这是构建你企业AI护城河的开始------专属数据+专属模型
开篇:为什么微调是中小企业的AI护城河?
最近我了解到一家医疗科技公司做AI诊断系统时,发现了一个有趣的现象:他们用GPT-4处理专业医疗问题时,准确率只有65%,但通过专门的数据微调后,准确率提升到了92%,而成本只有专门训练模型的1/20。
模型微调不是大公司的专利,而是中小企业的AI民主化工具。它让你能够:
- 用通用大模型的基础能力
- 结合你的专属数据和业务场景
- 打造真正属于你的AI专家
一、决策框架:何时该用Prompt、RAG、Fine-tuning?
1.1 三种技术的本质区别
Prompt工程:"考试指导"
- 比喻:考试时提供背景信息和明确指令
- 特点:零成本,立即见效
- 局限:受限于模型原有知识
RAG:"开卷考试"
- 比喻:允许查阅参考资料
- 特点:能处理最新和专属知识
- 局限:无法改变模型底层能力
微调:"专业培训"
- 比喻:进行专业领域的深度培训
- 特点:真正改变模型的行为模式
- 局限:成本较高,需要专业数据
1.2 决策流程图
开始
↓
需要实时最新知识?
↓ 是 → 选择RAG
↓ 否
需要高度专业化?
↓ 是 → 选择微调
↓ 否
选择Prompt工程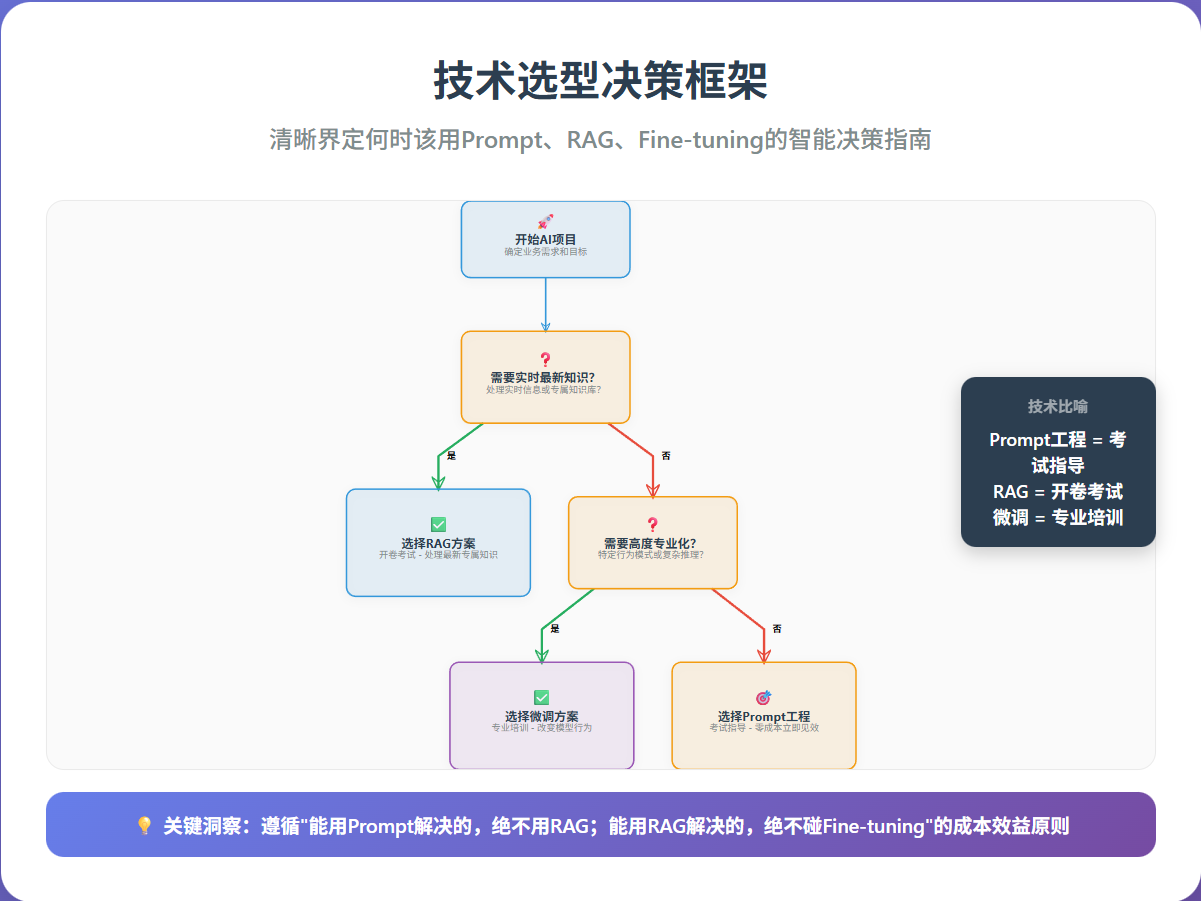
二、成本对比表:全参数微调 vs LoRA/QLoRA的详细ROI分析
2.1 不同微调方式的成本对比
| 微调方式 | 训练成本 | 推理成本 | 效果提升 | 适合场景 |
|---|---|---|---|---|
| 全参数微调 | 很高 | 中等 | 80-95% | 对准确率要求极高 |
| LoRA微调 | 中等 | 低 | 70-85% | 大多数企业场景 |
| QLoRA微调 | 低 | 低 | 65-80% | 资源受限场景 |
| Prompt工程 | 几乎为零 | 低 | 10-50% | 简单任务 |
2.2 实际成本案例分析
案例:金融客服系统微调
全参数微调方案:
- 训练成本:$5,000
- 推理成本:每月$800
- 准确率:92%
- ROI周期:12个月
LoRA微调方案:
- 训练成本:$800
- 推理成本:每月$500
- 准确率:88%
- ROI周期:3个月
结论:对于大多数企业,LoRA微调提供了最佳的性价比。
2.3 ROI计算公式
python
def calculate_roi(training_cost, monthly_inference_cost, accuracy_gain, business_value_per_point):
"""
计算微调的ROI
Args:
training_cost: 训练成本
monthly_inference_cost: 每月推理成本
accuracy_gain: 准确率提升百分比
business_value_per_point: 每1%准确率提升的业务价值
"""
annual_business_value = accuracy_gain * business_value_per_point * 12
annual_cost = training_cost + monthly_inference_cost * 12
roi = (annual_business_value - annual_cost) / annual_cost
payback_period = training_cost / (annual_business_value / 12 - monthly_inference_cost)
return {
'roi': roi,
'payback_period': payback_period,
'annual_net_value': annual_business_value - annual_cost
}
# 示例计算
result = calculate_roi(
training_cost=800, # LoRA微调成本
monthly_inference_cost=500, # 每月推理成本
accuracy_gain=20, # 准确率提升20%
business_value_per_point=100 # 每1%准确率提升价值$100/月
)
print(f"ROI: {result['roi']:.2f}")
print(f"回收期: {result['payback_period']:.1f} 个月")
print(f"年净收益: ${result['annual_net_value']}")
三、LoRA技术详解:参数高效微调的革命
3.1 LoRA的核心思想
LoRA(Low-Rank Adaptation)的核心洞察是:大模型在微调时,其实只需要调整很少的参数就能达到很好的效果。
数学原理
原始权重: W ∈ R^(d×k)
LoRA更新: ΔW = BA, 其中 B ∈ R^(d×r), A ∈ R^(r×k)
最终权重: W' = W + ΔW = W + BA其中 r << min(d,k),这就是"低秩"的含义。
3.2 LoRA的优势
- 参数效率:只训练0.1%-1%的参数
- 内存友好:大幅减少显存占用
- 快速训练:训练速度提升3-5倍
- 模块化:多个任务可以共享基础模型
3.3 LoRA实战代码
python
import torch
import torch.nn as nn
from peft import LoraConfig, get_peft_model
# LoRA配置
lora_config = LoraConfig(
r=16, # 秩
lora_alpha=32,
target_modules=["q_proj", "v_proj"], # 目标模块
lora_dropout=0.1,
bias="none",
)
# 应用LoRA到模型
model = ... # 你的基础模型
model = get_peft_model(model, lora_config)
# 查看可训练参数
model.print_trainable_parameters()
# 输出: trainable params: 8,388,608 || all params: 7,000,000,000 || trainable%: 0.12四、QLoRA:在消费级GPU上微调大模型
4.1 QLoRA的技术突破
QLoRA在LoRA基础上引入了4位量化,实现了显存的"大瘦身":
- 65B参数模型:从780GB显存降至48GB
- 7B参数模型:从16GB显存降至6GB
- 单张消费级GPU:RTX 4090即可微调大模型
4.2 QLoRA实战代码
python
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
from peft import LoraConfig, get_peft_model
# 4位量化配置
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# 加载量化模型
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-chat-hf",
quantization_config=bnb_config,
device_map="auto"
)
# 应用LoRA
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)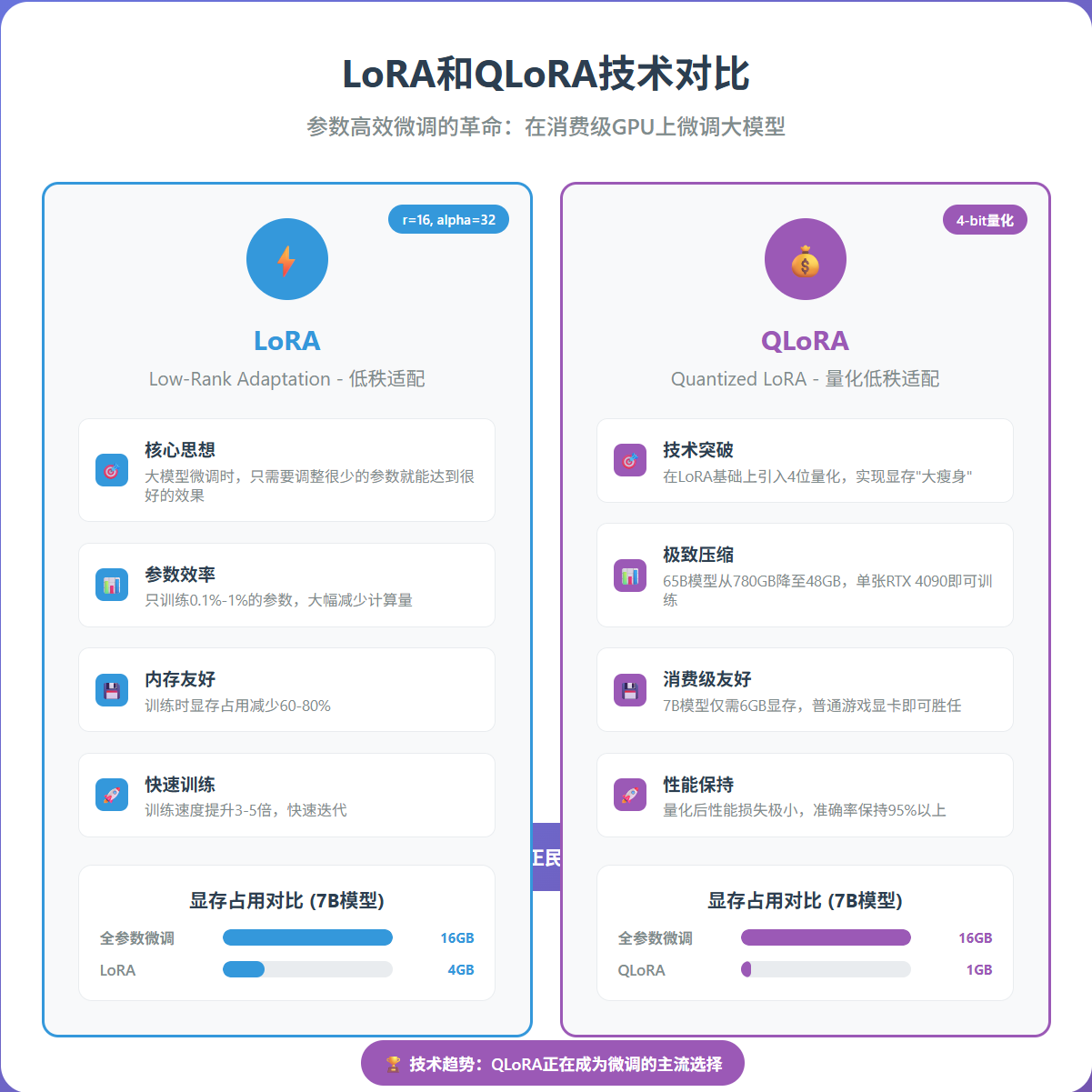
五、完整操作指南:从数据准备到评估上线的端到端流程
5.1 阶段1:数据准备(最关键的一步)
数据质量原则
- 质量 > 数量:1000条高质量数据 > 10000条低质量数据
- 多样性:覆盖各种场景和边缘情况
- 一致性:标注标准要统一
数据格式示例
json
{
"instruction": "请分析以下医疗报告,给出专业建议",
"input": "患者男性,45岁,主诉胸闷、气短1周。心电图显示ST段抬高...",
"output": "根据心电图表现,考虑急性心肌梗死可能。建议立即进行心肌酶谱检查..."
}5.2 阶段2:模型选择和配置
模型选择指南
| 业务场景 | 推荐模型 | 理由 |
|---|---|---|
| 中文任务 | Qwen、ChatGLM | 中文优化更好 |
| 代码生成 | CodeLlama | 专门优化 |
| 通用对话 | Llama、Mistral | 综合能力强 |
| 成本敏感 | 较小模型 | 推理成本低 |
超参数调优
python
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
warmup_steps=100,
learning_rate=2e-4,
fp16=True,
logging_steps=10,
save_steps=500,
)5.3 阶段3:训练和监控
训练监控指标
- 训练损失:确保在下降
- 评估准确率:在验证集上的表现
- GPU使用率:优化资源利用
- 训练速度:迭代次数/小时
早停策略
python
from transformers import EarlyStoppingCallback
early_stopping = EarlyStoppingCallback(
early_stopping_patience=3,
early_stopping_threshold=0.01
)5.4 阶段4:评估和优化
评估指标体系
python
def evaluate_model(model, test_dataset):
results = {}
# 准确率
results['accuracy'] = calculate_accuracy(model, test_dataset)
# 专业度
results['expertise_score'] = calculate_expertise(model, test_dataset)
# 一致性
results['consistency'] = calculate_consistency(model, test_dataset)
# 响应时间
results['response_time'] = calculate_response_time(model)
return results5.5 阶段5:部署和监控
生产部署策略
- A/B测试:新旧模型对比
- 灰度发布:逐步扩大流量
- 监控告警:性能异常检测
- 回滚机制:快速恢复
监控指标
- QPS(每秒查询数)
- 响应时间P95
- 错误率
- 成本消耗
六、实战案例:医疗问答系统微调
6.1 业务背景
一家医疗科技公司需要构建专业的医疗问答系统,处理患者关于症状、药物、治疗方案的问题。
6.2 技术方案
数据准备
- 来源:医学教科书、临床指南、专家问答
- 数量:5000条高质量问答对
- 标注:由执业医师审核
模型选择
- 基础模型:Qwen-7B-Chat
- 微调方式:QLoRA
- 训练硬件:单张RTX 4090
训练配置
python
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj", "k_proj", "o_proj"],
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM"
)
training_args = TrainingArguments(
output_dir="./medical-qa-model",
num_train_epochs=5,
per_device_train_batch_size=2,
gradient_accumulation_steps=8,
warmup_steps=100,
learning_rate=1e-4,
fp16=True,
logging_steps=50,
save_steps=500,
evaluation_strategy="steps",
eval_steps=500,
)6.3 效果对比
| 指标 | 微调前 | 微调后 | 提升 |
|---|---|---|---|
| 医疗准确率 | 65% | 92% | +27% |
| 专业术语理解 | 70% | 95% | +25% |
| 临床建议质量 | 60% | 88% | +28% |
| 用户满意度 | 3.2/5 | 4.6/5 | +1.4 |
6.4 成本分析
- 训练成本:$600(电费+云资源)
- 推理成本:每月$400
- 业务价值:每月$5,000(减少人工客服成本)
- ROI:2个月回收投资
七、常见陷阱和避坑指南
7.1 数据相关陷阱
陷阱1:数据质量不足
症状 :模型过拟合,在训练集上表现好但泛化能力差
解决方案:
- 加强数据清洗和去重
- 引入数据增强技术
- 建立严格的质量审核流程
陷阱2:数据分布偏差
症状 :模型在某些场景表现好,其他场景差
解决方案:
- 分析数据分布,确保覆盖所有重要场景
- 对稀有场景进行过采样
- 建立平衡的训练集
7.2 技术相关陷阱
陷阱3:过拟合
症状 :训练损失持续下降,但验证损失开始上升
解决方案:
- 使用早停策略
- 增加Dropout
- 数据增强
- 正则化
陷阱4:灾难性遗忘
症状 :模型忘记原有通用能力
解决方案:
- 在训练数据中混合通用数据
- 使用更小的学习率
- LoRA等参数高效方法
7.3 工程相关陷阱
陷阱5:评估不充分
症状 :线上效果远低于线下评估
解决方案:
- 建立真实的测试集
- A/B测试验证
- 监控线上表现
陷阱6:部署复杂
症状 :模型部署困难,维护成本高
解决方案:
- 使用标准化的部署工具
- 建立CI/CD流水线
- 容器化部署
八、未来趋势:微调技术的进化方向
8.1 自动化微调
未来的微调将越来越自动化:
- 自动超参数调优:AI优化AI的训练参数
- 自动数据选择:智能选择最有价值的数据
- 自动模型选择:根据任务自动选择最佳基础模型
8.2 多模态微调
随着多模态模型的发展,微调将扩展到:
- 图像理解:专业领域的图像识别
- 音频处理:特定场景的语音理解
- 视频分析:时序数据的专业处理
8.3 联邦微调
保护数据隐私的同时实现模型个性化:
- 本地训练:数据不出本地
- 模型聚合:中心服务器聚合模型更新
- 隐私保护:差分隐私等技术
九、总结与行动指南
9.1 核心要点回顾
- 微调是中小企业的AI民主化工具,不是大公司专利
- LoRA/QLoRA让微调成本大幅降低,在消费级GPU上即可完成
- 数据质量比数据数量更重要,1000条高质量数据足够
- 完整的生命周期管理从数据准备到部署监控缺一不可
9.2 立即行动的建议
个人层面:
- 学习LoRA/QLoRA技术原理
- 实践小规模微调项目
- 建立个人微调工具链
团队层面:
- 评估团队的微调需求
- 建立数据标注和质量控制流程
- 部署微调基础设施
企业层面:
- 制定AI微调战略
- 投资专业的数据团队
- 建立模型生命周期管理体系
9.3 下一站预告
在下一篇文章中,我们将深入探讨智能体开发框架深度解析,学习如何从"工具调用"进化到"自主业务员",这是AI应用的终极形态。
思考题:
- 在你的业务中,哪些场景最适合用模型微调?
- 如何评估微调项目的ROI?
- 你认为微调技术最大的挑战是什么?
欢迎在评论区分享你的微调实践经验!