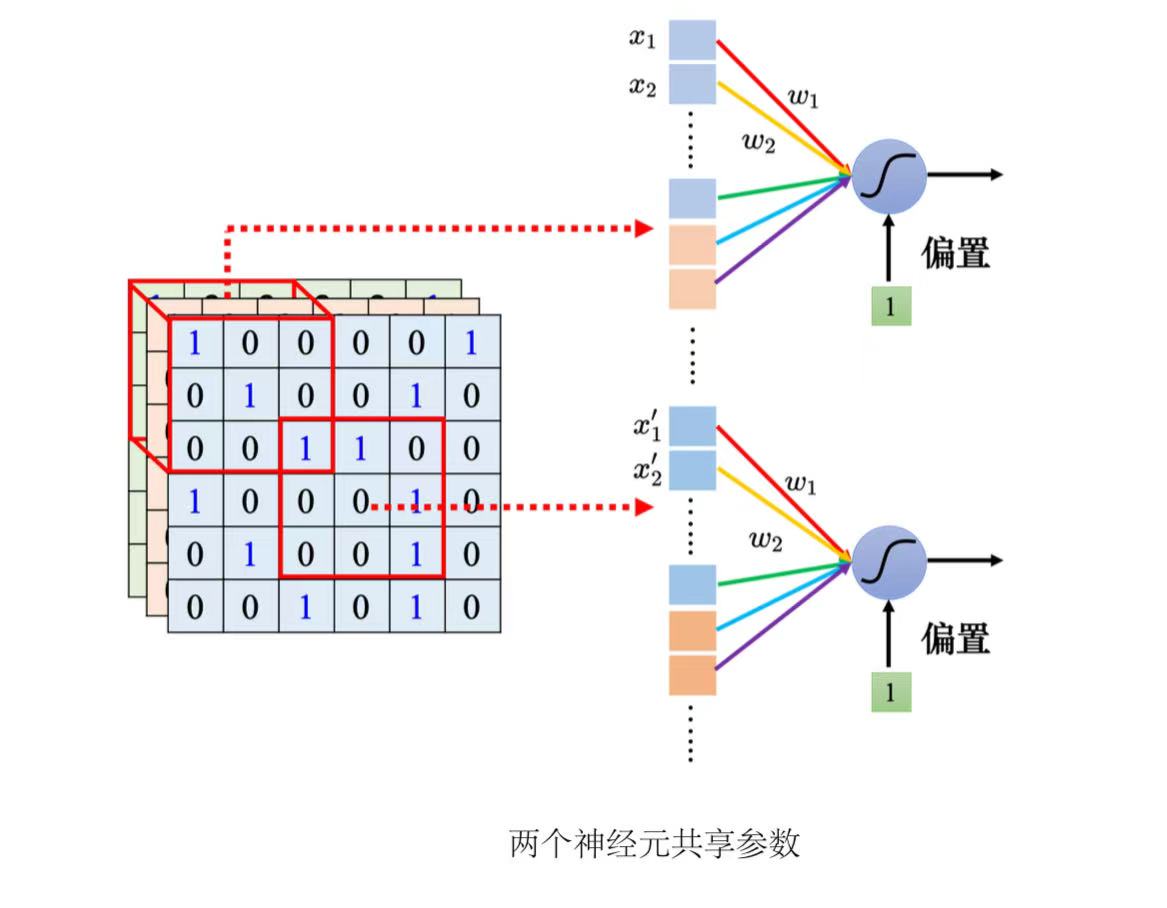
他们的输入不一样,即使共用参数,输出也是不一样的。
(2)滤波器(filter):每个感受野都有一组神经元在负责守备,比如64个神经元,它们彼此之间可以共享参数。每个感受野都只有一组参数,就是上面感受野的第 1 个神经元会跟下面感受野的第 1 个神经元共用参数,上面感受野的第 2 个神经元跟下面感受野的第 2 个神经元共用参数...这些参数称为滤波器。
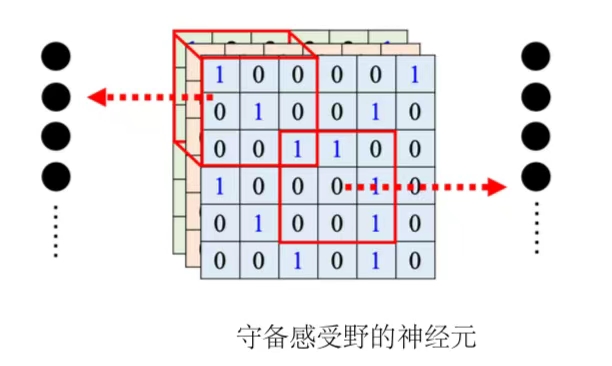
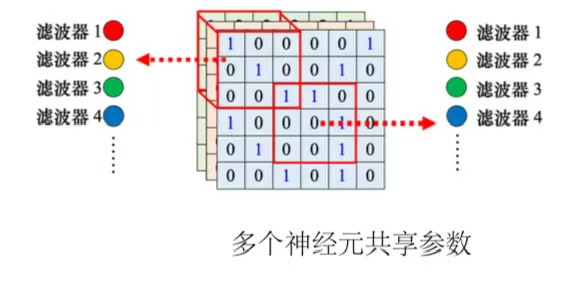
6、简化1和简化2总结
- 全连接层(fully-connected layer):全连接网络是弹性最大的,可以决定看整张图像还是一个小范围。
- 感受野(receptive field):加上感受野之后只能看一个小范围,网络弹性变小。
- 参数共享(parameter sharing):加上参数共享之后某一些神经元无论如何参数都要一模一样,又增加了对神经元的限制,进一步限制了网络的弹性。
(1)卷积层(convolutional layer):感受野加上参数共享就是卷积层。
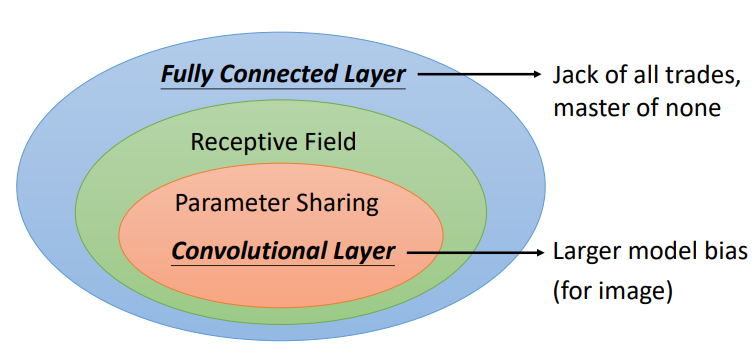
(2)卷积神经网络(CNN):用到卷积层的网络。
卷积神经网络的模型偏差较大。但模型偏差大不一定是坏事,因为当模型偏差大,模型的灵活性较低时,比较不容易过拟合。
从另一个角度看CNN1、卷积层中有很多的滤波器。
2、滤波器就是一个一个的张量,这些张量里面的数值就是模型里面的参数。这些滤波器里面的数值其实是未知的,它是可以通过学习找出来的。
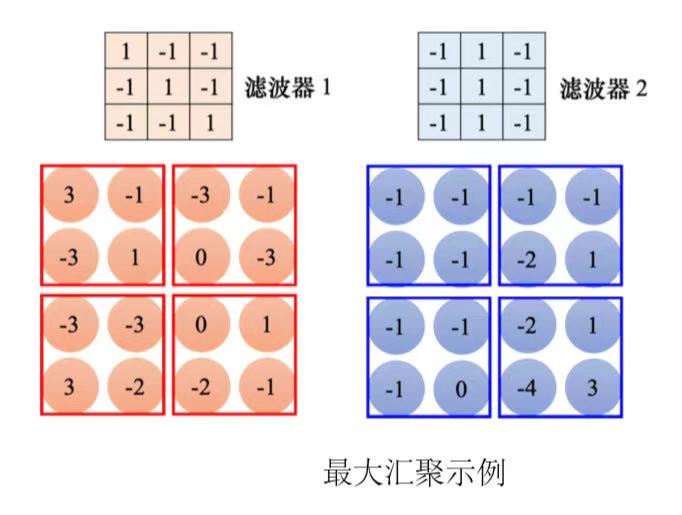
3、先把滤波器放在图片的左上角,与其做内积,设置好步幅,扫过整张图片,可得到模式检测的结果。
4、每个滤波器都做重复的过程,就可以得到特征映射(feature map),此时通道数量也变成了滤波器的数量。
5、卷积可以叠很多层。下一层滤波器的高度是上一次滤波器的数量,因为滤波器的高度是它要处理图像的通道。
6、如果滤波器的大小一直设置的较小的,网络够深也可以检测到比较大的pattern。
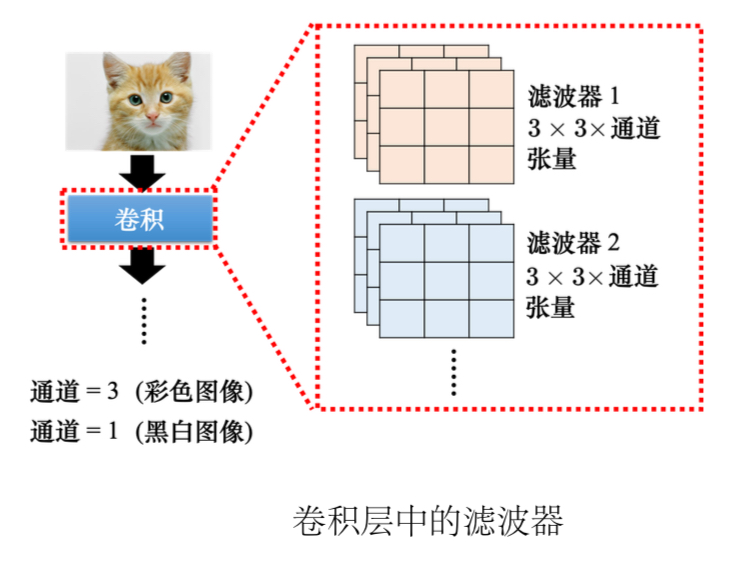
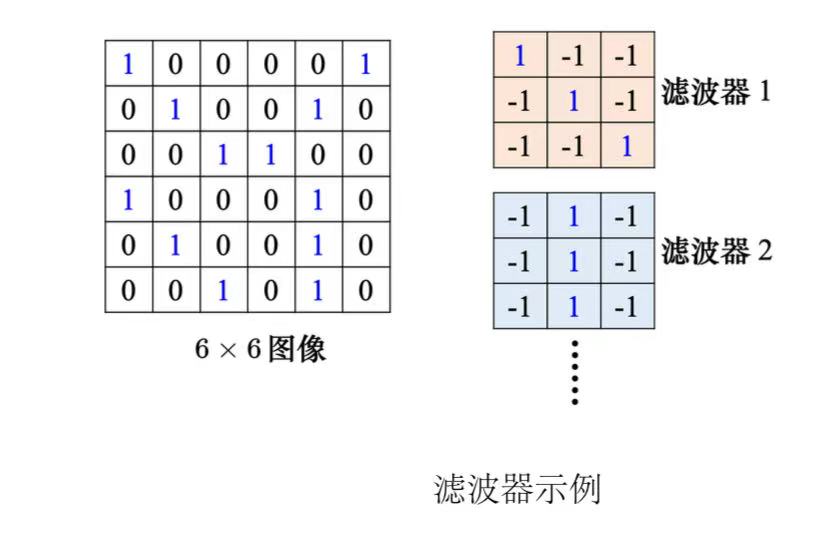
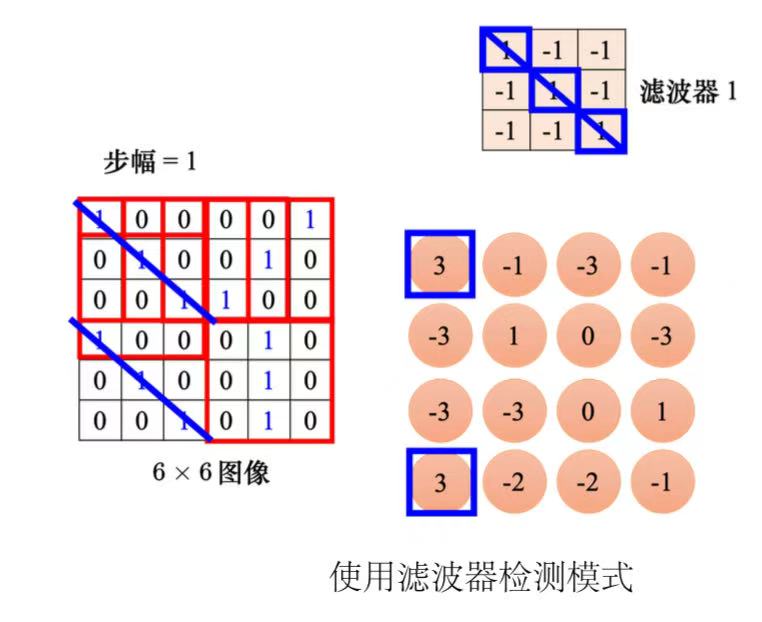
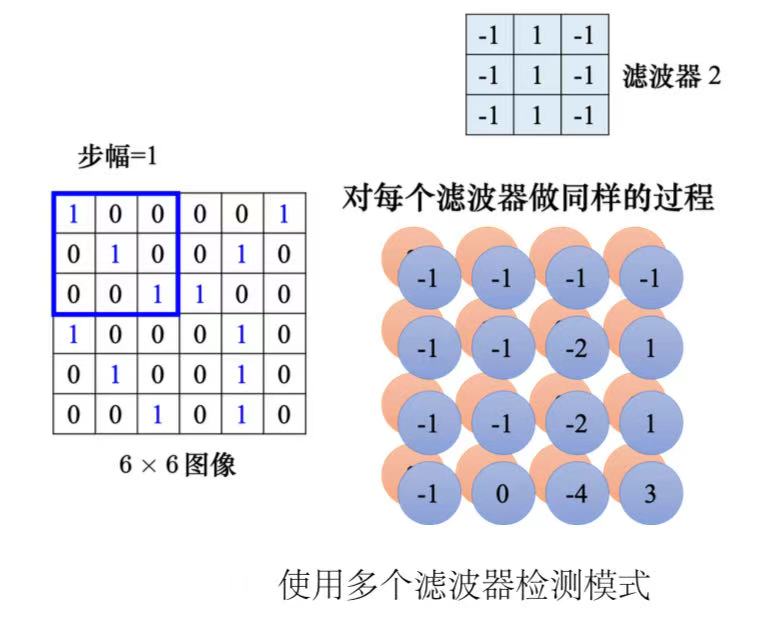
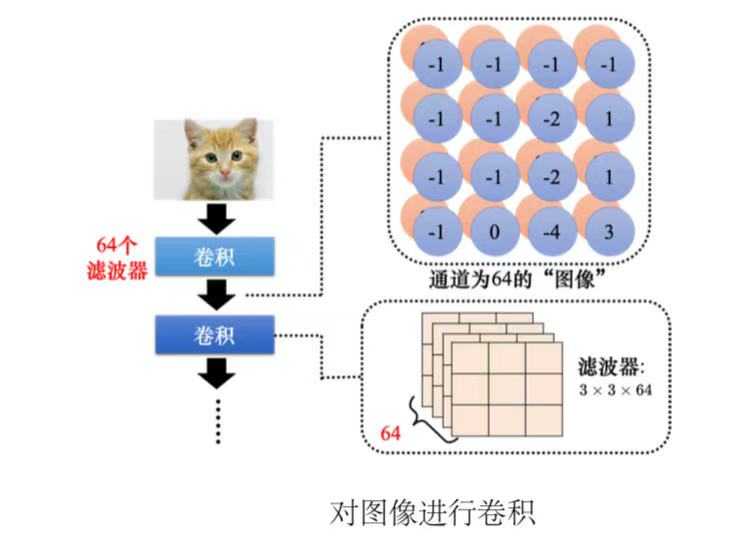
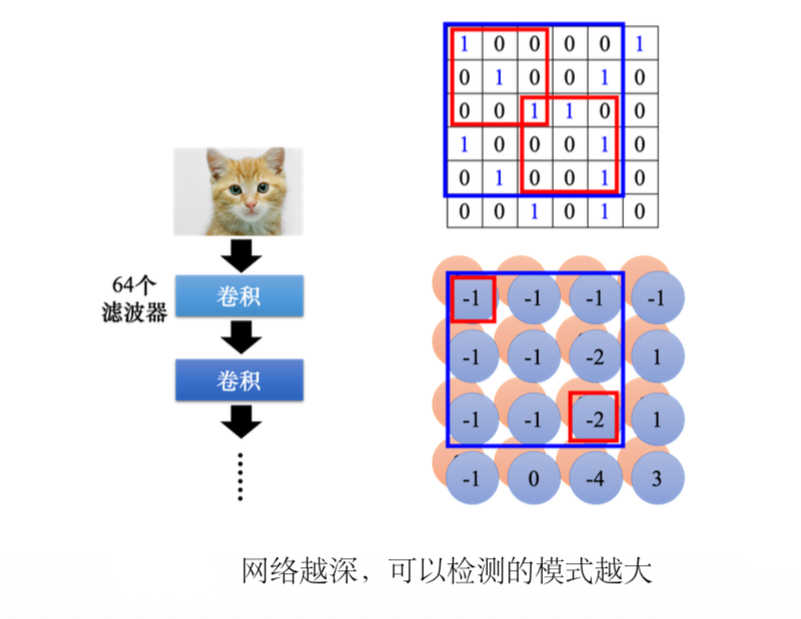
(3)总结:神经元是有bias的,滤波器也有bias。共用权重就是用滤波器扫过一张图片,这个过程就是卷积。把滤波器扫过图像就相当于不同的感受野神经元可以共用参数,这组公用的参数就叫做一个滤波器。
7、观察3
下采样不影响模式检测:把一张比较大的图像做下采样(Subsampling),把图像偶数的列都拿掉,奇数的行都拿掉,图像变成为原来的 1/4,但是不会影响里面是什么东西。
8、简化3
汇聚(Pooling):汇聚没有参数,所以它不是一个层,它里面没有权重,它没有要学习的东西,汇聚比较像 Sigmoid、ReLU 等激活函数。因为它里面是没有要学习的参数的,它就是一个操作符(operator),其行为都是固定好的,不需要根据数据学任何东西。
每个滤波器都产生一组数字,要做汇聚的时候,把这些数字分组,可以 2 × 2 个
一组,3 × 3、4 × 4 也可以,这个是我们自己决定的。汇聚有很多不同的版本,以最大汇聚(max pooling)为例。最大汇聚在每一组里面选一个代表,选的代表就是最大的一个。除了最大汇聚,还有平均汇聚 (mean pooling),平均汇聚是取每一组的平均值。
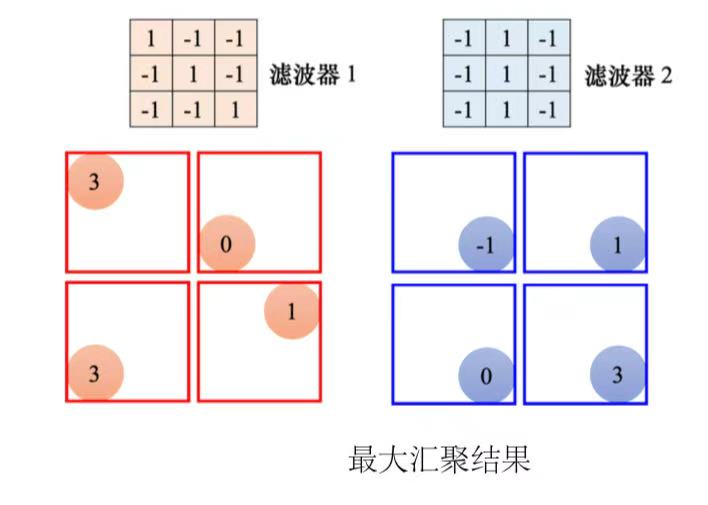
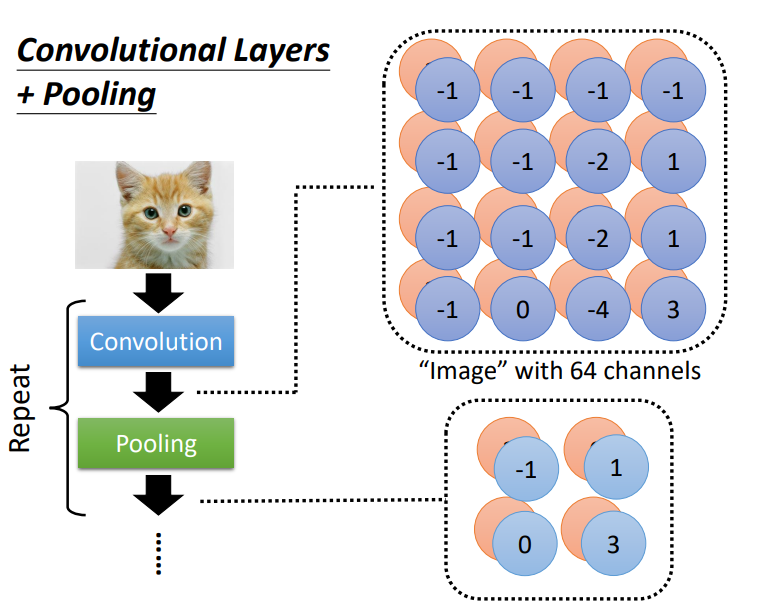
做完卷积以后,往往后面还会搭配pooling。pooling就是把图像变小。做完卷积以后会得到一
张图像,这张图像里面有很多的通道。做完pooling以后,这张图像的通道不变。一般实践中,卷积跟汇聚交替使用。
不过汇聚对于模型的性能(performance)可能会带来一点伤害。假设要检测的是非常微细的东西,随便做下采样,性能可能会稍微差一点。所以近年来图像的网络的设计往往也开始把汇聚丢掉,它会做那种全卷积的神经网络,整个网络里面都是卷积,完全都不用汇聚。
汇聚最主要的作用是减少运算量。通过下采样把图像变小,从而减少运算量。随着近年来运算能力越来越强,如果运算资源足够支撑不做汇聚,很多网络的架构的设计往往就不做汇聚,而是使用全卷积,卷积从头到尾看看做不做得起来,看看能不能做得更好。
如果做完几次卷积和汇聚以后,把汇聚的输出做扁平化(flatten),再把这个向量丢进全连接层里面,最终通过softmax来得到图像识别的结果。这就是一个经典的图像识别的网络,里面有卷积、汇聚和扁平化,最后再通过几个全连接层或sofmax来得到图像识别的结果。
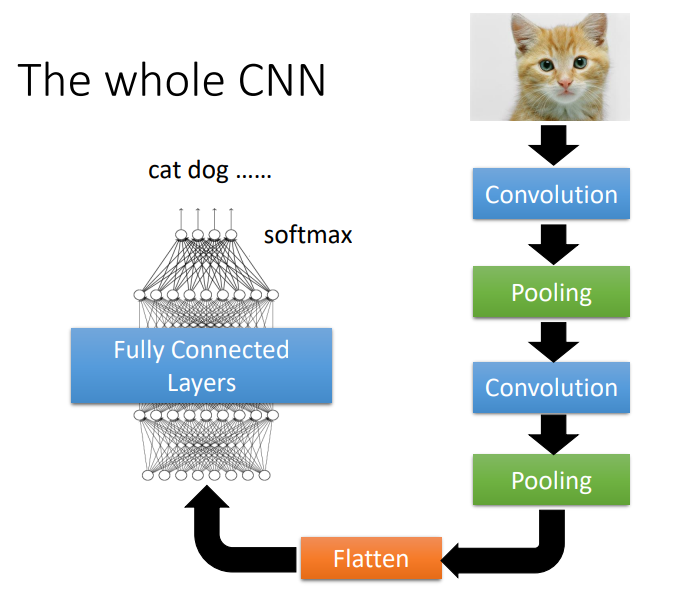
扁平化(flatten)就是把图像里面本来排成矩阵样子的东西"拉直",即把所有的数值"拉直"变成个向量。
9、练习
(1)数据集:https://www.kaggle.com/competitions/ml2023spring-hw3;
(2)说明:
-
torchvision.transforms
torchvision:专门用来处理图像;
transforms:提供一些常用的图像转换操作。 -
PIL:Python Image Library,图像处理标准库。
-
数据增强:防止出现过拟合。
-
数据归一化:在卷积层之后进行数据归一化处理,使得数据在Relu之前不会因数据过大而导致网络性能不稳定。
-
残差连接(Residual Connections):
解决梯度消失问题通过跳跃连接(skip connection),梯度可以直接从后面层传到前面层;
学习残差:模型学习的是 F(x) = H(x) - x,即目标函数与输入的差异;
简化优化:即使网络很深,也能有效训练;残差连接(skip connect)/(residual connections)-CSDN博客。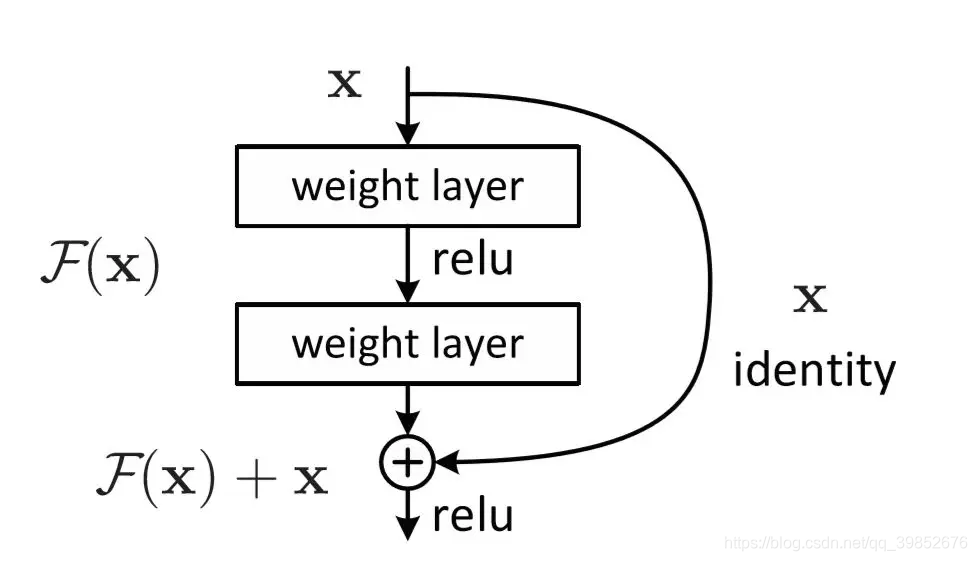
(3)代码:
python
import csv
import gc
import os.path
import numpy as np
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from PIL import Image
from torch.utils.data import DataLoader, Dataset
from tqdm.auto import tqdm
# 设置随机种子,确保实验结果可复现
def same_seeds(seed):
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
# 将图像统一裁剪成一样的大小,可以添加更多数据增强操作,最后将图像转为tensor
train_tfm = transforms.Compose([
# 将图像调整为固定形状(高度 = 宽度 = 128)
transforms.Resize((128, 128)),
# ToTensor() 最后一个变换
transforms.ToTensor(),
])
# 在测试和验证中不需要增强。只需要调整 PIL 图像大小并将其转换为 Tensor。
test_tfm = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
])
# DataSets
class FoodDataset(Dataset):
def __init__(self, path, tfm=test_tfm, files=None):
super(FoodDataset).__init__()
self.path = path
self.files = sorted([os.path.join(path, x) for x in os.listdir(path) if x.endswith(".jpg")])
if files is not None:
self.files = files
print(f"One {path} sample", self.files[0])
self.transform = tfm
def __len__(self):
return len(self.files)
def __getitem__(self, i):
fname = self.files[i]
img = Image.open(fname)
im = self.transform(img)
try:
# 从文件名中提取标签
label_str = fname.split("/")[-1].split("_")[0]
label = int(label_str)
# 确保标签在有效范围内
if label < 0 or label >= 11:
label = 0 # 默认类别
except:
label = 0 # 默认类别
return im, label
# 模型
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
# 卷积层(cnn_layers)和全连接层(fc_layers)
# 卷积层部分 (cnn_layers)
# 采用 nn.Sequential 顺序堆叠三层卷积块:
# input image size: [3, 128, 128]
# self.cnn_layers = nn.Sequential(
# # 3通道输入,64通道输出,3×3卷积核,步长1,填充1
# nn.Conv2d(3, 64, 3, 1, 1),
# # 批归一化
# nn.BatchNorm2d(64),
# # 激活函数
# nn.ReLU(),
# # 池化层, 2×2最大池化,步长2
# nn.MaxPool2d(2, 2, 0),
#
# # 64通道输入,128通道输出,3×3卷积核,步长1,填充1
# nn.Conv2d(64, 128, 3, 1, 1),
# nn.BatchNorm2d(128),
# nn.ReLU(),
# nn.MaxPool2d(2, 2, 0),
#
# # 128通道输入,256通道输出,3×3卷积核,步长1,填充1
# nn.Conv2d(128, 256, 3, 1, 1),
# nn.BatchNorm2d(256),
# nn.ReLU(),
# nn.MaxPool2d(4, 4, 0),
# )
# 使用残差块替换原有的卷积层
self.cnn_layers = nn.Sequential(
ResidualBlock(3, 64),
nn.MaxPool2d(2, 2, 0),
ResidualBlock(64, 128),
nn.MaxPool2d(2, 2, 0),
ResidualBlock(128, 256),
nn.MaxPool2d(4, 4, 0),
)
# 全连接层部分 (fc_layers), 输入维度: 256 * 8 * 8 (来自卷积层输出展平)
# 隐藏层: 两个256维的全连接层
# 输出层: 11个神经元,对应11类食物分类
self.fc_layers = nn.Sequential(
nn.Linear(256 * 8 * 8, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256, 11)
)
# 前向传播
# 输入图像经过 cnn_layers 提取特征
# 特征图通过 flatten(1) 展平为一维向量
# 展平后的特征送入 fc_layers 得到最终分类结果
def forward(self, x):
# input (x): [batch_size, 3, 128, 128]
# output: [batch_size, 11]
# 通过卷积层提取特征
x = self.cnn_layers(x)
# 提取的特征图在进入全连接层之前必须展平
x = x.flatten(1)
# 特征通过全连接层转换以获得最终的logits
x = self.fc_layers(x)
return x
# 残差块
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, 3, stride, 1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(out_channels, out_channels, 3, 1, 1)
self.bn2 = nn.BatchNorm2d(out_channels)
# 如果输入输出通道不一致,需要调整shortcut
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, stride),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
residual = self.shortcut(x)
out = self.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += residual
out = self.relu(out)
return out
# 设置每次训练时处理的样本数量为128
# 较大的批量大小有助于获得更稳定的梯度估计
# 需要根据GPU内存容量进行调整
batch_size = 128
# 构建数据集
train_set = FoodDataset("dataset/train", tfm=train_tfm)
valid_set = FoodDataset("dataset/valid", tfm=test_tfm)
test_set = FoodDataset("dataset/test", tfm=test_tfm)
# 构建数据加载器。
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=2, pin_memory=True)
valid_loader = DataLoader(valid_set, batch_size=batch_size, shuffle=True, num_workers=2, pin_memory=True)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
def trainer(train_set, valid_set, train_loader, val_loader, config, model, device):
"""
训练模型的主函数
Args:
train_set: 训练数据集
valid_set: 验证数据集
train_loader: 训练数据加载器
val_loader: 验证数据加载器
config: 配置参数
model: 模型实例
device: 计算设备
"""
# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=config['learning_rate'])
best_acc = 0.0
n_epochs = config['n_epoch']
for epoch in range(n_epochs):
train_acc = 0.0
train_loss = 0.0
model.train()
for i, batch in enumerate(tqdm(train_loader)):
features, labels = batch
features = features.to(device)
labels = labels.to(device)
# 过滤掉标签为-1的样本
mask = labels != -1
if not mask.any():
continue
features = features[mask]
labels = labels[mask]
optimizer.zero_grad()
outputs = model(features)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, train_pred = torch.max(outputs, dim=1)
train_acc += (train_pred.detach() == labels.detach()).sum().item()
train_loss += loss.item()
# 验证阶段
if len(valid_set) > 0:
val_acc = 0.0
val_loss = 0.0
model.eval()
with torch.no_grad():
for i, batch in enumerate(tqdm(val_loader)):
features, labels = batch
features = features.to(device)
labels = labels.to(device)
outputs = model(features)
loss = criterion(outputs, labels)
_, val_pred = torch.max(outputs, dim=1)
val_acc += (val_pred.cpu() == labels.cpu()).sum().item()
val_loss += loss.item()
print(
'[Epoch {:03d}/{:03d}] train_loss: {:.4f}, train_acc: {:.3f}, val_loss: {:.4f}, val_acc: {:.3f}'.format(
epoch + 1, n_epochs,
train_loss / len(train_loader), train_acc / len(train_set),
val_loss / len(val_loader), val_acc / len(valid_set)))
# 保存最优模型
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), config['model_path'])
print('saving model with acc {:.3f}'.format(best_acc))
else:
print('[Epoch {:03d}/{:03d}] train_loss: {:.4f}, train_acc: {:.3f}'.format(
epoch + 1, n_epochs,
train_loss / len(train_loader), train_acc / len(train_set)))
if len(valid_set) == 0:
torch.save(model.state_dict(), config['model_path'])
print('saving model with acc {:.3f}'.format(best_acc))
del train_loader, val_loader
gc.collect()
return
def predict(model, test_loader):
"""
对测试集进行预测
Args:
model: 训练好的模型
test_loader: 测试数据加载器
Returns:
预测结果数组
"""
pred = np.array([], dtype=np.int32)
model.eval()
with torch.no_grad():
for i, batch in enumerate(tqdm(test_loader)):
features = batch
features = features.to(device)
outputs = model(features)
_, test_pred = torch.max(outputs, dim=1)
pred = np.concatenate((pred, test_pred.cpu().numpy()), axis=0)
return pred
def save_pred(preds, file):
"""
保存预测结果到CSV文件
Args:
preds: 预测结果
file: 输出文件路径
"""
with open(file, 'w') as fp:
writer = csv.writer(fp)
writer.writerow(['Id', 'Class'])
for i, p in enumerate(preds):
writer.writerow([i, p])
# 配置参数
config = {
'seed': 0,
'batch_size': 512,
'n_epoch': 5,
'learning_rate': 1e-4,
'model_path': './model.ckpt'
}
if __name__ == '__main__':
import multiprocessing as mp
mp.freeze_support()
# 实例化模型并移至设备
model = Classifier().to(device)
# 训练
trainer(train_set, valid_set, train_loader, valid_loader, config, model, device)
# 预测
preds = predict(model, test_loader)
save_pred(preds, 'prediction.csv')二、自注意力机制(Self-attention)
1、输入是向量序列的情况
(1)文字处理:假设网络输入的是一个句子,每个句子的长度都不一样,如果把一个句子里面的词汇都描述成一个向量,用向量来表示,模型的输入就是一个向量序列,而且该向量序列的大小每次都不一样(句子长度决定)。
将词汇表示成向量的方法:
- One-hot Encoding:创建一个很长的向量,该向量的长度跟世界上存在的词汇的数量一样多。之间没有语义信息。
- Word Embedding:使用一个向量来表示一个词汇,而这个向量是包含语义信息的。
(2)声音信号:一个声音信号就是用一串向量来表示的。
(3)图(graph):社交网络是一个图,每一个节点就是一个人,可以看作是一个向量,里面有每个人的简介。所以图可以看做一堆向量所组成。
2、输出的情况
(1)输入与输出数量相同:每一个向量都有一个对应的标签。例如:词性标注(POS tagging),机器会自动决定每一个词汇的词性。
(2)输入是一个序列,输出是一个标签:整个序列只需要输出一个标签就好。例如:情感分析,给机器看一段话,要模型决定说这段话是积极的还是消极的。
(3)序列到序列:机器自己决定输出多少个标签。例如:翻译,语音识别输入。
3、自注意力的运作原理
(1)序列标注(sequence labeling):给序列里面的每一个向量一个标签。虽然输入是一个序列,但可以不要管它是不是一个序列,各个击破,把每一个向量分别输入到全连接网络里面得到输出。
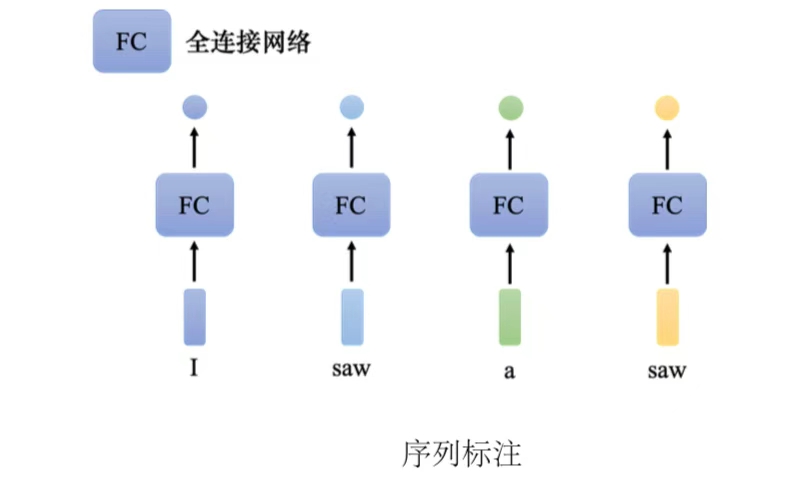
要让全连接网络考虑更多的信息,比如上下文信息。把每个向量的前后几个向量都"串"起来,一起输入到全连接网络。
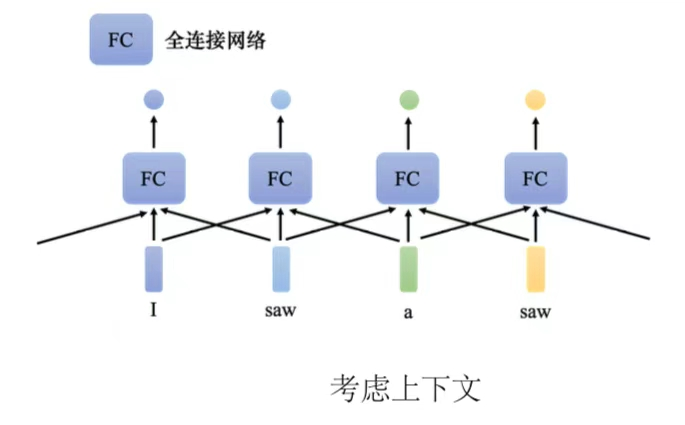
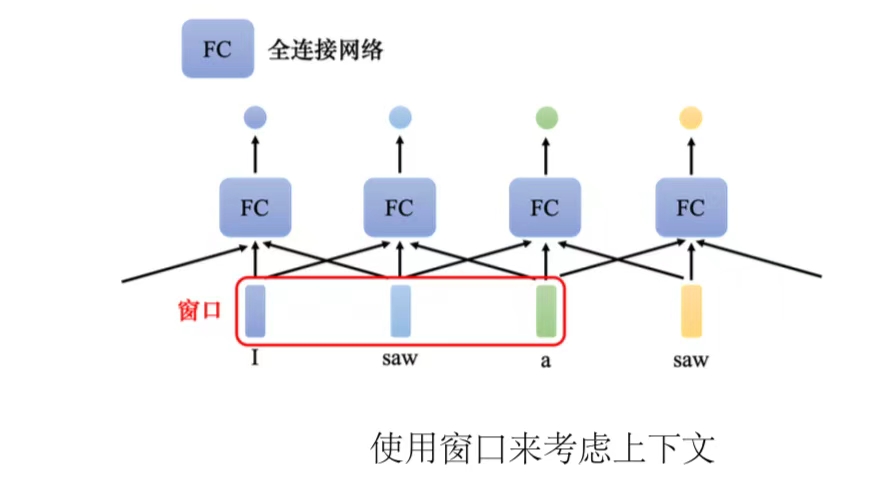
但是这种的方法还是有限制的,比如说如果某一个任务不是考虑一个窗口就可以解决的,而是要考虑一整个序列。
(2)自注意力模型:自注意力模型会"吃"整个序列的数据,输入几个向量,它就输出几个向量。得到的考虑了整个句子的向量丢进全连接网络,再得到输出。因此全连接网络不是只考虑一个非常小的范围或一个小的窗口,而是考虑整个序列的信息,再来决定现在应该要输出什么样的结果。
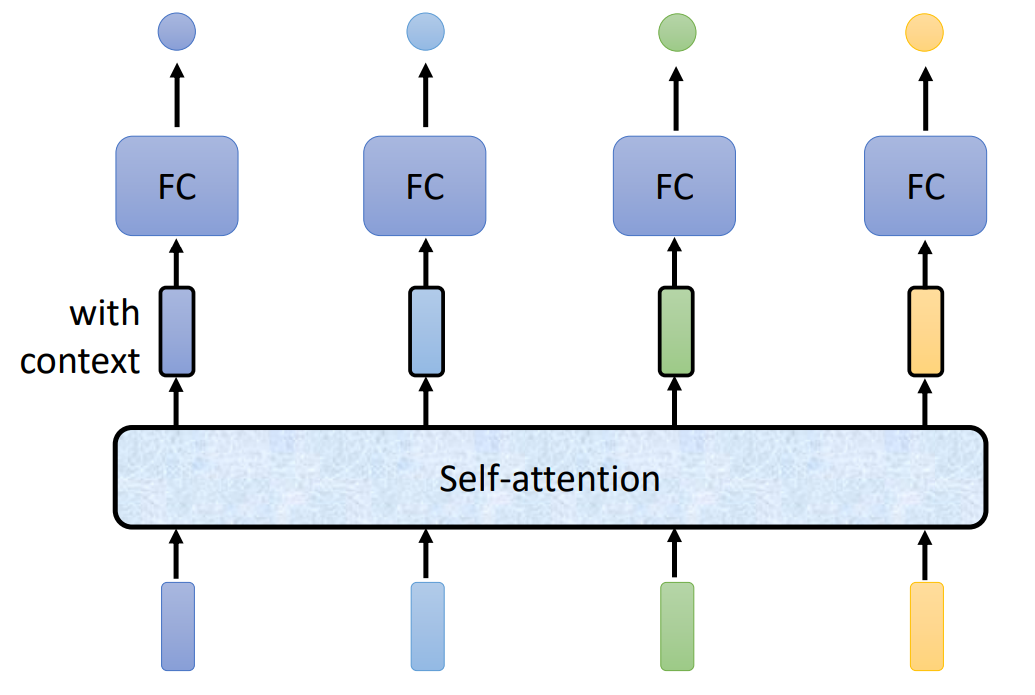
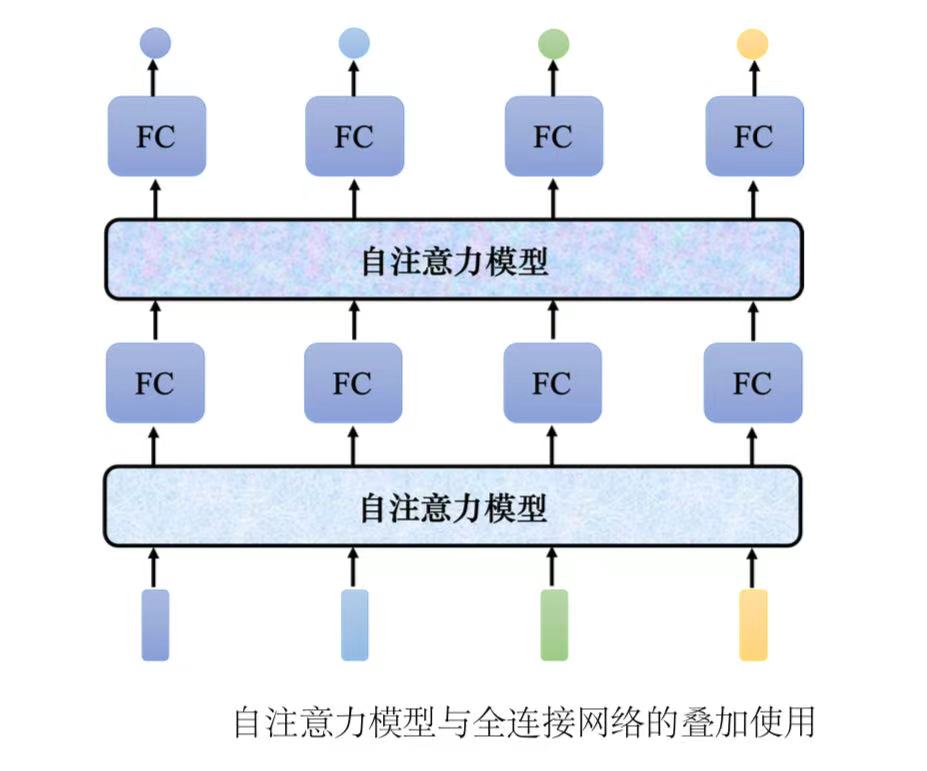
自注意力模型不是只能用一次,可以叠加很多次。全连接网络和自注意力模型可以交替使用。全连接网络专注于处理某一个位置的信息,自注意力把整个序列信息再处理一次
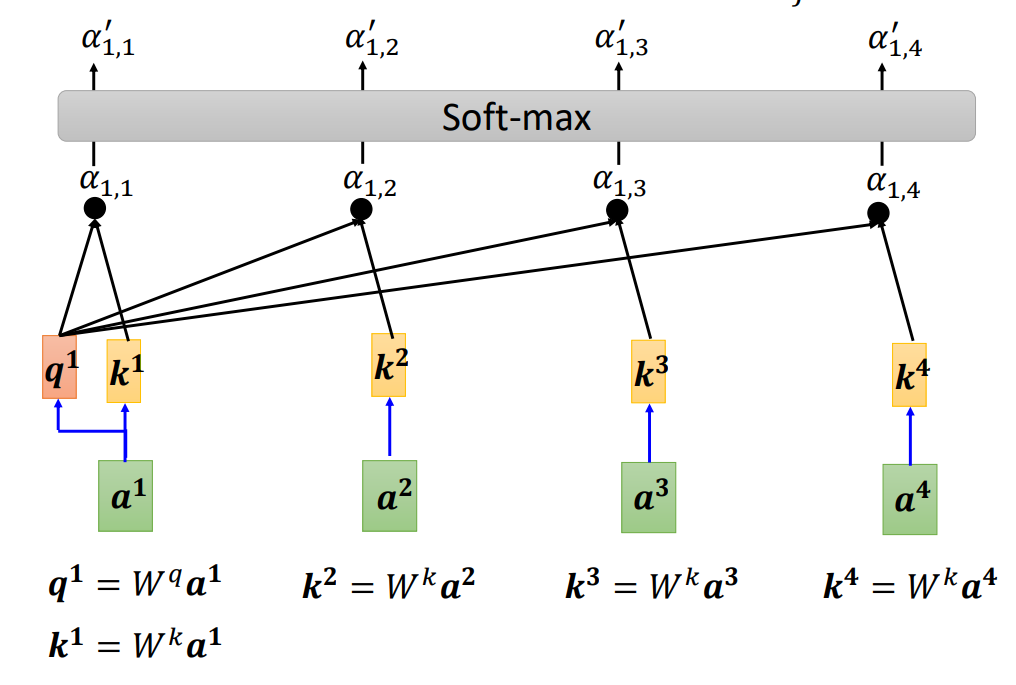
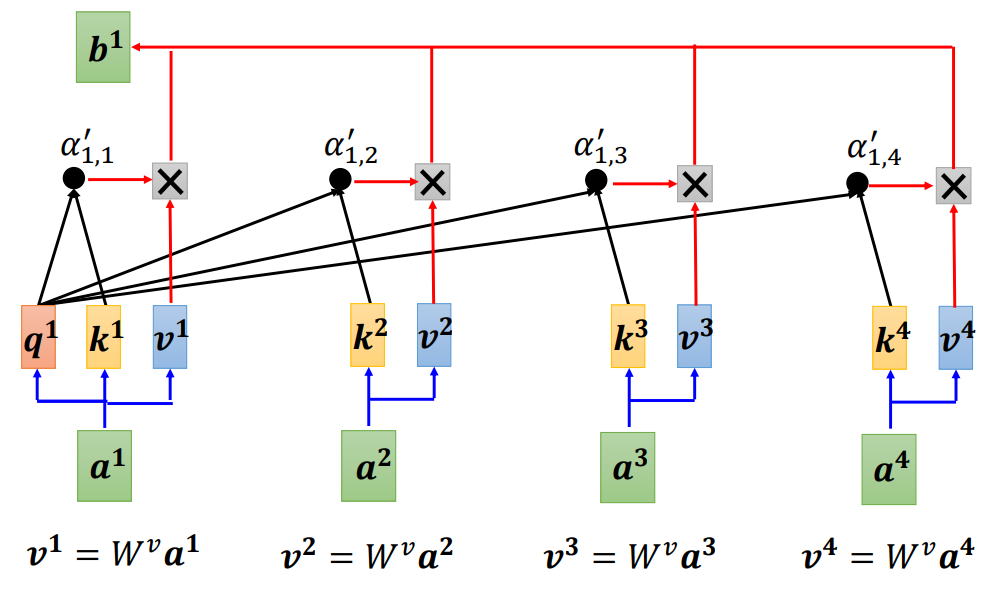
(3)自注意力模型运作过程
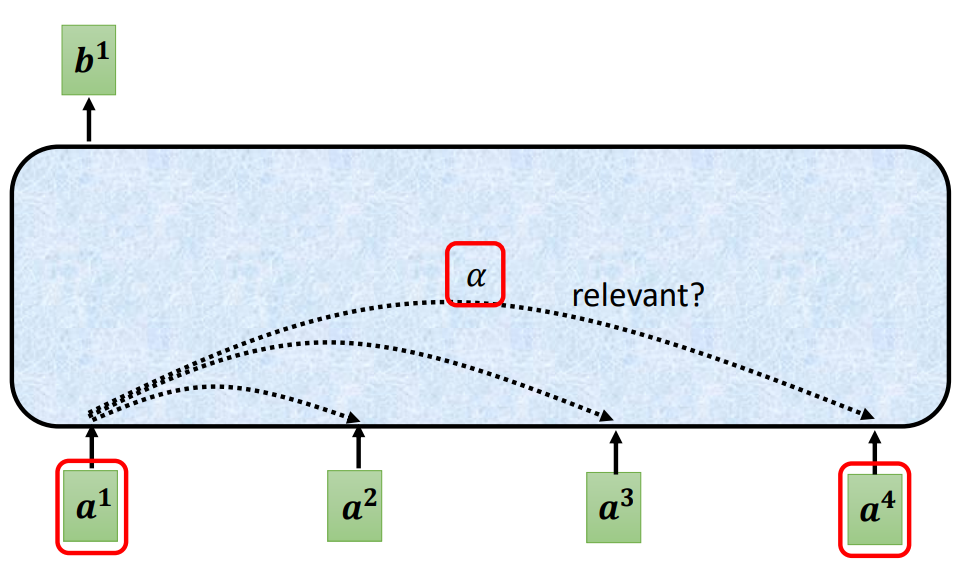
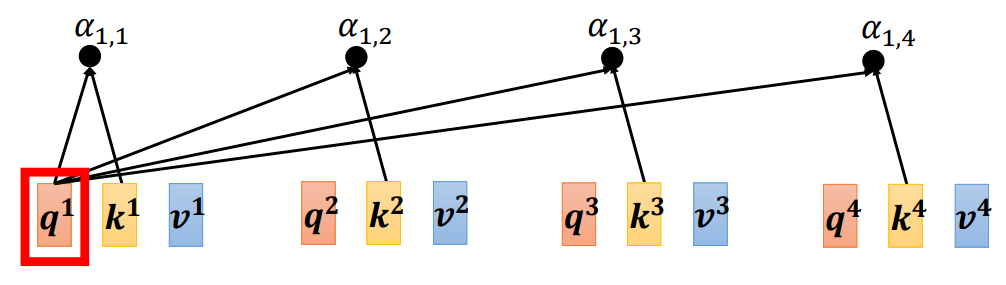
输入是一串向量,这个向量可能是整个网络的输入,也可能是某个隐藏层的输出,用a 来表示。输入一组向量a ,自注意力要输出一组向量b ,每个b 都是考虑了所有的a以后才生成出来的。
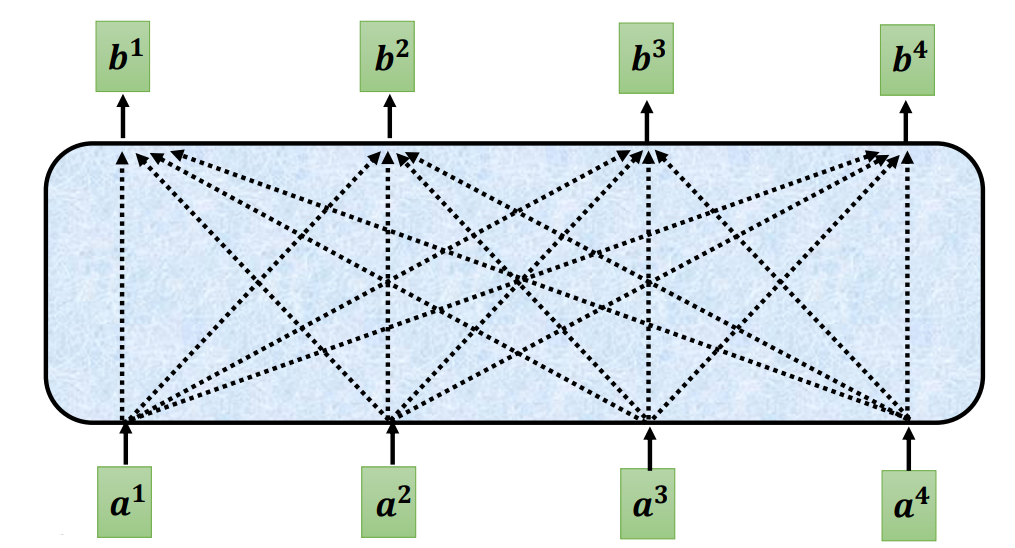
向量b 如何生成,以其中一个
为例:
根据
自注意力的目的是考虑整个序列,但是又不希望把整个序列所有的信息包在一个窗口里面。所以有一个特别的机制,这个机制是根据向量
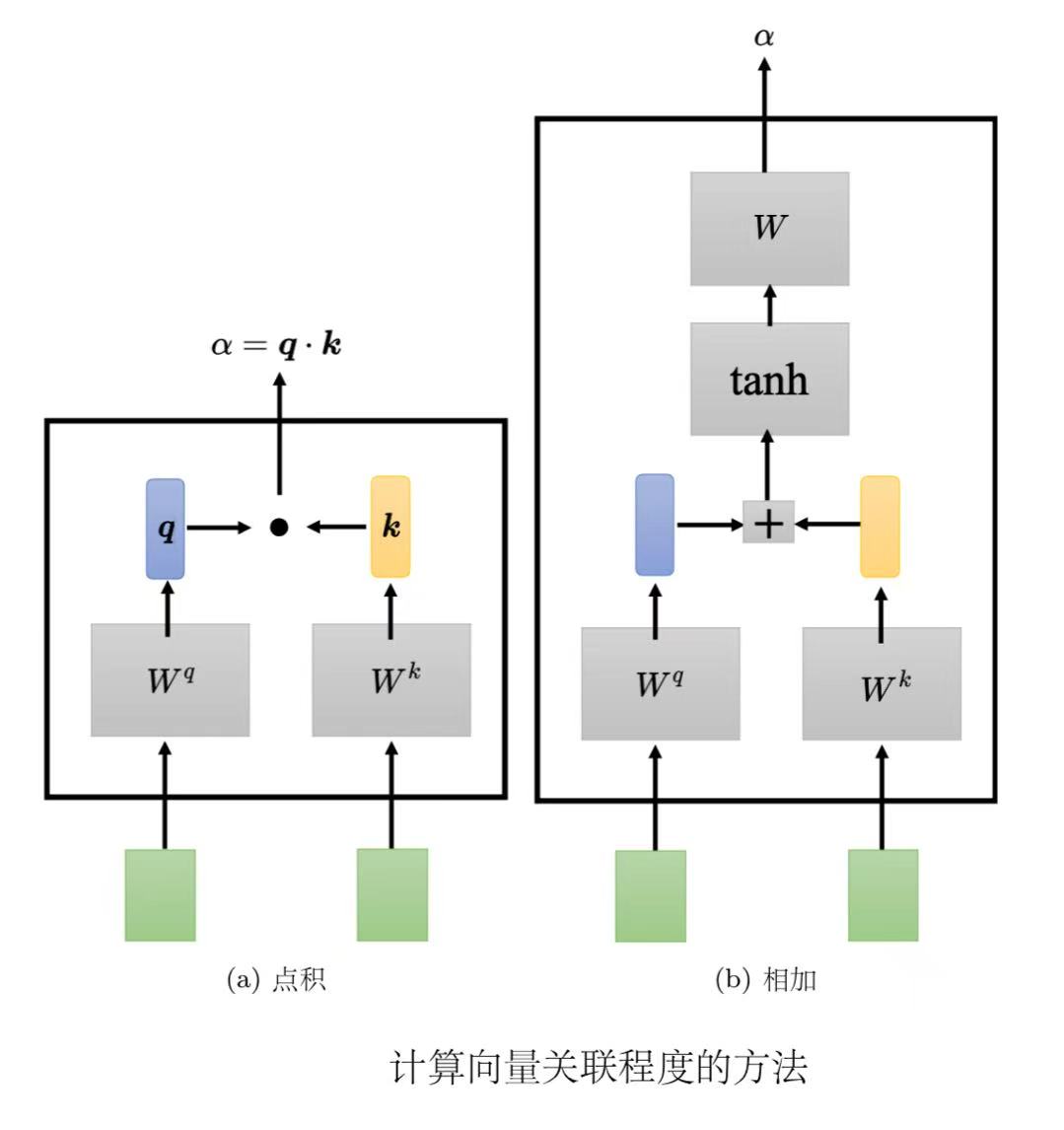
(1)点积(dot product):把输入的两个向量分别乘上两个不同的矩阵,左边这个向量乘上矩阵
(2)相加(additive):把两个向量通过分别计算分别计算
一般在实践的时候,对所有的关联性做一个softmax操作,把α全部取e的指数,再把指数的值全部加起来做归一化(normalize)得到
不一定要用softmax,也可以用其他激活函数,比如ReLU。
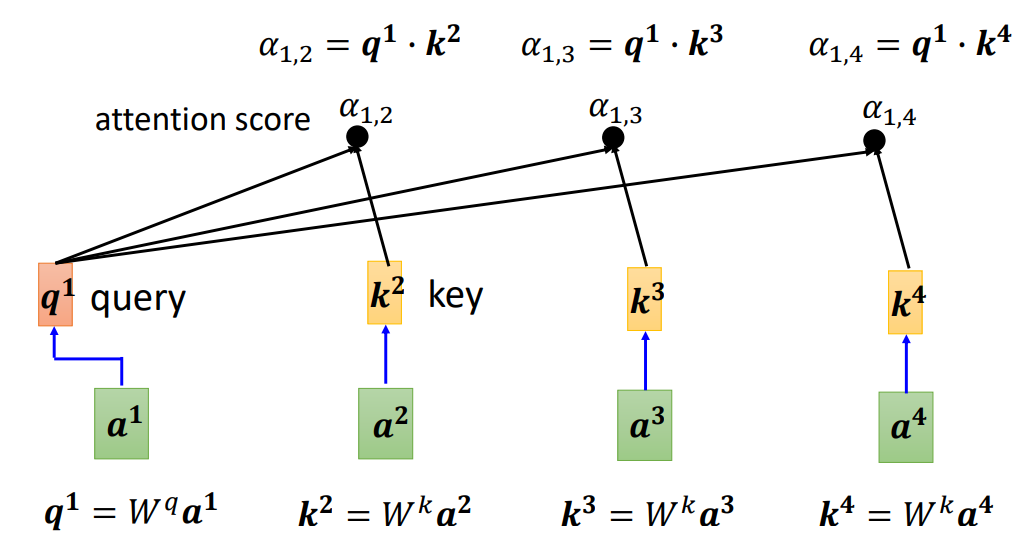
根据
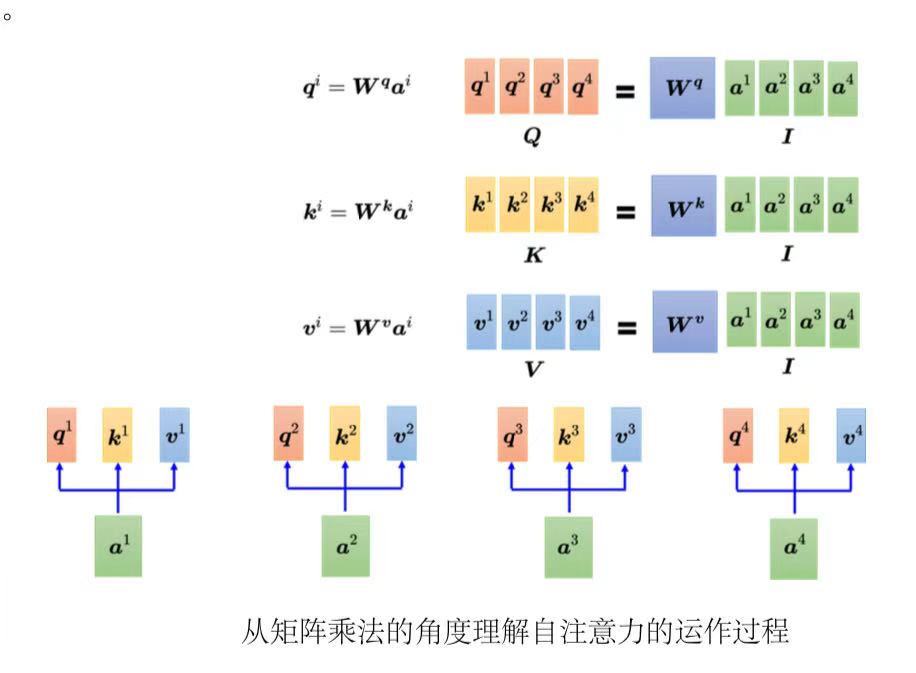
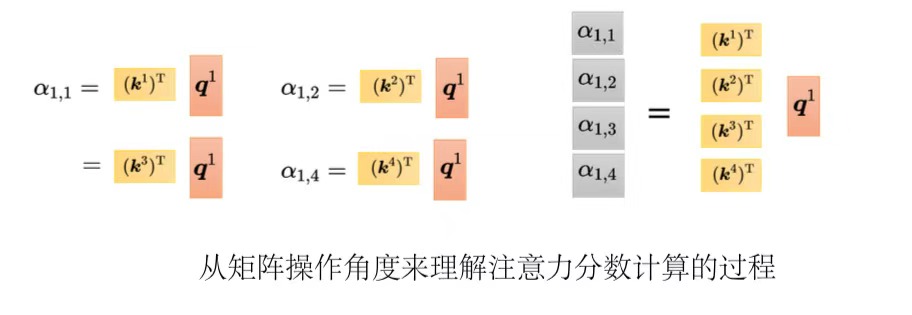
如果从矩阵乘法的角度解释自注意力的运作过程:
输入序列矩阵I,有四列,即
每一个q 都会去跟每一个k 去计算内积,得到注意力的分数。把k 所形成的矩阵
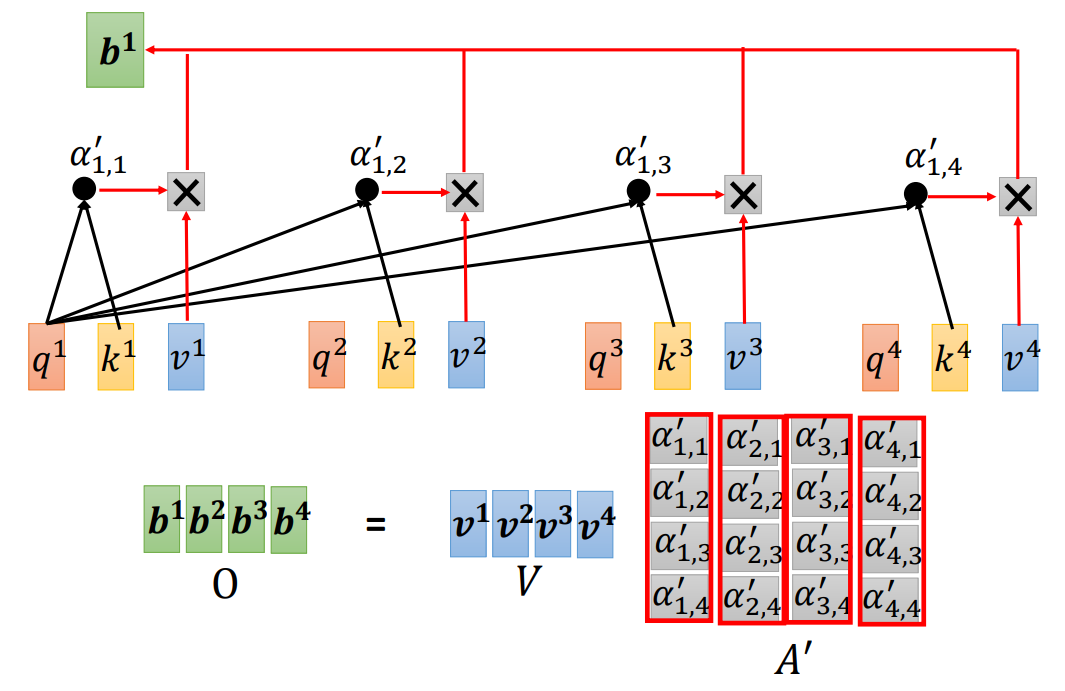
对注意力分数做归一化(normalization),比如使用softmax(最终得到的矩阵每一列相加是1),得到注意力矩阵(attention matrix)A' 。
把所有v 形成一个矩阵V ,乘上A' 得到注意力b 形成的矩阵O 。
总结:自注意力的输入是一组向量,将这排向量拼起来得到矩阵I,分别乘上三个矩阵:
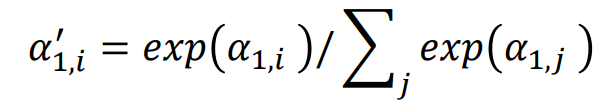
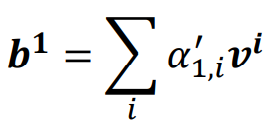

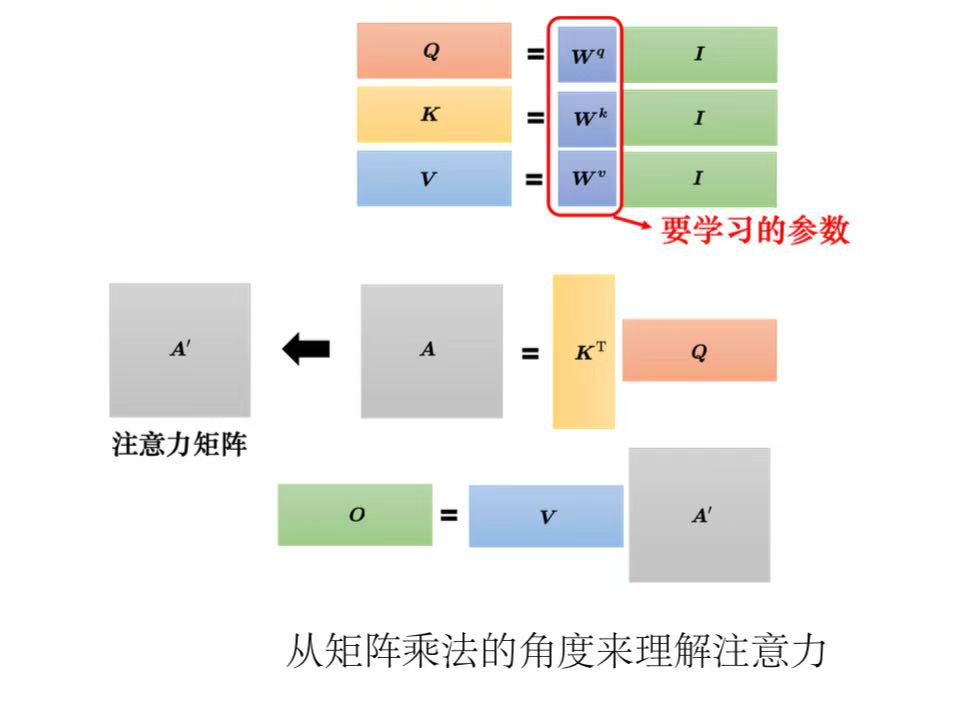
4、多头注意力
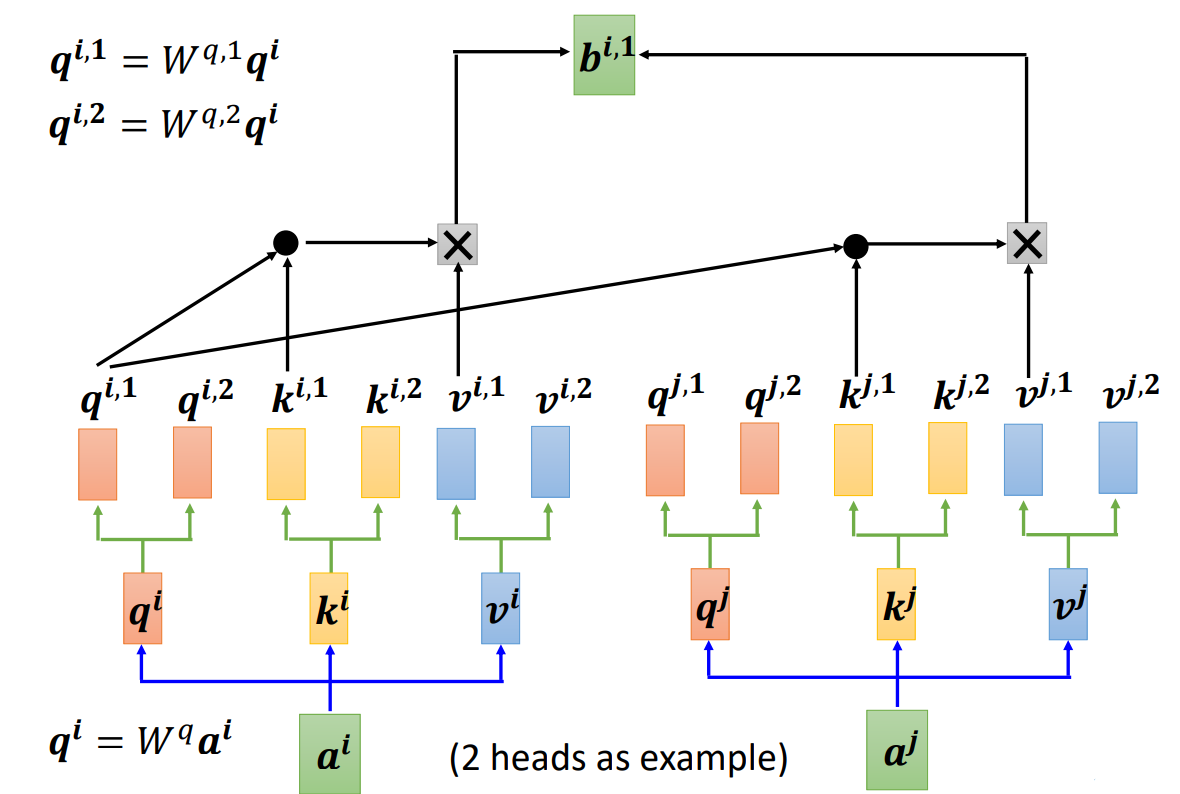
多头自注意力(Multi-head self-attention):通过并行计算多组注意力权重,捕获输入序列中不同位置的多样化依赖关系。其核心思想是将输入序列投影到多个子空间,分别计算注意力后合并结果。(需要几个头是一个超参数,需要调)
在使用自注意力计算相关性的时候,就是用q去找相关的k。但是相关有很多种不同的形式,所以也许可以有多个q,不同的q负责不同种类的相关性,这就是多头注意力。
先把a乘上一个矩阵得到q,接下来再把q乘上另外两个矩阵,分别得到、
。用两个上标
跟
代表有两个头,i 代表的是位置,1跟2代表是这个位置的第几个 q,这个问题里面有两种不同的相关性,所以需要产生两种不同的头来找两种不同的相关性。既然q有两个,k也就要有两个,v也就要有两个。就是把 q、k、v分别乘上两个矩阵,得到不同的头。对另外一个位置也做一样的事情,另外一个位置在输入a以后,它也会得到两个 q、两个 k、两个 v。接下来做自注意力,跟之前的操作是一模一样的,只是现在1那一类的一起做,2那一类的一起做。也就是
在算这个注意力的分数的时候,就不要管
了它就只管
就好。
分别与
、
算注意力,在做加权和的时候也不要管
了,看
跟
, 就好,把注意力的分数乘
和
,再相加得到
,这边只用了其中一个头。
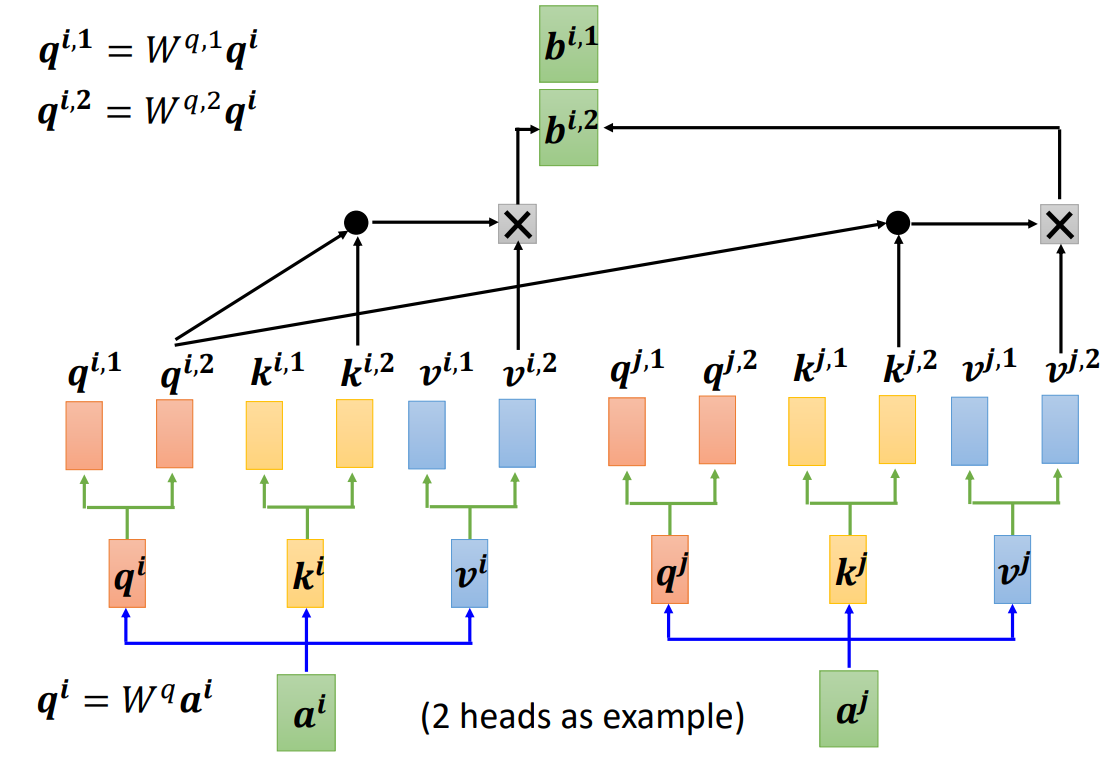
可以使用另外一个头做相同的事情。只对
做注意力,在做加权和的时候,只对
做加权和得到
。如果有多个头,操作相同。
得到跟
,可能会把
跟
接起来,再通过一个变换,即再乘上一个矩阵然后得到
,再送到下一层去。
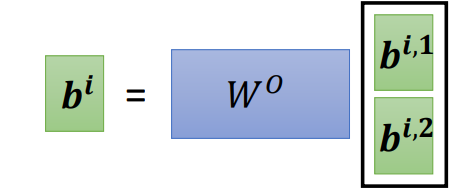
5、位置编码
对一个自注意力层而言,每一个输入是出现在序列的最前面还是最后面,它是完全没有信息的,即位置信息被忽略了。当位置信息很重要的时候,我们就要用到位置编码(positional encoding),即为每一个位置设定一个向量(位置向量),用来表示,上表i代表位置,不同位置就有不同向量,不同位置都有一个专属的e,如果看到
被加上
,它就知道现在出现的位置应该是在i这个位置。
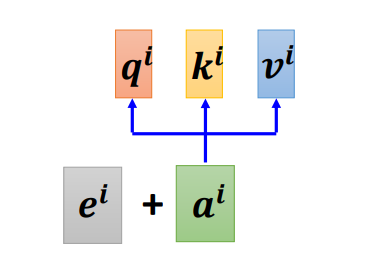
6、截断自注意力
截断自注意力(Truncated Self-attention)可以处理向量序列长度过大的问题。截断自注意力在做自注意力的时候不要看一整句话,就只看一个小的范围就好,这个范围是人设定的。如在做语音识别的时候,如果要辨识某个位置有什么样的音标,这个位置有什么样的内容,并不需要看整句话,只要看这句话以及它前后一定范围之内的信息,就可以判断。在做自注意力的时候,也许没有必要让自注意力考虑一整个句子,只需要考虑一个小范围就好,这样就可以加快运算的速度。
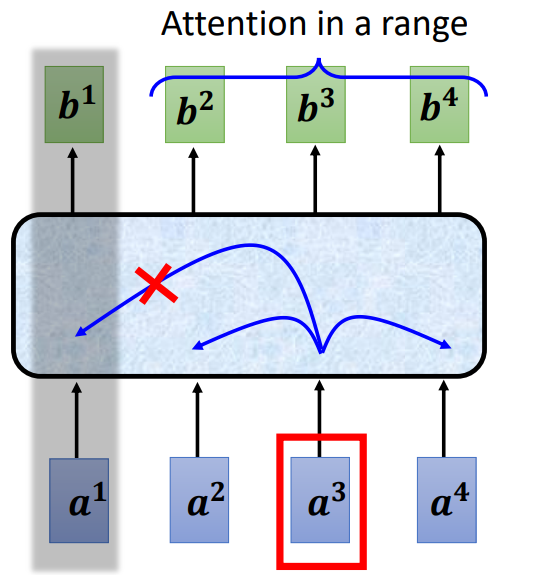
7、自注意力与CNN对比
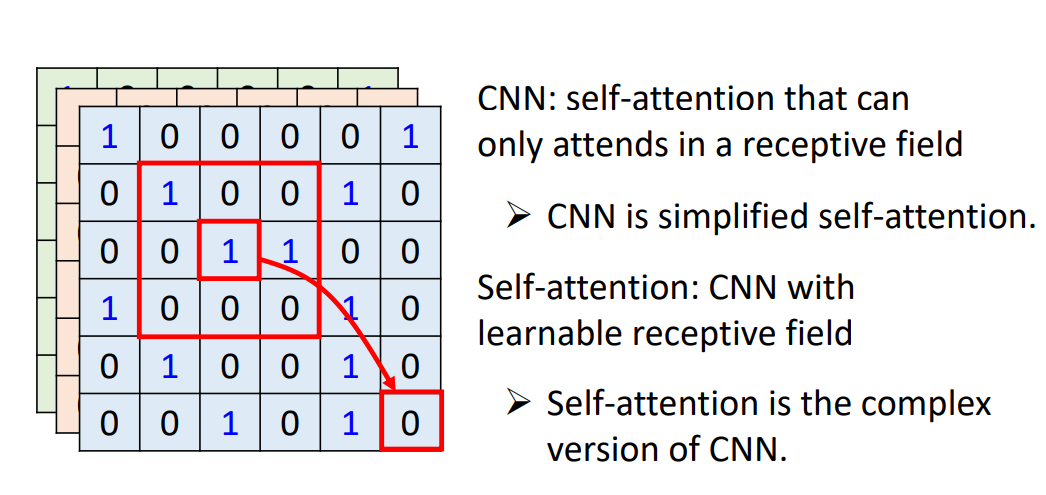
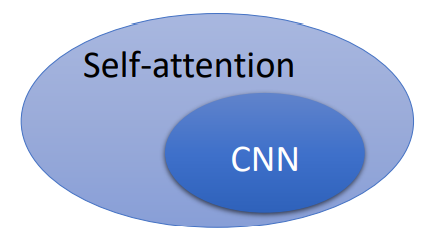
自注意力只要设定合适的参数,就可以做到跟卷积神经网络一模一样的事情。所以自注意力是更灵活的卷积神经网络,而卷积神经网络是受限制的自注意力。
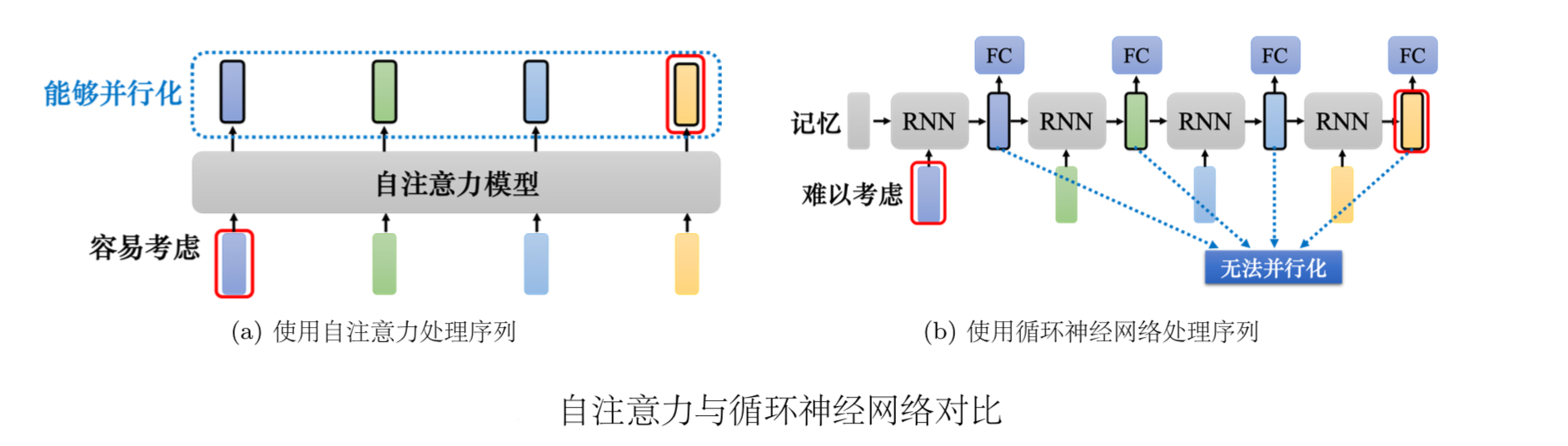
8、自注意力与RNN对比
自注意力跟循环神经网络有一个显而易见的不同,自注意力的每一个向量都考虑了整个输入的序列,而循环神经网络的每一个向量只考虑了左边已经输入的向量,它没有考虑右边的向量。但循环神经网络也可以是双向的,所以如果用双向循环神经网络(Bidirectional RecurrentNeural Network,Bi-RNN),那么每一个隐状态的输出也可以看作是考虑了整个输入的序列。
但是假设把循环神经网络的输出跟自注意力的输出拿来做对比,就算使用双向循环神经网络还是有一些差别的。对于循环神经网络,如果最右边黄色的向量要考虑最左边的输入,它就必须把最左边的输入存在记忆里面,才能不"忘掉",一路带到最右边,才能够在最后一个时间点被考虑。但自注意力输出一个查询,输出一个键,只要它们匹配(match)起来,"天涯若比邻"。自注意力可以轻易地从整个序列上非常远的向量抽取信息。
自注意力跟循环神经网络还有另外一个更主要的不同是,循环神经网络在处理输入、输出均为一组序列的时候,是没有办法并行化的。比如计算第二个输出的向量,不仅需要第二个输入的向量,还需要前一个时间点的输出向量。当输入是一组向量,输出是另一组向量的时候,循环神经网络无法并行处理所有的输出,但自注意力可以。自注意力输入一组向量,输出的时候,每一个向量是同时并行产生的,因此在运算速度上,自注意力会比循环神经网络更有效率。
9、Self-attention for Graph
图也可以看作是一堆向量,如果是一堆向量,就可以用自注意力来处理。图中的每一个节点(node)可以表示成一个向量。但我们不只有节点的信息,还有边(edge)的信息。如果节点之间是有相连的,这些节点也就是有关联的。之前在做自注意力的时候,所谓的关联性是网络自己找出来的。但是现在有了图的信息,关联性就不需要机器自动找出来,图上面的边已经暗示了节点跟节点之间的关联性。所以当把自注意力用在图上面的时候,我们可以在计算注意力矩阵的时候,只计算有边相连的节点就好。
注:如果两个节点之间没有相连,这两个节点之间就没有关系。既然没有关系,就不需要再去计算它的注意力分数,直接把它设为0。
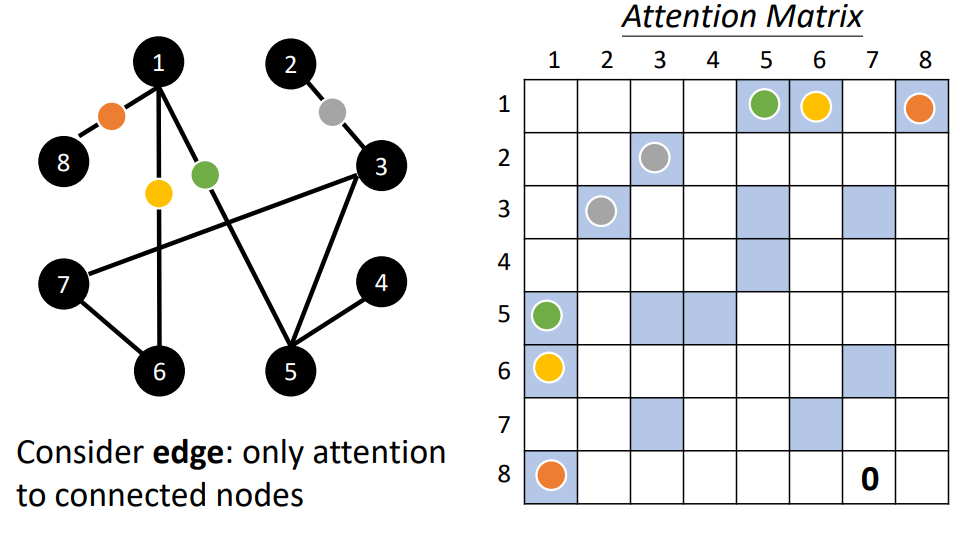
当把自注意力按照这种限制用在图上面的时候,其实就是一种图神经网络(Graph Neural Network,GNN)。
10、练习
(1)数据集:https://www.kaggle.com/competitions/ml2021spring-hw4/data;
(2)说明:
- JSON:JavaScript Object Notation,一种轻量级数据交换格式,json包用于读取json文件;
- pad_sequence:填充数据到相同长度;
- LambdaLR 是 PyTorch 中的一个学习率调度器类,用于自定义学习率调整策略。LambdaLR
主要特点:
自定义调度函数:允许用户通过 lr_lambda 函数来自定义学习率变化规律;
灵活控制:可以根据训练步数、epoch 数或其他条件动态调整学习率;
与优化器配合:直接作用于优化器对象,修改其学习率参数;
工作原理:
用户提供一个 lr_lambda 函数,该函数接收当前训练步数作为输入,LambdaLR 在每次调用 step() 时计算新的学习率,将计算得到的学习率应用到关联的 optimizer 上。
(3)代码:
python
import csv
import math
import os
import json
import numpy as np
import torch
import random
from pathlib import Path
from torch import nn
from torch.optim import Optimizer, AdamW
from torch.optim.lr_scheduler import LambdaLR
from torch.utils.data import Dataset, random_split, DataLoader
from torch.nn.utils.rnn import pad_sequence
from tqdm import tqdm
def same_seeds(seed):
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
'''
数据集说明:
metadata.json:
n_mels:梅尔频谱图的维度,表示每帧语音数据的特征维度
speakers:说话人信息,包含了多个说话人,每个说话人对应一组语音 utterance(话语)
feature_path:语音特征文件的路径(通常是 .pt 文件,即 PyTorch 的张量文件)
mel_len:该语音 utterance 的梅尔频谱图帧数。
testdata.json:
n_mels: 梅尔频谱图的维度
utterances: 包含多个语音片段的信息列表
feature_path: 语音特征文件的路径
mel_len: 梅尔频谱图的时间长度(帧数)
mapping.json:
speaker2id: 将字符串形式的说话人ID(如 id10001)映射到整数索引(从0开始)
d2speaker: speaker2id 的反向映射,将整数索引映射回说话人ID
'''
class myDataset(Dataset):
def __init__(self, data_dir, segment_len=128):
self.data_dir = data_dir
self.segment_len = segment_len
# 加载说话人映射关系,speaker2id 将说话人名称映射到数字索引
mapping_path = Path(data_dir) / "mapping.json"
mapping = json.load(mapping_path.open())
self.speaker2id = mapping["speaker2id"]
# 加载元数据,从 metadata.json 加载说话人及其语音片段信息
metadata_path = Path(data_dir) / "metadata.json"
metadata = json.load(open(metadata_path))["speakers"]
# 遍历所有说话人和他们的语音片段,构建数据列表
self.speaker_num = len(metadata.keys())
self.data = []
for speaker in metadata.keys():
for utterances in metadata[speaker]:
self.data.append([utterances["feature_path"], self.speaker2id[speaker]])
def __len__(self):
return len(self.data)
def __getitem__(self, index):
# 根据索引获取数据项
feat_path, speaker = self.data[index]
# 使用 torch.load 加载预处理好的梅尔频谱图特征
mel = torch.load(os.path.join(self.data_dir, feat_path))
# 如果语音长度超过设定的 segment_len,则随机截取一段
# 否则使用整个语音片段
if len(mel) > self.segment_len:
start = random.randint(0, len(mel) - self.segment_len)
mel = torch.FloatTensor(mel[start:start + self.segment_len])
else:
mel = torch.FloatTensor(mel)
# 将说话人ID转换为长整型张量,便于后续损失计算
speaker = torch.FloatTensor([speaker]).long()
return mel, speaker
# 提供获取说话人总数的接口
def get_speaker_number(self):
return self.speaker_num
# 批处理函数,用于处理从 myDataset 中取出的一个批次数据,主要解决不同长度序列的批处理问题。
def collate_batch(batch):
# 将传入的 batch(包含多个 (mel, speaker) 元组)解包
# 分别提取所有梅尔频谱图到 mel,所有说话人标签到 speaker
mel, speaker = zip(*batch)
# 使用 pad_sequence 对同一批次中的不同长度梅尔频谱图进行填充
# batch_first=True:输出张量格式为 (batch_size, sequence_length, feature_dim)
# padding_value=-20:用-20填充,这在对数域中代表极小值(log 10^(-20))
mel = pad_sequence(mel, batch_first=True, padding_value=-20) # pad log 10^(-20) which is very small value.
# mel: (batch size, length, 40)
# 将说话人标签转换为长整型张量,确保标签格式适合后续的损失函数计算
return mel, torch.FloatTensor(speaker).long()
def get_dataloader(data_dir, batch_size, n_workers):
"""Generate dataloader"""
dataset = myDataset(data_dir)
speaker_num = dataset.get_speaker_number()
# Split dataset into training dataset and validation dataset
trainlen = int(0.9 * len(dataset))
lengths = [trainlen, len(dataset) - trainlen]
trainset, validset = random_split(dataset, lengths)
train_loader = DataLoader(
trainset,
batch_size=batch_size,
shuffle=True,
drop_last=True,
num_workers=n_workers,
pin_memory=True,
collate_fn=collate_batch,
)
valid_loader = DataLoader(
validset,
batch_size=batch_size,
num_workers=n_workers,
drop_last=True,
pin_memory=True,
collate_fn=collate_batch,
)
return train_loader, valid_loader, speaker_num
class Classifier(nn.Module):
def __init__(self, d_model=80, n_spks=600, dropout=0.1):
super().__init__()
# 将输入的40维梅尔频谱图特征投影到 d_model 维度
self.prenet = nn.Linear(40, d_model)
# Transformer编码器层
# nhead=2: 注意力头数为2
# dim_feedforward=256: 前馈网络的隐藏层维度
self.encoder_layer = nn.TransformerEncoderLayer(
d_model=d_model, dim_feedforward=256, nhead=2
)
# self.encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=2)
# 两层全连接网络,最终输出说话人分类概率
self.pred_layer = nn.Sequential(
nn.Linear(d_model, d_model),
nn.ReLU(),
nn.Linear(d_model, n_spks),
)
# 前向传播过程
def forward(self, mels):
# 特征投影: 将40维特征映射到 d_model 维
out = self.prenet(mels)
# 维度调整: 转换为Transformer期望的 (length, batch, d_model) 格式
out = out.permute(1, 0, 2)
# Transformer编码: 应用Transformer编码
out = self.encoder_layer(out)
# 恢复维度: 转换回 (batch, length, d_model) 格式
out = out.transpose(0, 1)
# 池化操作: 对时间维度进行平均池化
stats = out.mean(dim=1)
# 分类预测: 生成最终的说话人分类结果
out = self.pred_layer(stats)
return out
# 学习率调度器,用于在训练过程中动态调整优化器的学习率。
# 学习率预热(Warmup): 训练初期线性增加学习率,避免模型初始阶段不稳定
# 余弦退火(Cosine Annealing): 预热后按余弦函数逐渐降低学习率至0
def get_cosine_schedule_with_warmup(
optimizer: Optimizer,
num_warmup_steps: int,
num_training_steps: int,
num_cycles: float = 0.5,
last_epoch: int = -1,
):
"""
Args:
optimizer (:class:`~torch.optim.Optimizer`):
优化器对象,将应用学习率调度
num_warmup_steps (:obj:`int`):
预热阶段的步数
num_training_steps (:obj:`int`):
总训练步数
num_cycles (:obj:`float`, `optional`, defaults to 0.5):
余弦波周期数,默认0.5(半个周期,从最大值降到0)
last_epoch (:obj:`int`, `optional`, defaults to -1):
恢复训练时的上一个epoch索引
Return:
:obj:`torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
"""
def lr_lambda(current_step):
# 预热阶段: 线性增长,学习率从0线性增长到初始设定值
if current_step < num_warmup_steps:
return float(current_step) / float(max(1, num_warmup_steps))
# 退火阶段: 余弦衰减,按照余弦函数规律逐渐降低学习率
progress = float(current_step - num_warmup_steps) / float(
max(1, num_training_steps - num_warmup_steps)
)
return max(
0.0, 0.5 * (1.0 + math.cos(math.pi * float(num_cycles) * 2.0 * progress))
)
# LambdaLR 是 PyTorch 中的一个学习率调度器类,用于自定义学习率调整策略。
return LambdaLR(optimizer, lr_lambda, last_epoch)
# 执行前向传播、计算损失和准确率。
def model_fn(batch, model, criterion, device):
mels, labels = batch
mels = mels.to(device)
labels = labels.to(device)
outs = model(mels)
loss = criterion(outs, labels)
# 使用 argmax(1) 获取概率最高的说话人ID作为预测结果
preds = outs.argmax(1)
accuracy = torch.mean((preds == labels).float())
return loss, accuracy
def valid(dataloader, model, criterion, device):
model.eval()
running_loss = 0.0
running_accuracy = 0.0
pbar = tqdm(total=len(dataloader.dataset), ncols=0, desc="Valid", unit=" uttr")
for i, batch in enumerate(dataloader):
with torch.no_grad():
loss, accuracy = model_fn(batch, model, criterion, device)
running_loss += loss.item()
running_accuracy += accuracy.item()
pbar.update(dataloader.batch_size)
pbar.set_postfix(
loss=f"{running_loss / (i + 1):.2f}",
accuracy=f"{running_accuracy / (i + 1):.2f}",
)
pbar.close()
model.train()
return running_accuracy / len(dataloader)
def parse_args():
"""arguments"""
config = {
"data_dir": "./Dataset",
"save_path": "model.ckpt",
"batch_size": 32,
"n_workers": 8,
"valid_steps": 2000,
"warmup_steps": 1000,
"save_steps": 10000,
"total_steps": 70000,
}
return config
def main(
data_dir,
save_path,
batch_size,
n_workers,
valid_steps,
warmup_steps,
total_steps,
save_steps,
):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"[Info]: Use {device} now!")
train_loader, valid_loader, speaker_num = get_dataloader(data_dir, batch_size, n_workers)
train_iterator = iter(train_loader)
print(f"[Info]: Finish loading data!", flush=True)
model = Classifier(n_spks=speaker_num).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = AdamW(model.parameters(), lr=1e-3)
scheduler = get_cosine_schedule_with_warmup(optimizer, warmup_steps, total_steps)
print(f"[Info]: Finish creating model!", flush=True)
best_accuracy = -1.0
best_state_dict = None
pbar = tqdm(total=valid_steps, ncols=0, desc="Train", unit=" step")
for step in range(total_steps):
# Get data
try:
batch = next(train_iterator)
except StopIteration:
train_iterator = iter(train_loader)
batch = next(train_iterator)
loss, accuracy = model_fn(batch, model, criterion, device)
batch_loss = loss.item()
batch_accuracy = accuracy.item()
# Updata model
loss.backward()
optimizer.step()
scheduler.step()
optimizer.zero_grad()
# Log
pbar.update()
pbar.set_postfix(
loss=f"{batch_loss:.2f}",
accuracy=f"{batch_accuracy:.2f}",
step=step + 1,
)
# Do validation
if (step + 1) % valid_steps == 0:
pbar.close()
valid_accuracy = valid(valid_loader, model, criterion, device)
# keep the best model
if valid_accuracy > best_accuracy:
best_accuracy = valid_accuracy
best_state_dict = model.state_dict()
pbar = tqdm(total=valid_steps, ncols=0, desc="Train", unit=" step")
# Save the best model so far.
if (step + 1) % save_steps == 0 and best_state_dict is not None:
torch.save(best_state_dict, save_path)
pbar.write(f"Step {step + 1}, best model saved. (accuracy={best_accuracy:.4f})")
pbar.close()
if __name__ == "__main__":
main(**parse_args())
class InferenceDataset(Dataset):
def __init__(self, data_dir):
testdata_path = Path(data_dir) / "testdata.json"
metadata = json.load(testdata_path.open())
self.data_dir = data_dir
self.data = metadata["utterances"]
def __len__(self):
return len(self.data)
def __getitem__(self, index):
utterance = self.data[index]
feat_path = utterance["feature_path"]
mel = torch.load(os.path.join(self.data_dir, feat_path))
return feat_path, mel
def inference_collate_batch(batch):
"""Collate a batch of data."""
feat_paths, mels = zip(*batch)
return feat_paths, torch.stack(mels)
def parse_args():
"""arguments"""
config = {
"data_dir": "./Dataset",
"model_path": "./model.ckpt",
"output_path": "./output.csv",
}
return config
def main(
data_dir,
model_path,
output_path,
):
"""Main function."""
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"[Info]: Use {device} now!")
mapping_path = Path(data_dir) / "mapping.json"
mapping = json.load(mapping_path.open())
dataset = InferenceDataset(data_dir)
dataloader = DataLoader(
dataset,
batch_size=1,
shuffle=False,
drop_last=False,
num_workers=8,
collate_fn=inference_collate_batch,
)
print(f"[Info]: Finish loading data!", flush=True)
speaker_num = len(mapping["id2speaker"])
model = Classifier(n_spks=speaker_num).to(device)
model.load_state_dict(torch.load(model_path))
model.eval()
print(f"[Info]: Finish creating model!", flush=True)
results = [["Id", "Category"]]
for feat_paths, mels in tqdm(dataloader):
with torch.no_grad():
mels = mels.to(device)
outs = model(mels)
preds = outs.argmax(1).cpu().numpy()
for feat_path, pred in zip(feat_paths, preds):
results.append([feat_path, mapping["id2speaker"][str(pred)]])
with open(output_path, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerows(results)
if __name__ == "__main__":
main(**parse_args())