文章目录
与clip的区别
clip是单帧搜索,CLIP4Clip是对整个视频进行搜索(比如帮我找到某个视频)
老师讲某个知识点的片段
教学视频中检索"老师讲解牛顿第二定律的片段";
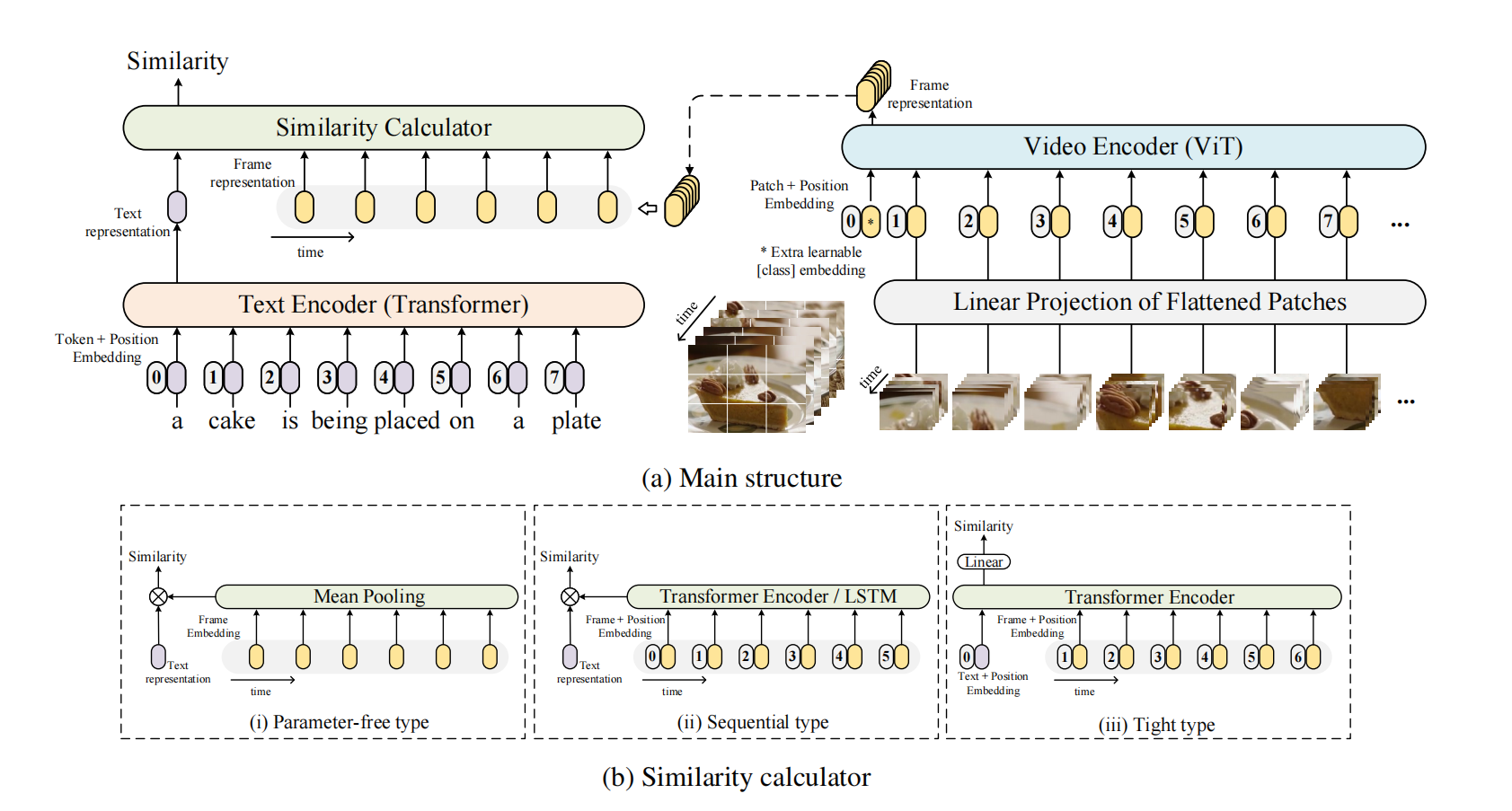
安防视频中检索"有人翻墙进入的时刻"。1.视频输入由多个帧(或视频片段)组成,而 CLIP 原本只处理单张图像,因此需要设计方法将多个视频帧的特征与文本进行对齐。
2.设计三种视频-文本相似度计算机制
这是论文的核心创新之一,探索了如何将多个视频帧的特征与文本特征进行匹配:
Parameter-free(无参数型):直接对多个视频帧的 CLIP 图像编码结果取平均,再与文本特征计算相似度。不引入新参数,简单高效。
Sequential(序列型):使用 RNN 或 Transformer 等序列模型建模帧间时序关系,再融合特征。
Tight(紧密型):在视频和文本编码之间引入更复杂的交互机制(如 cross-attention),实现更精细的对齐。
abstract
视频-文本检索在多模态研究中扮演着至关重要的角色,并已广泛应用于许多现实世界的网络应用中。CLIP(对比语言-图像预训练)是一种图像-语言预训练模型,已在从网络收集的图像-文本数据集中展现了强大的视觉概念学习能力。在本文中,我们提出了一种CLIP4Clip模型,旨在以端到端的方式将CLIP模型的知识迁移到视频-语言检索任务中。我们通过实证研究探讨了以下几个问题:
1)图像特征是否足以胜任视频-文本检索任务?
2)基于CLIP模型在大规模视频-文本数据集上进行后续预训练如何影响性能?3)建模视频帧之间时间依赖性的有效机制是什么?
4)模型在视频-文本检索任务中的超参数敏感性如何?
大量实验结果表明,从CLIP迁移而来的CLIP4Clip模型在多个视频-文本检索数据集上均达到了当前最优(SOTA)的性能,包括MSR-VTT、MSVC、LSMDC、ActivityNet和DiDeMo。我们的代码已公开发布,地址为:https://github.com/ArrowLuo/CLIP4Clip。
intruction
随着每天上传到网络的视频数量不断增加,视频-文本检索正逐渐成为人们高效查找相关视频的迫切需求。除了实际的网络应用外,视频-文本检索也是多模态视觉与语言理解中的一项基础研究任务。我们可以根据先前工作的输入形式将其直接区分为两类:原始视频(像素级)或视频特征(特征级)。
通常,预训练模型(Zhu 和 Yang, 2020;Luo 等, 2020;Li 等, 2020;Gabeur 等, 2020;Patrick 等, 2021;Rouditchenko 等, 2020)属于特征级方法,因为它们是在一些大规模视频-文本数据集(例如 Howto100M,Miech 等, 2019)上训练的。这些模型的输入是通过现成的、冻结的视频特征提取器生成的缓存特征。如果直接使用原始视频作为输入,会使预训练过程非常缓慢甚至不可行。然而,得益于大规模数据集,这些预训练模型在视频-文本检索任务上表现出显著的性能提升。
像素级方法则直接以原始视频作为输入进行模型训练(Torabi 等, 2016;Kiros 等, 2014;Yu 等, 2016a;Kaufman 等, 2017;Yu 等, 2017, 2018)。早期文献几乎都属于这一类方法。该方法将视频特征提取器与配对文本一起联合学习。相反,特征级方法高度依赖于一个合适的特征提取器,无法将学习信号反向传播至固定的视频编码器。
最近一些工作开始尝试采用像素级方法进行模型预训练,使预训练模型能够直接从原始视频中学习。其中的主要挑战是如何降低密集视频输入带来的巨大计算开销。例如,ClipBERT(Lei 等, 2021)采用稀疏采样策略,使得端到端预训练成为可能:具体来说,模型在每次训练步骤中仅从视频中稀疏地采样一个或少数几个短视频片段。实验结果表明,端到端训练有助于提升底层特征提取能力,而少量稀疏采样的片段已足以完成视频-文本检索任务。Frozen(Bain 等, 2021)将图像视为单帧视频,并设计了一种课程学习策略,在图像和视频数据集上联合训练模型。结果表明,从单帧图像逐步过渡到多帧视频的课程学习策略能有效提升训练效率。
本文的目标并非从头预训练一个新的视频-文本检索模型,而是重点研究如何将图像-文本预训练模型 CLIP(Radford 等, 2021)的知识迁移到视频-文本检索任务中。
我们利用预训练的 CLIP 模型,提出了一种名为 CLIP4Clip(CLIP for video Clip retrieval,即用于视频片段检索的 CLIP)的模型来解决视频-文本检索问题。具体而言,CLIP4Clip 建立在 CLIP 的基础上,并设计了一个相似度计算器,探索了三种相似度计算方式:无参数型(parameter-free type)、序列型(sequential type)和紧密型(tight type)。与我们的工作同期,Portillo-Quintero 等(2021)也基于 CLIP 开展了视频-文本检索研究。不同之处在于,他们的工作直接利用 CLIP 进行零样本预测,未考虑不同的相似度计算机制。而我们设计了多种相似度计算方法以提升性能,并以端到端方式训练模型。本文的主要贡献包括:
1)我们基于预训练的 CLIP 探索了三种相似度计算机制;
2)我们在一个大规模、含噪声的视频-语言数据集上对 CLIP 进行了后续预训练,以学习更优的检索空间。大量实验表明,我们的模型在 MSR-VTT(Xu 等, 2016)、MSVC(Chen 和 Dolan, 2011)、LSMDC(Rohrbach 等, 2015)、ActivityNet(Krishna 等, 2017a)和 DiDeMo(Hendricks 等, 2017)等多个数据集上均达到了新的最先进(SOTA)性能。
此外,通过广泛的实验,我们得出以下几点重要发现:
1)仅使用单帧图像远远不足以有效编码整个视频用于视频-文本检索任务。
2)在大规模视频-文本数据集上对 CLIP4Clip 模型进行后续预训练是必要的,能够显著提升性能,尤其是在零样本预测任务上提升幅度巨大。
3)对于小规模数据集,借助强大的预训练 CLIP 模型,最好避免引入过多新参数,采用对视频帧进行平均池化(mean pooling)的方式即可;而对于大规模数据集,则更适合引入更多参数(例如自注意力层)来学习帧间的时间依赖关系。
4)我们对超参数进行了细致研究,并报告了最优配置方案。